
ASNet: Auto-Augmented Siamese Neural Network for Action Recognition



Abstract
:1. Introduction
- We addressed the issue of using random cropping methods for data augmentation in CNN-based video action recognition: generating noisy samples through random cropping will adversely affect the performance of the trained action recognition model.
- We proposed a Siamese neural network architecture that can reduce the negative impact of non-informative samples through gradient compensation and enhance critical information in the inference process.
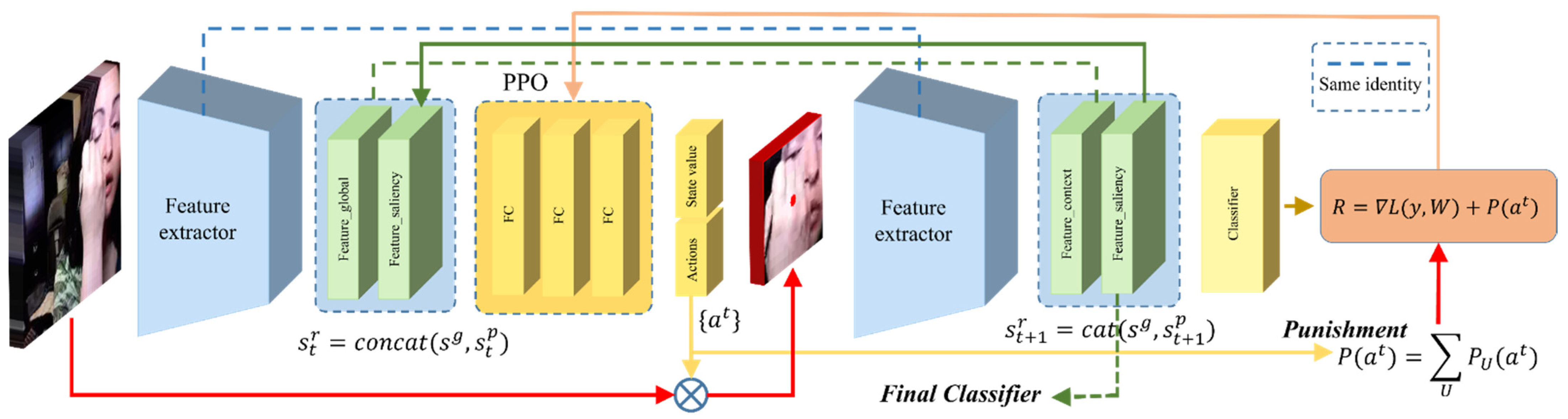
- We proposed a new type of reinforcement learning agent, called SPA (Saliency Patch Agent), to generate salient patches. SPA can be weakly supervised to crop the critical information for action recognition from input video clips without additional labels.
- The proposed method has undergone end-to-end training and achieved state-of-the-art performance on UCF-101 and HMDB-51 datasets.
2. Related Work
2.1. Deep Learning-Based Action Recognition
2.2. Data Augmentation
2.3. Saliency Detection for Action Recognition
2.4. Deep Reinforcement Learning in Action Recognition
3. ASNet Framework
3.1. Model Formulation
3.2. Salient Patch Agent
3.2.1. State and Action Space
3.2.2. Reward
| Algorithm1. Training procedure of the SPA model |
| Output: of SPA model |
| , , |
| do |
| do |
| 6: Get logits through , |
| 7: |
| from Policy |
| by getting |
| 12: |
| 13: end while |
| do |
| with gradient |
| 17: end while |
| 18: |
| 19: end while |
| Algorithm 2. Training procedure of ASNet |
| Input: Original input frame clips |
| Output: and |
| 1: Initialize and |
| 2: while do |
| 3: Get through conventional cropping on |
| 4: Get through SPA on |
| 5: Take and as inputs; Fix ; Train |
| 6: Fix ; Train through Algorithm 1 |
| 7: end while |
3.2.3. Training of Salient Patch Agent
4. Experiments
4.1. Experiment Settings and Implementation Details
4.1.1. Datasets
4.1.2. Training of CNN
4.1.3. Training of ASNet
4.1.4. Inference Details
4.2. Ablation Studies
4.2.1. Comparison with Different Cropping Strategies
4.2.2. ASNet with Different Backbones
4.2.3. ASNet with Different Feature Fusion Strategies
4.2.4. Hyperparameters
4.3. Analysis of ASNet
4.3.1. Exploration of ASNet Architecture
4.3.2. Visualization of ASNet
4.4. Comparison with the State of the Art
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mabrouk, A.B.; Zagrouba, E. Abnormal behavior recognition for intelligent video surveillance systems: A review. Expert Syst. Appl. 2018, 91, 480–491. [Google Scholar] [CrossRef]
- Ranasinghe, S.; Al Machot, F.; Mayr, H.C. A review on applications of activity recognition systems with regard to performance and evaluation. Int. J. Distrib. Sens. Netw. 2016, 12, 1550147716665520. [Google Scholar] [CrossRef] [Green Version]
- Turaga, P.; Chellappa, R.; Subrahmanian, V.S.; Udrea, O. Machine recognition of human activities: A survey. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1473–1488. [Google Scholar] [CrossRef] [Green Version]
- Jiang, M.; Pan, N.; Kong, J. Spatial-temporal saliency action mask attention network for action recognition. J. Vis. Commun. Image Represent. 2020, 71, 102846. [Google Scholar] [CrossRef]
- Zuo, Q.; Zou, L.; Fan, C.; Li, D.; Jiang, H.; Liu, Y. Whole and Part Adaptive Fusion Graph Convolutional Networks for Skeleton-Based Action Recognition. Sensors 2020, 20, 7149. [Google Scholar] [CrossRef] [PubMed]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Crasto, N.; Weinzaepfel, P.; Alahari, K.; Schmid, C. Mars: Motion-Augmented Rgb Stream for Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7882–7891. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seul, Korea, 27 October–2 November 2019. [Google Scholar]
- Fan, Q.; Chen, C.-F.; Kuehne, H.; Pistoia, M.; Cox, D. More is less: Learning efficient video representations by big-little network and depthwise temporal aggregation. arXiv 2019, arXiv:1912.00869. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Hara, K.; Kataoka, H.; Satoh, Y. Can Spatiotemporal 3d Cnns Retrace the History of 2d Cnns and Imagenet? In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018.
- Dong, M.; Fang, Z.; Li, Y.; Bi, S.; Chen, J. AR3D: Attention Residual 3D Network for Human Action Recognition. Sensors 2021, 21, 1656. [Google Scholar] [CrossRef] [PubMed]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Goyal, R.; Ebrahimi Kahou, S.; Michalski, V.; Materzynska, J.; Westphal, S.; Kim, H.; Haenel, V.; Fruend, I.; Yianilos, P.; Mueller-Freitag, M. The “something something” video database for learning and evaluating visual common sense. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Zhang, Y.; Sun, S.; Lei, L.; Liu, H.; Xie, H. STAC: Spatial-Temporal Attention on Compensation Information for Activity Recognition in FPV. Sensors 2021, 21, 1106. [Google Scholar] [CrossRef] [PubMed]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Feichtenhofer, C. X3d: Expanding architectures for efficient video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Li, Y.; Ji, B.; Shi, X.; Zhang, J.; Kang, B.; Wang, L. Tea: Temporal excitation and aggregation for action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, S.; Guo, S.; Huang, W.; Scott, M.R.; Wang, L. V4D: 4D Convolutional neural networks for video-level representation learning. arXiv 2020, arXiv:2002.07442. [Google Scholar]
- Li, X.; Shuai, B.; Tighe, J. Directional temporal modeling for action recognition. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 275–291. [Google Scholar]
- Bekker, A.J.; Goldberger, J. Training Deep Neural-Networks Based on Unreliable Labels. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016. [Google Scholar]
- Patrini, G.; Rozza, A.; Krishna Menon, A.; Nock, R.; Qu, L. Making deep neural networks robust to label noise: A loss correction approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Rolnick, D.; Veit, A.; Belongie, S.; Shavit, N. Deep learning is robust to massive label noise. arXiv 2017, arXiv:1705.10694. [Google Scholar]
- Song, H.; Kim, M.; Park, D.; Shin, Y.; Lee, J.-G. Learning from noisy labels with deep neural networks: A survey. arXiv 2020, arXiv:2007.08199. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Feiszli, M. Video classification with channel-separated convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Liu, J.; Luo, J.; Shah, M. Recognizing realistic actions from videos “in the wild”. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Niebles, J.C.; Chen, C.-W.; Fei-Fei, L. Modeling temporal structure of decomposable motion segments for activity classification. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2010; pp. 392–405. [Google Scholar]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C.-L. Dense trajectories and motion boundary descriptors for action recognition. Int. J. Comput. Vis. 2013, 103, 60–79. [Google Scholar] [CrossRef] [Green Version]
- Kantorov, V.; Laptev, I. Efficient feature extraction, encoding and classification for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. arXiv 2014, arXiv:1406.2199. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [Green Version]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2018. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3d residual networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhou, B.; Andonian, A.; Oliva, A.; Torralba, A. Temporal relational reasoning in videos. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Xie, S.; Sun, C.; Huang, J.; Tu, Z.; Murphy, K. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lin, J.; Gan, C.; Han, S. Tsm: Temporal shift module for efficient video understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Bengio, Y.; Bastien, F.; Bergeron, A.; Boulanger–Lewandowski, N.; Breuel, T.; Chherawala, Y.; Cisse, M.; Côté, M.; Erhan, D.; Eustache, J. Deep learners benefit more from out-of-distribution examples. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Lemley, J.; Bazrafkan, S.; Corcoran, P. Smart augmentation learning an optimal data augmentation strategy. IEEE Access 2017, 5, 5858–5869. [Google Scholar] [CrossRef]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Uddin, A.; Monira, M.; Shin, W.; Chung, T.; Bae, S.-H. SaliencyMix: A Saliency Guided Data Augmentation Strategy for Better Regularization. arXiv 2020, arXiv:2006.01791. [Google Scholar]
- Gong, C.; Wang, D.; Li, M.; Chandra, V.; Liu, Q. KeepAugment: A Simple Information-Preserving Data Augmentation Approach. arXiv 2020, arXiv:2011.11778. [Google Scholar]
- Megrhi, S.; Jmal, M.; Souidene, W.; Beghdadi, A. Spatio-temporal action localization and detection for human action recognition in big dataset. J. Vis. Commun. Image Represent. 2016, 41, 375–390. [Google Scholar] [CrossRef]
- Xu, Z.; Hu, R.; Chen, J.; Chen, C.; Chen, H.; Li, H.; Sun, Q. Action recognition by saliency-based dense sampling. Neurocomputing 2017, 236, 82–92. [Google Scholar] [CrossRef]
- Tu, Z.; Xie, W.; Qin, Q.; Poppe, R.; Veltkamp, R.C.; Li, B.; Yuan, J. Multi-stream CNN: Learning representations based on human-related regions for action recognition. Pattern Recognit. 2018, 79, 32–43. [Google Scholar] [CrossRef]
- Zhang, Y.; Po, L.M.; Liu, M.; Rehman, Y.A.U.; Ou, W.; Zhao, Y. Data-level information enhancement: Motion-patch-based Siamese Convolutional Neural Networks for human activity recognition in videos. Expert Syst. Appl. 2020, 147, 113203. [Google Scholar] [CrossRef]
- Tu, Z.; Xie, W.; Dauwels, J.; Li, B.; Yuan, J. Semantic cues enhanced multimodality multistream CNN for action recognition. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 1423–1437. [Google Scholar] [CrossRef]
- Weng, Z.; Jin, Z.; Chen, S.; Shen, Q.; Ren, X.; Li, W. Attention-Based Temporal Encoding Network with Background-Independent Motion Mask for Action Recognition. Comput. Intell. Neurosci. 2021, 2021, 8890808. [Google Scholar] [CrossRef]
- Pirinen, A.; Sminchisescu, C. Deep reinforcement learning of region proposal networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ren, L.; Lu, J.; Wang, Z.; Tian, Q.; Zhou, J. Collaborative deep reinforcement learning for multi-object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, D.; Wu, H.; Zhang, J.; Huang, K. A2-RL: Aesthetics aware reinforcement learning for image cropping. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Huang, Z.; Heng, W.; Zhou, S. Learning to paint with model-based deep reinforcement learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Han, J.; Yang, L.; Zhang, D.; Chang, X.; Liang, X. Reinforcement cutting-agent learning for video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Dong, W.; Zhang, Z.; Tan, T. Attention-aware sampling via deep reinforcement learning for action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 27 January–1 February 2019. [Google Scholar]
- Wu, W.; He, D.; Tan, X.; Chen, S.; Wen, S. Multi-agent reinforcement learning based frame sampling for effective untrimmed video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Zheng, Y.-D.; Liu, Z.; Lu, T.; Wang, L. Dynamic sampling networks for efficient action recognition in videos. IEEE Trans. Image Process. 2020, 29, 7970–7983. [Google Scholar] [CrossRef]
- Meng, Y.; Lin, C.-C.; Panda, R.; Sattigeri, P.; Karlinsky, L.; Oliva, A.; Saenko, K.; Feris, R. Ar-net: Adaptive frame resolution for efficient action recognition. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 86–104. [Google Scholar]
- Tang, Y.; Agrawal, S. Discretizing continuous action space for on-policy optimization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Nian, R.; Liu, J.; Huang, B. A review on reinforcement learning: Introduction and applications in industrial process control. Comput. Chem. Eng. 2020, 139, 106886. [Google Scholar] [CrossRef]
- Henderson, P.; Islam, R.; Bachman, P.; Pineau, J.; Precup, D.; Meger, D. Deep reinforcement learning that matters. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceeding of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Tran, D.; Ray, J.; Shou, Z.; Chang, S.-F.; Paluri, M. Convnet architecture search for spatiotemporal feature learning. arXiv 2017, arXiv:1708.05038. [Google Scholar]
- Wu, H.; Liu, J.; Zha, Z.-J.; Chen, Z.; Sun, X. Mutually Reinforced Spatio-Temporal Convolutional Tube for Human Action Recognition. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI-19), Macao, China, 10–16 August 2019. [Google Scholar]
- He, D.; Zhou, Z.; Gan, C.; Li, F.; Liu, X.; Li, Y.; Wang, L.; Wen, S. Stnet: Local and global spatial-temporal modeling for action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Liu, Z.; Li, Z.; Wang, R.; Zong, M.; Ji, W. Spatiotemporal saliency-based multi-stream networks with attention-aware LSTM for action recognition. Neural Comput. Appl. 2020, 32, 14593–14602. [Google Scholar] [CrossRef]
- Du, W.; Wang, Y.; Qiao, Y. Recurrent spatial-temporal attention network for action recognition in videos. IEEE Trans. Image Process. 2017, 27, 1347–1360. [Google Scholar] [CrossRef] [PubMed]
- Jiang, B.; Wang, M.; Gan, W.; Wu, W.; Yan, J. Stm: Spatiotemporal and motion encoding for action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Liu, Z.; Luo, D.; Wang, Y.; Wang, L.; Tai, Y.; Wang, C.; Li, J.; Huang, F.; Lu, T. Teinet: Towards an efficient architecture for video recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Zhou, Y.; Sun, X.; Luo, C.; Zha, Z.-J.; Zeng, W. Spatiotemporal fusion in 3D CNNs: A probabilistic view. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cropping Strategy | UCF-101 (%) | HMDB-51 (%) |
|---|---|---|
| Baseline | 91.7 | 66.7 |
| Random-cropping | 92.2 | 66.8 |
| Corner-cropping | 92.3 | 67.0 |
| Multiscale-cropping | 91.9 | 64.7 |
| Center-cropping | 92.5 | 67.6 |
| SPA-cropping | 93.7 | 69.2 |
| Fully-resize | 92.3 | 67.2 |
| Left Top Corner | 92.1 | 66.9 |
| Right Top Corner | 91.5 | 67.0 |
| Center | 92.5 | 67.6 |
| Left Bottom Corner | 92.0 | 67.1 |
| Right Bottom Corner | 92.2 | 67.1 |
| Backbone | Single Stream | Siamesecenter | ASNet | |||
|---|---|---|---|---|---|---|
| UCF-101 | HMDB-51 | UCF-101 | HMDB-51 | UCF-101 | HMDB-51 | |
| ResNet-18 | 84.5 | 57.3 | 85.0 | 57.5 | 86.7 | 57.5 |
| ResNet-50 | 88.7 | 62.4 | 88.8 | 62.4 | 90.5 | 62.4 |
| ResNet-101 | 88.6 | 63.6 | 88.9 | 63.8 | 90.6 | 64.7 |
| DenseNet-121 | 87.5 | 61.1 | 88.1 | 61.3 | 90.1 | 61.7 |
| ResNext-101 | 91.7 | 66.7 | 92.1 | 67.0 | 93.7 | 69.2 |
| ResNext-101 (64 f) | 95.2 | 74.1 | 95.4 | 75.2 | 96.4 | 77.7 |
| Fusion Strategy | UCF-101 (%) | HMDB-51 (%) |
|---|---|---|
| Baseline (single branch) | 91.7 | 66.7 |
| Individual | 92.8 | 68.1 |
| Sum | 92.7 | 67.8 |
| Concatenation | 93.7 | 69.2 |
| Convolution | 92.6 | 67.8 |
| Multiply | 92.1 | 66.8 |
| Steps | UCF-101 (%) | HMDB-51 (%) | ||||||
|---|---|---|---|---|---|---|---|---|
| 2 | 5 | 10 | 15 | 2 | 5 | 10 | 15 | |
| 2-actions | 92.4 | 92.5 | 92.8 | 93.0 | 67.5 | 67.8 | 67.8 | 67.9 |
| 3-actions | 93.1 | 93.6 | 93.7 | 93.4 | 68.3 | 68.5 | 69.2 | 68.7 |
| 4-actions | 92.9 | 93.2 | 93.7 | 93.5 | 67.9 | 68.2 | 68.5 | 68.5 |
| HMDB-51 (%) | |||
|---|---|---|---|
| Single-Stream Neural Network | ASNet | ||
| Center Crop | SPA Crop | Center and SPA Crop and | |
| 73.9 (baseline) | 74.5 | 75.5 | |
| 75.0 | 75.8 | 76.6 | |
| Methods | Input Size | GFLOPs × Views | UCF-101 | HMDB-51 |
|---|---|---|---|---|
| C3D [17] | 224 224 | 296.7 4 | 85.2 | 51.6 |
| Res3D [74] | 224 224 | - | 85.8 | 54.9 |
| P3D [39] | 224 224 | - | 88.6 | - |
| 3D-ResNext [11] | 112 112 | 48.4 4 | 95.1 | 73.4 |
| MRST-T [75] | 224 224 | 99.6 4 | 96.5 | 75.4 |
| StNet [76] | 256 256 | 310.5 4 | 94.3 | - |
| iDT-RCB [52] | - | - | 94.8 | - |
| STSAMANet [4] | 128 128 | - | 95.9 | - |
| STSVOS [55] | 224 224 | - | 93.9 | 67.2 |
| ATEN [56] | - | - | 94.6 | 70.5 |
| STS-ALSTM [77] | - | - | 92.7 | 64.4 |
| RSTAN [78] | - | - | 94.6 | 70.5 |
| TSN [10] | 224 224 | 3.2 250 | 93.2 | - |
| TSM [42] | 224 224 | 65 30 | 95.9 | 73.5 |
| STM [79] | 224 224 | 66.5 30 | 96.2 | 72.2 |
| TEINet [80] | 224 224 | 66 30 | 96.7 | 72.1 |
| DropPath [81] | 224 224 | 254 2 | 96.5 | - |
| I3D [6] | 224 224 | 107.9 4 | 95.4 | 74.5 |
| S3D [41] | 224 224 | 66.4 30 | 96.8 | 75.9 |
| R(2 + 1)D [18] | 112 112 | 152.4 4 | 96.8 | 74.5 |
| DSN [64] | 112 112 | 158 4 | 96.8 | 75.5 |
| ASNet | 112 112 | 104.5 4 | 96.8 | 76.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Po, L.-M.; Xiong, J.; REHMAN, Y.A.U.; Cheung, K.-W. ASNet: Auto-Augmented Siamese Neural Network for Action Recognition. Sensors 2021, 21, 4720. https://doi.org/10.3390/s21144720
Zhang Y, Po L-M, Xiong J, REHMAN YAU, Cheung K-W. ASNet: Auto-Augmented Siamese Neural Network for Action Recognition. Sensors. 2021; 21(14):4720. https://doi.org/10.3390/s21144720
Chicago/Turabian StyleZhang, Yujia, Lai-Man Po, Jingjing Xiong, Yasar Abbas Ur REHMAN, and Kwok-Wai Cheung. 2021. "ASNet: Auto-Augmented Siamese Neural Network for Action Recognition" Sensors 21, no. 14: 4720. https://doi.org/10.3390/s21144720
APA StyleZhang, Y., Po, L.-M., Xiong, J., REHMAN, Y. A. U., & Cheung, K.-W. (2021). ASNet: Auto-Augmented Siamese Neural Network for Action Recognition. Sensors, 21(14), 4720. https://doi.org/10.3390/s21144720