
Machine Learning Methods for Fear Classification Based on Physiological Features

 ,
,  ,
,  , ,
, ,  and
and
Abstract
:1. Introduction
2. Fear, an Adaptive Emotional Response
3. Physiological Data
3.1. Heart Rate Variability
3.2. Electrodermal Activity
- Skin Conductance Level (SCL)—the tonic component, a measure of continuous, slowly changing background characteristics (mean value 2–20 μS);
- Skin Conductance Response (SCR)—the phasic component, with rapid changes associated with specific and identifiable stimuli, as a result of momentary SNS activation (mean value 0.1–1.3 μS) [21].
4. Related Work
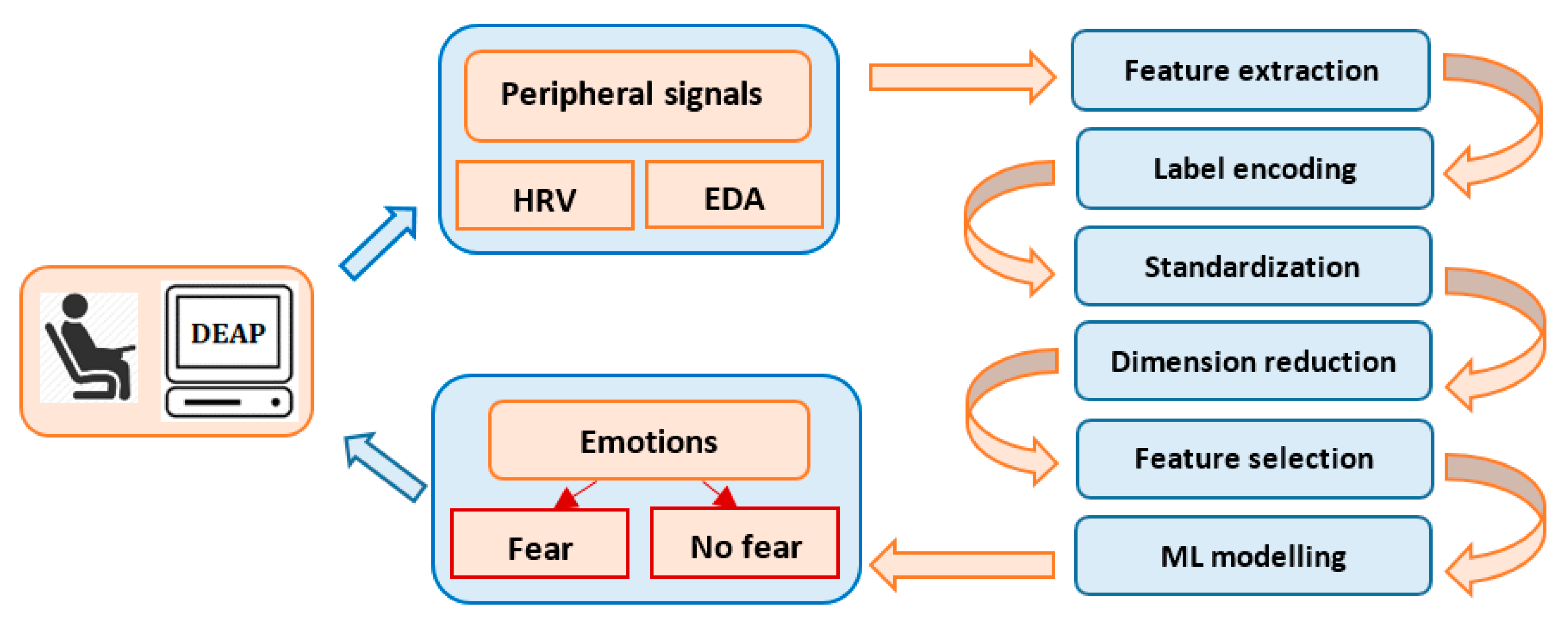
5. Research Design Framework
6. DEAP Feature Extraction
6.1. DEAP Description
- Electroencephalography (EEG) signals recorded from 32 channels;
- Electrooculography (EOG) signals recorded from eight channels;
- GSR signals corresponding to the EDA;
- Respiration signal recorded from a respiration belt;
- PPG signal measured on the left thumb, corresponding to HRV;
- Temperature signal measured on the left little finger;
- Status signal containing the markers sent from the stimuli presentation computer.
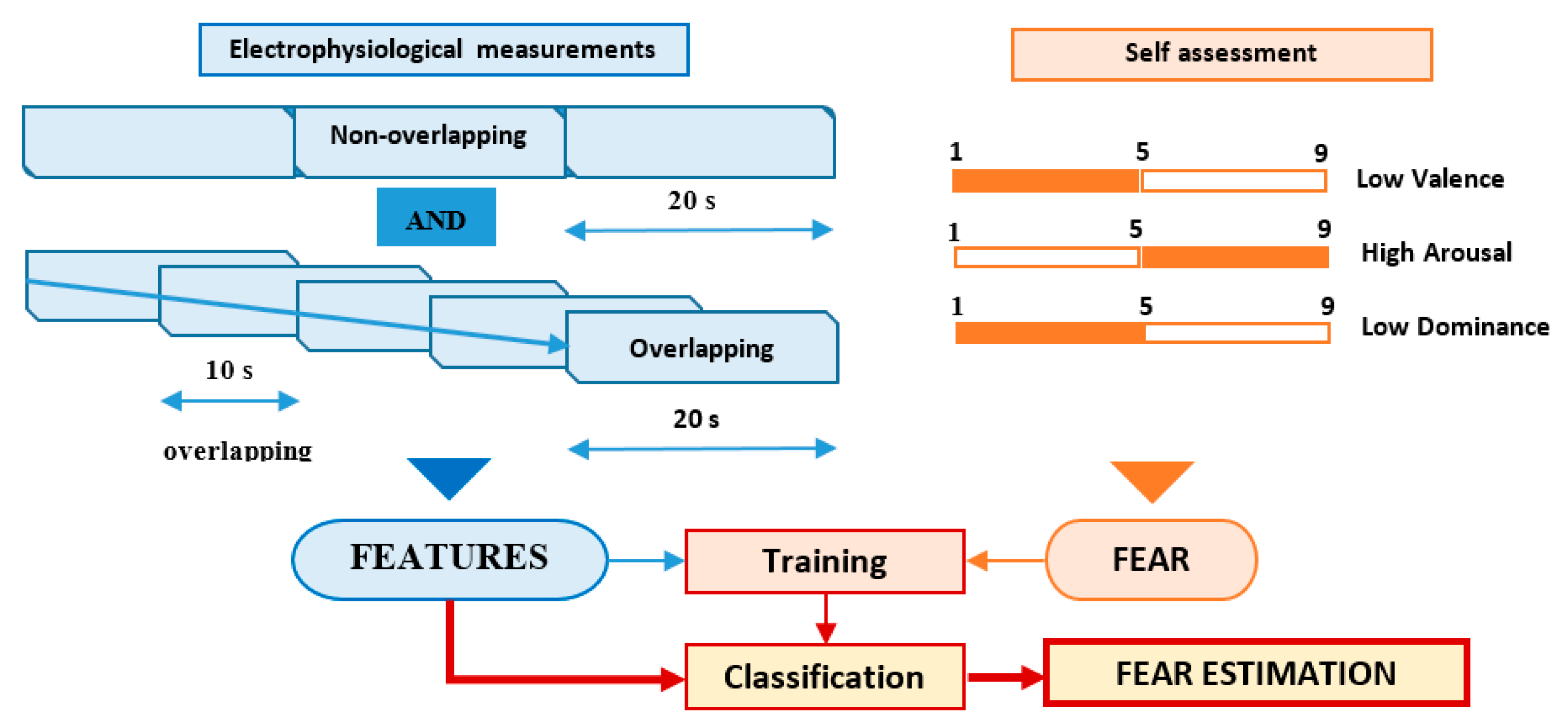
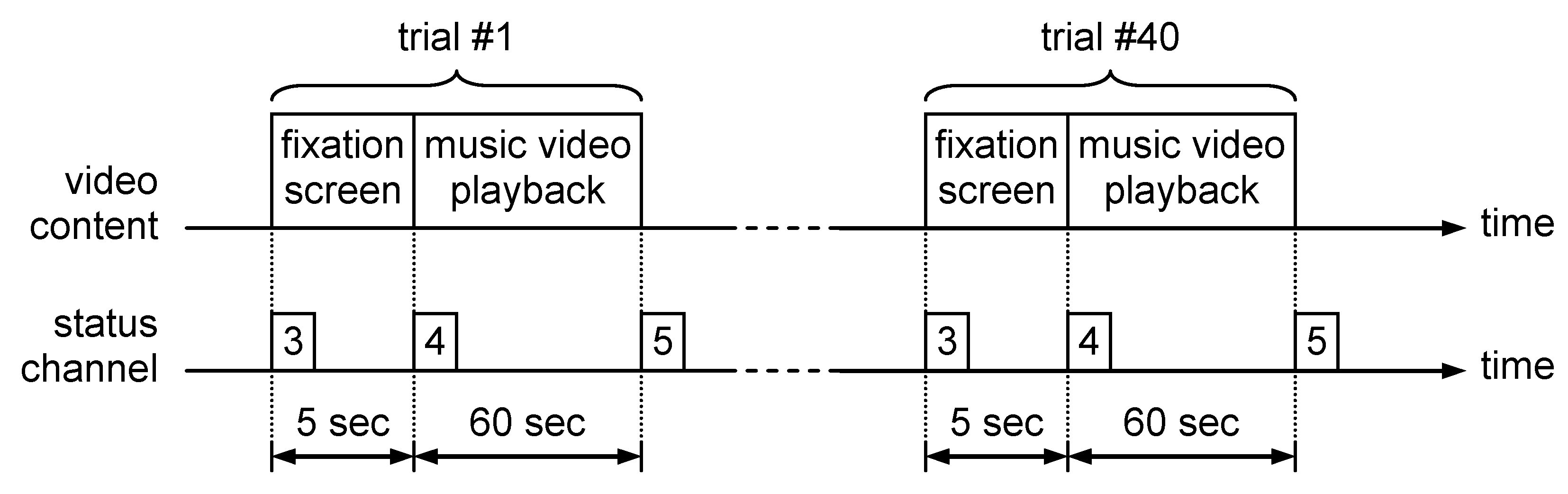
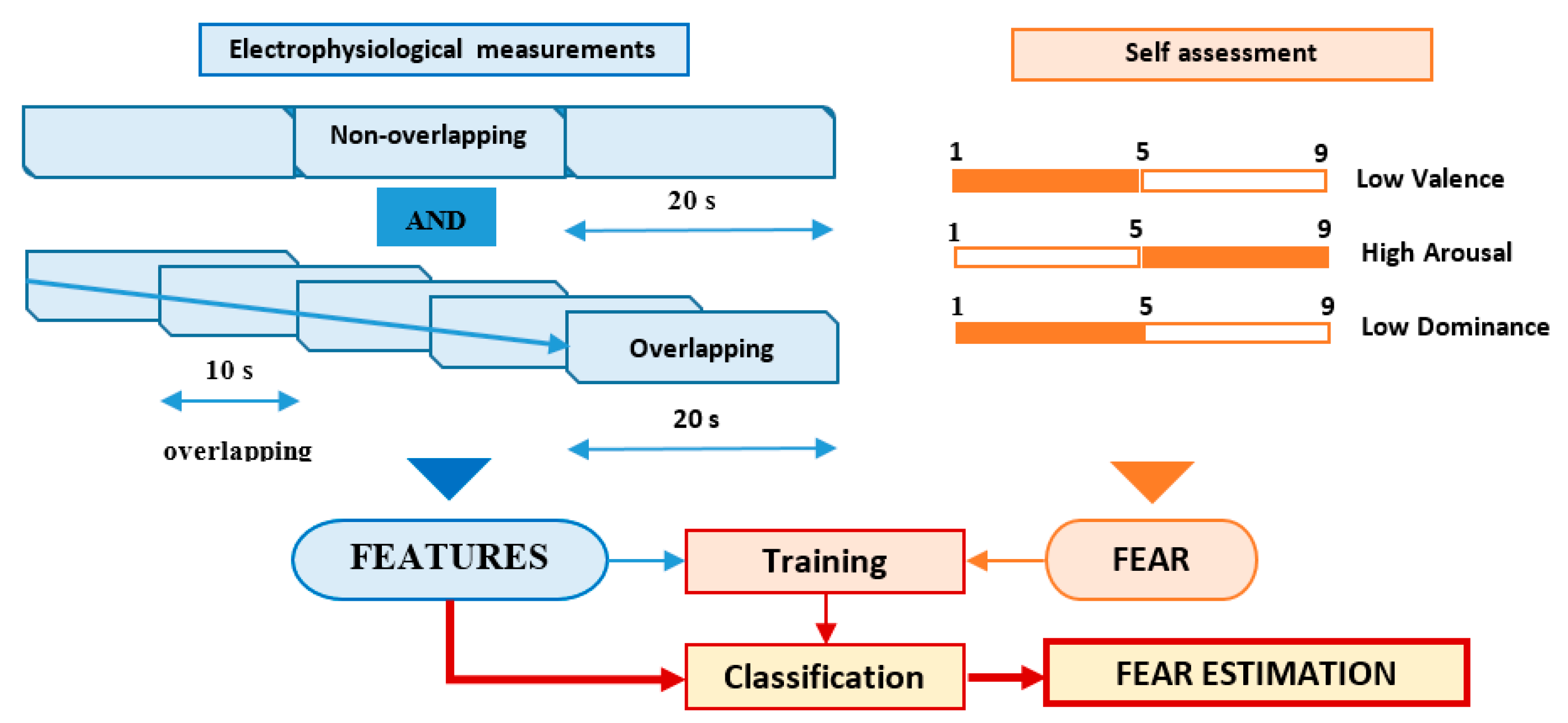
6.2. DEAP Features Extraction Protocol
- fear = 1 if valence ≤ 5 AND arousal > 5 AND dominance ≤ 5;
- fear = 0 in rest.
- Non-overlapping approach—each of the 60 s trials was segmented in three non-overlapping windows of 20 s length each. All signal features were evaluated in each window, the three values obtained for each feature being considered as independent. For this approach, for each trial, we evaluated a number of 120 features (3 segments × 40 features on each segment), as can be seen in Figure 4.
- Overlapping approach—each trial was segmented in five windows of 20 s length and 10 s overlap. Thus, five sets of 40 feature values were obtained for each trial, all of them being associated with the fear evaluated for that trial acting as five different data points, as can be seen in Figure 5.
6.3. Electrodermal Activity Features Extraction
- FIR filters have linear phase characteristics that help to preserve the waveshape of the signal;
- This class of filters is more suitable for fixed-point arithmetic implementation. This aspect is very important, especially for building the portable fear level estimation device that will use a low power microcontroller without floating point computing capabilities.
6.4. Heart Rate Variability Features Extraction
7. Fear Classification
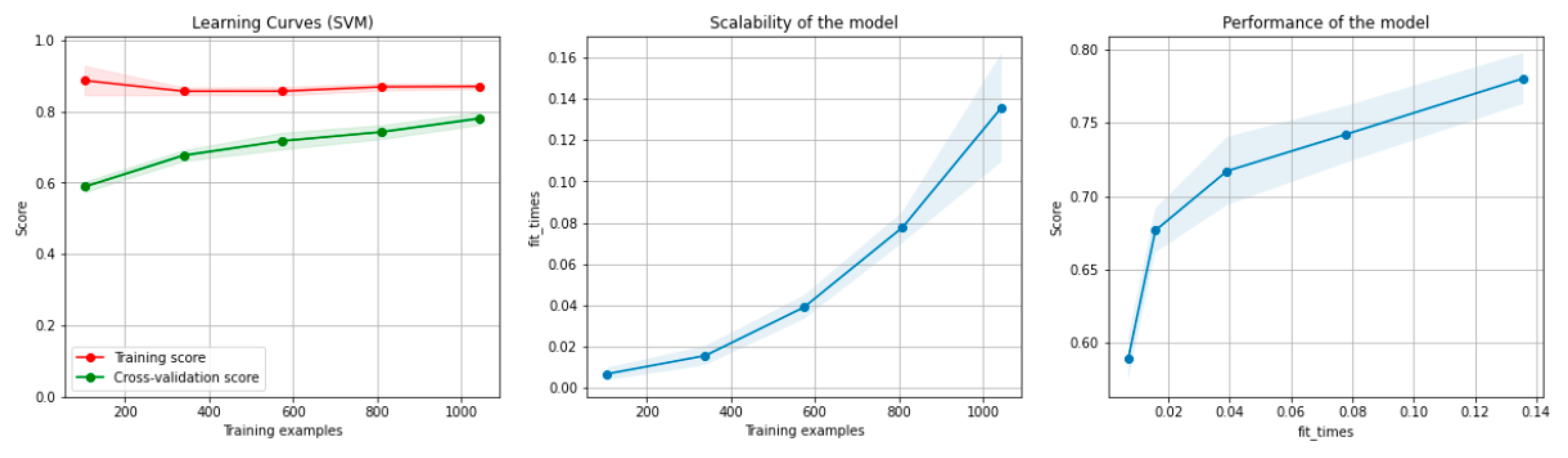
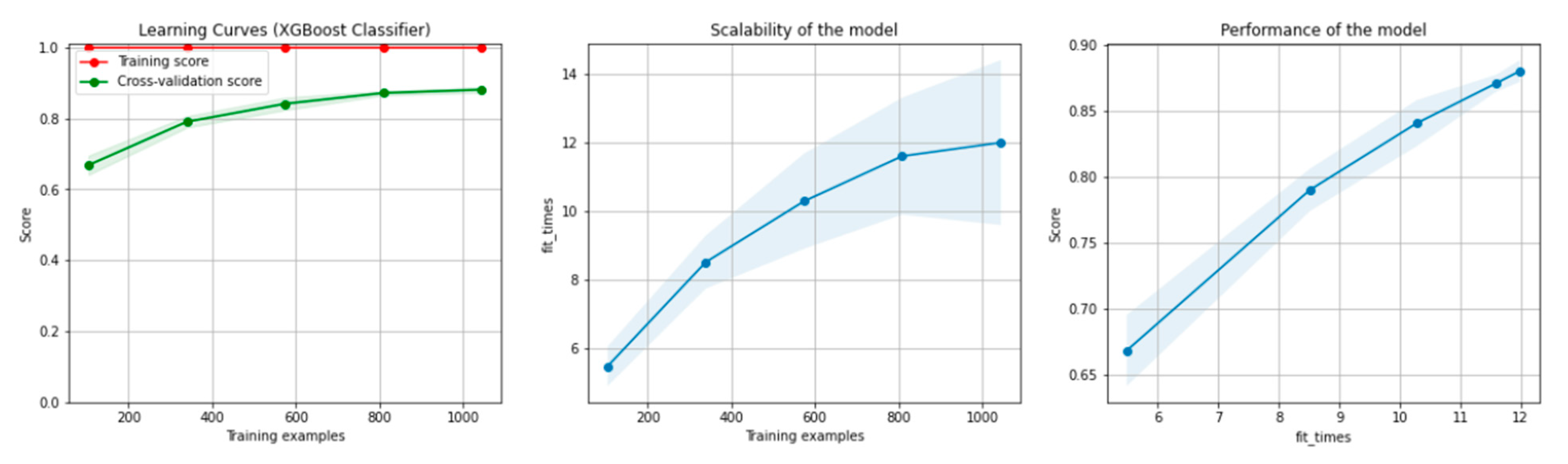
7.1. Machine Learning Methods
7.1.1. Classification Algorithms
- The classification report, which presents precision, recall, F1 score and support for both classes. Precision computes the proportion of positive identifications which are actually correct. Recall (sensitivity or true positive rate) calculates the fraction of true positives that are correctly identified. F1 score is the harmonic mean of precision and recall. It is more informative when the dataset is imbalanced [1], as in our case. Support represents the number of occurrences of each class in the dataset, a metric that indicates if the distribution of observations is balanced or imbalanced.
- The confusion matrix, a table called a contingency table, with two rows and two columns that contain: the rate of observations correctly predicted as negatives (True Negatives), the rate of observations incorrectly predicted as positives (False Positives), the proportion of observations incorrectly predicted as negatives (False Negatives) and the proportion of observations correctly predicted as positives (True Positives).
- Accuracy calculates the proportion of correct predictions (True Positives + True Negatives) from the total number of predictions.
- Specificity (or true negative rate) measures the proportion of negatives (True Negatives) which are correctly identified.
- The ROC Area Under Curve (ROC AUC) score is a reliable measurement used for binary classification that tells us how much the model distinguishes between classes. Some models can have a high F1 score on average, but a much lower F1 score for one of the classes. A high value of the ROC AUC score means that the model is capable of classifying 0s as 0s and 1s as 1s, so there is an increased rate of True Positives and True Negatives. Acceptable models have an ROC AUC score between 0.7 and 0.8 and those which exceed 0.8 or even 0.9 are considered very solid. The ROC AUC score is optimistic for imbalanced datasets.
- For any data point x from one class, wx + b > 0.
- For any data point x from another class, wx + b < 0.
7.1.2. Dimensionality Reduction and Feature Selection Algorithms
- We split the original dataset into training and testing subsets (70% training and 30% testing), using the train_test_split function from the scikit-learn library.
- We applied a five-fold cross-validation on the training subset that ran in parallel on all available cores. The values we tested for the penalty C were: {0.1, 1, 10, 100, 1000, 10,000} and for the kernel coefficient γ: {1/number_of_features, 1/number_of_features ∗ 10, 1/number_of_features ∗ 100, 1/number_of_features ∗ 1000}. The variable number_of_features represents the number of features, which is equal to k.
- The most optimized estimator (the model with the best set of hyperparameters that maximized classification accuracy on the training subset) was validated on the testing subset, computing the resulting confusion matrix, classification report, F1 score, ROC AUC score, accuracy, sensitivity and specificity.
- max_depth—the maximum depth of an individual tree. We picked three options: {3, 10, None}. None means that the nodes are expanded until all leaves are pure or until all leaves contain less than min_samples_split samples.
- min_samples_split—the minimum number of samples required for node splitting. A small value can cause overfitting and a large one leads to underfitting. The values to explore for this hyperparameter were: {10, 30, 50, 70, 90}.
- max_features—the number of features required for best node splitting in an individual tree. The options we considered were sqrt(number_of_features) and log2(number_of_features).
- n_estimators—the number of trees required for majority voting in the bagging algorithm after the individual trees have been trained separately. More trees lead to better classification rates. The options we tweaked were {100, 300, 500}.
7.2. Deep Learning Methods
- We used the train_test_split function from the scikit-library with a fixed seed for the random_state variable with the aim to always obtain the same, predictable slices from the input and the label arrays for the training and testing sessions, averaging the results for 10 rounds.
- We performed a five-fold cross-validation which is beneficial in the case of overfitting.
8. Results
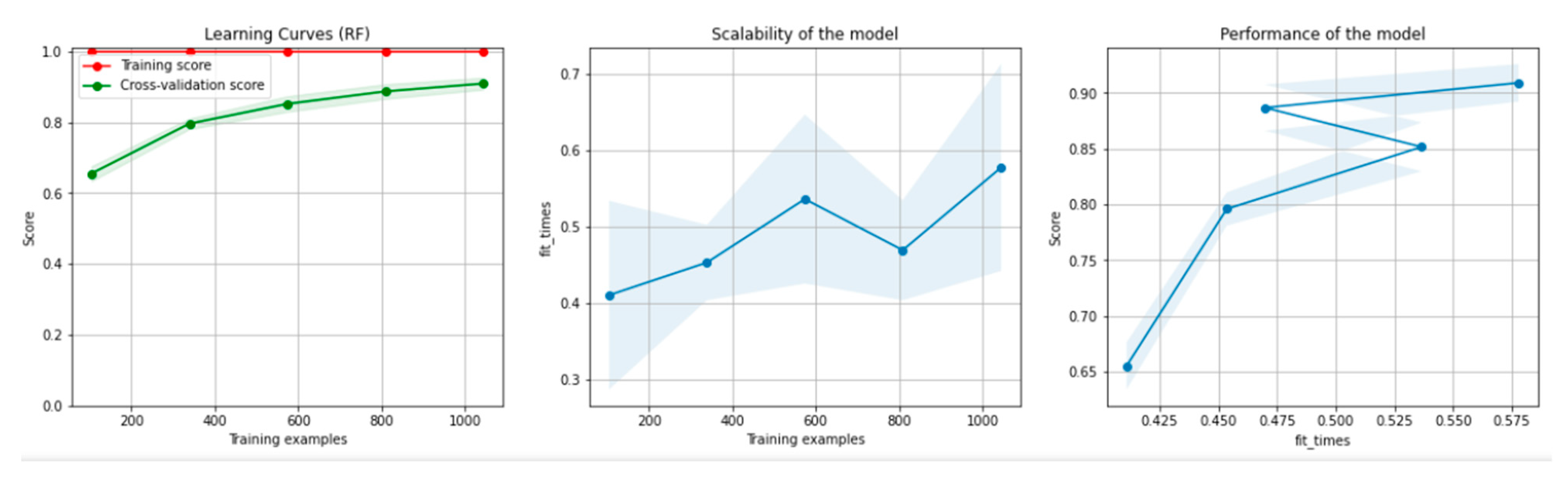
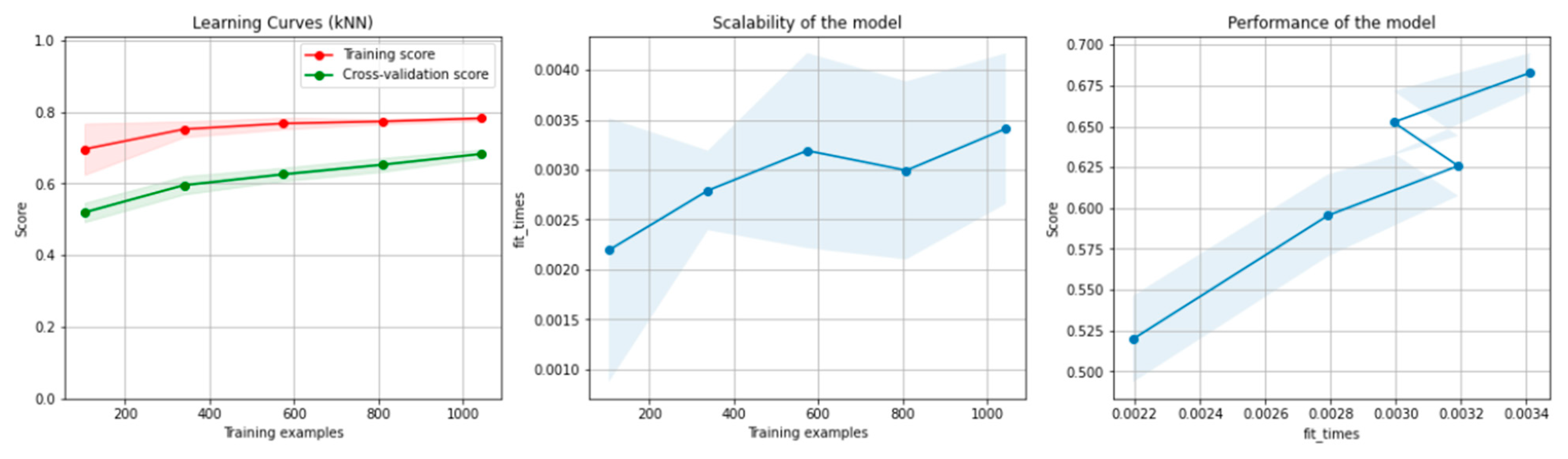
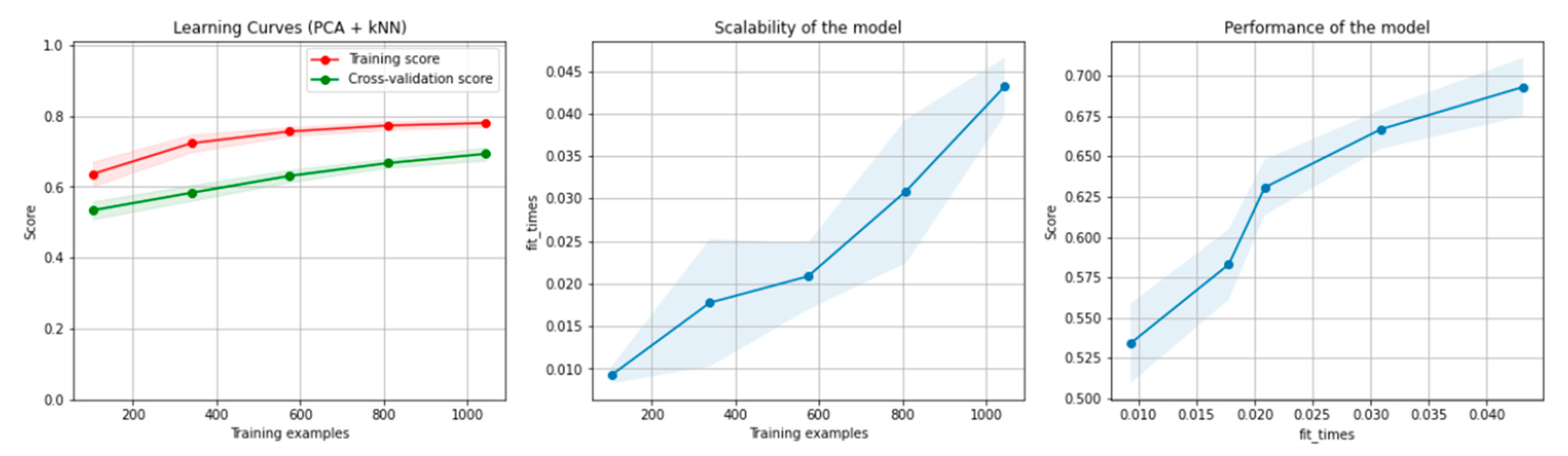
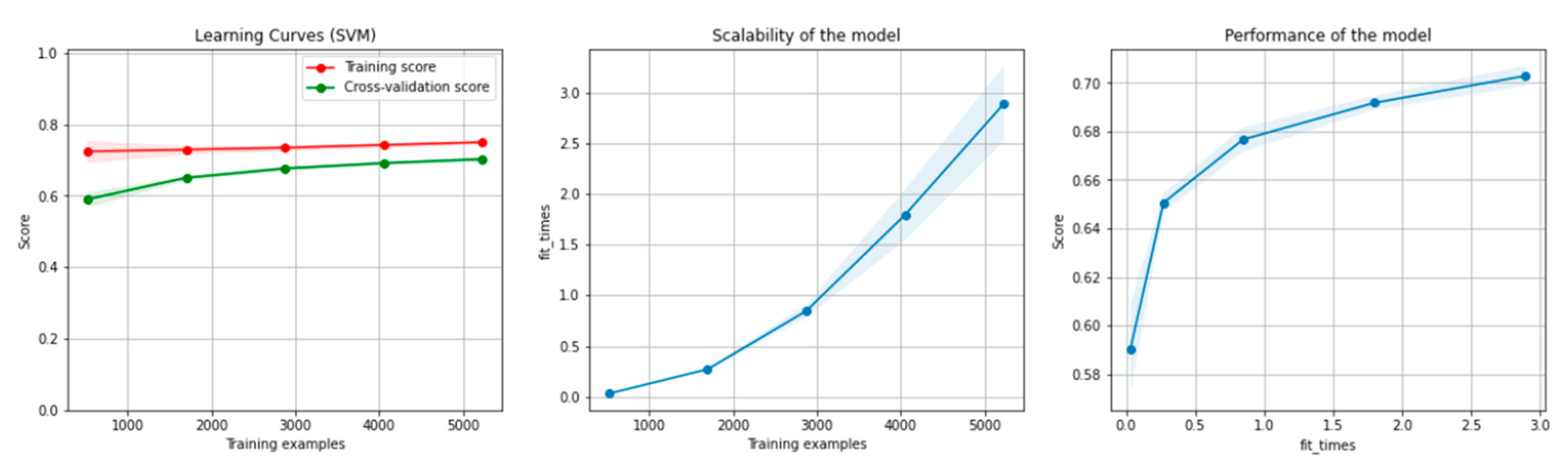
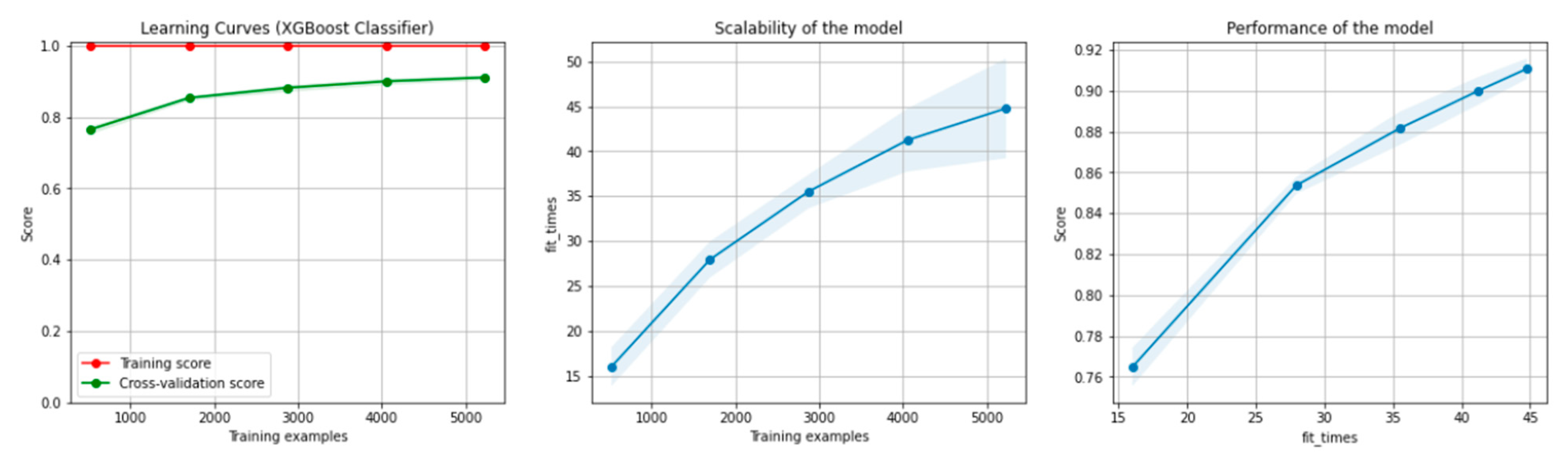
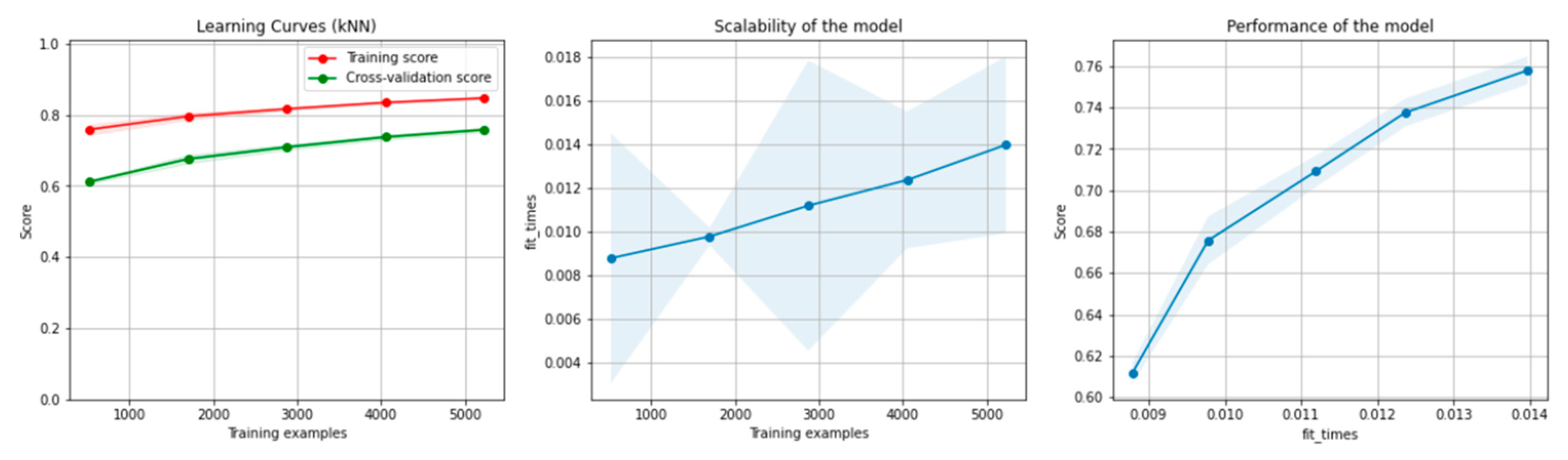
8.1. Results of the Machine Learning Algorithms
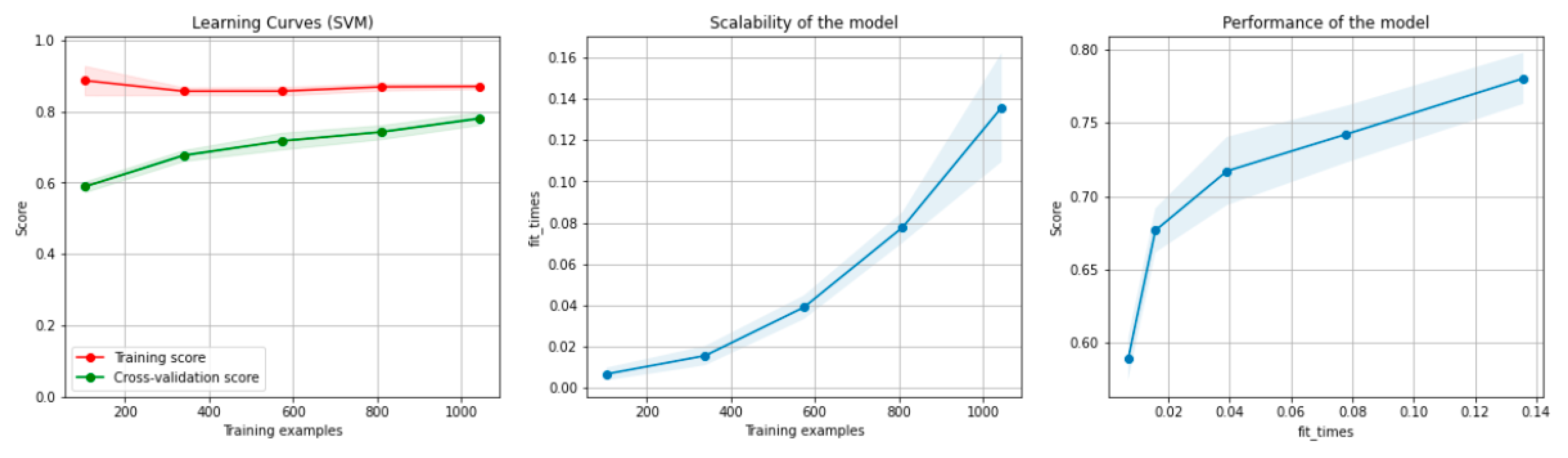
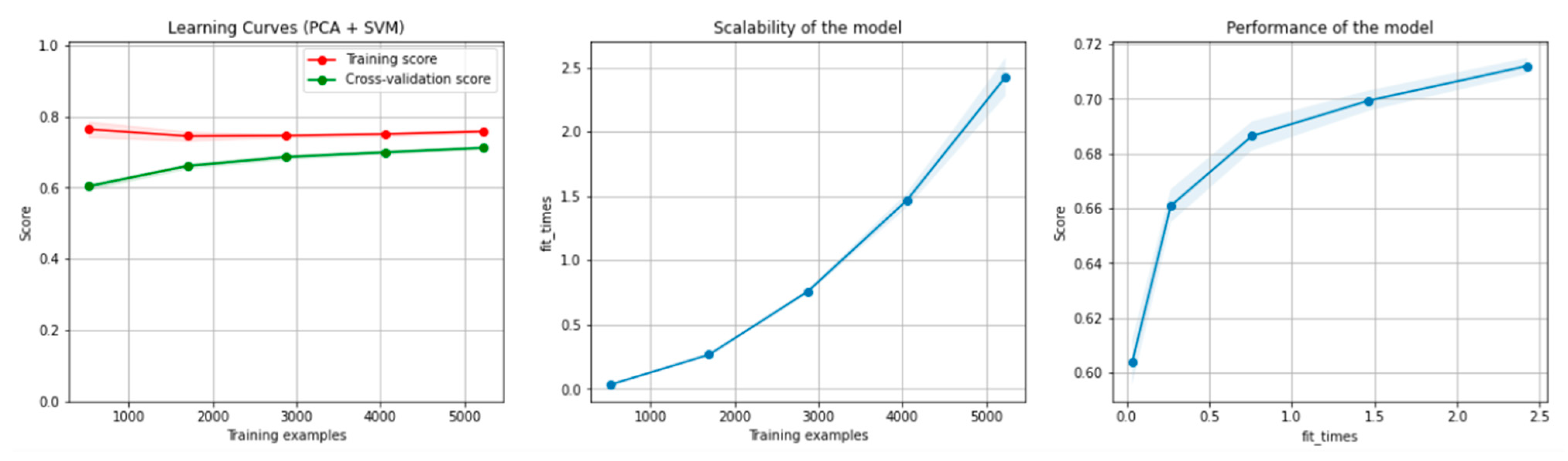
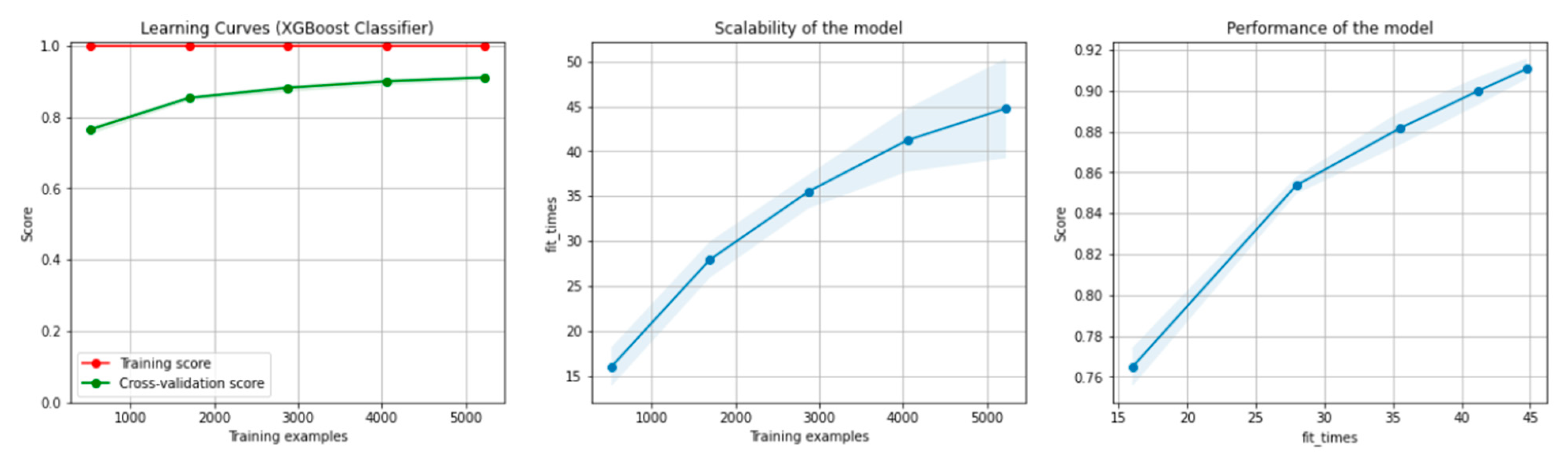
8.1.1. Results for the Non-Overlapping Dataset
8.1.2. Results for the Overlapping Dataset
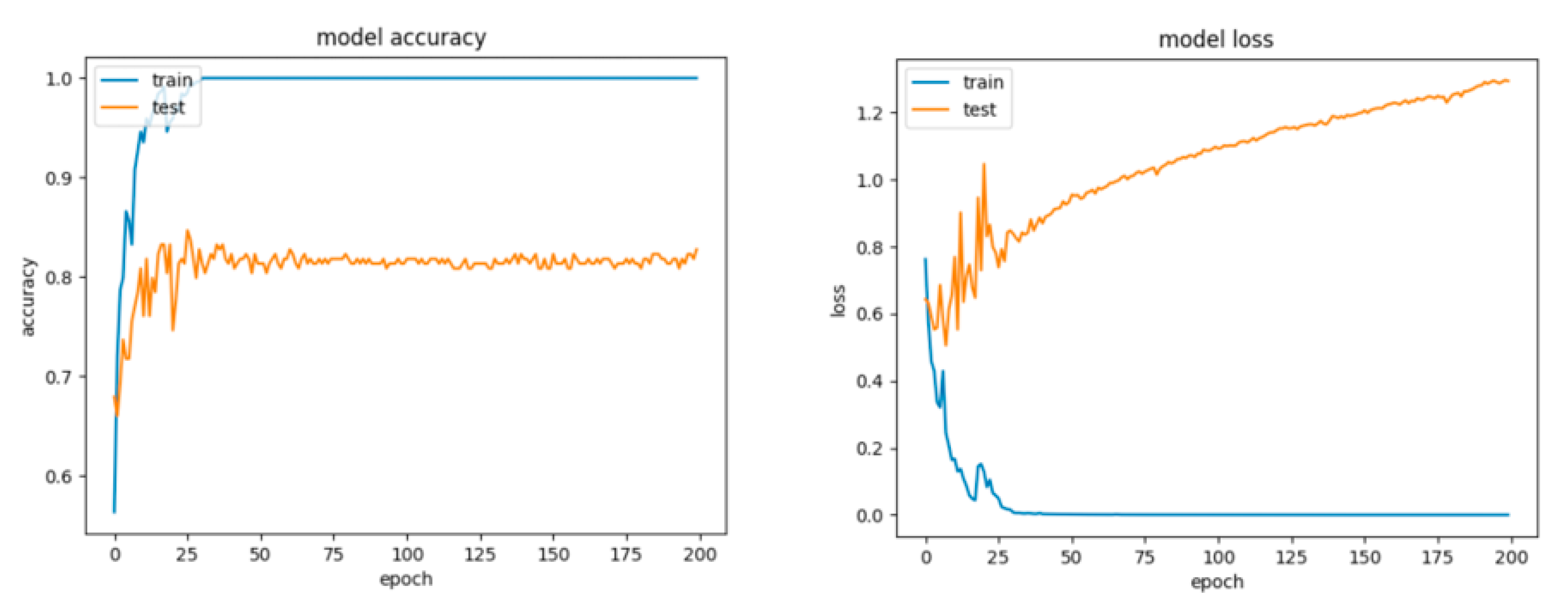
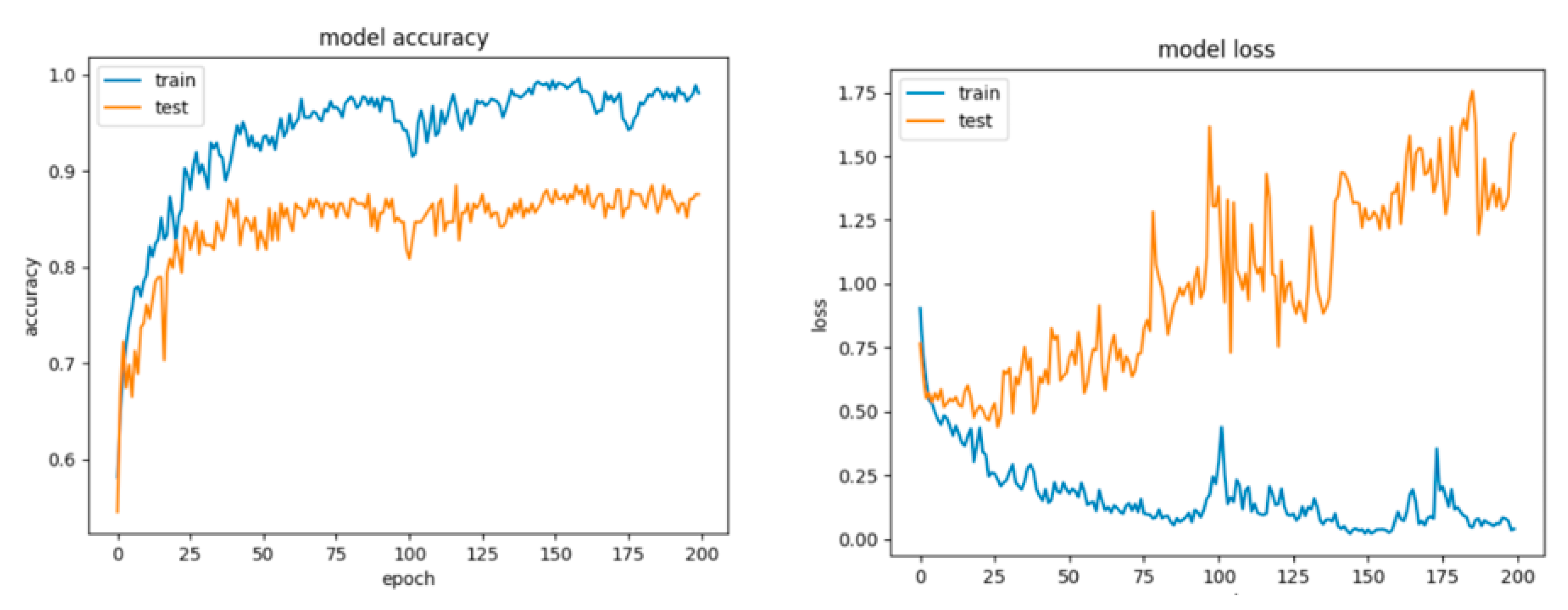
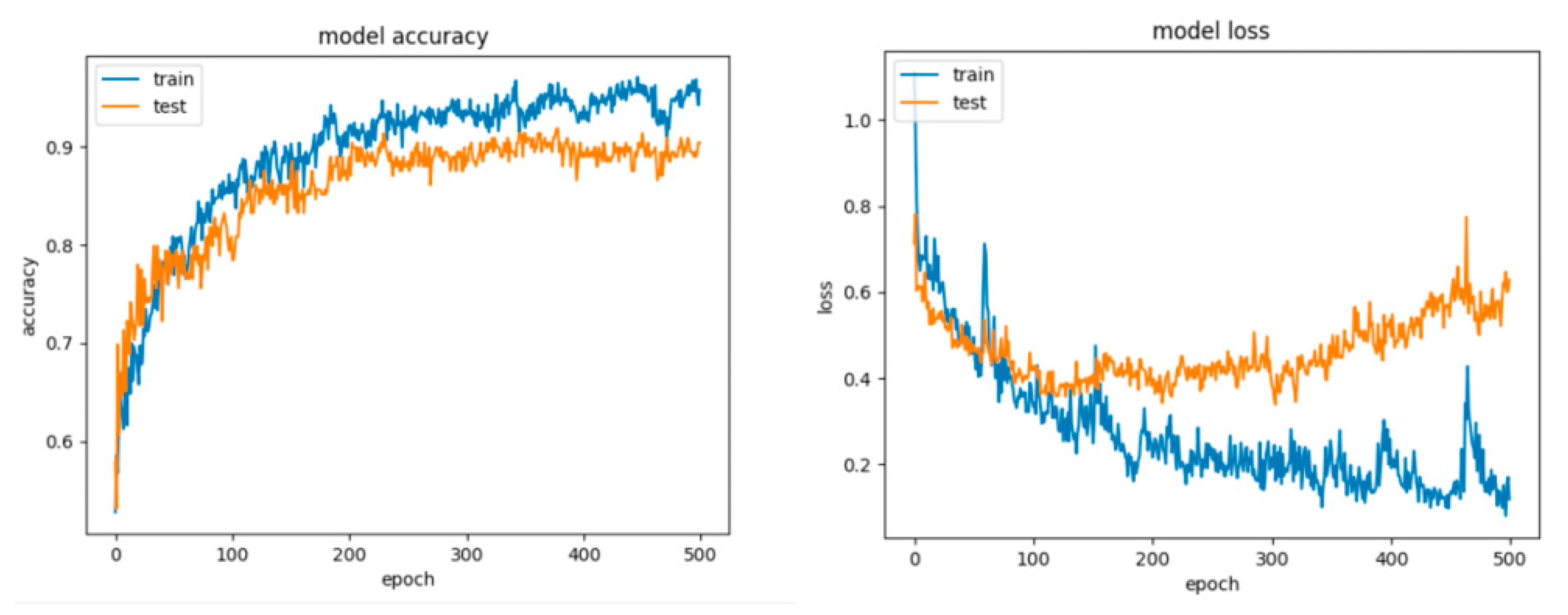
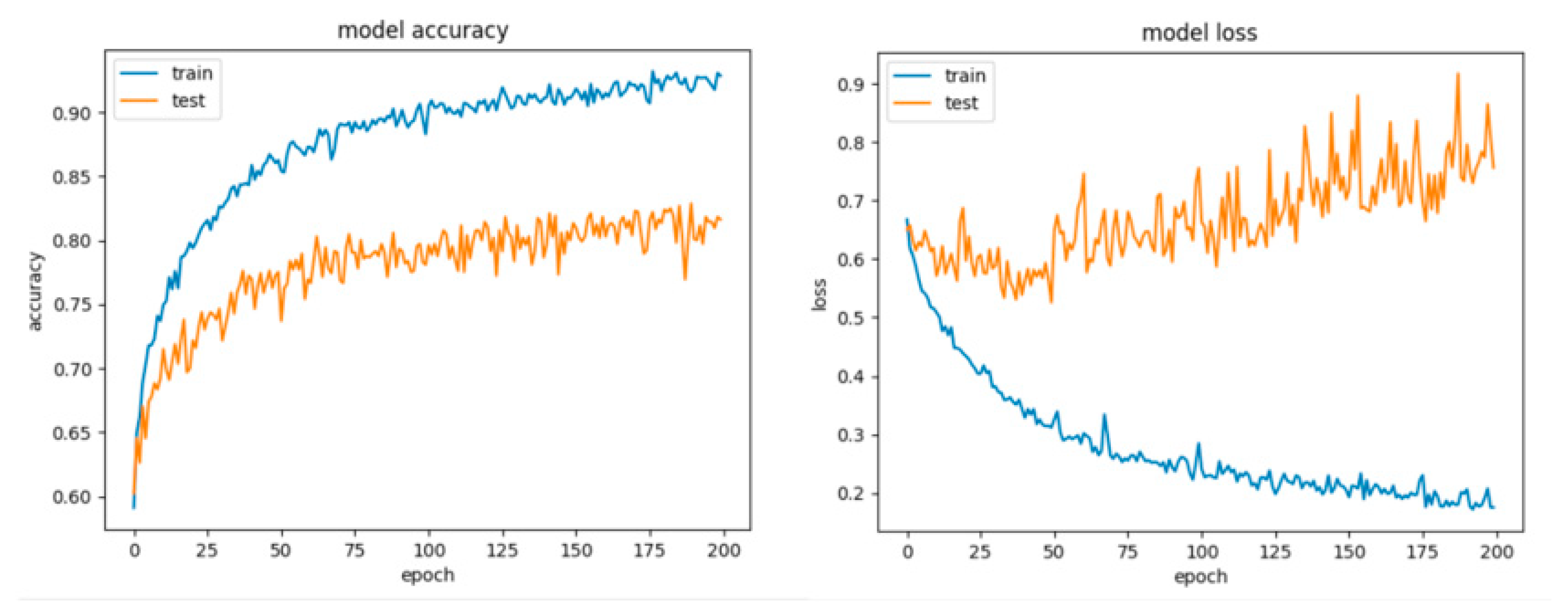
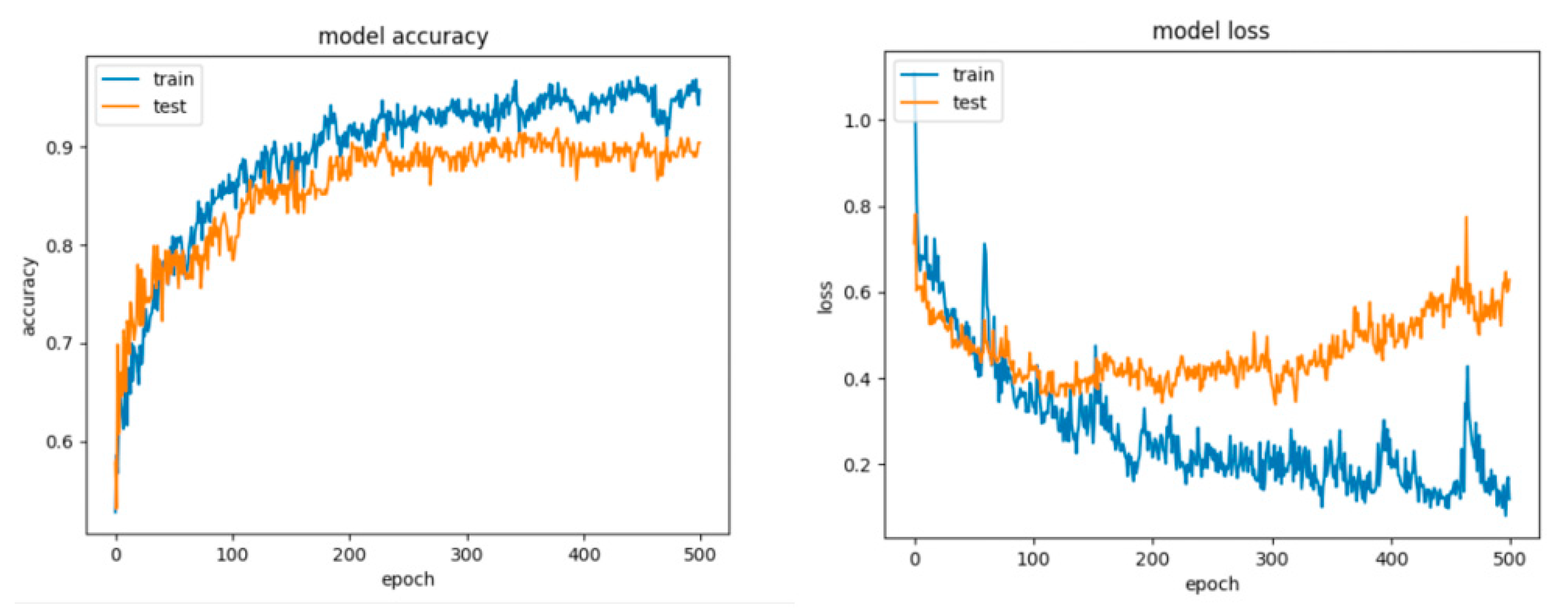
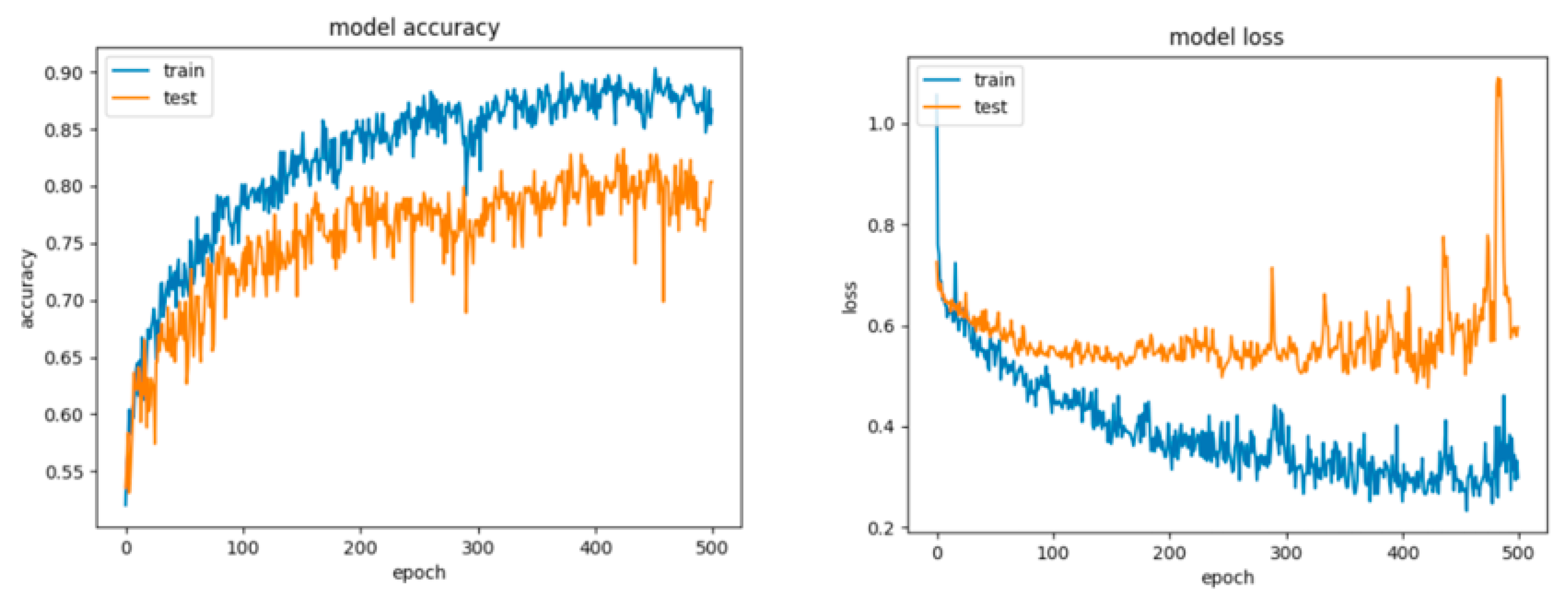
8.2. Results for the Artificial Networks Configurations
8.2.1. Results for the Non-Overlapping Dataset
8.2.2. Results for the Overlapping Dataset
9. Discussion
9.1. Discussion of the Results for the Non-Overlapping Dataset
9.2. Discussion of the Results for the Overlapping Dataset
9.3. Discussion of Feature Selection
9.4. Predictions Interpretation Using the LIME Method
9.5. Comparison with Similar Studies
9.6. Limitations of the Current Study
10. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Domínguez-Jiménez, J.; Campo-Landines, K.; Martínez-Santos, J.; Delahoz, E.; Contreras-Ortiz, S. A machine learning model for emotion recognition from physiological signals. Biomed. Signal Process. Control. 2020, 55, 101646. [Google Scholar] [CrossRef]
- Öhman, A.; Carlsson, K.; Lundqvist, D.; Ingvar, M. On the unconscious subcortical origin of human fear. Physiol. Behav. 2007, 92, 180–185. [Google Scholar] [CrossRef] [PubMed]
- Ressler, K.J. Amygdala Activity, Fear, and Anxiety: Modulation by Stress. Biol. Psychiatry 2010, 67, 1117–1119. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Ekman, P.; Sorenson, E.R.; Friesen, W.V. Pan-Cultural Elements in Facial Displays of Emotion. Science 1969, 164, 86–88. [Google Scholar] [CrossRef] [Green Version]
- Matsuda, Y.-T.; Fujimura, T.; Katahira, K.; Okada, M.; Ueno, K.; Cheng, K.; Okanoya, K. The implicit processing of categorical and dimensional strategies: An fMRI study of facial emotion perception. Front. Hum. Neurosci. 2013, 7, 551. [Google Scholar] [CrossRef] [Green Version]
- Russell, J.A. A circumplex model of affect. J. Pers. Soc. Psychol. 1980, 39, 1161–1178. [Google Scholar] [CrossRef]
- Shu, L.; Xie, J.; Yang, M.; Li, Z.; Li, Z.; Liao, D.; Xu, X.; Yang, X. A Review of Emotion Recognition Using Physiological Signals. Sensors 2018, 18, 2074. [Google Scholar] [CrossRef] [Green Version]
- Bradley, M.M.; Lang, P.J. Measuring emotion: The self-assessment manikin and the semantic differential. J. Behav. Ther. Exp. Psychiatry 1994, 25, 49–59. [Google Scholar] [CrossRef]
- Demaree, H.A.; Everhart, D.; Youngstrom, E.A.; Harrison, D.W. Brain Lateralization of Emotional Processing: Historical Roots and a Future Incorporating “Dominance”. Behav. Cogn. Neurosci. Rev. 2005, 4, 3–20. [Google Scholar] [CrossRef] [Green Version]
- Kołakowska, A.; Szwoch, W.; Szwoch, M. A Review of Emotion Recognition Methods Based on Data Acquired via Smartphone Sensors. Sensors 2020, 20, 6367. [Google Scholar] [CrossRef]
- Egger, M.; Ley, M.; Hanke, S. Emotion Recognition from Physiological Signal Analysis: A Review. Electron. Notes Theor. Comput. Sci. 2019, 343, 35–55. [Google Scholar] [CrossRef]
- Picard, R.W.; Healey, J. Affective wearables. Pers. Ubiquitous Comput. 1997, 1, 231–240. [Google Scholar] [CrossRef]
- Shaffer, F.; Ginsberg, J. An Overview of Heart Rate Variability Metrics and Norms. Front. Public Health 2017, 5, 258. [Google Scholar] [CrossRef] [Green Version]
- Schäfer, S.K.; Ihmig, F.R.; Neurohr, F.; Kiefer, S.; Staginnus, M.; Lass-Hennemann, J.; Michael, T. Effects of heart rate variability biofeedback during exposure to fear-provoking stimuli within spider-fearful individuals: Study protocol for a randomized controlled trial. Trials 2018, 19, 184. [Google Scholar] [CrossRef] [Green Version]
- Appelhans, B.M.; Luecken, L.J. Heart Rate Variability as an Index of Regulated Emotional Responding. Rev. Gen. Psychol. 2006, 10, 229–240. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.; Ji, L.; Liu, C. Heart rate variability monitoring for emotion and disorders of emotion. Physiol. Meas. 2019, 40, 064004. [Google Scholar] [CrossRef] [PubMed]
- Pinheiro, N.; Couceiro, R.; Henriques, J.; Muehlsteff, J.; Quintal, I.; Goncalves, L.; Carvalho, P. Can PPG be used for HRV analysis? In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; Volume 2016, pp. 2945–2949. [Google Scholar]
- Lee, M.; Lee, Y.K.; Lim, M.-T.; Kang, T.-K. Emotion Recognition Using Convolutional Neural Network with Selected Statistical Photoplethysmogram Features. Appl. Sci. 2020, 10, 3501. [Google Scholar] [CrossRef]
- Sarchiapone, M.; Gramaglia, C.; Iosue, M.; Carli, V.; Mandelli, L.; Serretti, A.; Marangon, D.; Zeppegno, P. The association between electrodermal activity (EDA), depression and suicidal behaviour: A systematic review and narrative synthesis. BMC Psychiatry 2018, 18, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Braithwaite, J.; Watson, D.; Robert, J.; Mickey, R. A Guide for Analysing Electrodermal Activity (EDA) & Skin Conductance Responses (SCRs) for Psychological Experiments; University of Birmingham: Birmingham, AL, USA, 2013. [Google Scholar]
- Wendt, J.; Lotze, M.; Weike, A.I.; Hosten, N.; Hamm, A.O. Brain activation and defensive response mobilization during sustained exposure to phobia-related and other affective pictures in spider phobia. Psychophysiology 2008, 45, 205–215. [Google Scholar] [CrossRef] [PubMed]
- Malik, M. Heart Rate Variability: Standards of Measurement, Physiological Interpretation and Clinical Use. Task Force of the European Society of Cardiology and the North American Society of Pacing and Electrophysiology. Ann. Noninvasive Electrocardiol. 1996, 1, 151–181. [Google Scholar] [CrossRef]
- Machajdik, J.; Hanbury, A. Affective image classification using features inspired by psychology and art theory. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 83–92. [Google Scholar]
- Francese, R.; Risi, M.; Tortora, G. A user-centered approach for detecting emotions with low-cost sensors. Multimed. Tools Appl. 2020, 79, 1–23. [Google Scholar] [CrossRef]
- Vijayakumar, S.; Flynn, R.; Murray, N. A Comparative Study of Machine Learning Techniques for Emotion Recognition from Peripheral Physiological Signals. In Proceedings of the ISSC 2020 31st Irish Signals and System Conference, Letterkenny, Ireland, 11–12 June 2020. [Google Scholar]
- Doma, V.; Pirouz, M. A comparative analysis of machine learning methods for emotion recognition using EEG and peripheral physiological signals. J. Big Data 2020, 7, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Pan, L.; Yin, Z.; She, S.; Song, A. Emotional State Recognition from Peripheral Physiological Signals Using Fused Nonlinear Features and Team-Collaboration Identification Strategy. Entropy 2020, 22, 511. [Google Scholar] [CrossRef]
- Oh, S.; Lee, J.-Y.; Kim, D.K. The Design of CNN Architectures for Optimal Six Basic Emotion Classification Using Multiple Physiological Signals. Sensors 2020, 20, 866. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, H.-W.; Huang, Y.-S.; Lin, C.-H.; Chien, J.-C.; Haraikawa, K.; Shieh, J.-S. Heart Rate Variability Signal Features for Emotion Recognition by Using Principal Component Analysis and Support Vectors Machine. In Proceedings of the 2016 IEEE 16th International Conference on Bioinformatics and Bioengineering (BIBE), Taichung, Taiwan, 31 October–2 November 2016; pp. 274–277. [Google Scholar]
- Miranda, J.A.; Canabal, M.F.; Lanza-Gutierrez, J.M.; Garcia, M.P.; Lopez-Ongil, C. Toward Fear Detection using Affect Recognition. In Proceedings of the 2019 XXXIV Conference on Design of Circuits and Integrated Systems (DCIS), Bilbao, Spain, 20–22 November 2019; pp. 1–4. [Google Scholar]
- Miranda, J.; Canabal, M.F.; Gutiérrez-Martín, L.; Lanza-Gutierrez, J.; Portela-García, M.; López-Ongil, C. Fear Recognition for Women Using a Reduced Set of Physiological Signals. Sensors 2021, 21, 1587. [Google Scholar] [CrossRef] [PubMed]
- Soleymani, M.; Lichtenauer, J.; Pun, T.; Pantic, M. A Multimodal Database for Affect Recognition and Implicit Tagging. IEEE Trans. Affect. Comput. 2012, 3, 42–55. [Google Scholar] [CrossRef] [Green Version]
- Bălan, O.; Moise, G.; Moldoveanu, A.; Leordeanu, M.; Moldoveanu, F. Fear Level Classification Based on Emotional Dimensions and Machine Learning Techniques. Sensors 2019, 19, 1738. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bălan, O.; Moise, G.; Petrescu, L.; Moldoveanu, A.; Leordeanu, M.; Moldoveanu, F. Emotion Classification Based on Biophysical Signals and Machine Learning Techniques. Symmetry 2019, 12, 21. [Google Scholar] [CrossRef] [Green Version]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.-S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. DEAP: A Database for Emotion Analysis; Using Physiological Signals. IEEE Trans. Affect. Comput. 2011, 3, 18–31. [Google Scholar] [CrossRef] [Green Version]
- Benedek, M.; Kaernbach, C. A continuous measure of phasic electrodermal activity. J. Neurosci. Methods 2010, 190, 80–91. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Granato, M.; Gadia, D.; Maggiorini, D.; Ripamonti, L.A. Feature Extraction and Selection for Real-Time Emotion Recognition in Video Games Players. In Proceedings of the 2018 14th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Las Palmas de Gran Canaria, Spain, 26–29 November 2018; pp. 717–724. [Google Scholar]
- Oskoei, M.A.; Hu, H. GA-based Feature Subset Selection for Myoelectric Classification. In Proceedings of the 2006 IEEE International Conference on Robotics and Biomimetics, Kunming, China, 17–20 December 2006; pp. 1465–1470. [Google Scholar]
- Ferdinando, H.; Ye, L.; Seppänen, T.; Alasaarela, E. Emotion Recognition by Heart Rate Variability. Aust. J. Basic Appl. Sci. 2014, 8, 50–55. [Google Scholar]
- Lee, T.; Chiu, H. Frequency-domain heart rate variability analysis performed by digital filters. In Proceedings of the 2010 Computing in Cardiology, Belfast, UK, 26–29 September 2010; pp. 589–592. [Google Scholar]
- Occam. Available online: https://www.britannica.com/topic/Occams-razor (accessed on 5 May 2021).
- Liu, Y.H. Python Machine Learning by Example, 3rd ed.; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- SMOTE. Available online: https://machinelearningmastery.com/smote-oversampling-for-imbalanced-classification/ (accessed on 5 May 2021).
- Scikit. Available online: https://scikit-learn.org/ (accessed on 5 May 2021).
- Keras. Available online: https://keras.io/ (accessed on 5 May 2021).
- Tensorflow. Available online: https://www.tensorflow.org/ (accessed on 5 May 2021).
- Matplot. Available online: https://matplotlib.org/ (accessed on 5 May 2021).
- Tensorboard. Available online: https://www.tensorflow.org/tensorboard (accessed on 5 May 2021).
- Heaton, J. The Number of Hidden Layers. Available online: https://www.heatonresearch.com/2017/06/01/hidden-layers.html (accessed on 5 May 2021).
- Sachdev, H.S. Choosing Number of Hidden Layers and Number of Hidden Neurons in Neural Networks. Available online: https://www.linkedin.com/pulse/choosing-number-hidden-layers-neurons-neural-networks-sachdev#:~:text=Choosing%20Hidden%20Layers&text=If%20data%20is%20less%20complex,hidden%20layers%20can%20be%20used (accessed on 5 May 2021).
- Kleiger, R.E.; Stein, P.K.; Bigger, J.T. Heart Rate Variability: Measurement and Clinical Utility. Ann. Noninvasive Electrocardiol. 2005, 10, 88–101. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Radecic, D.L. LIME: How to Interpret Machine Learning Models with Python. Available online: https://towardsdatascience.com/lime-how-to-interpret-machine-learning-models-with-python-94b0e7e4432e (accessed on 7 June 2021).
- Anton, C.; Mitrut, O.; Moldoveanu, A.; Moldoveanu, F.; Kosinka, J. A serious VR game for acrophobia therapy in an urban environment. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Virtual Reality (AIVR), Utrecht, The Netherlands, 14–18 December 2020; pp. 258–265. [Google Scholar]
- Toma, E.; Bălan, O.; Lambru, C.; Moldoveanu, A.; Moldoveanu, F. Ophiophobia 3D—A Game for Treating Fear of Snakes. In Proceedings of the 2020 IEEE 10th International Conference on Intelligent Systems (IS), Varna, Bulgaria, 28–30 August 2020; pp. 205–210. [Google Scholar]
- Maraloi, M.; Mitrut, O.; Moldoveanu, A.; Moldoveanu, F. Claustrophobia Virtual Reality Exposure Therapy—An Interactive Game for Reducing Anxiety in Closed Spaces. In Proceedings of the 36th International Business Information Management Association (IBIMA), Granada, Spain, 4–5 November 2020; p. 7469. [Google Scholar]
- Coada, D.; Mitrut, O.; Moldoveanu, A.; Moldoveanu, F. Pyrophobia-3D: A Virtual Envi-ronment for Fear of Fire Therapy. In Proceedings of the 36th International Business Information Management Association (IBIMA), Granada, Spain, 4–5 November 2020; pp. 6090–6104. [Google Scholar]
- Moldoveanu, A.; Langrand, C.; Balan, O.; Morar, A.; Mocanu, I.; Moldoveanu, F. The design principles of a game for treating fear of public speaking. In Proceedings of the EDULEARN20 Proceedings, IATED, Virtual Conference, Valencia, Spain, 6–7 July 2020; pp. 5506–5511. [Google Scholar]
- Ieracitano, C.; Mammone, N.; Hussain, A.; Morabito, F.C. A novel explainable machine learning approach for EEG-based brain-computer interface systems. Neural Comput. Appl. 2021, 1–14. [Google Scholar] [CrossRef]
- Doborjeh, Z.; Doborjeh, M.; Crook-Rumsey, M.; Taylor, T.; Wang, G.Y.; Moreau, D.; Krägeloh, C.; Wrapson, W.; Siegert, R.J.; Kasabov, N.; et al. Interpretability of Spatiotemporal Dynamics of the Brain Processes Followed by Mindfulness Intervention in a Brain-Inspired Spiking Neural Network Architecture. Sensors 2020, 20, 7354. [Google Scholar] [CrossRef] [PubMed]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SVM | PCA Dimensionality Reduction + SVM | XGBoost Feature Selection + SVM | Pearson Feature Selection + SVM | L1 Regularization Feature Selection + SVM | Random Forest Classification Feature Selection + SVM | Recursive Feature Elimination Feature Selection + SVM | |
|---|---|---|---|---|---|---|---|
| 5-fold cross-validation training | 86.7% | 92.7% | - | - | - | - | - |
| 5-fold cross-validation test | 70.1% | 75.7% | - | - | - | - | - |
| The best model | C = 10, gamma = 0.083 (1/n_features ∗ 10) | C = 1000, gamma = 0.083 (1/n_features ∗ 10) | 110 features C = 10, gamma = 0.09 (1/n_features ∗ 10) | 80 features C = 10, gamma = 0.125 (1/n_features ∗ 10) | 90 features C = 10, gamma = 0.11 (1/n_features ∗ 10) | 50 features C = 10, gamma = 0.2 (1/n_features ∗ 10) | 40 features C = 1000, gamma = 0.25 (1/n_features ∗ 10) |
| Cross-validation grid search test | 87.8% | 90.3% | 87.8% | 89.1% | 88.5% | 87.7% | 89.5% |
| F1 score | 93% | 93.5% | 92.8% | 92.8% | 88.4% | 92.8% | 92.8% |
| ROC AUC score | 92.7% | 93.5% | 92.1% | 92.3% | 87.7% | 92.1% | 92.7% |
| Accuracy | 93% | 93.5% | 92.8% | 92.8% | 88.6% | 92.8% | 92.8% |
| Sensitivity | 90% | 93.5% | 86% | 88% | 79.5% | 85.5% | 92% |
| Specificity | 95.5% | 93.5% | 98.3% | 96.7% | 95.9% | 98.7% | 93.5% |
| Average F1 score (10 iterations) | 91% | 92.3% | - | - | - | - | - |
| Average ROC AUC score (10 iterations) | 90.3% | 92% | - | - | - | - | - |
| Average accuracy (10 iterations) | 91% | 92.4% | - | - | - | - | - |
| Average sensitivity (10 iterations) | 83.9% | 89% | - | - | - | - | - |
| Average specificity (10 iterations) | 96.8% | 95.1% | - | - | - | - | - |
| GBT | RF | |
|---|---|---|
| 5-fold cross-validation training | 100% | 100% |
| 5-fold cross-validation test | 81% | 81.9% |
| The best model | Iteration 9 | max_depth = None, max_features = log2, min_samples_split = 10, n_estimators = 300 |
| Cross-validation grid search test | - | 87.4% |
| F1 score | 90.5% | 90.1% |
| ROC AUC score | 90% | 89.4% |
| Accuracy | 90.6% | 90.2% |
| Sensitivity | 84.5% | 83% |
| Specificity | 95.5% | 95.9% |
| Average F1 score (10 iterations) | 88.9% | 88.7% |
| Average ROC AUC score (10 iterations) | 88.4% | 88.2% |
| Average accuracy (10 iterations) | 89% | 88.8% |
| Average sensitivity (10 iterations) | 83.4% | 81.9% |
| Average specificity (10 iterations) | 93.5% | 94.4% |
| kNN | PCA Dimensionality Reduction + kNN | XGBoost Feature Selection + kNN | Pearson Feature Selection + kNN | L1 Regularization Feature Selection + kNN | Random Forest Classification Feature Selection + kNN | |
|---|---|---|---|---|---|---|
| 5-fold cross-validation training | 75.4% | 73.3% | - | - | - | - |
| 5-fold cross-validation test | 61.5% | 62.1% | - | - | - | - |
| The best model | leaf_size = 5, n_neighbors = 4, p = 1 | leaf_size = 42, n_neighbors = 4, p = 1 | 30 features leaf_size = 5, n_neighbors = 3, p = 1 | 90 features leaf_size = 5, n_neighbors = 4, p = 1 | 80 features leaf_size = 5, n_neighbors = 4, p = 1 | 60 features leaf_size = 5, n_neighbors = 4, p = 1 |
| Cross-validation grid search test | 75.8% | 72.8% | 76.4% | 75.7% | 75.4% | 76% |
| F1 score | 80.2% | 78.6% | 80.3% | 80.4% | 79.5% | 80.2% |
| ROC AUC score | 80.8% | 79.6% | 81.4% | 81% | 80.1% | 80.5% |
| Accuracy | 80.1% | 78.6% | 80.4% | 80.4% | 79.5% | 80.1% |
| Sensitivity | 87% | 89% | 91% | 87% | 86% | 83.5% |
| Specificity | 74.6% | 70.2% | 71.8% | 75.1% | 74.2% | 77.5% |
| Average F1 score (10 iterations) | 77.2% | 75.1% | - | - | - | - |
| Average ROC AUC score (10 iterations) | 77.9% | 76.6% | - | - | - | - |
| Average accuracy (10 iterations) | 77.2% | 75.3% | - | - | - | - |
| Average sensitivity (10 iterations) | 84.4% | 88.7% | - | - | - | - |
| Average specificity (10 iterations) | 71.4% | 64.6% | - | - | - | - |
| SVM | kNN |
|---|---|
| GSR_fmd[W3] | SCL_fmd[W2] |
| HRV_NN50[W3] | GSR_fmd[W1] |
| HRV_hlr[W1] | HRV_hlr[W1] |
| GSR_fmd[W2] | SCR_fmd[W1] |
| SCR_fmd[W1] | HRV_NN50[W3] |
| HRV_NN20[W2] | GSR_fmd[W3] |
| HRV_hlr[W3] | HRV_NN20[W2] |
| SCL_fmd[W1] | SCR_ssc[W2] |
| SCR_wamp[W1] | SCL_fmd[W3] |
| SCR_mav[W2] | SCL_fmd[W1] |
| SVM | PCA Dimensionality Reduction + SVM | XGBoost Feature Selection + SVM | Pearson Feature Selection + SVM | L1 Regularization Feature Selection + SVM | Random Forest Classification Feature Selection + SVM | Recursive Feature Elimination Feature Selection + SVM | |
|---|---|---|---|---|---|---|---|
| 5-fold cross-validation training | 73.6% | 75.2% | - | - | - | - | - |
| 5-fold cross-validation test | 66.2% | 67.2% | - | - | - | - | - |
| The best model | C = 10, gamma = 0.25 (1/n_features ∗ 10) | C = 10, gamma = 0.25 (1/n_features ∗ 10) | 40 features C = 10, gamma = 0.25 (1/n_features ∗ 10) | 40 features C = 10, gamma = 0.25 (1/n_features ∗ 10) | 40 features C = 10, gamma = 0.25 (1/n_features ∗ 10) | 40 features C = 10, gamma = 0.25 (1/n_features ∗ 10) | 40 features C = 10, gamma = 0.25 (1/n_features ∗ 10) |
| Cross-validation grid search test | 85.3% | 83.9% | 85.1% | 85.5% | 85.5% | 86.2% | 86.1% |
| F1 score | 88.9% | 85.8% | 89.2% | 87.8% | 88.1% | 87% | 87.5% |
| ROC AUC score | 88.8% | 86% | 89.2% | 87.8% | 88% | 86.9% | 87.4% |
| Accuracy | 88.9% | 85.8% | 89.2% | 87.8% | 88.1% | 87% | 87.5% |
| Sensitivity | 87.4% | 87.6% | 89.2% | 87.9% | 86.7% | 85.8% | 86.8% |
| Specificity | 90.2% | 84.4% | 89.1% | 87.7% | 89.3% | 88% | 88.1% |
| Average F1 score (10 iterations) | 87.9% | 86% | - | - | - | - | - |
| Average ROC AUC score (10 iterations) | 87.8% | 86.2% | - | - | - | - | - |
| Average accuracy (10 iterations) | 87.9% | 86% | - | - | - | - | - |
| Average sensitivity (10 iterations) | 87% | 88.6% | - | - | - | - | - |
| Average specificity (10 iterations) | 88.6% | 83.9% | - | - | - | - | - |
| GBT | RF | |
|---|---|---|
| 5-fold cross-validation training | 100% | 100% |
| 5-fold cross-validation test | 86.2% | 85.4% |
| The best model | Iteration 7 | max_depth = None, max_features = sqrt, min_samples_split = 10, n_estimators = 300 |
| Cross-validation grid search test | - | 89.3% |
| F1 score | 92.2% | 90.2% |
| ROC AUC score | 91.7% | 89.6% |
| Accuracy | 92.2% | 90.3% |
| Sensitivity | 87.3% | 83.4% |
| Specificity | 96.2% | 95.8% |
| Average F1 score (10 iterations) | 91.7% | 89.8% |
| Average ROC AUC score (10 iterations) | 91.1% | 89.2% |
| Average accuracy (10 iterations) | 91.7% | 89.9% |
| Average sensitivity (10 iterations) | 85.4% | 82.2% |
| Average specificity (10 iterations) | 96.8% | 96.1% |
| kNN | PCA Dimensionality Reduction + kNN | XGBoost Feature Selection + kNN | Pearson Feature Selection + kNN | L1 Regularization Feature Selection + kNN | Random Forest Classification Feature Selection + kNN | |
|---|---|---|---|---|---|---|
| 5-fold cross-validation training | 81% | 80.6% | - | - | - | - |
| 5-fold cross-validation test | 69.8% | 69.3% | - | - | - | - |
| The best model | leaf_size = 5, n_neighbors = 4, p = 1 | leaf_size = 6, n_neighbors = 4, p = 1 | 30 features leaf_size = 5, n_neighbors = 3, p = 1 | 40 features leaf_size = 5, n_neighbors = 3, p = 1 | 40 features leaf_size = 5, n_neighbors = 4, p = 1 | 30 features leaf_size = 5, n_neighbors = 3, p = 1 |
| Cross-validation grid search test | 78.6% | 75.7% | 79.9% | 80% | 79.8% | 80.6% |
| F1 score | 84% | 78.7% | 81.7% | 80.2% | 81% | 81.8% |
| ROC AUC score | 83.9% | 78.7% | 82.5% | 81.3% | 81% | 82.5% |
| Accuracy | 84% | 78.7% | 81.7% | 80.2% | 81% | 81.7% |
| Sensitivity | 83.3% | 79.3% | 90% | 91.1% | 81% | 89.3% |
| Specificity | 84.6% | 78.3% | 75.1% | 71.4% | 81% | 75.7% |
| Average F1 score (10 iterations) | 81.7% | 77.8% | - | - | - | - |
| Average ROC AUC score (10 iterations) | 81.8% | 78.2% | - | - | - | - |
| Average accuracy (10 iterations) | 81.7% | 77.8% | - | - | - | - |
| Average sensitivity (10 iterations) | 83.1% | 81.1% | - | - | - | - |
| Average specificity (10 iterations) | 80.6% | 75.2% | - | - | - | - |
| SVM | kNN |
|---|---|
| SCL_fmd | SCL_fmd |
| SCR_fmd | GSR_fmd |
| HRV_NN20 | SCR_fmd |
| GSR_fmd | HRV_NN50 |
| HRV_NN50 | HRV_hlr |
| HRV_hlr | HRV_NN20 |
| GSR_mav | GSR_mav |
| SCL_mav | SCL_mav |
| HRV_pNN20 | GSR_str |
| GSR_nimp | GSR_nimp |
| Number of Hidden Layers | Number of Neurons on the Hidden Layer | Dropout | Number of Epochs | |
|---|---|---|---|---|
| Config. 1 | - | - | - | 200 |
| Config. 2 | - | - | 0.5 for the input layer | 200 |
| Config. 3 | - | - | 0.8 for the input layer | 500 |
| Config. 4 | 1 | 80 | 0.8 for the input layer | 500 |
| Config. 5 | 1 | 11 | 0.8 for the input layer | 500 |
| Config. 1 | Config. 2 | Config. 3 | Config. 4 | Config. 5 | |
|---|---|---|---|---|---|
| F1 score | 87.5% | 85.7% | 86.3% | 85.2% | 83.7% |
| ROC AUC score | 87.7% | 85.5% | 86.1% | 85.9% | 83.6% |
| Accuracy | 87.5% | 85.7% | 86.4% | 85.3% | 83.7% |
| Sensitivity | 90.2% | 83.4% | 82.5% | 93.2% | 82.5% |
| Specificity | 85.1% | 87.6% | 89.7% | 78.6% | 84.7% |
| Cross-Validation | Test (10 Runs Averaged) | |
|---|---|---|
| F1 score | 97.4% | 92.8% |
| ROC AUC score | 97.5% | 92.4% |
| Accuracy | 97.4% | 92.8% |
| Sensitivity | 98.4% | 87.8% |
| Specificity | 96.6% | 97.1% |
| Number of Hidden Layers | Number of Neurons on the Hidden Layers | Dropout | Number of Epochs | |
|---|---|---|---|---|
| Config. 1 | - | - | - | 200 |
| Config. 2 | - | - | 0.5 for the input layer | 200 |
| Config. 3 | - | - | - | 500 |
| Config. 4 | - | - | 0.5 for the input layer | 500 |
| Config. 5 | 1 | 6 | 0.5 for the input layer | 200 |
| Config. 6 | 2 | 27 and 6 | 0.5 for the input layer | 200 |
| Config. 7 | 3 | 30, 20 and 10 | 0.5 for the input layer | 200 |
| Config. 1 | Config. 2 | Config. 3 | Config. 4 | Config. 5 | Config. 6 | Config. 7 | |
|---|---|---|---|---|---|---|---|
| F1 score | 81% | 77.6% | 80.2% | 77.2% | 75.7% | 73.7% | 67.2% |
| ROC AUC score | 80.8% | 77.4% | 80.6% | 77.6% | 76% | 75.6% | 71.3% |
| Accuracy | 81% | 77.5% | 80.1% | 77.1% | 75.6% | 73.9% | 68.5% |
| Sensitivity | 79.3% | 76.9% | 84.5% | 81.4% | 79.2% | 90% | 94.9% |
| Specificity | 82.4% | 78% | 76.7% | 73.8% | 72.7% | 61.3% | 47.8% |
| Cross-Validation | Test (10 Runs Averaged) | |
|---|---|---|
| F1 score | 85.7% | 78.3% |
| ROC AUC score | 85.6% | 78.8% |
| Accuracy | 85.8% | 78.2% |
| Sensitivity | 83.8% | 83.9% |
| Specificity | 87.3% | 73.7% |
| SVM | DT | kNN | ||||
|---|---|---|---|---|---|---|
| Grid search for the best configuration | Average over 10 iterations | Grid search for the best configuration | Average over 10 iterations | Grid search for the best configuration | Average over 10 iterations | |
| p | 0.48 | 0.51 | 0.85 | 0.92 | 0.98 | 0.72 |
| F | 0.92 | 0.47 | 0.03 | 0.008 | 0.13 | 0.12 |
| SVM | DT | kNN | ||||
|---|---|---|---|---|---|---|
| Grid search for the best configuration | Average over 10 iterations | Grid search for the best configuration | Average over 10 iterations | Grid search for the best configuration | Average over 10 iterations | |
| p | 0.012 | 0.06 | 0.41 | 0.52 | 0.37 | 0.006 |
| F | 3.93 | 4.65 | 0.72 | 0.44 | 1.1 | 13.64 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Petrescu, L.; Petrescu, C.; Oprea, A.; Mitruț, O.; Moise, G.; Moldoveanu, A.; Moldoveanu, F. Machine Learning Methods for Fear Classification Based on Physiological Features. Sensors 2021, 21, 4519. https://doi.org/10.3390/s21134519
Petrescu L, Petrescu C, Oprea A, Mitruț O, Moise G, Moldoveanu A, Moldoveanu F. Machine Learning Methods for Fear Classification Based on Physiological Features. Sensors. 2021; 21(13):4519. https://doi.org/10.3390/s21134519
Chicago/Turabian StylePetrescu, Livia, Cătălin Petrescu, Ana Oprea, Oana Mitruț, Gabriela Moise, Alin Moldoveanu, and Florica Moldoveanu. 2021. "Machine Learning Methods for Fear Classification Based on Physiological Features" Sensors 21, no. 13: 4519. https://doi.org/10.3390/s21134519
APA StylePetrescu, L., Petrescu, C., Oprea, A., Mitruț, O., Moise, G., Moldoveanu, A., & Moldoveanu, F. (2021). Machine Learning Methods for Fear Classification Based on Physiological Features. Sensors, 21(13), 4519. https://doi.org/10.3390/s21134519