

Attred: Attribute Based Resource Discovery for IoT



Abstract
1. Introduction
- Location-aware discoverability: Decentralized resource discovery using the proposed region based DHT overlay with a proposed tuple data structure that creates a location-aware overlay (considering the physical location of underlying nodes) and allows multi-attribute and location-based resource discovery.
- Decentralized discovery control: Fine-grained discovery control for clients to discover the address data of the resources based on their attributes without a centralized entity, which fits the distributed nature of IoT environment.
- Distributed Computation: A secure distributed computation to distribute some of the heavy computations in Attred using additive secret sharing without affecting the security of the model.
2. Related Works
3. Preliminaries
3.1. Security Definitions
- a.
- Non-degeneracy: ;
- b.
- Bilinearity: , ;
- c.
- Computability: , there exists an efficient algorithm to compute .
3.2. Distributed Hash Table
- Easy Computation: given m, it is easy to compute .
- One-way: given h, it is hard to find any m such that . This property is also called preimage resistance.
- Strong Collision Resistance: it is hard to find two distinct messages with .
3.3. Resource Discovery in IoT
3.4. Attribute Based Encryption
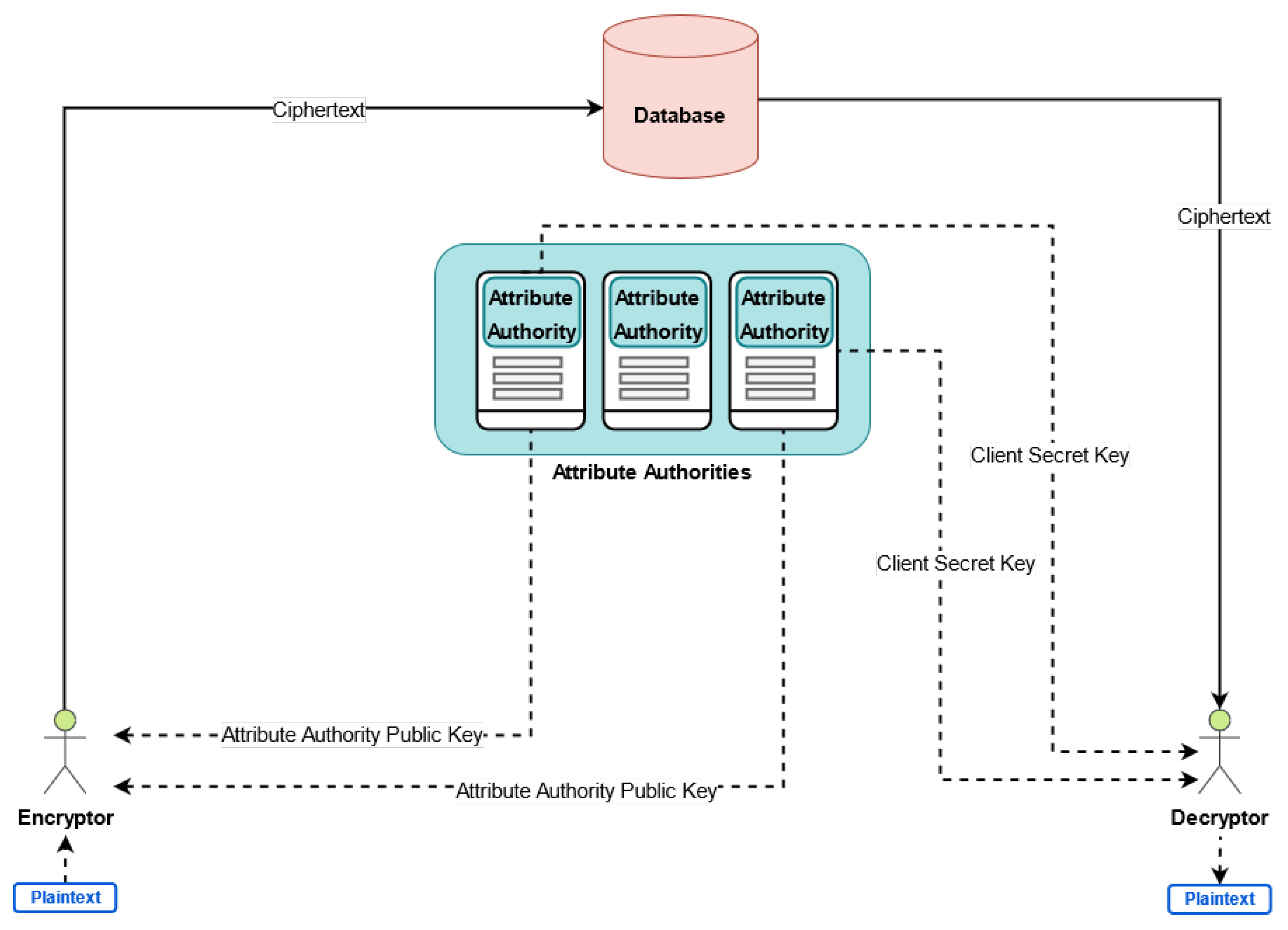
4. Model Description
4.1. Model Features
- Scalability: Attred is based on the RDHT as an overlay for managing the edge and fog nodes in the system. Due to adopting the DHT technology, the added overhead increases logarithmically which makes it scalable.
- Attribute based discovery: The resources in Attred can be discovered based on their attributes. Therefore, there is no need to know the exact identifier of a resource to be able to discover it.
- Location aware discovery: Attred creates an overlay of IoT gateways divided logically into multiple region sets in RDHT and the resources can be registered and discovered based on their physical locations.
- Attribute based access control: The resources in the system are able to define the set of attributes that a client should have in order to being able to discover the registered resources. This feature allows some resources to being discoverable only by a predefined subset of clients based on their attributes.
- Discoverability: Attred is able to be fully integrated with the Distributed Address Table (DAT) [40] as parts of its system to allow discovering and accessing all resources in the network including those behind the Network Address Translator (NAT). This is a crucial requirement for IoT environment with huge number of nodes behind a firewall/NAT.
- Responsibility Definition: Attred clearly defines a specific node or a distinct subset of nodes that are responsible for registering any resource in the system, without relying on any centralized organizing entity. Therefore, during the discovery process the same distributed subset of nodes can be used to discover the required resources.
4.2. Security Model
- Discovery correctness: any semi-honest client that has the required attributes defined in the discovery policy can discover the address data of the resource.
- Discovery soundness: every PPT adversary and without the required attributes defined in the discovery policy can discover the resource with negligible probability only.
- Resource privacy: every PPT adversary can learn the relationship between the address data and a resource, without having required attributes defined in the discovery policy with negligible probability only.
- Client privacy: every PPT adversary can learn the private attributes in discovery requests issued by members of with negligible probability only.
4.3. Overlay Description
4.4. System Setup
4.5. Attribute Authority Registration
4.6. Client Secret Key Generation
4.7. Resource Registration
- Tag Definition and Generation: the object o that wants to register its resource in the network defines set of attributes that describes the resource (e.g., its location, its type, etc.). Based on these attributes and using the hash function , it generates the tags that represent the first part of the final tuples.
- Ownership Generation: the object o generates a random number , and adds its hashed value using the hash function as a later proof of ownership of the generated tuple.
- Discovery Policy Definition: in this step the object o defines the Boolean formula in the final tuples, the represents the set of attributes of clients that are eligible to discover the resource . This step is conduced locally, as we need to let the resources themselves define the legitimate clients.
- Registration Level Definition: The object o defines the regions in which the resource has to be registered in. It can be local level, general level or both. The local level results in registering the resource in the same region, while the general level results in registering the resource in the general region, regardless of its physical location.
- Resource Address Encryption: The object o after defining and generating the tags and the attributes can encrypt the resource address. If the object o does not have the required computational power, the address data can be encrypted in the directly connected gateway w. In both cases (encrypting directly in the object or in the gateway), Attred proposes an approach of securely distributing parts of the heavy computation steps to other nodes. Lets assume that the directly connected gateway w receives the set of tags, the address data, and the attribute set from the object o. Taking the address data () of , the system global parameters () and set of public keys of the attribute authorities (), the gateway w generates the parameter of the tuples. The parameter includes a main component , the encrypted address data using ABE and a set of three components () for each attribute i in the discovery policy. The later set of three components are used by the clients to be able to decrypt the address of a discovered resource. The gateway w first converts the Boolean formula of the discovery policy to a linear secret sharing scheme (LSSS) matrix . As instance, the in Figure 3 will be converted to . The gateway w then chooses a random secret , and generates a vector (i.e., an ordered finite list of numbers) where its length is equal to number of columns in , its first element is set to s, and the rest elements chosen randomly from . This vector ensures that only clients with required attributes can get the random secret s that is required to decrypt the address data. It also generates a vector where its length is equal to number of columns in , its first element set to zero, and the rest elements chosen randomly from . This vector ensures that no two clients can combine their attributes in an attempt to decrypt the address data.Additionally, it chooses three parameters for each attribute i, i.e., each leaf in the discovery policy. is selected randomly from . The gateway w computes for each attribute i in the discovery policy using (2), where denotes the ith row in .The address data of the registered resource is encrypted as (4) and the three parameters of an attribute i in the discovery policy is computed as in (5)–(7).There are a number of public and independent computational nodes in the system as illustrated in Figure 5. These nodes are assumed to be independent and semi-honest computational nodes that are able to perform heavy computational operations. The resource registration and discovery can be done without involving the computational node, but using those nodes improves the resource registration time. Assume that the nodes performing the encryption wants to improve the registration time and has connections with independent semi-honest computational nodes, as instance cloud servers, such that . The steps in Equations (4)–(7) can be distributed based on the additive secret sharing and computed using (12)–(15) instead, as following: The node w first chooses random additive shares such that their summation is equal to the random parameter .Then, for each attribute i in the discovery policy , the node w also chooses random additive shares for and satisfying (9)–(11), respectively. These are done to be able to distribute the computation overhead of heavy exponentiation among the semi-honest nodes, without revealing the secret values.After selecting the random numbers, each of the computational nodes receives and a set for each attribute i. A node j and after receiving the set, computes and using (5)–(7), respectively. Then, the node j sends the results back to w. The node w and after receiving the results from all nodes, starts computing the final parameter using (12) for and (13)–(15) for the three components () of each attribute i in the discovery policy.It is noteworthy to mention that if the defined discovery policy by the object will not change, the distributed computation can be done in advance and stored locally regardless of the address data of the resource. This means that in this case the computational nodes do not have to be online at the time of resource registration.
- Tuple Signing: The tuples are constructed as in which is the hashed value of an attribute in of the resource, is used later to proof the ownership of this tuple, is the the discovery policy that defines the required attribute set of the clients that can discover this resource, and is the encrypted address data of the resource. These tuples of the resource are signed by the gateway w.
- Resource Registration: Finally, the gateway w puts each of the generated and signed tuples in the corresponding peer in RDHT that is responsible to store this tuple (i.e., its identifier is the closet to the parameter in the tuple). The registration is done in the same local region, in the general region or in both regions, based on the request of the object o.
4.8. Resource Discovery
- Query Generation: First, the client sends its attribute, the required attributes of the resource to be discovered in the network and the targeted region to the directly connected gateway w. The gateway w generates set of tags, by hashing the required attributes of the discovered resources in the received request from .
- Lookup: in this step, the gateway w issues the lookup process in the targeted region in RDHT overlay to retrieve the specific tuples based on the required s and the set of attributes of the client . The later information, i.e., the attributes of the client, is optional and can be ignored to hide the attributes of the clients. The discovery can be local, intra-regional or regional. The local discovery is done to discover a resource that is registered in the same region that the client belongs to. In this case, both source and destination gateways share the same d prefix bits, where d is the length of the output of the used hash function . The intra-regional discovery is done to discover a resource that is registered in a different region of the same region set. This means the the identifiers of both source and destination of the lookup share same prefix bits. The regional discovery is done to discover a resource that is registered in a region that belongs to a different region set, or a general resource regardless of its physical location. The recipient nodes in RDHT first filters the resources based on the required s, and then checks the parameter of the filtered tuples and get the final set of tuples based on the required attributes in the parameter of each tuple and the attributes of the client . If has not been sent in the request, all results returned back to the gateway w. The result of each of the lookup operations is a set of data parameters that indicates the resources with the specific attribute i.
- Result Verification: after receiving the digitally signed results of the required attributes, they will be verified and the intersected members of sets will be gathered. In addition, the parameter of the generated set will be checked locally and filtered based on the required attributes in the parameter of each tuple in and the attributes of the client (i.e., ). Some ranking approaches to might be applied in this step as well.
- Resource Address Discovery: finally, depending on the attributes of client and parameter in the retrieved tuples, the resources in will be returned to and the retrieved of the resource in the tuples will be decrypted based on the attributes of client . For each attribute i in parameter of the tuple, and using the and components in the and its relevant secret key of that attribute, the client computes the value in (16). The results of the retrieved values of all attributes is used in (17) to retrieve the pairing value of the random secret s.where is a constant in such that returns a vector with the first element only set to one, and the rest set to zero. Finally, the address data of the resource is recovered by decrypting the address data as in (18).
4.9. Resource Update and Removal
5. Evaluations
5.1. Security Analysis
5.2. Discussion
5.3. Complexity Analysis
- Local Registering or discovering a resource in Attred ().
- Registering or discovering a resource in the general region in Attred ().
- Intra-regional discovering a resource in the same region set ().
- Regional discovering of a resource in a different region set than the client region ().
5.4. Performance Analysis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Correction Statement
Abbreviations
| AA | Attribute Authority |
| ABE | Attributed Based Encryption |
| CP | Cipher Policy |
| DABE | Decentralized Attributed Based Encryption |
| DHT | Distributed Hash Table |
| KP | Key Policy |
| LSSS | Linear Secret Sharing Scheme |
| MA | Multi Authority |
| RDHT | Region-Based Distributed Hash Table |
References
- Vailshery, L. Global IoT and non-IoT Connections 2010–2025. Available online: https://www.statista.com/statistics/1101442/iot-number-of-connected-devices-worldwide/ (accessed on 8 June 2021).
- Jara, A.J.; Lopez, P.; Fernandez, D.; Castillo, J.F.; Zamora, M.A.; Skarmeta, A.F. Mobile digcovery: A global service discovery for the internet of things. In Proceedings of the 2013 27th International Conference on Advanced Information Networking and Applications Workshops, Barcelona, Spain, 25–28 March 2013; pp. 1325–1330. [Google Scholar]
- Jia, B.; Li, W.; Zhou, T. A centralized service discovery algorithm via multi-stage semantic service matching in internet of things. In Proceedings of the IEEE International Conference on Computational Science and Engineering (CSE), Guangzhou, China, 21–24 July 2017; pp. 422–427. [Google Scholar]
- Cheshire, S.; Krochmal, M. DNS-Based Service Discovery; Technical Report, RFC 6763; Internet Engineering Task Force (IETF): Fremont, CA, USA, 2013. [Google Scholar]
- Mokadem, R.; Hameurlain, A.; Tjoa, A.M. Resource discovery service while minimizing maintenance overhead in hierarchical DHT systems. Int. J. Adapt. Resilient Auton. Syst. IJARAS 2012, 3, 1–17. [Google Scholar] [CrossRef]
- Paganelli, F.; Parlanti, D. A DHT-based discovery service for the Internet of Things. J. Comput. Netw. Commun. 2012. [Google Scholar] [CrossRef]
- Cirani, S.; Davoli, L.; Ferrari, G.; Léone, R.; Medagliani, P.; Picone, M.; Veltri, L. A scalable and self-configuring architecture for service discovery in the internet of things. IEEE Internet Things J. 2014, 1, 508–521. [Google Scholar] [CrossRef]
- Alshawki, M.B.; Crispo, B.; Ligeti, P. A Decentralized and Scalable Model for Resource Discovery in IoT Network. In Proceedings of the 2019 International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Barcelona, Spain, 21–23 October 2019; pp. 1–4. [Google Scholar]
- Tanganelli, G.; Vallati, C.; Mingozzi, E. A fog-based distributed look-up service for intelligent transportation systems. In Proceedings of the 18th International Symposium on a World of Wireless, Mobile and Multimedia Networks (WoWMoM), Macau, China, 12–15 June 2017; pp. 1–6. [Google Scholar]
- Alshawki, M.B.; Yan, Y.; Ligeti, P.; Reich, C. A Decentralized Resource Discovery Using Attribute Based Encryption for Internet of Things. In Proceedings of the 2020 4th Cyber Security in Networking Conference (CSNet), Lausanne, Switzerland, 21–23 October 2020; pp. 1–3. [Google Scholar]
- Cabrera, C.; White, G.; Palade, A.; Clarke, S. The right service at the right place: A service model for smart cities. In Proceedings of the 2018 IEEE International Conference on Pervasive Computing and Communications (PerCom), Athens, Greece, 19–23 March 2018; pp. 1–10. [Google Scholar]
- Alshawki, M.B.; Ligeti, P.; Reich, C. On Security and Performance Requirements of Decentralized Resource Discovery in IoT. In Proceedings of the International Conference on Recent Innovations in Computing, Jammu, India, 8–9 June 2021. [Google Scholar]
- Zhang, B.; Mor, N.; Kolb, J.; Chan, D.S.; Lutz, K.; Allman, E.; Wawrzynek, J.; Lee, E.; Kubiatowicz, J. The cloud is not enough: Saving iot from the cloud. In Proceedings of the 7th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 15), Santa Clara, CA, USA, 6–7 July 2015. [Google Scholar]
- Bonomi, F.; Milito, R.; Zhu, J.; Addepalli, S. Fog computing and its role in the internet of things. In Proceedings of the First Edition of the MCC Workshop on Mobile Cloud Computing, Helsinki, Finland, 17 August 2012; pp. 13–16. [Google Scholar]
- Mokbel, M.F.; Aref, W.G.; Kamel, I. Performance of multi-dimensional space-filling curves. In Proceedings of the 10th ACM International Symposium on Advances in Geographic Information Systems, McLean, VA, USA, 8–9 November 2002; pp. 149–154. [Google Scholar]
- Ramabhadran, S.; Ratnasamy, S.; Hellerstein, J.M.; Shenker, S. Prefix hash tree: An indexing data structure over distributed hash tables. In Proceedings of the 23rd ACM Symposium on Principles of Distributed Computing, St. John’s, NL, Canada, 25–28 July 2004. [Google Scholar]
- Maymounkov, P.; Mazieres, D. Kademlia: A peer-to-peer information system based on the xor metric. In Proceedings of the International Workshop on Peer-to-Peer Systems, Cambridge, MA, USA, 7–8 March 2002; pp. 53–65. [Google Scholar]
- Picone, M.; Amoretti, M.; Zanichelli, F. GeoKad: A P2P distributed localization protocol. In Proceedings of the 2010 8th IEEE International Conference on Pervasive Computing and Communications Workshops (PERCOM Workshops), Mannheim, Germany, 29 March–2 April 2010; pp. 800–803. [Google Scholar]
- Alshawki, M.B.; Ligeti, P.; Reich, C. Private/Public Resource Discovery for IoT: A Two-Layer Decentralized Model. In Proceedings of the 12th Conference of PhD Students in Computer Science, SZTE, Szeged, Hungary, 24–26 June 2020. [Google Scholar]
- Pahl, M.; Stefan, L. A Modular Distributed IoT Service Discovery. In Proceedings of the IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Arlington, VA, USA, 8–12 April 2019; pp. 448–454. [Google Scholar]
- Pahl, M. Distributed Smart Space Orchestration. Ph.D. Thesis, Technische Universität München, München, Germany, 2014. [Google Scholar]
- Guo, R.; Shi, H.; Zheng, D.; Jing, C.; Zhuang, C.; Wang, Z. Flexible and efficient blockchain-based ABE scheme with multi-authority for medical on demand in telemedicine system. IEEE Access 2019, 7, 88012–88025. [Google Scholar] [CrossRef]
- Trabelsi, Y.S.; Roudier, Y. Enabling Secure Service Discovery with Attribute Based Encryption; Institut Eurecom Department of Corporate Communications: Sophia Antipolis, France, 2006; p. 19. [Google Scholar]
- Wang, W.; Qi, F.; Wu, X.; Tang, Z. Distributed multi-authority attribute-based encryption scheme for friend discovery in mobile social networks. Procedia Comput. Sci. 2016, 80, 617–626. [Google Scholar] [CrossRef]
- Yan, Y.; Alshawki, M.B.; Ligeti, P. Attribute-based Encryption in Cloud Computing Environment. In Proceedings of the 2020 International Conference on Computing, Electronics & Communications Engineering (iCCECE), Southend, UK, 17–18 August 2020; pp. 63–68. [Google Scholar]
- Bellare, M.; Waters, B.; Yilek, S. Identity-Based Encryption Secure against Selective Opening Attack. In Proceedings of the 8th Theory of Cryptography Conference, Providence, RI, USA, 28–30 March 2011; pp. 235–252. [Google Scholar]
- Maurer, W.D.; Lewis, T.G. Hash table methods. ACM Comput. Surv. CSUR 1975, 7, 5–19. [Google Scholar] [CrossRef]
- Stoica, I.; Morris, R.; Karger, D.; Kaashoek, M.F.; Balakrishnan, H. Chord: A scalable peer-to-peer lookup service for internet applications. ACM Sigcomm Comput. Commun. Rev. 2001, 31, 149–160. [Google Scholar] [CrossRef]
- Rowstron, A.; Druschel, P. Pastry: Scalable, decentralized object location, and routing for large-scale peer-to-peer systems. In Proceedings of the IFIP/ACM International Conference on Distributed Systems Platforms and Open Distributed Processing, Heidelberg, Germany, 12–16 November 2001; pp. 329–350. [Google Scholar]
- Zhao, B.Y.; Huang, L.; Stribling, J.; Rhea, S.C.; Joseph, A.D.; Kubiatowicz, J.D. Tapestry: A resilient global-scale overlay for service deployment. IEEE J. Sel. Areas Commun. 2004, 22, 41–53. [Google Scholar] [CrossRef]
- Woungang, I.; Tseng, F.; Lin, Y.; Chou, L.; Chao, H.; Obaidat, M.S. MR-Chord: Improved chord lookup performance in structured mobile P2P networks. IEEE Syst. J. 2014, 20, 743–751. [Google Scholar] [CrossRef]
- Alshawki, M.B.; Ligeti, P.; Reich, C. Region-Based Distributed Hash Table for Fog Computing Infrastructure. In Proceedings of the 13th Joint Conference on Mathematics and Informatics, Budapest, Hungary, 1–3 October 2020; pp. 82–83. [Google Scholar]
- Pattar, S.; Buyya, R.; Venugopal, K.; Iyengar, S.; Patnaik, L. Searching for the IoT resources: Fundamentals, requirements, comprehensive review, and future directions. IEEE Commun. Surv. Tutor. 2018, 20, 2101–2132. [Google Scholar] [CrossRef]
- Sahai, A.; Waters, B. Fuzzy identity-based encryption. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Aarhus, Denmark, 22–26 May 2005; pp. 457–473. [Google Scholar]
- Goyal, V.; Pandey, O.; Sahai, A.; Waters, B. Attribute-based encryption for fine-grained access control of encrypted data. In Proceedings of the 13th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 30 October–3 November 2006; pp. 89–98. [Google Scholar]
- Bethencourt, J.; Sahai, A.; Waters, B. Ciphertext-policy attribute-based encryption. In Proceedings of the 2007 IEEE Symposium on Security and Privacy (SP’07), Berkeley, CA, USA, 20–23 May 2007; pp. 321–334. [Google Scholar]
- Chase, M. Multi-authority attribute based encryption. In Proceedings of the Theory of Cryptography Conference, Amsterdam, The Netherlands, 21–24 February 2007; pp. 515–534. [Google Scholar]
- Lewko, A.; Waters, B. Decentralizing attribute-based encryption. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Tallinn, Estonia, 15–19 May 2011; pp. 568–588. [Google Scholar]
- Dhara, K.; Guo, Y.; Kolberg, M.; Wu, X. Overview of Structured Peer-to-Peer Overlay Algorithms. In Handbook of Peer-to-Peer Networking; Springer: New York, NY, USA, 2010; pp. 223–256. [Google Scholar]
- Alshawki, M.B.; Ligeti, P.; Nagy, A.; Reich, C. Distributed Address Table (DAT): A Decentralized Model for End-to-End Communication in IoT. J. P2p Netw. Appl. 2021. to appear. [Google Scholar]
- Yang, Y.; Zhang, X.; Yu, J.; Zhang, P. Research on the hash function structures and its application. Wirel. Pers. Commun. 2017, 94, 2969–2985. [Google Scholar] [CrossRef]
- Horalek, J.; Holík, F.; Horák, O.; Petr, L.; Sobeslav, V. Analysis of the use of Rainbow Tables to break hash. J. Intell. Fuzzy Syst. 2017, 32, 1523–1534. [Google Scholar] [CrossRef]
- Montresor, A.; Jelasity, M. PeerSim: A Scalable P2P Simulator. In Proceedings of the IEEE Ninth International Conference on Peer-to-Peer Computing, Seattle, WA, USA, 9–11 September 2009; pp. 99–100. [Google Scholar]
- Jimenez, R.; Osmani, F.; Knutsson, B. Sub-second lookups on a large-scale Kademlia-based overlay. In Proceedings of the IEEE International Conference on Peer-to-Peer Computing, Kyoto, Japan, 31 August–2 September 2011; pp. 82–91. [Google Scholar]
- Roos, S.; Salah, H.; Strufe, T. On the Routing of Kademlia-type Systems; Advances in Computer Communications and Networks; River Publishers: Delft, The Netherlands, 2017. [Google Scholar]
- Ambrosin, M.; Anzanpour, A.; Conti, M.; Dargahi, T.; Moosavi, S.; Rahmani, A.M.; Liljeberg, P. On the feasibility of attribute-based encryption on internet of things devices. IEEE Micro 2016, 36, 25–35. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Decentralized | Location Aware Overlay | Multi Attributes | Security Considerations | Controlled Discovery |
|---|---|---|---|---|---|
| Jara et al. [2] | ✗ | ✗ | ✓ | ✗ | ✗ |
| Jia et al. [3] | ✗ | ✗ | ✓ | ✗ | ✗ |
| Cheshire et al. [4] | ✗ | ✗ | ✓ | ✓ | ✗ |
| Mokadem et al. [5] | ✓ | ✗ | ✗ | ✗ | ✗ |
| Paganelli et al. [6] | ✓ | ✗ | ✓ | ✗ | ✗ |
| Cirani et al. [7] | ✓ | ✓ | ✗ | ✗ | ✗ |
| Tanganelli et al. [9] | ✓ | ✗ | ✓ | ✗ | ✗ |
| Cabrera et al. [11] | ✓ | ✓ | ✓ | ✗ | ✗ |
| Kamel et al. [8] | ✓ | ✗ | ✓ | ✓ | ✗ |
| Pahl et al. [20] | ✓ | ✗ | ✓ | ✓ | ✓ |
| Trabelsi et al. [23] | ✓ | ✗ | ✓ | ✓ | ✓ |
| Kamel et al. [10] | ✓ | ✗ | ✓ | ✓ | ✓ |
| Wang et al. [24] | ✗ | ✗ | ✓ | ✓ | ✓ |
| Attred | ✓ | ✓ | ✓ | ✓ | ✓ |
| Type | Parameter |
|---|---|
| local connection latency | 2 ms |
| sub-regional latency (local region) | 3–8 ms |
| intra-regional latency (region set) | 10–30 ms |
| long distance latency | 80–120 ms |
| Model | Approach | Properties |
|---|---|---|
| Jia et al. [3] | Centralized Resource Discovery | direct matching |
| Cirani et al. [7] | Location based discovery | 5 hops |
| Tanganelli et al. [9] | Fog based discovery | 100 nodes |
| Pahl et al. [20] | Modular discovery | 4 predicates/search providers |
| Attred | Region discovery | 10,000 nodes |
| Number of Attributes | Local Execution Time (ms) | Distributed Execution Time (ms) | Improvement (%) | |
|---|---|---|---|---|
| IoT Gateway | Computational Nodes | |||
| 1 | 280 | 94 | 5 | 64.6 |
| 2 | 403 | 128 | 11 | 65.5 |
| 3 | 599 | 139 | 19 | 73.6 |
| 4 | 710 | 154 | 25 | 74.8 |
| 5 | 898 | 171 | 33 | 77.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alshawki, M.B.; Yan, Y.; Ligeti, P.; Reich, C. Attred: Attribute Based Resource Discovery for IoT. Sensors 2021, 21, 4721. https://doi.org/10.3390/s21144721
Alshawki MB, Yan Y, Ligeti P, Reich C. Attred: Attribute Based Resource Discovery for IoT. Sensors. 2021; 21(14):4721. https://doi.org/10.3390/s21144721
Chicago/Turabian StyleAlshawki, Mohammed B., Yuping Yan, Peter Ligeti, and Christoph Reich. 2021. "Attred: Attribute Based Resource Discovery for IoT" Sensors 21, no. 14: 4721. https://doi.org/10.3390/s21144721
APA StyleAlshawki, M. B., Yan, Y., Ligeti, P., & Reich, C. (2021). Attred: Attribute Based Resource Discovery for IoT. Sensors, 21(14), 4721. https://doi.org/10.3390/s21144721