
Cross Attention Squeeze Excitation Network (CASE-Net) for Whole Body Fetal MRI Segmentation

 ,
,
Abstract
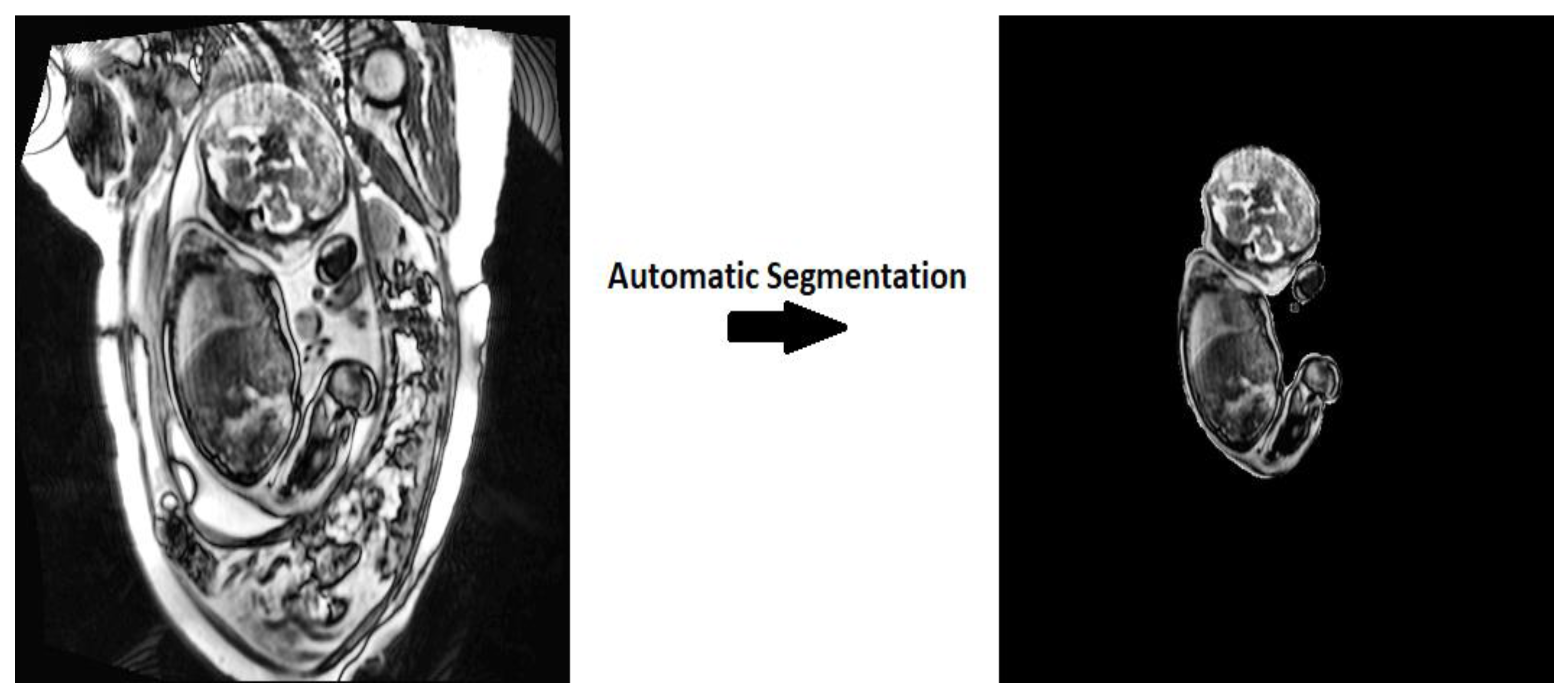
1. Introduction
- Curation of a manually segmented sagittal fetal MRI dataset;
- Design of a novel CNN-based architecture for the automatic segmentation of fetal MRI images, with comparable results to state-of-the-art methods.
2. Materials and Methods
2.1. Acquisition
2.2. Dataset
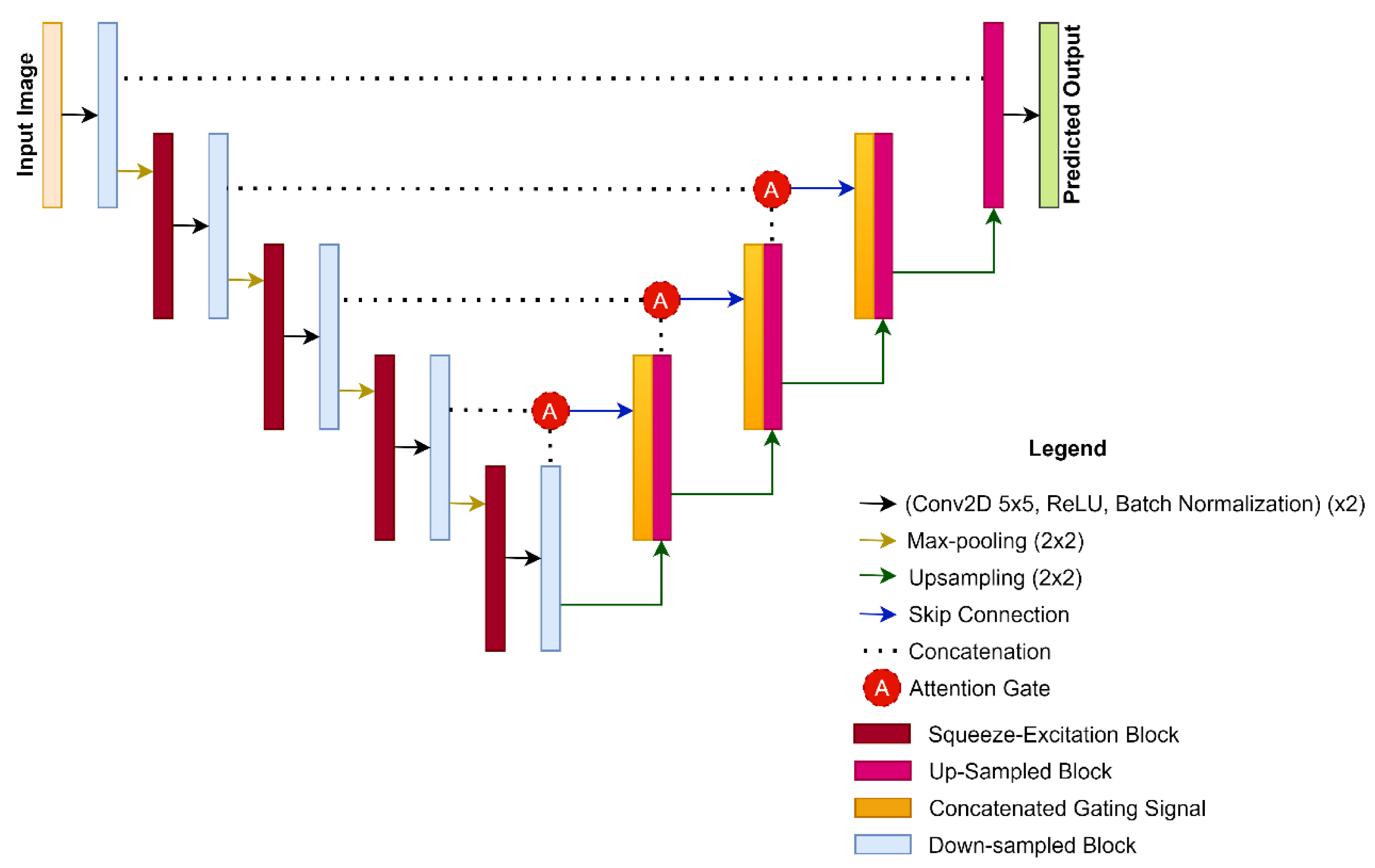
2.3. CASE-Net Architecture
2.4. Squeeze-and-Excitation Networks
2.5. Attention Modules
2.6. Hyper Parametric Changes
2.7. Experiments
2.8. Statistical Analyses
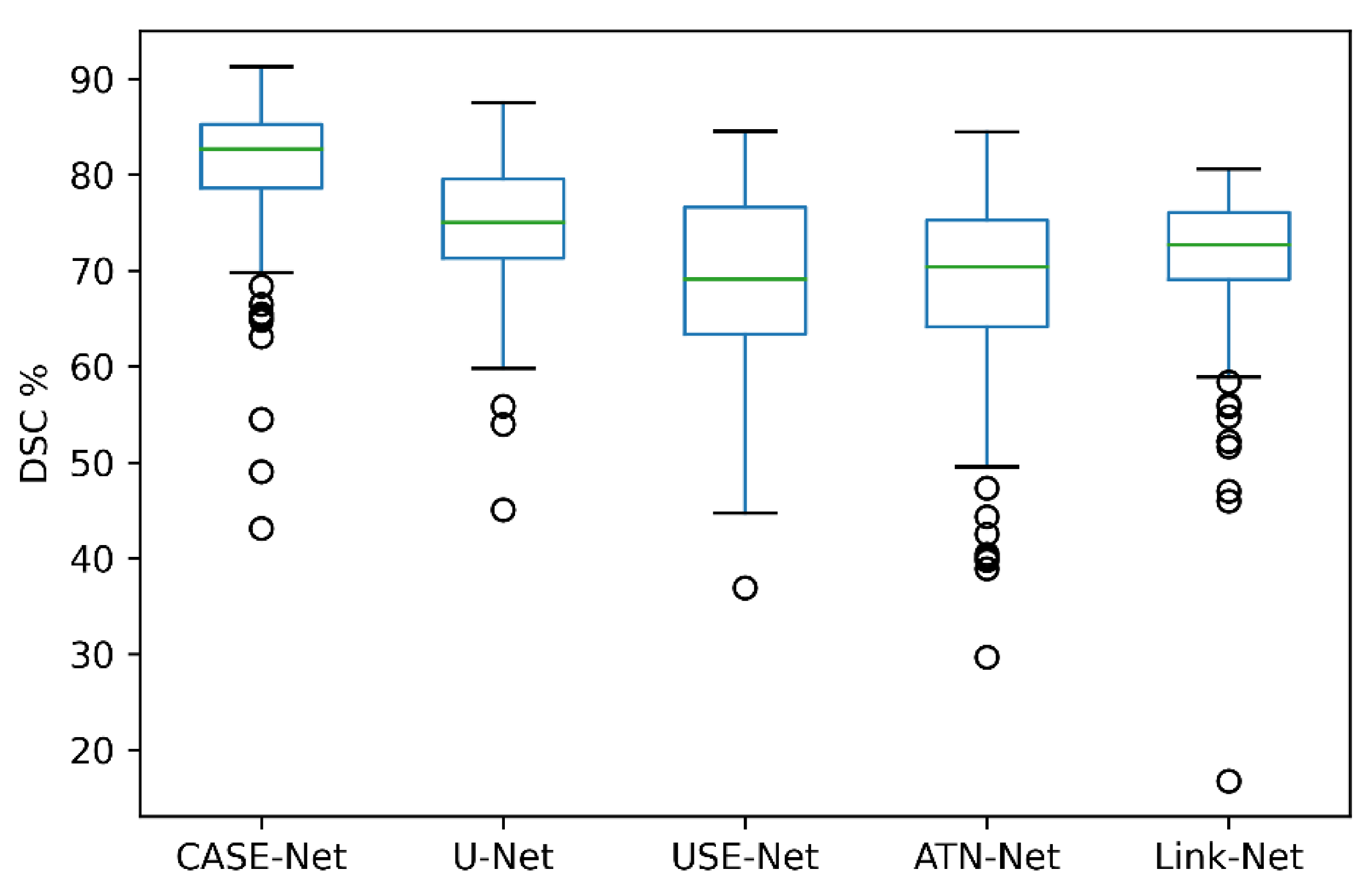
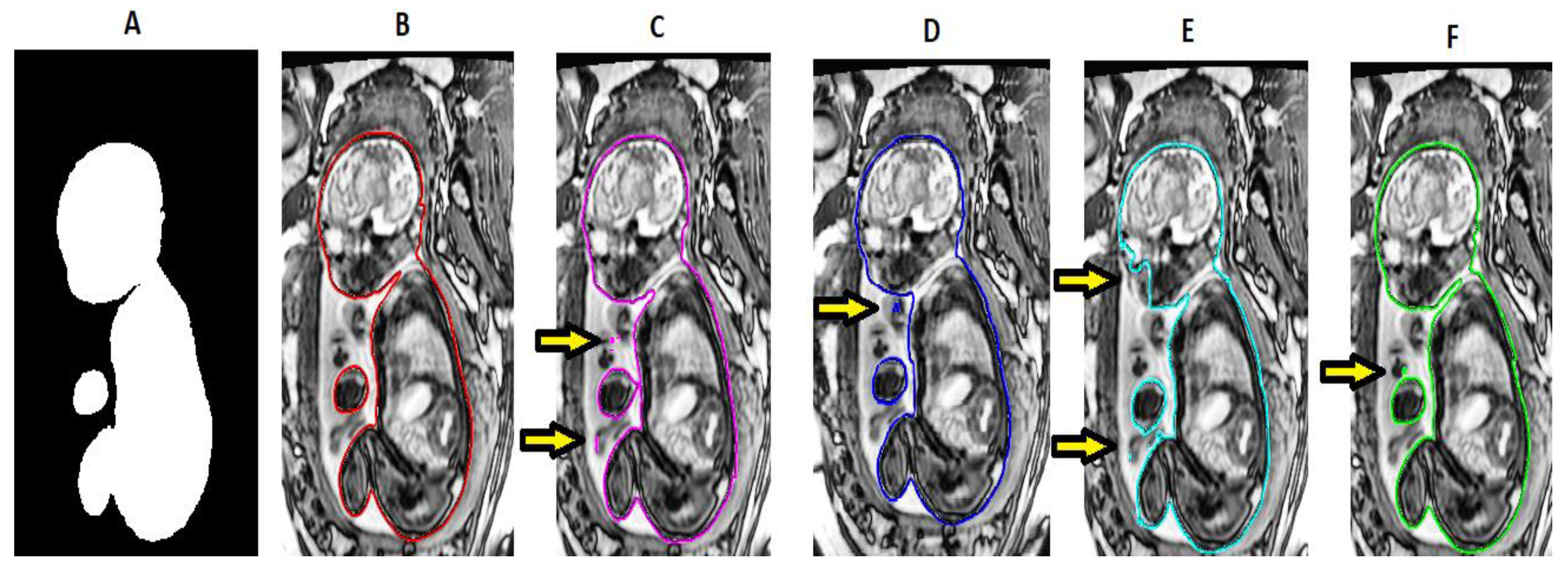
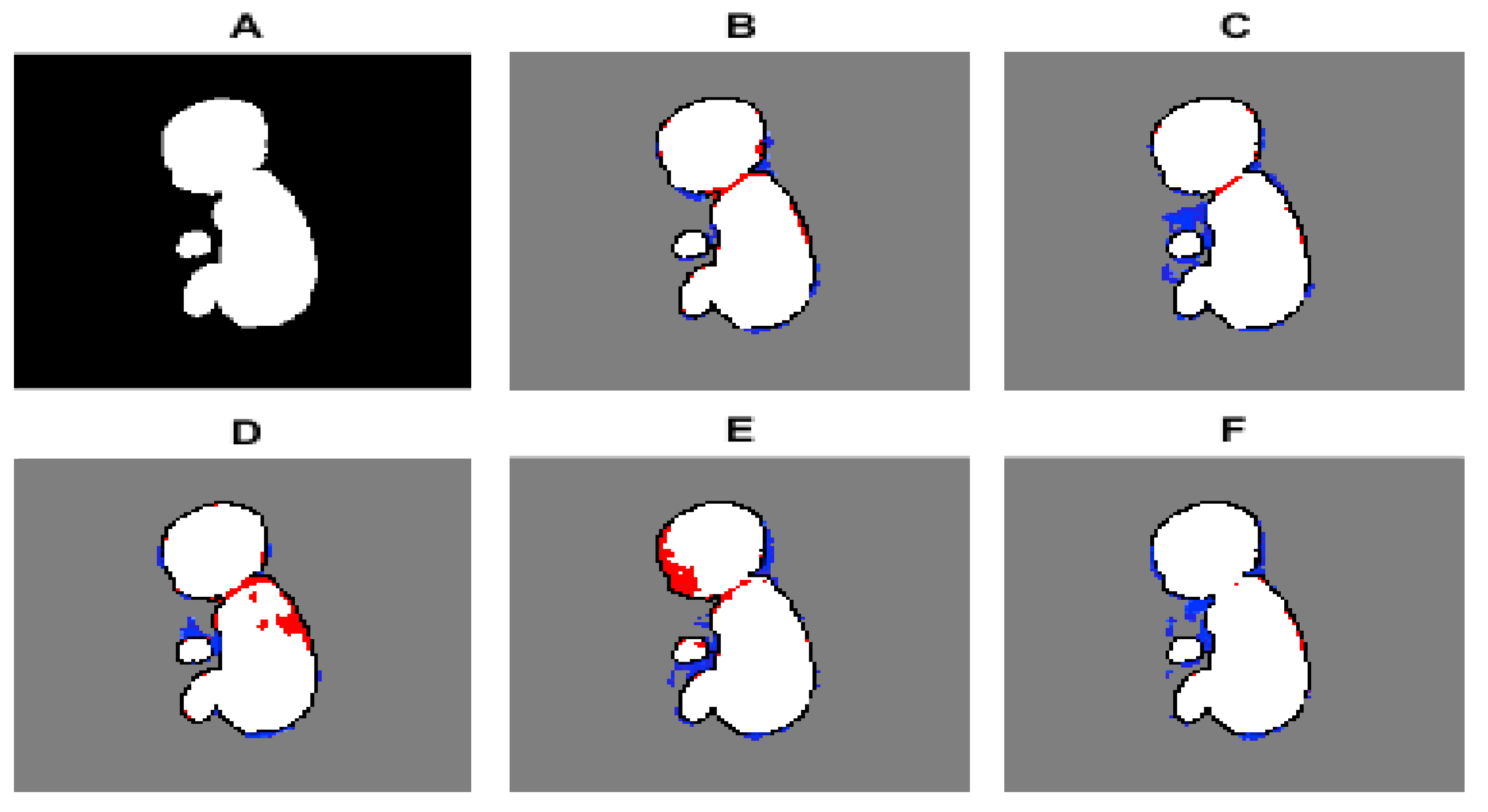
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Said, A.; El-Kattan, E.; Abdel-Hakeem, A.; Saleem, S. In utero MRI diagnosis of fetal malformations in oligohydramnios pregnancies. Egypt. J. Radiol. Nucl. Med. 2016. [Google Scholar] [CrossRef]
- Zhang, T.; Matthew, J.; Lohezic, M.; Davidson, A.; Aljabar, P.; Rutherford, M.; Rueckert, D.; Hajnal, J.V. Graph-based whole body segmentation in fetal MR images. In Proceedings of the MICCAI Work PIPPI, Athens, Greece, 21 October 2016. [Google Scholar]
- Işın, A.; Direkoglu, C.; Şah, M. Review of MRI-based Brain Tumor Image Segmentation Using Deep Learning Methods. Procedia Comput. Sci. 2016, 102, 317–324. [Google Scholar] [CrossRef]
- Gholipour, A.; Estroff, J.A.; Barnewolt, C.E.; Connolly, S.A.; Warfield, S.K. Fetal brain volumetry through MRI volumetric reconstruction and segmentation. Int. J. Comput. Assist. Radiol. Surg. 2011, 6, 329–339. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Kleesiek, J.; Urban, G.; Hubert, A.; Schwarz, D.; Maier-Hein, K.; Bendszus, M.; Biller, A. Deep MRI brain extraction: A 3D convolutional neural network for skull stripping. NeuroImage 2016, 129, 460–469. [Google Scholar] [CrossRef] [PubMed]
- Khalili, N.; Moeskops, P.; Claessens, N.H.P.; Scherpenzeel, S.; Turk, E.; de Heus, R.; Benders, M.J.N.L.; Viergever, M.A.; Pluim, J.P.W.; Išgum, I. Automatic segmentation of the intracranial volume in fetal MR images. Lect. Notes Comput. Sci. (Incl. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 2017, 10554 LNCS, 42–51. [Google Scholar] [CrossRef]
- Hermawati, F.A.; Tjandrasa, H.; Suciati, N. Phase-based thresholding schemes for segmentation of fetal thigh cross-sectional region in ultrasound images. J. King Saud Univ.-Comput. Inf. Sci. 2021. [Google Scholar] [CrossRef]
- Khalili, N.; Turk, E.; Benders, M.; Moeskops, P.; Claessens, N.; de Heus, R.; Franx, A.; Wagenaar, N.; Breur, J.; Viergever, M.; et al. Automatic extraction of the intracranial volume in fetal and neonatal MR scans using convolutional neural networks. NeuroImage Clin. 2019, 24, 102061. [Google Scholar] [CrossRef] [PubMed]
- Khalili, N.; Lessmann, N.; Turk, E.; Claessens, N.; de Heus, R.; Kolk, T.; Viergever, M.; Benders, M.; Išgum, I. Automatic brain tissue segmentation in fetal MRI using convolutional neural networks. Magn. Reson. Imaging 2019, 64, 77–89. [Google Scholar] [CrossRef] [PubMed]
- Ebner, M.; Wang, G.; Li, W.; Aertsen, M.; Patel, P.A.; Aughwane, R.; Melbourne, A.; Doel, T.; Dymarkowski, S.; De Coppi, P.; et al. An automated framework for localization, segmentation and super-resolution reconstruction of fetal brain MRI. NeuroImage 2020, 206, 116324. [Google Scholar] [CrossRef] [PubMed]
- Yu, L.; Guo, Y.; Wang, Y.; Yu, J.; Chen, P. Segmentation of Fetal Left Ventricle in Echocardiographic Sequences Based on Dynamic Convolutional Neural Networks. IEEE Trans. Biomed. Eng. 2017, 64, 1886–1895. [Google Scholar] [CrossRef]
- Cerrolaza, J.J.; Sinclair, M.; Li, Y.; Gomez, A.; Ferrante, E.; Matthew, J.; Gupta, C.; Knight, C.L.; Knight, C.L.; Rueckert, D. Deep learning with ultrasound physics for fetal skull segmentation. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 564–567. [Google Scholar] [CrossRef]
- Wang, G.; Li, W.; Zuluaga, M.A.; Pratt, R.; Patel, P.A.; Aertsen, M.; Doel, T.; David, A.L.; Deprest, J.; Ourselin, S.; et al. Interactive Medical Image Segmentation Using Deep Learning with Image-Specific Fine Tuning. IEEE Trans. Med. Imaging 2018, 37, 1562–1573. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. arXiv 2020, arXiv:1709.01507. [Google Scholar] [CrossRef]
- Rundo, L.; Han, C.; Nagano, Y.; Zhang, J.; Hataya, R.; Militello, C.; Tangherloni, A.; Nobile, M.S.; Ferretti, C.; Besozzi, D.; et al. USE-Net: Incorporating Squeeze-and-Excitation blocks into U-Net for prostate zonal segmentation of multi-institutional MRI datasets. arXiv 2019, arXiv:1904.08254. [Google Scholar] [CrossRef]
- Cheng, J.; Tian, S.; Yu, L.; Lu, H.; Lv, X. Fully convolutional attention network for biomedical image segmentation. Artif. Intell. Med. 2020, 107, 101899. [Google Scholar] [CrossRef]
- Schlemper, J.; Oktay, O.; Schaap, M.; Heinrich, M.; Kainz, B.; Glocker, B.; Rueckert, D. Attention gated networks: Learning to leverage salient regions in medical images. Med. Image Anal. 2019, 53, 197–207. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.; Lee, M.; Heinrich, M. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Seed, M.; Macgowan, K.C. Fetal Cardiovascular MRI. Magn. Flash 2014, 57, 66–72. [Google Scholar]
- Im, D.; Han, D.; Choi, S.; Kang, S.; Yoo, H.J. DT-CNN: Dilated and Transposed Convolution Neural Network Accelerator for Real-Time Image Segmentation on Mobile Devices. In Proceedings of the 2019 IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting Encoder Representations for Efficient Semantic. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017. [Google Scholar] [CrossRef]
- Dumoulin, V.; Francesco, V. A Guide to Convolution Arithmetic for Deep Learning. arXiv 2016, arXiv:1603.07285. [Google Scholar]
- Ravishankar, H.; Prabhu, S.; Vaidya, V.; Singhal, N. Hybrid approach for automatic segmentation of fetal abdomen from ultrasound images using deep learning. In Proceedings of the 2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI), Prague, Czech Republic, 13–16 April 2016; pp. 779–782. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset 1 | Dataset 2 | Dataset 3 | Dataset 4 | Dataset 5 | Dataset 6 | |
|---|---|---|---|---|---|---|
| Person 1 | 495.54 | 366.36 | 1101.5 | 612.45 | 444.3 | 456.48 |
| Person 2 | 465.54 | 309.99 | 1158.5 | 522.39 | 350.33 | 370.46 |
| Model | Loss | DSC | Recall | Precision |
|---|---|---|---|---|
| CASE-Net | 0.005 | 87.36 ± 0.83 | 91.79 ± 0.44 | 95.54 ± 0.13 |
| UNet | 0.069 | 85.17 ± 0.41 | 89.24 ± 0.26 | 94.55 ± 0.17 |
| USE-Net | 0.04 | 86.07 ± 0.41 | 86.61 ± 2.49 | 96.74 ± 0.27 |
| ATN-Net | 0.131 | 82.27 ± 0.47 | 88.69 ± 1.25 | 96.51 ± 0.27 |
| Link-Net | 0.096 | 82.72 ± 0.61 | 80.39 ± 4.96 | 95.86 ± 0.27 |
| Method | Loss | DSC | Recall | Precision |
|---|---|---|---|---|
| CASE-Net | 0.005 | 87.36 ± 0.83 | 91.79 ± 0.44 | 95.54 ± 0.13 |
| W/3 × 3 Kernel | 0.052 | 83.50 ± 0.35 | 86.51 ± 2.35 | 96.47 ± 0.24 |
| W/O ATN | 0.018 | 84.35 ± 0.13 | 89.06 ± 1.78 | 96.26 ± 0.20 |
| W/O SE | 0.11 | 81.19 ± 1.20 | 80.95 ± 4.20 | 96.69 ± 0.40 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lo, J.; Nithiyanantham, S.; Cardinell, J.; Young, D.; Cho, S.; Kirubarajan, A.; Wagner, M.W.; Azma, R.; Miller, S.; Seed, M.; et al. Cross Attention Squeeze Excitation Network (CASE-Net) for Whole Body Fetal MRI Segmentation. Sensors 2021, 21, 4490. https://doi.org/10.3390/s21134490
Lo J, Nithiyanantham S, Cardinell J, Young D, Cho S, Kirubarajan A, Wagner MW, Azma R, Miller S, Seed M, et al. Cross Attention Squeeze Excitation Network (CASE-Net) for Whole Body Fetal MRI Segmentation. Sensors. 2021; 21(13):4490. https://doi.org/10.3390/s21134490
Chicago/Turabian StyleLo, Justin, Saiee Nithiyanantham, Jillian Cardinell, Dylan Young, Sherwin Cho, Abirami Kirubarajan, Matthias W. Wagner, Roxana Azma, Steven Miller, Mike Seed, and et al. 2021. "Cross Attention Squeeze Excitation Network (CASE-Net) for Whole Body Fetal MRI Segmentation" Sensors 21, no. 13: 4490. https://doi.org/10.3390/s21134490
APA StyleLo, J., Nithiyanantham, S., Cardinell, J., Young, D., Cho, S., Kirubarajan, A., Wagner, M. W., Azma, R., Miller, S., Seed, M., Ertl-Wagner, B., & Sussman, D. (2021). Cross Attention Squeeze Excitation Network (CASE-Net) for Whole Body Fetal MRI Segmentation. Sensors, 21(13), 4490. https://doi.org/10.3390/s21134490