
Deep-Learning-Based Multimodal Emotion Classification for Music Videos



Abstract
:1. Introduction
- (a)
- (b)
- We trained unimodal and multimodal architectures with music, video, and facial expressions using our supervised data. The networks were designed using 2D and 3D convolution filters. Later, the network complexity was reduced by using a novel channel and separable filter convolution.
- (c)
- An ablation study was conducted to find a robust and optimal solution for emotion classification in music videos. Music was found to be the dominant source for emotion-based content, and video and facial expressions were positioned in a secondary role.
- (d)
- The slow–fast network strategy [17] was applied for multimodal emotion classification. The slow and fast branches were designed to capture spatiotemporal information from music, video, and facial expression inputs. The learned features of two parallel branches of a slow–fast network were shared and boosted by using a multimodal transfer module (MMTM) [18], which is an extension of “squeeze and excitation” (SE) [19].
2. Related Works
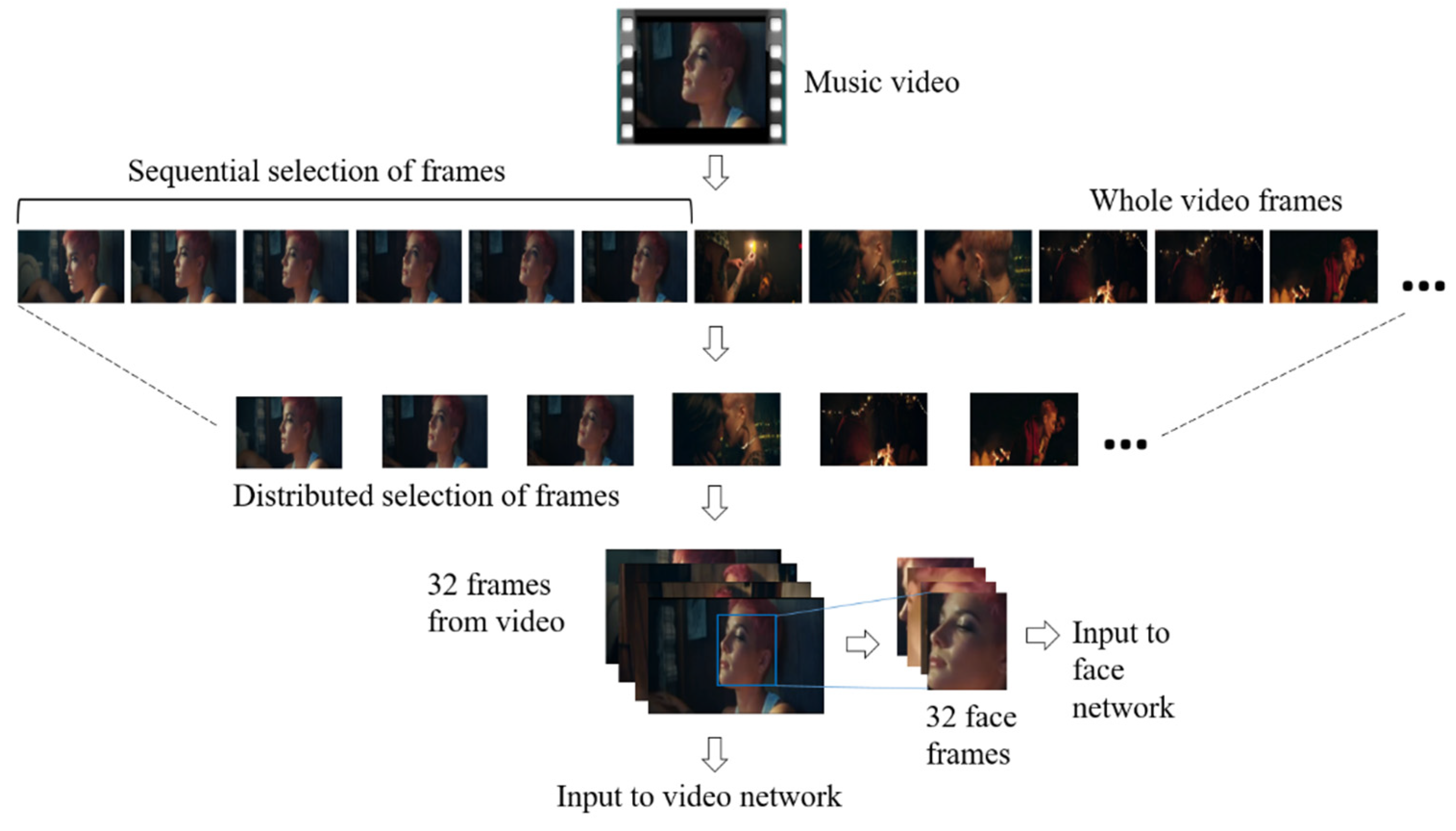
3. Data Preparations
4. Proposed Approach
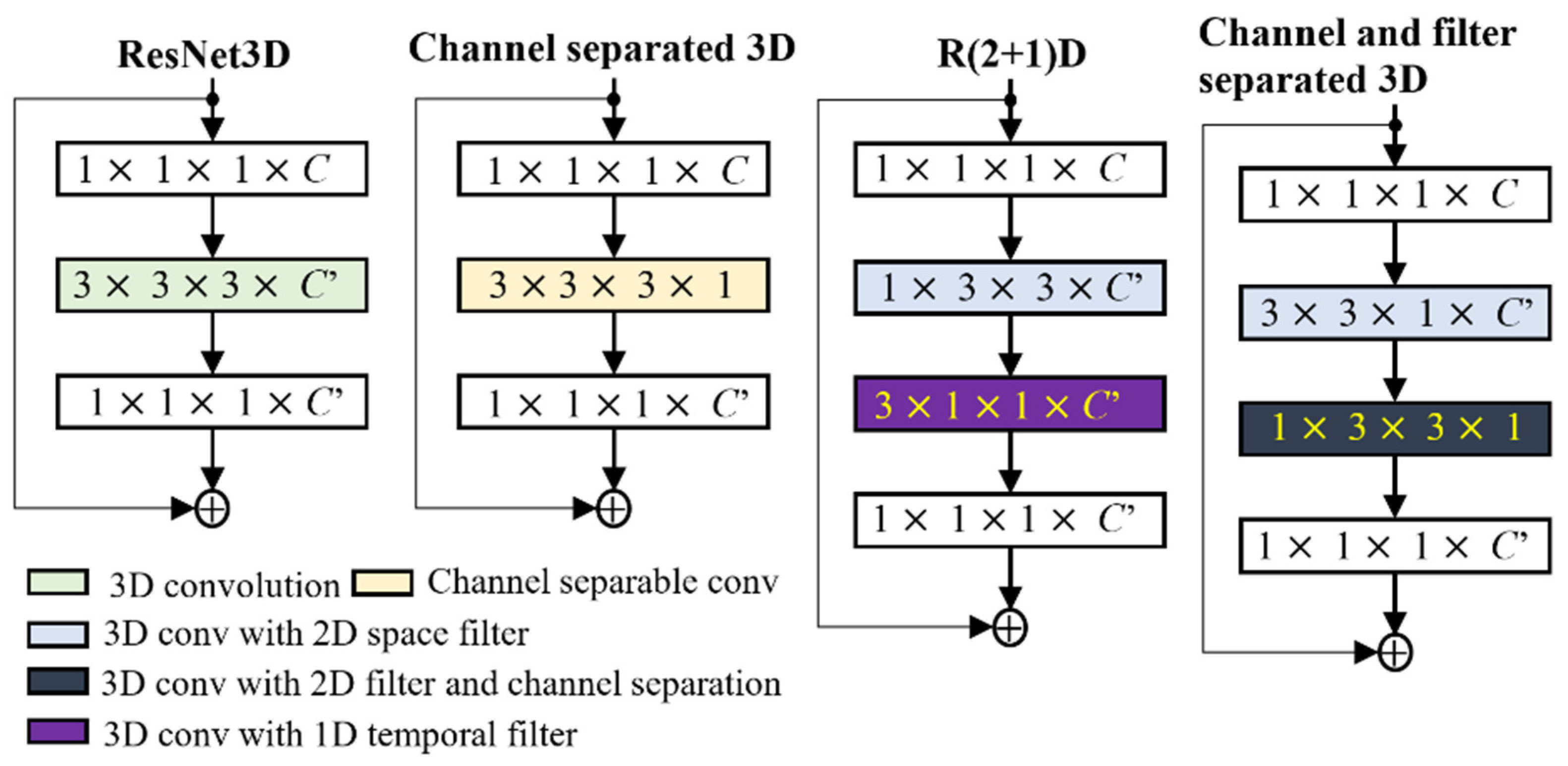
4.1. Convolution Filter
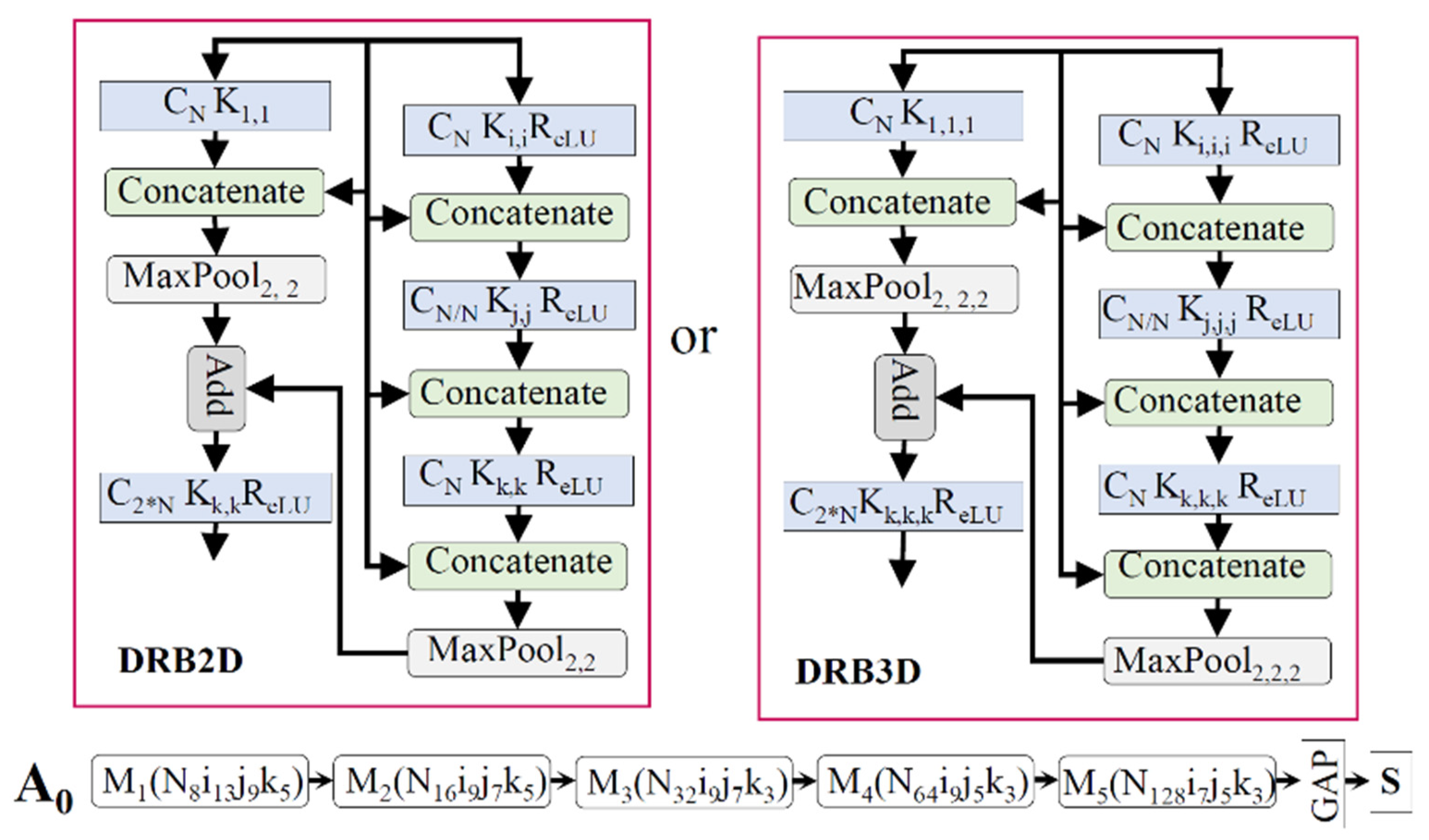
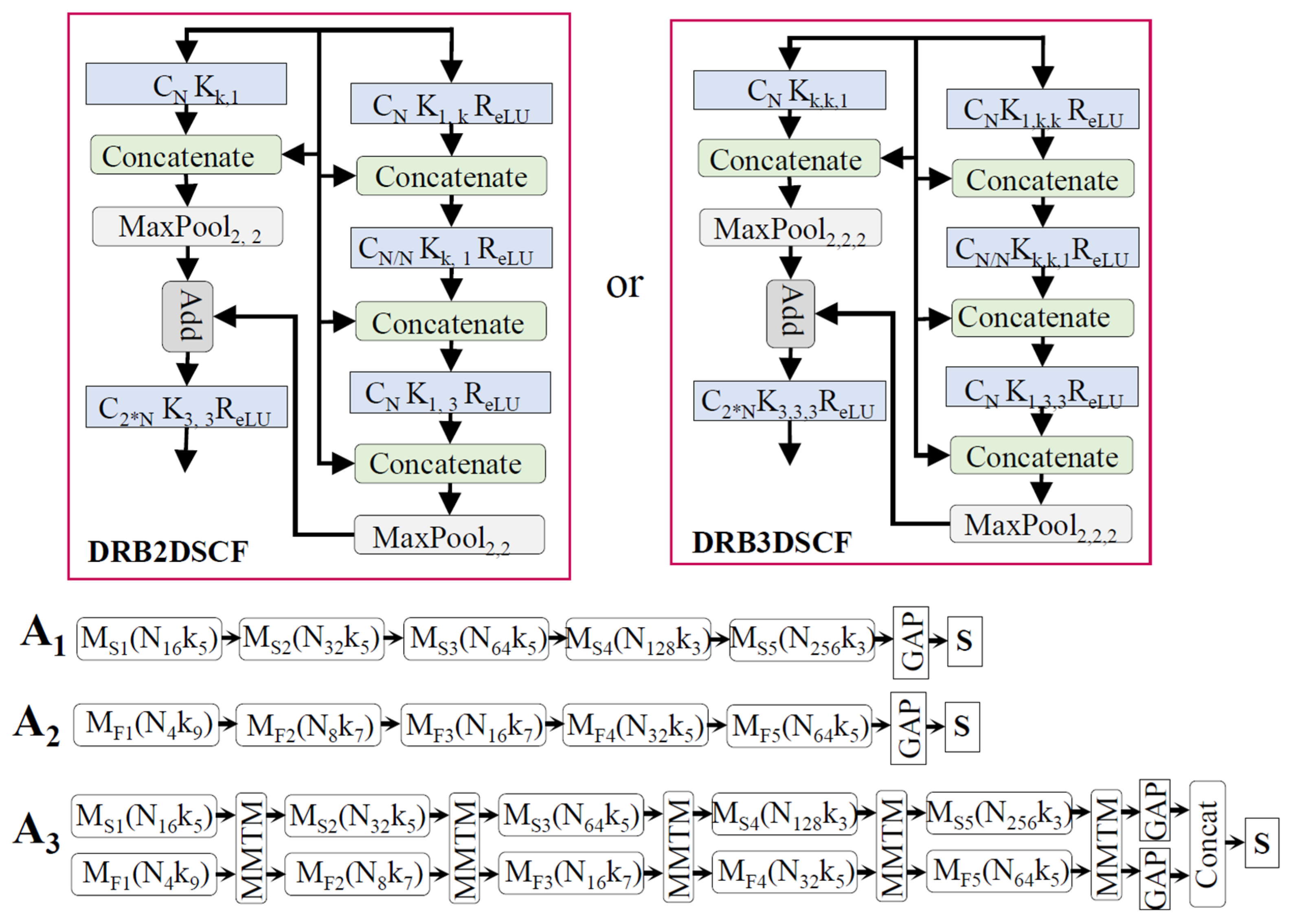
4.2. Proposed Networks
5. Experimental Results
5.1. Results of the Unimodal Architectures
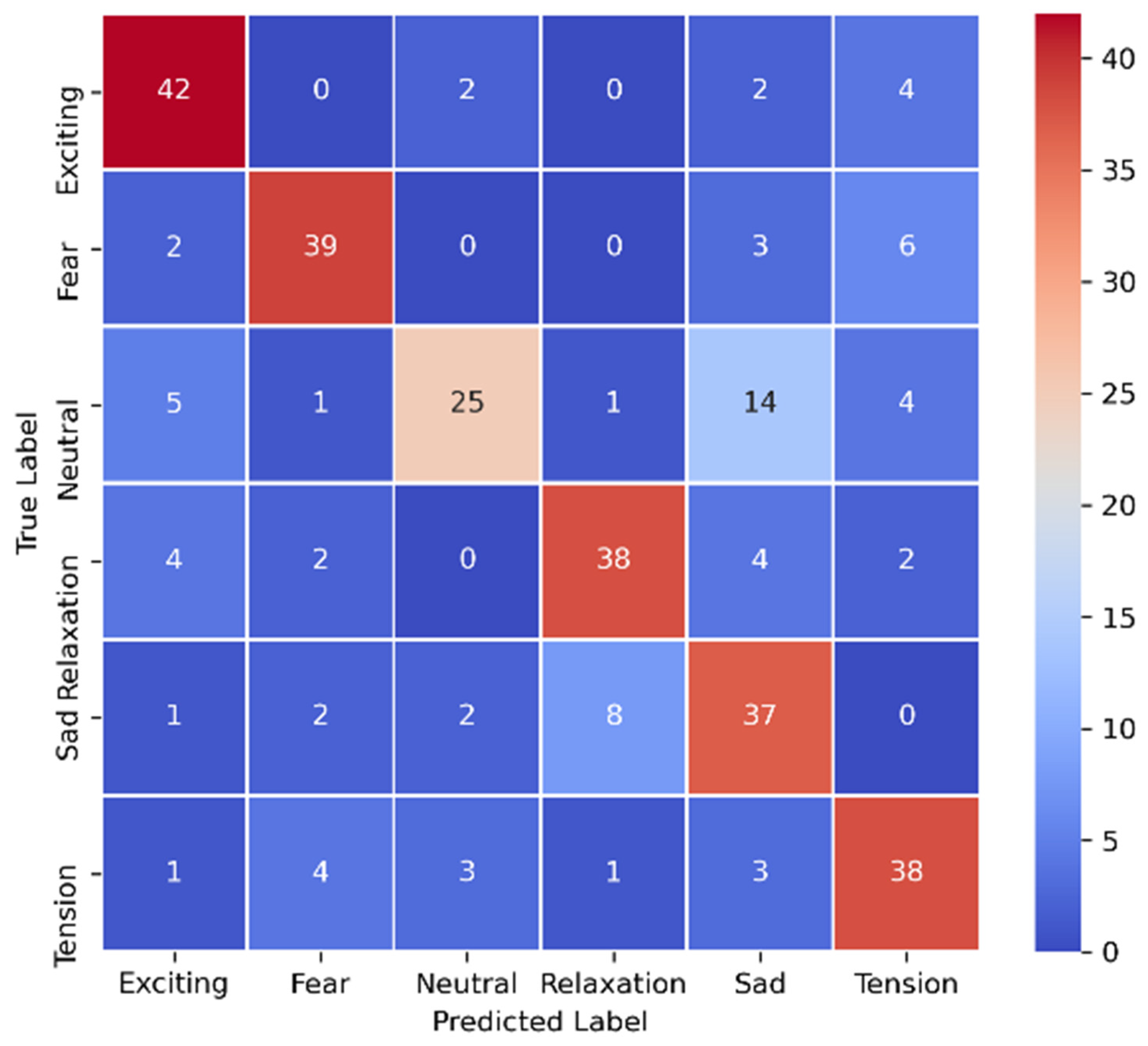
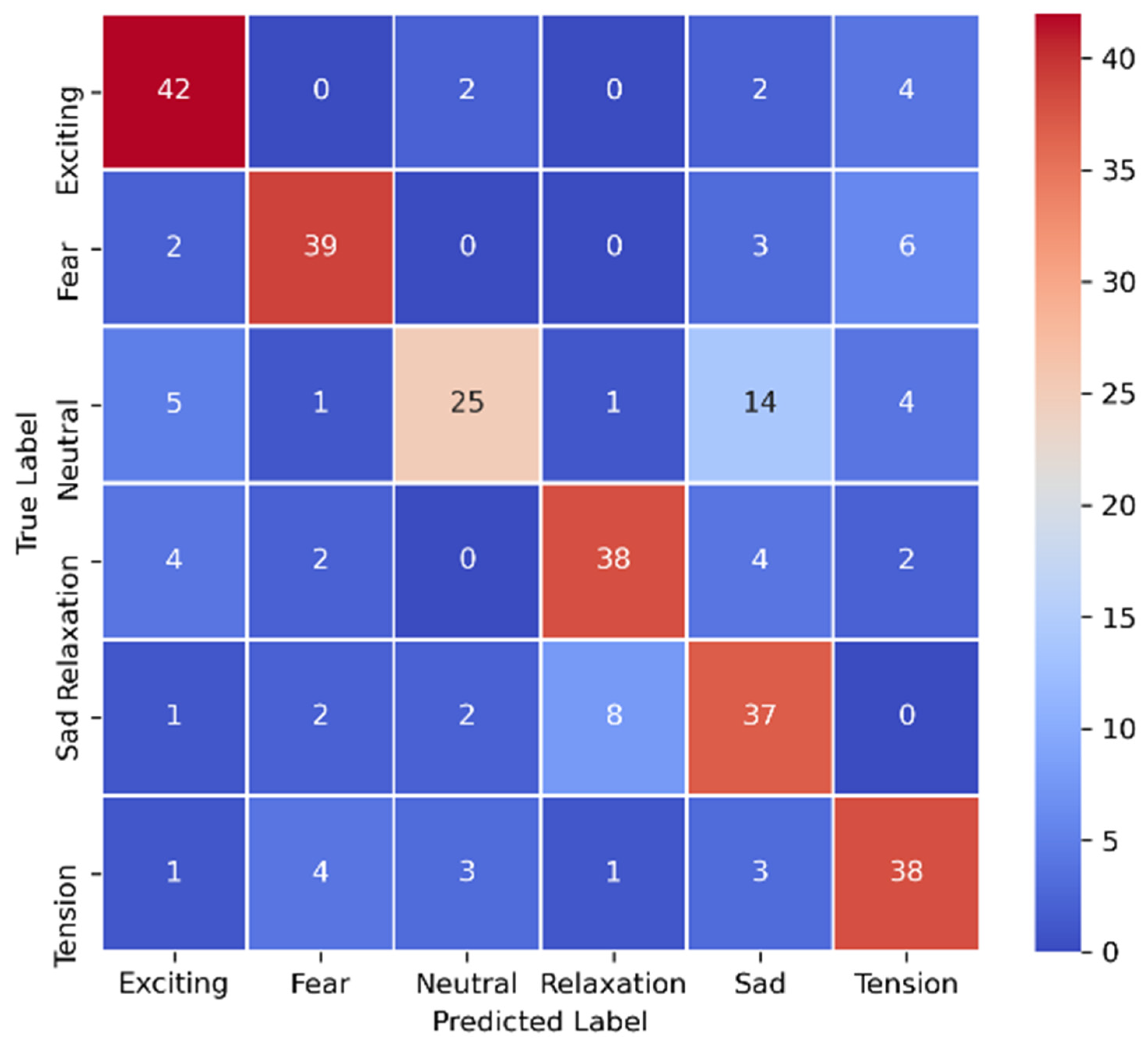
5.2. Result of the Multimodal Architecture
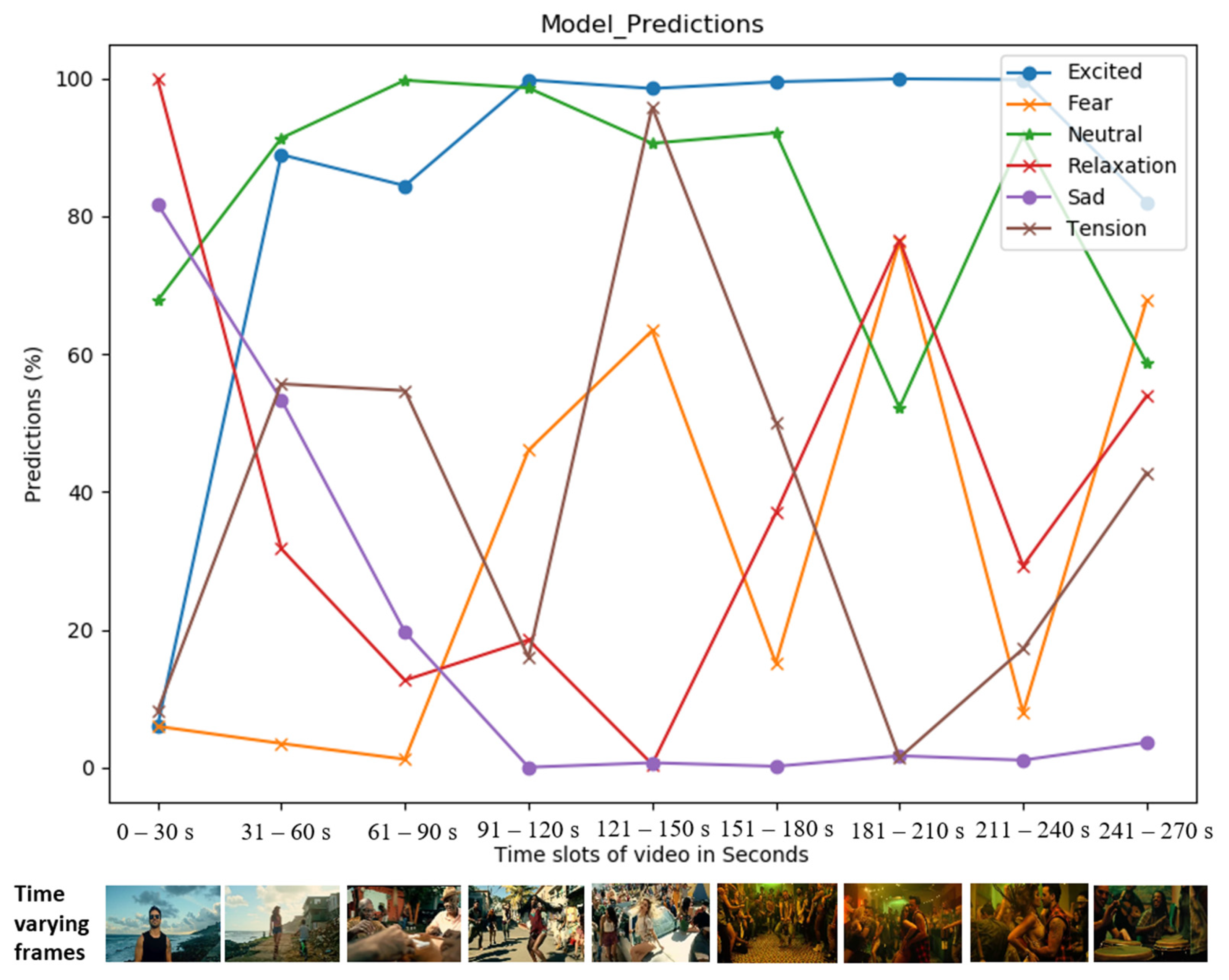
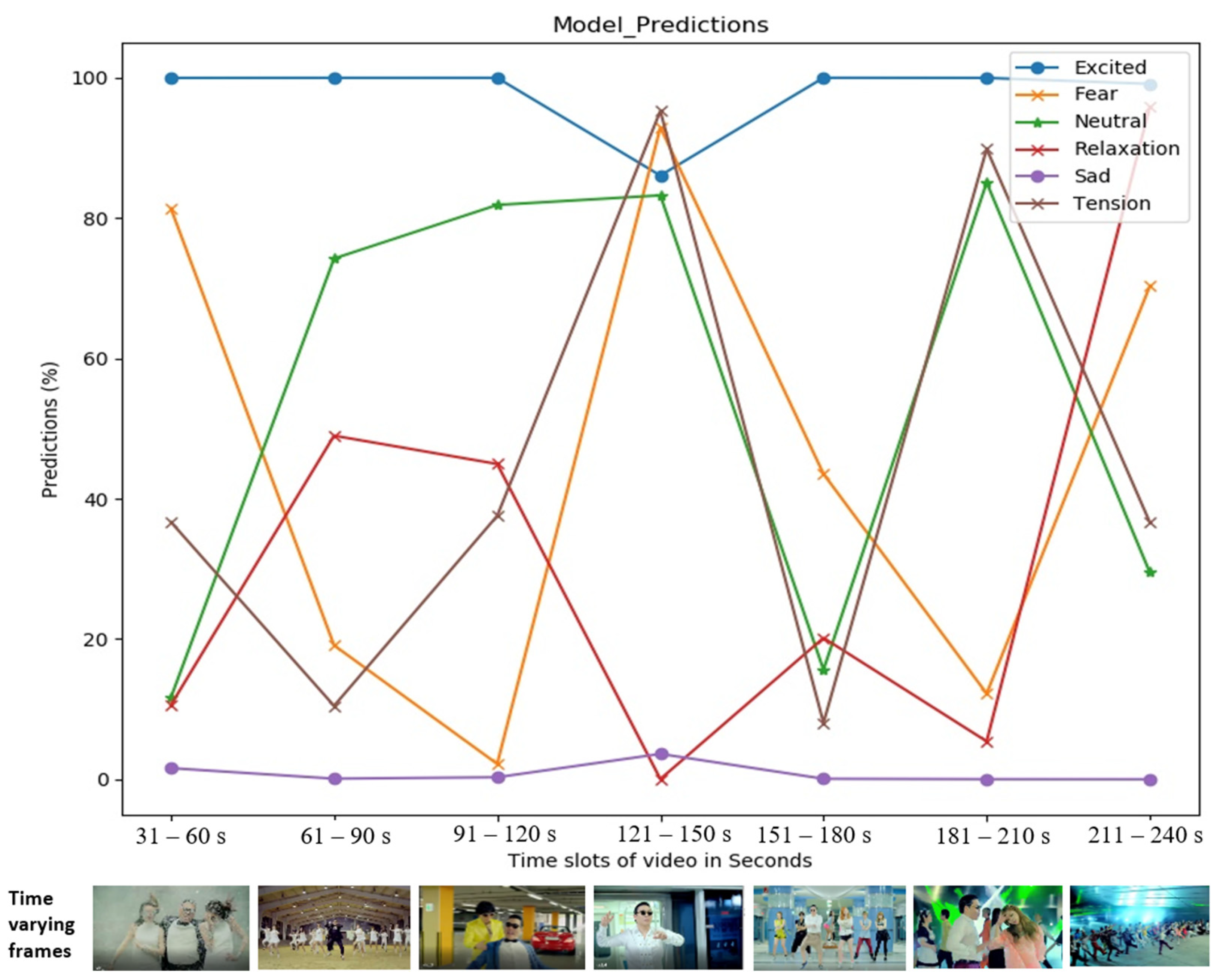
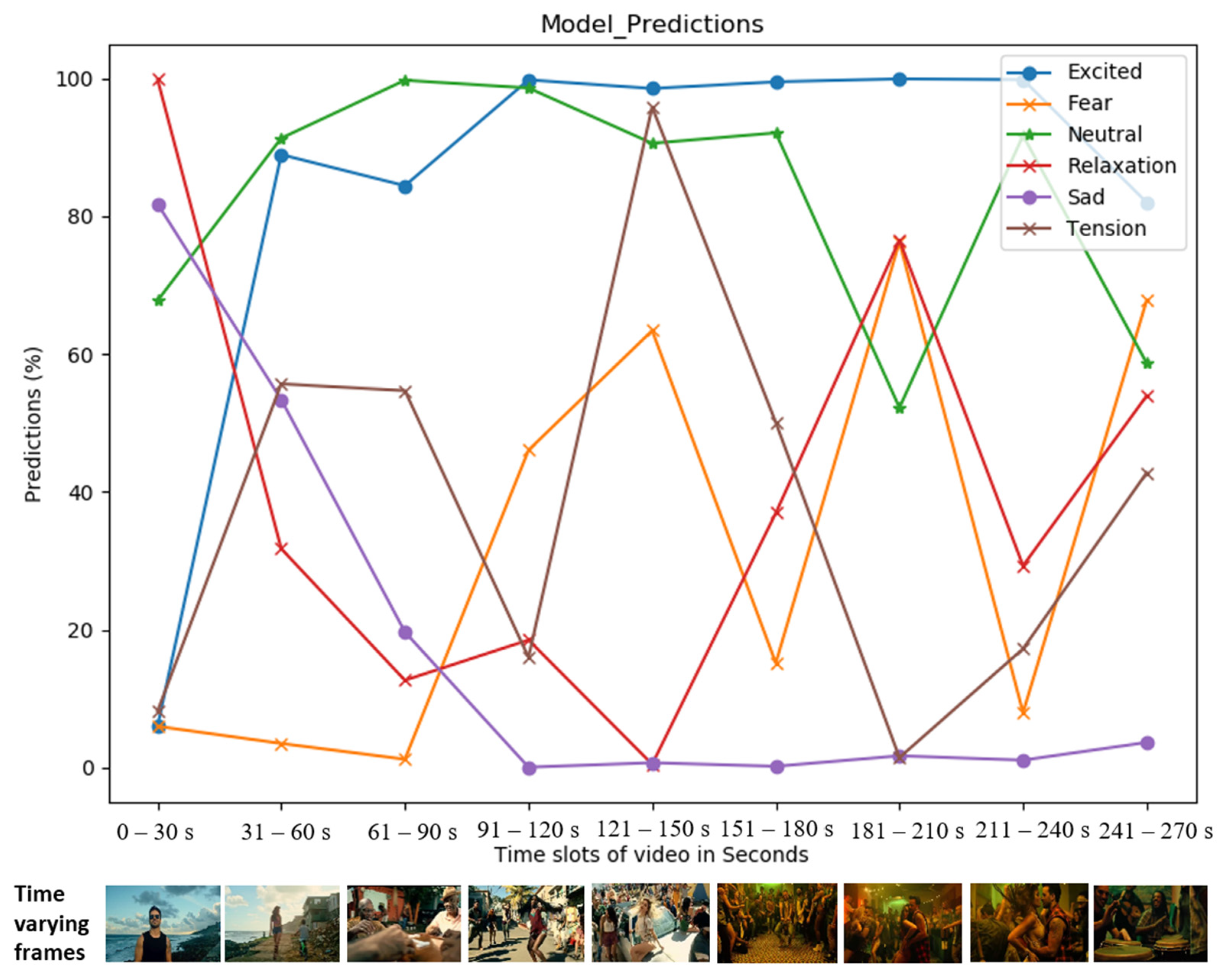
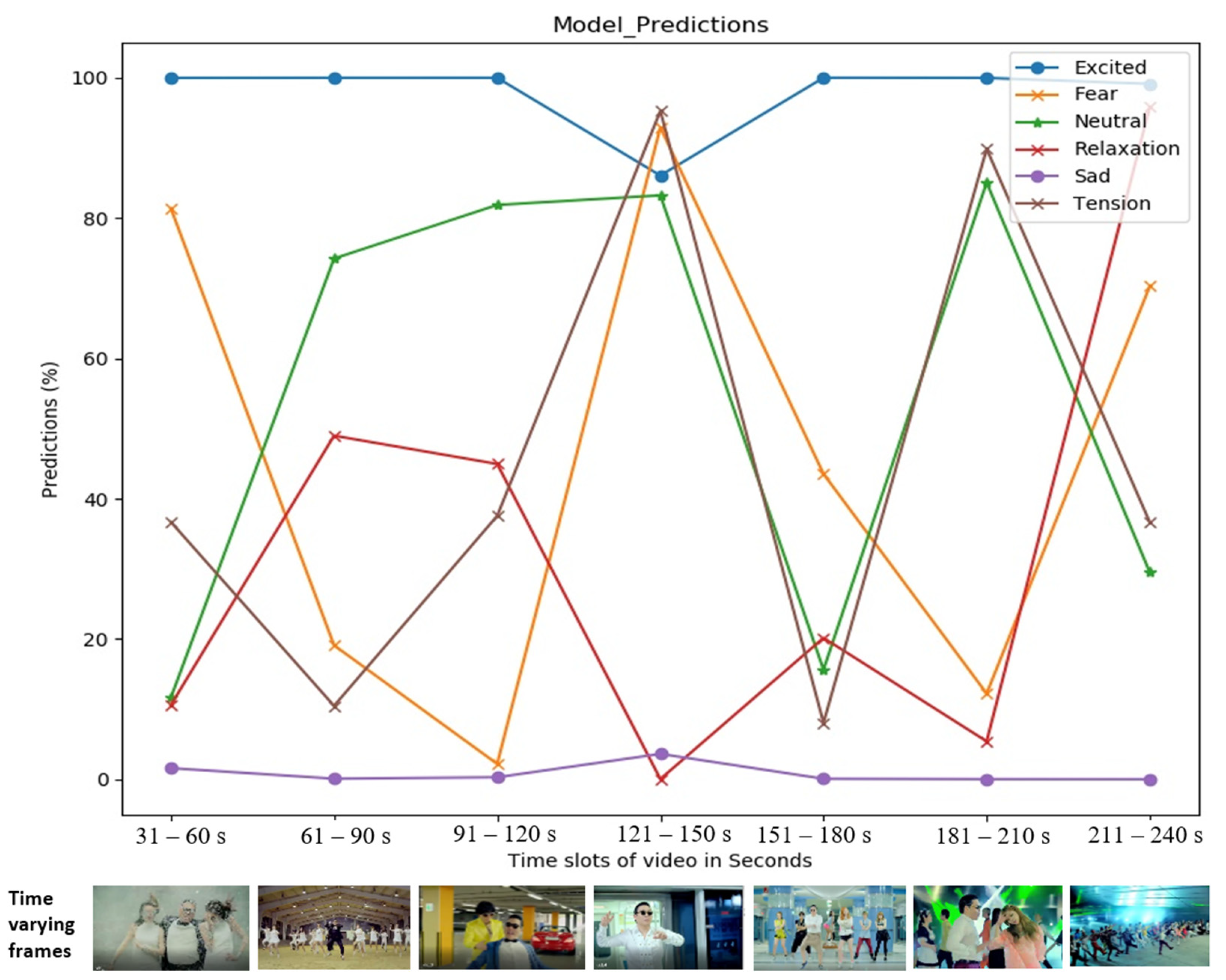
5.3. Analysis Based on Visual Predictions
5.4. Comparisons with Past Studies
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| MER | Music Emotion Recognition |
| DNN | Deep Neural Network |
| CNN | Convolutional Neural Network |
| GMM | Gaussian mixture model |
| SVM | Support Vector Machine |
| CLR | Calibrated Label Ranking |
| MVMM | Music Video Multi-Modal |
| C3D | Convolutional 3 Dimensional |
| CAL500 | Computer Audition Lab 500-song |
| DEAP120 | Database for Emotion Analysis using Physiological signals with 120 samples |
| MMTM | Multimodal Transfer Module |
| SE | Squeeze-and-Excitation |
| MFCC | Mel Frequency Cepstral Coefficient |
| ROC | Receiver Operation Characteristics |
| AUC | Area Under Curve |
| GAP | Global Average Pooling |
| FFT | Fast Fourier Transform |
| T-F | Time-Frequency |
| 2/3D | 2/3 Dimension |
| DRB2DSC | Dense Residual Block 2D Standard Convolution |
| DRB3DSC | Dense Residual Block 3D Standard Convolution |
| DRB2DSCFC | Dense Residual Block 2D with Separable Channel and Filter Convolution |
| DRB3DSCFC | Dense Residual Block 3D with Separable Channel and Filter Convolution |
References
- Yang, Y.H.; Chen, H.H. Machine Recognition of Music Emotion: A Review. ACM Trans. Intell. Syst. Technol. 2012. [Google Scholar] [CrossRef]
- Juslin, P.N.; Laukka, P. Expression, Perception, and Induction of Musical Emotions: A Review and a Questionnaire Study of Everyday Listening. J. New Music Res. 2004, 33, 217–238. [Google Scholar] [CrossRef]
- Elvers, P.; Fischinger, T.; Steffens, J. Music Listening as Self-enhancement: Effects of Empowering Music on Momentary Explicit and Implicit Self-esteem. Psychol. Music 2018, 46, 307–325. [Google Scholar] [CrossRef]
- Raglio, A.; Attardo, L.; Gontero, G.; Rollino, S.; Groppo, E.; Granieri, E. Effects of Music and Music Therapy on Mood in Neurological Patients. World J. Psychiatry 2015, 5, 68–78. [Google Scholar] [CrossRef] [PubMed]
- Patricia, E.B. Music as a Mood Modulator. Retrospective Theses and Dissertations, 1992, 17311. Available online: https://lib.dr.iastate.edu/rtd/17311 (accessed on 7 June 2017).
- Eerola, T.; Peltola, H.R. Memorable Experiences with Sad Music—Reasons, Reactions and Mechanisms of Three Types of Experiences. PLoS ONE 2016, 11, e0157444. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bogt, T.; Canale, N.; Lenzi, M.; Vieno, A.; Eijnden, R. Sad Music Depresses Sad Adolescents: A Listener’s Profile. Psychol. Music 2019, 49, 257–272. [Google Scholar] [CrossRef] [Green Version]
- Pannese, A.; Rappaz, M.A.; Grandjean, G. Metaphor and Music Emotion: Ancient Views and Future Directions. Conscious. Cogn. 2016, 44, 61–71. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Siles, I.; Segura-Castillo, A.; Sancho, M.; Solís-Quesada, R. Genres as Social Affect: Cultivating Moods and Emotions through Playlists on Spotify. Soc. Media Soc. 2019, 5, 2056305119847514. [Google Scholar] [CrossRef] [Green Version]
- Schriewer, K.; Bulaj, G. Music Streaming Services as Adjunct Therapies for Depression, Anxiety, and Bipolar Symptoms: Convergence of Digital Technologies, Mobile Apps, Emotions, and Global Mental Health. Front. Public Health 2016, 4, 217. [Google Scholar] [CrossRef] [Green Version]
- Pandeya, Y.R.; Kim, D.; Lee, J. Domestic Cat Sound Classification Using Learned Features from Deep Neural Nets. Appl. Sci. 2018, 8, 1949. [Google Scholar] [CrossRef] [Green Version]
- Pandeya, Y.R.; Bhattarai, B.; Lee, J. Visual Object Detector for Cow Sound Event Detection. IEEE Access 2020, 8, 162625–162633. [Google Scholar] [CrossRef]
- Pandeya, Y.R.; Lee, J. Domestic Cat Sound Classification Using Transfer Learning. Int. J. Fuzzy Log. Intell. Syst. 2018, 18, 154–160. [Google Scholar] [CrossRef] [Green Version]
- Pandeya, Y.R.; Bhattarai, B.; Lee, J. Sound Event Detection in Cowshed using Synthetic Data and Convolutional Neural Network. In Proceedings of the 2020 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 21–23 October 2020; pp. 273–276. [Google Scholar]
- Bhattarai, B.; Pandeya, Y.R.; Lee, J. Parallel Stacked Hourglass Network for Music Source Separatio. IEEE Access 2020, 8, 206016–206027. [Google Scholar] [CrossRef]
- Pandeya, Y.R.; Lee, J. Deep Learning-based Late Fusion of Multimodal Information for Emotion Classification of Music Video. Multimed. Tools Appl. 2020, 80, 2887–2905. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October 2019–2 November 2019. [Google Scholar]
- Joze, H.R.V.; Shaban, A.; Iuzzolino, M.L.; Koishida, K. MMTM: Multimodal Transfer Module for CNN Fusion. In Proceedings of the CVPR 2020, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Lopes, P.; Liapis, A.; Yannakakis, G.N. Modelling Affect for Horror Soundscapes. IEEE Trans. Affect. Comput. 2019, 10, 209–222. [Google Scholar] [CrossRef] [Green Version]
- Naoki, N.; Katsutoshi, I.; Hiromasa, F.; Goto, M.; Ogata, T.; Okuno, H.G. A Musical Mood Trajectory Estimation Method Using Lyrics and Acoustic Features. In Proceedings of the 1st international ACM workshop on Music information retrieval with user-centered and multimodal strategies, Scottsdale, AZ, USA, 28 November 2011–1 December 2011; pp. 51–56. [Google Scholar]
- Song, Y.; Dixon, S.; Pearce, M. Evaluation of Musical Features for Music Emotion Classification. In Proceedings of the 13th International Society for Music Information Retrieval Conference (ISMIR), Porto, Portugal, 8–12 October 2012; pp. 523–528. [Google Scholar]
- Lin, C.; Liu, M.; Hsiung, W.; Jhang, J. Music Emotion Recognition Based on Two-level Support Vector Classification. In Proceedings of the 2016 International Conference on Machine Learning and Cybernetics (ICMLC), Jeju Island, Korea, 10–13 July 2016; pp. 375–389. [Google Scholar]
- Han, K.M.; Zin, T.; Tun, H.M. Extraction of Audio Features for Emotion Recognition System Based on Music. Int. J. Sci. Technol. Res. 2016, 5, 53–56. [Google Scholar]
- Panda, R.; Malheiro, R.; Paiva, R.P. Novel Audio Features for Music Emotion Recognition. IEEE Trans. Affect. Comput. 2020, 11, 614–626. [Google Scholar] [CrossRef]
- Aljanaki, A.; Yang, Y.H.; Soleymani, M. Developing a Benchmark for Emotional Analysis of Music. PLoS ONE 2017, 12, e0173392. [Google Scholar] [CrossRef] [Green Version]
- Malik, M.; Adavanne, A.; Drossos, K.; Virtanen, T.; Ticha, D.; Jarina, R. Stacked Convolutional and Recurrent Neural Networks for Music Emotion Recognition. arXiv 2017, arXiv:1706.02292v1. Available online: https://arxiv.org/abs/1706.02292 (accessed on 7 June 2017).
- Jakubik, J.; Kwaśnicka, H. Music Emotion Analysis using Semantic Embedding Recurrent Neural Networks. In Proceedings of the 2017 IEEE International Conference on INnovations in Intelligent SysTems and Applications (INISTA), Gdynia, Poland, 3–5 July 2017; pp. 271–276. [Google Scholar]
- Liu, X.; Chen, Q.; Wu, X.; Yan, L.; Yang, L. CNN Based Music Emotion Classification. arXiv 2017, arXiv:1704.05665. Available online: https://arxiv.org/abs/1704.05665 (accessed on 19 April 2017).
- Tsunoo, E.; Akase, T.; Ono, N.; Sagayama, S. Music mood classification by rhythm and bass-line unit pattern analysis. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 265–268. [Google Scholar]
- Turnbull, D.; Barrington, L.; Torres, D.; Lanckriet, G. Towards musical query-by-semantic description using the cal500 data set. In Proceedings of the ACM SIGIR, Amsterdam, The Netherlands, 23–27 July 2007; pp. 439–446. [Google Scholar]
- Li, S.; Huang, L. Music Emotions Recognition Based on Feature Analysis. In Proceedings of the 2018 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 13–15 October 2018; pp. 1–5. [Google Scholar]
- Wang, S.; Wang, J.; Yang, Y.; Wang, H. Towards time-varying music auto-tagging based on cal500 expansion. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Chengdu, China, 14–18 July 2014; pp. 1–6. [Google Scholar]
- Berardinis, J.; Cangelosi, A.; Coutinho, E. The Multiple Voices of Music Emotions: Source Separation for Improving Music Emotion Recognition Models and Their Interpretability. In Proceedings of the ISMIR 2020, Montréal, QC, Canada, 11–16 October 2020. [Google Scholar]
- Chaki, S.; Doshi, P.; Bhattacharya, S.; Patnaik, P. Explaining Perceived Emotions in Music: An Attentive Approach. In Proceedings of the ISMIR 2020, Montréal, QC, Canada, 11–16 October 2020. [Google Scholar]
- Orjesek, R.; Jarina, R.; Chmulik, M.; Kuba, M. DNN Based Music Emotion Recognition from Raw Audio Signal. In Proceedings of the 29th International Conference Radioelektronika (RADIOELEKTRONIKA), Pardubice, Czech Republic, 16–18 April 2019; pp. 1–4. [Google Scholar]
- Choi, W.; Kim, M.; Chung, J.; Lee, D.; Jung, S. Investigating U-nets with Various Intermediate blocks for Spectrogram-Based Singing Voice Separation. In Proceedings of the ISMIR2020, Montréal, QC, Canada, 11–16 October 2020. [Google Scholar]
- Yin, D.; Luo, C.; Xiong, Z.; Zeng, W. Phasen: A phase-and-harmonics-aware speech enhancement network. arXiv 2019, arXiv:1911.04697. Available online: https://www.isca-speech.org/archive/Interspeech_2018/abstracts/1773.html (accessed on 12 November 2019).
- Takahashi, N.; Agrawal, P.; Goswami, N.; Mitsufuji, Y. Phasenet: Discretized phase modeling with deep neural networks for audio source separation. Interspeech 2018, 2713–2717. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Xu, M. Modeling temporal information using discrete fourier transform for recognizing emotions in user-generated videos. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 629–633. [Google Scholar]
- Xu, B.; Fu, Y.; Jiang, Y.; Li, B.; Sigal, L. Heterogeneous Knowledge Transfer in Video Emotion Recognition, Attribution and Summarization. IEEE Trans. Affect. Comput. 2018, 9, 255–270. [Google Scholar] [CrossRef] [Green Version]
- Tu, G.; Fu, Y.; Li, B.; Gao, J.; Jiang, Y.; Xue, X. A Multi-Task Neural Approach for Emotion Attribution, Classification, and Summarization. IEEE Trans. Multimed. 2020, 22, 148–159. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Kim, S.; Kiim, S.; Sohn, K. Spatiotemporal Attention Based Deep Neural Networks for Emotion Recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 1513–1517. [Google Scholar]
- Sun, M.; Hsu, S.; Yang, M.; Chien, J. Context-aware Cascade Attention-based RNN for Video Emotion Recognition. In Proceedings of the 2018 First Asian Conference on Affective Computing and Intelligent Interaction (ACII Asia), Beijing, China, 20–22 May 2018; pp. 1–6. [Google Scholar]
- Xu, B.; Zheng, Y.; Ye, H.; Wu, C.; Wang, H.; Sun, G. Video Emotion Recognition with Concept Selection. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 406–411. [Google Scholar]
- Irie, G.; Satou, T.; Kojima, A.; Yamasaki, T.; Aizawa, K. Affective Audio-Visual Words and Latent Topic Driving Model for Realizing Movie Affective Scene Classification. IEEE Trans. Multimedia 2010, 12, 523–535. [Google Scholar] [CrossRef]
- Mo, S.; Niu, J.; Su, Y.; Das, S.K. A Novel Feature Set for Video Emotion Recognition. Neurocomputing 2018, 291, 11–20. [Google Scholar] [CrossRef]
- Kaya, H.; Gürpınar, F.; Salah, A.A. Video-based Emotion Recognition in the Wild using Deep Transfer Learning and Score Fusion. Image Vis. Comput. 2017, 65, 66–75. [Google Scholar] [CrossRef]
- Li, H.; Kumar, N.; Chen, R.; Georgiou, P. A Deep Reinforcement Learning Framework for Identifying Funny Scenes in Movies. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 3116–3120. [Google Scholar]
- Ekman, P.; Friesen, W.V. Constants Across Cultures in the Face and Emotion. J. Pers. Soc. Psychol. 1971, 17, 124. [Google Scholar]
- Pantic, M.; Rothkrantz, L.J.M. Automatic Analysis of Facial Expressions: The State of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1424–1445. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Deng, W. Deep Facial Expression Recognition: A Survey. IEEE Trans. Affect. Comput. 2020. [Google Scholar] [CrossRef] [Green Version]
- Majumder, A.; Behera, L.; Subramanian, V.K. Automatic Facial Expression Recognition System Using Deep Network-Based Data Fusion. IEEE Trans. Cybern. 2018, 48, 103–114. [Google Scholar] [CrossRef]
- Kuo, C.; Lai, S.; Sarkis, M. A Compact Deep Learning Model for Robust Facial Expression Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2202–22028. [Google Scholar]
- Nanda, A.; Im, W.; Choi, K.S.; Yang, H.S. Combined Center Dispersion Loss Function for Deep Facial Expression Recognition. Pattern Recognit. Lett. 2021, 141, 8–15. [Google Scholar] [CrossRef]
- Tao, F.; Busso, C. End-to-End Audiovisual Speech Recognition System with Multitask Learning. IEEE Trans. Multimed. 2021, 23, 1–11. [Google Scholar] [CrossRef]
- Eskimez, S.E.; Maddox, R.K.; Xu, C.; Duan, Z. Noise-Resilient Training Method for Face Landmark Generation from Speech. In Proceedings of the IEEE/ACM Transactions on Audio, Speech, and Language Processing, Los Altos, CA, USA, 16 October 2019; Volume 28, pp. 27–38. [Google Scholar] [CrossRef] [Green Version]
- Zeng, H.; Wang, X.; Wu, A.; Wang, Y.; Li, Q.; Endert, A.; Qu, H. EmoCo: Visual Analysis of Emotion Coherence in Presentation Videos. IEEE Trans. Vis. Comput. Graph. 2020, 26, 927–937. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Seanglidet, Y.; Lee, B.S.; Yeo, C.K. Mood prediction from facial video with music “therapy” on a smartphone. In Proceedings of the 2016 Wireless Telecommunications Symposium (WTS), London, UK, 18–20 April 2016; pp. 1–5. [Google Scholar]
- Kostiuk, B.; Costa, Y.M.G.; Britto, A.S.; Hu, X.; Silla, C.N. Multi-label Emotion Classification in Music Videos Using Ensembles of Audio and Video Features. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 517–523. [Google Scholar]
- Acar, E.; Hopfgartner, F.; Albayrak, S. Understanding Affective Content of Music Videos through Learned Representations. In Proceedings of the International Conference on Multimedia Modeling, Dublin, Ireland, 10–18 January 2014. [Google Scholar]
- Ekman, P. Basic Emotions in Handbook of Cognition and Emotion; Wiley: Hoboken, NJ, USA, 1999; pp. 45–60. [Google Scholar]
- Russell, J.A. A Circumplex Model of Affect. J. Personal. Soc. Psychol. 1980, 39, 1161–1178. [Google Scholar] [CrossRef]
- Thayer, R.E. The Biopsychology of Mood and Arousal; Oxford University Press: Oxford, UK, 1989. [Google Scholar]
- Plutchik, R. A General Psychoevolutionary Theory of Emotion in Theories of Emotion, 4th ed.; Academic Press: Cambridge, MA, USA, 1980; pp. 3–33. [Google Scholar]
- Skodras, E.; Fakotakis, N.; Ebrahimi, T. Multimedia Content Analysis for Emotional Characterization of Music Video Clips. EURASIP J. Image Video Process. 2013, 2013, 26. [Google Scholar]
- Gómez-Cañón, J.S.; Cano, E.; Herrera, P.; Gómez, E. Joyful for You and Tender for Us: The Influence of Individual Characteristics and Language on Emotion Labeling and Classification. In Proceedings of the ISMIR 2020, Montréal, QC, Canada, 11–16 October 2020. [Google Scholar]
- Eerola, T.; Vuoskoski, J.K. A comparison of the discrete and dimensional models of emotion in music. Psychol. Music 2011, 39, 18–49. [Google Scholar] [CrossRef] [Green Version]
- Makris, D.; Kermanidis, K.L.; Karydis, I. The Greek Audio Dataset. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Rhodes, Greece, 19–21 September 2014. [Google Scholar]
- Aljanaki, A.; Wiering, F.; Veltkamp, R.C. Studying emotion induced by music through a crowdsourcing game. Inf. Process. Manag. 2016, 52, 115–128. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.H.; Lin, Y.C.; Su, Y.F.; Chen, H.H. A Regression Approach to Music Emotion Recognition. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 448–457. [Google Scholar] [CrossRef]
- Livingstone, S.R.; Russo, R.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Kim, S.; Kim, S.; Park, J.; Sohn, K. Context-Aware Emotion Recognition Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Malandrakis, N.; Potamianos, A.; Evangelopoulos, G.; Zlatintsi, A. A supervised approach to movie emotion tracking. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 2376–2379. [Google Scholar]
- Baveye, Y.; Dellandrea, E.; Chamaret, C.; Chen, L. LIRIS-ACCEDE: A video database for affective content analysis. IEEE Trans. Affect. Comput. 2015, 6, 43–55. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.H.; Chen, H.H. Music Emotion Recognition; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Geirhos, R.; Jacobsen, J.H.; Michaelis, C.; Zemel, R.; Brendel, W.; Bethge, M.; Wichmann, F.A. Shortcut Learning in Deep Neural Networks. arXiv 2021, arXiv:2004.07780v4. Available online: https://arxiv.org/abs/2004.07780 (accessed on 16 April 2020). [CrossRef]
- CJ-Moore, B. An Introduction to the Psychology of Hearing; Brill: Leiden, The Netherlands, 2012. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. arXiv 2018, arXiv:1705.07750v3. [Google Scholar]
- Du, T.; Heng, W.; Lorenzo, T.; Matt, F. Video Classification with Channel-Separated Convolutional Networks. arXiv 2019, arXiv:1904.02811v4. Available online: https://arxiv.org/abs/1904.02811 (accessed on 4 April 2019).
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A Closer Look at Spatiotemporal Convolutions for Action Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Pons, J.; Lidy, T.; Serra, X. Experimenting with musically motivated convolutional neural networks. In Proceedings of the 2016 14th International Workshop on Content-Based Multimedia Indexing (CBMI), Bucharest, Romania, 15–17 June 2016; pp. 1–6. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-Scale Video Classification with Convolutional Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Poria, S.; Cambria, E.; Bajpai, R.; Hussain, A. A review of Affective Computing: From Unimodal Analysis to Multimodal Fusion. Inf. Fusion 2017, 37, 98–125. [Google Scholar] [CrossRef] [Green Version]
- Morris, J.D.; Boone, M.A. The Effects of Music on Emotional Response, Brand Attitude, and Purchase Intent in an Emotional Advertising Condition. Adv. Consum. Res. 1998, 25, 518–526. [Google Scholar]
- Park, J.; Park, J.; Park, J. The Effects of User Engagements for User and Company Generated Videos on Music Sales: Empirical Evidence from YouTube. Front. Psychol. 2018, 9, 1880. [Google Scholar] [CrossRef] [Green Version]
- Abolhasani, M.; Oakes, S.; Oakes, H. Music in advertising and consumer identity: The search for Heideggerian authenticity. Mark. Theory 2017, 17, 473–490. [Google Scholar] [CrossRef] [Green Version]
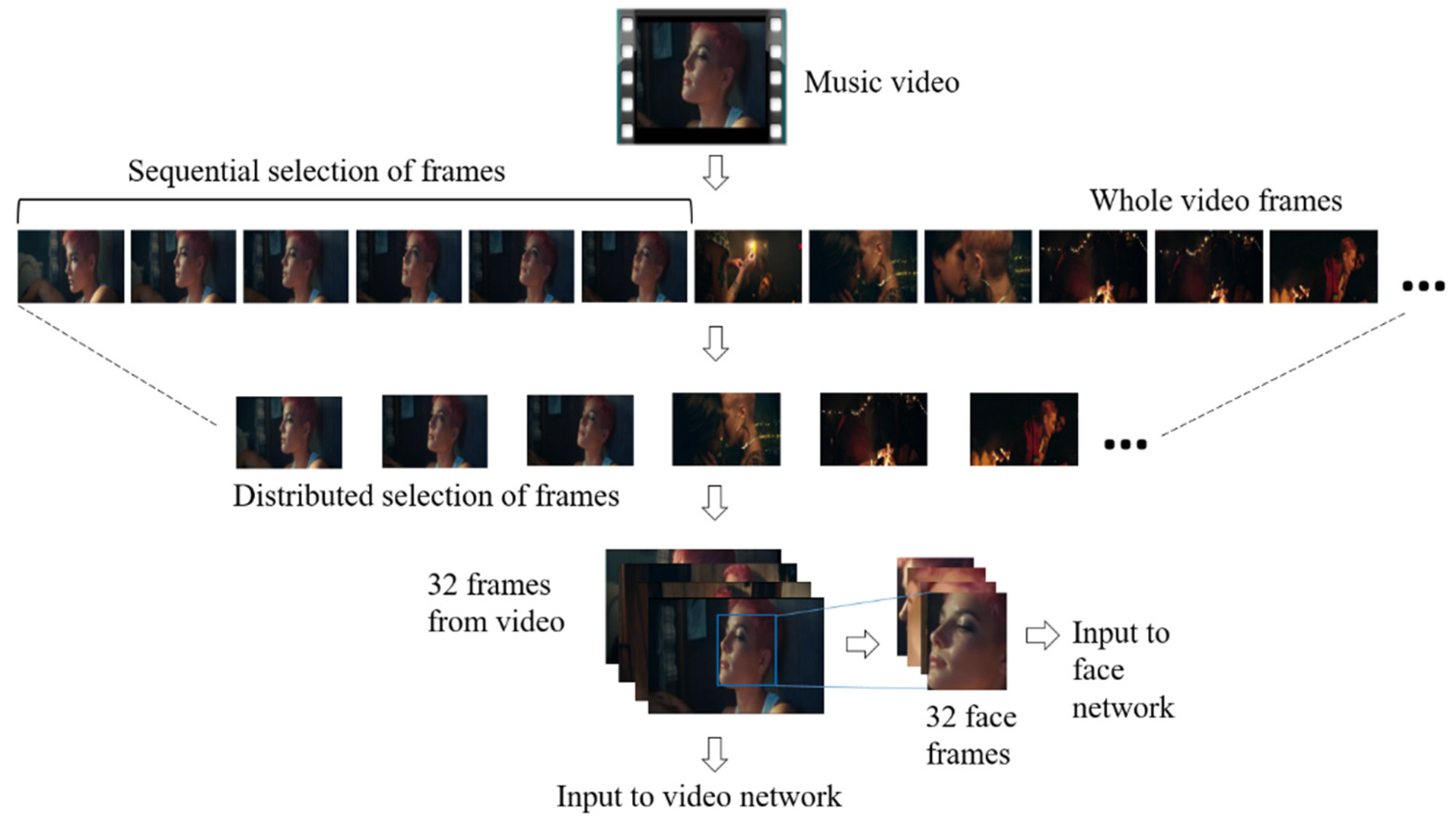
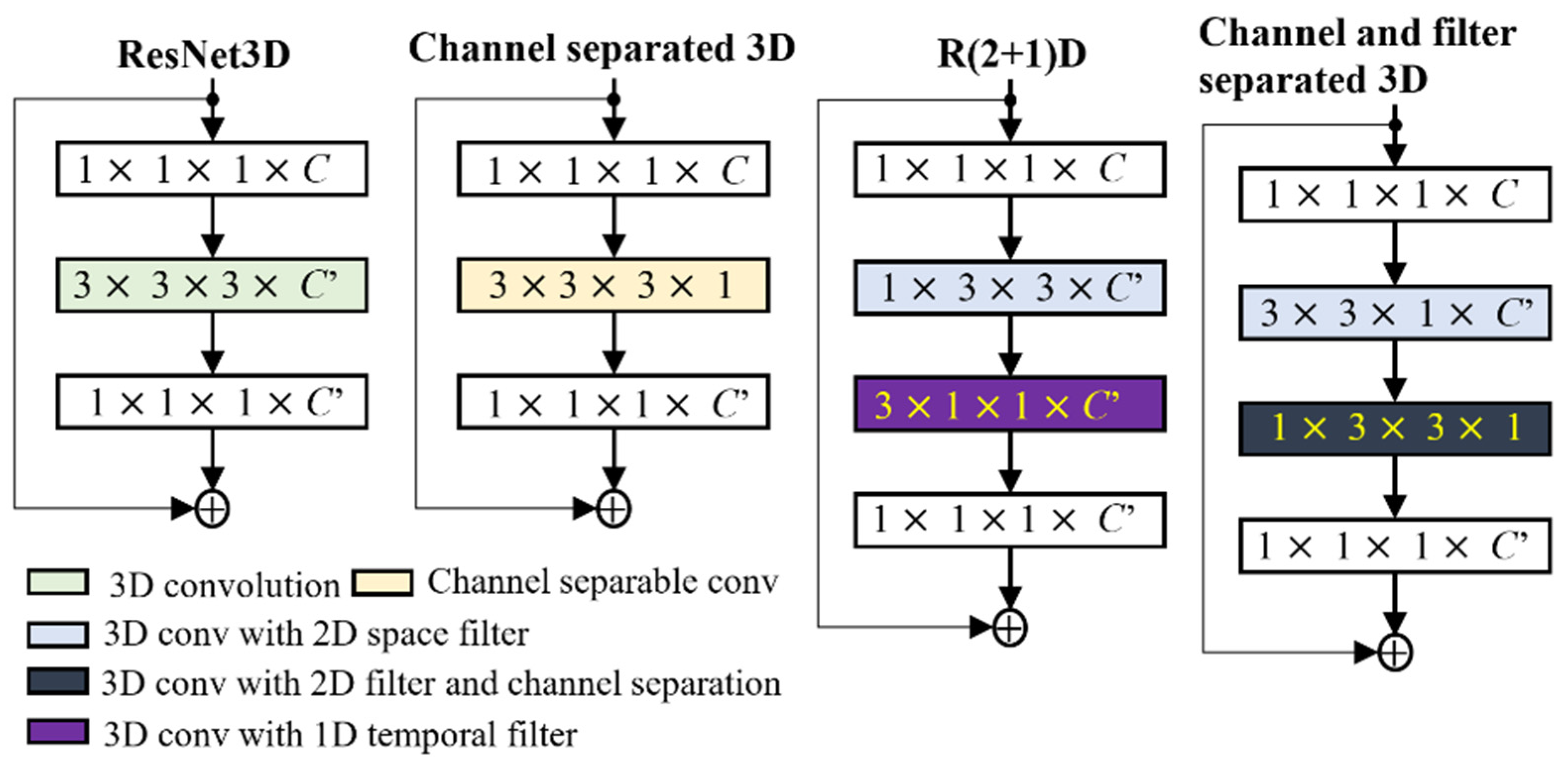
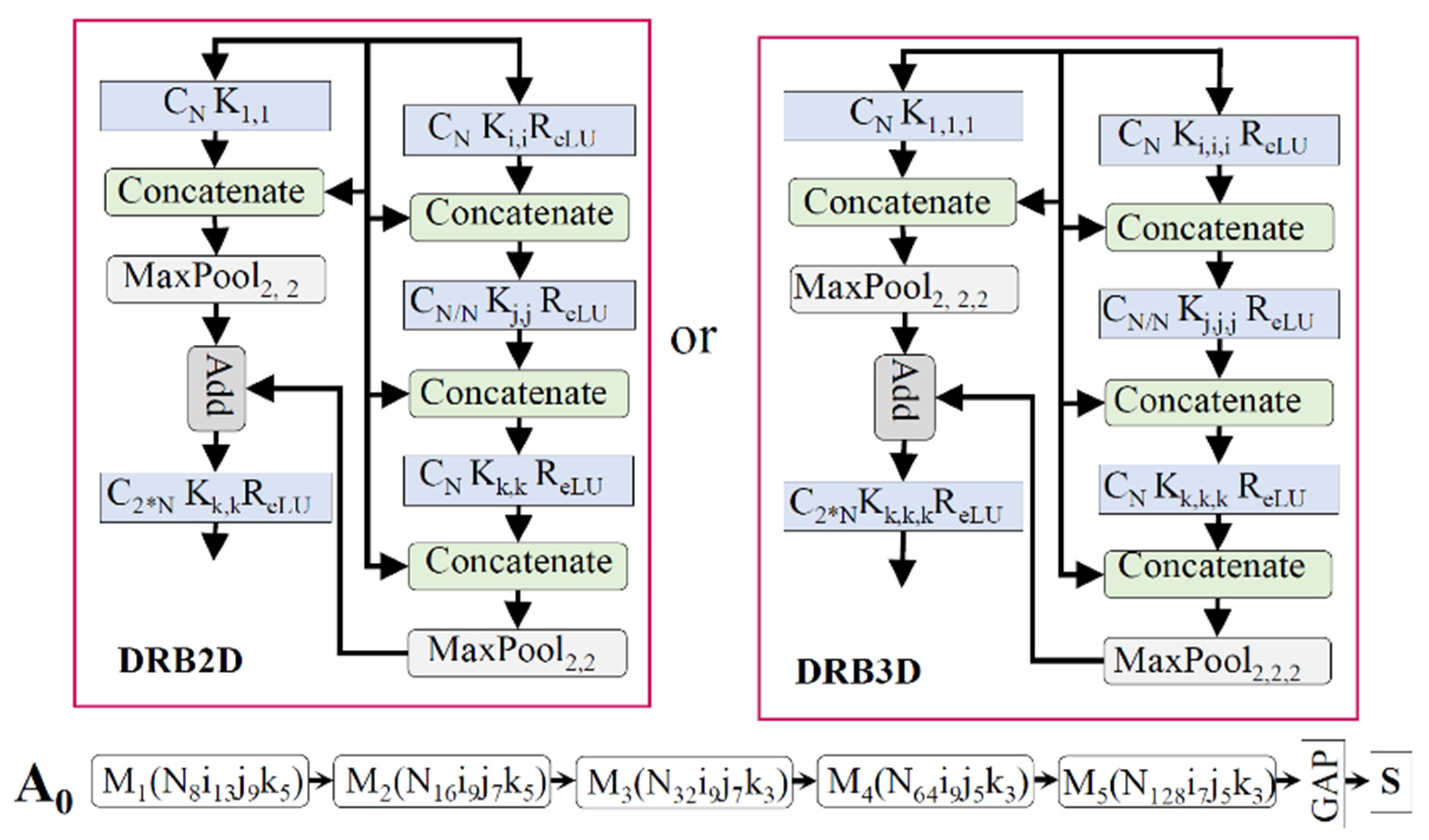
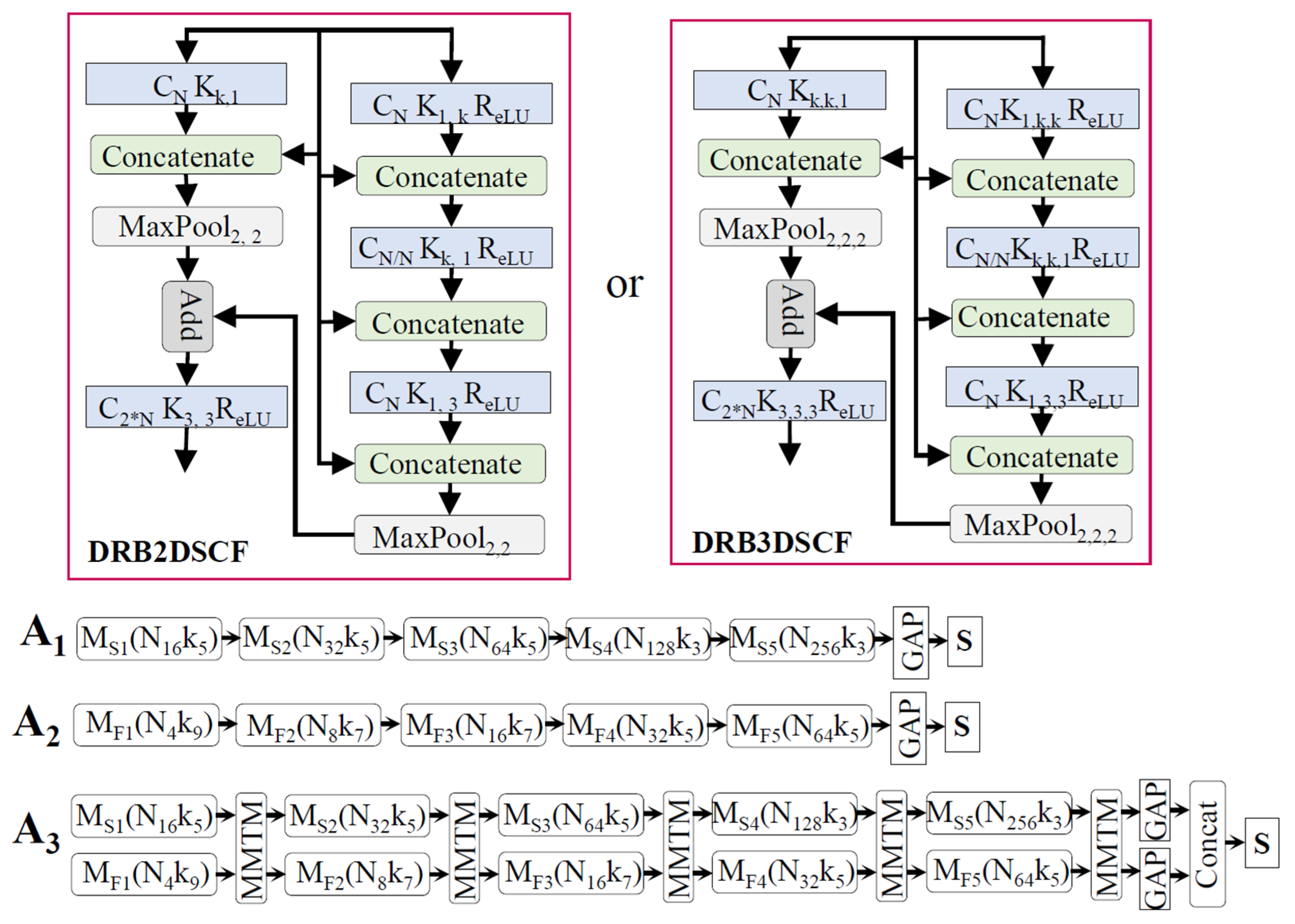

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Emotion Class | Emotion Adjectives | Training Samples | Validation Samples | Testing Samples |
|---|---|---|---|---|
| Excited | Happy, Fun, Love, Sexy, Joy, Pleasure, Exciting, Adorable, Cheerful, Surprising, Interest | 843 | 102 | 50 |
| Fear | Horror, Fear, Scary, Disgust, Terror | 828 | 111 | 50 |
| Neutral | Towards (Sad, Fearful, Exciting, Relax) Ecstasy, Mellow | 678 | 99 | 50 |
| Relaxation | Calm, Chill, Relaxing | 1057 | 148 | 50 |
| Sad | Hate, Depressing, Melancholic, Sentimental, Shameful, Distress, Anguish | 730 | 111 | 50 |
| Tension | Anger, Hate, Rage | 652 | 84 | 50 |
| Total | 4788 | 655 | 300 | |
| Model | Test Accuracy | F1-Score | ROC AUC Score | Parameters |
|---|---|---|---|---|
| C3D | 0.3866 | 0.39 | 0.731 | 57,544,966 |
| A0 without SE (Face_A0_noSE) | 0.460 | 0.45 | 0.778 | 19,397,078 |
| A0 with SE (Face_A0_SE) | 0.516 | 0.51 | 0.820 | 19,409,478 |
| A1 without SE (Face_A1_noSE) | 0.4933 | 0.46 | 0.810 | 11,876,982 |
| A1 with SE (Face_A1_SE) | 0.490 | 0.46 | 0.794 | 11,924,566 |
| A2 without SE (Face_A2_noSE) | 0.430 | 0.37 | 0.769 | 845,670 |
| A2 with SE (Face_A2_SE) | 0.403 | 0.37 | 0.755 | 849,406 |
| A3 without MMTM (Face_A3_noMMTM) | 0.449 | 0.42 | 0.781 | 24,083,846 |
| A3 with MMTM (Face_A3_MMTM) | 0.419 | 0.41 | 0.782 | 24,174,918 |
| Model | Test Accuracy | F1-Score | ROC AUC Score | Parameters |
|---|---|---|---|---|
| A0 without SE (Music_A0_noSE) | 0.5900 | 0.58 | 0.863 | 3,637,142 |
| A0 with SE (Music_A0_SE) | 0.5766 | 0.61 | 0.852 | 3,659,782 |
| A1 without SE (Music_A1_noSE) | 0.5366 | 0.51 | 0.859 | 3,946,949 |
| A1 with SE (Music_A1_SE) | 0.6466 | 0.62 | 0.890 | 3,994,533 |
| A2 without SE (Music_A2_noSE) | 0.6399 | 0.61 | 0.897 | 261,297 |
| A2 with SE (Music_A2_SE) | 0.6266 | 0.61 | 0.878 | 267,369 |
| A3 without MMTM (Music_A3_noMMTM) | 0.3166 | 0.22 | 0.635 | 4,208,240 |
| A3 with MMTM (Music_A3_MMTM) | 0.2433 | 0.17 | 0.610 | 7,941,004 |
| Model | Test Accuracy | F1-Score | ROC AUC Score | Parameters |
|---|---|---|---|---|
| C3D | 0.3266 | 0.19 | 0.723 | 57,544,966 |
| A0 without SE (Video_A0_noSE) | 0.4233 | 0.36 | 0.742 | 19,397,078 |
| A0 with SE (Video_A0_SE) | 0.4833 | 0.46 | 0.806 | 19,409,478 |
| A1 without SE (Video_A1_noSE) | 0.4099 | 0.39 | 0.754 | 11,876,982 |
| A1 with SE (Video_A1_SE) | 0.3666 | 0.35 | 0.736 | 11,922,518 |
| A2 without SE (Video_A2_noSE) | 0.3633 | 0.33 | 0.710 | 845,670 |
| A2 with SE (Video_A2_SE) | 0.3866 | 0.34 | 0.727 | 849,406 |
| A3 without MMTM (Vodeo_A3_noMMTM) | 0.4666 | 0.44 | 0.774 | 12,722,646 |
| A3 with MMTM (Vodeo_A3_MMTM) | 0.5233 | 0.53 | 0.837 | 24,174,918 |
| Model | Test Accuracy | F1-Score | ROC AUC Score | Parameters |
|---|---|---|---|---|
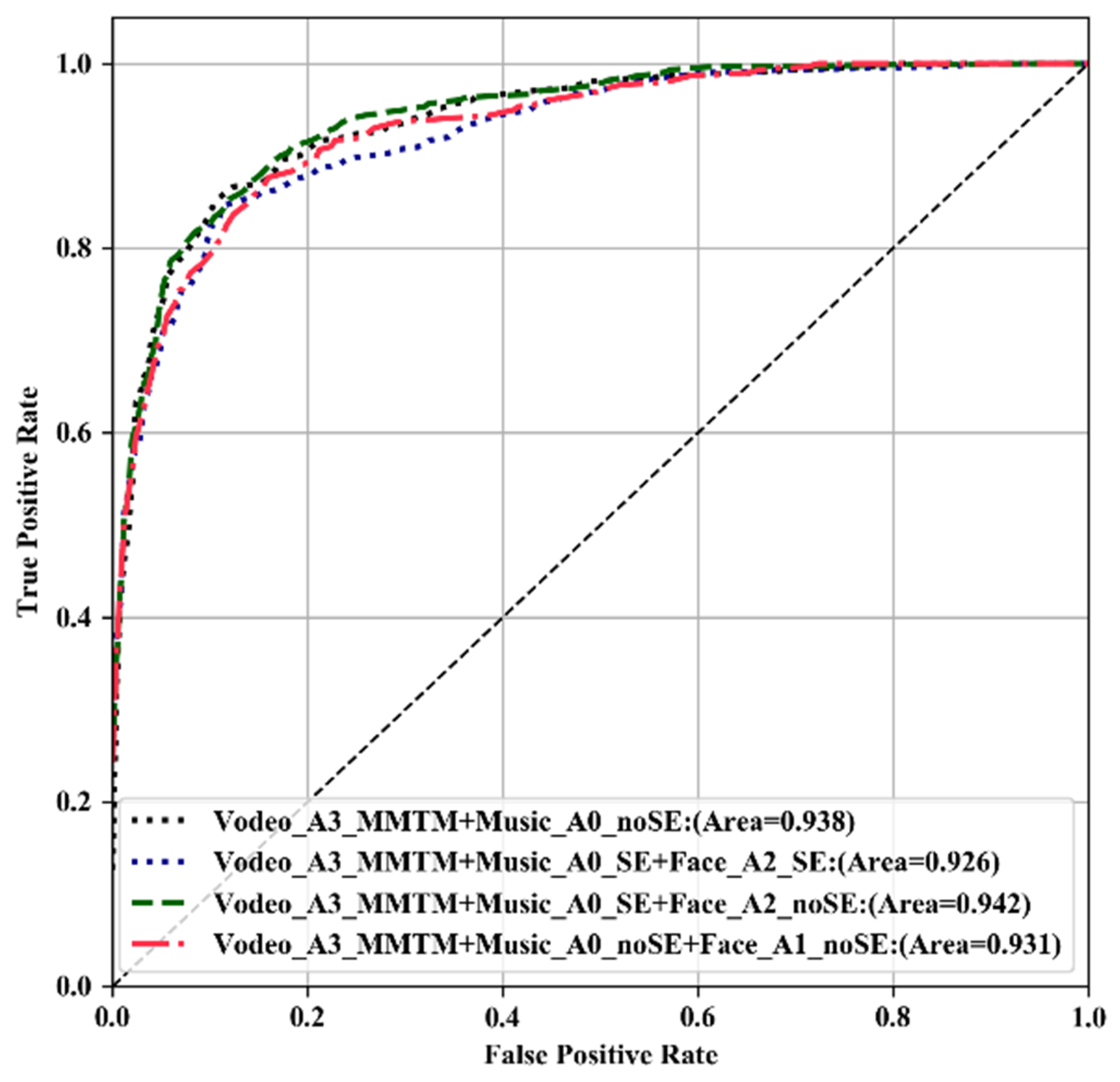
| Vodeo_A3_MMTM + Music_A0_noSE | 0.7400 | 0.71 | 0.938 | 27,812,054 |
| Vodeo_A3_MMTM + Music_A1_noSE | 0.6733 | 0.66 | 0.919 | 28,121,861 |
| Vodeo_A3_MMTM + Music_A2_noSE | 0.6399 | 0.64 | 0.896 | 24,436,209 |
| Model | Test Accuracy | F1-Score | ROC AUC Score | Parameters |
|---|---|---|---|---|
| Vodeo_A3_MMTM + Music_A0_SE + Face_A2_SE | 0.74000 | 0.73 | 0.926 | 28,660,878 |
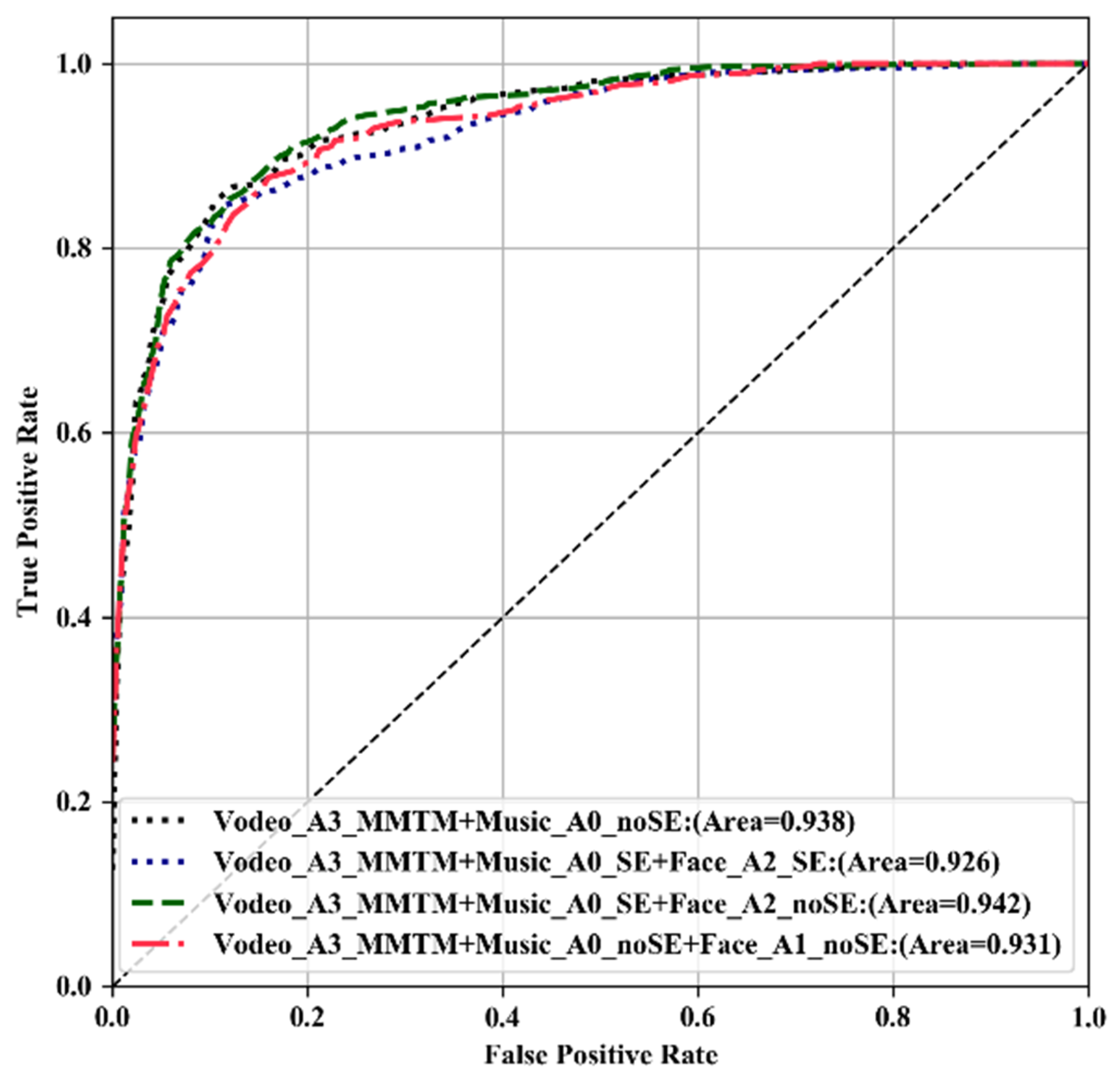
| Vodeo_A3_MMTM + Music_A0_SE + Face_A2_noSE | 0.73333 | 0.72 | 0.942 | 28,589,478 |
| Vodeo_A3_MMTM + Music_A0_noSE + Face_A2_noSE | 0.73333 | 0.71 | 0.939 | 28,657,718 |
| Vodeo_A3_MMTM + Music_A0_SE + Face_A1_noSE | 0.6899 | 0.69 | 0.917 | 39,369,624 |
| Vodeo_A3_MMTM + Music_A0_noSE + Face_A1_noSE | 0.71666 | 0.71 | 0.931 | 39,689,030 |
| Video_A1_noSE + Music_A0_noSE + Face_A2_noSE | 0.69666 | 0.70 | 0.912 | 16,356,198 |
| Video_A2_noSE + Music_A0_noSE + Face_A2_noSE | 0.68666 | 0.67 | 0.915 | 4,587,350 |
| Video_A2_noSE + Music_A2_noSE + Face_A2_noSE | 0.610 | 0.59 | 0.873 | 1,433,649 |
| Video_A1_noSE + Music_A1_noSE + Face_A1_noSE | 0.63666 | 0.63 | 0.860 | 19,432,869 |
| Video_A1_noSE + Music_A1_noSE + Face_A2_noSE | 0.69999 | 0.69 | 0.925 | 11,942,805 |
| Video Frame | Class-Wise Probability | Video Frame | Class-Wise Probability |
|---|---|---|---|
 Ground truth: Excited |
|  Ground truth: Neutral |
|
 Ground truth: Sad |
|  Ground truth: Fear |
|
 Ground truth: Relaxation |
|  Ground truth: Tension |
|
| Method | Dataset | Data Type | Emotion Class | Score |
|---|---|---|---|---|
| RNN [25] | LastFM | Music | 4 | 0.542 (Accuracy) |
| CNN [22] | CAL500 | Music | 18 | 0.534 (F1-score) |
| CAL500 exp | Music | 18 | 0.709 (F1-Score) | |
| SVM [21] | Own | Music | 4 | 0.764(F1-Score) |
| GMM [56] | DEAP120 | Music and video | 8 | 0.90 (Accuracy) |
| CLR [50] | CAL500 | Music and video | 18 | 0.744 (Accuracy) |
| MM [50] | Own | Music and video | 6 | 0.88 (F1-Score) |
| Our | Own | Music and video | 6 | 0.71 (F1-Score) |
| Our | Own | Music, video and Face | 6 | 0.73 (F1-Score) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pandeya, Y.R.; Bhattarai, B.; Lee, J. Deep-Learning-Based Multimodal Emotion Classification for Music Videos. Sensors 2021, 21, 4927. https://doi.org/10.3390/s21144927
Pandeya YR, Bhattarai B, Lee J. Deep-Learning-Based Multimodal Emotion Classification for Music Videos. Sensors. 2021; 21(14):4927. https://doi.org/10.3390/s21144927
Chicago/Turabian StylePandeya, Yagya Raj, Bhuwan Bhattarai, and Joonwhoan Lee. 2021. "Deep-Learning-Based Multimodal Emotion Classification for Music Videos" Sensors 21, no. 14: 4927. https://doi.org/10.3390/s21144927
APA StylePandeya, Y. R., Bhattarai, B., & Lee, J. (2021). Deep-Learning-Based Multimodal Emotion Classification for Music Videos. Sensors, 21(14), 4927. https://doi.org/10.3390/s21144927