
Automatic Visual Attention Detection for Mobile Eye Tracking Using Pre-Trained Computer Vision Models and Human Gaze


Abstract
1. Introduction
2. Related Work
2.1. Eye Gaze in Human-Computer Interaction
2.2. Gaze-to-AOI Mapping
2.3. Computer Vision
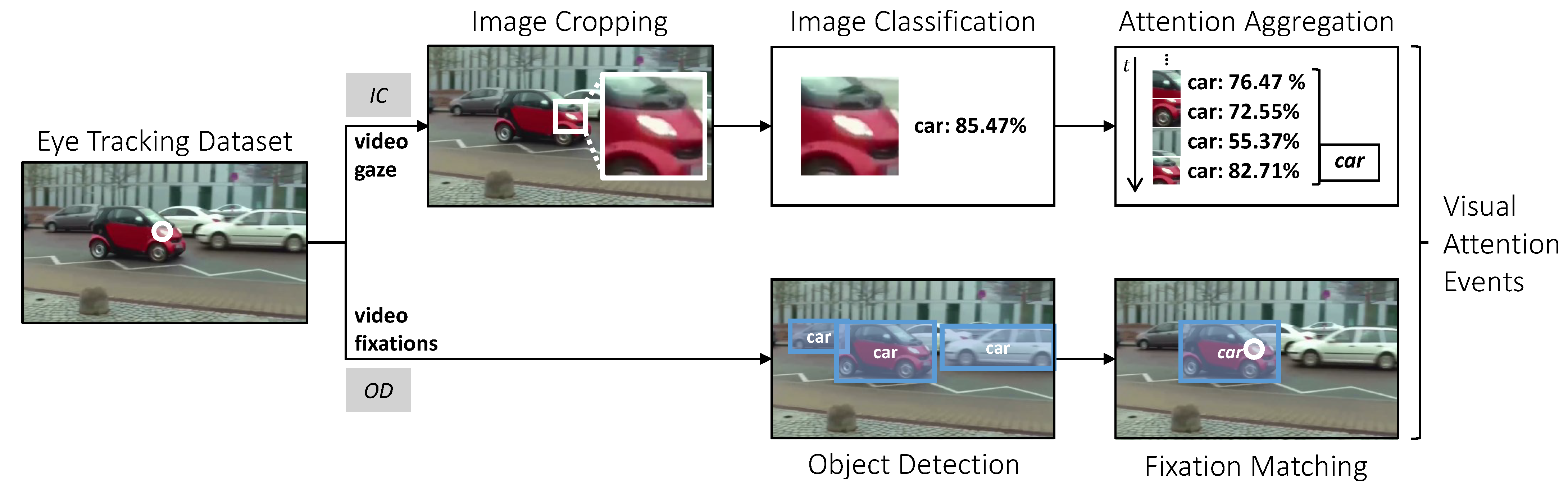
3. Method
3.1. Detect Attention Using Gaze-Guided Image Classification (IC)
3.2. Detect Attention Using Object Detection (OD)
4. Evaluation
4.1. Dataset
4.1.1. Scenarios & Challenges
4.1.2. Mapping Class Labels to AOIs
4.2. Metrics
4.2.1. Event Metrics
4.2.2. Frame Metrics
4.3. Experiment Conditions & Procedure
4.4. Results
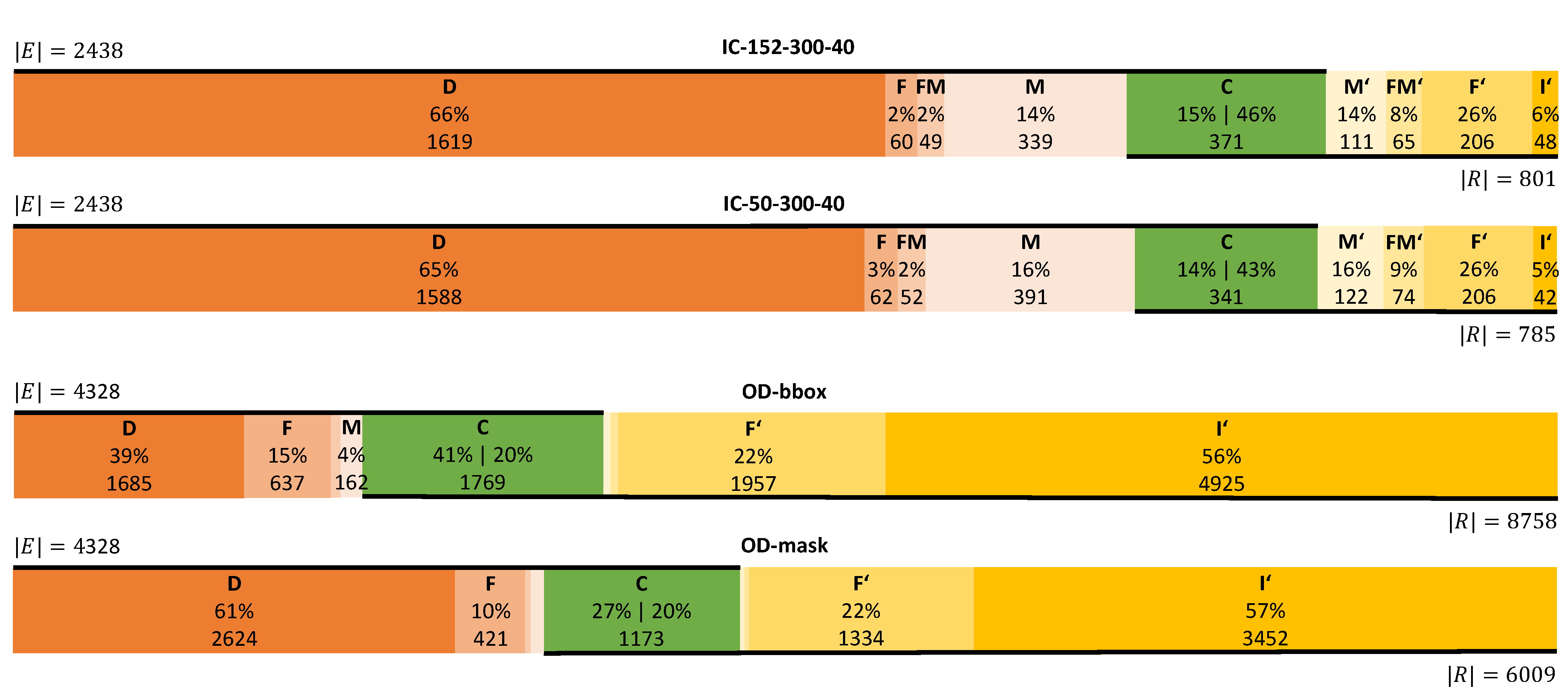
4.4.1. Overall Performance
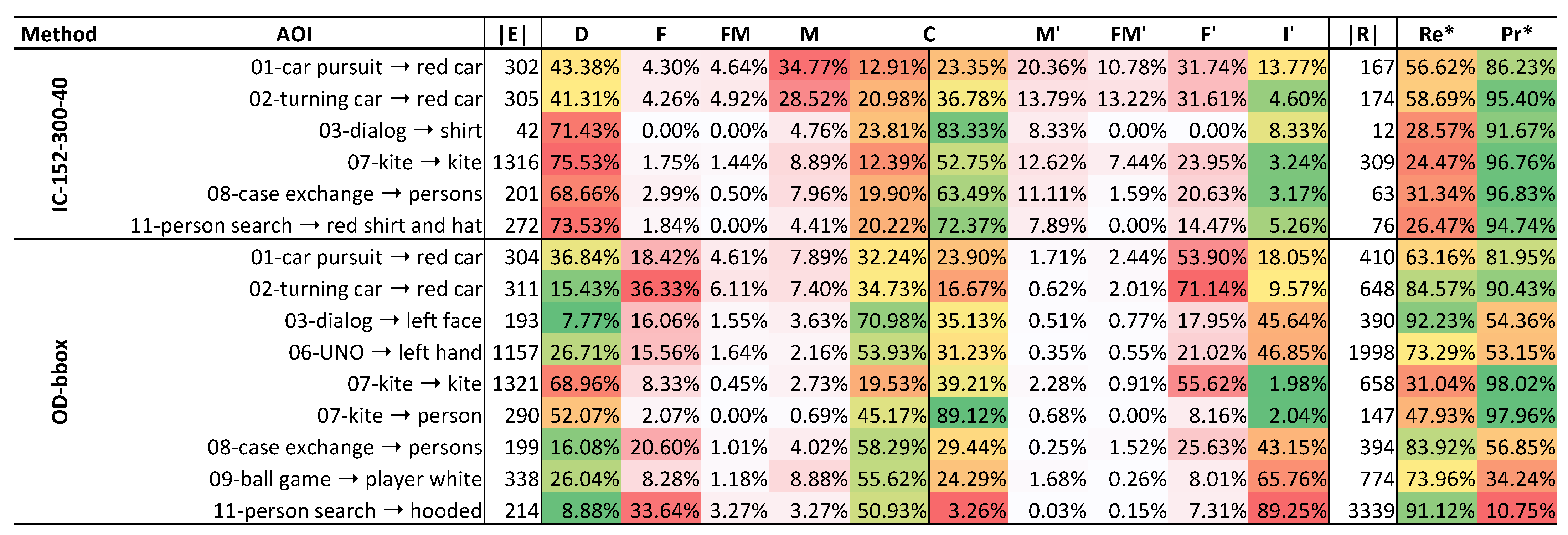
4.4.2. AOI Performance Breakdown
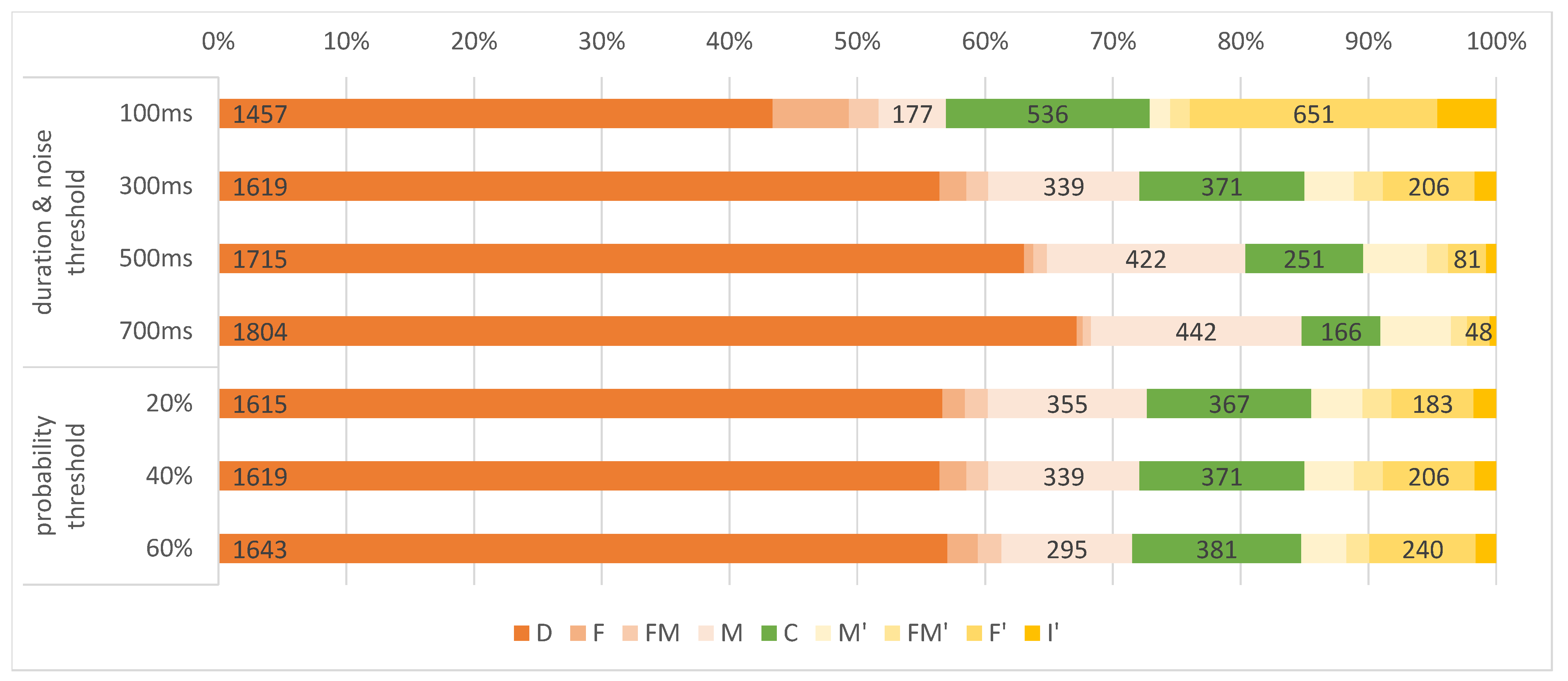
4.4.3. Impact of IC Parameters on Performance
5. Discussion
5.1. Overall Performance
5.2. Performance per AOI
5.3. Impact of IC Parameters
5.4. Impact of Re-Annotating the Ground Truth Data on Deletions
5.5. Limitations & Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| General | |
| AOI | Area of Interest |
| IC | [Method] Detect Attention using Gaze-guided Image Classification |
| OD | [Method] Detect Attention using Object Detection |
| EAD | Event Analysis Diagram |
| Event-based Error Classes and Metrics | |
| Number of ground truth events | |
| Number of predicted events, or returns | |
| D | Number of deletion errors (false negatives) |
| Number of insertion errors (false positives) | |
| Number of fragmentation errors | |
| Number of merge errors | |
| Number of fragmentation and merge errors (if both occur together) | |
| C | Number of correct events |
| Event-based precision (conservative) | |
| Event-based recall (conservative) | |
| Event-based precision (progressive) | |
| Event-based recall (progressive) | |
| Frame-based Error Classes and Metrics | |
| P | Total number of positive frames |
| N | Total number of negative frames |
| Number of true positives (frames) | |
| Number of true negatives (frames) | |
| Number of deletion errors (frames), deletion rate | |
| Number of insertion errors (frames), insertion rate | |
| Number of fragmentation errors (frames), fragmentation rate | |
| Number of merge errors (frames), merging rate | |
| Number of overfill errors (frames), ratio of overfills | |
| Number of underfill errors (frames), ratio of underfills | |
| True positive rate | |
| False positive rate | |
References
- Holmqvist, K.; Andersson, R. Eye Tracking: A Comprehensive Guide to Methods, Paradigms and Measures; Lund Eye-Tracking Research Institute: Lund, Sweden, 2011. [Google Scholar]
- Kurzhals, K.; Bopp, C.F.; Bässler, J.; Ebinger, F.; Weiskopf, D. Benchmark data for evaluating visualization and analysis techniques for eye tracking for video stimuli. In Proceedings of the Fifth Workshop on Beyond Time and Errors: Novel Evaluation Methods for Visualization, BELIV ’14, Paris, France, 10 November 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 54–60. [Google Scholar] [CrossRef]
- Yu, L.H.; Eizenman, M. A new methodology for determining point-of-gaze in head-mounted eye tracking systems. IEEE Trans. Biomed. Eng. 2004, 51, 1765–1773. [Google Scholar] [CrossRef]
- Pfeiffer, T.; Renner, P.; Pfeiffer-Leßmann, N. EyeSee3D 2.0: Model-based real-time analysis of mobile eye-tracking in static and dynamic three-dimensional scenes. In Proceedings of the Ninth Biennial ACM Symposium on Eye Tracking Research & Applications, ETRA ’16, Charleston, SC, USA, 14 March 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 189–196. [Google Scholar] [CrossRef]
- Barz, M.; Daiber, F.; Sonntag, D.; Bulling, A. Error-Aware Gaze-Based Interfaces for Robust Mobile Gaze Interaction. In Proceedings of the 2018 ACM Symposium on Eye Tracking Research & Applications, Warsaw, Poland, 14 June 2018; ACM: New York, NY, USA, 2018; pp. 24:1–24:10. [Google Scholar] [CrossRef]
- Mehlmann, G.; Häring, M.; Janowski, K.; Baur, T.; Gebhard, P.; André, E. Exploring a Model of Gaze for Grounding in Multimodal HRI. In Proceedings of the 16th International Conference on Multimodal Interaction-ICMI ’14, Istanbul, Turkey, 12 November 2014; ACM: New York, NY, USA, 2014; pp. 247–254. [Google Scholar] [CrossRef]
- Barz, M.; Sonntag, D. Gaze-guided object classification using deep neural networks for attention-based computing. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing Adjunct-UbiComp ’16, Heidelberg, Germany, 12 September 2016; ACM Press: New York, NY, USA, 2016; pp. 253–256. [Google Scholar] [CrossRef]
- Kurzhals, K.; Hlawatsch, M.; Seeger, C.; Weiskopf, D. Visual Analytics for Mobile Eye Tracking. IEEE Trans. Vis. Comput. Graph. 2017, 23, 301–310. [Google Scholar] [CrossRef] [PubMed]
- Machado, E.; Carrillo, I.; Chen, L. Visual Attention-Based Object Detection in Cluttered Environments. In Proceedings of the 2019 IEEE SmartWorld, Ubiquitous Intelligence Computing, Advanced Trusted Computing, Scalable Computing Communications, Cloud Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Leicester, UK, 19–23 August 2019; pp. 133–139. [Google Scholar] [CrossRef]
- Pontillo, D.F.; Kinsman, T.B.; Pelz, J.B. SemantiCode: Using content similarity and database-driven matching to code wearable eyetracker gaze data. In Eye Tracking Research and Applications Symposium (ETRA); ACM Press: New York, NY, USA, 2010; pp. 267–270. [Google Scholar] [CrossRef]
- Toyama, T.; Kieninger, T.; Shafait, F.; Dengel, A. Gaze guided object recognition using a head-mounted eye tracker. In Proceedings of the Symposium on Eye Tracking Research and Applications, ETRA ’12, Santa Barbara, CA, USA, 28 March 2012; ACM: New York, NY, USA, 2012; pp. 91–98. [Google Scholar] [CrossRef]
- Panetta, K.; Wan, Q.; Kaszowska, A.; Taylor, H.A.; Agaian, S. Software Architecture for Automating Cognitive Science Eye-Tracking Data Analysis and Object Annotation. IEEE Trans. Hum. Mach. Syst. 2019, 49, 268–277. [Google Scholar] [CrossRef]
- Venuprasad, P.; Xu, L.; Huang, E.; Gilman, A.; Chukoskie, L.; Cosman, P. Analyzing Gaze Behavior Using Object Detection and Unsupervised Clustering. In Proceedings of the ACM Symposium on Eye Tracking Research and Applications, Stuttgart, Germany, 2 June 2012; Association for Computing Machinery: New York, NY, USA, 2020; p. 9. [Google Scholar] [CrossRef]
- Brône, G.; Oben, B.; Goedemé, T. Towards a more effective method for analyzing mobile eye-tracking data: Integrating gaze data with object recognition algorithms. In Proceedings of the 1st International Workshop on Pervasive Eye Tracking & Mobile Eye-Based Interaction, PETMEI ’11, Beijing, China, 18 September 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 53–56. [Google Scholar] [CrossRef]
- De Beugher, S.; Brône, G.; Goedemé, T. Automatic analysis of in-the-wild mobile eye-tracking experiments using object, face and person detection. In Proceedings of the 2014 International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014; Volume 1, pp. 625–633. [Google Scholar]
- Wolf, J.; Hess, S.; Bachmann, D.; Lohmeyer, Q.; Meboldt, M. Automating areas of interest analysis in mobile eye tracking experiments based on machine learning. J. Eye Mov. Res. 2018, 11, 6. [Google Scholar] [CrossRef]
- Huang, C.M.; Mutlu, B. Anticipatory robot control for efficient human-robot collaboration. In Proceedings of the 2016 11th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Christchurch, New Zealand, 7–10 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 83–90. [Google Scholar] [CrossRef]
- Ward, J.A.; Lukowicz, P.; Gellersen, H.W. Performance metrics for activity recognition. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–23. [Google Scholar] [CrossRef]
- Borji, A.; Itti, L. State-of-the-Art in Visual Attention Modeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 185–207. [Google Scholar] [CrossRef]
- Yarbus, A.L. Eye movements and vision. Neuropsychologia 1967, 6, 222. [Google Scholar] [CrossRef]
- Land, M.F.; Hayhoe, M. In what ways do eye movements contribute to everyday activities? Vis. Res. 2001, 41, 3559–3565. [Google Scholar] [CrossRef]
- DeAngelus, M.; Pelz, J.B. Top-down control of eye movements: Yarbus revisited. Vis. Cogn. 2009, 17, 790–811. [Google Scholar] [CrossRef]
- Rothkopf, C.A.; Ballard, D.H.; Hayhoe, M.M. Task and context determine where you look. J. Vis. 2016, 7, 16. [Google Scholar] [CrossRef]
- André, E.; Chai, J.Y. Introduction to the special issue on eye gaze in intelligent human-machine interaction. ACM Trans. Interact. Intell. Syst. 2012, 1, 1–3. [Google Scholar] [CrossRef]
- André, E.; Chai, J. Introduction to the special section on eye gaze and conversation. ACM Trans. Interact. Intell. Syst. 2013, 3, 1–2. [Google Scholar] [CrossRef]
- Nakano, Y.I.; Bednarik, R.; Huang, H.H.; Jokinen, K. Introduction to the special issue on new directions in eye gaze for interactive intelligent systems. ACM Trans. Interact. Intell. Syst. 2016, 6, 1–3. [Google Scholar] [CrossRef]
- Qvarfordt, P. Gaze-informed multimodal interaction. In The Handbook of Multimodal-Multisensor Interfaces: Foundations, User Modeling, and Common Modality Combinations; ACM: New York, NY, USA, 2017; Volume 1, pp. 365–402. [Google Scholar] [CrossRef]
- Ishii, R.; Nakano, Y.I.; Nishida, T. Gaze awareness in conversational agents: Estimating a user’s conversational engagement from eye gaze. ACM Trans. Interact. Intell. Syst. 2013, 3, 11:1–11:25. [Google Scholar] [CrossRef]
- Ishii, R.; Otsuka, K.; Kumano, S.; Yamato, J. Prediction of Who Will Be the Next Speaker and When Using Gaze Behavior in Multiparty Meetings. ACM Trans. Interact. Intell. Syst. 2016, 6, 4:1–4:31. [Google Scholar] [CrossRef]
- Jokinen, K.; Furukawa, H.; Nishida, M.; Yamamoto, S. Gaze and turn-taking behavior in casual conversational interactions. ACM Trans. Interact. Intell. Syst. 2013, 3, 1–30. [Google Scholar] [CrossRef]
- Prasov, Z.; Chai, J.Y. What’s in a Gaze? The Role of Eye-gaze in Reference Resolution in Multimodal Conversational Interfaces. In Proceedings of the 13th International Conference on Intelligent User Interfaces, Gran Canaria, Spain, 13 January 2008; ACM: New York, NY, USA, 2008; pp. 20–29. [Google Scholar] [CrossRef]
- Xu, T.; Zhang, H.; Yu, C. See you see me: The role of Eye contact in multimodal human-robot interaction. ACM Trans. Interact. Intell. Syst. 2016, 6, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Baur, T.; Mehlmann, G.; Damian, I.; Lingenfelser, F.; Wagner, J.; Lugrin, B.; André, E.; Gebhard, P. Context-aware automated analysis and annotation of social human-agent interactions. ACM Trans. Interact. Intell. Syst. 2015, 5, 1–33. [Google Scholar] [CrossRef]
- Thomason, J.; Sinapov, J.; Svetlik, M.; Stone, P.; Mooney, R.J. Learning Multi-modal Grounded Linguistic Semantics by Playing “I Spy”. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9 July 2016; pp. 3477–3483. [Google Scholar]
- Buscher, G.; Dengel, A.; Biedert, R.; van Elst, L. Attentive documents: Eye tracking as implicit feedback for information retrieval and beyond. ACM Trans. Interact. Intell. Syst. 2012, 1, 1–30. [Google Scholar] [CrossRef]
- Sattar, H.; Müller, S.; Fritz, M.; Bulling, A. Prediction of search targets from fixations in open-world settings. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE Computer Society: Los Alamitos, CA, USA, 2015; pp. 981–990. [Google Scholar] [CrossRef]
- Sattar, H.; Bulling, A.; Fritz, M. Predicting the Category and Attributes of Visual Search Targets Using Deep Gaze Pooling. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshop (ICCVW), Venice, Italy, 22–29 October 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 2740–2748. [Google Scholar] [CrossRef]
- Sattar, H.; Fritz, M.; Bulling, A. Deep gaze pooling: Inferring and visually decoding search intents from human gaze fixations. Neurocomputing 2020, 387, 369–382. [Google Scholar] [CrossRef]
- Stauden, S.; Barz, M.; Sonntag, D. Visual Search Target Inference using Bag of Deep Visual Words. In KI 2018: Advances in Artificial Intelligence; Trollmann, F., Turhan, A.Y., Eds.; Springer: Cham, Switzerland, 2018; pp. 297–304. [Google Scholar] [CrossRef]
- Barz, M.; Stauden, S.; Sonntag, D. Visual Search Target Inference in Natural Interaction Settings with Machine Learning. In Proceedings of the 2020 ACM Symposium on Eye Tracking Research & Applications, Stuttgart, Germany, 2 June 2012; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Bulling, A.; Weichel, C.; Gellersen, H. EyeContext: Recognition of High-level Contextual Cues from Human Visual Behaviour. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 305–308. [Google Scholar] [CrossRef]
- Steil, J.; Bulling, A. Discovery of everyday human activities from long-term visual behaviour using topic models. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing-UbiComp ’15, Osaka, Japan, 7 September 2015; ACM Press: New York, NY, USA, 2015; pp. 75–85. [Google Scholar] [CrossRef]
- Steil, J.; Müller, P.; Sugano, Y.; Bulling, A. Forecasting user attention during everyday mobile interactions using device-integrated and wearable sensors. In Proceedings of the 20th International Conference on Human-Computer Interaction with Mobile Devices and Services, MobileHCI ’18, Barcelona, Spain, 3 September 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1–13. [Google Scholar] [CrossRef]
- Fathi, A.; Li, Y.; Rehg, J.M. Learning to Recognize Daily Actions Using Gaze. In Computer Vision–ECCV 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 314–327. [Google Scholar] [CrossRef]
- Li, Y.; Zhefan Ye, Z.; Rehg, J.M. Delving into egocentric actions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 287–295. [Google Scholar] [CrossRef]
- Li, Y.; Liu, M.; Rehg, J.M. In the Eye of Beholder: Joint Learning of Gaze and Actions in First Person Video. In Proceedings of the The European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 619–635. [Google Scholar]
- Shiga, Y.; Toyama, T.; Utsumi, Y.; Kise, K.; Dengel, A. Daily activity recognition combining gaze motion and visual features. In Proceedings of the UbiComp 2014-Adjunct Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing; Association for Computing Machinery, Inc.: New York, NY, USA, 2014; pp. 1103–1111. [Google Scholar] [CrossRef]
- Ramirez-Amaro, K.; Minhas, H.N.; Zehetleitner, M.; Beetz, M.; Cheng, G. Added value of gaze-exploiting semantic representation to allow robots inferring human behaviors. ACM Trans. Interact. Intell. Syst. 2017, 7, 1–30. [Google Scholar] [CrossRef]
- Kurzhals, K.; Rodrigues, N.; Koch, M.; Stoll, M.; Bruhn, A.; Bulling, A.; Weiskopf, D. Visual analytics and annotation of pervasive eye tracking video. In Proceedings of the Eye Tracking Research and Applications Symposium (ETRA), Stuttgart, Germany, 2 June 2012; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Steichen, B.; Conati, C.; Carenini, G. Inferring visualization task properties, user performance, and user cognitive abilities from eye gaze data. ACM Trans. Interact. Intell. Syst. 2014, 4, 1–29. [Google Scholar] [CrossRef]
- Conati, C.; Lallé, S.; Rahman, M.A.; Toker, D. Comparing and Combining Interaction Data and Eye-tracking Data for the Real-time Prediction of User Cognitive Abilities in Visualization Tasks. ACM Trans. Interact. Intell. Syst. 2020, 10, 12. [Google Scholar] [CrossRef]
- De Beugher, S.; Ichiche, Y.; Brône, G.; Goedemé, T. Automatic analysis of eye-tracking data using object detection algorithms. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, UbiComp ’12, Pittsburgh, PA, USA, 5 September 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 677–680. [Google Scholar] [CrossRef]
- Evans, K.M.; Jacobs, R.A.; Tarduno, J.A.; Pelz, J.B. Collecting and Analyzing Eye-Tracking Data in Outdoor Environments. J. Eye Mov. Res. 2012, 5, 19. [Google Scholar] [CrossRef]
- Fong, A.; Hoffman, D.; Ratwani, R.M. Making Sense of Mobile Eye-Tracking Data in the Real-World: A Human-in-the-Loop Analysis Approach. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2016, 60, 1569–1573. [Google Scholar] [CrossRef]
- Panetta, K.; Wan, Q.; Rajeev, S.; Kaszowska, A.; Gardony, A.L.; Naranjo, K.; Taylor, H.A.; Agaian, S. ISeeColor: Method for Advanced Visual Analytics of Eye Tracking Data. IEEE Access 2020, 8, 52278–52287. [Google Scholar] [CrossRef]
- Sümer, O.; Goldberg, P.; Stürmer, K.; Seidel, T.; Gerjets, P.; Trautwein, U.; Kasneci, E. Teachers’ Perception in the Classroom. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 19–21 June 2018; pp. 2315–2324. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese Visual Tracking With Very Deep Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4282–4291. [Google Scholar]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. VGGFace2: A Dataset for Recognising Faces across Pose and Age. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 67–74. [Google Scholar] [CrossRef]
- Callemein, T.; Van Beeck, K.; Brône, G.; Goedemé, T. Automated Analysis of Eye-Tracker-Based Human-Human Interaction Studies. In Information Science and Applications 2018; Lecture Notes in Electrical Engineering; Kim, K.J., Baek, N., Eds.; Springer: Singapore, 2019; pp. 499–509. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Toyama, T.; Sonntag, D. Towards episodic memory support for dementia patients by recognizing objects, faces and text in eye gaze. In KI 2015: Advances in Artificial Intelligence; Springer: Cham, Switzerland, 2015; Volume 9324, pp. 316–323. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper With Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Batliner, M.; Hess, S.; Ehrlich-Adám, C.; Lohmeyer, Q.; Meboldt, M. Automated areas of interest analysis for usability studies of tangible screen-based user interfaces using mobile eye tracking. AI EDAM 2020, 34, 505–514. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. CoRR 2017, arXiv:1704.04861. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.J.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. CoRR 2014, arXiv:1405.0312. [Google Scholar]
- Zhao, Z.; Zheng, P.; Xu, S.; Wu, X. Object Detection With Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ma, M.; Fan, H.; Kitani, K.M. Going Deeper into First-Person Activity Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1894–1903. [Google Scholar]
- Bertasius, G.; Park, H.S.; Yu, S.X.; Shi, J. First-Person Action-Object Detection with EgoNet. CoRR 2016, arXiv:1603.04908. [Google Scholar]
- Barz, M.; Kapp, S.; Kuhn, J.; Sonntag, D. Automatic Recognition and Augmentation of Attended Objects in Real-time using Eye Tracking and a Head-mounted Display. In Proceedings of the ACM Symposium on Eye Tracking Research and Applications, ETRA ’21 Adjunct, Virtual Event, Germany, 25 May 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 2 May 2021).
- Steil, J.; Huang, M.X.; Bulling, A. Fixation detection for head-mounted eye tracking based on visual similarity of gaze targets. In Proceedings of the Eye Tracking Research and Applications Symposium (ETRA), Warsaw, Poland, 14 June 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Käding, C.; Rodner, E.; Freytag, A.; Denzler, J. Fine-Tuning Deep Neural Networks in Continuous Learning Scenarios. In Computer Vision–ACCV 2016 Workshops: ACCV 2016 International Workshops, Taipei, Taiwan, 20–24 November 2016, Revised Selected Papers, Part III; Chen, C.S., Lu, J., Ma, K.K., Eds.; Springer: Cham, Switzerland, 2017; pp. 588–605. [Google Scholar] [CrossRef]
- Sonntag, D.; Barz, M.; Zacharias, J.; Stauden, S.; Rahmani, V.; Fóthi, Á.; Lörincz, A. Fine-tuning deep CNN models on specific MS COCO categories. CoRR 2017, arXiv:1709.01476. [Google Scholar]
- Simard, P.; Amershi, S.; Chickering, M.; Edelman Pelton, A.; Ghorashi, S.; Meek, C.; Ramos, G.; Suh, J.; Verwey, J.; Wang, M.; et al. Machine Teaching: A New Paradigm for Building Machine Learning Systems. CoRR 2017, arXiv:1707.06742. [Google Scholar]
- Dudley, J.J.; Kristensson, P.O. A Review of User Interface Design for Interactive Machine Learning. ACM Trans. Interact. Intell. Syst. 2018, 8, 1–37. [Google Scholar] [CrossRef]
- Barz, M.; Daiber, F.; Bulling, A. Prediction of Gaze Estimation Error for Error-Aware Gaze-Based Interfaces. In Proceedings of the Ninth Biennial ACM Symposium on Eye Tracking Research & Applications, ETRA ’16, Charleston, SC, USA, 14 March 2016; ACM Press: New York, NY, USA, 2016; pp. 275–278. [Google Scholar] [CrossRef]
- Kapp, S.; Barz, M.; Mukhametov, S.; Sonntag, D.; Kuhn, J. ARETT: Augmented Reality Eye Tracking Toolkit for Head Mounted Displays. Sensors 2021, 21, 2234. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | AOI | ImageNet Labels | MS COCO Labels |
|---|---|---|---|
| 01-car pursuit (25 s) | red car | streetcar, sports car, minivan, cab, minibus, limousine, car mirror, racer, passenger car | car |
| white car | – | – | |
| 02-turning car (28 s) | red car | streetcar, sports car, minivan, cab, minibus, limousine, car mirror, racer, passenger car | car |
| 03-dialog (19 s) | left face | ear | person |
| right face | – | – | |
| shirt | sweatshirt | – | |
| 04-thimblerig (30 s) | cup1 | cocktail shaker, coffee mug, cup | cup |
| cup2 | – | bowl | |
| cup3 | – | – | |
| 05-memory (148 s) | cards | desk | dining table |
| 06-UNO (121 s) | left hand | – | person |
| right hand | – | – | |
| stack covered | desk | dining table | |
| stack uncovered | – | – | |
| 07-kite (97 s) | person | lab coat, poncho, cardigan, cloak, sweatshirt, trench coat | person |
| kite | balloon, kite, parachute | kite | |
| 08-case exchange (27 s) | persons | sombrero, cowboy hat | person |
| textbox | – | – | |
| case | mailbag, packet, plastic bag, shopping basket, backpack, bucket, crate | handbag, suitcase | |
| suspects | lab coat, poncho, cardigan, cloak, sweatshirt, trench coat | – | |
| 09-ball game (31 s) | ball | baseball, basketball, rugby ball, tennis ball, volleyball, soccer ball | sports ball |
| player white | ballplayer | person | |
| player red1 | – | – | |
| player red2 | – | – | |
| player red3 | – | – | |
| 10-bag search (133 s) | red bag | plastic bag | handbag |
| yellow bag | – | – | |
| blue bag | – | – | |
| red-white bag | – | – | |
| brown bag | mailbag | – | |
| persons | lab coat, poncho, cardigan, cloak, sweatshirt, trench coat | person | |
| 11-person search (172 s) | hooded | lab coat, poncho, cardigan, cloak, sweatshirt, trench coat | person |
| red shirt and hat | sombrero, cowboy hat | – | |
| persons | – | – |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barz, M.; Sonntag, D. Automatic Visual Attention Detection for Mobile Eye Tracking Using Pre-Trained Computer Vision Models and Human Gaze. Sensors 2021, 21, 4143. https://doi.org/10.3390/s21124143
Barz M, Sonntag D. Automatic Visual Attention Detection for Mobile Eye Tracking Using Pre-Trained Computer Vision Models and Human Gaze. Sensors. 2021; 21(12):4143. https://doi.org/10.3390/s21124143
Chicago/Turabian StyleBarz, Michael, and Daniel Sonntag. 2021. "Automatic Visual Attention Detection for Mobile Eye Tracking Using Pre-Trained Computer Vision Models and Human Gaze" Sensors 21, no. 12: 4143. https://doi.org/10.3390/s21124143
APA StyleBarz, M., & Sonntag, D. (2021). Automatic Visual Attention Detection for Mobile Eye Tracking Using Pre-Trained Computer Vision Models and Human Gaze. Sensors, 21(12), 4143. https://doi.org/10.3390/s21124143