
Radar Transformer: An Object Classification Network Based on 4D MMW Imaging Radar


Abstract
1. Introduction
- We generated an MMW imaging radar classification dataset. To the best of our knowledge, no publicly available classification dataset for high-resolution imaging radars has yet appeared. We collected dynamic and static road participants, including persons, cyclists, motorcyclists, cars and buses, and we manually annotated them. A total of 10,000 frames of data are available, with each object point containing spatial information, as well as Doppler velocity information and signal-to-noise ratio (SNR).
- We propose a new network architecture for imaging radar point-cloud classification based on transformer, which takes the five-dimensional information of radar point clouds as input. After the input embedding, the features are extracted by local hierarchical feature extraction and global feature extraction, with the two not being independent but exhibiting multilevel deep fusion. Combined with scalar attention and vector attention, deep features can be fully extracted.
- Experiments show that our proposed network can better represent the imaging radar point cloud than the mainstream point-cloud network and exhibits state-of-the-art (SOTA) performance in the object classification task.
2. Methodology
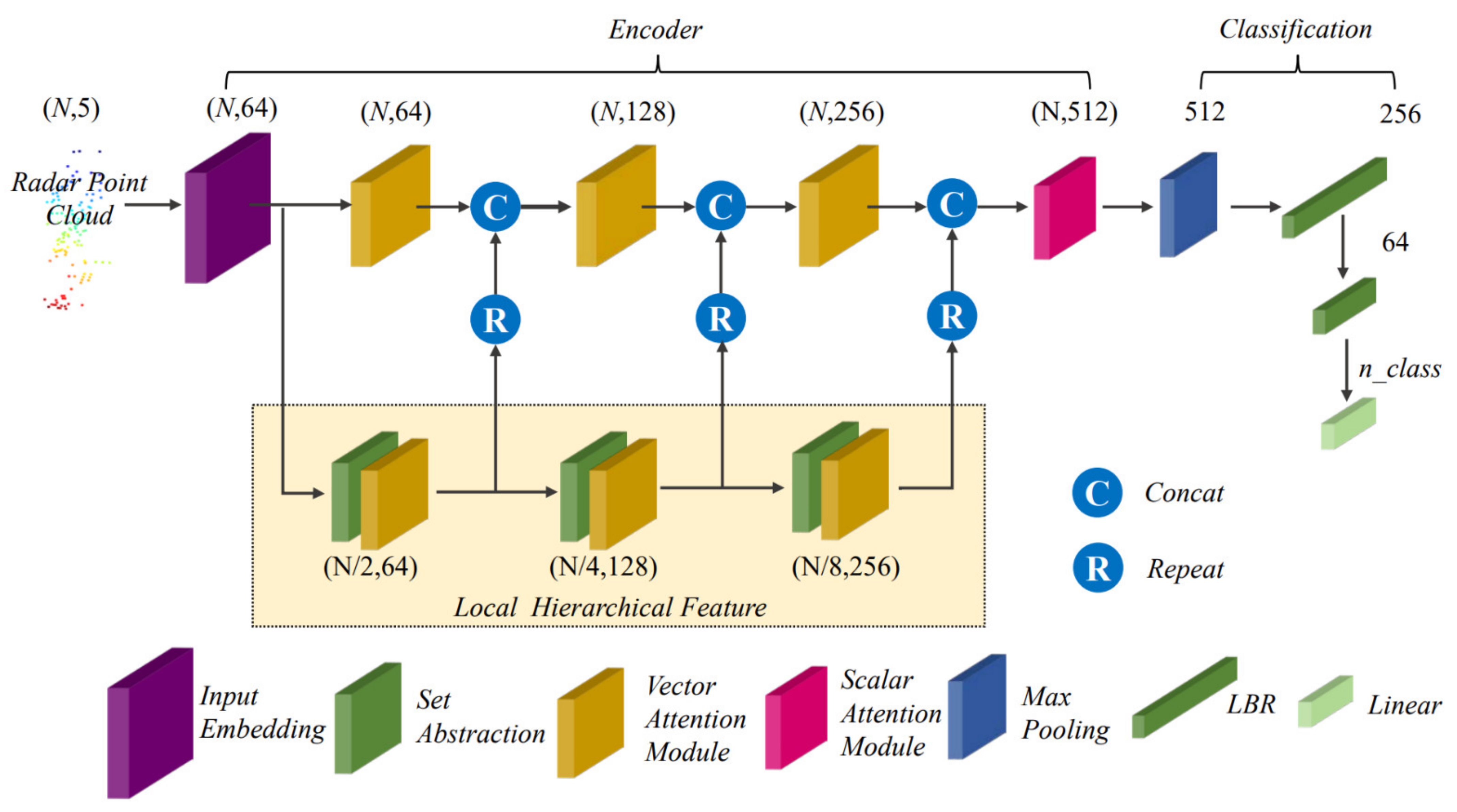
2.1. Network Architecture
2.2. Input Embedding
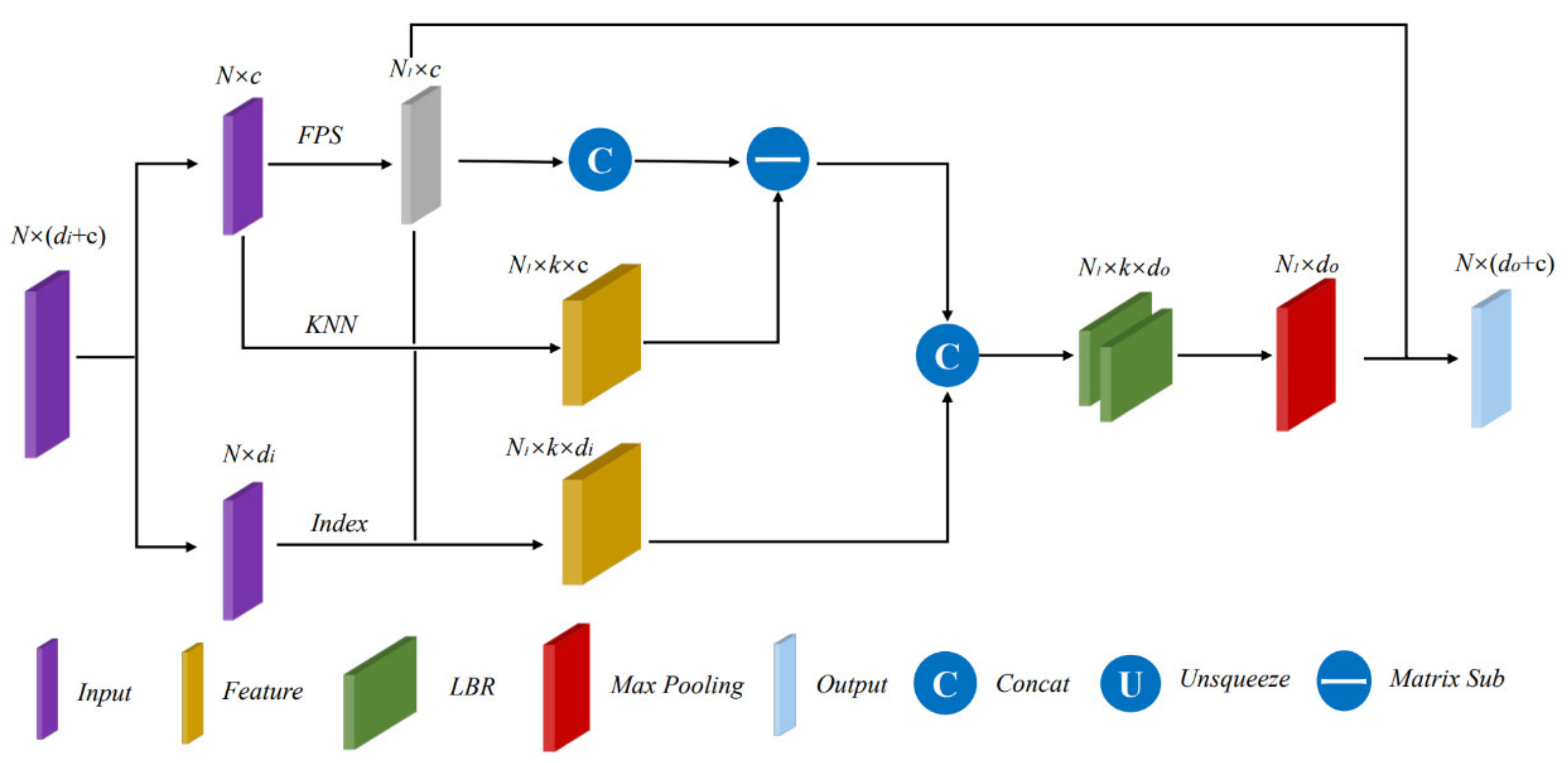
2.3. Set Abstraction
| Algorithm 1 Farthest Point Sampling (FPS) |
| Input:. Output: Sampled point set .
|
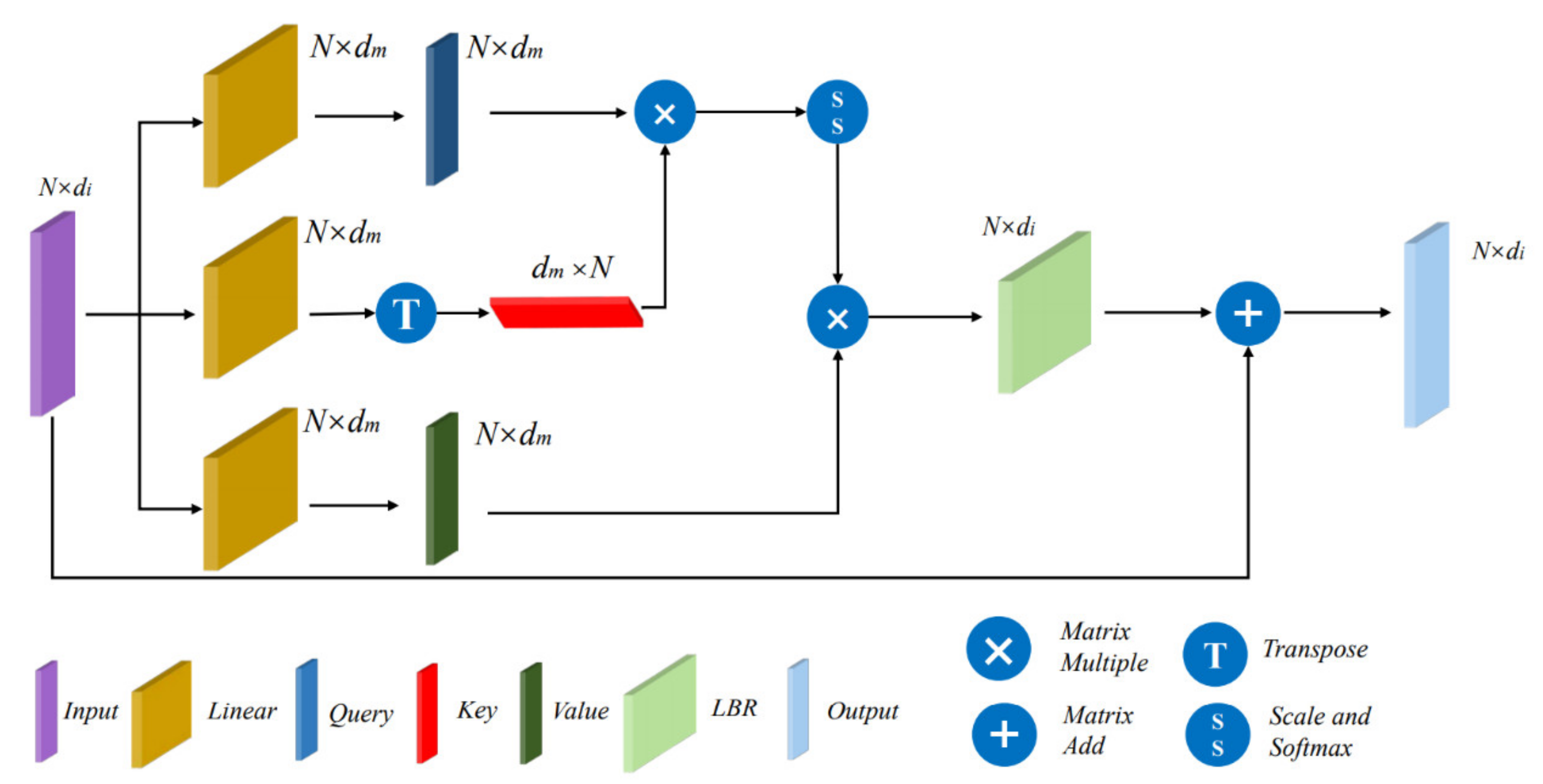
2.4. Scalar Attention Module
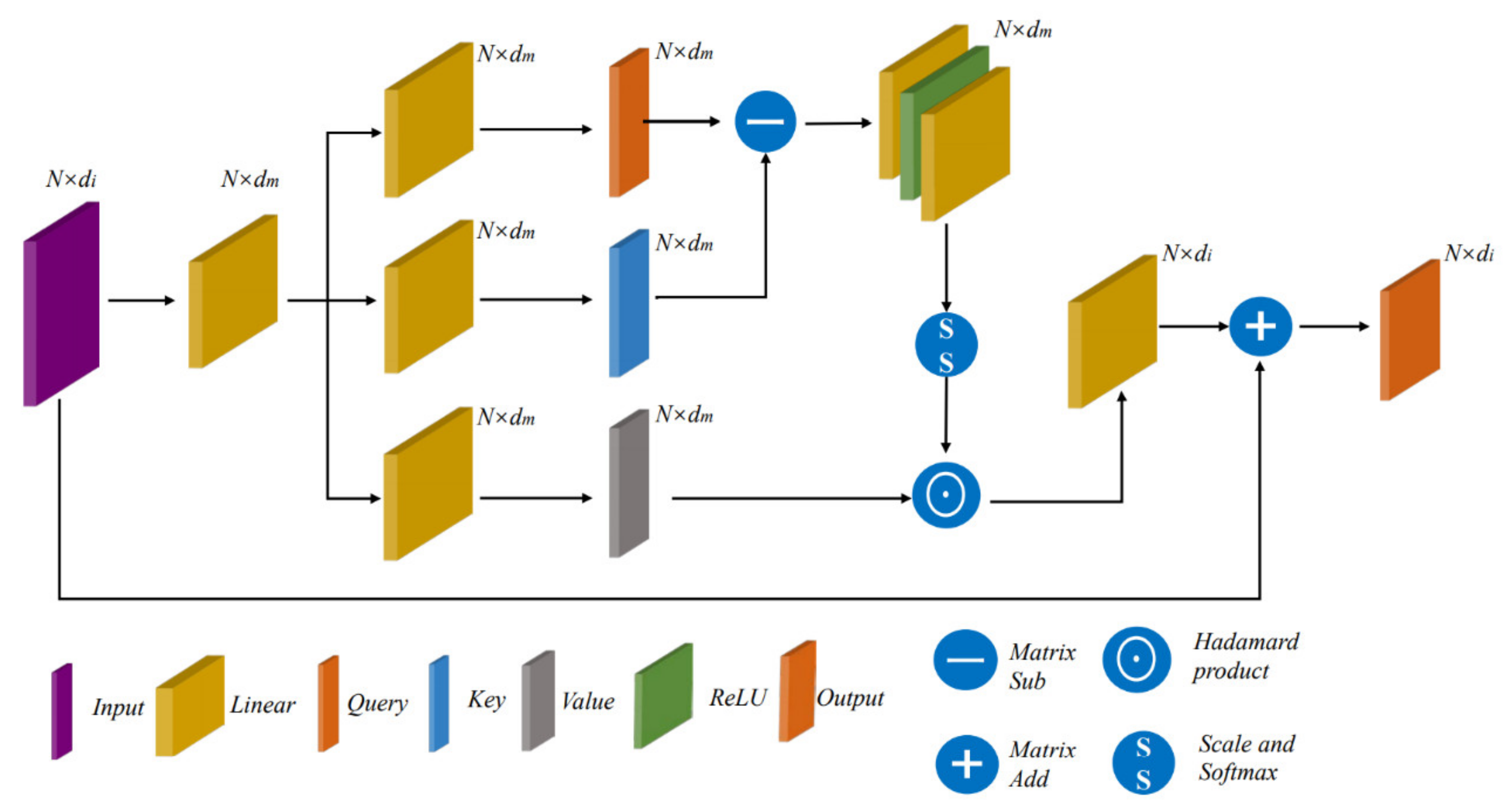
2.5. Vector Attention Module
3. Results
3.1. Dataset
3.1.1. Experimental Equipment
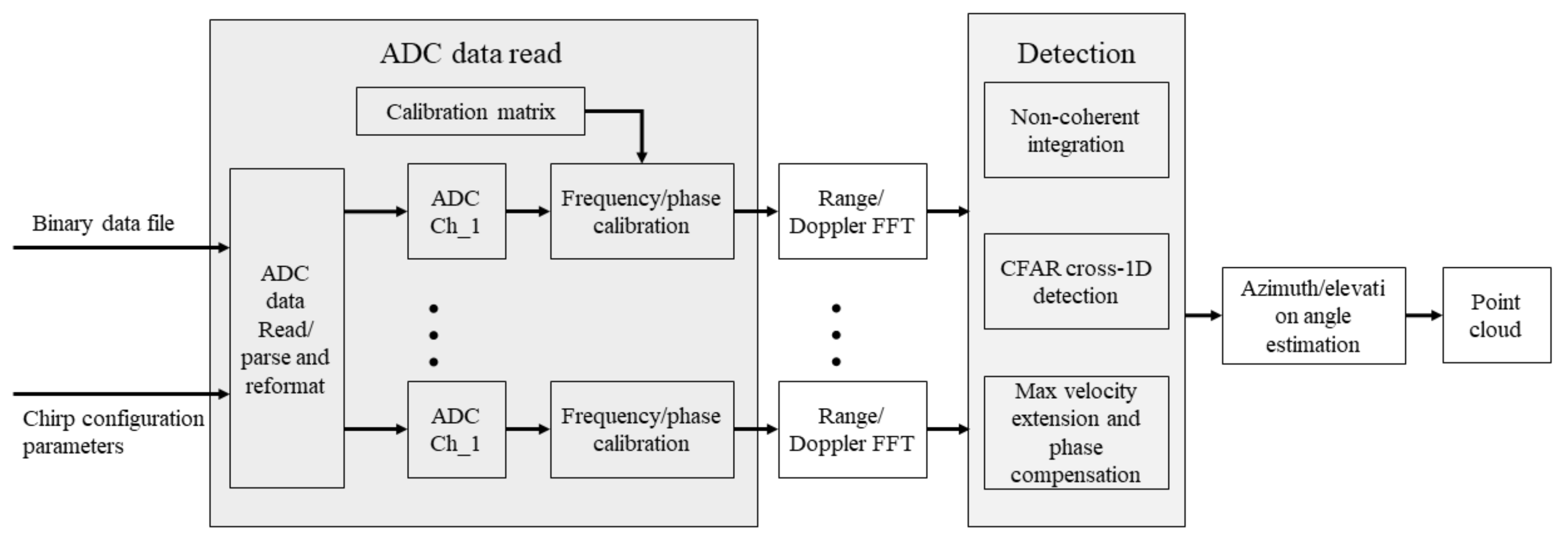
3.1.2. Radar Signal Processing
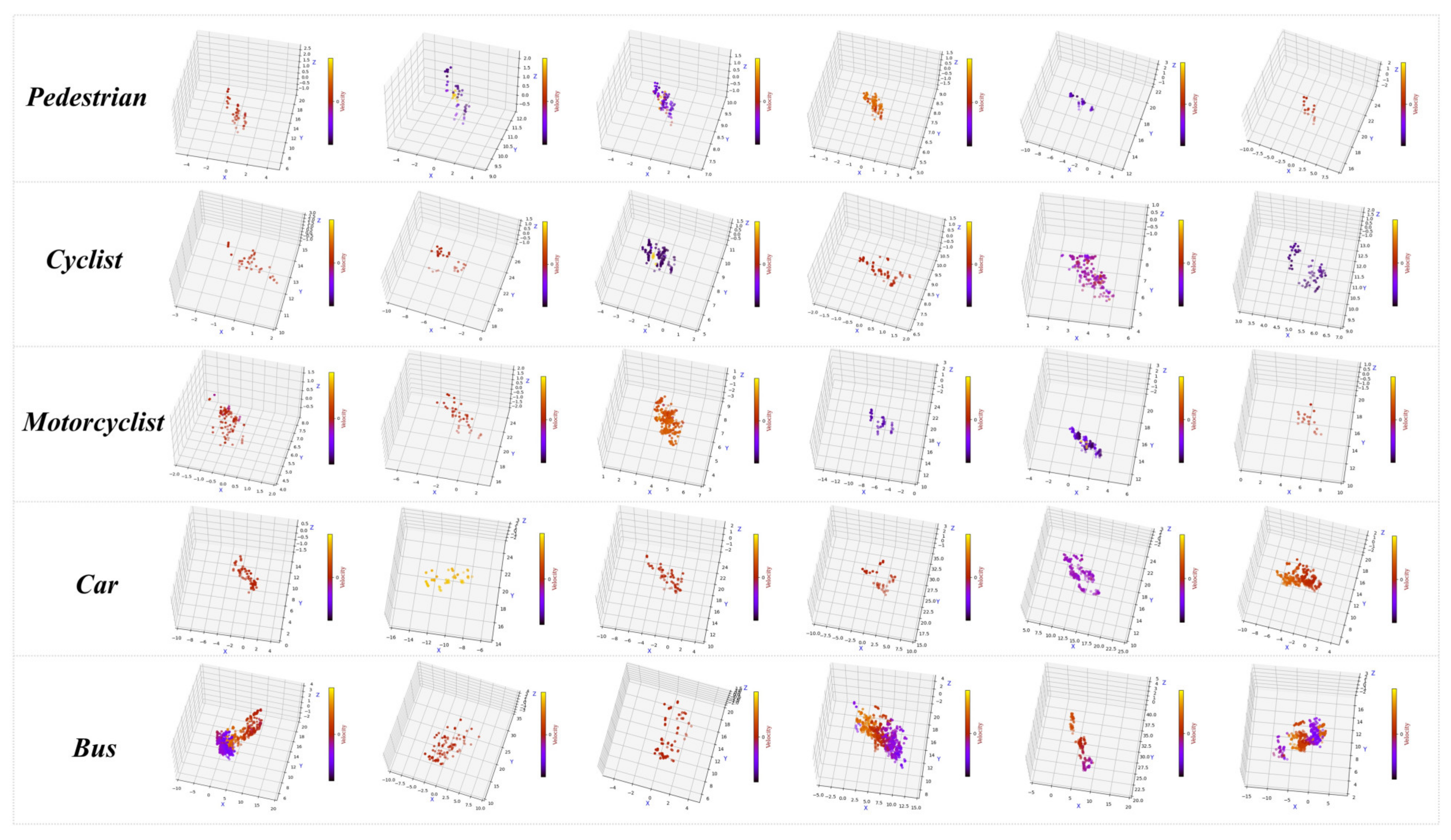
3.1.3. Data Acquisition and Production
3.2. Experimental Details
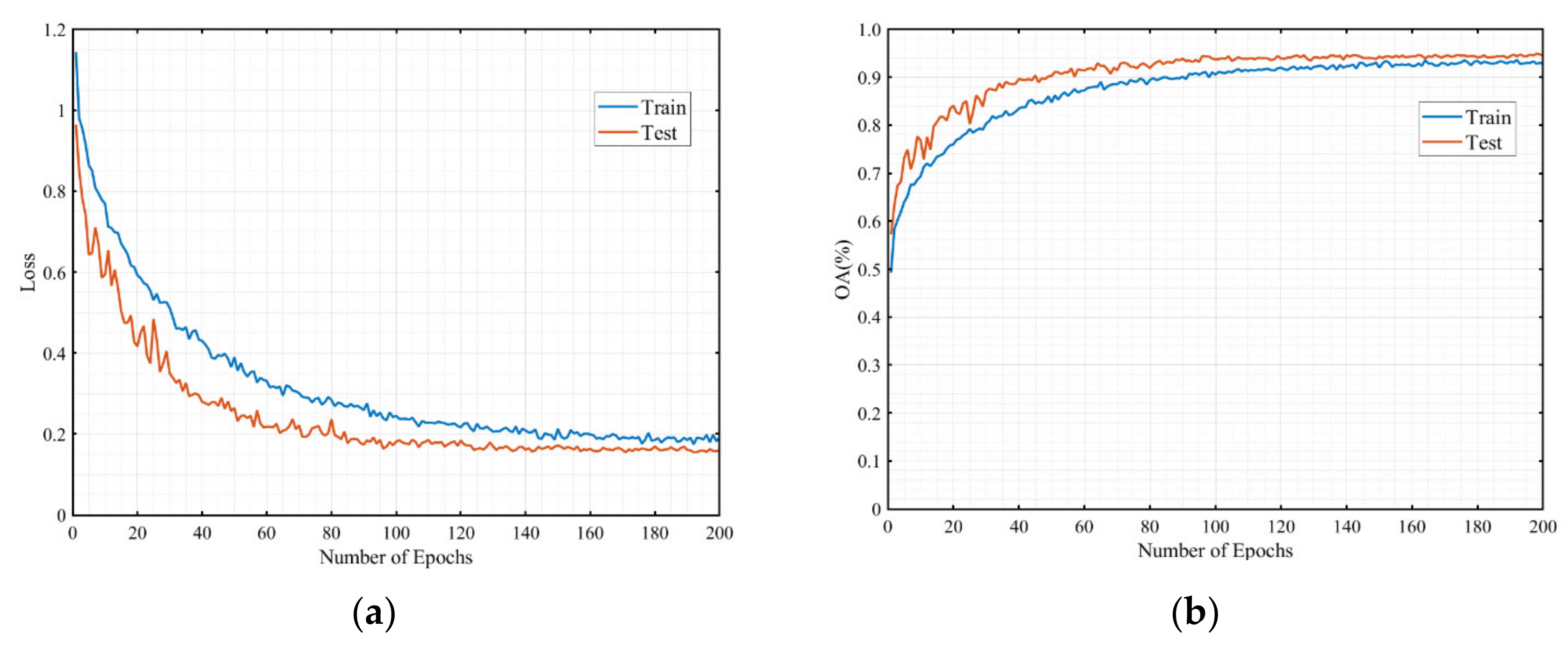
3.3. Evaluation Metrics
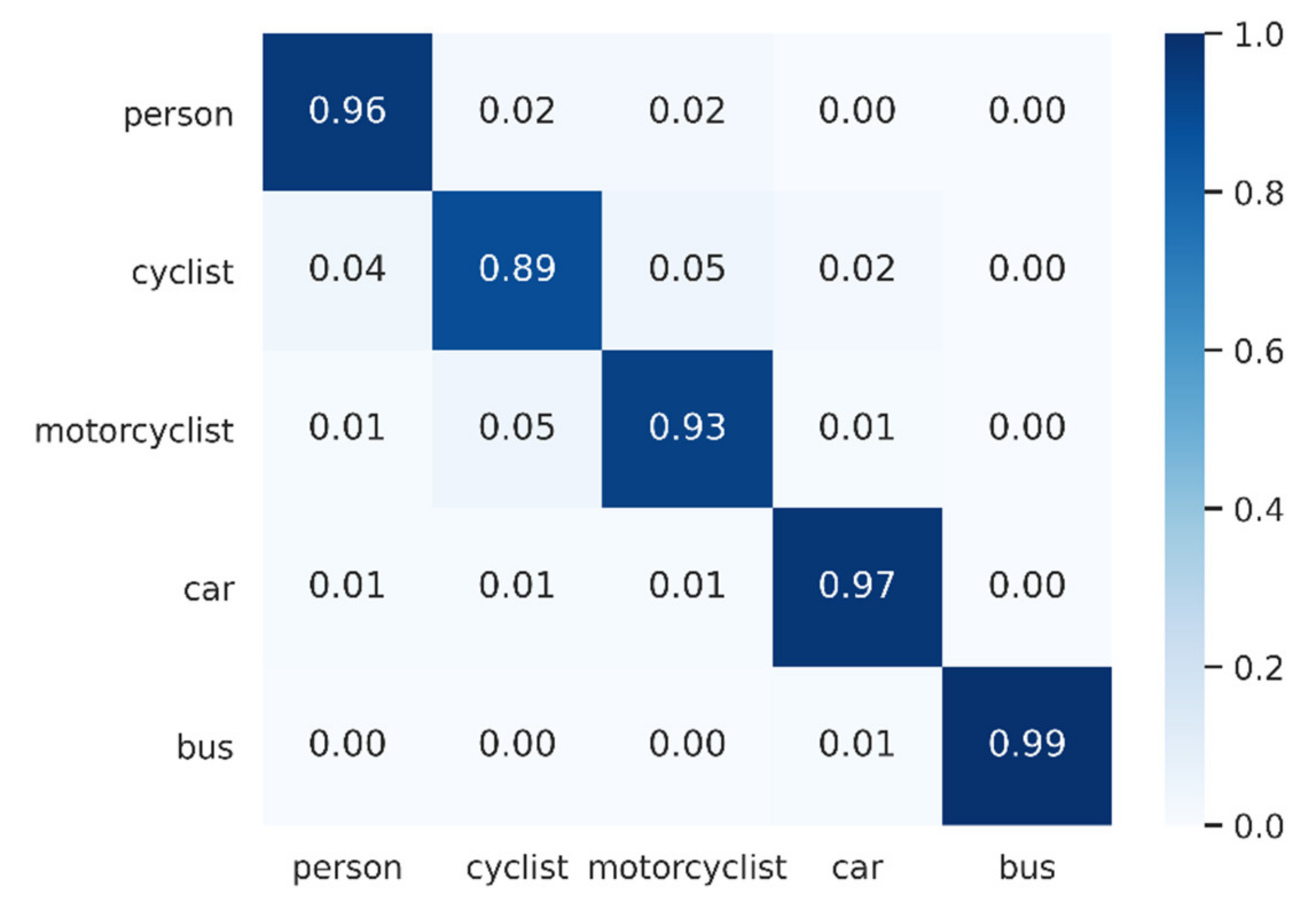
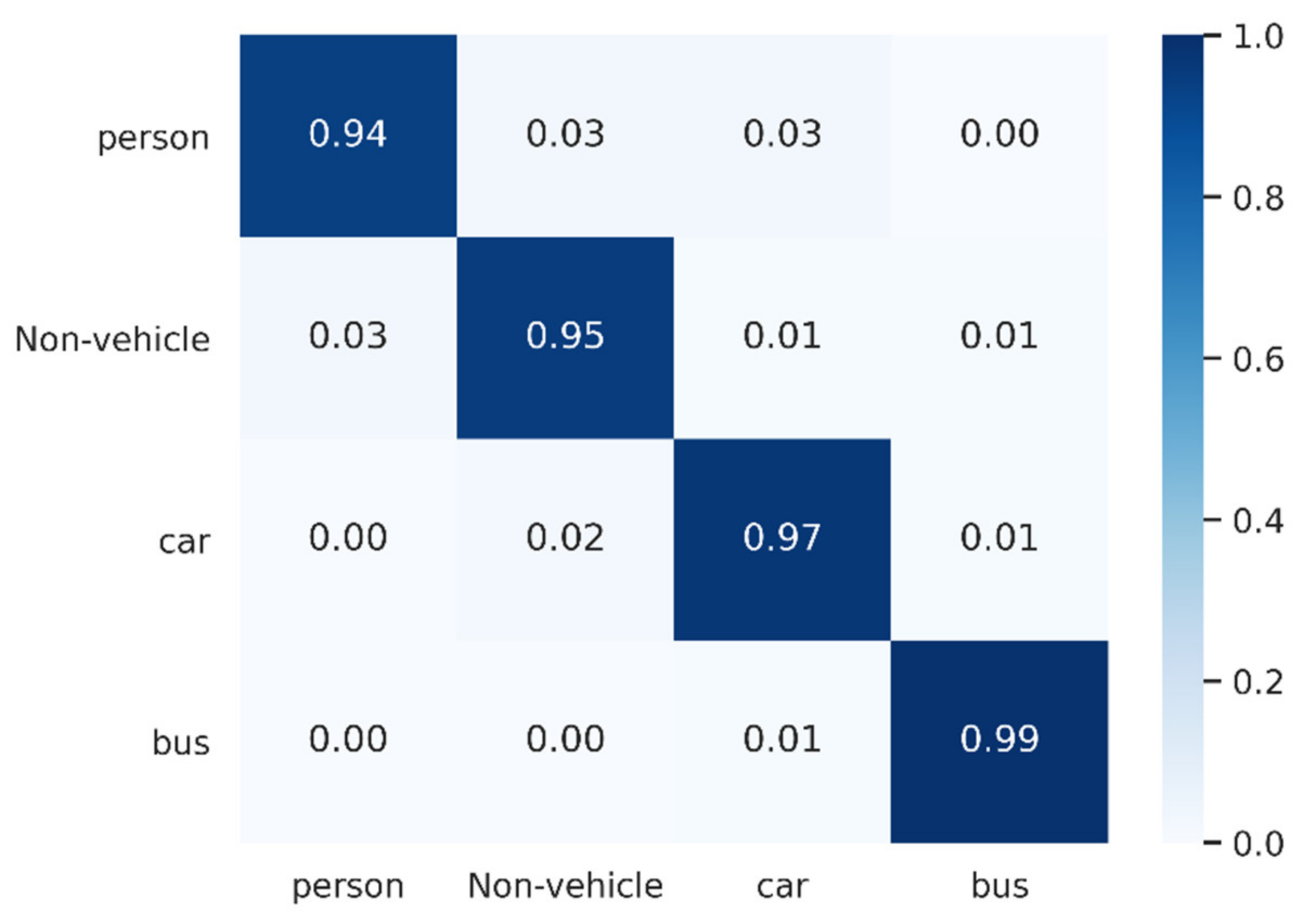
3.4. Experimental Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Agafonov, A.; Yumaganov, A. 3D Objects Detection in an Autonomous Car Driving Problem. In Proceedings of the 2020 International Conference on Information Technology and Nanotechnology (ITNT), Samara, Russia, 26–29 May 2020; pp. 1–5. [Google Scholar]
- Novickis, R.; Levinskis, A.; Kadikis, R.; Fescenko, V.; Ozols, K. Functional Architecture for Autonomous Driving and its Implementation. In Proceedings of the 2020 17th Biennial Baltic Electronics Conference (BEC), Tallinn, Estonia, 6–8 October 2020; pp. 1–6. [Google Scholar]
- Kocić, J.; Jovičić, N.; Drndarević, V. Sensors and Sensor Fusion in Autonomous Vehicles. In Proceedings of the 2018 26th Telecommunications Forum (TELFOR), Belgrade, Serbia, 20–21 November 2018; pp. 420–425. [Google Scholar]
- Lee, S.; Yoon, Y.-J.; Lee, J.-E.; Kim, S.-C. Human–vehicle classification using feature-based SVM in 77-GHz automotive FMCW radar. IET Radar Sonar Navig. 2017, 11, 1589–1596. [Google Scholar] [CrossRef]
- Brisken, S.; Ruf, F.; Höhne, F. Recent evolution of automotive imaging radar and its information content. IET Radar Sonar Navig. 2018, 12, 1078–1081. [Google Scholar] [CrossRef]
- Li, G.; Sit, Y.L.; Manchala, S.; Kettner, T.; Ossowska, A.; Krupinski, K.; Sturm, C.; Lubbert, U. Novel 4D 79 GHz Radar Concept for Object Detection and Active Safety Applications. In Proceedings of the 2019 12th German Microwave Conference (GeMiC), Stuttgart, Germany, 25–27 March 2019; pp. 87–90. [Google Scholar]
- Stolz, M.; Wolf, M.; Meinl, F.; Kunert, M.; Menzel, W. A New Antenna Array and Signal Processing Concept for an Automotive 4D Radar. In Proceedings of the 2018 15th European Radar Conference (EuRAD), Madrid, Spain, 26–28 September 2018; pp. 63–66. [Google Scholar]
- Jin, F.; Sengupta, A.; Cao, S.; Wu, Y. MmWave Radar Point Cloud Segmentation using GMM in Multimodal Traffic Monitoring. In Proceedings of the 2020 IEEE International Radar Conference (RADAR), Washington, DC, USA, 28–30 April 2020; pp. 732–737. [Google Scholar]
- Alujaim, I.; Park, I.; Kim, Y. Human Motion Detection Using Planar Array FMCW Radar Through 3D Point Clouds. In Proceedings of the 2020 14th European Conference on Antennas and Propagation (EuCAP), Copenhagen, Denmark, 15–20 March 2020; pp. 1–3. [Google Scholar]
- Meyer, M.; Kuschk, G. Automotive Radar Dataset for Deep Learning Based 3D Object Detection. In Proceedings of the 2019 16th European Radar Conference (EuRAD), Paris, France, 2–4 October 2019; pp. 129–132. [Google Scholar]
- Minar, M.R.; Naher, J. Recent Advances in Deep Learning: An Overview. arXiv 2018, arXiv:1807.08169. [Google Scholar]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Dai, A.; Nießner, M. 3DMV: Joint 3D-Multi-view Prediction for 3D Semantic Scene Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Cham, Switzerland, 8–14 September 2018; pp. 458–474. [Google Scholar]
- Kanezaki, A.; Matsushita, Y.; Nishida, Y. RotationNet: Joint Object Categorization and Pose Estimation Using Multiviews from Unsupervised Viewpoints. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5010–5019. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A deep representation for volumetric shapes. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Riegler, G.; Ulusoy, A.O.; Geiger, A. OctNet: Learning Deep 3D Representations at High Resolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6620–6629. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graph. 2019, 38, 146. [Google Scholar] [CrossRef]
- Simonovsky, M.; Komodakis, N. Dynamic Edge-Conditioned Filters in Convolutional Neural Networks on Graphs. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 29–38. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Klokov, R.; Lempitsky, V. Escape from Cells: Deep Kd-Networks for the Recognition of 3D Point Cloud Models. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 863–872. [Google Scholar]
- Wu, W.; Qi, Z.; Fuxin, L. PointConv: Deep Convolutional Networks on 3D Point Clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9613–9622. [Google Scholar]
- Yi, L.; Kim, V.G.; Ceylan, D.; Shen, I.-C.; Yan, M.; Su, H.; Lu, C.; Huang, Q.; Sheffer, A.; Guibas, L. A scalable active framework for region annotation in 3D shape collections. ACM Trans. Graph. 2016, 35, 210. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA; 2017; pp. 6000–6010. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R. Transformer-XL: Attentive Language Models beyond a Fixed-Length Context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2978–2988. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2019, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wu, B.; Xu, C.; Dai, X.; Wan, A.; Zhang, P.; Yan, Z.; Tomizuka, M.; Gonzalez, J.; Keutzer, K.; Vajda, P. Visual Transformers: Token-based Image Representation and Processing for Computer Vision. arXiv 2020, arXiv:2006.03677. [Google Scholar]
- Guo, M.-H.; Cai, J.-X.; Liu, Z.-N.; Mu, T.-J.; Martin, R.R.; Hu, S.-M. PCT: Point cloud transformer. Comput. Vis. Media 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Zhao, H.; Jia, J.; Koltun, V. Exploring Self-Attention for Image Recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10073–10082. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D Object Detection Network for Autonomous Driving. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6526–6534. [Google Scholar]
- Church, K.W. Word2Vec. Nat. Lang. Eng. 2017, 23, 155–162. [Google Scholar] [CrossRef]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11618–11628. [Google Scholar]
- Wang, Y.; Jiang, Z.; Li, Y.; Hwang, J.N.; Xing, G.; Liu, H. RODNet: A Real-Time Radar Object Detection Network Cross-Supervised by Camera-Radar Fused Object 3D Localization. IEEE J. Sel. Top. Signal Process. 2021. [Google Scholar] [CrossRef]
- Barnes, D.; Gadd, M.; Murcutt, P.; Newman, P.; Posner, I. The Oxford Radar RobotCar Dataset: A Radar Extension to the Oxford RobotCar Dataset. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 6433–6438. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the NIPS Autodiff Workshop, Long Beach, CA, USA, 9 December 2017. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value (MIMO) |
|---|---|
| Maximum range | 150 m |
| Range resolution | 60 cm |
| Azimuth angle resolution | 1.4° |
| Elevation angle resolution | 18° |
| Maximum velocity | 133 kph |
| Velocity resolution | 0.53 kph |
| Antennas | 12 × TX, 16 × RX |
| Azimuth array | 86 element virtual array |
| Elevation array | 4 element virtual array |
| Method | OA | Person | Cyclist | Motorcyclist | Car | Bus |
|---|---|---|---|---|---|---|
| PointNet [12] | 87.0% | 91.5% | 69.0% | 80.6% | 93.3% | 97.8% |
| PointNet++ (SSG) [21] | 91.0% | 93.0% | 82.0% | 85.1% | 94.5% | 98.6% |
| PointNet++ (MSG) [21] | 93.3% | 94.8% | 86.1% | 90.1% | 95.8% | 99.5% |
| DGCNN [20] | 90.1% | 92.3% | 77.3% | 88.1% | 94.1% | 98.5% |
| PCT [31] | 86.4% | 87.3% | 76.1% | 79.5% | 90.6% | 98.5% |
| NPCT [31] | 87.5% | 88.5% | 80.3% | 79.0% | 91.5% | 98.1% |
| SPCT [31] | 93.0% | 95.1% | 83.6% | 90.8% | 96.1% | 99.1% |
| PointConv [23] | 89.8% | 93.3% | 80.1% | 81.1% | 95.6% | 98.8% |
| Radar Transformer | 94.9% | 96.4% | 89.1% | 93.0% | 96.8% | 99.4% |
| Scalar Attention Number | 0 | 1 | 2 | 3 |
| OA (%) | 91.5% | 94.9% | 91.0% | 60.0% |
| Method | Params (M) | Train_Time (s/epoch) | VRAM_Train (MB) | Infer_Time (ms) | VRAM_Infer (MB) |
|---|---|---|---|---|---|
| PointNet [12] | 3.46 | 9.71 | 693 | 3.71 | 623 |
| PointNet++ (SSG) [21] | 1.47 | 19.12 | 683 | 40.38 | 571 |
| PointNet++ (MSG) [21] | 1.74 | 22.24 | 927 | 45.13 | 679 |
| DGCNN [20] | 1.81 | 4.89 | 807 | 2.80 | 647 |
| PCT [31] | 2.88 | 15.12 | 789 | 20.98 | 657 |
| NPCT [31] | 1.36 | 7.32 | 611 | 3.74 | 577 |
| SPCT [31] | 1.36 | 7.50 | 613 | 3.82 | 578 |
| PointConv [23] | 19.56 | 33.22 | 1835 | 66.88 | 1119 |
| Radar Transformer | 2.28 | 20.94 | 689 | 19.87 | 620 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, J.; Zheng, L.; Li, S.; Tan, B.; Chen, S.; Huang, L. Radar Transformer: An Object Classification Network Based on 4D MMW Imaging Radar. Sensors 2021, 21, 3854. https://doi.org/10.3390/s21113854
Bai J, Zheng L, Li S, Tan B, Chen S, Huang L. Radar Transformer: An Object Classification Network Based on 4D MMW Imaging Radar. Sensors. 2021; 21(11):3854. https://doi.org/10.3390/s21113854
Chicago/Turabian StyleBai, Jie, Lianqing Zheng, Sen Li, Bin Tan, Sihan Chen, and Libo Huang. 2021. "Radar Transformer: An Object Classification Network Based on 4D MMW Imaging Radar" Sensors 21, no. 11: 3854. https://doi.org/10.3390/s21113854
APA StyleBai, J., Zheng, L., Li, S., Tan, B., Chen, S., & Huang, L. (2021). Radar Transformer: An Object Classification Network Based on 4D MMW Imaging Radar. Sensors, 21(11), 3854. https://doi.org/10.3390/s21113854