
V2X Wireless Technology Identification Using Time–Frequency Analysis and Random Forest Classifier



Abstract
:1. Introduction
2. Background
2.1. Cyclostationarity
2.2. Time–Frequency Analysis
3. Signal Model
3.1. ITS-G5
3.2. LTE-V2X
3.3. NR-V2X
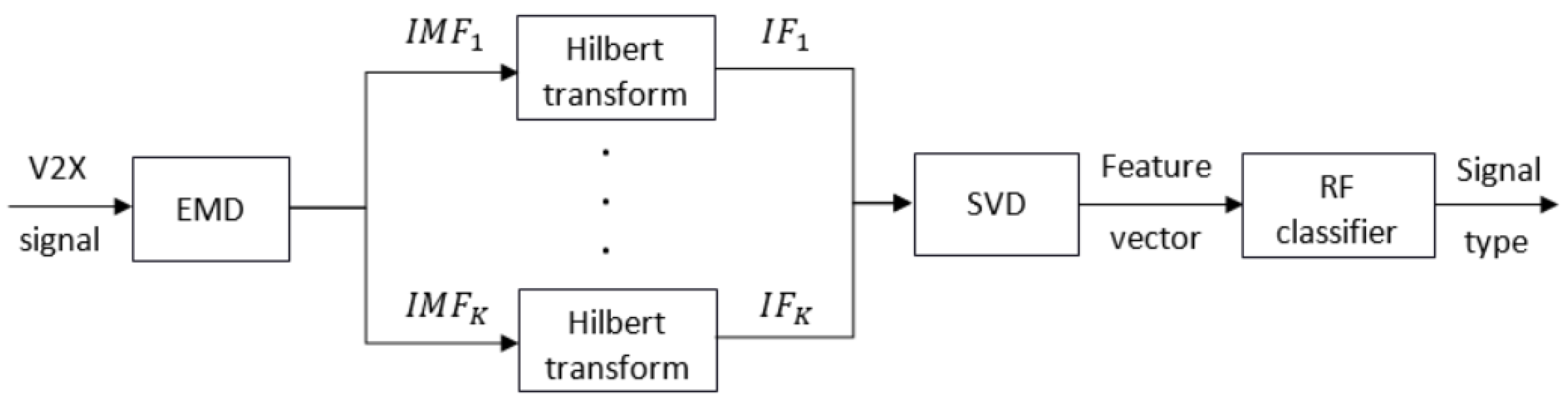
4. Signal Identification
4.1. Feature Vector Extraction
4.2. Random Forest Classifier
- Building the individual trees of the forest using algorithms such as C4.5 or CART.
- Sampling randomly the original training dataset without deletion of the selected data in order to create an in-bag subset for each tree.
- Selecting randomly a set of features to construct the nodes and leaves of each tree.
- Selecting the root node of the tree, which represents the attribute (feature) with the highest Information Gain (IG).
- Splitting the training data at the root node into subsets for every possible value of the attribute. Then, at each node, the splitting is conducted if the IG is positive; otherwise the node becomes a leaf node. The information gain of splitting the training dataset (Y) into subsets () is given by:where J is the number of signal classes and the proportion of the class j in the subset .
- Repeating this process of tree growing at each node using the subset that reaches the branch and the remaining attributes until all attributes are selected. The most occurring signal class that reached that node is the classification output of the tree.
4.3. Classification Metrics
5. Performance Evaluation
5.1. Dataset Generation
5.2. Simulation Results
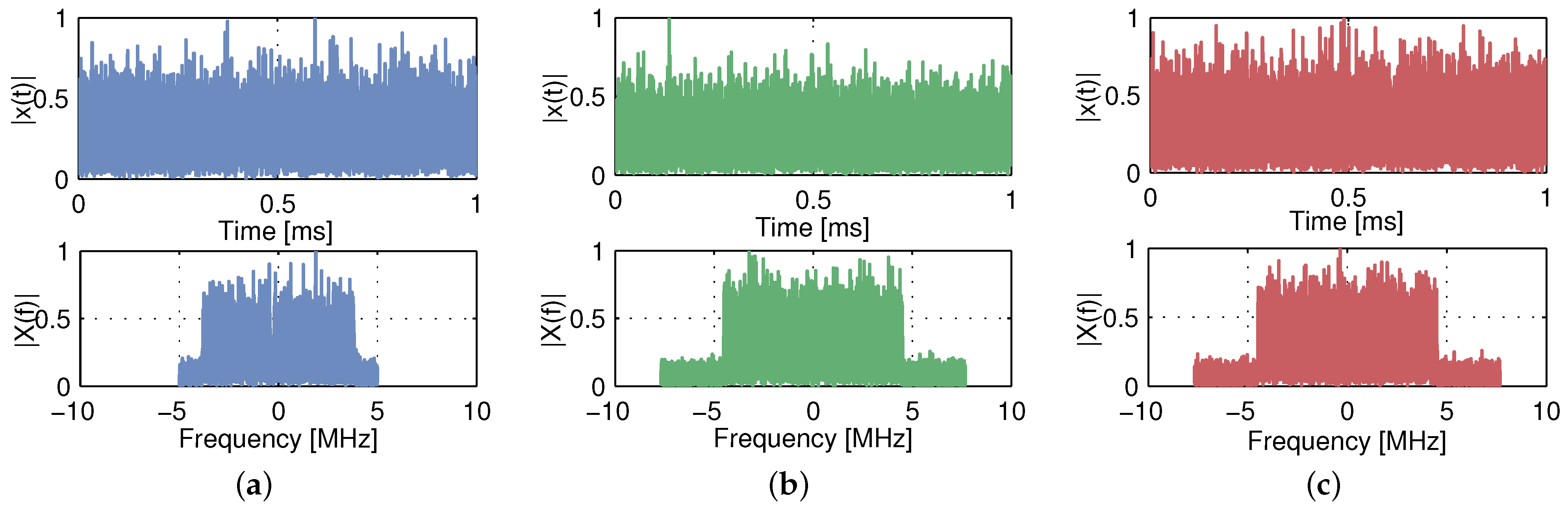
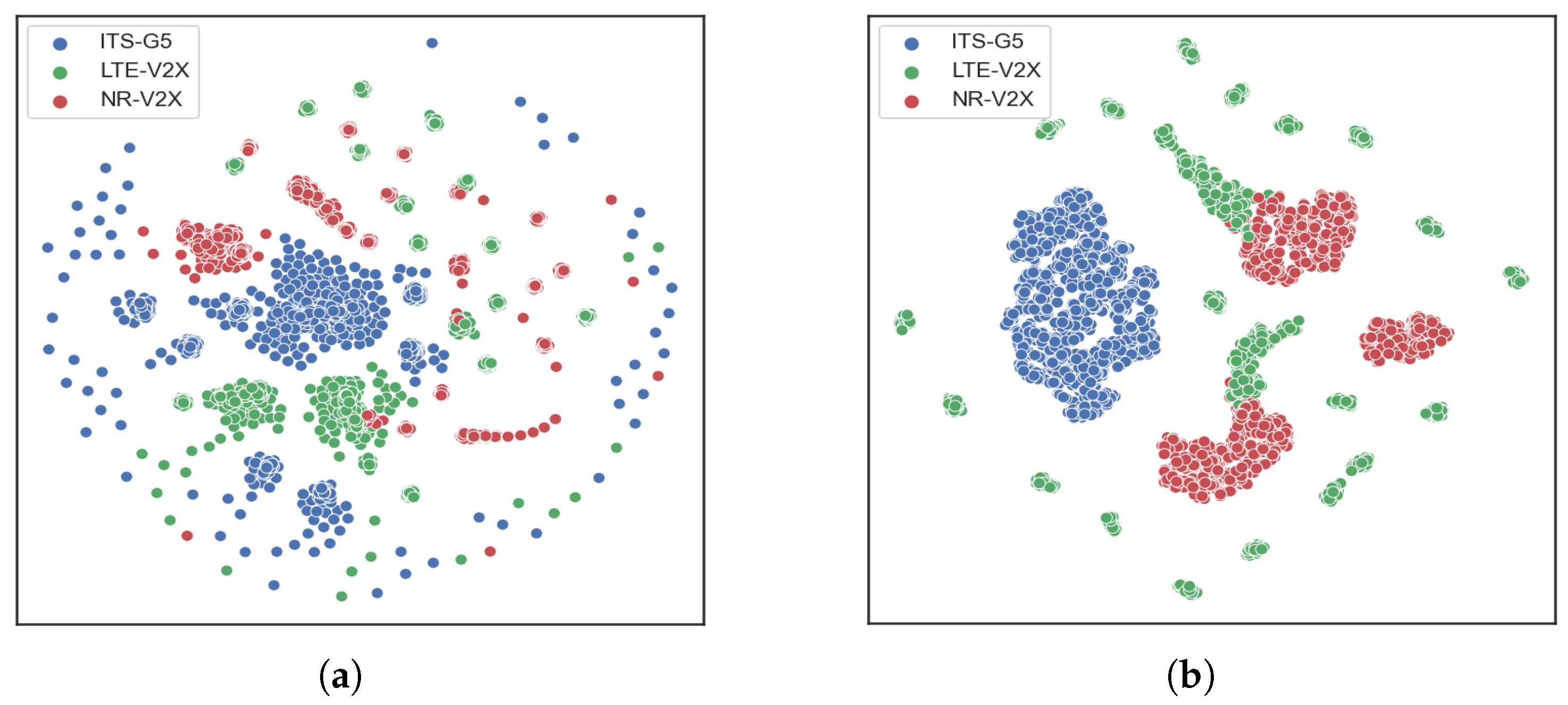
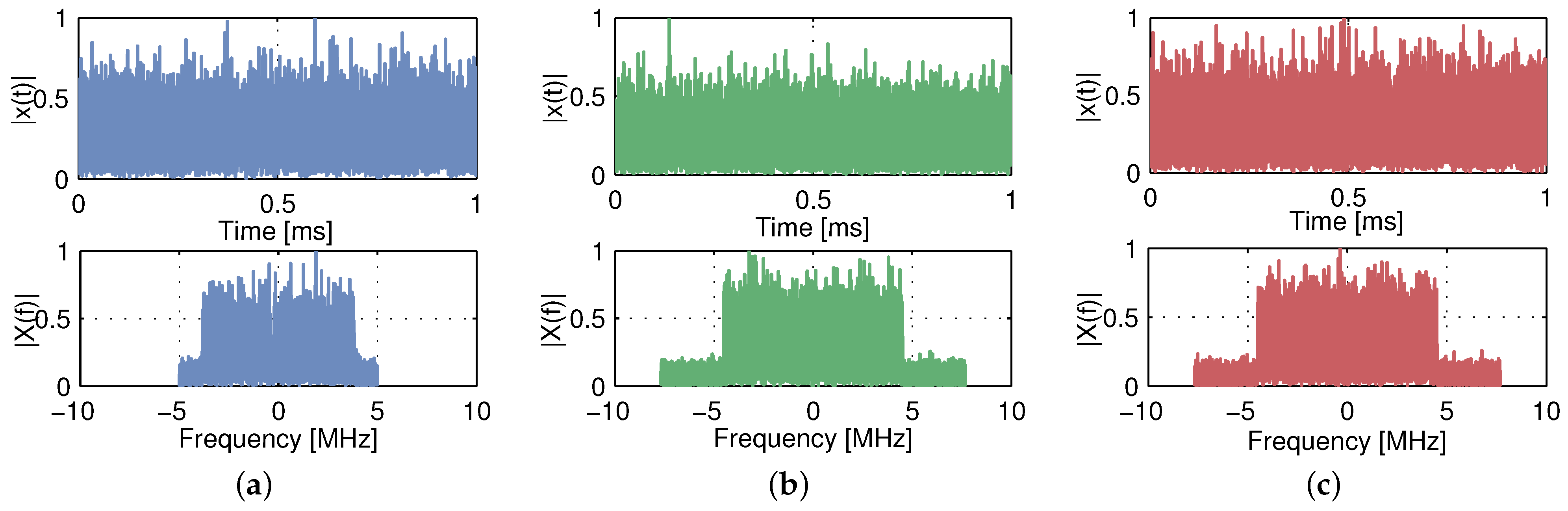
5.2.1. Data Analysis
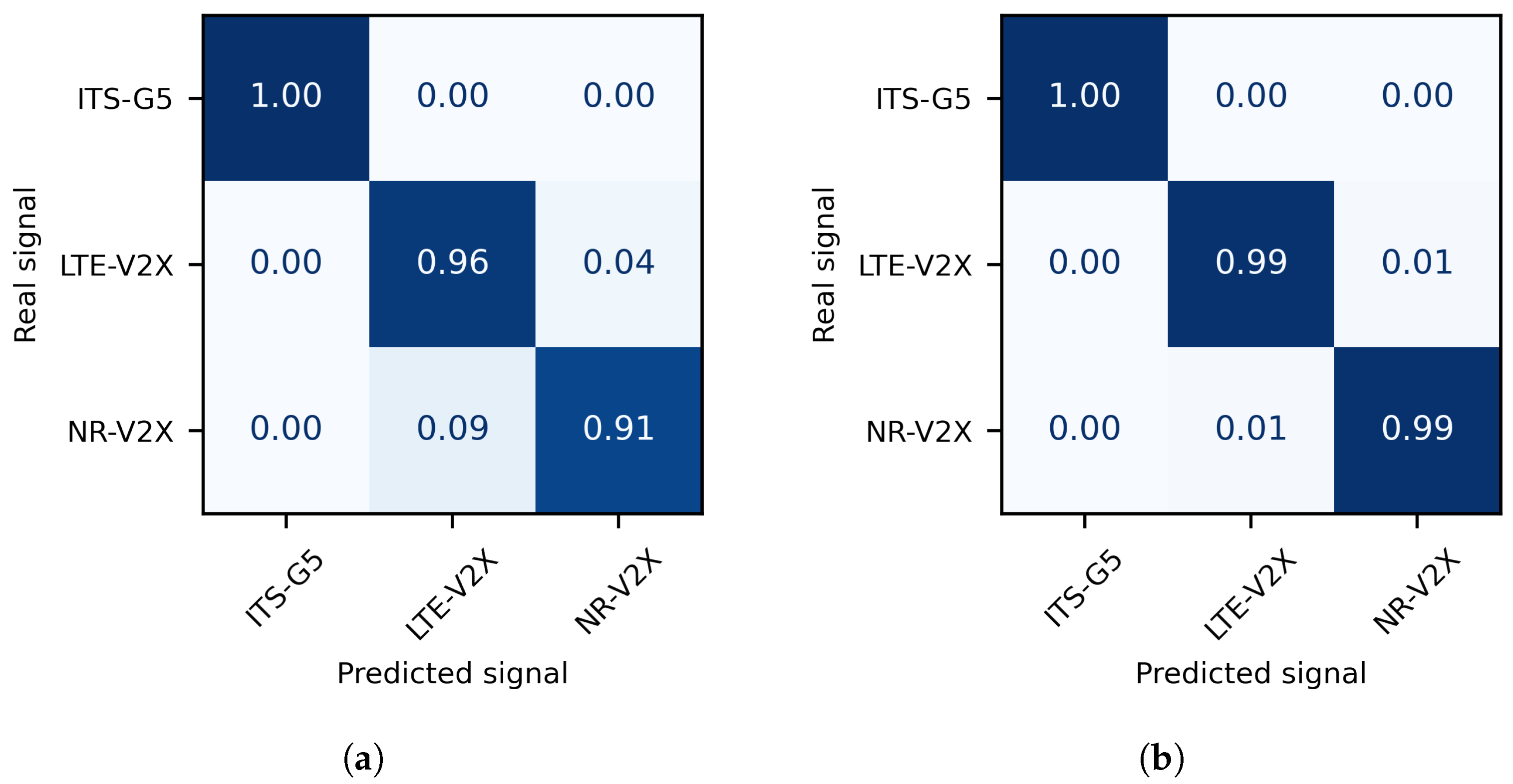
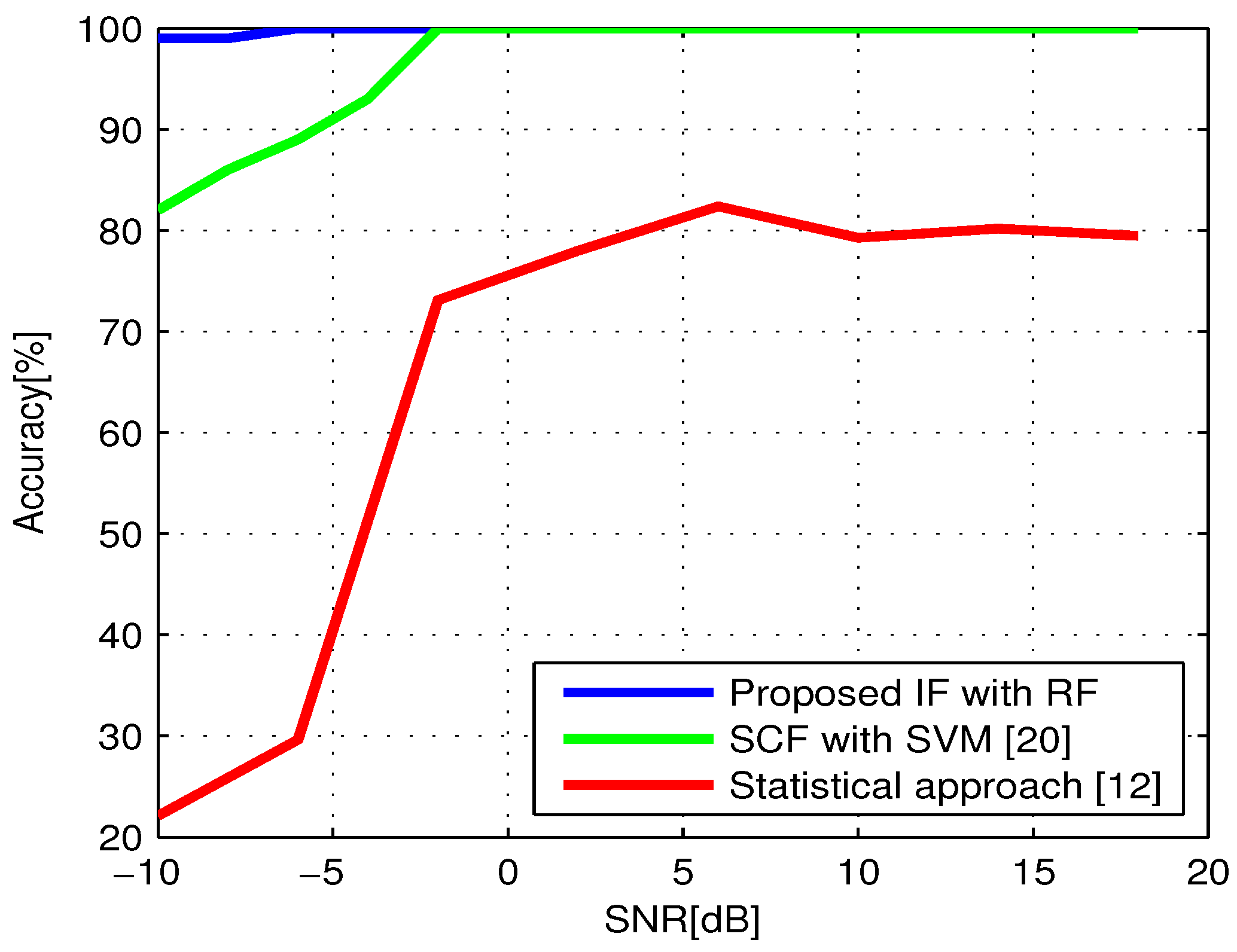
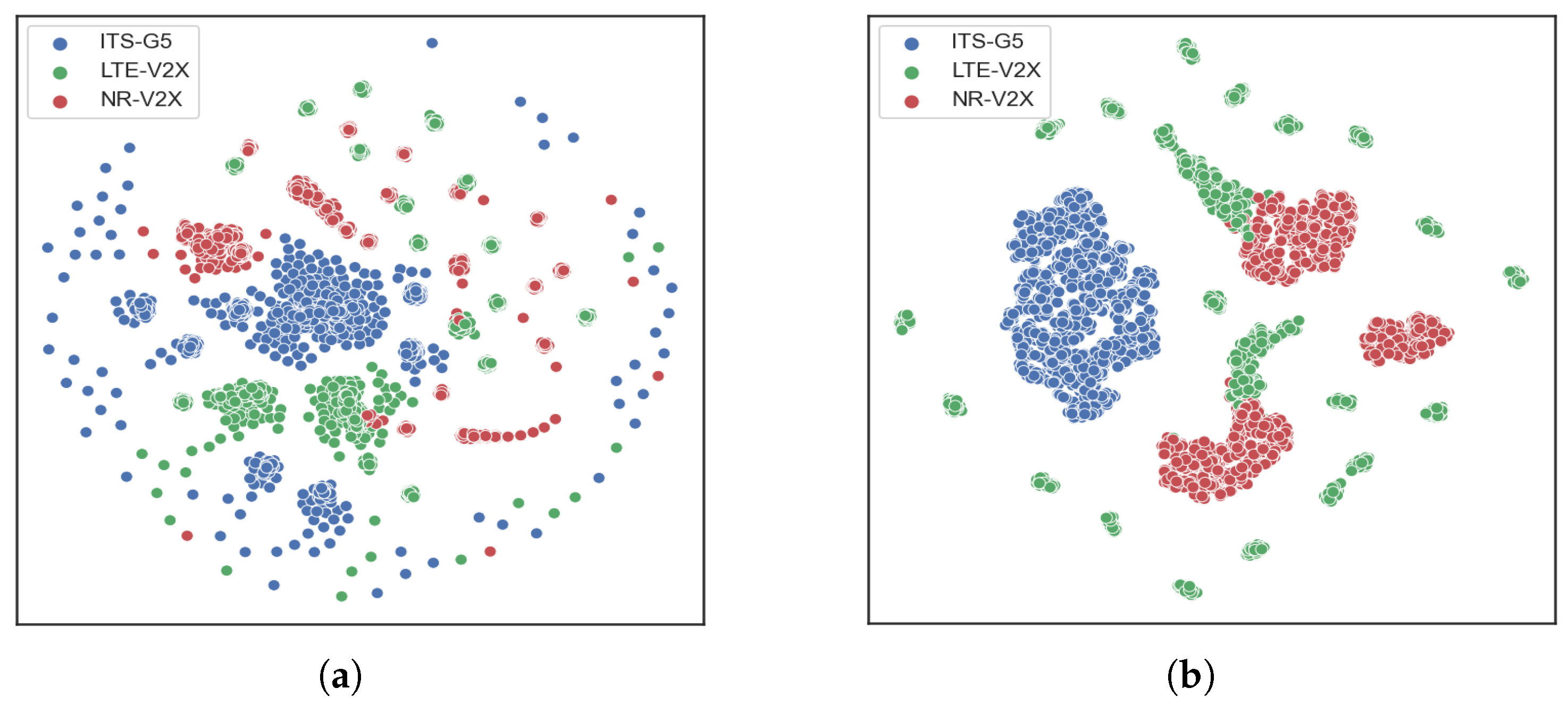
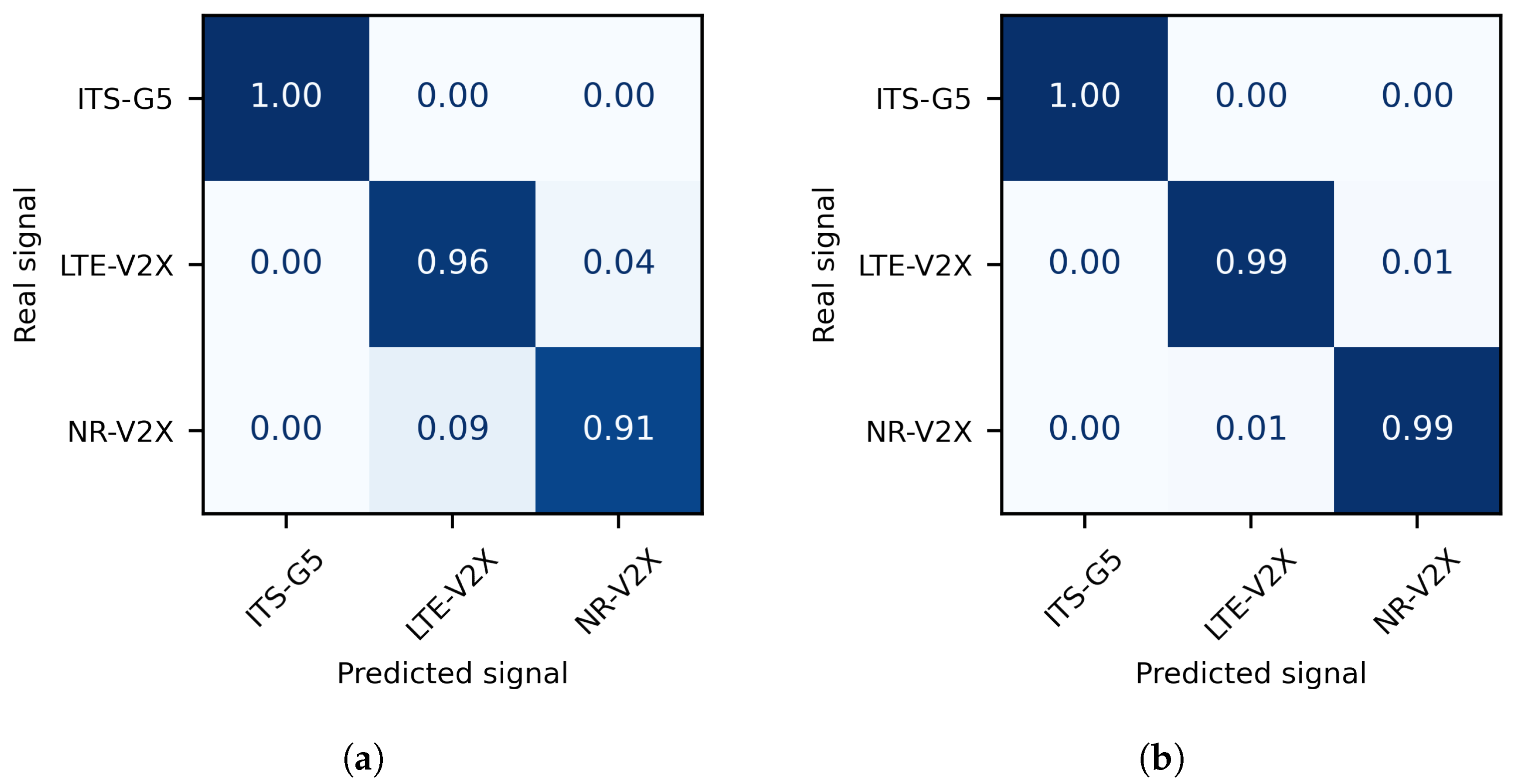
5.2.2. Performance Analysis
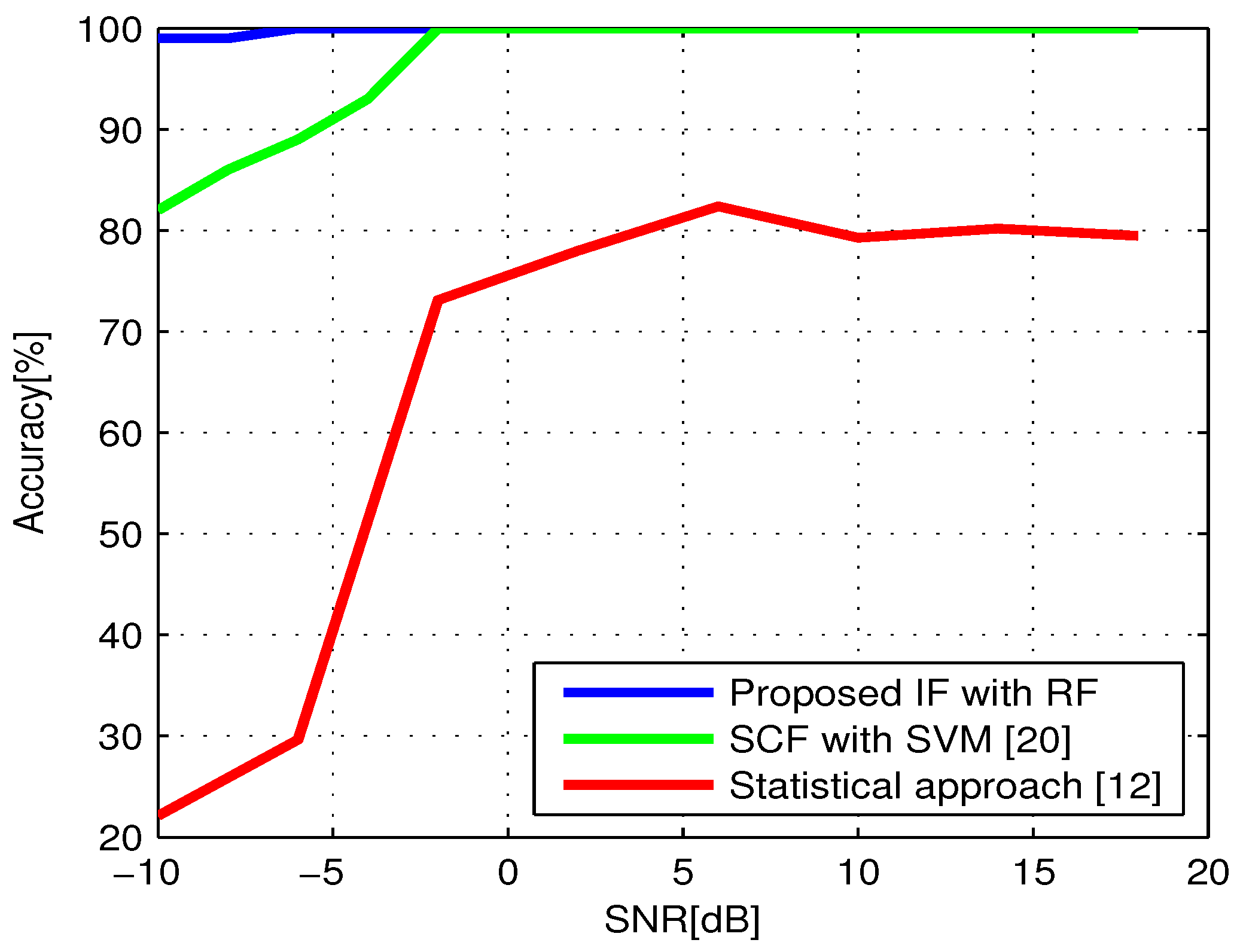
5.2.3. Complexity Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AWGN | Additive White Gaussian Noise |
| BPSK | Binary Phase Shift Keying |
| CAF | Cyclic Autocorrelation Function |
| CP | Cyclic Prefix |
| DMRS | Demodulation Reference Signal |
| EMD | Empirical Mode Decomposition |
| FAM | FFT Accumulation Method |
| FFT | Fast Fourier Transform |
| GSM | Global System for Mobile communication |
| IF | Instantaneous Frequency |
| IMF | Intrinsic Mode Function |
| ITS | Intelligent Transport Systems |
| LTE | Long-Term Evolution |
| ML | Machine Learning |
| NR | New Radio |
| OFDM | Orthogonal Frequency Division Multiplexing |
| QAM | Quadrature Amplitude Modulation |
| QPSK | Quadrature Phase Shift Keying |
| RB | Ressource Block |
| SCF | Spectral Correlation Function |
| SCI | Sidelink Control Information |
| SNR | Signal to Noise Ratio |
| SVD | Singular Value Decomposition |
| SVM | Support Vector Machine |
| TB | Transport Block |
| TF | time–frequency |
| t-SNE | t-Distributed Stochastic Neighbour Embedding |
| V2X | Vehicle-to-Everything |
| WiMAX | Worldwide Interoperability for Microwave Access |
References
- Kiela, K.; Barzdenas, V.; Jurgo, M.; Macaitis, V.; Rafanavicius, J.; Vasjanov, A.; Kladovscikov, L.; Navickas, R. Review of V2X–IoT Standards and Frameworks for ITS Applications. Appl. Sci. 2020, 10, 4314. [Google Scholar] [CrossRef]
- ETSI. ITS-G5 Access layer specification for Intelligent Transport Systems operating in the 5 GHz frequency band. In EN 302 663-V1.3.1-Intelligent Transport Systems (ITS); Technical Report; ETSI: Sophia Antipolis, France, 2019. [Google Scholar]
- ETSI. Evolved Universal Terrestrial Radio Access (E-UTRA) and Evolved Universal Terrestrial Radio Access Network (E-UTRAN); Overall description; Stage 2 (3GPP TS 36.300 version 14.2.0 Release 14). In TS 136 300-V14.2.0-LTE; Technical Report; ETSI: Sophia Antipolis, France, 2017. [Google Scholar]
- ETSI. 5G; Overall description of Radio Access Network (RAN) aspects for Vehicle-to-everything (V2X) based on LTE and NR (3GPP TR 37.985 version 16.0.0 Release 16). In TR 137 985-V16.0.0-LTE; Technical Report; ETSI: Sophia Antipolis, France, 2020. [Google Scholar]
- Choi, J.; Marojevic, V.; Dietrich, C.B.; Reed, J.H.; Ahn, S. Survey of Spectrum Regulation for Intelligent Transportation Systems. IEEE Access 2020, 8, 140145–140160. [Google Scholar] [CrossRef]
- Dobre, O.; Abdi, A.; Bar-Ness, Y.; Su, W. Survey of automatic modulation classification techniques: Classical approaches and new trends. IET Commun. 2007, 1, 137. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y.Q.; Liu, J.; Tan, X.H. Digital modulation recognition based on instantaneous information. J. China Univ. Posts Telecommun. 2010, 17, 52–90. [Google Scholar] [CrossRef]
- Moser, E.; Moran, M.K.; Hillen, E.; Li, D.; Wu, Z. Automatic modulation classification via instantaneous features. In Proceedings of the IEEE National Aerospace Electronics Conference, NAECON, Dayton, OH, USA, 15–19 June 2015; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2016; pp. 218–223. [Google Scholar] [CrossRef]
- Le Martret, C.J.; Boitea, D.M. Modulation classification by means of different orders statistical moments. In Proceedings of the IEEE Military Communications Conference MILCOM, Monterey, CA, USA, 3–5 November 1997; Volume 3, pp. 1387–1391. [Google Scholar] [CrossRef]
- Swami, A.; Sadler, B.M. Hierarchical digital modulation classification using cumulants. IEEE Trans. Commun. 2000, 48, 416–429. [Google Scholar] [CrossRef]
- Zhang, Q.; Dobre, O.A.; Eldemerdash, Y.A.; Rajan, S.; Inkol, R. Second-order cyclostationarity of BT-SCLD signals: Theoretical developments and applications to signal classification and blind parameter estimation. IEEE Trans. Wirel. Commun. 2013, 12, 1501–1511. [Google Scholar] [CrossRef]
- Karami, E.; Dobre, O.A.; Adnani, N. Identification of GSM and LTE signals using their second-order cyclostationarity. In Proceedings of the Conference Record-IEEE Instrumentation and Measurement Technology Conference, Pisa, Italy, 11–14 May 2015; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2015; pp. 1108–1112. [Google Scholar] [CrossRef] [Green Version]
- Al-Habashna, A.; Dobre, O.A.; Venkatesan, R.; Popescu, D.C. Second-order cyclostationarity of mobile WiMAX and LTE OFDM signals and application to spectrum awareness in cognitive radio systems. IEEE J. Sel. Top. Signal Process. 2012, 6, 26–42. [Google Scholar] [CrossRef]
- Al-Nuaimi, D.H.; Hashim, I.A.; Zainal Abidin, I.S.; Salman, L.B.; Mat Isa, N.A. Performance of Feature-Based Techniques for Automatic Digital Modulation Recognition and Classification—A Review. Electronics 2019, 8, 1407. [Google Scholar] [CrossRef] [Green Version]
- Shi, Y.; Davaslioglu, K.; Sagduyu, Y.E.; Headley, W.C.; Fowler, M.; Green, G. Deep Learning for RF Signal Classification in Unknown and Dynamic Spectrum Environments. In Proceedings of the 2019 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Newark, NJ, USA, 11–14 November 2019. [Google Scholar]
- Bitar, N.; Muhammad, S.; Refai, H.H. Wireless technology identification using deep convolutional neural networks. In Proceedings of the IEEE International Symposium on Personal, Indoor and Mobile Radio Communications, PIMRC, Montreal, QC, Canada, 8–13 October 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Li, X.; Dong, F.; Zhang, S.; Guo, W. A Survey on Deep Learning Techniques in Wireless Signal Recognition. Wirel. Commun. Mob. Comput. 2019. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.X.; Ren, Y.J. Recognition of digital modulation signals based on high order cumulants and support vector machines. In Proceedings of the 2009 Second ISECS International Colloquium on Computing, Communication, Control, and Management, CCCM 2009, Sanya, China, 8–9 August 2009; Volume 4, pp. 271–274. [Google Scholar] [CrossRef]
- Wang, X.; Gao, Z.; Fang, Y.; Yuan, S.; Zhao, H.; Gong, W.; Qiu, M.; Liu, Q. A signal modulation type recognition method based on kernel PCA and random forest in cognitive network. In Intelligent Computing Methodologies; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; Volume 8589, pp. 522–528. [Google Scholar] [CrossRef]
- Tekbiyik, K.; Akbunar, O.; Ekti, A.R.; Gorcin, A.; Karabulut Kurt, G. Multi-dimensional wireless signal identification based on support vector machines. IEEE Access 2019, 7, 138890–138903. [Google Scholar] [CrossRef]
- Tekbıyık, K.; Akbunar, O.; Ekti, A.R.; Görçin, A.; Kurt, G.K.; Qaraqe, K.A. Spectrum Sensing and Signal Identification with Deep Learning based on Spectral Correlation Function. arXiv 2020, arXiv:2003.08359. [Google Scholar]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Snin, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Fraiwan, L.; Lweesy, K.; Khasawneh, N.; Wenz, H.; Dickhaus, H. Automated sleep stage identification system based on time–frequency analysis of a single EEG channel and random forest classifier. Comput. Methods Programs Biomed. 2012, 108, 10–19. [Google Scholar] [CrossRef]
- Anwar, W.; Franchi, N.; Fettweis, G. Physical layer evaluation of V2X communications technologies: 5G NR-V2X, LTE-V2X, IEEE 802.11bd, and IEEE 802.11p. In Proceedings of the IEEE Vehicular Technology Conference, Honolulu, HI, USA, 22–25 September 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Sattiraju, R.; Wang, D.; Weinand, A.; Schotten, H.D. Link Level Performance Comparison of C-V2X and ITS-G5 for Vehicular Channel Models. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May 2020. [Google Scholar]
- Bazzi, A.; Cecchini, G.; Menarini, M.; Masini, B.M.; Zanella, A. Survey and Perspectives of Vehicular Wi-Fi versus Sidelink Cellular-V2X in the 5G Era. Future Internet 2019, 11, 122. [Google Scholar] [CrossRef] [Green Version]
- Fan, Y.; Liu, L.; Dong, S.; Zhuang, L.; Qiu, J.; Cai, C.; Song, M. Network Performance Test and Analysis of LTE-V2X in Industrial Park Scenario. Wirel. Commun. Mob. Comput. 2020, 2020, 1–12. [Google Scholar] [CrossRef]
- Mannoni, V.; Berg, V.; Sesia, S.; Perraud, E. A Comparison of the V2X Communication Systems: ITS-G5 and C-V2X. In Proceedings of the IEEE Vehicular Technology Conference (VTC) Spring 2019, Kuala Lumpur, Malaysia, 28 April–1 May 2019. [Google Scholar]
- Bagheri, H.; Noor-A-Rahim, M.; Liu, Z.; Lee, H.; Pesch, D.; Moessner, K.; Xiao, P. 5G NR-V2X: Towards Connected and Cooperative Autonomous Driving. arXiv 2020, arXiv:2009.03638. [Google Scholar]
- Skiribou, C.; Elbahhar, F.; Elassali, R. DMRS-based channel estimation for railway communications in tunnel environments. Veh. Commun. 2021, 29, 100340. [Google Scholar] [CrossRef]
- Jouny, I. Target recognition using scattering features extracted with EMD. In Proceedings of the 2014 IEEE Radar Conference, Cincinnati, OH, USA, 19–23 May 2014; pp. 0126–0129. [Google Scholar]
- Cheng, J.; Yu, D.; Yang, Y. A fault diagnosis approach for gears based on IMF AR model and SVM. EURASIP J. Adv. Signal Process. 2008, 2008, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Tanwar, S.; Ramani, T.; Tyagi, S. Dimensionality reduction using PCA and SVD in big data: A comparative case study. In International Conference on Future Internet Technologies and Trends; Springer: Berlin/Heidelberg, Germany, 2018; Volume 220, pp. 116–125. [Google Scholar] [CrossRef]
- Louppe, G. Understanding Random Forests: From Theory to Practice. Ph.D. Thesis, University of Liège, Liège, Belgium, 2014. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Bagging Predictors; Technical Report; Springer: Berlin/Heidelberg, Germany, 1994. [Google Scholar]
- MATLAB, version 8.1.0.604 (R2013a); The MathWorks Inc.: Natick, MA, USA, 2013.
- Van Der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Wang, Y.H.; Yeh, C.H.; Young, H.W.V.; Hu, K.; Lo, M.T. On the computational complexity of the empirical mode decomposition algorithm. Phys. A Stat. Mech. Appl. 2014, 400, 159–167. [Google Scholar] [CrossRef]
- Bilato, R.; Maj, O.; Brambilla, M. An algorithm for fast hilbert transform of real functions. Adv. Comput. Math. 2014, 40, 1159–1168. [Google Scholar] [CrossRef]
- Li, X.; Wang, S.; Cai, Y. Tutorial: Complexity analysis of Singular Value Decomposition and its variants. arXiv 2019, arXiv:1906.12085. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ITS-G5 | LTE-V2X | NR-V2X | |
|---|---|---|---|
| Bandwidth | 10 MHz | {10, 20} MHz | {10, 20, 50} MHz |
| Subcarrier spacing | 156.25 kHz | 15 kHz | {15, 30} kHz |
| FFT size | 64 | {1024, 2048} | {512, 1024, 2048} |
| CP size | 16 | {72, 144} | {36, 72, 144} |
| QAM order | {4, 16, 64} | {4, 16} | {4, 16} |
| Model | Signal | Precision | Recall | F1–Score |
|---|---|---|---|---|
| Proposed IF with RF | ITS-G5 | 1 | 1 | 1 |
| LTE-V2X | 0.99 | 0.99 | 0.99 | |
| NR-V2X | 0.99 | 0.99 | 0.99 | |
| Average | 0.99 | 0.99 | 0.99 | |
| SCF with SVM [20] | ITS-G5 | 1 | 1 | 1 |
| LTE-V2X | 0.91 | 0.96 | 0.94 | |
| NR-V2X | 0.96 | 0.91 | 0.93 | |
| Average | 0.96 | 0.96 | 0.96 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Skiribou, C.; Elbahhar, F. V2X Wireless Technology Identification Using Time–Frequency Analysis and Random Forest Classifier. Sensors 2021, 21, 4286. https://doi.org/10.3390/s21134286
Skiribou C, Elbahhar F. V2X Wireless Technology Identification Using Time–Frequency Analysis and Random Forest Classifier. Sensors. 2021; 21(13):4286. https://doi.org/10.3390/s21134286
Chicago/Turabian StyleSkiribou, Camelia, and Fouzia Elbahhar. 2021. "V2X Wireless Technology Identification Using Time–Frequency Analysis and Random Forest Classifier" Sensors 21, no. 13: 4286. https://doi.org/10.3390/s21134286
APA StyleSkiribou, C., & Elbahhar, F. (2021). V2X Wireless Technology Identification Using Time–Frequency Analysis and Random Forest Classifier. Sensors, 21(13), 4286. https://doi.org/10.3390/s21134286