
Machine Learning Strategy for Soil Nutrients Prediction Using Spectroscopic Method

Abstract
1. Introduction
2. Analysis of Machine Learning Methods
3. Materials and Methods
3.1. Research Dataset
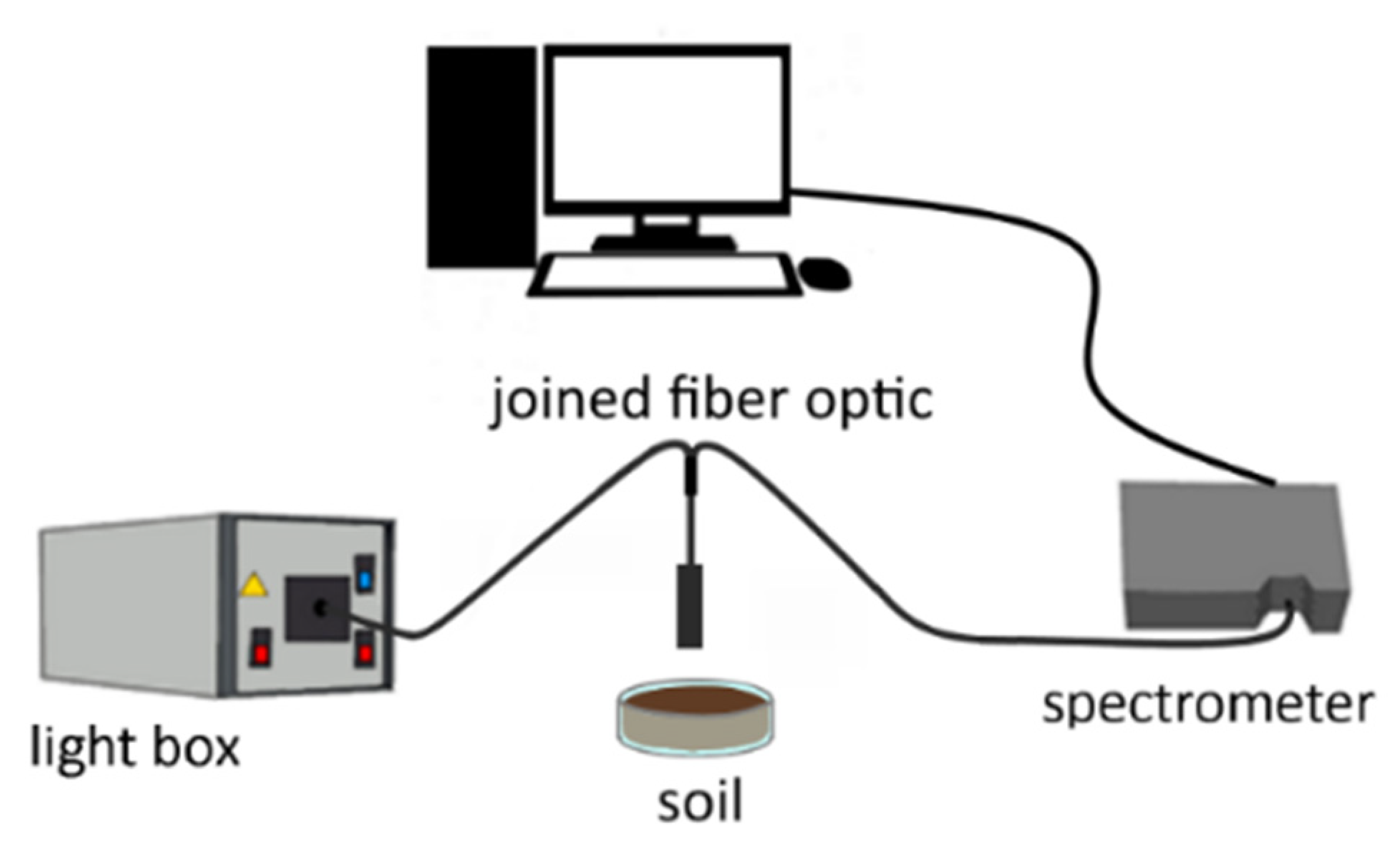
3.2. Spectroscopic Data Acquisition
4. Research Results
5. Discussion
6. Conclusions
- Multi-component analysis outperforms single-component soil prediction;
- There is no universal ML technique that can be used with the same accuracy for different research datasets and problems. Nevertheless, the comparative analysis shows a good performance of LS-SVM and ANN for our research dataset;
- The dataset of measurements corresponding to the local agricultural soil provide more effective prediction of soil properties than a dataset consisting of different geographical positions;
- The use of principal component analysis has been shown to improve overall prediction accuracy. By comparative analysis, it was estimated that 50 principal components are the optimal number for an accurate result;
- Repeated measurements followed by averaging of the same soil measurements can improve the accuracy of soil property characterization.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Adamchuk, V.; Lund, E.; Sethuramasamyraja, B.; Morgan, M.; Dobermann, A.; Marx, D. Direct measurement of soil chemical properties on-the-go using ion-selective electrodes. Comput. Electron. Agric. 2005, 48, 272–294. [Google Scholar] [CrossRef]
- Davenport, J.; Jabro, J. Assessment of hand held ion selective electrode technology for direct measurement of soil chemical properties. Commun. Soil Sci. Plant Anal. 2011, 32, 3077–3085. [Google Scholar] [CrossRef]
- Bogrekci, I.; Lee, S. Design of a Portable Raman Sensor for Phosphorus Sensing in Soils. In 2005 ASAE Annual International Meeting; American Society of Agricultural and Biological Engineers: St. Joseph, MI, USA, 2005. [Google Scholar] [CrossRef]
- Villas-Boas, P.R.; Franco, M.A.; Martin-Neto, L.; Gollany, H.T.; Milori, D.M.B.P. Applications of laser-induced breakdown spectroscopy for soil characterization, part II: Review of elemental analysis and soil classification. Eur. J. Soil Sci. 2020, 71, 805–818. [Google Scholar] [CrossRef]
- Vohland, M.; Besold, J.; Hill, J.; Fründ, H.C. Comparing different multivariate calibration methods for the determination of soil organic carbon pools with visible to near infrared spectroscopy. Geoderma 2011, 166, 198–205. [Google Scholar] [CrossRef]
- Tekin, Y.; Tumsavaş, Z.; Ulusoy, Y.; Mouazen, A.M. On-line Vis-Nir sensor determination of soil variations of sodium, potassium and magnesium. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Shanghai, China, 2016; Volume 41, p. 012011. [Google Scholar] [CrossRef]
- Mohamadi, H. Determination of Several Soil Properties Based on Ultra-Violet, Visible, and Near-Infrared Reflectance Spectroscopy. In Proceedings of the 34th International Conference on Food and Agricultural Engineering (ICFAE), Copenhagen, Denmark, 12 March 2016. [Google Scholar]
- Stenberg, B.; Rossel, R.A.V.; Mouazen, A.M.; Wetterlind, J. Chapter Five—Visible and Near Infrared Spectroscopy in Soil Science. Adv. Agron. 2010, 107, 163–215. [Google Scholar] [CrossRef]
- Chang, C.W.; Laird, D.A.; Mausbach, M.J.; Hurburgh, C.R. Near-Infrared Reflectance Spectroscopy-Principal Components Regression Analyses of Soil Properties. Soil Sci. Soc. Am. J. 2001, 65, 480–490. [Google Scholar] [CrossRef]
- Yang, M.; Xu, D.; Chen, S.; Li, H.; Shi, Z. Evaluation of Machine Learning Approaches to Predict Soil Organic Matter and pH Using vis-NIR Spectra. Sensors 2019, 19, 263. [Google Scholar] [CrossRef]
- Angelopoulou, T.; Balafoutis, A.; Zalidis, G.; Bochtis, D. From Laboratory to Proximal Sensing Spectroscopy for Soil Organic Carbon Estimation—A Review. Sustainability 2020, 12, 443. [Google Scholar] [CrossRef]
- Monteiro-Silva, F.; Jorge, P.; Martins, R. Optical Sensing of Nitrogen, Phosphorus and Potassium: A Spectrophotometrical Approach Toward Smart Nutrient Deployment. Chemosensors 2019, 7, 51. [Google Scholar] [CrossRef]
- Yu, H.; Liu, D.; Chen, G.; Wan, B.; Wang, S.; Yang, B. A neural network ensemble method for precision fertilization modeling. Math. Comput. Model. 2010, 51, 1375–1382. [Google Scholar] [CrossRef]
- Wankhede, D. Analysis and Prediction of Soil Nutrients pHNPK for Crop using Machine Learning Classifier: A Review. In International Conference on Mobile Computing and Sustainable Informatics; Springer EAI/Springer Innovations in Communication and Computing: Lalitpur, Nepal, 2020. [Google Scholar]
- Puno, J.C.; Sybingco, E.; Dadios, E.; Valenzuela, I.; Cuello, J. Determination of soil nutrients and pH level using image processing and artificial neural network. In Proceedings of the 2017 IEEE 9th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment and Management (HNICEM), Manila, Philippines, 1–3 December 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Wu, C.; Chen, Y.; Hong, X.; Liu, Z.; Peng, C. Evaluating soil nutrients of Dacrydium pectinatum in China using machine learning techniques. For. Ecosyst. 2020, 7. [Google Scholar] [CrossRef]
- Hill, M.; Connolly, P.; Reutemann, P.; Fletcher, D. The use of data mining to assist crop protection decisions on kiwifruit in New Zealand. Comput. Electron. Agric. 2014, 108, 250–257. [Google Scholar] [CrossRef]
- Rajeswari, V.; Arunesh, D.P.K.A. Analysing Soil Data using Data Mining Classification Techniques. Indian J. Sci. Technol. 2016, 9. [Google Scholar] [CrossRef]
- Padarian, J.; Minasny, B.; Mcbratney, A. Machine learning and soil sciences: A review aided by machine learning tools. Soil Discuss. 2019. [Google Scholar] [CrossRef]
- Ruder, S. An Overview of Multi-Task Learning in Deep Neural Networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Srivastava, A.; Singh, S. DRIS Norms and their Field Validation in Nagpur Mandarin. J. Plant Nutr. 2008, 31, 1091–1107. [Google Scholar] [CrossRef]
- Heckman, J.R. FS719, Soil Fertility Test Interpretation. Phosphorus, Potassium, Magnesium, and Calcium; Rutgers Cooperative Extension, The state university of New Jersey: New Brunswick, NJ, USA, 2006; pp. 1091–1107. [Google Scholar]
- Nutrients Testing-Agro Cares. Available online: https://www.agrocares.com/products/scanner (accessed on 17 June 2021).
- Morellos, A.; Pantazi, X.E.; Moshou, D.; Alexandridis, T.; Whetton, R.; Tziotzios, G.; Wiebensohn, J.; Bill, R.; Mouazen, A.M. Machine learning based prediction of soil total nitrogen, organic carbon and moisture content by using VIS-NIR spectroscopy. Biosyst. Eng. 2016, 152, 104–116. [Google Scholar] [CrossRef]
- Ng, W.; Husnain, H.; Anggria, L.; Siregar, A.; Hartatik, W.; Sulaeman, Y.; Jones, E.; Minasny, B. Developing a soil spectral library using a low-cost NIR spectrometer for precision fertilization in Indonesia. Geoderma Reg. 2020, 22, e00319. [Google Scholar] [CrossRef]
- Pantazi, X.; Moshou, D.; Alexandridis, T.; Whetton, R.; Mouazen, A. Wheat yield prediction using machine learning and advanced sensing techniques. Comput. Electron. Agric. 2016, 121, 57–65. [Google Scholar] [CrossRef]
- EnviStats India 2019 (Vol. II-Environment Accounts); Technical Report Vol. II-Environment Accounts; Ministry of Statistics and Programme Implementation: New Delhi, India, 2019.
- Rossel, R.A.V.; Rizzo, R.; Demattê, J.; Behrens, T. Spatial Modeling of a Soil Fertility Index using Visible-Near-Infrared Spectra and Terrain Attributes. Soil Sci. Soc. Am. J. 2010, 74, 1293–1300. [Google Scholar] [CrossRef]
- Costa, E.M.; dos Anjos, L.H.C.; Pinheiro, H.S.K.; Gelsleichter, Y.A.; Marcondes, R.A.T. Spatial Bayesian belief networks: A participatory approach for mapping environmental vulnerability at the Itatiaia National Park, Brazil. Environ. Earth Sci. 2020, 359. [Google Scholar] [CrossRef]
- Rabie, R.; Saffaj, T.; Bouzida, I.; Saidi, O.; Kadmiri, I.M.; Lakssir, B.; El Hadrami, E.M. A comparative study between a new method and other machine learning algorithms for soil organic carbon and total nitrogen prediction using near infrared spectroscopy. Chemom. Intell. Lab. Syst. 2019, 195. [Google Scholar] [CrossRef]
- Stevens, A.; van Wesemael, B.; Bartholomeus, H.; Rosillon, D.; Tychon, B.; Ben-Dor, E. Laboratory, field and airborne spectroscopy for monitoring organic carbon content in agricultural soils. Geoderma 2008, 144, 395–404. [Google Scholar] [CrossRef]
- Moura-Bueno, J.M.; Dalmolin, R.S.D.; ten Caten, A.; Dotto, A.C.; Demattê, J.A. Stratification of a local VIS-NIR-SWIR spectral library by homogeneity criteria yields more accurate soil organic carbon predictions. Geoderma 2019, 337, 565–581. [Google Scholar] [CrossRef]
- Nawar, S.; Mouazen, A. On-line vis-NIR spectroscopy prediction of soil organic carbon using machine learning. Soil Tillage Res. 2019, 190, 120–127. [Google Scholar] [CrossRef]
- Benedet, L.; Acuña-Guzman, S.F.; Faria, W.M.; Silva, S.H.G.; Mancini, M.; dos Teixeira, A.F.S.; Pierangeli, L.M.P.; Acerbi, F.W., Jr.; Gomide, L.R.; Pádua, A.L., Jr.; et al. Rapid soil fertility prediction using X-ray fluorescence data and machine learning algorithms. Catena 2021, 197, 105003. [Google Scholar] [CrossRef]
- Rose, S.; Savarimuthu, N.; Sangeetha, S. Machine Learning and Statistical Approaches used in Estimating Parameters that Affect the Soil Fertility Status: A Survey. In Proceedings of the 2018 Second International Conference on Green Computing and Internet of Things (ICGCIoT), Bangalore, India, 16–18 August 2018; pp. 381–385. [Google Scholar] [CrossRef]
- Ghanshala, K.; Chauhan, R.; Joshi, R. A Novel Framework for Smart Crop Monitoring Using Internet of Things (IOT). In Proceedings of the 2018 First International Conference on Secure Cyber Computing and Communication (ICSCCC), Jalandhar, India, 15–17 December 2018; pp. 62–67. [Google Scholar] [CrossRef]
- John, K.; Isong, I.; Kebonye, N.; Ayito, E.; Agyeman, P.; Afu, S. Using Machine Learning Algorithms to Estimate Soil Organic Carbon Variability with Environmental Variables and Soil Nutrient Indicators in an Alluvial Soil. Land 2020, 9, 487. [Google Scholar] [CrossRef]
- Olga, C.; Janez, T. Comparison between Electrical Impedance and Optical Spectroscopy for a Field Soil Analysis. In Proceedings of the Eleventh International Conference on Sensor Device Technologies and Applications, Valencia, Spain, 21–25 November 2020; Zhukov, V., Arkady, Eds.; IARIA: Valencia, Spain, 2020; pp. 97–102. [Google Scholar]
- Olga, C.; Janez, T.; Tasic, J.F. On the Fly Soil Classification Using Impedance Spectroscopy. In Proceedings of the SEIA’19, 5th International Conference on Sensors and Electronic Instrumental Advances & 1st IFSA Frequency & Time Conference (IFTC), Adeje, Tenerife (Canary Islands), Barcelona, Spain, 25–27 September 2019; Yurish, V., Sergey, Y., Eds.; IFSA Publishing: Barcelona, Spain, 2019; pp. 61–62. [Google Scholar]
- Peng, Y.; Zhao, L.; Hu, Y.; Wang, G.; Wang, L.; Liu, Z. Prediction of Soil Nutrient Contents Using Visible and Near-Infrared Reflectance Spectroscopy. ISPRS Int. J. Geo Inf. 2019, 8, 437. [Google Scholar] [CrossRef]
- Jin, X.; Li, S.; Zhang, W.; Zhu, J.; Sun, J. Prediction of Soil-Available Potassium Content with Visible Near-Infrared Ray Spectroscopy of Different Pretreatment Transformations by the Boosting Algorithms. Appl. Sci. 2020, 10, 1520. [Google Scholar] [CrossRef]
- Shao, Y.; He, Y. Nitrogen, phosphorus, and potassium prediction in soils, using infrared spectroscopy. Soil Res. 2011, 49, 166–172. [Google Scholar] [CrossRef]
- Wang, Y.; Li, M.; Ji, R.; Wang, M.; Zheng, L. Comparison of Soil Total Nitrogen Content Prediction Models Based on Vis-NIR Spectroscopy. Sensors 2020, 20, 7078. [Google Scholar] [CrossRef] [PubMed]
- Ding, J.; Yang, A.X.; Wang, J.; Sagan, V.; Yu, D. Machine-learning-based quantitative estimation of soil organic carbon content by VIS/NIR spectroscopy. PeerJ 2018, 6, e5714. [Google Scholar] [CrossRef] [PubMed]
- Gholizadeh, A.; Saberioon, M.; Ben-Dor, E.; Rossel, R.V.; Boruvka, L. Modelling potentially toxic elements in forest soils with vis–NIR spectra and learning algorithms. Environ. Pollut. 2020, 267, 115574. [Google Scholar] [CrossRef]
- Li, X.; Fan, P.P.; Liu, Y.; Hou, G.L.; Wang, Q.; Lv, M.R. Prediction Results of Different Modeling Methods in Soil Nutrient Concentrations Based on Spectral Technology. J. Appl. Spectrosc. 2019, 86. [Google Scholar] [CrossRef]
- Leng, W.; Zhou, Y.; Fudi, C.; Xiu, Z.L.; Yang, D. Evaluation Models for Soil Nutrient Based on Support Vector Machine and Artificial Neural Networks. Sci. World J. 2014, 2014, 478569. [Google Scholar] [CrossRef]
- MATLAB. 9.7.0.1190202 (R2019b); The MathWorks Inc.: Natick, MA, USA, 2018.
- Agreculture Institute of Slovenia. Available online: https://arhiv.kis.si/pls/kis/!kis.web?j=EN (accessed on 29 March 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods Used for Comparison | Best Method | Reference |
|---|---|---|
| PCR, PLSR, LS-SVM and CB | LS-SVM for OC, CB for N | [24] |
| PLSR, LS-SVM, ELM and CB | ELM for OC | [10] |
| ANN, RF PLSR and CB | CB for OC, PLSR for N | [29] |
| PLS, BPNN, ELM | ELM for OC and N | [30] |
| PLSR, BPNN and GA-BPNN | GA-BPNN for N, P, K | [40] |
| PLS and SVR | SVR for available K | [41] |
| LS-SVM and PLSR | LS-VM for N, P and K | [42] |
| OLSE, RF and ELM | ELM for N | [43] |
| AOC-iPLS, RF and RF-SVM | RF-SVM for OC | [44] |
| PLSR, SVM, RF, ANN and DL | ANN for Cr and Al | [45] |
| PCR, PLSR, LS-SVM, BP-NN | BPNN and LS-SVM for different nutrients | [46] |
| RF, Cubist, SVM, ANN and MLR. | RF for OC | [37] |
| 13 ANN models | GRNN for nutrients | [47] |
| Method | Advantages |
|---|---|
| Regression | Low computation time |
| Performs well with large datasets | |
| Reduce data dimensionality | |
| Provide a feature selection | |
| Easy to implement | |
| DT | Can be effectively applied for the nonlinear problem |
| Performs well with large datasets | |
| In built feature selection procedure | |
| Easy to implement | |
| SVM | Can be effectively applied for the nonlinear problem |
| Performs well when data dimensionality is greater than the number of samples | |
| Low risk of the over-fitting | |
| NB | Can be effectively applied for the nonlinear problem |
| Low computation time | |
| Suitable for multi-class problems | |
| Effective for small training datasets | |
| Easy to implement | |
| Robust to small dataset changes | |
| Probabilistic predictions can be obtained | |
| RF | Can be effectively applied for the nonlinear problem |
| May be applicable to soils under a great variety of environments | |
| Act to reduce bias | |
| Performs well with large datasets | |
| Overfitting is less common | |
| Accommodate random inputs and random features | |
| Can be used for classification as well as for regression | |
| NN | Can be effectively applied for the nonlinear problem |
| Effective in many applications | |
| Defined fault tolerance that makes classification more robust | |
| Robust to small dataset changes | |
| Can perform in parallel without affecting the system |
| Method | Disadvantages |
|---|---|
| Regression | Do not deal with nonlinear problems |
| over-fitting may occur | |
| DT | Over-fitting may occur |
| Non-robust to small dataset changes | |
| Input parameters, such as nods numbers, need to be defined manually | |
| SVM | Non-robust to small dataset changes |
| Is not suitable for large datasets, where data dimensionality is smaller than number of samples | |
| Effective kernel function is not easy to define | |
| Large computational time for large datasets | |
| Different impact of the weights parameters that is not easy to visualize their impact | |
| Needs adaptation for multi-class problems | |
| Not easy to implement | |
| NB | Assigning zero probability to a categorical variable is not available |
| variable loss of accuracy | |
| RF | Had difficulty predicting high and low laboratory measured values, underestimating and overestimating them, respectively |
| Number of trees need to be defined manually | |
| Long computation time | |
| Large computational power is required due to the large amount of the trees created by the algorithm | |
| NN | Effective architecture parameters need to be defined manually |
| Difficult to implement | |
| Require large training dataset | |
| Large computational power is required | |
| Weights are assigned randomly, so as to acquire high accuracy, the process of training the data must be iterative | |
| Classes have to be translated into numerical values | |
| The duration of the network is unknown |
| Score, mg/100 g | Category I | Category II | Category III |
|---|---|---|---|
| 0–3 | 1 | 1 | 1 |
| 5–7 | 2 | ||
| 8–10 | 3 | ||
| 11–13 | 4 | 2 | |
| 14–17 | 5 | ||
| 18–20 | 6 | 2 | |
| 21–23 | 7 | 3 | |
| 24–27 | 8 | ||
| 28–30 | 9 | ||
| 31–33 | 10 | 4 | 3 |
| 34–37 | 11 | ||
| 38–40 | 12 | ||
| >40 | 13 | 5 |
| Categories | Phosphorus | Potassium | Magnesium |
|---|---|---|---|
| Category I | 74.47% | 79.43% | 84.39% |
| Category II | 61.7% | 72.34% | 80.85% |
| Category III | 60.99% | 70.21% | 63.83% |
| ML Method | Phosphorus | Potassium | Magnesium | |||
|---|---|---|---|---|---|---|
| P | PKM | K | PKM | M | PKM | |
| SVM | 60.9% | 61.0% | 69.5% | 69.5% | 73.8% | 79.4% |
| DT | 61.7% | 61.7% | 71.6% | 72.3% | 82.3% | 80.9% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trontelj ml., J.; Chambers, O. Machine Learning Strategy for Soil Nutrients Prediction Using Spectroscopic Method. Sensors 2021, 21, 4208. https://doi.org/10.3390/s21124208
Trontelj ml. J, Chambers O. Machine Learning Strategy for Soil Nutrients Prediction Using Spectroscopic Method. Sensors. 2021; 21(12):4208. https://doi.org/10.3390/s21124208
Chicago/Turabian StyleTrontelj ml., Janez, and Olga Chambers. 2021. "Machine Learning Strategy for Soil Nutrients Prediction Using Spectroscopic Method" Sensors 21, no. 12: 4208. https://doi.org/10.3390/s21124208
APA StyleTrontelj ml., J., & Chambers, O. (2021). Machine Learning Strategy for Soil Nutrients Prediction Using Spectroscopic Method. Sensors, 21(12), 4208. https://doi.org/10.3390/s21124208