
Ambient Healthcare Approach with Hybrid Whale Optimization Algorithm and Naïve Bayes Classifier

 ,
,  ,
, 
 , and
, and 
Abstract
:1. Introduction
- The massive collected data storage;
- Eliminate privacy and security leakage at a different platform level;
- Energy management with continuous monitoring leads to an increase in data volume and analytical demands;
- Deliver the information at the proper time and in a reliable manner;
- Heterogeneity: the diversity of the connected things;
- High dynamics: the dynamic global network infrastructure;
- Quality of Service (QoS) supports both QoS and functional properties concerning a Service-Level Agreement (SLA).
2. Related Work
2.1. Healthcare Architectures
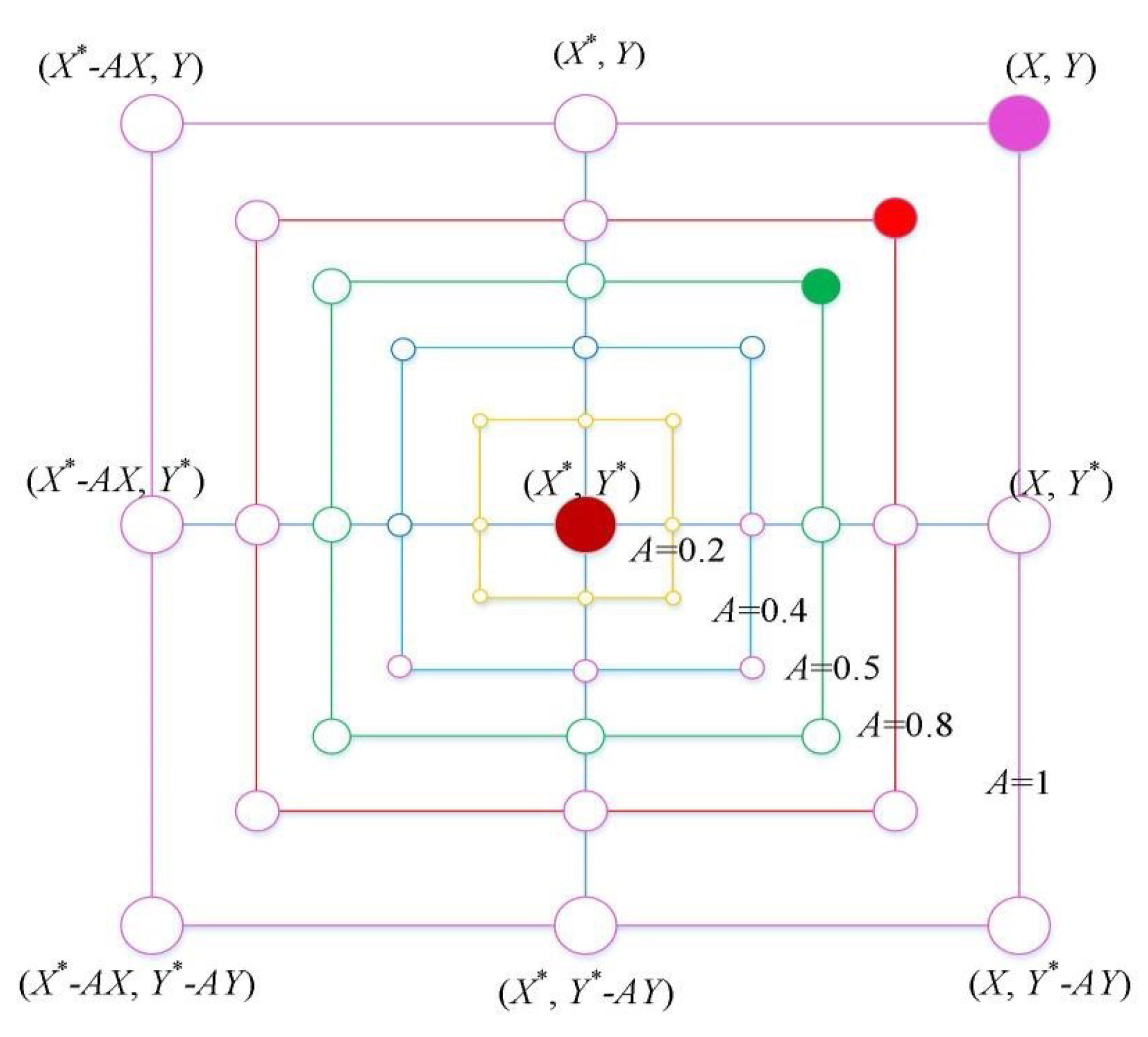
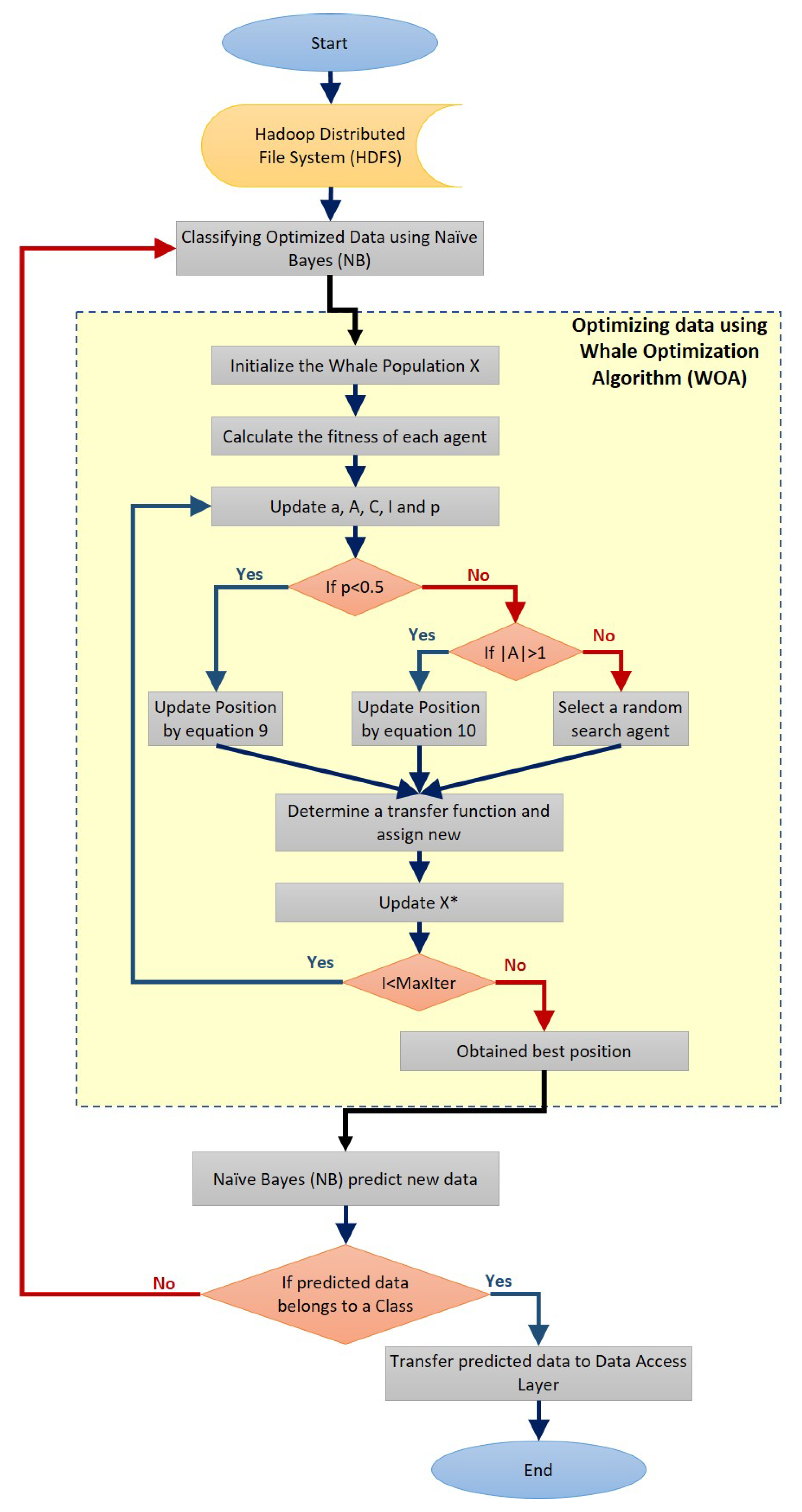
2.2. Whale Optimization Algorithm
| Algorithm 1: The WOA |
 |
2.3. Naïve Bayes Algorithm
- : the posterior probability of class (c, target) given predictor (x, attributes).
- : the prior probability of class.
- : the likelihood which is the probability of the predictor given class.
- : the prior probability of the predictor.
3. Methods
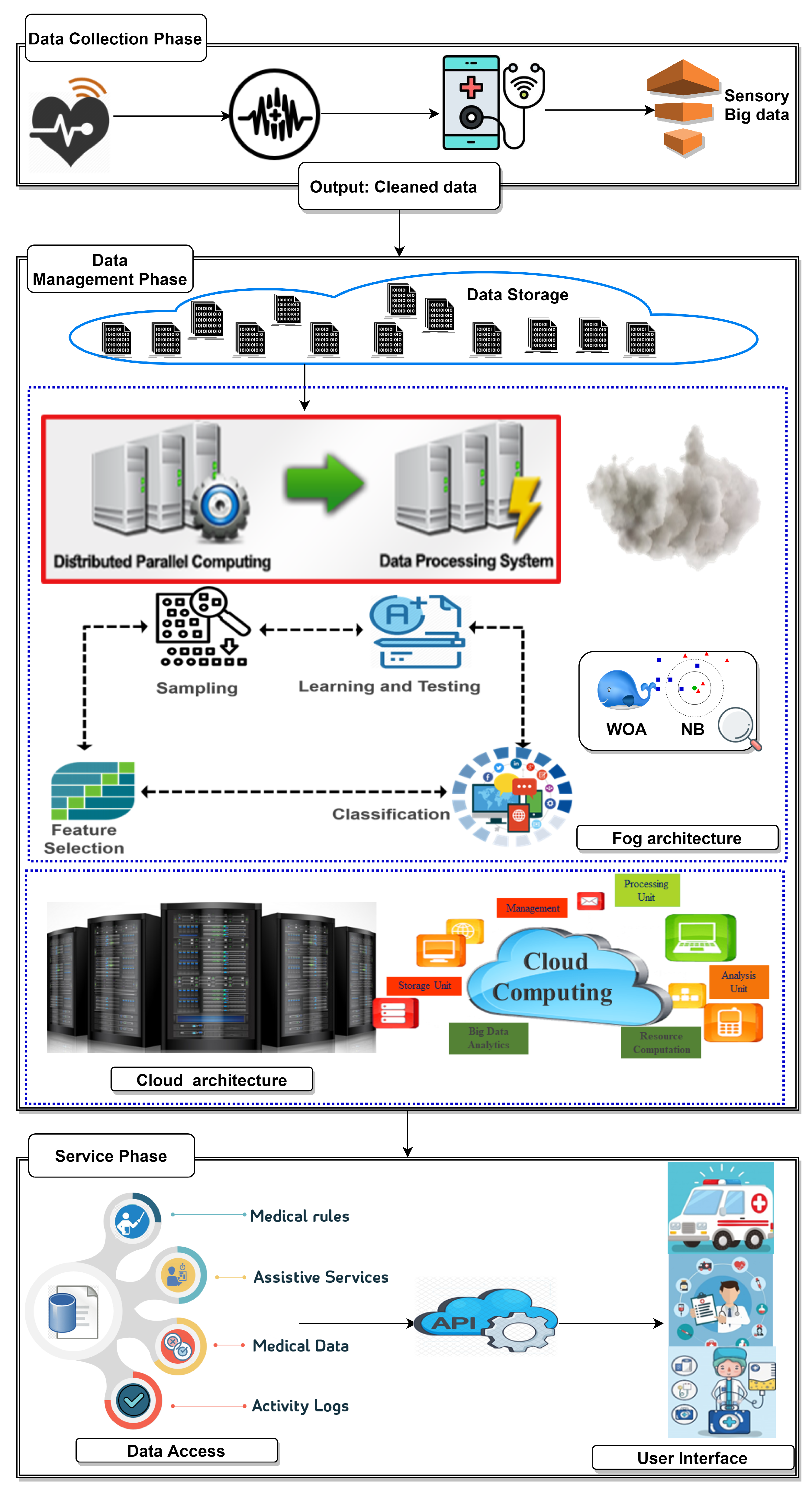
3.1. The Ambient Intelligent Healthcare Approach
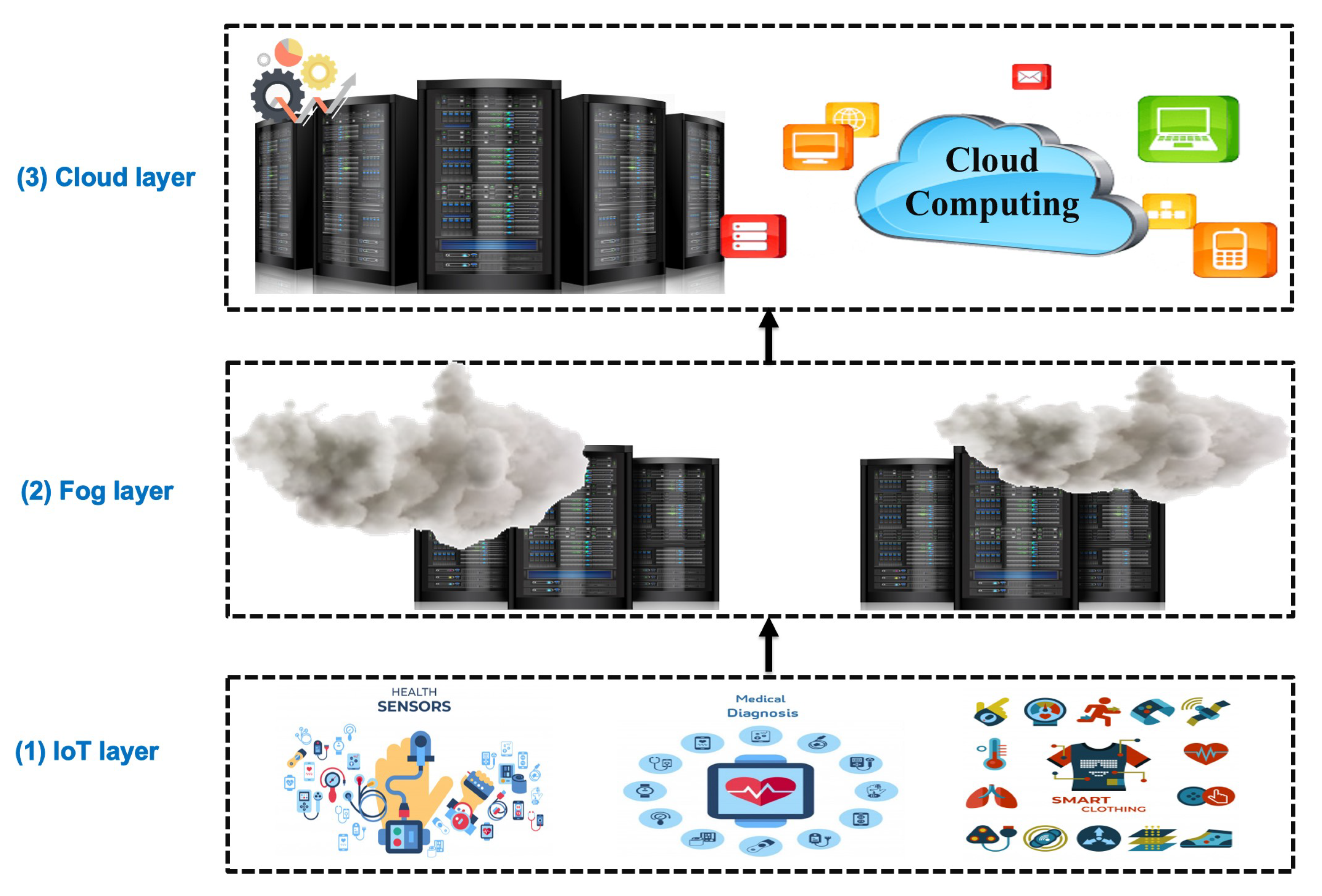
3.1.1. The Data Collection Phase
3.1.2. The Data Management Phase
- F denotes fitness function.
- R: the length of the selected feature subset.
- C: the total feature numbers.
- : classification accuracy of the subset with length R.
- : argument .
- : argument .
3.1.3. The Service Phase
4. Simulation and Computer Results
- Accuracy: The validity of the predicted data by the system; improving this factor makes the decision making easier and more convenient.
- Time: The time that the system will take to classify the data; eliminating this factor will minimize the cost.
- Data Variety: The amount of accepted data by the system; this indicates how flexible the approach is by accepting more forms of data.
4.1. Used Datasets and Physical Meaning
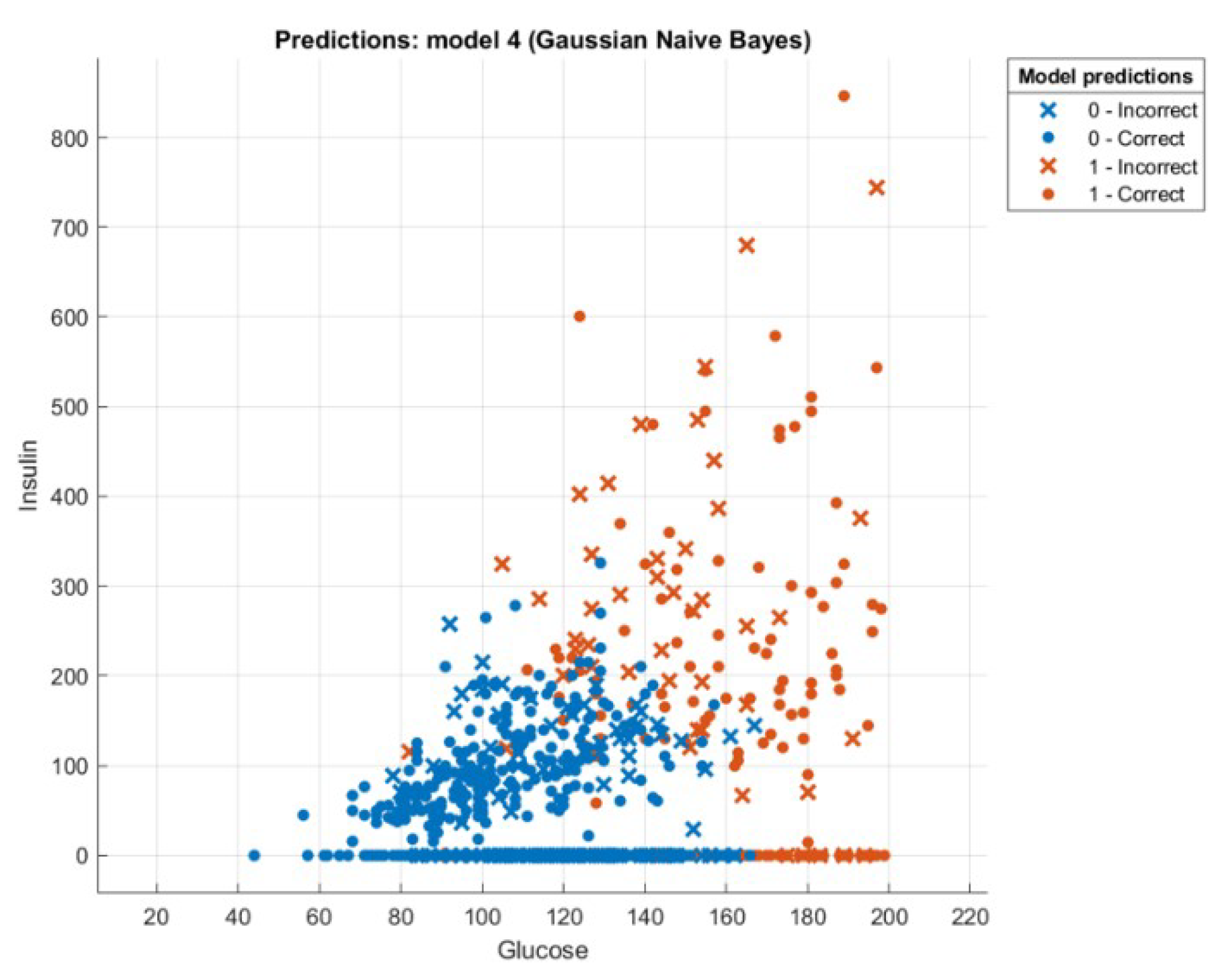
4.1.1. Diabetes
4.1.2. Heart Disease Uci
4.1.3. Heart Attack Prediction
4.1.4. Sonar
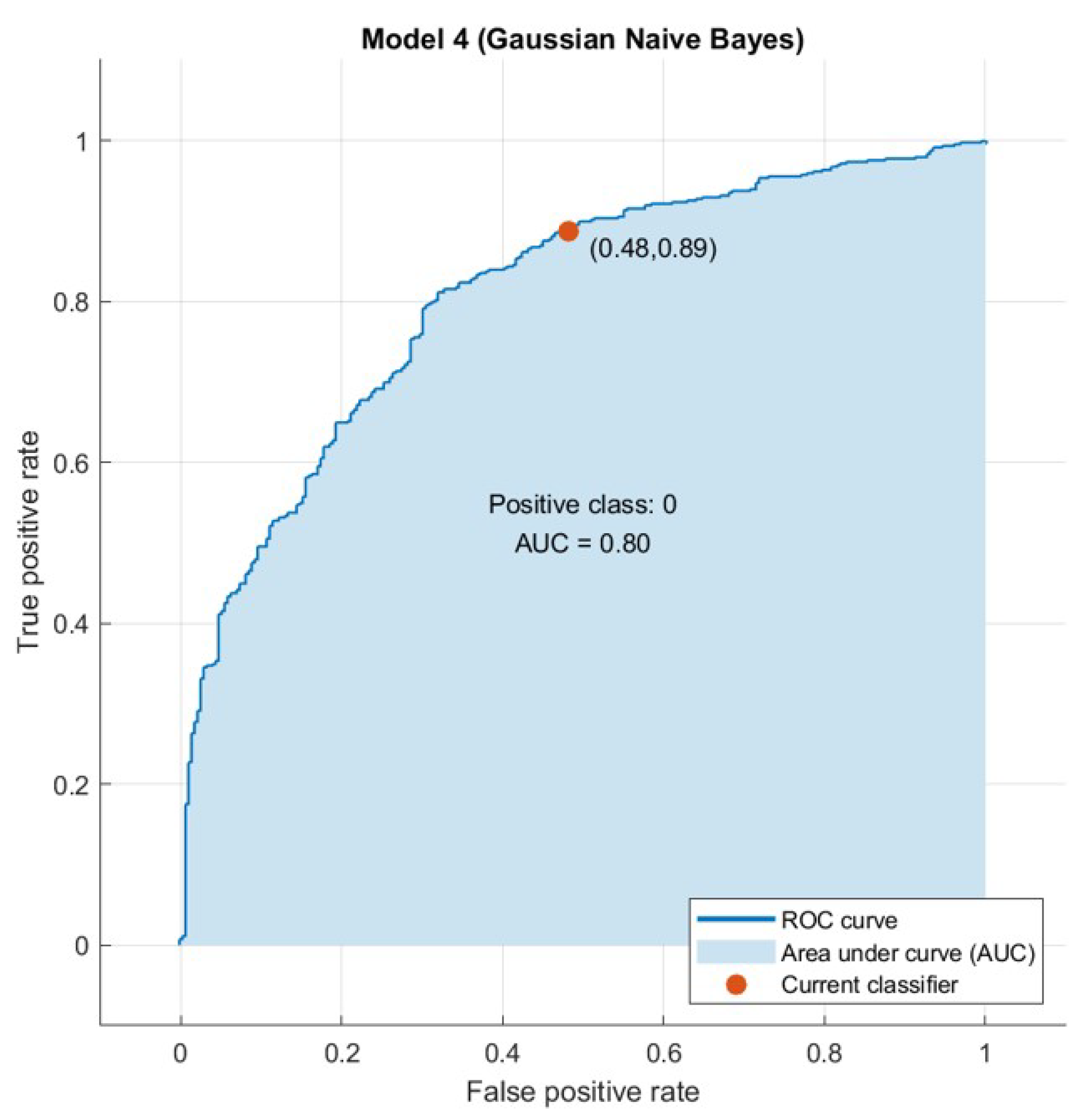
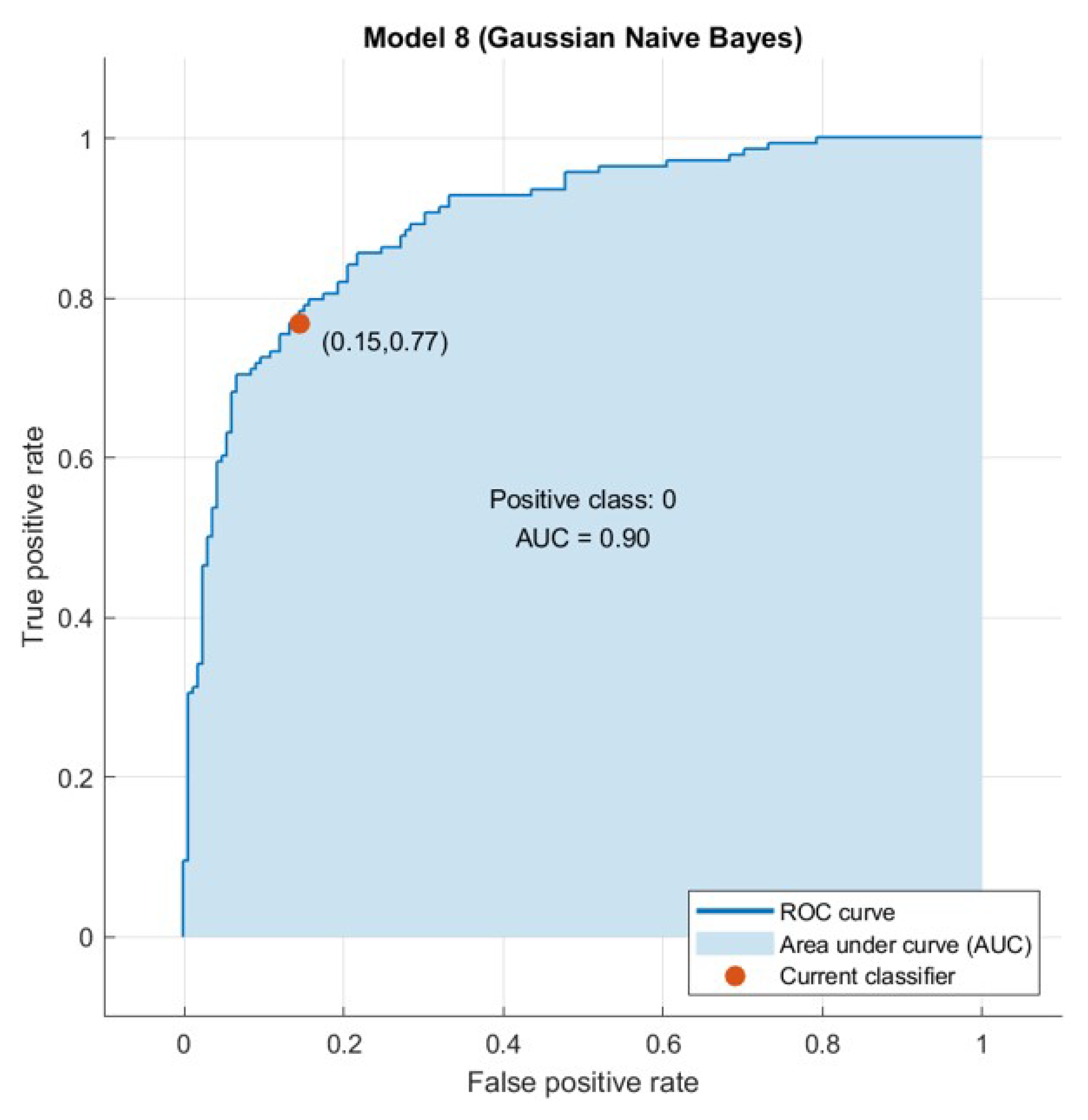
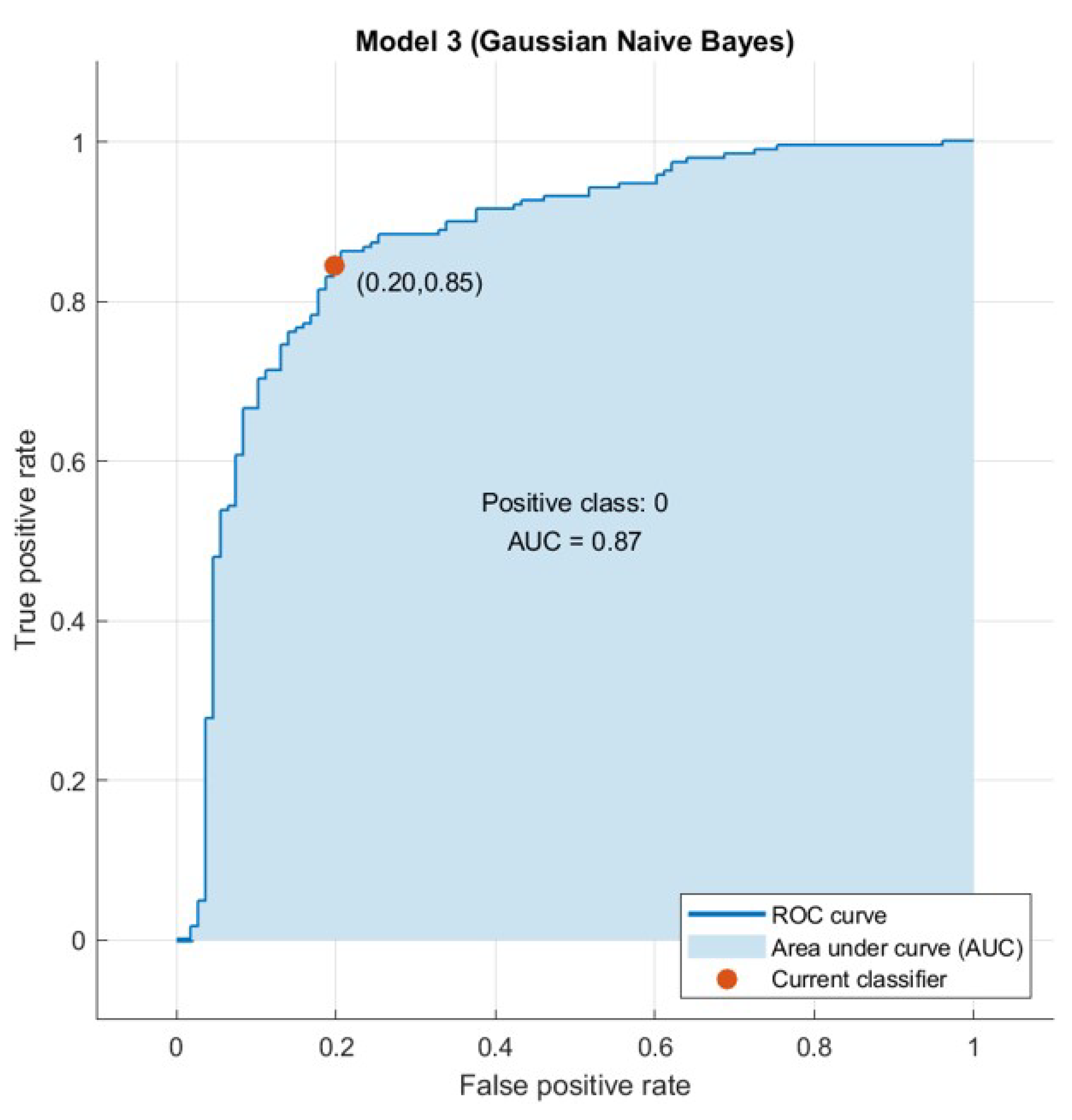
4.2. Computer Results
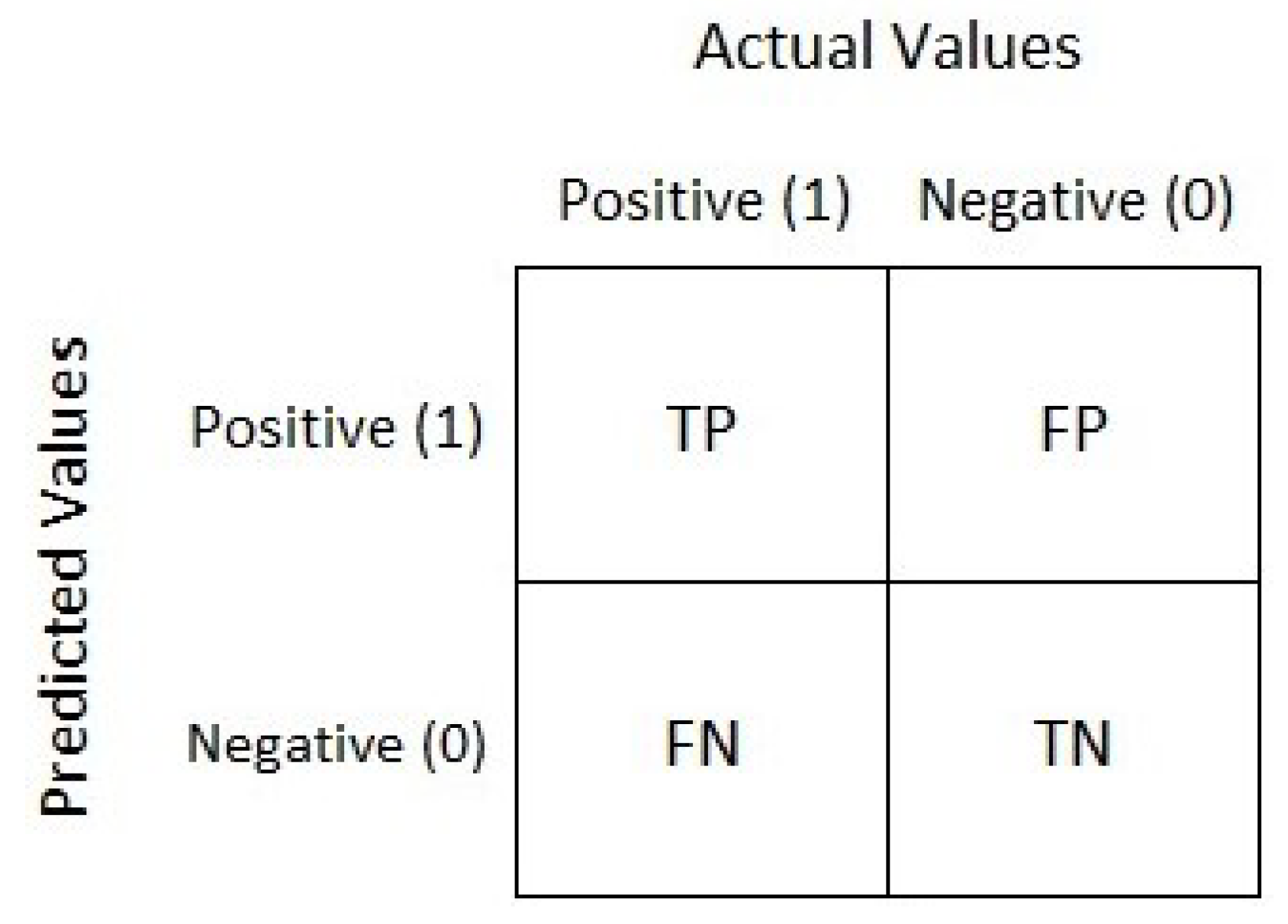
- Positive (P): Observation is positive (for example: is an apple).
- Negative (N): Observation is not positive (for example: is not an apple).
- True Positive (TP): Observation is positive and is predicted to be positive.
- False Negative (FN): Observation is positive but is predicted negative.
- True Negative (TN): Observation is negative and is predicted to be negative.
- False Positive (FP): Observation is negative but is predicted positive.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tariq, N.; Asim, M.; Al-Obeidat, F.; Zubair Farooqi, M.; Baker, T.; Hammoudeh, M.; Ghafir, I. The security of big data in fog-enabled IoT applications including blockchain: A survey. Sensors 2019, 19, 1788. [Google Scholar] [CrossRef] [Green Version]
- Shehab, N.; Badawy, M.; Arafat, H. Big Data Analytics Concepts, Technologies Challenges, and Opportunities. In Proceedings of the International Conference on Advanced Intelligent Systems and Informatics, Cairo, Egypt, 19–21 October; Springer: Berlin, Germany, 2019; pp. 92–101. [Google Scholar]
- Katal, A.; Wazid, M.; Goudar, R.H. Big data: Issues, challenges, tools and good practices. In Proceedings of the 2013 Sixth International Conference on Contemporary Computing (IC3), Noida, India, 8–10 August 2013; pp. 404–409. [Google Scholar]
- Gantz, J.; Reinsel, D. Extracting value from chaos. IDC Iview 2011, 1142, 1–12. [Google Scholar]
- Sin, K.; Muthu, L. Application of big data in education data mining and learning analytics–A literature review. ICTACT J. Soft Comput. 2015, 5, 1035–1049. [Google Scholar] [CrossRef]
- Abawajy, J.H.; Hassan, M.M. Federated internet of things and cloud computing pervasive patient health monitoring system. IEEE Commun. Mag. 2017, 55, 48–53. [Google Scholar] [CrossRef]
- Labrinidis, A.; Jagadish, H.V. Challenges and opportunities with big data. Proc. VLDB Endow. 2012, 5, 2032–2033. [Google Scholar] [CrossRef]
- Reda, M.; Haikal, A.Y.; Elhosseini, M.A.; Badawy, M. An innovative damped cuckoo search algorithm with a comparative study against other adaptive variants. IEEE Access 2019, 7, 119272–119293. [Google Scholar] [CrossRef]
- Hassan, M.K.; El Desouky, A.I.; Badawy, M.M.; Sarhan, A.M.; Elhoseny, M.; Gunasekaran, M. EoT-driven hybrid ambient assisted living framework with naïve Bayes–firefly algorithm. Neural Comput. Appl. 2019, 31, 1275–1300. [Google Scholar] [CrossRef]
- Andriopoulou, F.; Dagiuklas, T.; Orphanoudakis, T. Integrating IoT and fog computing for healthcare service delivery. In Components and Services for IoT Platforms; Springer: Berlin, Germany, 2017; pp. 213–232. [Google Scholar]
- Masouros, D.; Bakolas, I.; Tsoutsouras, V.; Siozios, K.; Soudris, D. From edge to cloud: Design and implementation of a healthcare Internet of Things infrastructure. In Proceedings of the 2017 27th International Symposium on Power and Timing Modeling, Optimization and Simulation (PATMOS), Thessaloniki, Greece, 25–27 September 2017; pp. 1–6. [Google Scholar]
- Tuli, S.; Basumatary, N.; Gill, S.S.; Kahani, M.; Arya, R.C.; Wander, G.S.; Buyya, R. Healthfog: An ensemble deep learning based smart healthcare system for automatic diagnosis of heart diseases in integrated iot and fog computing environments. Future Gener. Comput. Syst. 2020, 104, 187–200. [Google Scholar] [CrossRef] [Green Version]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Cortés-Toro, E.M.; Crawford, B.; Gómez-Pulido, J.A.; Soto, R.; Lanza-Gutiérrez, J.M. A new metaheuristic inspired by the vapour-liquid equilibrium for continuous optimization. Appl. Sci. 2018, 8, 2080. [Google Scholar] [CrossRef] [Green Version]
- Diab, D.M.; El Hindi, K.M. Using differential evolution for fine tuning naïve Bayesian classifiers and its application for text classification. Appl. Soft Comput. 2017, 54, 183–199. [Google Scholar] [CrossRef]
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The hadoop distributed file system. In Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Incline Village, NA, USA, 3–7 May 2010; pp. 1–10. [Google Scholar]
- White, T. Hadoop: The Definitive Guide; O’Reilly Media, Inc.: Newton, MA, USA, 2012. [Google Scholar]
- Learning, Kaggle Your Machine, Data Science Community. Available online: https://www.kaggle.com (accessed on 4 July 2021).
- Jiang, L.; Zhang, L.; Yu, L.; Wang, D. Class-specific attribute weighted naive Bayes. Pattern Recognit. 2019, 88, 321–330. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Ling, C.X.; Huang, J.; Zhang, H. AUC: A statistically consistent and more discriminating measure than accuracy. IJCAI 2003, 3, 519–524. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
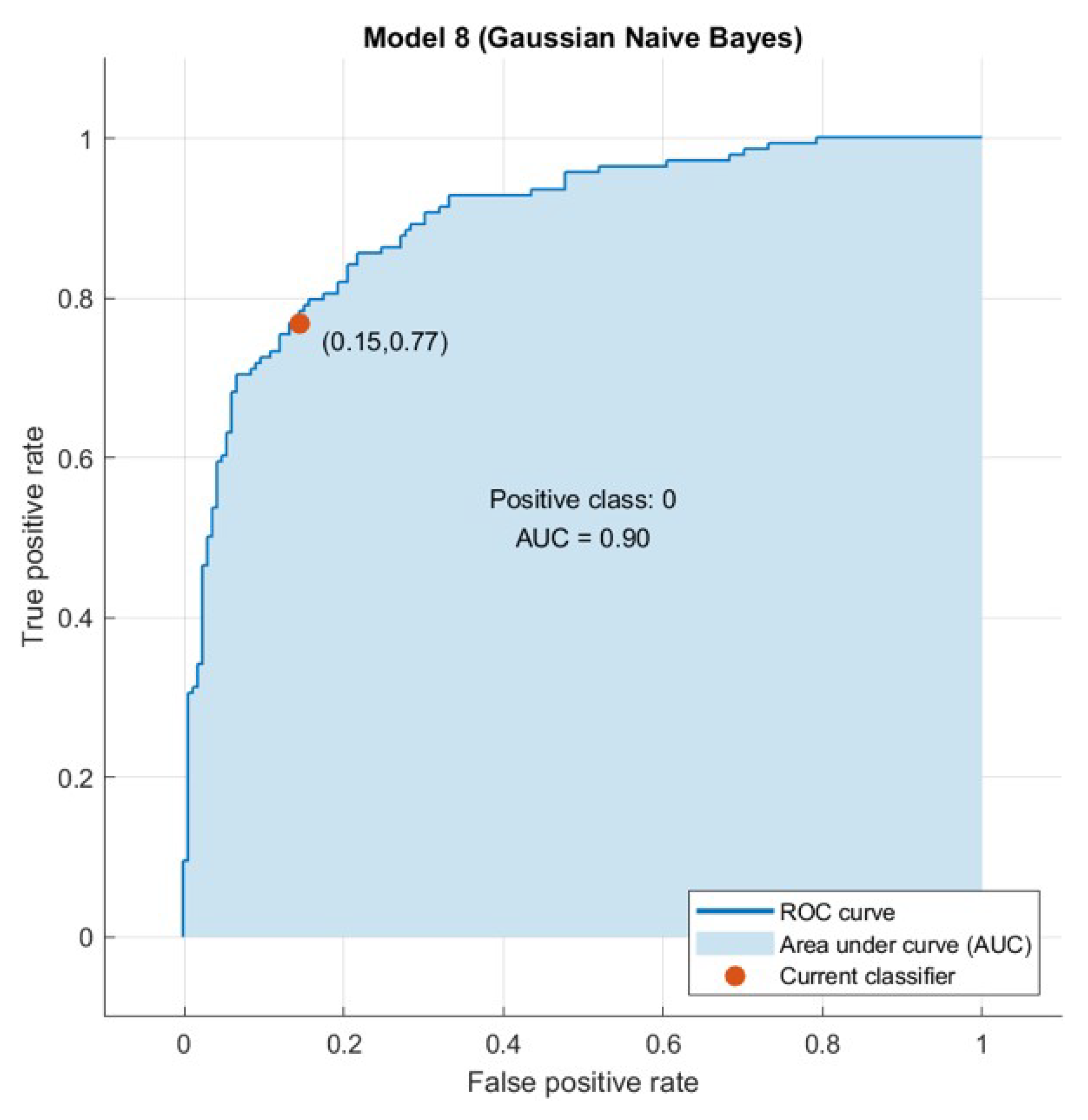{kind=link}
{kind=link}
{kind=link}
| Architecture | No. of Layers | Scalability | Flexibility | Real-Time Support | Energy-Efficiency | Computational Cost |
|---|---|---|---|---|---|---|
| PPHM [6] | Three Layer | Scalable | Flexible | N/A | Energy-efficient | High |
| HSDA [10] | Three Layers | Moderate | Moderate | support | Moderate | Moderate |
| EFCHioT [11] | Three Layers | Scalable | Limited | support | Energy-efficient | High |
| HAAL-NBFA [9] | Four Layers | Scalable | Limited | support | Moderate | High |
| HealthFog [12] | Three Layers | Limited | Moderate | support | Energy-efficient | Low |
| Dataset | # Instances | # Features | Clasisfication Type | Availability |
|---|---|---|---|---|
| Heart disease UCI | 303 | 14 | Multiclass | The data set is publicly available on the Kaggle website https://www.kaggle.com/ronitf/heart-disease-uci (accessed on 2 July 2021) |
| Pima Indians Diabetes Database | 768 | 9 | Binary class | The data set is publicly available on the Kaggle website https://www.kaggle.com/uciml/pima-indians-diabetes-database (accessed on 2 July 2021) |
| Heart Attack Prediction | 294 | 76 | Multiclass | The data set is publicly available on the Kaggle website https://www.kaggle.com/imnikhilanand/heart-attack-prediction (accessed on 2 July 2021) |
| Sonar | 1334 | 60 | Binary class | The data set is publicly available on the Kaggle website https://www.kaggle.com/ypzhangsam/sonaralldata (accessed on 2 July 2021) |
| Classifier | Datasets | ||||
|---|---|---|---|---|---|
| Algorithm(s) | Parameters | Diabetes | Heart-C | Heart-H | Sonar |
| No. of Features | 8 of 8 | 13 of 13 | 13 of 13 | 60 of 60 | |
| NB | Accuracy (%) | 77.24 | 83.04 | 83.91 | 85.4 |
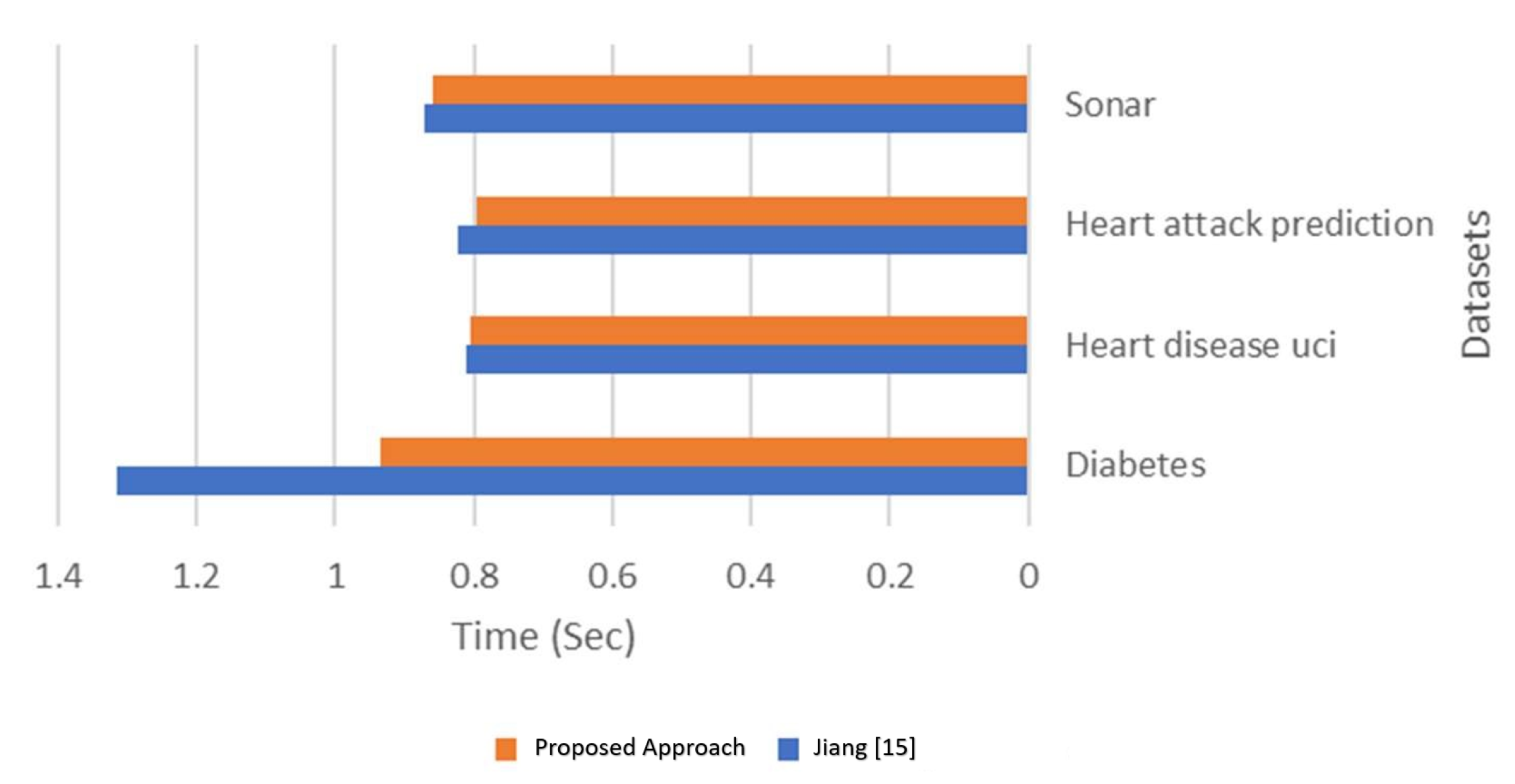
| Time (s) | 1.3151 | 0.81224 | 0.82374 | 0.87044 | |
| No. of Features | 4 of 8 | 12 of 13 | 12 of 13 | 52 of 60 | |
| WOA and NB | Accuracy (%) | 79.82 | 85.48 | 87.07 | 88.94 |
| Time (s) | 0.93421 | 0.80358 | 0.79651 | 0.85827 | |
| Datasets/Metrics | TP | FP | FN | TN | Precision | Recall | Specificity | Sensitivity |
|---|---|---|---|---|---|---|---|---|
| Diabetes | 4730 | 410 | 1140 | 1400 | 92% | 80.57% | 77% | 81% |
| Heart disease uci | 1120 | 260 | 180 | 1470 | 81% | 86.15% | 85% | 86% |
| Heart attack prediction | 1660 | 250 | 130 | 900 | 82% | 90% | 78% | 93% |
| Sonar | 980 | 130 | 100 | 870 | 88% | 91% | 87% | 91% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alwateer, M.; Almars, A.M.; Areed, K.N.; Elhosseini, M.A.; Haikal, A.Y.; Badawy, M. Ambient Healthcare Approach with Hybrid Whale Optimization Algorithm and Naïve Bayes Classifier. Sensors 2021, 21, 4579. https://doi.org/10.3390/s21134579
Alwateer M, Almars AM, Areed KN, Elhosseini MA, Haikal AY, Badawy M. Ambient Healthcare Approach with Hybrid Whale Optimization Algorithm and Naïve Bayes Classifier. Sensors. 2021; 21(13):4579. https://doi.org/10.3390/s21134579
Chicago/Turabian StyleAlwateer, Majed, Abdulqader M. Almars, Kareem N. Areed, Mostafa A. Elhosseini, Amira Y. Haikal, and Mahmoud Badawy. 2021. "Ambient Healthcare Approach with Hybrid Whale Optimization Algorithm and Naïve Bayes Classifier" Sensors 21, no. 13: 4579. https://doi.org/10.3390/s21134579
APA StyleAlwateer, M., Almars, A. M., Areed, K. N., Elhosseini, M. A., Haikal, A. Y., & Badawy, M. (2021). Ambient Healthcare Approach with Hybrid Whale Optimization Algorithm and Naïve Bayes Classifier. Sensors, 21(13), 4579. https://doi.org/10.3390/s21134579