1. Introduction
Abnormalities are present everywhere in day-to-day life. In many cases, these abnormalities or anomalies can be life critical and therefore they have to be identified at all costs. Anomaly detection is the process of identifying dissimilar samples from a total lot of samples [
1]. A wide range of applications already exists which are based on the detection of abnormalities such as medical diagnostics, video surveillance, fraud detection, surface defect detection, etc. [
2]. It is fairly simple for humans to detect abnormalities in images if some prior information about what anomalies look like is known. However, this is an extremely complex task to automate. To begin with, the borderline between normal and anomalous behavior is often marginal and imprecise. The scarcity of labeled data for training and validation also imposes further limitations on the performance that can be achieved in anomaly detection. Two major challenges that are typically encountered in anomaly detection with high dimensional data such as images are the absence of labeled data and the shortage of anomalous instances [
2]. To address these problems, this work focuses on unsupervised anomaly detection algorithms that require no labels in the training set or only labels from one class. Algorithms that utilize only one class of samples come under the category of one-class learning algorithms that aim to identify whether a data point belongs to a particular category [
3].
To solve multi-perspective anomaly detection, one has to first know how single-view anomaly detection can be addressed. Standard single-view anomaly detection techniques such as One-Class SVM (OC-SVM) [
4] or Kernel Density Estimation (KDE) [
5] work out of the box with low-dimensional data but these techniques often fail when dealing with high-dimensional data such as images [
6]. To successfully use these methods with images, typically discriminative features or feature vectors of fixed length are extracted using some hand-designed feature extractors. This process is time-consuming and also requires human effort for designing sensible feature extractors. Deep learning has established itself as the first and foremost method for automatic feature extraction from images. Single-view anomaly detection techniques can be broadly categorized into two types of methods, i.e., pure deep learning-based algorithms that solve anomaly detection, or a combination of deep learning with traditional machine learning approaches [
7]. The latter approach is also known as a hybrid approach as it combines two domains by using the advantages of both. One such state-of-the-art pure deep-learning-based single-view anomaly detection technique is Deep Support Vector Data Description (Deep SVDD) [
6]. Deep SVDD can be considered as an extension of the Support Vector Data Description (SVDD) [
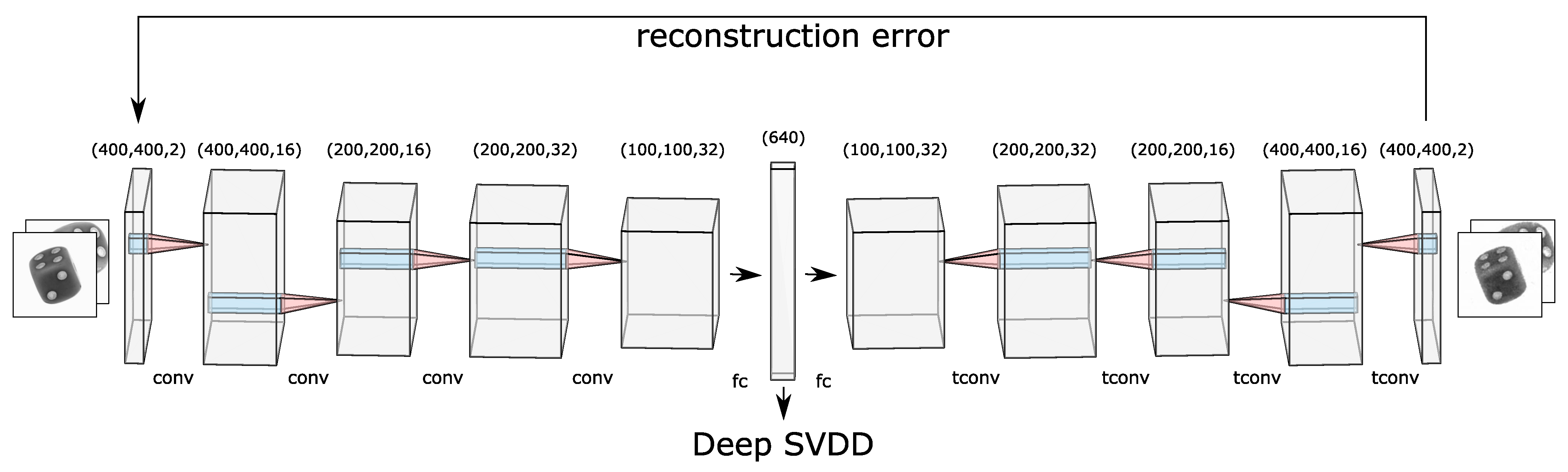
8] algorithm which aims to confine all the one-class data points inside a minimal volume hypersphere. The Deep SVDD algorithm employs a neural network to transform high-dimensional input into lower-dimensional feature space such that a minimal volume hypersphere comprising of all the one-class data points can be built.
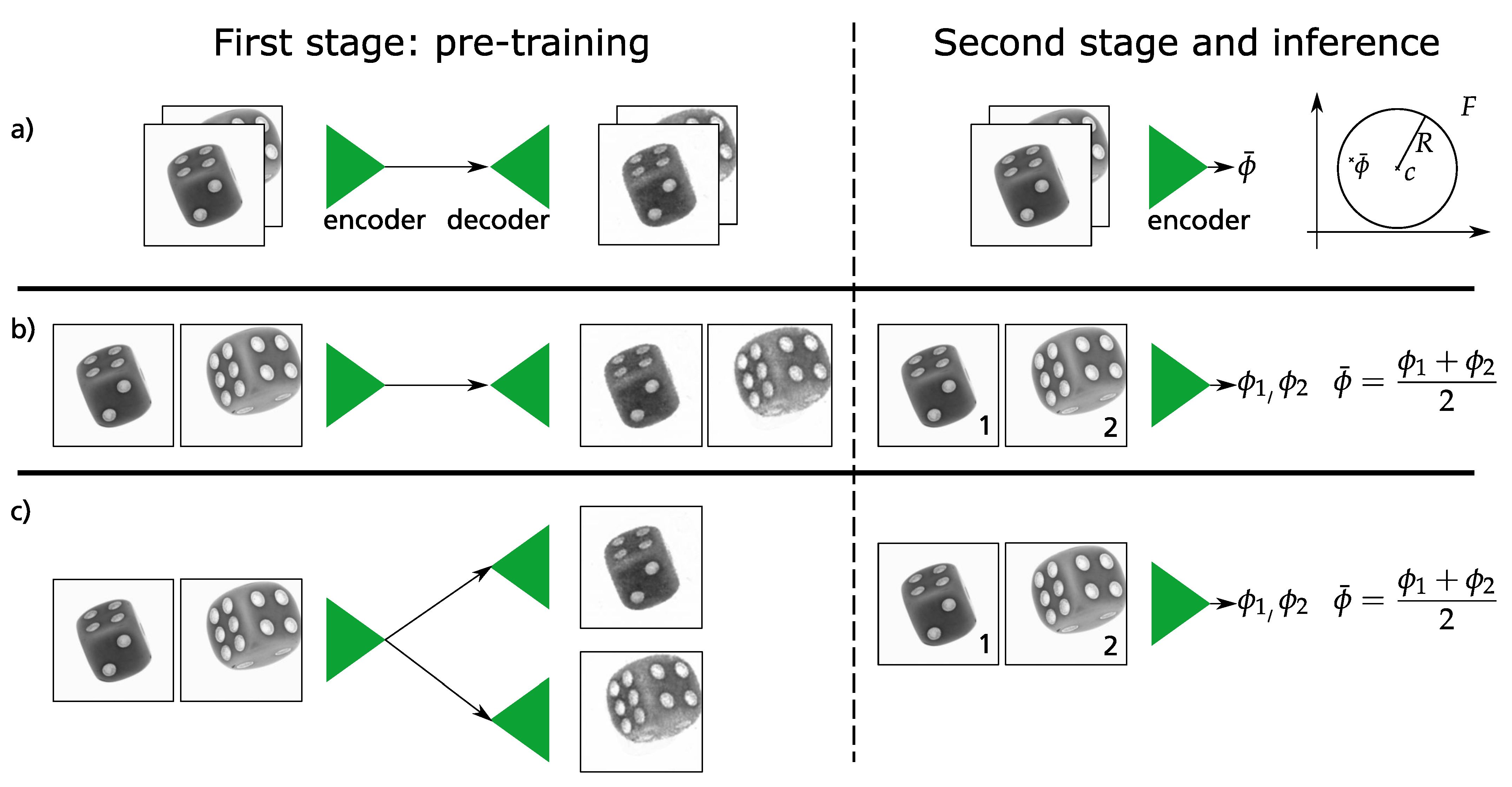
In this work, we extend the Deep SVDD algorithm to address multi-perspective anomaly detection based on novel fusion techniques. If multiple images of a sample are available, all having different pose or lighting conditions then how does one decide if the object is anomalous? For making such a prediction, one may need to know in which perspective the anomaly is present, and if it can be trusted. The multi-perspective anomaly detection task can be addressed using state-of-the-art single-perspective anomaly approaches by employing them multiple times on each of the perspectives, followed by a fusion of the individual predictions with a voting scheme. Here, a voting schema such as majority voting should consider the statistics of each experiment and their inter-dependency to obtain consensus. Motivated by the expected anomalies (e.g., scratches on a concave surface), an experimental setting with three perspectives can be designed where a majority schema will never be able to detect the anomaly as long as at most one perspective has the chance to view the anomaly. In contrast, a minority voting is not promising while considering finite false positive or negative rates, e.g., the pseudo scrap rate will be always higher compared to single-perspective runs. Consequently, we have to adapt an existing single-perspective approach and fuse information prior to classification. To combine information from different perspectives, three different fusion strategies are developed, i.e., early fusion, late fusion, and late fusion with dual decoders.
We outline the major contributions of this work as:
We enhance the Deep SVDD algorithm by using a denoising process and data augmentation techniques.
We introduce three different fusion approaches that can handle multiple perspectives (as a proof of concept we work with two perspectives) of an object to obtain one single robust prediction as to whether the object is anomalous.
We develop a new multi-perspective image dataset (also containing two perspectives) that is used for evaluating different algorithms.
We perform exhaustive evaluations of our approach on both our proposed dices dataset and the standard MNIST dataset on which we achieve state-of-the-art performance. For the dices dataset, the focus is on the detection of low-level anomalies. The use of MNIST refers to high-level anomalies, because the whole object (i.e., every single digit) changes.
The rest of the paper is structured as follows. We first present the related work in anomaly detection in
Section 2. We then present a short introduction on single-view anomaly detection technique Deep SVDD [
6] in
Section 3, followed by a detailed description of the three different fusion techniques. Subsequently, we describe the data collection procedure that we employ for the “dices dataset” that we introduce in this work and a brief description of how we extend the MNIST dataset [
9] to a multi-perspective setting. In
Section 4, we present the results of our approach on multi-perspective data in comparison to baseline techniques and provide a thorough discussion on the results in
Section 5. Finally, we present the conclusions and directions for future work in
Section 6.
2. Related Work
Ruff et al. [
10] already covers an extensive review to detect anomalies with the help of machine learning and deep learning techniques. Two major findings are: First, deep learning can be easily applied to high-dimensional data. Second, one favorite route to extract features implies convolutional autoencoders of different flavors of which we are using deep (e.g., [
11]) and denoising autoencoders [
12]. Furthermore, generative approaches also try to learn the “normal” class [
13] but are harder to train. In this contribution, we employ the Deep SVDD [
6] approach that uses the advantage of feature extraction with the help of an autoencoder. Furthermore, Ruff et al. even provide a semi-supervised version of their Deep SVDD [
14]. If only one-class training data is available this variation of Deep SVDD cannot be employed.
This contribution focuses on how to fuse information for multi-perspective anomaly detection. Multiple perspectives or views are generally associated with data obtained from different modalities [
15]. In the case of high dimensional data such as images, it also refers to different features that can be extracted for a single-view such as a scene descriptor (GIST, [
16]), Histogram of Oriented Gradients (HOG), and Local Binary Patterns (LBP) [
17]. Whereas, multi-perspective in our case refer to different perspectives of an object that are captured from different orientations. The fusion of multiple perspectives for addressing complex tasks such as image classification or 3D shape reconstruction has gained interest in recent years [
18,
19,
20,
21,
22]. The fusion of (low-dimensional) data is common in many fields such as autonomous vehicles where data from different sensors are merged using Kalman filters [
23], whereas the fusion of high dimensional data puts new questions.
First, how to fuse the information. Sophisticated approaches use so-called gating networks which compute averaging weights in inference times, e.g., [
24,
25]. Another approach is to use recurrent networks to merge autoencoders [
19]. As a robust training of anomaly detection itself is challenging, we simpler methods such as stacking images as different color channels [
26] can be exploited. This is precisely one of the innovations of the present contribution. We achieve significant anomaly detection rates with simple fusion approaches. Next, when do the data fusion [
22], e.g., Sun et al. fuse their information almost at the beginning of one network [
27] whereas Lin and Kumar [
20] concatenate the compressed feature vectors at the end of individual processing. Seeland and Mäder [
22] pointed out that doing so (with the help of a fully connected layer) is the most promising in their classification tasks. Thus, a novelty of this paper is not only to answer the question when the fusion will takes place but also to answer this question in an unsupervised setting.
Nevertheless, there is a lack of work on anomaly detection using multiple views. One of the application covers the detection of facial micro-expressions [
28], e.g., applied on the CASME dataset [
29]. Sheng et al. extract features from images through local binary pattern (LBP) histograms and perform the anomaly detection step on them. In contrast, Deep SVDD directly acts on the latent space. Therefore, it is desirable to build a multi-perspective variant of it to further improve its robustness.
5. Discussion
While analysing the results for the multi-perspective anomaly detection techniques (
Section 4.1) specifically the ones without any augmentation (
Table 2 and
Table 3), it is clear that the early fusion technique performs the best. The reason for this is based on the way that the data points are mapped in the feature space where the hypersphere is found. As described in
Section 3.4, in early fusion there is no averaging of the feature space vectors compared to the other two fusion techniques. The different perspectives are stacked together and fed as input to the algorithm. In late fusion and late fusion with dual decoders, due to averaging of the feature vectors, the overall location is transferred to the wrong side of the hypersphere. For example, consider a case wherein one perspective the anomaly is present and in the opposite perspective, it is not. Hence, the feature space vector for the anomalous perspective is mapped outside the hypersphere and for the non-anomalous perspective inside. In particular cases, the averaging process puts the final feature vector inside the hypersphere which would indeed lead to misclassification. As soon as more than two perspectives are used for the evaluation, this effect should worsen.
From
Table 3, it can be observed that the late fusion technique performs better than the late fusion with the dual decoder. This can be attributed to the same averaging phenomenon: In numerical values, the average Euclidean distance between feature vectors
and
for late fusion with and without dual decoder strongly deviate from each other by the factor of 100. As mentioned before, the hyperparameters are optimized w.r.t. ROC AUC scores and not, e.g., average precision. Hence, the confusion matrices do not look satisfactorily in particular cases, e.g., late fusion w/ dual decoder.
We evaluated the best performing fusion technique, i.e., early fusion with denoising autoencoder on the extended multi-perspective MNIST dataset. The results achieved are summarized together in
Table 5 and good performance is observed for all the different datasets. The dataset having digit one as a non-anomalous class achieved the highest ROC AUC score of more than 99%. Compared to “single-perspective” anomaly detection in [
6], ROC AUC scores are further increased relatively up to 11% for MNIST digit five.
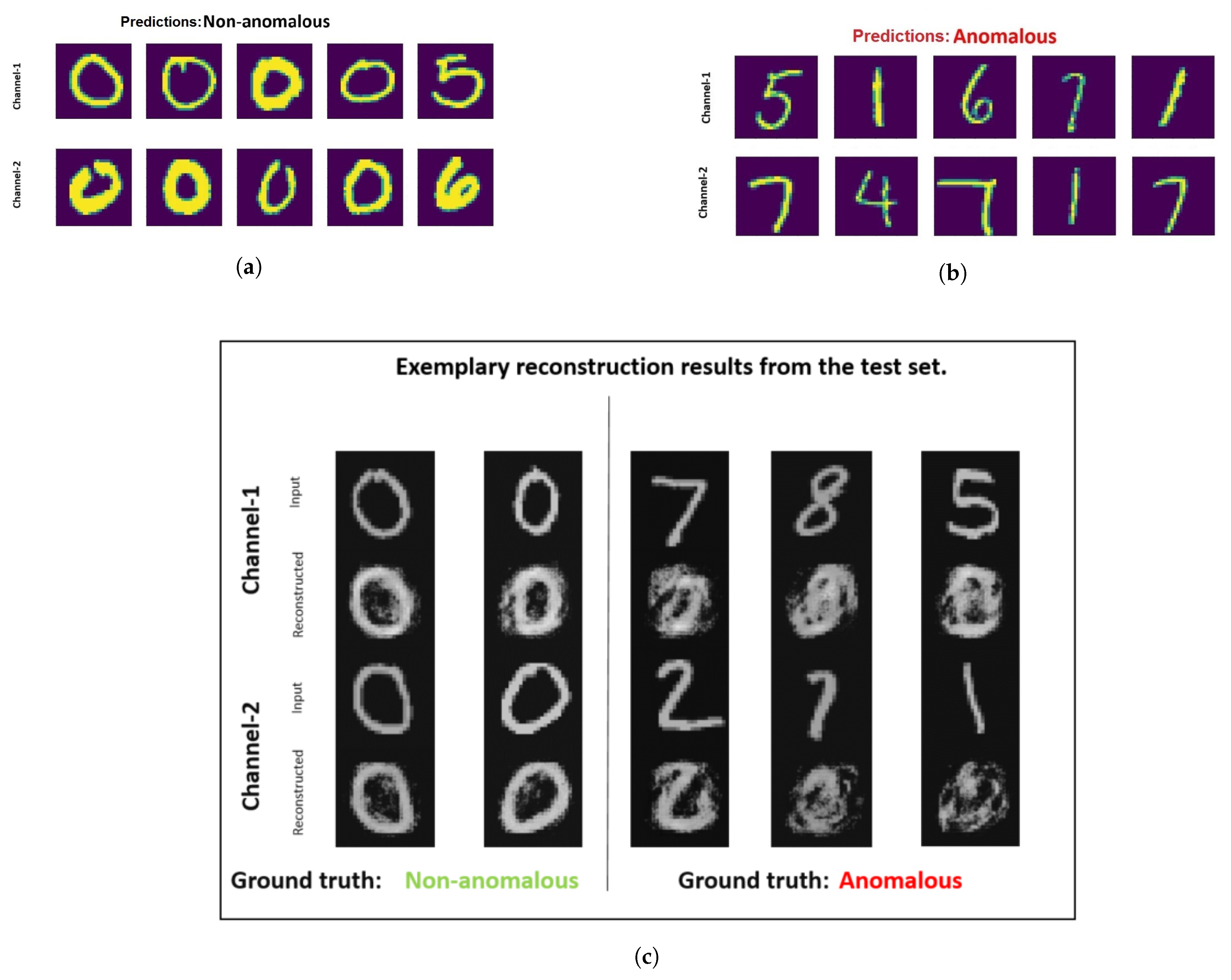
From
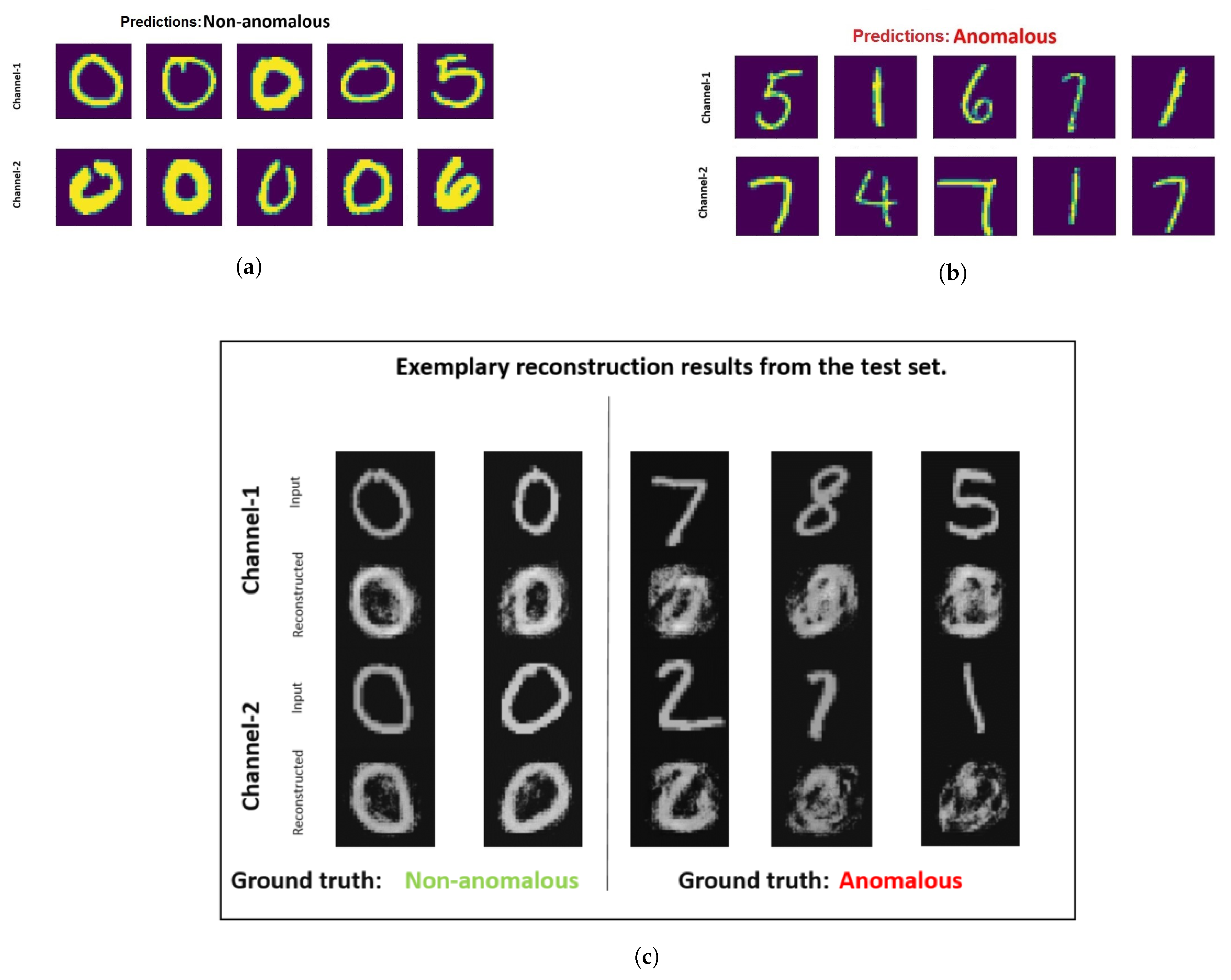
Figure 5a it can be analyzed that the denoising early fusion technique predicts the non-anomalous samples well as digit zero is not present in the top-five anomalous samples. It is also interesting to analyze the fifth most non-anomalous sample which in reality is an example of a misclassified sample. This sample has an image of digit five in channel one and digit six in channel two. One reason for this misclassification could be because of the high visual similarity of the image representing digit six with the non-anomalous class samples containing zeros. In contrast to that, the correct classified image stack having digit six in channel one appears far dissimilar to zero with a closed circle. In
Figure 5c it is visible that the autoencoder used in the pre-training stage of the denoising early fusion technique fails to reconstruct the anomalous samples.
The high performance of our fusion techniques on the MNIST data compared to the performance on our dices dataset (ROC AUC scores of up to 99% vs. 74%) can be attributed to two arguments. First, the anomaly itself covers a greater area in the images (the whole digit is different vs. small scratch on dice) which leads to a higher impact on the used error function during training. In the literature, this aspect is known as “high-level” and “low-level” anomalies [
10]. In the experiment with MNIST, it should be emphasized that the network used is capable of learning the different digits as the respective good object. In the dices dataset, an anomaly is usually present in only one of the perspectives. Whereas, in the MNIST multi-perspective dataset, often both perspectives hold different “anomalous” digits.
It is precisely at this point that it is important to draw comparisons with state-of-the-art shallow anomaly detection algorithms. Looking at the results in
Table 6, in the case of the “high-level” anomalies of the multi-perspective MNIST dataset it makes sense to use an Isolation Forest or One-Class SVM algorithm for the evaluation. However, as soon as “low-level” anomalies occur, the Deep SVDD w/ fusion approach should be chosen (see
Table 4). Obviously, extracting features with a deep network is likely to perform better than with PCA. Furthermore, the performance of the methods depends on the diversity of the dataset, i.e., which “low-level” type of anomaly is to be detected. While adding another dataset would benchmark diversity and thus generalization more, important properties can already be inferred. A closer look at
Table 8 shows that types drilling and sawing are detected much better than, e.g., scratches, since correspondingly less area in the image is occupied by the anomaly. Interestingly, the detection of missing dots works less well than drilling. One reason may be that the network does not learn complex dot patterns of the individual cube faces and is therefore not sensitive to missing dots in the individual pattern.
Observing the results from the ablation study performed with the different augmented multi-perspective dices datasets, it is clear that the augmentations help the model to perform better compared to previous ROC AUC scores. For example in the first set, where all the different types of augmentations are employed, an ROC AUC of
(see
Table 7) is achieved which is the best so far for multi-perspective anomaly detection on the dices test dataset. One may notice that the augmentation technique of erasing patches has similarities with the appearance of certain anomalies in the testing dataset, i.e., drilled holes and missing dots. As mentioned in [
13], this may lead to misclassification. In our case, the erased patches are too big and have a rectangular shape compared to particular anomalies. Hence, the application of this augmentation technique helps the model to generalize better.
It is important to note that the early fusion is not able to benefit from the augmentations (no matter what flavor), but the late fusion and late fusion with multiple decoders not only catches up but surpasses the performance of the early fusion approach. Compare also
Table 8 in this context. Thus, we have confirmed an important result of Seeland and Mäder [
22] also for an unsupervised setting, that fusion should occur as late as possible in latent space. Data augmentation has regularization effects and a high extent of regularization may also cause the model to underfit, which could be the case for early fusion. Interestingly, the misclassification issue while averaging two feature vectors is solved here which leads to the conclusion that as soon as the extraction of relevant features works after training with augmented and noised data, the averaging issue is of less relevance. The best performance of the dual decoding network of
ROC AUC score can be attributed to the same aspect. The feature extraction of the encoder should work effectively so that the two decoders can process the information successfully. Furthermore, it is important to note that all the techniques that boost the multi-perspective anomaly detection performance can also be employed for single-perspective anomaly detection based on Deep SVDD.
6. Conclusions
This work presents novel approaches that address multi-perspective anomaly detection using the fusion of information to extend the well-known Deep SVDD algorithm. As a proof of concept, we employ these approaches for two perspectives. In the case the two perspectives have a chance to miss the anomaly at all it is recommended to use more than two perspectives. The core idea is to fuse the information of the two perspectives at the input of the network (“early fusion”) and the output (“late fusion”). The network itself—a convolutional autoencoder with or without noised input—is trained from scratch whereas hyperparameters were optimized with the Bayesian toolset BOHB.
Another contribution of this work is the novel multi-perspective dices dataset which we use for evaluating the proposed fusion techniques. One promising fusion method is employed on the standard MNIST dataset. This dataset is successfully transferred into the multi-perspective setting and evaluated using early fusion with the denoising autoencoder technique. Overall, the results on the adapted MNIST dataset illustrate the robustness and effectiveness of our approach on “high-level” anomalies, independent what object (digit) is considered. A ROC AUC score of >99% for one of the 10 MNIST adaptions is achieved. The highest ROC AUC score (80%) while predicting anomalies in the multi-perspective dices dataset is achieved with the late fusion technique together with different image augmentation strategies. Here, the detailed anomaly detection rate strongly depends on what kind of anomaly is to be detected (e.g., scratches vs. missing dots on dices).
For future work, increasing the size of the training set size can improve the performance as the authors in [
13] show that the classical supervised classification networks require approximately 5000 labeled examples per class to match or exceed human performance. Augmenting data is inexpensive compared to human effort and time; the number and types of augmentations can be increased to further improve the performance of multi-perspective anomaly detection. Furthermore, in the use case described in this work, there is a lack of anomalous samples available during the training process and another interesting approach would be to consider the augmented samples as anomalous for forming an adversarial training process. The augmented samples can be used indirectly in the training process by not updating the model on these augmented samples but using them as anomalous samples. Utilizing a similarity metric, the difference between the good class samples and the augmented samples can be maximized which will indeed force the network to extract even more robust features from the good class samples.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}