
Measurement Noise Model for Depth Camera-Based People Tracking


Abstract
:1. Introduction
- 1.
- A non-parametric, state-dependent measurement noise model for depth camera-based people tracking systems that utilise the plan-view approach. In our model, the measurement noise is modelled in the plan-view domain as 2D Gaussian distribution. The measurements are expressed in the polar coordinate system, and the error distributions for the bearing and range are separately defined as deviations from predefined reference points;
- 2.
- A method for determining the noise model directly from the people detections. For reference, we use either the ground truth points or the trajectories that are reconstructed in our depth camera network autocalibration method.
- As we do not have any explicit model for the measurement noise, the approach can be used with different kinds of depth cameras, and even with depth sensor networks that consist of a heterogeneous set of sensors.
- The noise model can be directly derived from people detections, and no separate calibration routines or calibration targets (such as checkerboard planes) are needed. When used in conjunction with our depth camera network self-calibration routine [19], it allows fully automatic system configuration.
2. People Tracking with Depth Sensor Network
2.1. Overview
2.2. Plan-View Transformation
2.3. Tracking
2.4. Transforming Observations to Global Frame
2.5. Camera Network Calibration
3. Measurement Noise Model for Plan-View Tracking
3.1. Error Sources of Depth Sensors
3.2. Measurement Noise Model
4. Experiments
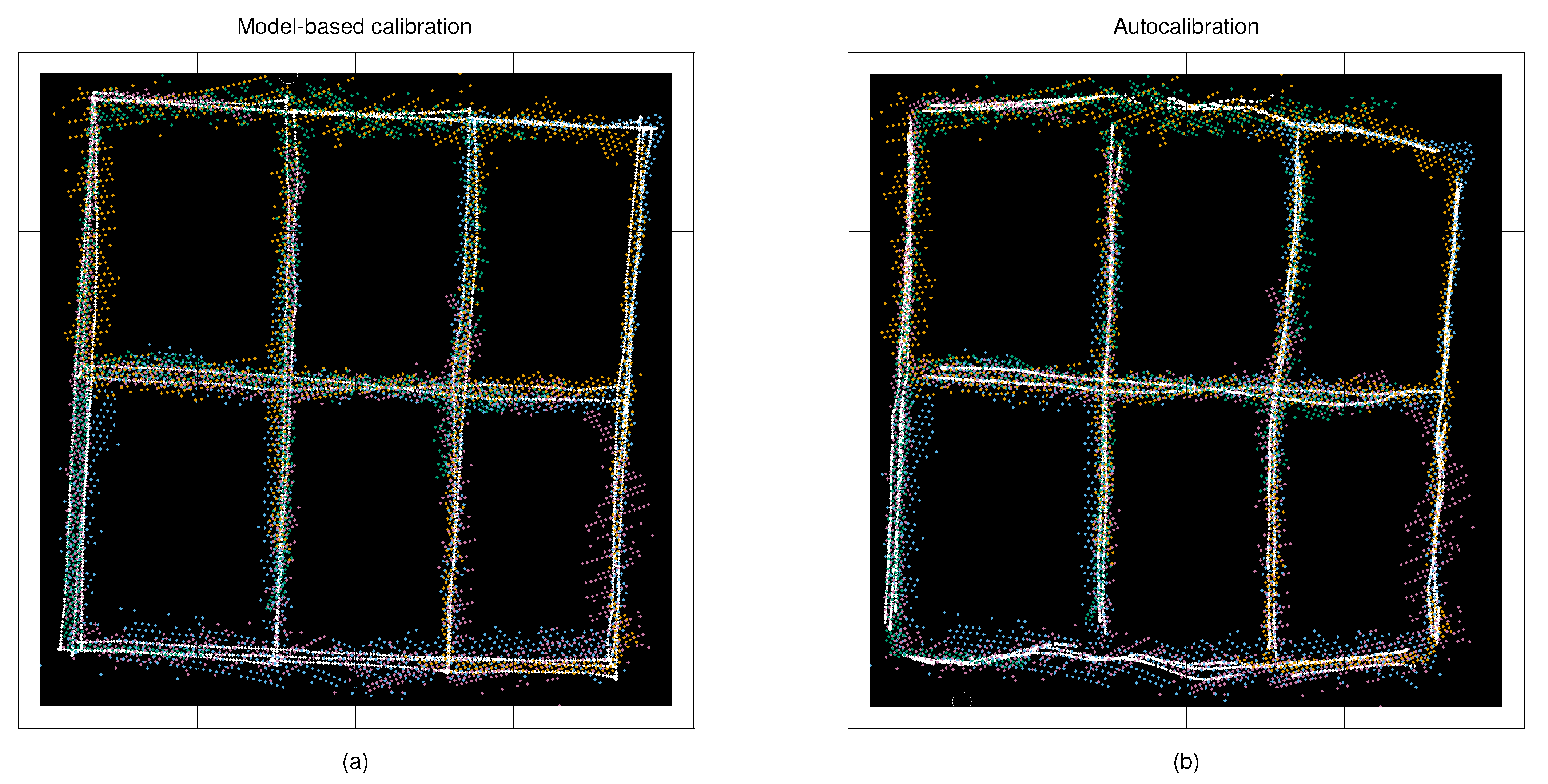
4.1. Experiment Set-Up
4.2. Detecting Moving Targets
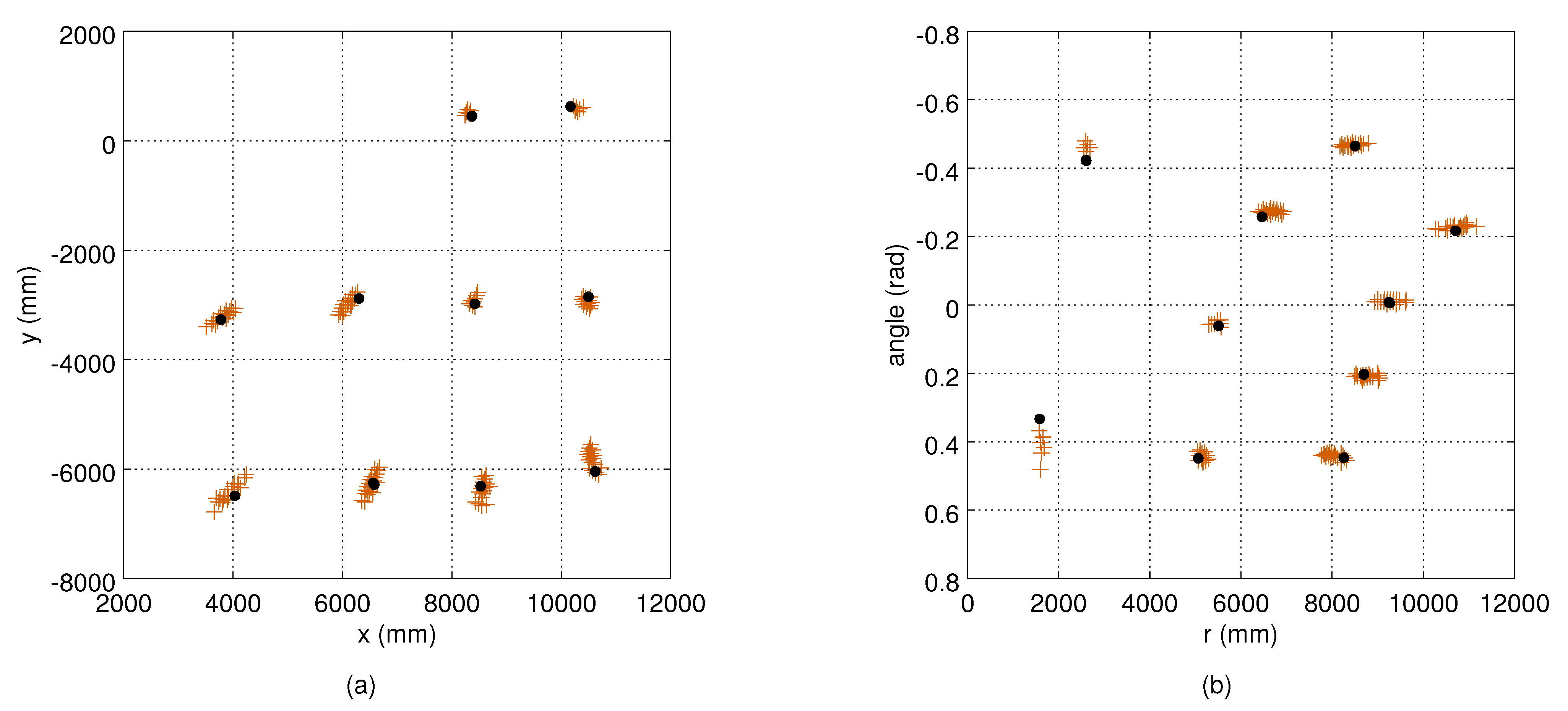
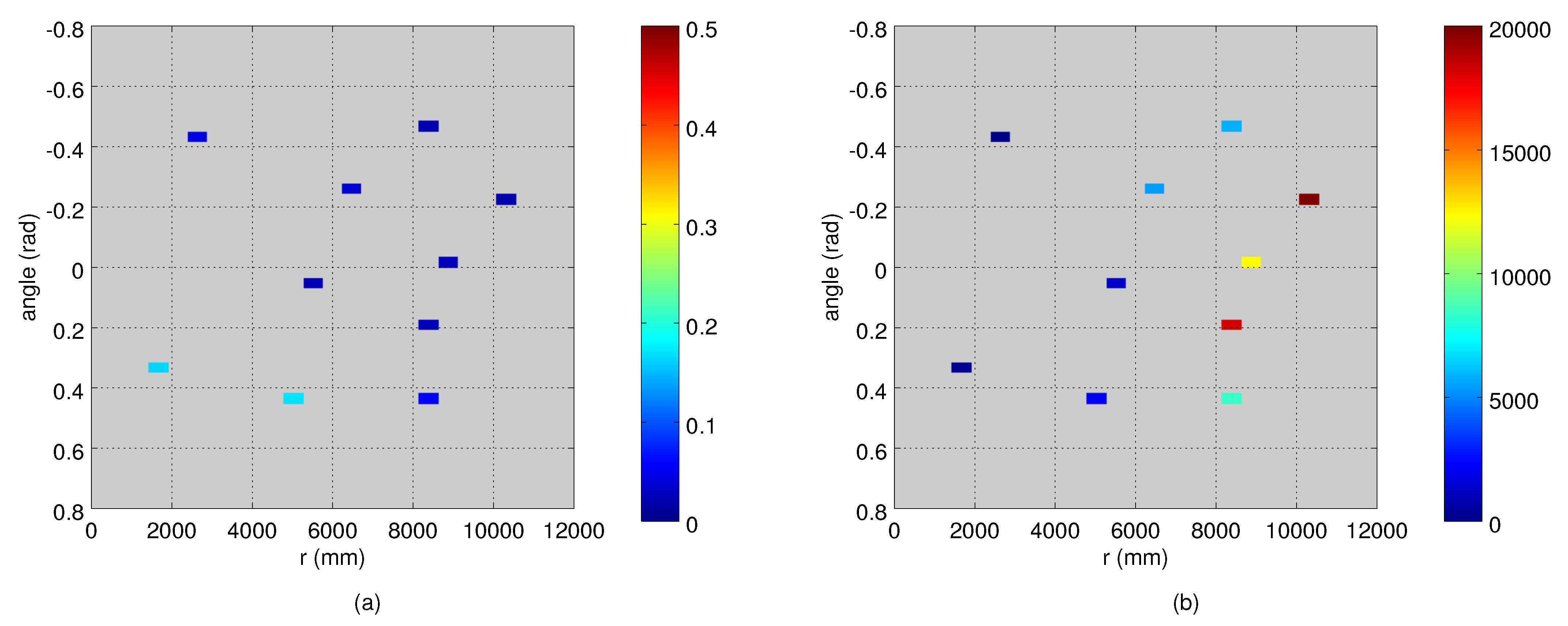
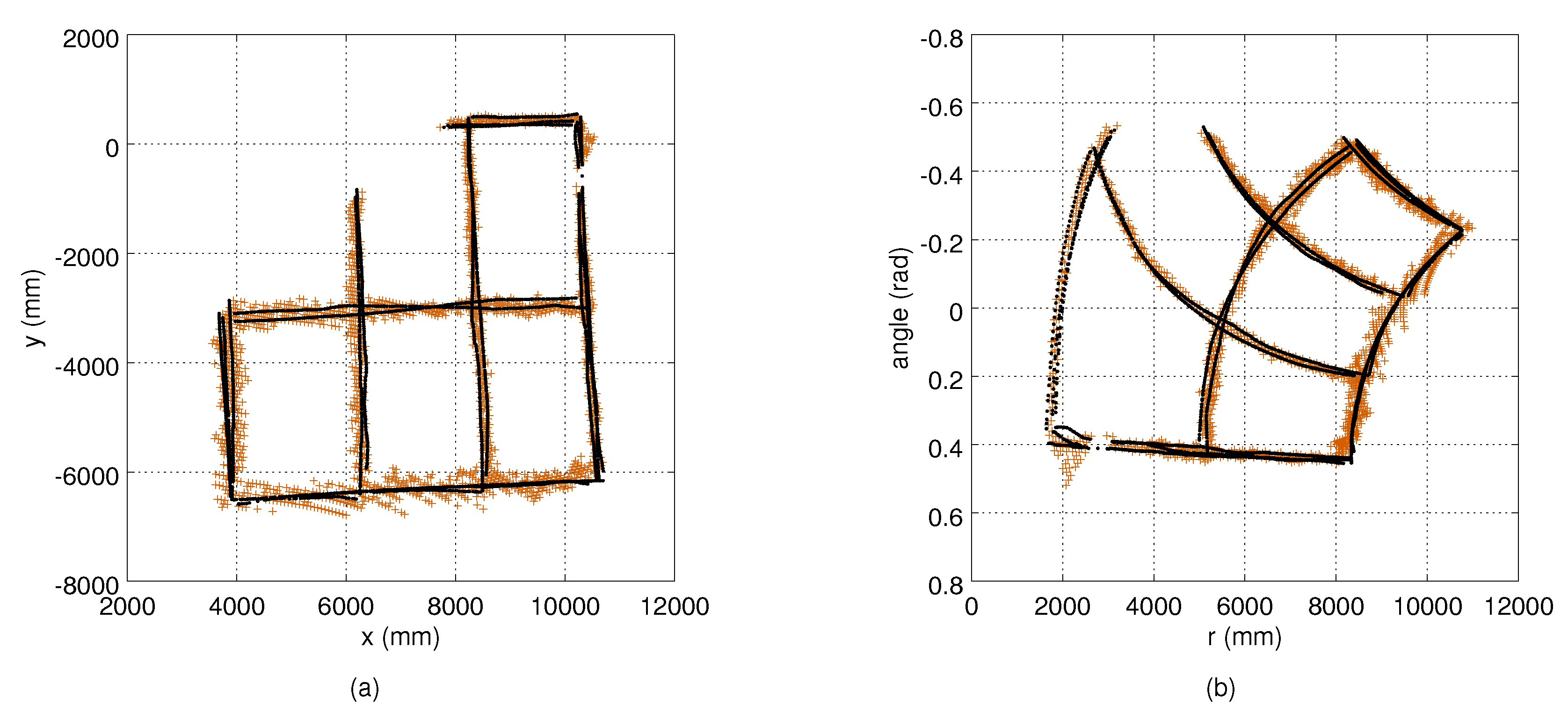
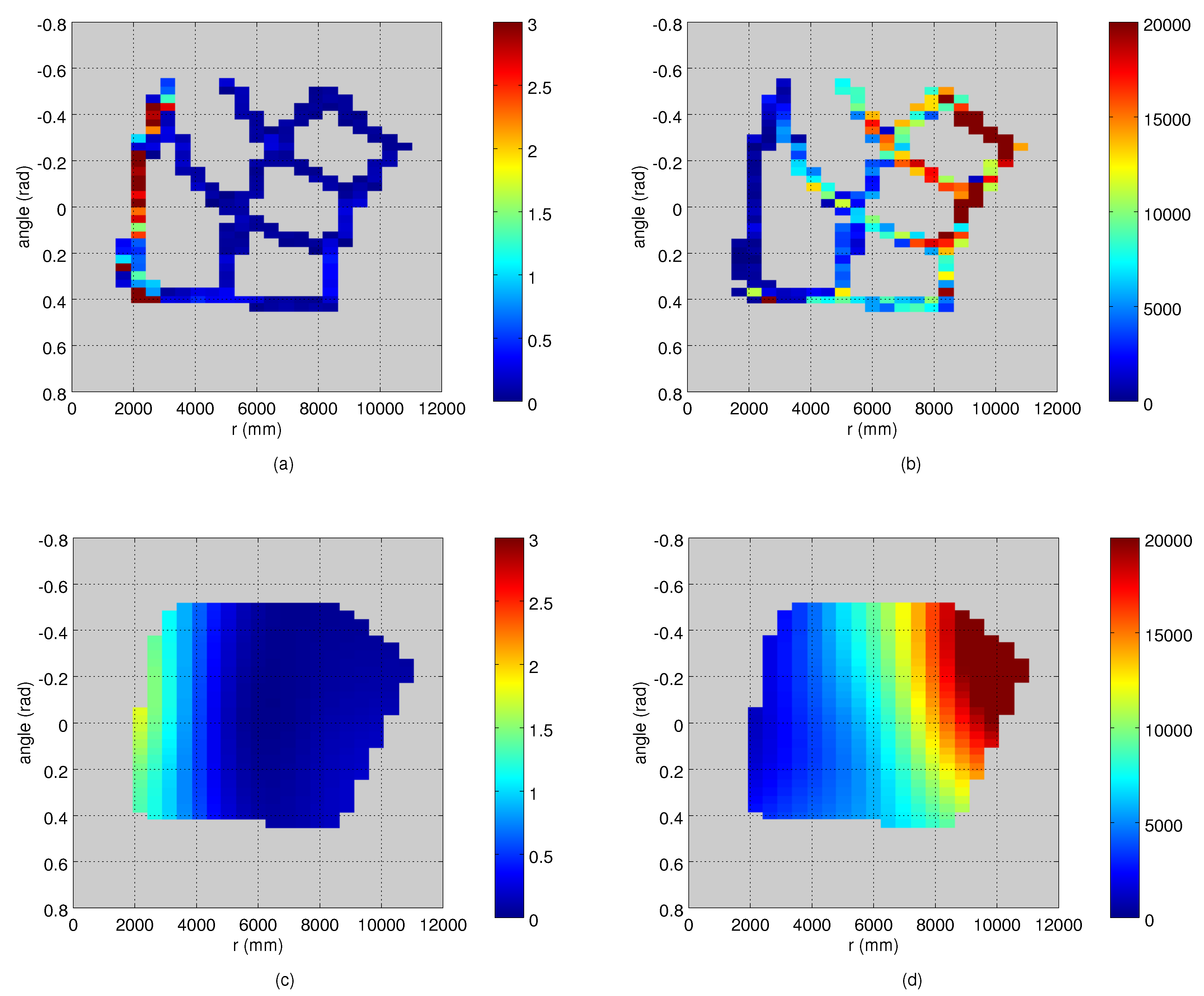
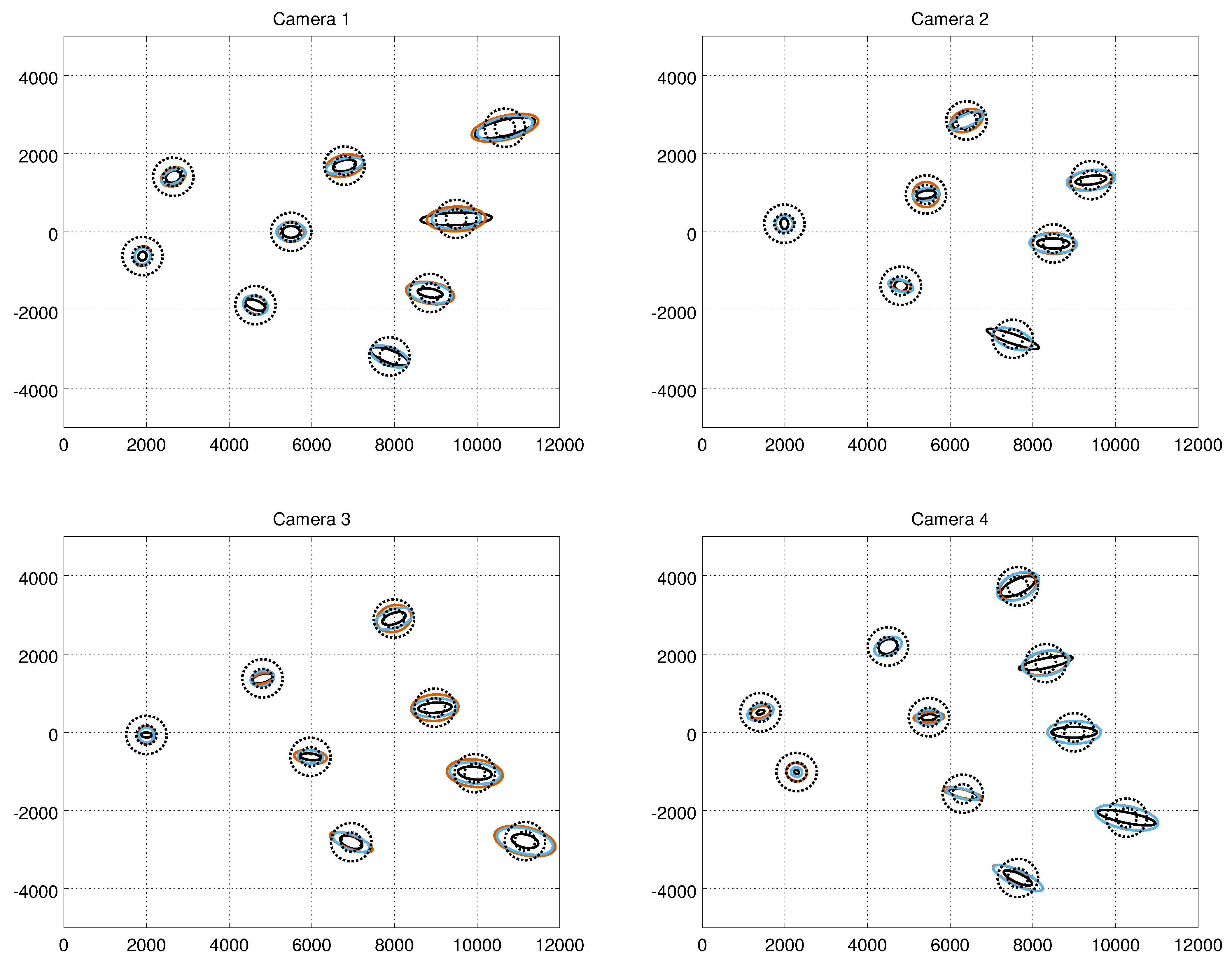
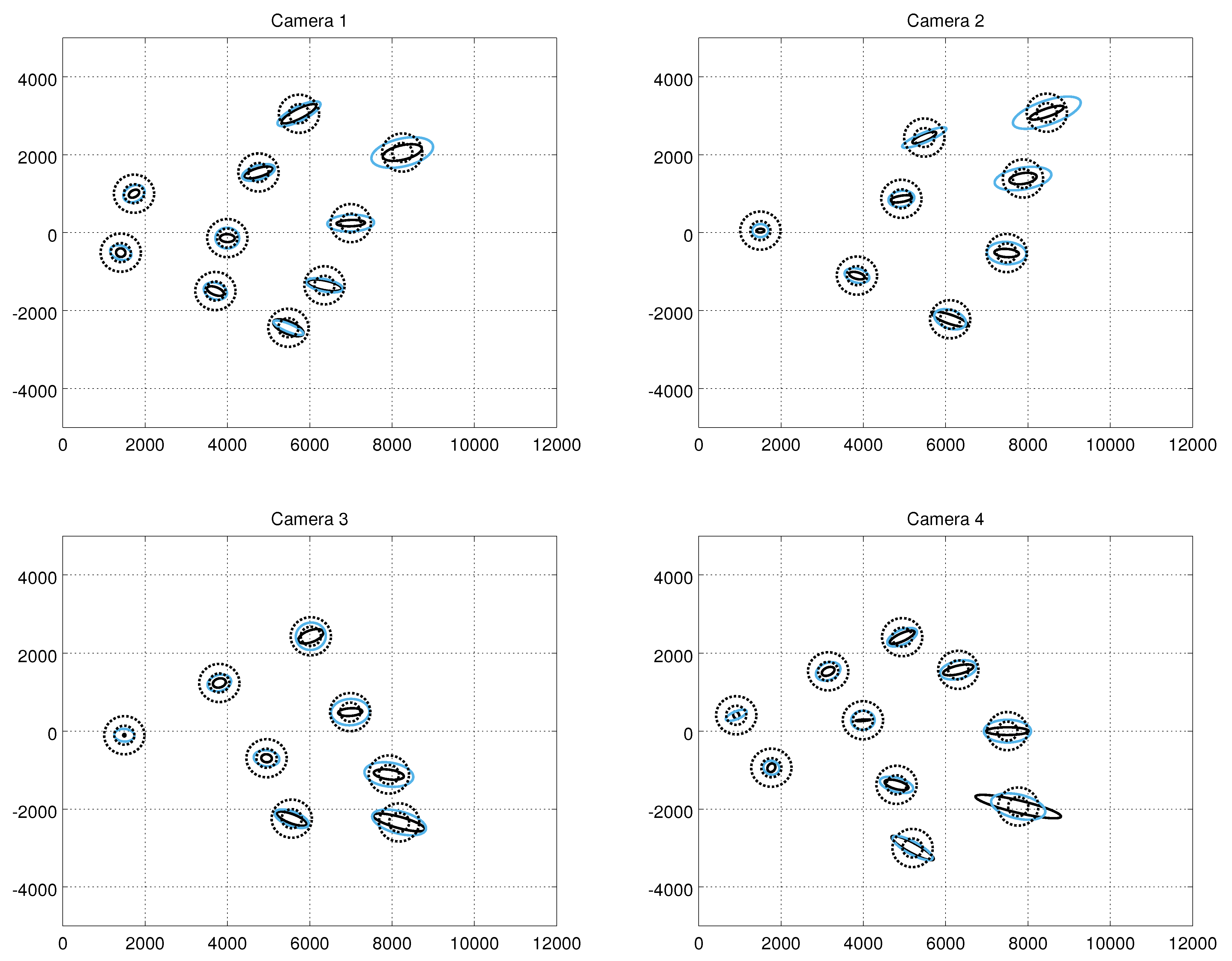
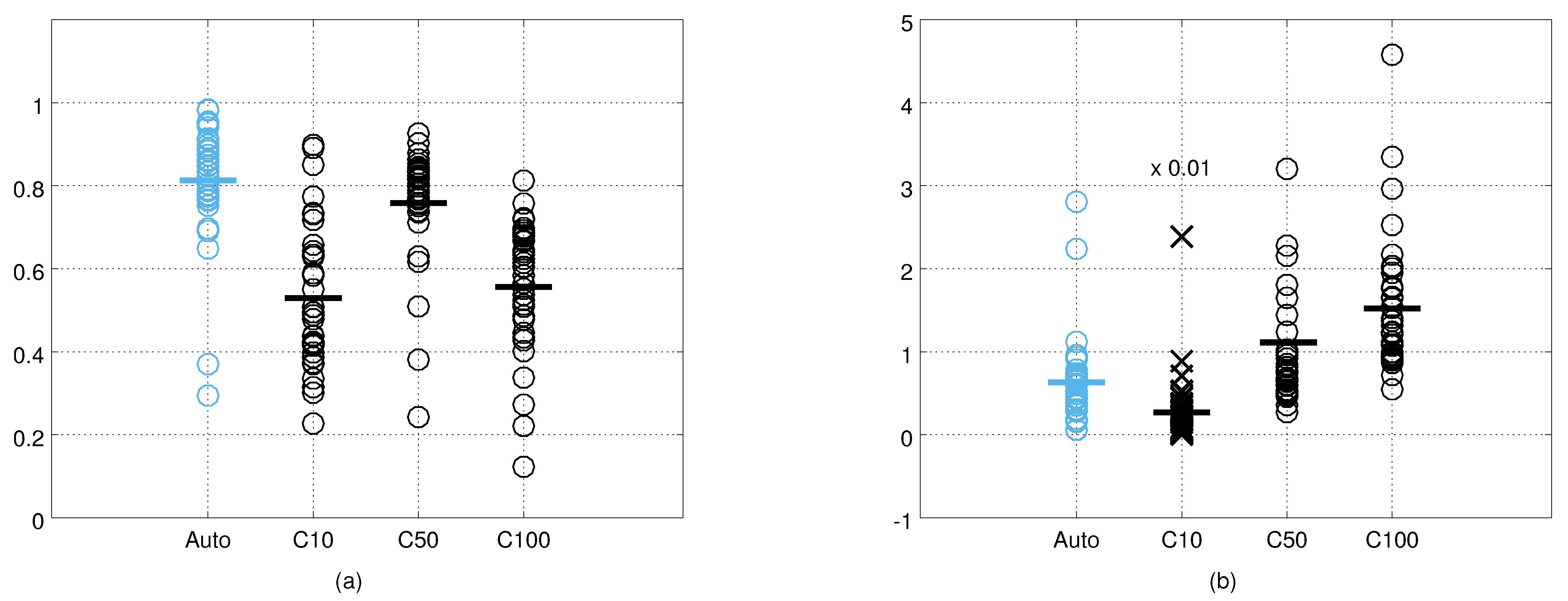
4.3. Computing and Evaluating the Measurement Noise
4.4. Tracking
5. Results
5.1. Measurement Noise Covariances
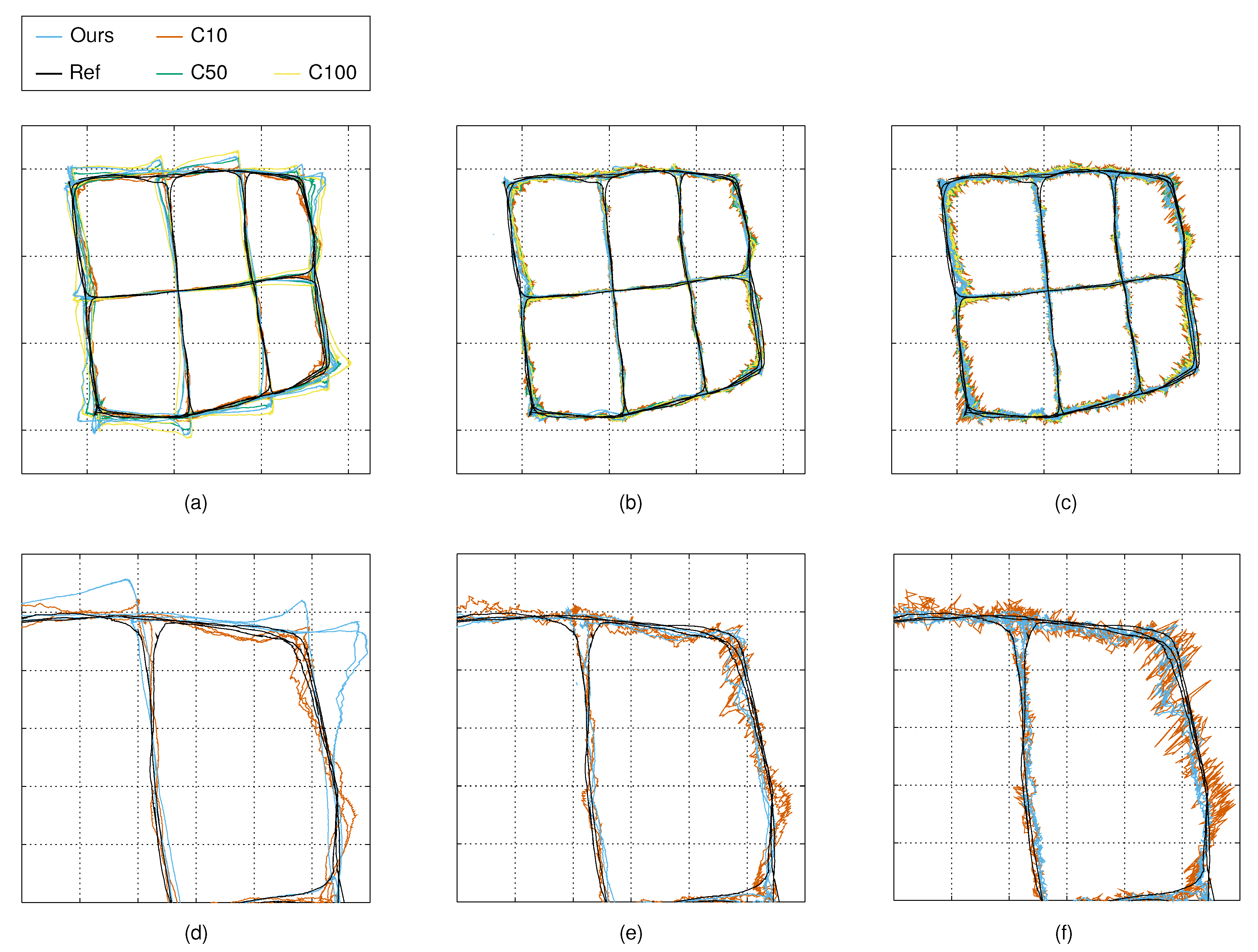
5.2. Tracking
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Harville, M. Stereo person tracking with adaptive plan-view templates of height and occupancy statistics. Image Vis. Comput. 2004, 22, 127–142. [Google Scholar] [CrossRef]
- Bevilacqua, A.; Stefano, L.; Azzari, P. People Tracking Using a Time-of-Flight Depth Sensor. In Proceedings of the 2006 IEEE International Conference on Video and Signal Based Surveillance, Sydney, Australia, 22–24 November 2006. [Google Scholar]
- Sarbolandi, H.; Lefloch, D.; Kolb, A. Kinect range sensing: Structured-light versus Time-of-Flight Kinect. Comput. Vis. Image Underst. 2015, 139, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Khoshelham, K.; Elberink, S.O. Accuracy and Resolution of Kinect Depth Data for Indoor Mapping Applications. Sensors 2012, 12, 1437–1454. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nguyen, C.V.; Izadi, S.; Lovell, D. Modeling Kinect Sensor Noise for Improved 3D Reconstruction and Tracking. In Proceedings of the 2012 Second International Conference on 3D Imaging, Modeling, Processing, Visualization Transmission, Zurich, Switzerland, 13–15 October 2012; pp. 524–530. [Google Scholar]
- Zennaro, S.; Munaro, M.; Milani, S.; Zanuttigh, P.; Bernardi, A.; Ghidoni, S.; Menegatti, E. Performance evaluation of the 1st and 2nd generation Kinect for multimedia applications. In Proceedings of the 2015 IEEE International Conference on Multimedia and Expo (ICME), Turin, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Smisek, J.; Jancosek, M.; Pajdla, T. 3D with Kinect. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 1154–1160. [Google Scholar]
- Munaro, M.; Menegatti, E. Fast RGB-D people tracking for service robots. Auton. Robot. 2014, 37, 227–242. [Google Scholar] [CrossRef]
- Belhedi, A.; Bartoli, A.; Bourgeois, S.; Hamrouni, K.; Sayd, P.; Gay-Bellile, V. Noise Modelling and Uncertainty Propagation for TOF Sensors. In Computer Vision—ECCV 2012, Workshops and Demonstrations; Fusiello, A., Murino, V., Cucchiara, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 476–485. [Google Scholar]
- Stahlschmidt, C.; Gavriilidis, A.; Velten, J.; Kummert, A. People Detection and Tracking from a Top-View Position Using a Time-of-Flight Camera. In Multimedia Communications, Services and Security; Dziech, A., Czyżewski, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 213–223. [Google Scholar]
- Muscoloni, A.; Mattoccia, S. Real-time tracking with an embedded 3D camera with FPGA processing. In Proceedings of the 2014 International Conference on 3D Imaging, Liège, Belgium, 9–10 December 2014; pp. 1–7. [Google Scholar]
- Liu, J.; Liu, Y.; Zhang, G.; Zhu, P.; Chen, Y.Q. Detecting and tracking people in real time with RGB-D camera. Pattern Recognit. Lett. 2015, 53, 16–23. [Google Scholar] [CrossRef]
- Almazán, E.J.; Jones, G.A. Tracking People across Multiple Non-overlapping RGB-D Sensors. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 831–837. [Google Scholar]
- Van Crombrugge, I.; Penne, R.; Vanlanduit, S. People tracking with range cameras using density maps and 2D blob splitting. Integr.-Comput. Aided Eng. 2019, 26, 285–295. [Google Scholar] [CrossRef]
- Tseng, T.; Liu, A.; Hsiao, P.; Huang, C.; Fu, L. Real-time people detection and tracking for indoor surveillance using multiple top-view depth cameras. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 4077–4082. [Google Scholar]
- Munaro, M.; Basso, F.; Menegatti, E. OpenPTrack: Open source multi-camera calibration and people tracking for RGB-D camera networks. Robot. Auton. Syst. 2015, 75. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Sturm, J.; Cremers, D.; Lee, D. Real-time human motion tracking using multiple depth cameras. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Algarve, Portugal, 7–12 October 2012; pp. 2389–2395. [Google Scholar]
- Carraro, M.; Munaro, M.; Menegatti, E. Skeleton estimation and tracking by means of depth data fusion from depth camera networks. Robot. Auton. Syst. 2018, 110, 151–159. [Google Scholar] [CrossRef] [Green Version]
- Korkalo, O.; Tikkanen, T.; Kemppi, P.; Honkamaa, P. Auto-calibration of depth camera networks for people tracking. Mach. Vis. Appl. 2019, 30, 671–688. [Google Scholar] [CrossRef] [Green Version]
- Bar-Shalom, Y.; Kirubarajan, T.; Li, X.R. Estimation with Applications to Tracking and Navigation; John Wiley & Sons, Inc.: New York, NY, USA, 2002. [Google Scholar]
- Bookstein, F.L. Principal warps: Thin-plate splines and the decomposition of deformations. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 567–585. [Google Scholar] [CrossRef] [Green Version]
- Belhedi, A.; Bartoli, A.; Gay-bellile, V.; Bourgeois, S.; Sayd, P.; Hamrouni, K. Depth Correction for Depth Camera From Planarity. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012; BMVA Press: Surrey, UK, 2012; p. 43. [Google Scholar]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A. ROS: An Open-Source Robot Operating System. In ICRA Workshop on Open Source Software; Kobe, Japan, 2009; Volume 3, p. 5. Available online: http://www.cim.mcgill.ca/~dudek/417/Papers/quigley-icra2009-ros.pdf (accessed on 29 June 2021).
- Pierce, S. Barnes Objective Analysis. MATLAB Central File Exchange. Available online: https://www.mathworks.com/matlabcentral/fileexchange/28666-barnes-objective-analysis (accessed on 29 April 2021).
- Eaton, J.W.; Bateman, D.; Hauberg, S.; Wehbring, R. GNU Octave Version 4.0.0 Manual: A High-Level Interactive Language for Numerical Computations; SoHo Books: London, UK, 2015. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
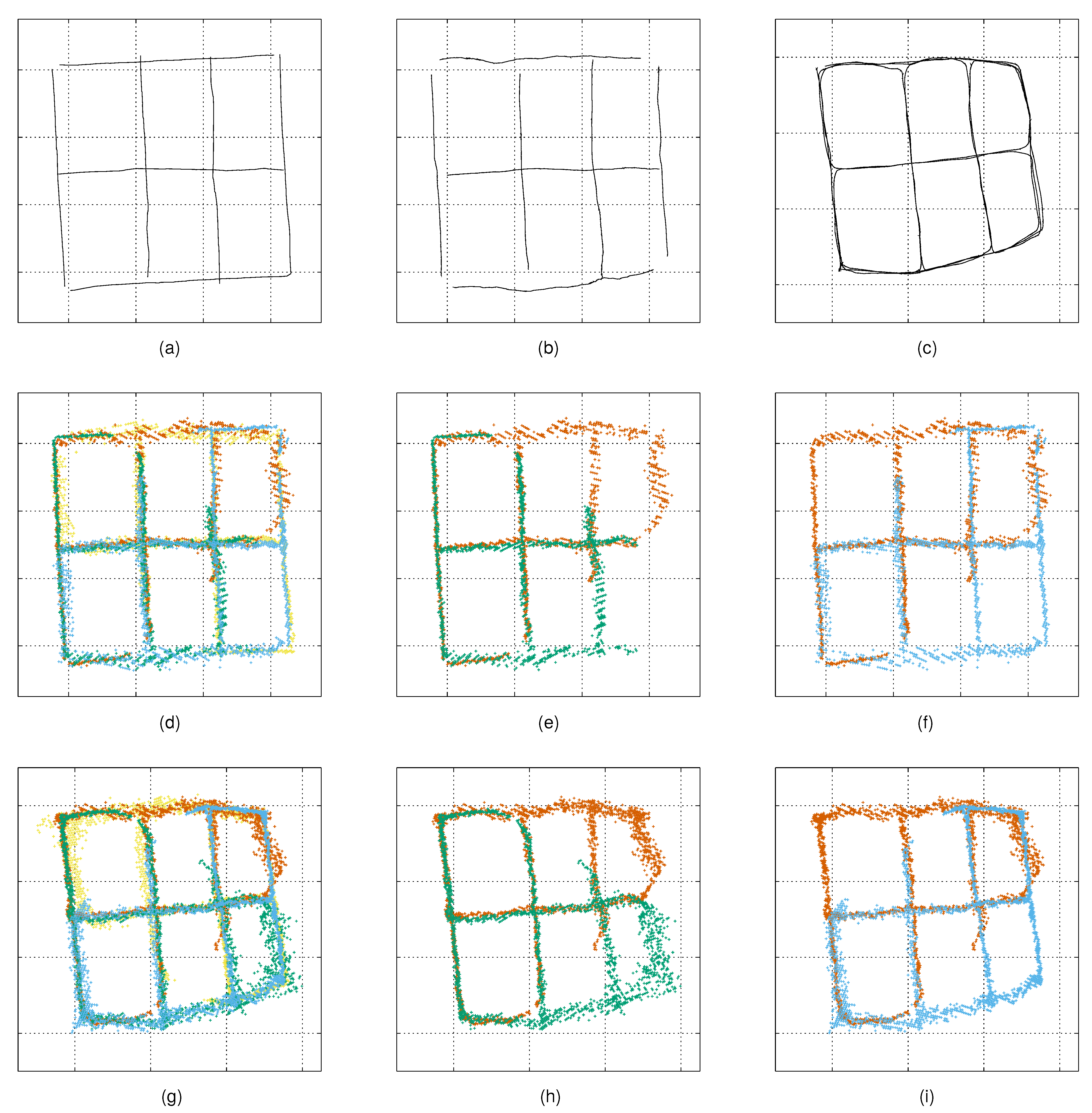{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
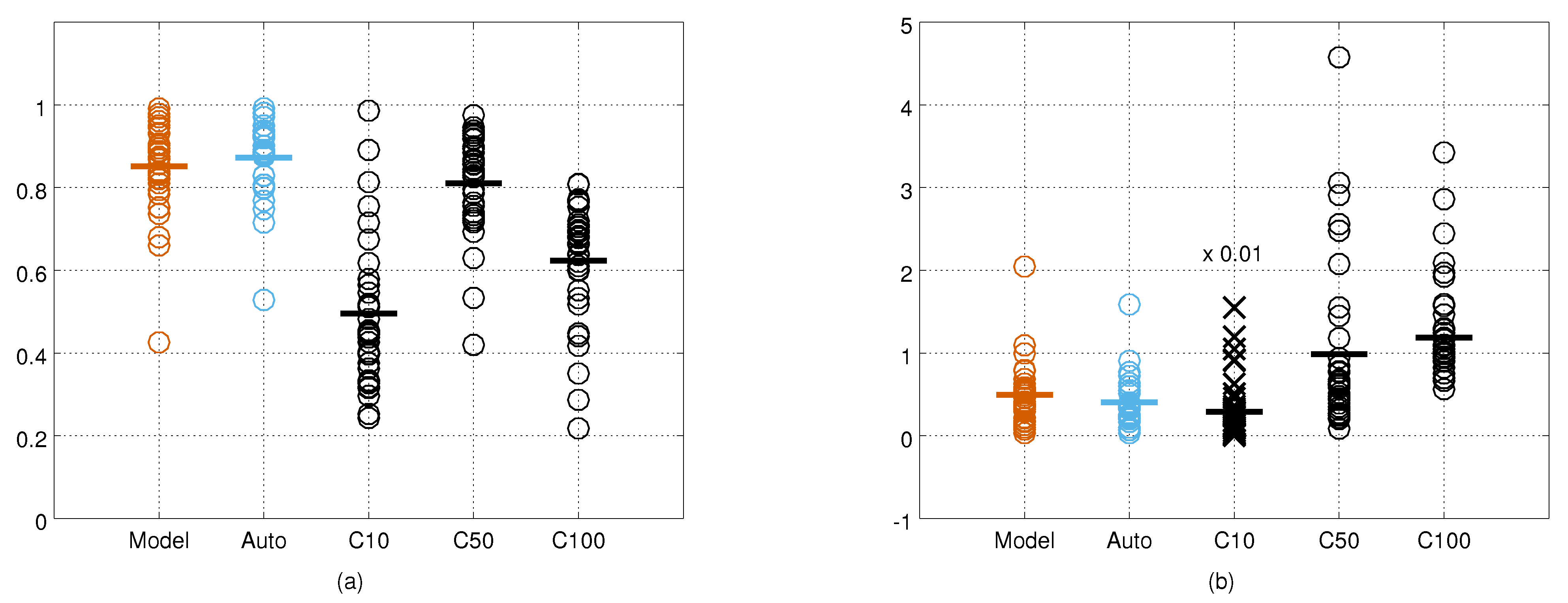{kind=link}
{kind=link}
{kind=link}
| Camera 1 | Camera 2 | Camera 3 | Camera 4 | All | |
|---|---|---|---|---|---|
| Model-based | 0.88 (0.07) | 0.86 (0.07) | 0.82 (0.09) | 0.82 (0.17) | 0.85 (0.11) |
| Auto | 0.91 (0.06) | 0.88 (0.06) | 0.87 (0.06) | 0.83 (0.14) | 0.87 (0.09) |
| 0.45 (0.16) | 0.49 (0.15) | 0.50 (0.15) | 0.52 (0.25) | 0.49 (0.18) | |
| 0.84 (0.09) | 0.83 (0.07) | 0.86 (0.11) | 0.75 (0.17) | 0.81 (0.12) | |
| 0.65 (0.11) | 0.61 (0.11) | 0.63 (0.14) | 0.59 (0.20) | 0.62 (0.15) | |
| Auto | 0.87 (0.09) | 0.79 (0.09) | 0.76 (0.20) | 0.80 (0.17) | 0.81 (0.14) |
| 0.51 (0.15) | 0.54 (0.17) | 0.54 (0.17) | 0.52 (0.20) | 0.53 (0.17) | |
| 0.82 (0.05) | 0.77 (0.11) | 0.76 (0.21) | 0.71 (0.14) | 0.76 (0.14) | |
| 0.60 (0.13) | 0.56 (0.14) | 0.56 (0.20) | 0.53 (0.16) | 0.56 (0.15) |
| Camera 1 | Camera 2 | Camera 3 | Camera 4 | All | |
|---|---|---|---|---|---|
| Model-based | 0.39 (0.23) | 0.46 (0.21) | 0.56 (0.29) | 0.58 (0.59) | 0.49 (0.37) |
| Auto | 0.31 (0.19) | 0.38 (0.19) | 0.41 (0.19) | 0.53 (0.45) | 0.41 (0.29) |
| 43.9 (55.4) | 28.4 (30.4) | 19.3 (11.5) | 37.9 (37.4) | 33.2 (37.6) | |
| 1.21 (1.55) | 0.83 (0.78) | 0.50 (0.32) | 1.32 (0.93) | 1.00 (1.03) | |
| 1.17 (0.42) | 1.25 (0.44) | 1.20 (0.58) | 1.47 (0.96) | 1.28 (0.64) | |
| Auto | 0.43 (0.25) | 0.65 (0.28) | 0.83 (0.84) | 0.66 (0.61) | 0.63 (0.54) |
| 23.7 (18.1) | 20.4 (14.6) | 24.2 (28.4) | 44.3 (72.1) | 28.8 (41.5) | |
| 0.71 (0.17) | 0.81 (0.40) | 1.09 (1.06) | 1.76 (2.17) | 1.11 (1.29) | |
| 1.28 (0.52) | 1.49 (0.66) | 1.65 (1.25) | 1.72 (0.77) | 1.53 (0.81) |
| Calibration | Ours | ||||
|---|---|---|---|---|---|
| Model based | 125.6 | 122.1 | 132.5 | 156.9 | |
| Auto, robot | 107.9 | 89.6 | 103.0 | 129.5 | |
| Auto, person | 202.0 | 103.5 | 173.6 | 279.0 | |
| Model | 105.6 | 126.2 | 122.9 | 122.3 | |
| Auto, robot | 82.5 | 92.5 | 89.5 | 89.4 | |
| Auto, person | 101.4 | 100.4 | 98.9 | 103.5 | |
| Model | 113.9 | 139.5 | 129.0 | 126.3 | |
| Auto, robot | 94.1 | 109.7 | 96.2 | 92.4 | |
| Auto, person | 101.3 | 115.1 | 102.8 | 101.0 |
| Calibration | Ours | ||||
|---|---|---|---|---|---|
| Model based | 194.1 | 134.7 | 165.6 | 209.1 | |
| Auto, robot | 165.5 | 106.3 | 133.8 | 178.2 | |
| Auto, person | 336.6 | 143.0 | 259.9 | 427.2 | |
| Model | 134.1 | 132.8 | 132.8 | 135.8 | |
| Auto, robot | 109.0 | 107.6 | 105.3 | 107.0 | |
| Auto, person | 131.5 | 132.6 | 135.9 | 143.8 | |
| Model | 130.9 | 144.9 | 135.2 | 132.9 | |
| Auto, robot | 108.5 | 122.4 | 110.7 | 107.9 | |
| Auto, person | 132.1 | 143.1 | 133.1 | 132.0 |
| Calibration | Ours | ||||
|---|---|---|---|---|---|
| Model based | 147.0 | 126.2 | 140.6 | 173.7 | |
| Auto, robot | 126.0 | 96.6 | 116.3 | 152.7 | |
| Auto, person | 254.2 | 117.6 | 223.0 | 369.8 | |
| Model | 117.1 | 131.1 | 127.8 | 126.9 | |
| Auto, robot | 92.6 | 99.7 | 96.7 | 96.9 | |
| Auto, person | 111.5 | 111.0 | 111.8 | 118.0 | |
| Model | 124.6 | 151.4 | 135.5 | 131.6 | |
| Auto, robot | 97.7 | 122.9 | 104.4 | 99.9 | |
| Auto, person | 110.8 | 122.9 | 113.1 | 111.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Korkalo, O.; Takala, T. Measurement Noise Model for Depth Camera-Based People Tracking. Sensors 2021, 21, 4488. https://doi.org/10.3390/s21134488
Korkalo O, Takala T. Measurement Noise Model for Depth Camera-Based People Tracking. Sensors. 2021; 21(13):4488. https://doi.org/10.3390/s21134488
Chicago/Turabian StyleKorkalo, Otto, and Tapio Takala. 2021. "Measurement Noise Model for Depth Camera-Based People Tracking" Sensors 21, no. 13: 4488. https://doi.org/10.3390/s21134488
APA StyleKorkalo, O., & Takala, T. (2021). Measurement Noise Model for Depth Camera-Based People Tracking. Sensors, 21(13), 4488. https://doi.org/10.3390/s21134488