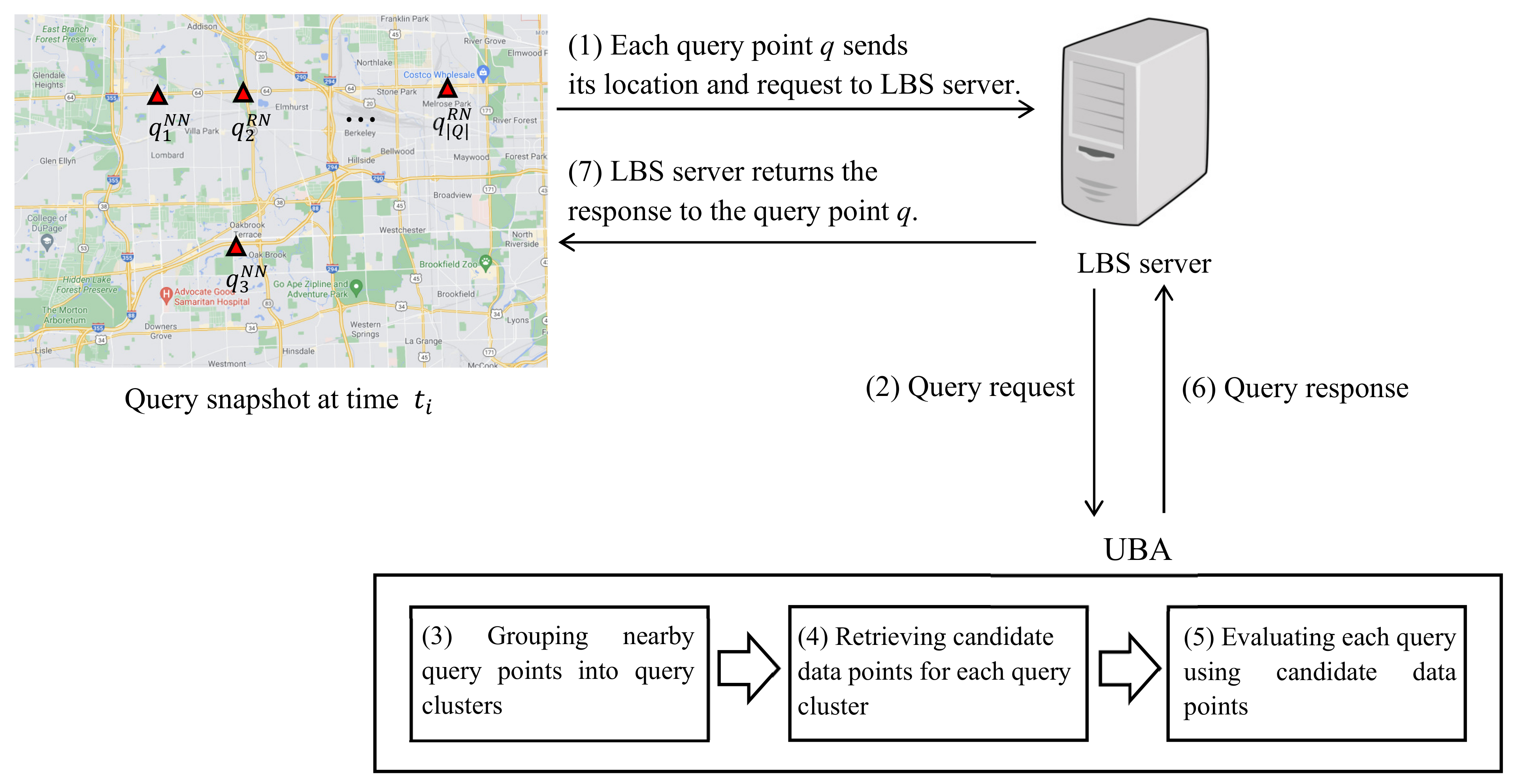
5.1. Experimental Settings
Three real-world spatial networks [
52] (
Table 5) were used for the empirical study. These real-world spatial networks have different sizes and are part of the United States road network. For convenience, the extents of the spatial networks were normalized to a unit square
, and the query distance
r was set to
. The query points followed a centroid distribution, and the data points followed either a centroid or uniform distribution. Here, centroid-based points were generated to mimic highly skewed distributions of POIs in the real world. First, the centroids
were selected randomly based on the extent of the spatial networks, where
is to the number of centroids. The points around each centroid followed a normal distribution, with the mean indicating the centroid, and the standard deviation was set to
. A total of 1–10 centroids were selected as the query points, and five centroids were selected as the data points. The number of NN queries was the same as that of the RN queries for the SP queries. The experimental parameters are listed in
Table 6. In each experiment, a single parameter was varied within the range, and the other parameters were maintained at their default values (shown in bold).
Next, the proposed UBA was compared in terms of query processing time and the number of evaluated SP queries to a sequential algorithm called SEQ, which computes SP queries sequentially. Here, it was assumed that the query and data points moved freely within the dynamic spatial networks. Note that it is impractical to exploit the precomputation techniques presented in the literature [
12,
13,
15] because the precomputed distances might be invalidated frequently when the query and data points run freely within a dynamic spatial network. UBA and SEQ use common subroutines for similar tasks, e.g., the evaluation of SP queries at a single query point; thus, both algorithms were implemented in C++ using the Microsoft Visual Studio 2019 development environment. The experiments were executed on a desktop computer running the Windows 10 operating system with 32 GB RAM and a 3.1 GHz processor (i9-9900). As in many recent studies [
11,
26,
53], the indexing structures for UBA and SEQ remained in main memory to provide prompt responses, which are crucial in online map services. The experiments were repeated 10 times, and the average processing time was measured to determine the SP queries in
Q. As stated previously, the proposed UBA is orthogonal to one-query-at-a-time processing algorithms [
3,
11,
12,
13,
14,
15] and can be easily incorporated into these algorithms. In this study, INE [
3] and RNE [
3] were used to evaluate the NN and RN queries, respectively, for the dynamic spatial networks because INE and RNE are based on network expansion similar to Dijkstra’s algorithm, which is well-suited to dynamic spatial networks.
5.2. Experimental Results
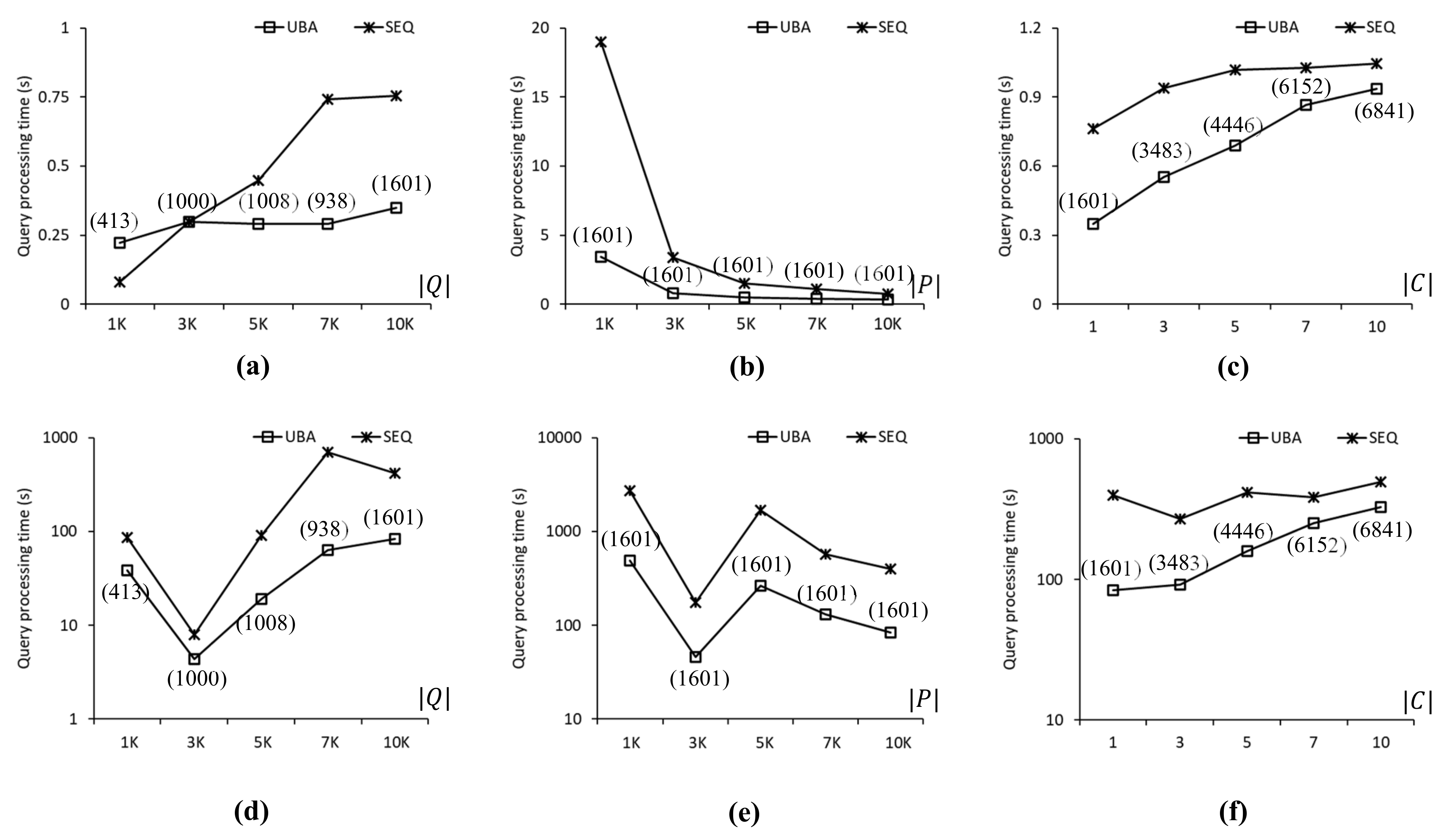
Figure 7 compares the query processing times of UBA and SEQ to evaluate the SP queries in the CAL roadmap. In
Figure 7,
Figure 8 and
Figure 9, the three upper-row and three bottom-row charts show the experimental results when the data points followed a uniform distribution and a centroid distribution, respectively. Each chart shows the query processing time and number of evaluated SP queries by varying one parameter at a time (
Table 6). The values in parentheses in
Figure 7,
Figure 8,
Figure 9 and
Figure 10 indicate the number of SP queries evaluated by the proposed UBA. Note that the numbers of SP queries evaluated by SEQ were omitted because these numbers were exactly equal to
of the SP queries in
Q.
Figure 7a shows the query processing times of UBA and SEQ when
of the query points was between 1 K and 10 K, i.e.,
. As can be seen, the proposed UBA clearly outperformed SEQ as the number of SP queries in
Q increased. In terms of query processing times, UBA was up to 2.9 times faster than SEQ for
. However, UBA was up to 2.59 times slower than SEQ for
. Note that the proposed UBA was not sensitive to
, unlike SEQ, which means that the effectiveness of batch processing in UBA increased as
increased. When
,
,
,
, and
, UBA evaluated fewer SP queries than SEQ by 75%, 89%, 88%, 91%, and 92%, respectively.
Figure 7b shows the query processing times when
of data points was varied between 1 K and 10 K, i.e.,
. Thus, UBA clearly outperformed SEQ in all cases. The query processing times of UBA were up to 8.9 times lower than those of SEQ when
. As the
value decreased, the search space for the NN query processing increased. Regardless of the change in
, UBA and SEQ evaluated 789 and 10,000 SP queries, respectively.
Figure 7c shows the query processing times when
of the centroids for the query points was varied between 1 and 10, i.e.,
. The proposed UBA was up to 2.3 times faster than SEQ for all cases. As
increased, the difference in query processing times between UBA and SEQ decreased because increasing
led to a reduced density of the query points, which resulted in an increased
value. Specifically, when
1, 3, 5, 7, and 10, UBA evaluated 789, 1196, 2438, 3928, and 4015 SP queries, respectively, whereas SEQ evaluated 10 K SP queries for all these cases.
Figure 7d–f show the query processing times of UBA and SEQ when the data points followed a centroid distribution. The query processing times of the proposed UBA were up to 18.95 times lower than those of SEQ for all cases. Unlike the case shown in
Figure 7a, the query processing times of UBA and SEQ did not increase with
, as shown in
Figure 7d, which means that the query processing time was more sensitive to the distribution of data points than
when the data points followed a highly skewed distribution. When
,
,
,
, and
, the query processing times of UBA were 21.7, 162.8, 21.9, 126.8, and 468.7 s, respectively. As shown in
Figure 7d–f, UBA was faster than SEQ in all cases. The difference in query processing times between UBA and SEQ for a centroid distribution of data points was up to several orders of magnitude greater than that for a uniform distribution of data points.
Figure 8 compares the query processing times obtained when using UBA and SEQ to evaluate the SP queries in the FLA roadmap.
Figure 8a shows the query processing time as a function of
. We found that the proposed UBA was up to 2.2 times faster than SEQ for
. However, SEQ was 2.7 times faster than UBA for
because the batch processing of UBA was for a large number rather than a small number of SP queries.
Figure 8b shows the query processing time as a function of
. UBA was 5.5 and 2.2 times faster than SEQ for
and
, respectively, even though UBA and SEQ evaluated 1601 and 10,000 SP queries, respectively, for these two cases. This is because the search space for the NN queries when
was greater than that when
.
Figure 8c shows the query processing time as a function of
, which, for UBA was up to 2.1 times shorter than that of SEQ in all cases. Clearly, the number of query clusters increased with
, which adversely affected the performance of the proposed UBA. As shown in
Figure 8d–f, UBA was up to 11 times faster than SEQ in all cases. The query processing times of both UBA and SEQ fluctuated, which means that the distribution of highly skewed data points affected the NN query processing time significantly. Specifically, as shown in
Figure 8d, the query processing time of UBA for
was 8.9 times longer than that for
despite the difference in the number of SP queries in
Q.
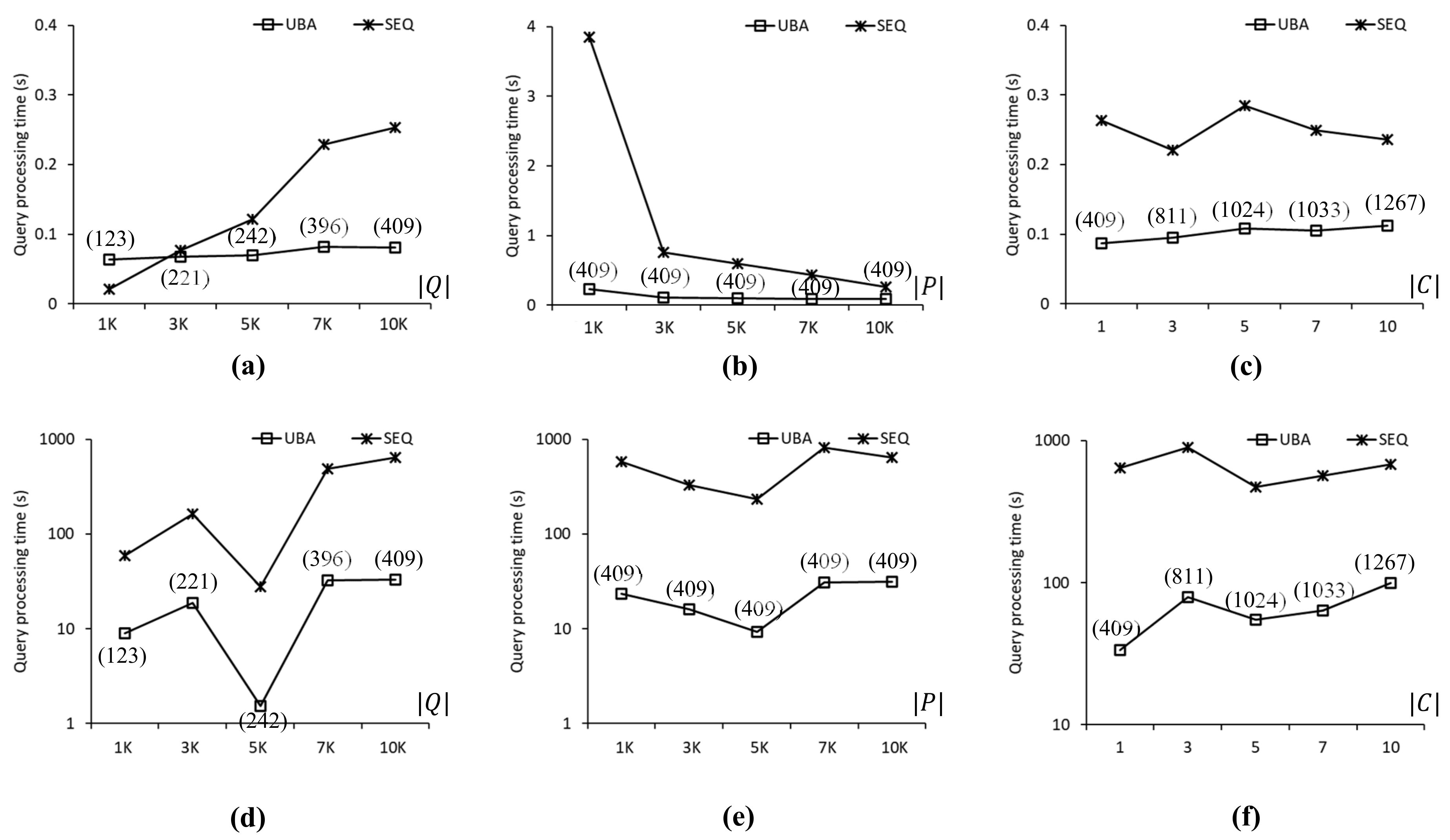
Figure 9 compares the query processing times obtained using UBA and SEQ with the COL roadmap. As shown in
Figure 9a, the proposed UBA was up to 3.1 times faster than SEQ when
. Here, as
increased, UBA was superior to SEQ. As shown in
Figure 9b, UBA was up to 16.3 times faster than SEQ regardless of the
value because UBA and SEQ evaluated 409 and 10,000 SP queries, respectively. Clearly, this difference in the number of evaluated SP queries (i.e., 9591) occurred the proposed UBA can exploit the batch processing of the clustered SP queries; thus, unnecessary distance computations can be avoided. As shown in
Figure 9c, UBA clearly outperformed SEQ in all cases of
. As
increased, the density of the query points decreased, which was ineffective for the batch processing of UBA. As shown in
Figure 9d–f, UBA was up to 26.6 times faster than SEQ in all cases. As shown in
Figure 9d, the query processing times of UBA and SEQ fluctuated significantly because the highly skewed distributions of data points affected the search space of the NN queries significantly.
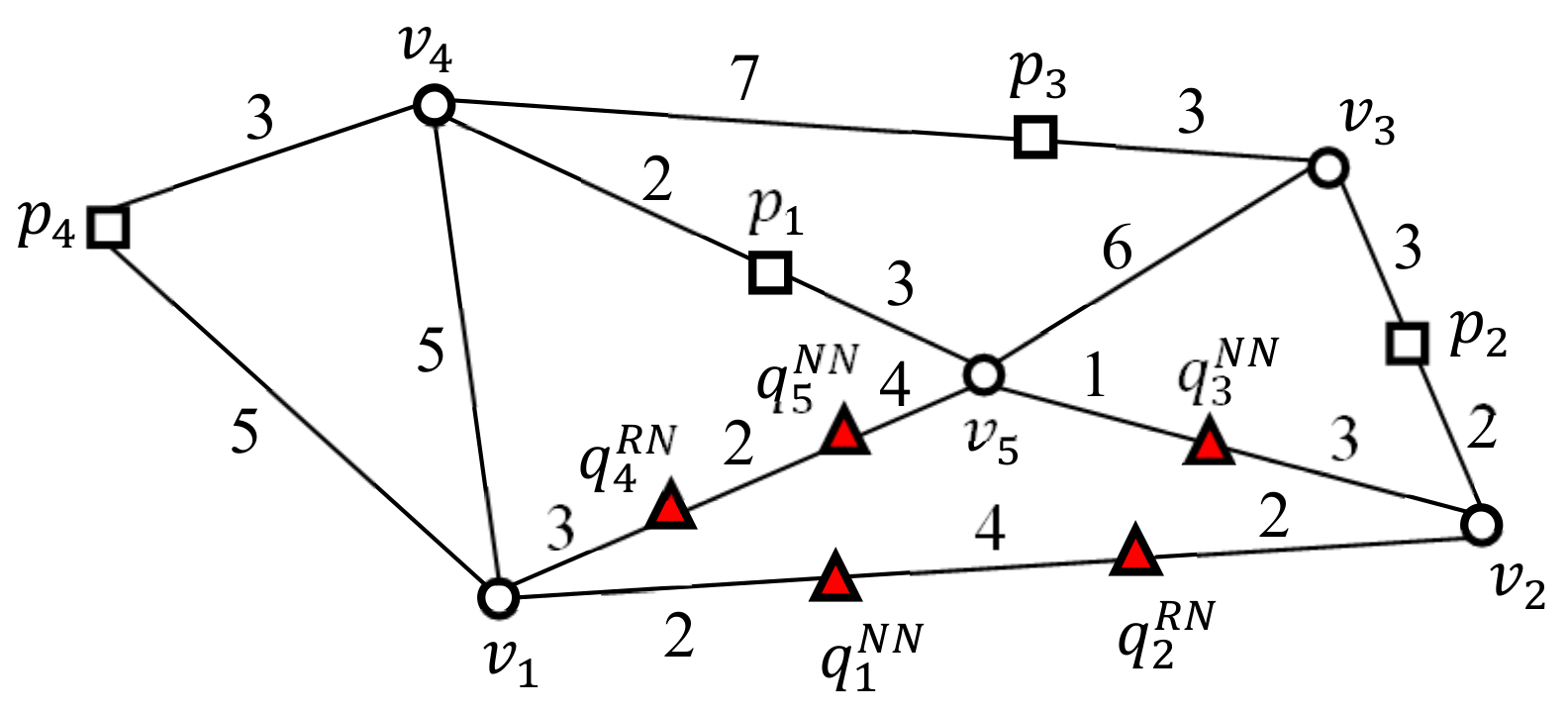
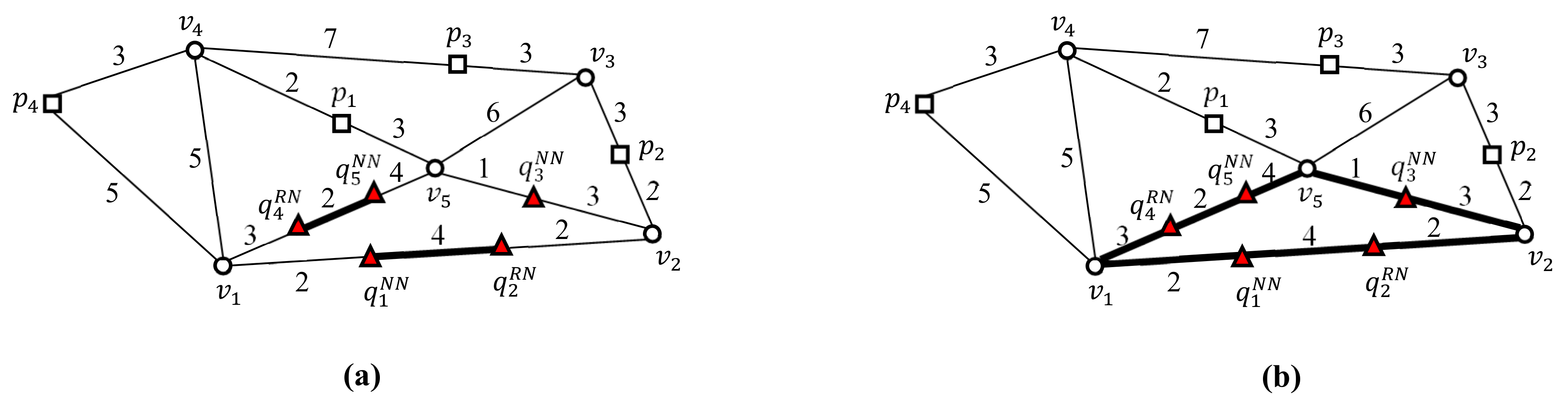
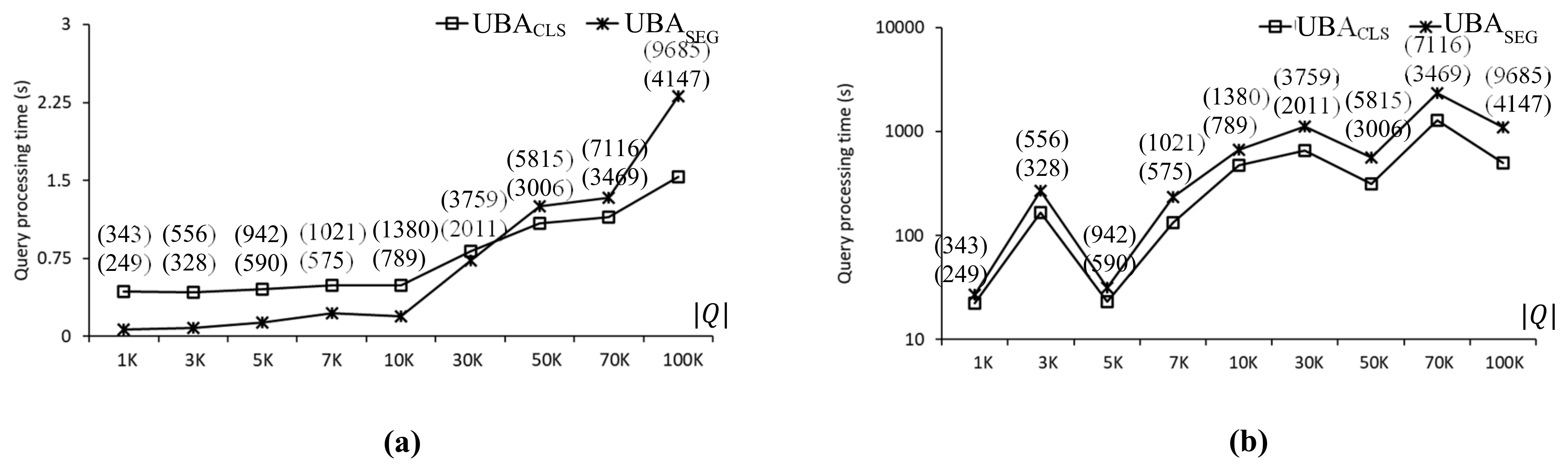
Two versions of UBA, i.e.,
and
, were implemented and evaluated to investigate the effect of the two-step clustering method on the batch processing of UBA and its scalability in terms of
.
transforms nearby query points into query segments, and
transforms nearby query points into query clusters.
and
are illustrated in
Figure 5a,b, respectively.
Figure 10 compares the query processing times using
and
with the CAL roadmap, where the two values in the parentheses indicate the number of SP queries evaluated by
and
, respectively. As can be seen, the number of SP queries evaluated by
was greater than that of
. As shown in
Figure 10a, when the data points exhibited a uniform distribution,
was up to 6.1 times faster than
for
. However, as
increased,
was faster than
, which means that
scaled better than
with
. Specifically,
was 1.5 times faster than
for
. As shown in
Figure 10b, when the data points exhibited a centroid distribution,
was up to 2.2 times faster than
in all cases. Therefore,
scaled with
better than
. It is clear that the distribution of data points affected query processing time significantly. Specifically, when the data points exhibited uniform and centroid distributions, the query processing times of
were 1.5 and 497.7 s, respectively, for
.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}