
Action Generative Networks Planning for Deformable Object with Raw Observations

Abstract
:1. Introduction
2. Related Work
2.1. Deformable Object Planning
2.2. Contrastive Prediction
3. Our AGN Approach
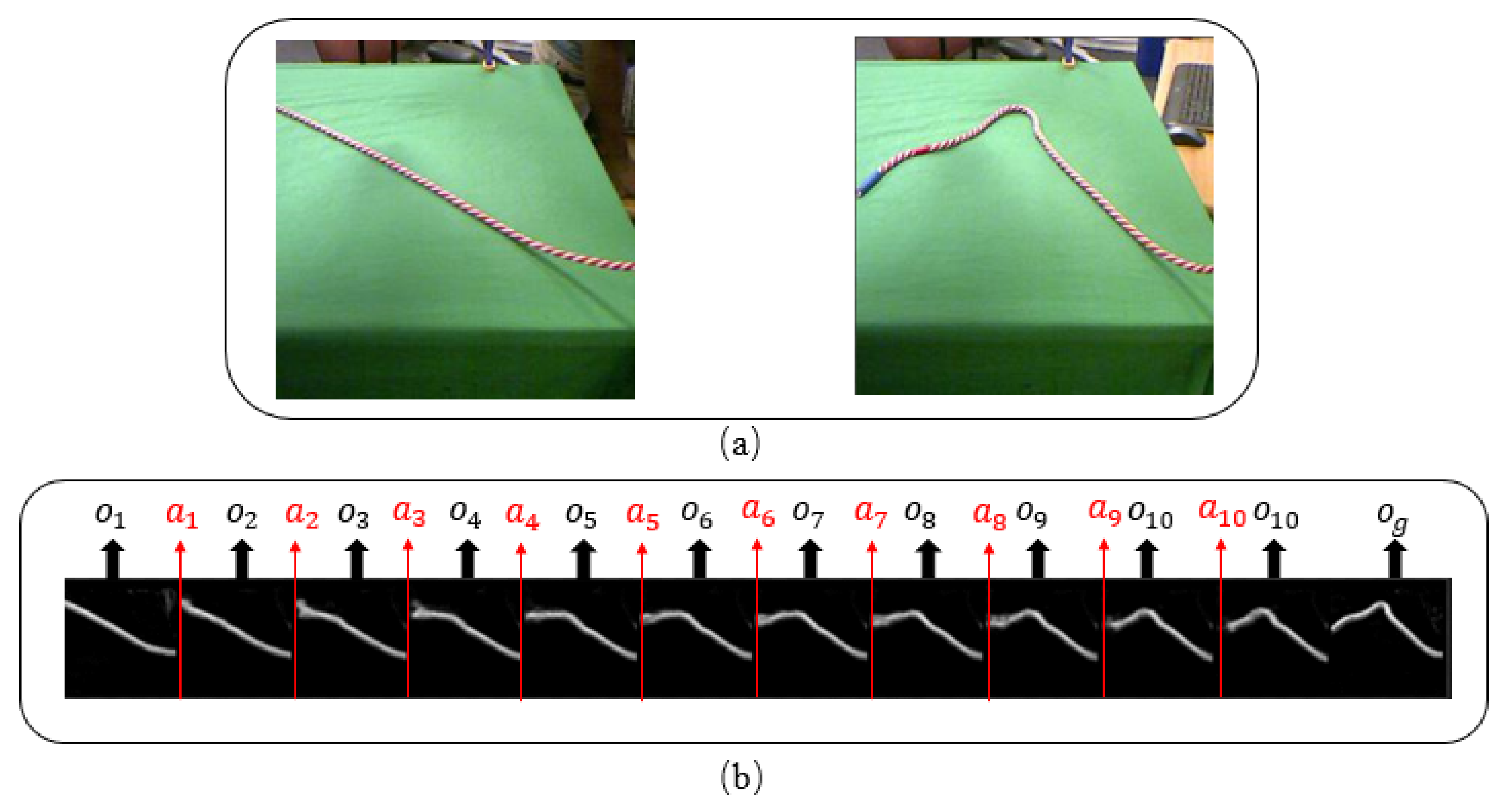
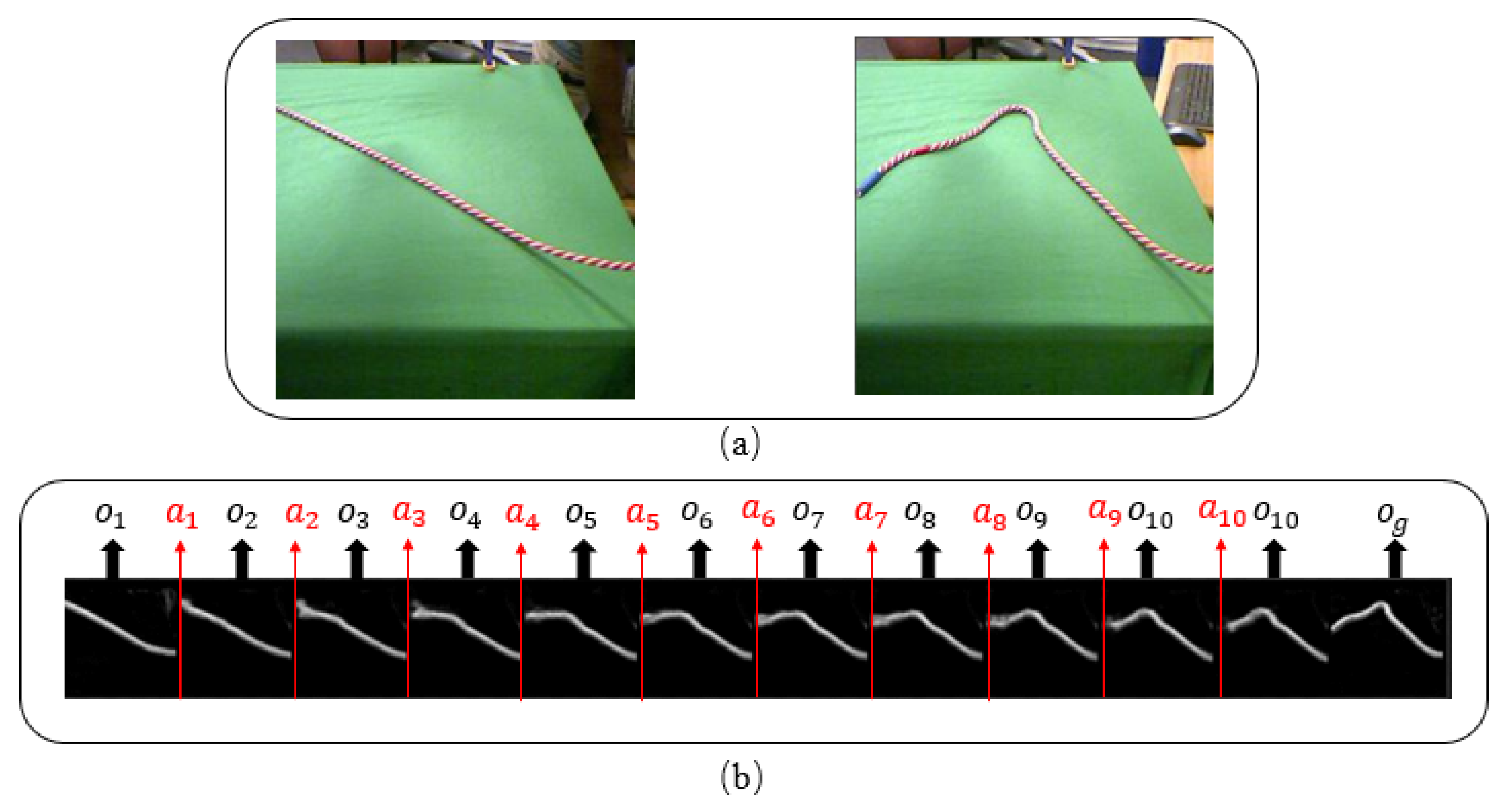
3.1. Problem Definition
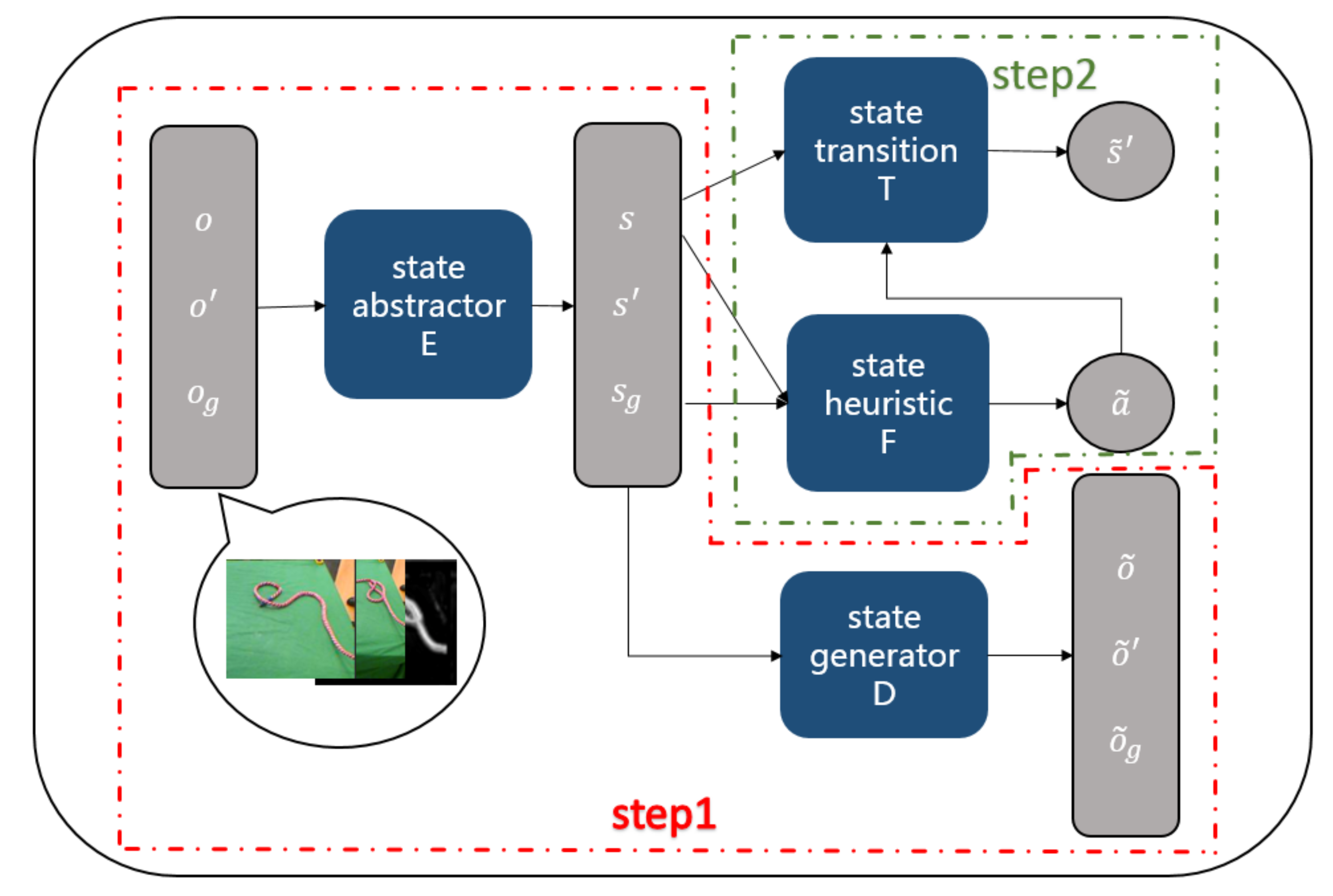
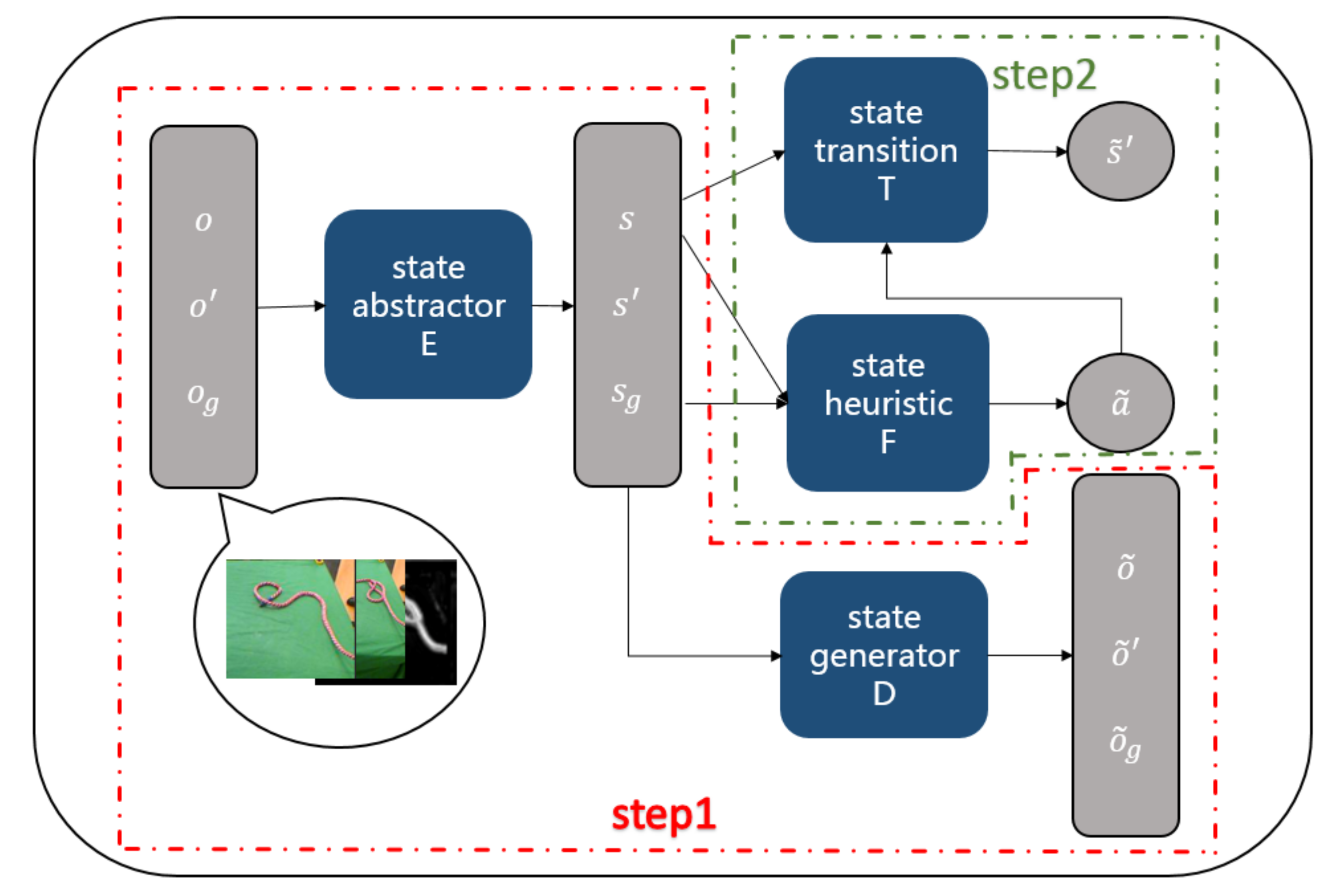
3.2. Algorithm Framework
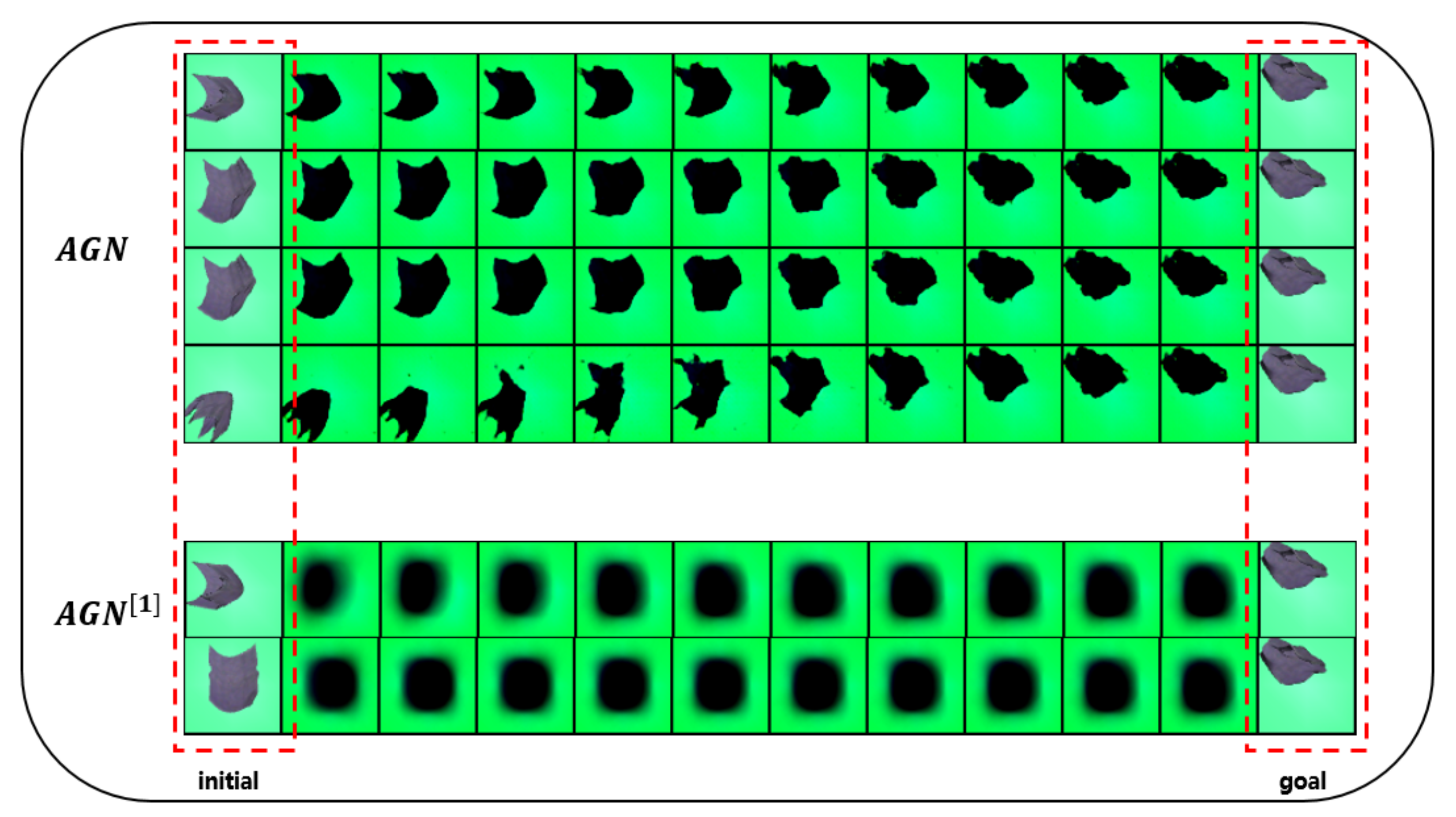
3.3. Planning with AGN
- Firstly, state-abstractor model E outputs abstract state and with and , respectively.
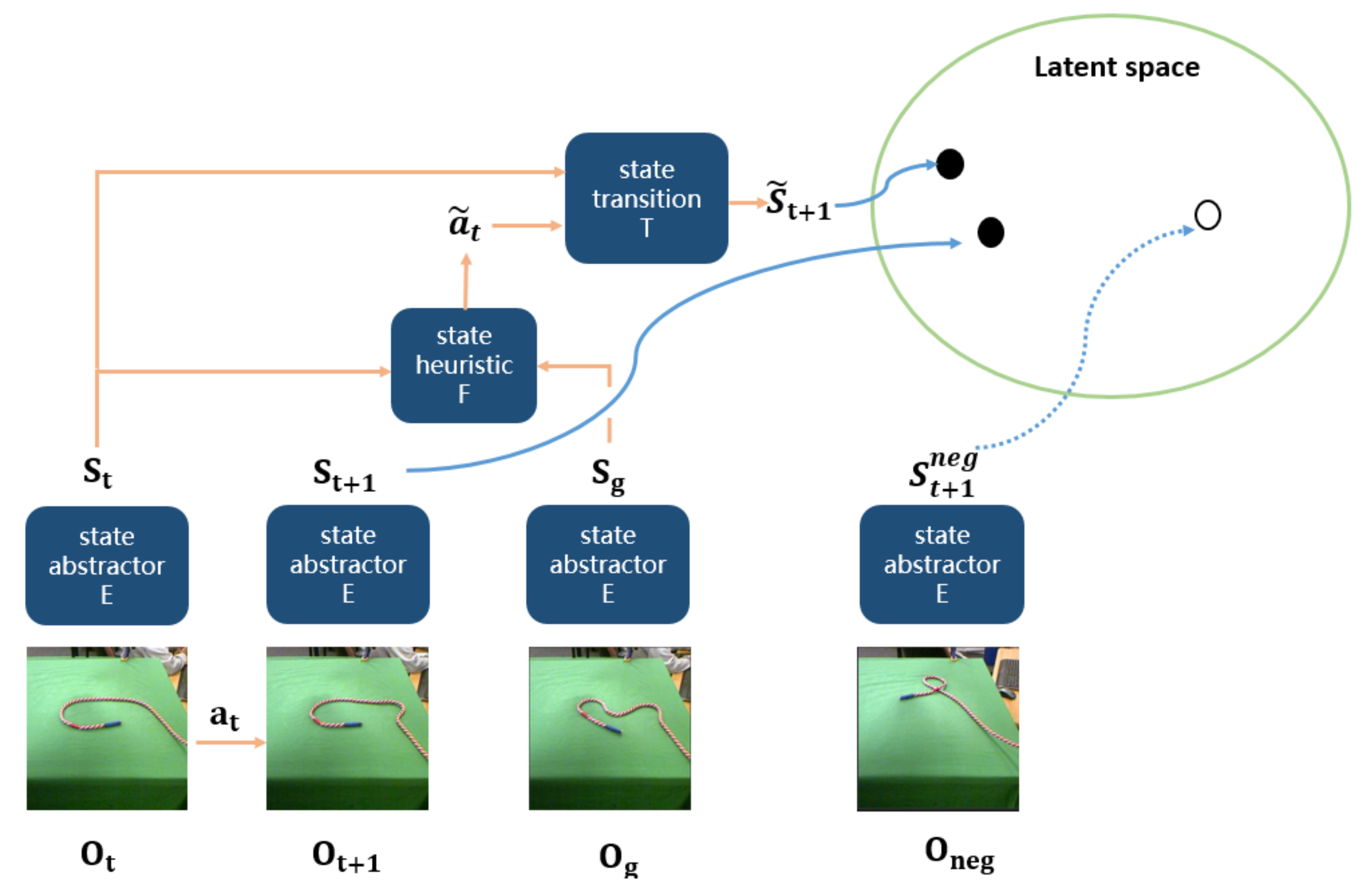
- Secondly, we compute an action sequence reaching from and derive an action state trajectory by Algorithm 1. We first perform linear interpolation between and , and attain an initial sequence = . As for each pair of and , we compute an action by the heuristic model. If can reach after executing action , we add state and action into . Otherwise, we interpolate a latent state into between and . We repeat the above procedures until each pair of states in can be transformed by an action computed by the heuristic model. Finally, we attain an action state trajectory .
| Algorithm 1 planning algorithm. |
| input:, , F, T. |
| output: |
|
- Finally, we compute an action observation trajectory . We first sample k different Gaussian noises randomly. Then we can obtain k different action observation trajectories given an action state trajectory and a noise by state-generator model D. At last, we select an optimal action observation trajectory among the k trajectories.
4. Experiments
4.1. Baselines
4.2. Evaluation Criterion
- Trajectory confidence, to evaluate whether an observation transition is feasible or not.
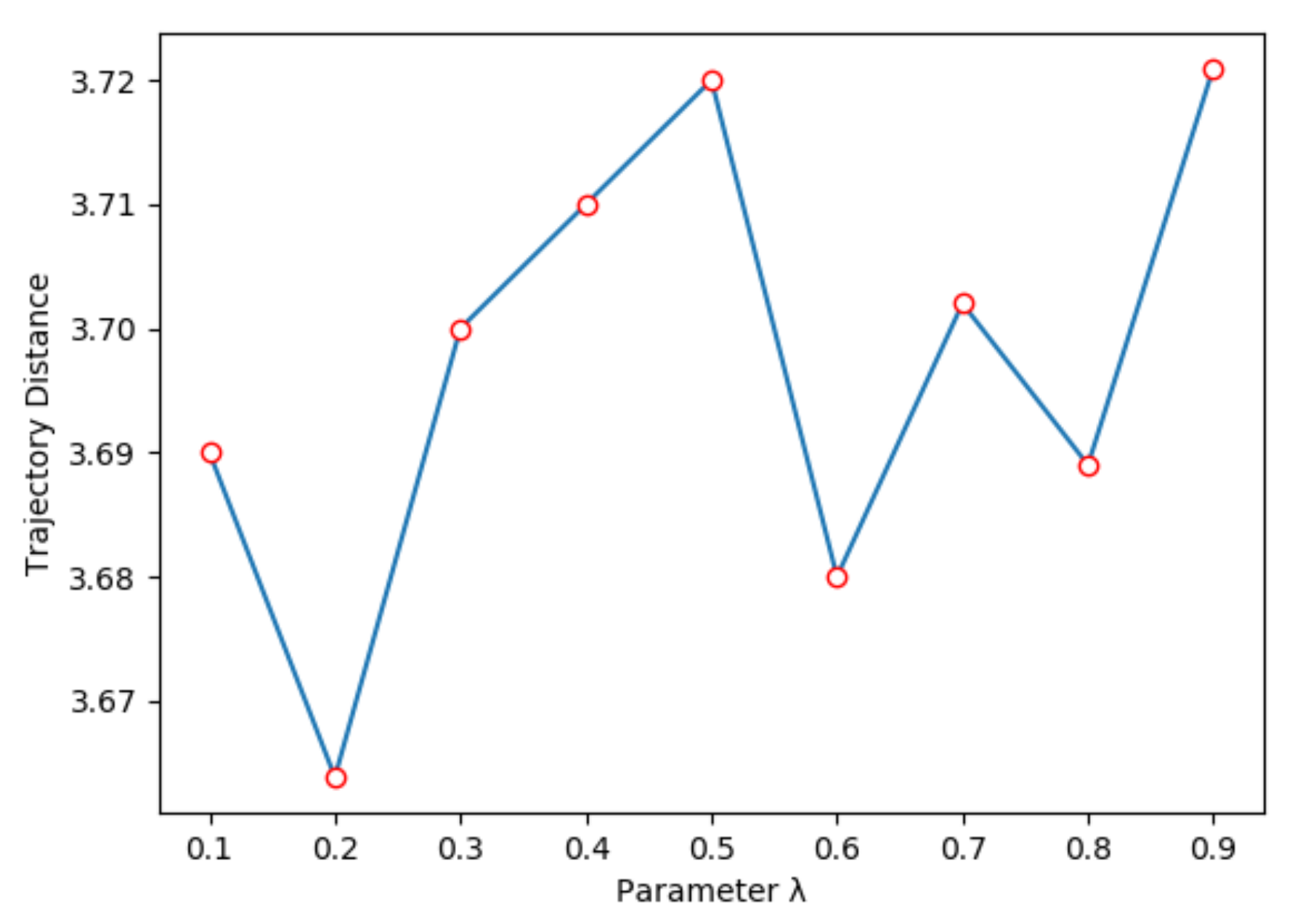
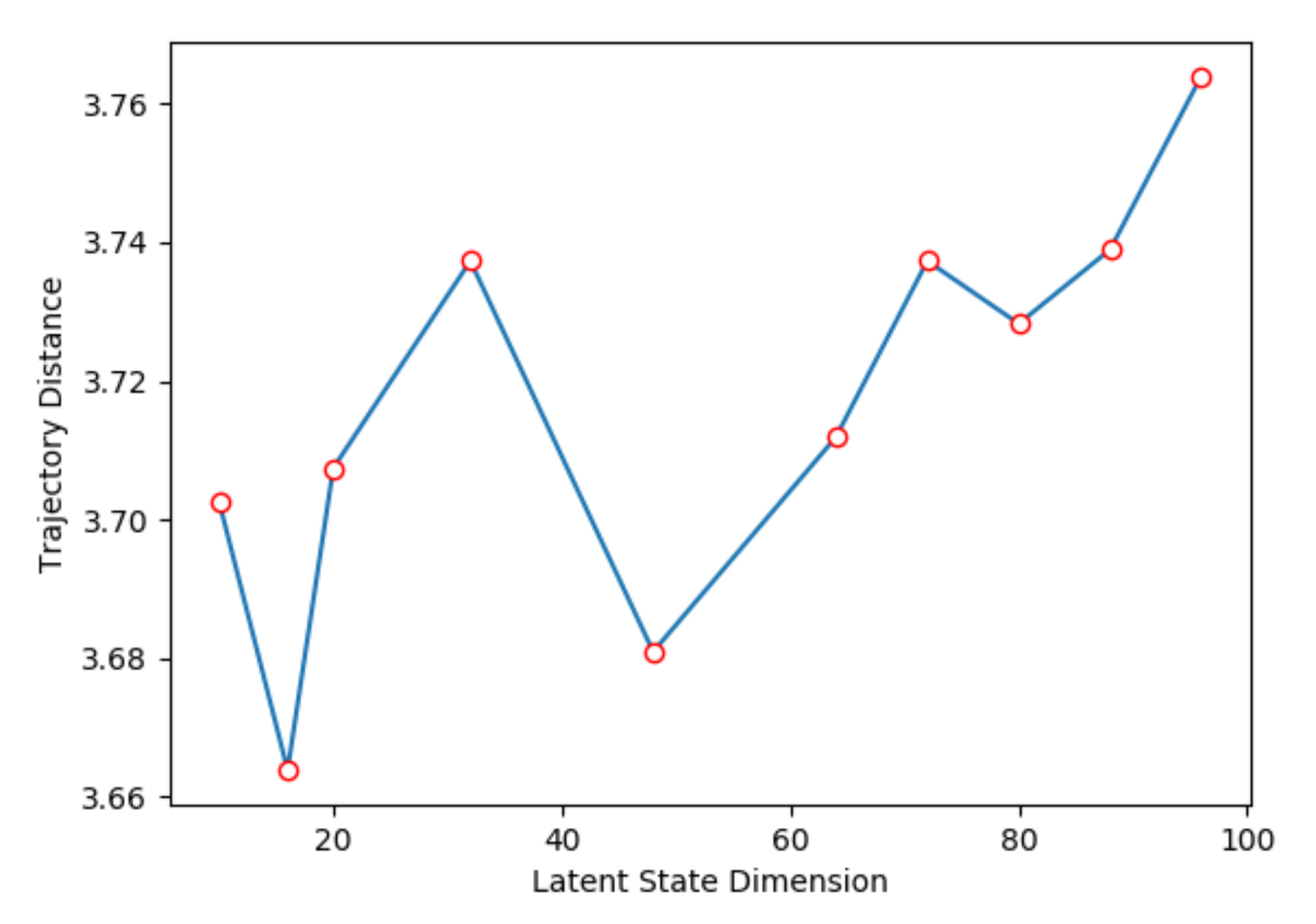
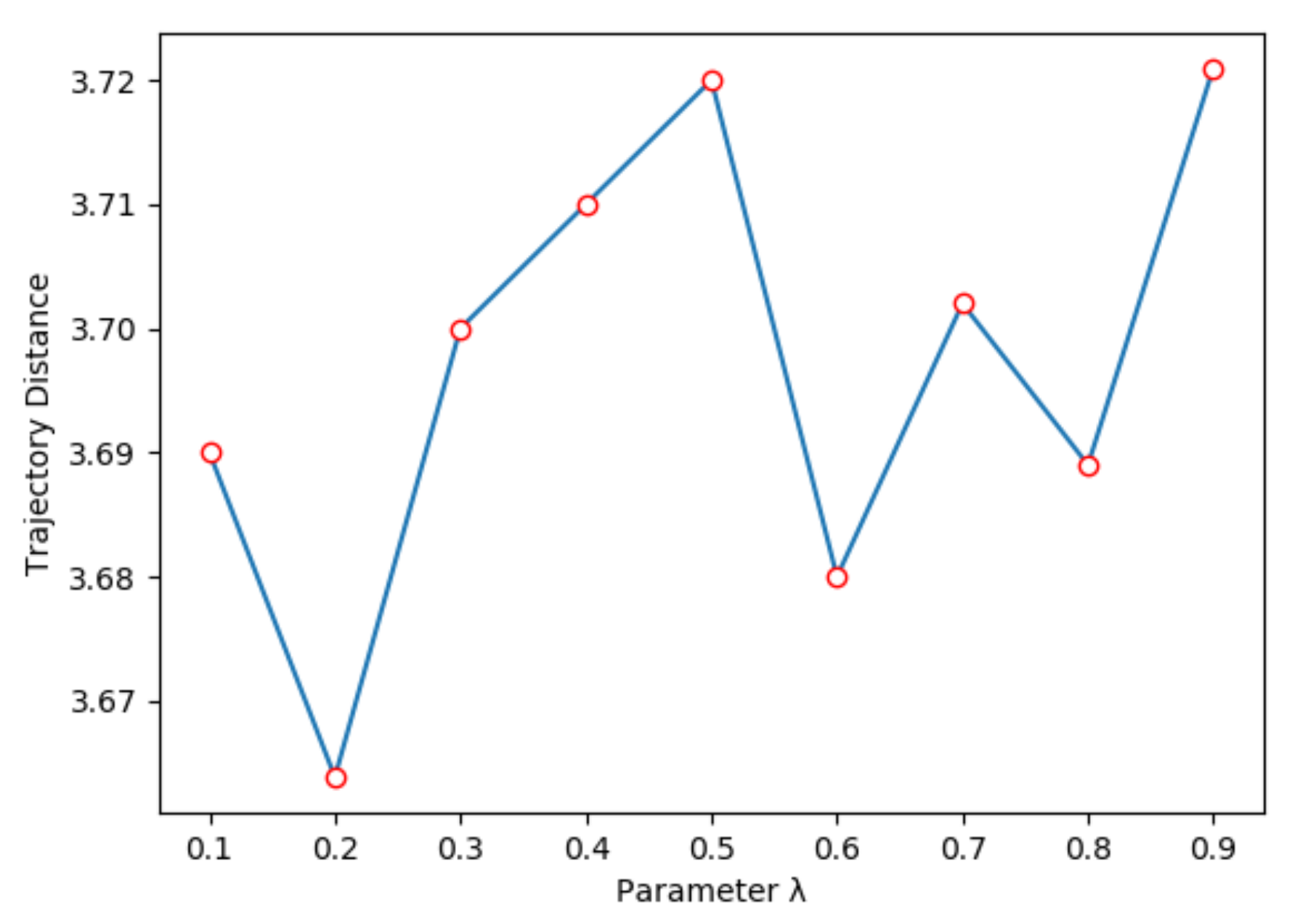
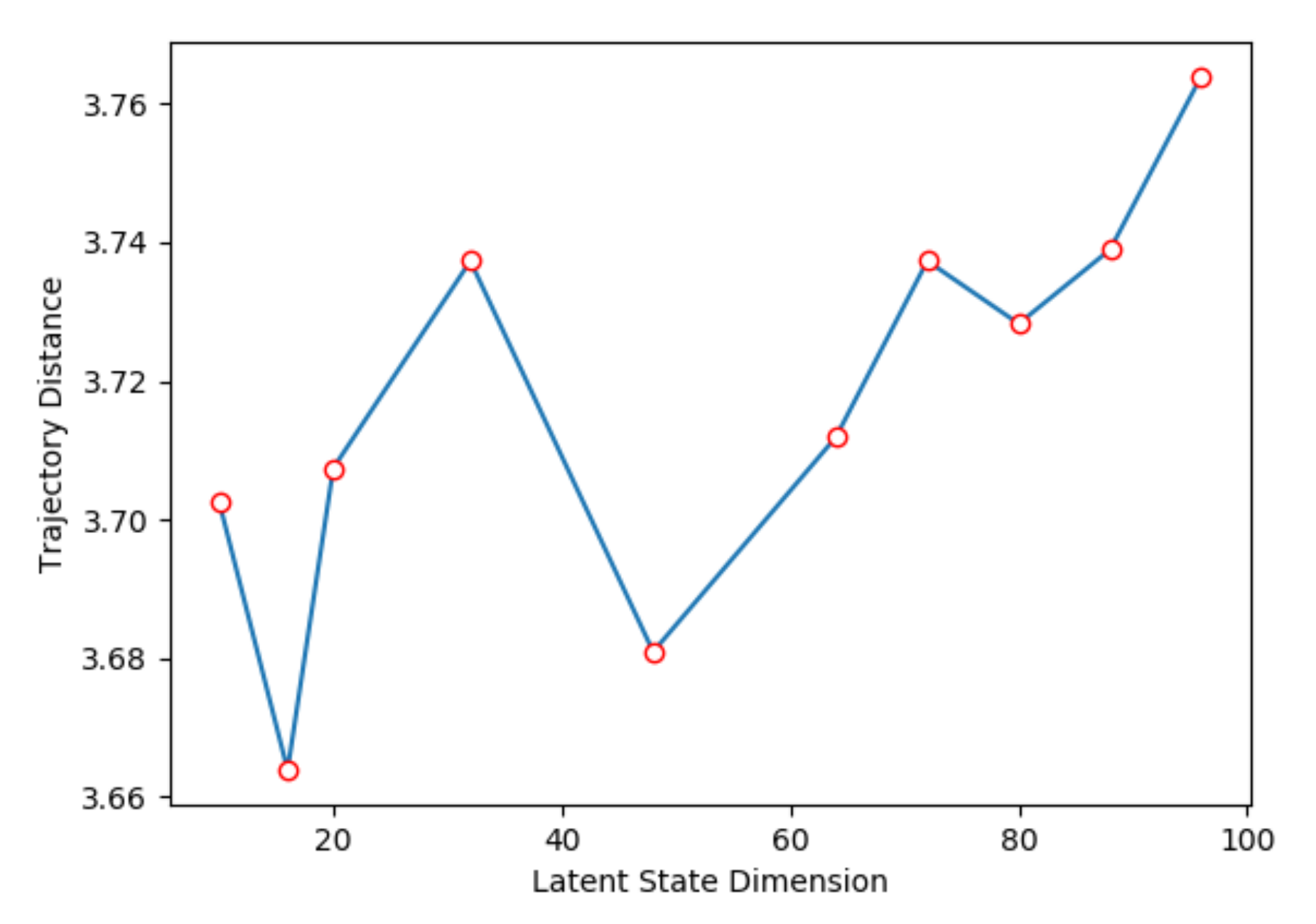
- Trajectory distance, to evaluate the Euclidean distance between the current observation and the next observation after the current action is performed.
- Final-to-goal distance, to evaluate the Euclidean distance between the final observation and goal observation.
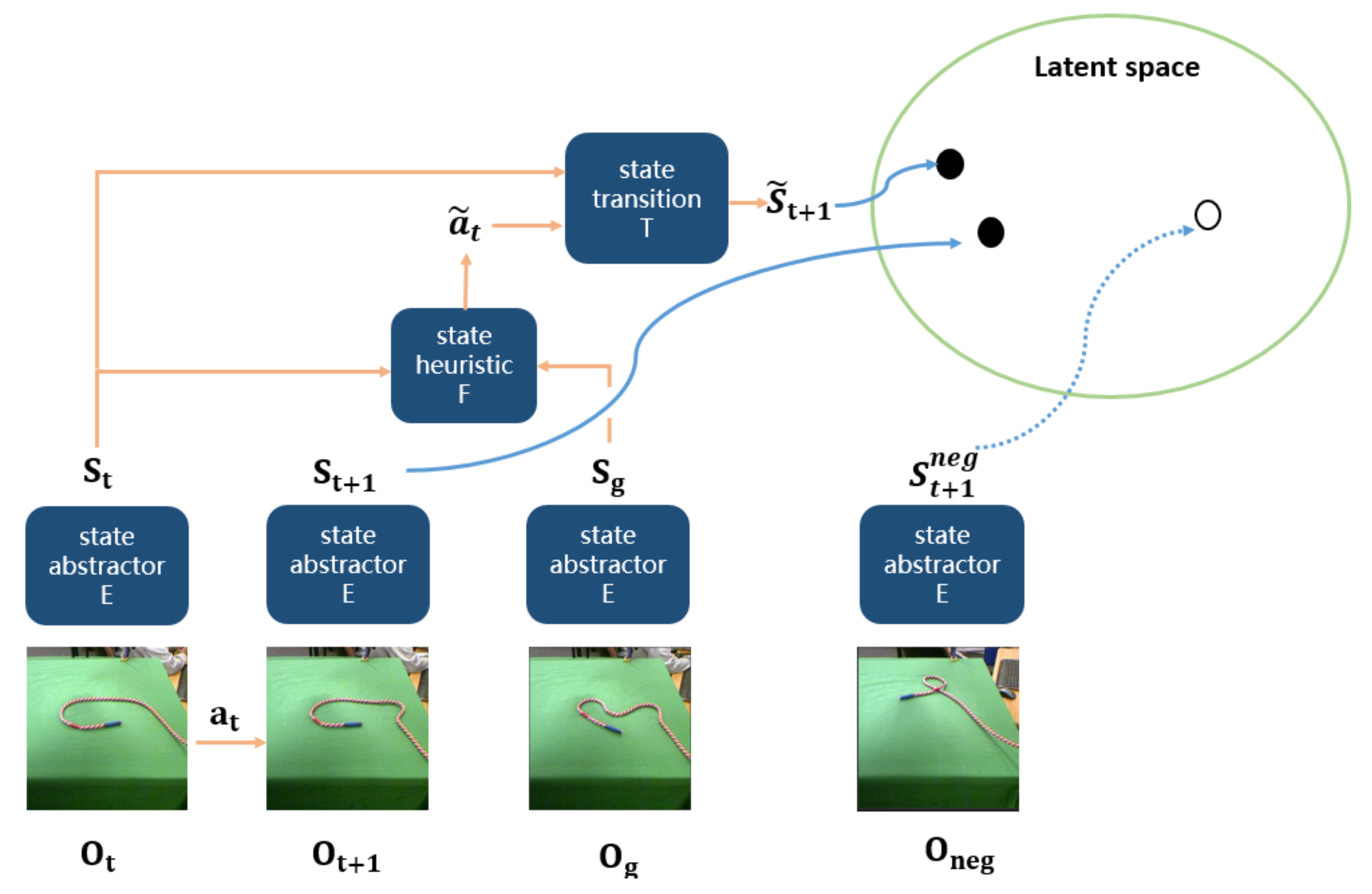
- The Judge model takes a pair of observations as input and outputs a binary result of whether the observation is feasible or not. The training dataset consists of positive observation pairs, which are 1 timestep apart, and negative pairs that are randomly sampled from different rope manipulation trajectories. To avoid the background of rope influencing the training of Judge, we preprocess the rope data using the background subtraction pipeline mentioned above.To validate the accuracy of the Judge model, we evaluate it with observation traces to observe the binary outputs. Given an m-length observation trace, Judge takes the first observation and an observation, which is n steps apart, where n is from 1 to . The binary output decreases from 1 to 0 smoothly with n increasing, indicating that the Judge model has the ability to recognize a feasible observation pair. We test Judge with 100 traces out of the testing dataset for AGN and the accuracy is 98%.
- The EVAL model takes a pair of observations , an action , and an observation as inputs, where is a predicting next observation and is a real next observation, they are updated from a current observation after executing action . The EVAL model outputs a distance between and . The training dataset consists of positive next observations, we trained the EVAL model by letting the predict next observation be close to the real next observation . On a held-out test set, the distance between the predict next observation and real next observation converges to 0.
4.3. Rope Manipulation
4.4. Cloth Manipulation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ghallab, M.; Nau, D.S.; Traverso, P. Automated Planning and Acting; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning—An Introduction; Adaptive Computation and Machine Learning; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Schulman, J.; Lee, A.X.; Ho, J.; Abbeel, P. Tracking deformable objects with point clouds. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 1130–1137. [Google Scholar]
- Wu, Y.; Yan, W.; Kurutach, T.; Pinto, L.; Abbeel, P. Learning to Manipulate Deformable Objects without Demonstrations. arXiv 2019, arXiv:1910.13439. [Google Scholar]
- Seita, D.; Ganapathi, A.; Hoque, R.; Hwang, M.; Cen, E.; Tanwani, A.K.; Balakrishna, A.; Thananjeyan, B.; Ichnowski, J.; Jamali, N.; et al. Deep Imitation Learning of Sequential Fabric Smoothing From an Algorithmic Supervisor. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2020, Las Vegas, NV, USA, 24 October–24 January 2021; pp. 9651–9658. [Google Scholar]
- Essahbi, N.; Bouzgarrou, B.C.; Gogu, G. Soft Material Modeling for Robotic Manipulation. Appl. Mech. Mater. 2012, 162, 184–193. [Google Scholar] [CrossRef]
- Mirza, M.; Jaegle, A.; Hunt, J.J.; Guez, A.; Tunyasuvunakool, S.; Muldal, A.; Weber, T.; Karkus, P.; Racanière, S.; Buesing, L.; et al. Physically Embedded Planning Problems: New Challenges for Reinforcement Learning. arXiv 2020, arXiv:2009.05524. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.I.; Moritz, P. Trust Region Policy Optimization. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015; Bach, F.R., Blei, D.M., Eds.; Volume 37, pp. 1889–1897. [Google Scholar]
- Hafner, D.; Lillicrap, T.P.; Ba, J.; Norouzi, M. Dream to Control: Learning Behaviors by Latent Imagination. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.A.; Fidjeland, A.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Levine, S.; Finn, C.; Darrell, T.; Abbeel, P. End-to-End Training of Deep Visuomotor Policies. J. Mach. Learn. Res. 2016, 17, 1334–1373. [Google Scholar]
- Matas, J.; James, S.; Davison, A.J. Sim-to-Real Reinforcement Learning for Deformable Object Manipulation. arXiv 2018, arXiv:1806.07851. [Google Scholar]
- Seita, D.; Ganapathi, A.; Hoque, R.; Hwang, M.; Cen, E.; Tanwani, A.K.; Balakrishna, A.; Thananjeyan, B.; Ichnowski, J.; Jamali, N.; et al. Deep Imitation Learning of Sequential Fabric Smoothing Policies. arXiv 2019, arXiv:1910.04854. [Google Scholar]
- Nagabandi, A.; Kahn, G.; Fearing, R.S.; Levine, S. Neural Network Dynamics for Model-Based Deep Reinforcement Learning with Model-Free Fine-Tuning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation, ICRA 2018, Brisbane, Australia, 21–25 May 2018; pp. 7559–7566. [Google Scholar]
- Berenson, D. Manipulation of deformable objects without modeling and simulating deformation. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 4525–4532. [Google Scholar]
- Wang, A.; Kurutach, T.; Abbeel, P.; Tamar, A. Learning Robotic Manipulation through Visual Planning and Acting. In Proceedings of the Robotics: Science and Systems XV, Breisgau, Germany, 22–26 June 2019. [Google Scholar]
- Agrawal, P.; Nair, A.; Abbeel, P.; Malik, J.; Levine, S. Learning to Poke by Poking: Experiential Learning of Intuitive Physics. In Proceedings of the Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Nair, A.; Chen, D.; Agrawal, P.; Isola, P.; Abbeel, P.; Malik, J.; Levine, S. Combining self-supervised learning and imitation for vision-based rope manipulation. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation, ICRA 2017, Singapore, 29 May–3 June 2017; pp. 2146–2153. [Google Scholar]
- Kurutach, T.; Tamar, A.; Yang, G.; Russell, S.J.; Abbeel, P. Learning Plannable Representations with Causal InfoGAN. arXiv 2018, arXiv:1807.09341. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. arXiv 2016, arXiv:1606.03657. [Google Scholar]
- Srivastava, A.; Valkov, L.; Russell, C.; Gutmann, M.U.; Sutton, C. VAEGAN: Reducing Mode Collapse in GANs using Implicit Variational Learning. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; pp. 3308–3318. [Google Scholar]
- Van den Oord, A.; Li, Y.; Vinyals, O. Representation Learning with Contrastive Predictive Coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Arriola-Rios, V.E.; Güler, P.; Ficuciello, F.; Kragic, D.; Siciliano, B.; Wyatt, J.L. Modeling of Deformable Objects for Robotic Manipulation: A Tutorial and Review. Front. Robot. AI 2020, 7, 82. [Google Scholar] [CrossRef] [PubMed]
- McConachie, D.; Ruan, M.; Berenson, D. Interleaving Planning and Control for Deformable Object Manipulation. In Proceedings of the Robotics Research, The 18th International Symposium, ISRR 2017, Puerto Varas, Chile, 11–14 December 2017; Amato, N.M., Hager, G., Thomas, S.L., Torres-Torriti, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10, pp. 1019–1036. [Google Scholar]
- Chung, J.; Kastner, K.; Dinh, L.; Goel, K.; Courville, A.C.; Bengio, Y. A Recurrent Latent Variable Model for Sequential Data. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 2980–2988. [Google Scholar]
- Watter, M.; Springenberg, J.T.; Boedecker, J.; Riedmiller, M.A. Embed to Control: A Locally Linear Latent Dynamics Model for Control from Raw Images. arXiv 2015, arXiv:1506.07365. [Google Scholar]
- Ha, J.S.; Park, Y.J.; Chae, H.J.; Park, S.S.; Choi, H.L. Adaptive Path-Integral Autoencoders: Representation Learning and Planning for Dynamical Systems. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Konidaris, G.; Kaelbling, L.P.; Lozano-Pérez, T. From Skills to Symbols: Learning Symbolic Representations for Abstract High-Level Planning. J. Artif. Intell. Res. 2018, 61, 215–289. [Google Scholar] [CrossRef]
- Srinivas, A.; Jabri, A.; Abbeel, P.; Levine, S.; Finn, C. Universal Planning Networks: Learning Generalizable Representations for Visuomotor Control. ICML 2018, 4739–4748. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–8 December 2013; Burges, C.J.C., Bottou, L., Ghahramani, Z., Weinberger, K.Q., Eds.; pp. 3111–3119. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive Multiview Coding. In Computer Vision; Lecture Notes in Computer Science; Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12356, pp. 776–794. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G.E. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13–18 July 2020; Volume 119, pp. 1597–1607. [Google Scholar]
- Kaiser, L.; Babaeizadeh, M.; Milos, P.; Osinski, B.; Campbell, R.H.; Czechowski, K.; Erhan, D.; Finn, C.; Kozakowski, P.; Levine, S.; et al. Model Based Reinforcement Learning for Atari. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Zhuo, H.H.; Zha, Y.; Kambhampati, S.; Tian, X. Discovering Underlying Plans Based on Shallow Models. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Zhuo, H.H.; Kambhampati, S. Model-lite planning: Case-based vs. model-based approaches. Artif. Intell. 2017, 246, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Zhuo, H.H.; Yang, Q. Action-model acquisition for planning via transfer learning. Artif. Intell. 2014, 212, 80–103. [Google Scholar] [CrossRef]
- Zhuo, H.H.; Muñoz-Avila, H.; Yang, Q. Learning hierarchical task network domains from partially observed plan traces. Artif. Intell. 2014, 212, 134–157. [Google Scholar] [CrossRef]
- Zhuo, H.H. Recognizing Multi-Agent Plans When Action Models and Team Plans Are Both Incomplete. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–24. [Google Scholar] [CrossRef]
- Feng, W.; Zhuo, H.H.; Kambhampati, S. Extracting Action Sequences from Texts Based on Deep Reinforcement Learning. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, Stockholm, Sweden, 13–19 July 2018; pp. 4064–4070. [Google Scholar] [CrossRef] [Green Version]
- Zhuo, H.H. Human-Aware Plan Recognition. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 3686–3693. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Trajectory Confidence | Trajectory Distance | Final–to–Goal Distance | |
|---|---|---|---|
| visualforward | 0.719 | 9.7189 | 5.5484 |
| jointdynamics | 0.567 | 10.680 | 5.046 |
| ausalinfoGAN | 0.884 | 9.0219 | 2.29 |
| AGN | 0.935 | 1.432 | 2.126 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sheng, Z.; Jin, K.; Ma, Z.; Zhuo, H.-H. Action Generative Networks Planning for Deformable Object with Raw Observations. Sensors 2021, 21, 4552. https://doi.org/10.3390/s21134552
Sheng Z, Jin K, Ma Z, Zhuo H-H. Action Generative Networks Planning for Deformable Object with Raw Observations. Sensors. 2021; 21(13):4552. https://doi.org/10.3390/s21134552
Chicago/Turabian StyleSheng, Ziqi, Kebing Jin, Zhihao Ma, and Hankz-Hankui Zhuo. 2021. "Action Generative Networks Planning for Deformable Object with Raw Observations" Sensors 21, no. 13: 4552. https://doi.org/10.3390/s21134552
APA StyleSheng, Z., Jin, K., Ma, Z., & Zhuo, H.-H. (2021). Action Generative Networks Planning for Deformable Object with Raw Observations. Sensors, 21(13), 4552. https://doi.org/10.3390/s21134552