
Efficient Graph Collaborative Filtering via Contrastive Learning


Abstract
:1. Introduction
- We propose an Efficient Graph Collaborative Filtering (EGCF) method, which simplifies the GNN-based CF methods by preserving merely one-layer graph convolution to propagate collaborative information for improving the computational efficiency;
- We introduce constrastive learning into graph collaborative filtering to enhance the representation learning of users and items and take the high-order connectivity between users and items into consideration;
- Comprehensive experiments conducted on two benchmark datasets, i.e., Yelp2018 and Amazon-book, demonstrate that EGCF can achieve the state-of-the-art performance in terms of Recall and NDCG.
2. Related Work
2.1. Collaborative Filtering
2.2. Contrastive Learning
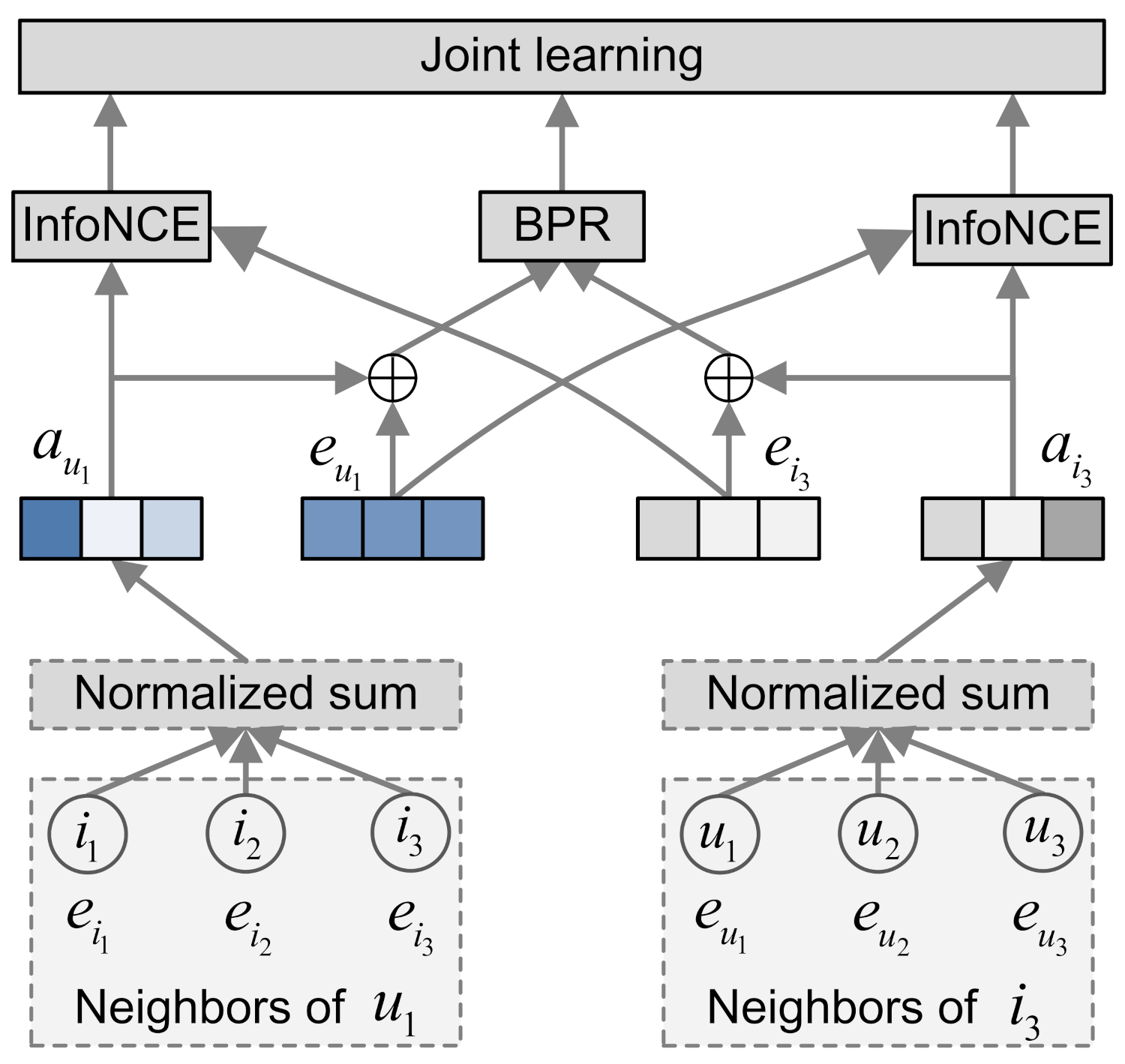
3. Approach
3.1. Graph Convolution
3.2. Supervised and Contrastive Learning
3.2.1. Supervised Learning
3.2.2. Contrastive Learning
3.3. Joint Learning
| Algorithm 1. Learning algorithm of EGCF. |
|
3.4. Model Complexity Analysis
- Adjacency matrix normalization. After constructing the adjacent matrix of the user–item bipartite graph, the weights need to be normalized, which consumes a complexity of , where is the interaction number;
- Graph convolution. Let s and B denote the number of epochs and the size of each training mini-batch, then the complexity of the graph convolution is for LightGCN while for EGCF since we reduce the layer number of graph convolution to 1;
- Supervised loss. As for the supervised loss produced by Equation (4), LightGCN and EGCF share the same complexity, i.e., ;
- Contrastive loss. Compared with LightGCN, the additional complexity of contrastive loss in EGCF can be denoted as , which comes from the item side and the user side , respectively.
4. Experiments
4.1. Research Questions
- (RQ1)
- Can our proposed EGCF outperform the competitive baselines on the collaborative filtering task?
- (RQ2)
- How is the training efficiency of EGCF compared with the state-of-the-art baseline LightGCN?
- (RQ3)
- How does each component in EGCF contribute to the recommendation accuracy of EGCF?
- (RQ4)
- What is the impact of the trade-off parameters including and on the performance of EGCF?
4.2. Datasets and Evaluation Metrics
4.3. Model Summary
- MF [8] utilizes the matrix factorization to exploit the user–item interactions and the BPR loss to optimize the model parameters, where users and items are simply represented by their corresponding IDs.
- Multi-VAE [32] is an item-based CF method relying on the variational autoencoder (VAE). Here it is assumed that the data is generated from the multinomial distribution and the parameters are estimated by the variational inference.
- NGCF [2] models the collaborative signal in the user–item interactions by exploiting the high-order connectivity between users and items using multi-layer GCNs.
- DGCF [21] introduces the disentangled learning into graph collaborative filtering to consider user’s diverse interests, which proposes the intent-aware interaction graph to model the distribution over multi intents for each user–item interaction.
- LightGCN [11] simplifies NGCF by removing the feature transformation and nonlinear functions in GCN and preserving the most essential component, i.e., neighborhood aggregation for collaborative filtering.
4.4. Experimental Setup
5. Results and Discussion
5.1. Overall Performance
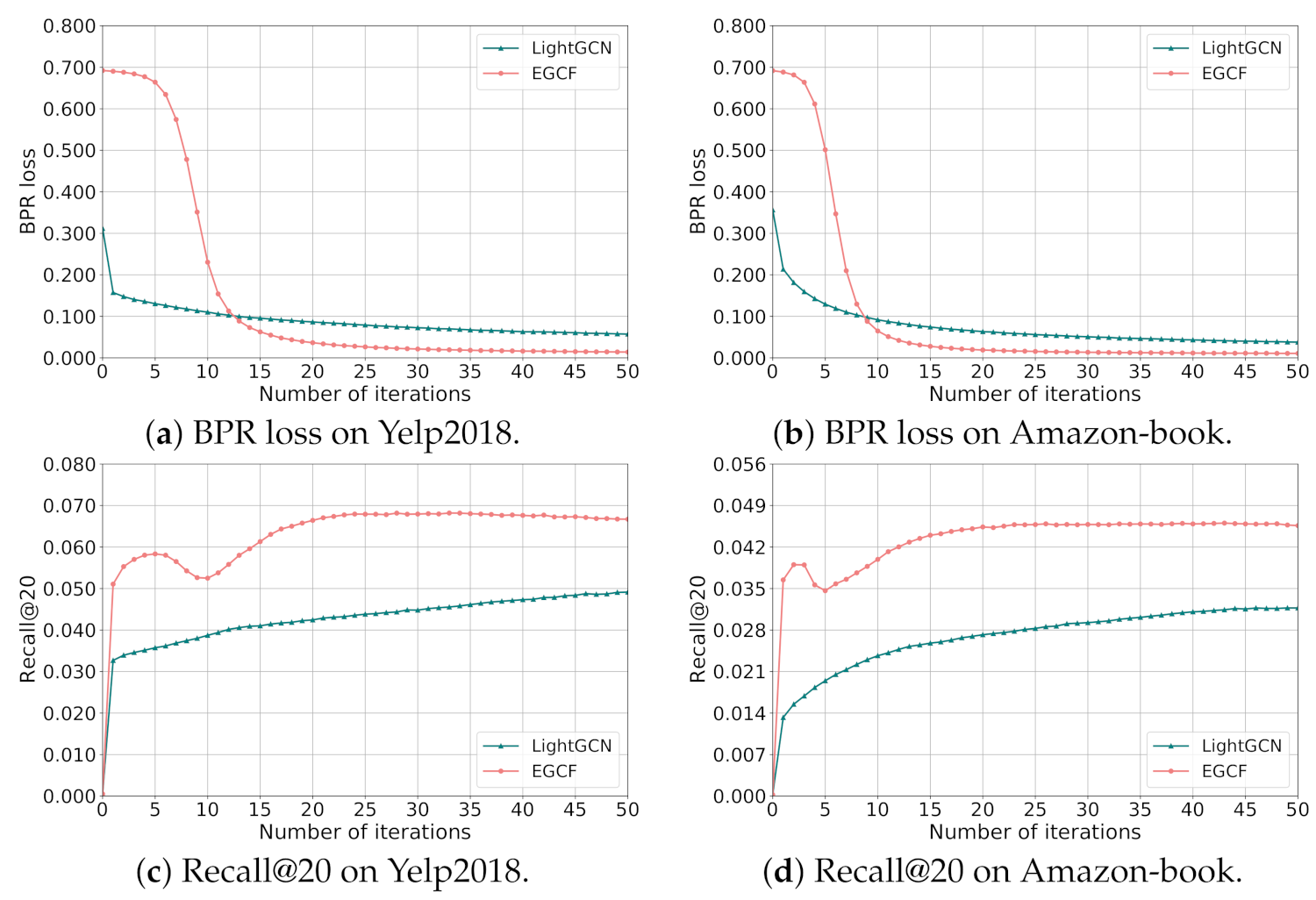
5.2. Training Efficiency
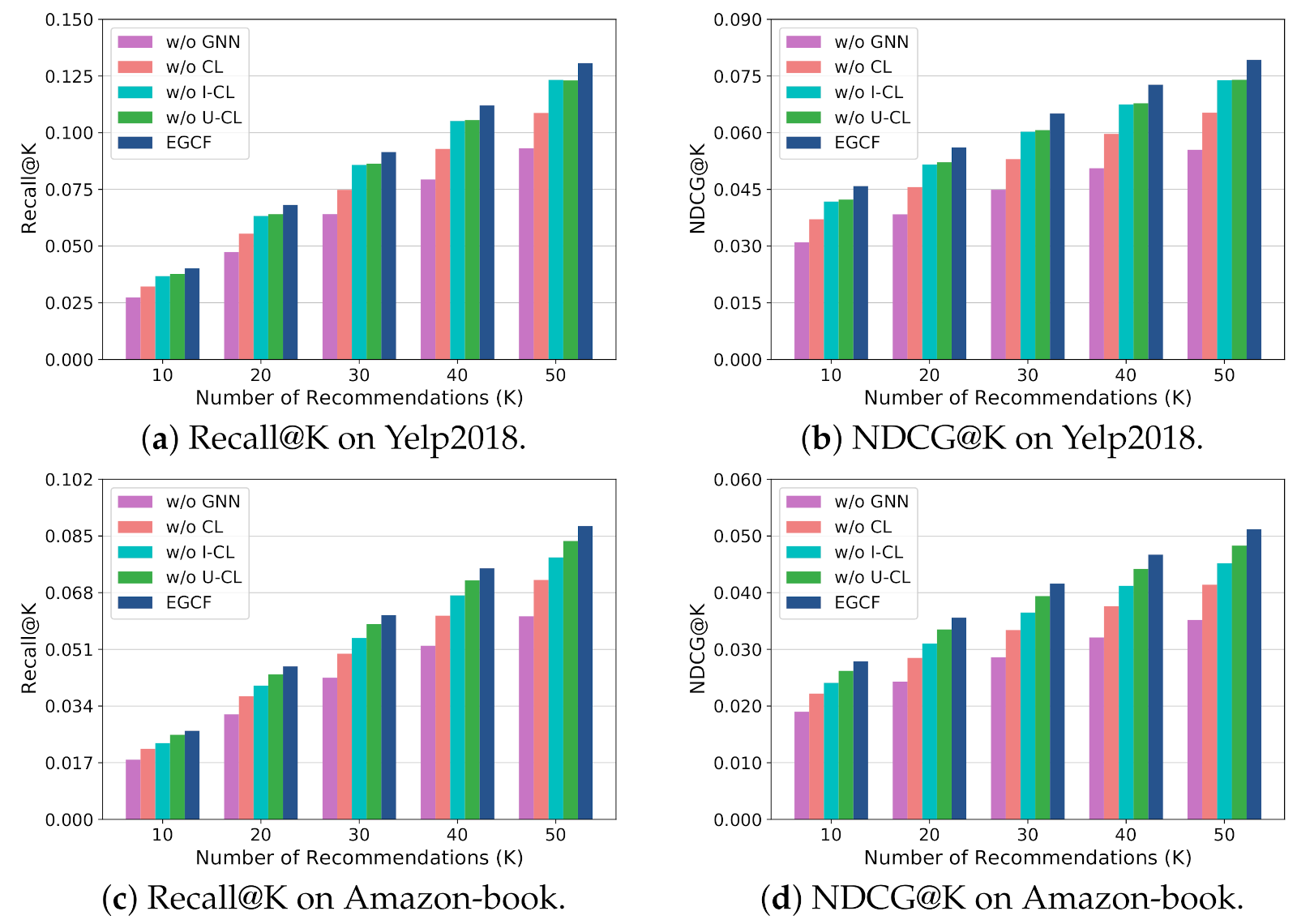
5.3. Ablation Study
- w/o CL removes the contrastive loss obtained by Equation (7) from EGCF.
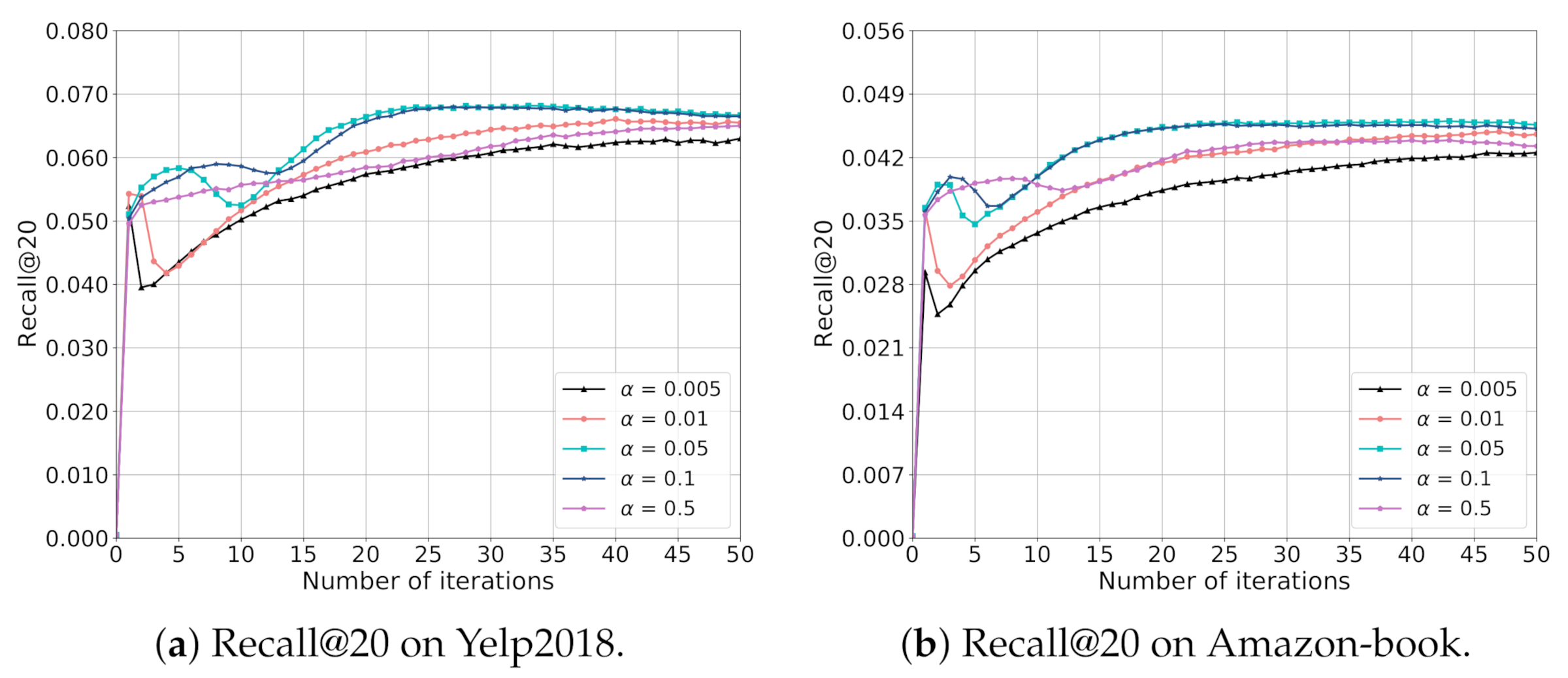
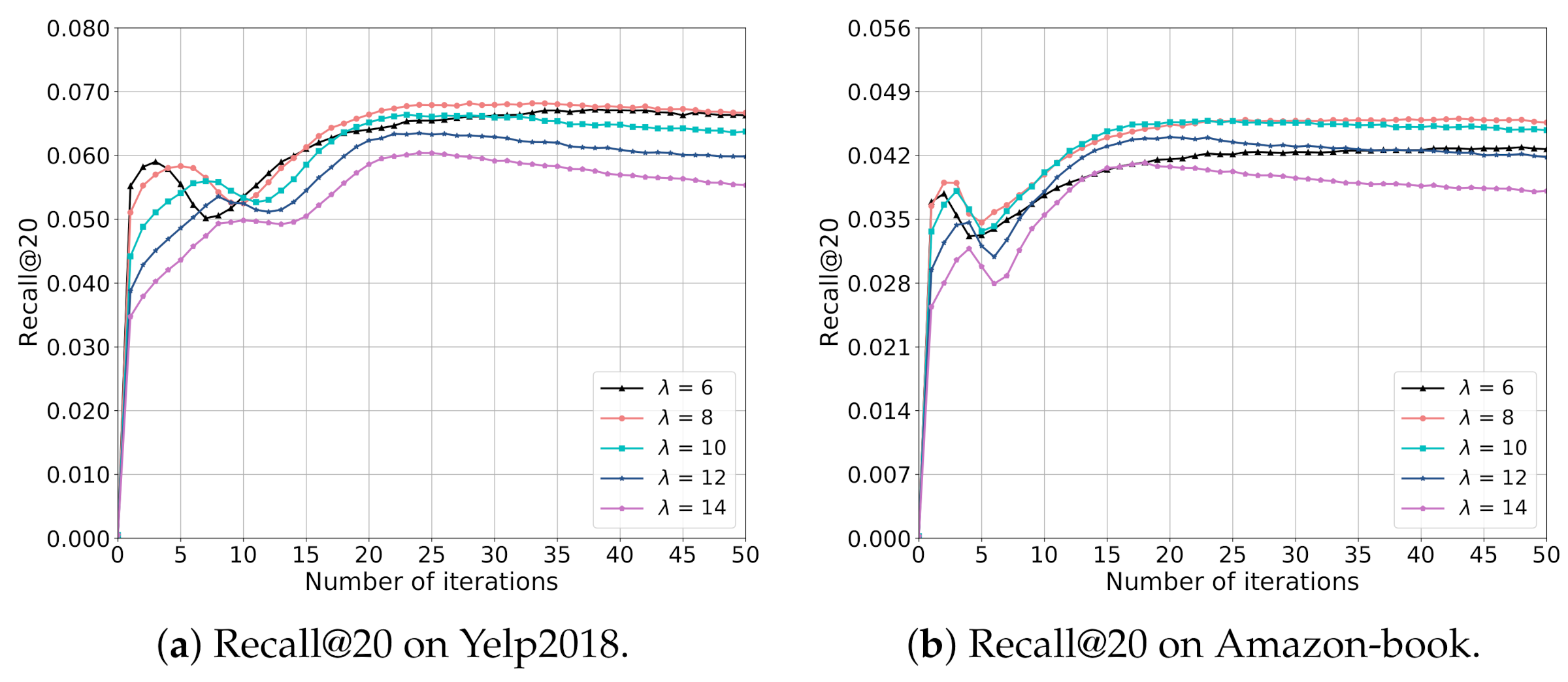
5.4. Hyper-Parameter Analysis
5.4.1. Impact of Parameter
5.4.2. Impact of Parameter
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T. Neural Collaborative Filtering. In Proceedings of the International World Wide Web Conference (WWW’17), Perth, Australia, 3–7 April 2017; ACM: New York, NY, USA, 2017; pp. 173–182. [Google Scholar]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T. Neural Graph Collaborative Filtering. In Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’19), Paris, France, 21–25 July 2019; ACM: New York, NY, USA, 2019; pp. 165–174. [Google Scholar]
- Song, X.; Guo, Y.; Chang, Y.; Zhang, F.; Tan, J.; Yang, J.; Shi, X. A Hybrid Recommendation System for Marine Science Observation Data Based on Content and Literature Filtering. Sensors 2020, 20, 6414. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep Learning Based Recommender System: A Survey and New Perspectives. ACM Comput. Surv. 2019, 52, 5:1–5:38. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Hu, L.; Wang, Y.; Cao, L.; Sheng, Q.Z.; Orgun, M.A. Sequential Recommender Systems: Challenges, Progress and Prospects. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI’19), Macao, China, 10–16 August 2019; pp. 6332–6338. [Google Scholar]
- Kuang, L.; Yu, L.; Huang, L.; Wang, Y.; Ma, P.; Li, C.; Zhu, Y. A Personalized QoS Prediction Approach for CPS Service Recommendation Based on Reputation and Location-Aware Collaborative Filtering. Sensors 2018, 18, 1556. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, T.Y.; Ko, H.; Kim, S.H.; Kim, H.D. Modeling of Recommendation System Based on Emotional Information and Collaborative Filtering. Sensors 2021, 21, 1997. [Google Scholar] [CrossRef] [PubMed]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian Personalized Ranking from Implicit Feedback. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence (UAI’09), Montreal, QC, Canada, 18–21 June 2009; pp. 452–461. [Google Scholar]
- Kabbur, S.; Ning, X.; Karypis, G. FISM: Factored item similarity models for top-N recommender systems. In Proceedings of the International Conference on Knowledge Discovery and Data Mining (KDD’13), Chicago, IL, USA, 11–14 August 2013; ACM: New York, NY, USA, 2013; pp. 659–667. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations (ICLR’17), Toulon, France, 24–26 April 2017. [Google Scholar]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. In Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’20), Xi’an, China, 25–30 July 2020; ACM: New York, NY, USA, 2020; pp. 639–648. [Google Scholar]
- Wang, X.; Huang, T.; Wang, D.; Yuan, Y.; Liu, Z.; He, X.; Chua, T. Learning Intents behind Interactions with Knowledge Graph for Recommendation. In Proceedings of the Web Conference 2021 (WWW’21), Ljubljana, Slovenia, 19–23 April 2021; ACM: New York, NY, USA, 2021; pp. 878–887. [Google Scholar]
- van den Oord, A.; Li, Y.; Vinyals, O. Representation Learning with Contrastive Predictive Coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Rao, N.; Yu, H.; Ravikumar, P.; Dhillon, I.S. Collaborative Filtering with Graph Information: Consistency and Scalable Methods. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS’15), Montreal, QC, Canada, 7–12 December 2015; pp. 2107–2115. [Google Scholar]
- Tay, Y.; Tuan, L.A.; Hui, S.C. Latent Relational Metric Learning via Memory-based Attention for Collaborative Ranking. In Proceedings of the International World Wide Web Conference (WWW’18), Lyon, France, 23–27 April 2018; ACM: New York, NY, USA, 2018; pp. 729–739. [Google Scholar]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the International Conference on Knowledge Discovery and Data Mining (KDD’08), Las Vegas, NV, USA, 24–27 August 2008; ACM: New York, NY, USA, 2008; pp. 426–434. [Google Scholar]
- Chen, J.; Zhang, H.; He, X.; Nie, L.; Liu, W.; Chua, T. Attentive Collaborative Filtering: Multimedia Recommendation with Item- and Component-Level Attention. In Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’17), Tokyo, Japan, 7–11 August 2017; ACM: New York, NY, USA, 2017; pp. 335–344. [Google Scholar]
- He, X.; He, Z.; Song, J.; Liu, Z.; Jiang, Y.; Chua, T. NAIS: Neural Attentive Item Similarity Model for Recommendation. IEEE Trans. Knowl. Data Eng. 2018, 30, 2354–2366. [Google Scholar] [CrossRef] [Green Version]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations (ICLR’18), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wu, F.; Souza, A.H., Jr.; Zhang, T.; Fifty, C.; Yu, T.; Weinberger, K.Q. Simplifying Graph Convolutional Networks. In Proceedings of the 36th International Conference on Machine Learning (ICML’19), Long Beach, CA, USA, 9–15 June 2019; pp. 6861–6871. [Google Scholar]
- Wang, X.; Jin, H.; Zhang, A.; He, X.; Xu, T.; Chua, T. Disentangled Graph Collaborative Filtering. In Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’20), Xi’an, China, 25–30 July 2020; ACM: New York, NY, USA, 2020; pp. 1001–1010. [Google Scholar]
- Wu, Z.; Xiong, Y.; Yu, S.X.; Lin, D. Unsupervised Feature Learning via Non-Parametric Instance Discrimination. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR’18), CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3733–3742. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G.E. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning (ICML’20), Vienna, Austria, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R.B. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR’20), Seattle, WA, USA, 13–19 June 2020; pp. 9726–9735. [Google Scholar]
- Logeswaran, L.; Lee, H. An efficient framework for learning sentence representations. In Proceedings of the International Conference on Learning Representations (ICLR’18), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Joshi, M.; Chen, D.; Liu, Y.; Weld, D.S.; Zettlemoyer, L.; Levy, O. SpanBERT: Improving Pre-training by Representing and Predicting Spans. Trans. Assoc. Comput. Linguist. 2020, 8, 64–77. [Google Scholar] [CrossRef]
- Zhou, K.; Wang, H.; Zhao, W.X.; Zhu, Y.; Wang, S.; Zhang, F.; Wang, Z.; Wen, J. S3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization. In Proceedings of the 29th ACM International Conference on Information and Knowledge Management (CIKM’20), Galway, Ireland, 19–23 October 2020; ACM: New York, NY, USA, 2020; pp. 1893–1902. [Google Scholar]
- Xie, X.; Sun, F.; Liu, Z.; Gao, J.; Ding, B.; Cui, B. Contrastive Pre-training for Sequential Recommendation. arXiv 2020, arXiv:2010.14395. [Google Scholar]
- Ma, J.; Zhou, C.; Yang, H.; Cui, P.; Wang, X.; Zhu, W. Disentangled Self-Supervision in Sequential Recommenders. In Proceedings of the International Conference on Knowledge Discovery and Data Mining (KDD’20), San Diego, CA, USA, 23–27 August 2020; ACM: New York, NY, USA, 2020; pp. 483–491. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- He, R.; McAuley, J.J. VBPR: Visual Bayesian Personalized Ranking from Implicit Feedback. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI’16), Phoenix, AZ, USA, 12–17 February 2016; pp. 144–150. [Google Scholar]
- Liang, D.; Krishnan, R.G.; Hoffman, M.D.; Jebara, T. Variational Autoencoders for Collaborative Filtering. In Proceedings of the International World Wide Web Conference (WWW’18), Lyon, France, 23–27 April 2018; ACM: New York, NY, USA, 2018; pp. 689–698. [Google Scholar]
- van den Berg, R.; Kipf, T.N.; Welling, M. Graph Convolutional Matrix Completion. arXiv 2017, arXiv:1706.02263. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics (AISTATS’10), Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR’15), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Wang, F.; Xiang, X.; Cheng, J.; Yuille, A.L. NormFace: L2 Hypersphere Embedding for Face Verification. In Proceedings of the International Conference on Multimedia (MM’17), Mountain View, CA, USA, 23–27 October 2017; ACM: New York, NY, USA, 2017; pp. 1041–1049. [Google Scholar]
- Chen, C.; Zhang, M.; Zhang, Y.; Ma, W.; Liu, Y.; Ma, S. Efficient Heterogeneous Collaborative Filtering without Negative Sampling for Recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI’20), New York, NY, USA, 7–12 February 2020; pp. 19–26. [Google Scholar]
- Chen, C.; Zhang, M.; Zhang, Y.; Liu, Y.; Ma, S. Efficient Neural Matrix Factorization without Sampling for Recommendation. ACM Trans. Inf. Syst. 2020, 38, 14:1–14:28. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Zhang, F.; Wang, J.; Zhao, M.; Li, W.; Xie, X.; Guo, M. RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management (CIKM’18), Torino, Italy, 22–26 October 2018; ACM: New York, NY, USA, 2018; pp. 417–426. [Google Scholar]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T. KGAT: Knowledge Graph Attention Network for Recommendation. In Proceedings of the International Conference on Knowledge Discovery & Data Mining (KDD’19), Anchorage, AK, USA, 4–8 August 2019; ACM: New York, NY, USA, 2019; pp. 950–958. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| the user set containing all users | |
| the item set containing all items | |
| the observed interactions between and | |
| d | the dimension of the user and item embeddings |
| the user–item bipartite graph constructed from | |
| the initial item embeddings of nodes in | |
| the item representations of nodes in learnt by SGCN | |
| the neighbors of user u and item i in the bipartite graph | |
| the propagated information for user u and item i | |
| the prediction score of user u on item i | |
| the supervised Bayesian personalized ranking loss | |
| the trade-off parameter for scaling the cosine similarity | |
| the item-side, user-side and combined contrastive loss | |
| the trade-off parameter for balancing and | |
| the combined loss for joint learning | |
| L | the layer number of GNNs |
| s | the number of training epochs for model optimization |
| B | the size of each training mini-batch |
| K | the number of items recommended to the user |
| Component | LightGCN | EGCF |
|---|---|---|
| Adjacency Matrix | ||
| Graph Convolution | ||
| Supervised Loss | ||
| Contrastive Loss | - |
| Dataset | #Users | #Items | #Interactions | #Density |
|---|---|---|---|---|
| Yelp2018 | 31,668 | 38,048 | 1,561,406 | 0.00130 |
| Amazon-book | 52,643 | 91,599 | 2,984,108 | 0.00062 |
| Method | Yelp2018 | Amazon-Book | ||
|---|---|---|---|---|
| Recall@20 | NDCG@20 | Recall@20 | NDCG@20 | |
| MF | 0.0433 | 0.0354 | 0.0250 | 0.0196 |
| GRMF | 0.0571 | 0.0462 | 0.0354 | 0.0270 |
| Mult-VAE | 0.0584 | 0.0450 | 0.0407 | 0.0315 |
| GC-MC | 0.0462 | 0.0379 | 0.0288 | 0.0224 |
| NGCF | 0.0579 | 0.0477 | 0.0344 | 0.0263 |
| DGCF | 0.0640 | 0.0522 | 0.0399 | 0.0308 |
| LightGCN | 0.0641 | 0.0525 | 0.0411 | 0.0315 |
| EGCF | 0.0682 | 0.0561 | 0.0459 | 0.0356 |
| Method | Yelp2018 | Amazon-Book | ||||
|---|---|---|---|---|---|---|
| S | I | T | S | I | T | |
| LightGCN | 22.19 s | 720 | 266.28 m | 85.07 s | 700 | 992.48 m |
| EGCF | 10.11 s | 633 | 665.56 m | 34.97 s | 626 | 615.15 m |
| Recall@20 | |||||
|---|---|---|---|---|---|
| = 0.005 | 0.0512 | 0.0524 | 0.0524 | 0.0643 | 0.0637 |
| = 0.01 | 0.0536 | 0.0543 | 0.0549 | 0.0652 | 0.0637 |
| = 0.05 | 0.0590 | 0.0682 | 0.0664 | 0.0635 | 0.0604 |
| = 0.1 | 0.0679 | 0.0680 | 0.0652 | 0.0614 | 0.0576 |
| = 0.5 | 0.0665 | 0.0650 | 0.0603 | 0.0554 | 0.0507 |
| NDCG@20 | |||||
| = 0.005 | 0.0413 | 0.0428 | 0.0429 | 0.0526 | 0.0523 |
| = 0.01 | 0.0440 | 0.0445 | 0.0451 | 0.0535 | 0.0524 |
| = 0.05 | 0.0484 | 0.0561 | 0.0545 | 0.0523 | 0.0497 |
| = 0.1 | 0.0552 | 0.0559 | 0.0539 | 0.0508 | 0.0474 |
| = 0.5 | 0.0544 | 0.0534 | 0.0496 | 0.0458 | 0.0420 |
| Recall@20 | |||||
|---|---|---|---|---|---|
| = 0.005 | 0.0420 | 0.0436 | 0.0447 | 0.0446 | 0.0432 |
| = 0.01 | 0.0424 | 0.0450 | 0.0460 | 0.0451 | 0.0433 |
| = 0.05 | 0.0429 | 0.0459 | 0.0458 | 0.0440 | 0.0412 |
| = 0.1 | 0.0428 | 0.0457 | 0.0454 | 0.0429 | 0.0399 |
| = 0.5 | 0.0391 | 0.0439 | 0.0425 | 0.0391 | 0.0350 |
| NDCG@20 | |||||
| = 0.005 | 0.0324 | 0.0336 | 0.0347 | 0.0344 | 0.0335 |
| = 0.01 | 0.0327 | 0.0348 | 0.0356 | 0.0349 | 0.0337 |
| = 0.05 | 0.0332 | 0.0357 | 0.0356 | 0.0342 | 0.0320 |
| = 0.1 | 0.0332 | 0.0353 | 0.0352 | 0.0334 | 0.0310 |
| = 0.5 | 0.0310 | 0.0337 | 0.0328 | 0.0304 | 0.0274 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, Z.; Chen, H. Efficient Graph Collaborative Filtering via Contrastive Learning. Sensors 2021, 21, 4666. https://doi.org/10.3390/s21144666
Pan Z, Chen H. Efficient Graph Collaborative Filtering via Contrastive Learning. Sensors. 2021; 21(14):4666. https://doi.org/10.3390/s21144666
Chicago/Turabian StylePan, Zhiqiang, and Honghui Chen. 2021. "Efficient Graph Collaborative Filtering via Contrastive Learning" Sensors 21, no. 14: 4666. https://doi.org/10.3390/s21144666
APA StylePan, Z., & Chen, H. (2021). Efficient Graph Collaborative Filtering via Contrastive Learning. Sensors, 21(14), 4666. https://doi.org/10.3390/s21144666