1. Introduction
Evaluating the status of a PV plant is an important task in maintaining a high output performance and low operating costs. Operation and maintenance (O & M) companies aim at detecting any failure in a PV system and taking suitable countermeasures. Considering the cost-effectiveness of the different techniques for failure identification (visual inspection, thermography, electroluminescence, etc.) an efficient procedure for a plant evaluation is to first check for any power loss recorded by the monitoring system, followed, if needed, by other on-site techniques for identifying the plant failure [
1]. Efficient and reliable methods, appropriate for online monitoring, should be used to detect any failure that causes power losses. A power loss in a PV plant can be correlated to the values of current, voltage, temperature, irradiance, thermal cycling, shading, and others [
2]. While shading is difficult to measure and quantify, the other parameters can be measured within the PV plant monitoring system. Failures in a PV plant can be located in the PV modules, inverters, cables and interconnectors, mounting, or other components. Typical failures [
1,
3] located in PV modules include cracks, potential induced degradation (PID), burned marks and hail damage of the cells, soiling or physical damage as failure of the front glass, delamination as failure of the encapsulant, and others. Because of the many different types of failures, identifying one type of failure in a PV system is a challenging task. Nowadays increasingly more research is being done on diagnosing a specific set of failures [
4,
5,
6,
7].
A PV performance analysis involves the estimation of the long-term degradation rates, that quantify the gradual reduction of performance of a PV system over time. In many cases the degradation rates are calculated based on a metric called the performance ratio (PR) [
8,
9,
10], which is the ratio of the measured and nominal power. Variants of the standard PR include a corrected PR that uses a corrected measured power to compensate for the differences in measured irradiance and module temperature, with respect to the Standard Test Conditions (STC). For example, a corrected PR is used in [
9,
11,
12]. PR can be calculated on a yearly, monthly, or daily basis, after which an analysis of the PR time-series is done to evaluate the degradation. When a linear degradation over time is assumed, methods based on linear regression models and seasonal decomposition have been mostly used [
13]. A simple linear regression model fits a linear model to the raw PR time-series [
10], or to the trend component extracted after seasonal decomposition [
8]. In another approach, the degradation ratio is extracted from the distribution of the year-on-year degradation calculated as the rate of change of the PR between the same days in two subsequent years [
9]. For cases of nonlinear degradation rates, change point analysis has been performed to detect the changes in the degradation slopes, after which linear degradation rates are calculated between every two consecutive points of change [
14].
Appropriate preprocessing and filtering of the dataset is needed to eliminate outliers, noise, and minimize seasonal oscillations [
11]. An investigation of the uncertainty of several different methods for degradation estimations shows that the simple linear regression performed on the PR time-series has higher uncertainty than the methods that use seasonal decomposition [
8,
11]. However, an important requirement for the seasonal decomposition methods is an accurate estimation of the model parameters [
11]. On the other hand, using a corrected PR requires a valid measurement of irradiance and module temperature, which in some cases are not available in a monitoring system. There is then the need of defining statistical approaches for degradation estimation that can either be used without the environmental sensor data, or that are not dependent on the accuracy of the seasonal decomposition models.
Besides gradual degradation, the performance of a PV plant can undergo sudden changes caused by localized failures in the system. A variety of statistical methods have been used for failure diagnostics, mostly involving machine learning (ML) regression models [
13,
15]. ML regression models have been used to monitor the operation of a PV system by estimating the expected output, being it either power, current, or voltage, and identifying as anomalies all instances where the measured output deviates from the predicted one. One approach to estimate the expected power output involves deriving the parameters of the standard nonlinear models of the relationship between current and voltage values, which are usually given by the PV module manufacturer, but are not always available [
16]. Other approaches predict an expected daily power output, taking as input a combination of environmental data and data specific to the PV plant [
17,
18]. For this purpose, ANN (Artificial Neural Network) [
18], SVM (Support vector machine) [
17] and Regression trees have been used as regression models. Some results show a great performance of the ML models, obtaining a high correlation of more than 0.99 between the measured and predicted power output [
18]. For a real-time optimum voltage and current prediction, recurrent ANN are investigated in [
4], showing high accuracy of more than 98.2% [
4]. An alternative approach of using data-driven models for power prediction is to use the one-diode model [
19,
20]. A comparison between the performance of the one-diode model and a recursive linear regression model showed a better performance in the regression model [
6]. Once a regression model is derived, this can be used by failure detection algorithms. In some studies [
16,
20], to perform the fault detection, both the measured and predicted outputs are used. In one case, upper and lower boundaries of the loss in power are set up in advance based on which a fault is detected [
20]. In another study, a weighted moving average control chart of the power residuals is used [
16]. However, all these methods for output regression and fault detection have been so far tested only on one PV plant. For this reason, finding an approach for robust anomaly detection that can be used on several PV systems is still a great challenge as different systems may present different features.
The purpose of this work is to develop models for the assessment of the condition of a PV plant by monitoring the variation of its output. Two different sources for a decrease in performance are considered, i.e., progressive degradation and sudden anomalies. For each of these scenarios, multiple approaches for the plant’s assessment are considered and compared. For the detection of progressive degradation, we propose novel methods for degradation estimation that overcome some of the issues of the existing methods. More precisely, one of the methods does not rely on any environmental sensor data, and therefore it can be used in scenarios where these data are not available. The other method targets to find a reliable degradation evaluation without the use of any seasonal decomposition models, thereby avoiding the problem of an accurate estimation of the model parameters. For anomaly detection, instead, the developed approaches are based on regression models that predict the expected output for each inverter of the PV plant. We propose novel approaches to detect the anomalies by using the produced output. Compared to other approaches, our approach uses some of the measured data as training data. All the approaches considered in this work rely on statistical machine learning techniques and are therefore designed to be derived only from the available data without the need for an in-depth inspection of the plant. The proposed approaches are then validated on the data extracted from three different PV plants located in Europe, ranging from 4 to 19 inverters per plant, and each monitored for 5–6 years.
More in detail,
Section 2.1 and
Section 2.2 present the approaches developed for the estimation of the plant’s degradation and for the identification of anomalies, respectively.
Section 3.1 and
Section 3.2 discuss the applications of these methods to the selected PV plants, comparing the results. Finally,
Section 4 draws the conclusions.
3. Results
For our investigation we have made use of data coming from three plants. A crystalline silicon technology is used in all plants. For anonymity reasons, we will call them plants A, B, C, and they have the following characteristics:
plant A, location Slovenia: data acquired between September 2013 and April 2020, however with some long interruptions due to lack of data from some sensors, 19 inverters have been considered. In this plant, global irradiation, and ambient and module temperatures are measured. The irradiation sensor is based on a thin film solar cell, whereas the module temperature sensor is a Pt100. The installed capacity of the plant is approximately 315 kWp and contains 1313 pieces of 240 Wp modules composed of multicrystalline silicon (multi-c-Si) cells. Regarding the placement of the modules, there are two different orientations: southwest (200°) and southeast (135°). More precisely, there are 12 inverters with southwest orientation, 6 have southeast orientation, while one inverter has modules connected to both orientations. Moreover, the irradiation sensor shares the same southwest orientation of the first 12 inverters.
plant B, location Sardinia, Italy: data acquired between April 2014 and April 2019, 4 inverters have been considered. Around 4/5 of the modules are west-oriented and the others have southwest orientation. This plant has crystalline silicon (c-Si) cells. The measurement sensors consist of an irradiation and ambient temperature sensor. The irradiation sensor is based on a silicon solar cell, while the module temperature is not measured.
plant C, location Italy: data acquired between January 2011 and April 2020, 5 inverters have been considered. Each inverter is connected to three strings, each with 16 PV modules. All inverters have modules with the south orientation. In this plant, irradiation, ambient and module temperatures are measured. The plant is composed of crystalline silicon technology modules. No specifications of the sensor technology is available.
The investigated plants have very different sensor infrastructures and do not always have detailed information about the sensors available. For these reasons, the focus of this paper is not on the condition of the sensors, which we investigated in [
31], but rather on the methods for deriving reliable prediction models using a variety of possibly unknown sensors. It can also be observed that, in plant A, the modules and the irradiance sensor come from different technologies. According to the work in [
32], using amorphous silicon irradiance sensors, which are a much cheaper technology, in a c-Si plant is not optimal, but this should result only in a fixed offset. However, as the prediction models presented in this work learn the relationship between the irradiance values and DC plant values from the measured data, such an offset is automatically compensated.
Moreover, for some of the plants the status of the investigated strings has been assessed with an on-site inspection. For plant A the inspection using thermal imaging showed inactive parts in the PV modules, that explains the higher degradation in voltage which will be shown in
Section 3.1. For plant B, no on-site inspection could be performed. Finally, for plant C, the on-site inspection using thermal imaging and IV-curve measurements showed only a slight PID behavior, but an overall good operation of the plant with no suspicious behaviors, consistently with the results in
Section 3.1.
3.1. Degradation Estimation
A well-operating PV plant using the crystalline silicon technology has an estimated power degradation due to aging of 0.5–0.6% per year [
33]. The estimated degradation of the inspected plants, using the proposed approaches, are presented next. These results are also compared to a popular method where the degradation is calculated based on a linear standard least square regression applied to the temperature corrected PR [
10]. The data are first filtered using appropriate irradiance, outlier and stability filters as suggested in [
10,
12]. The reference PR-based degradation rate is calculated only for plants A and C, for which the module temperature and the coefficients needed to calculate the PR are known. Because of the high difference in these datasets, the applied outlier filter was customised for both datasets.
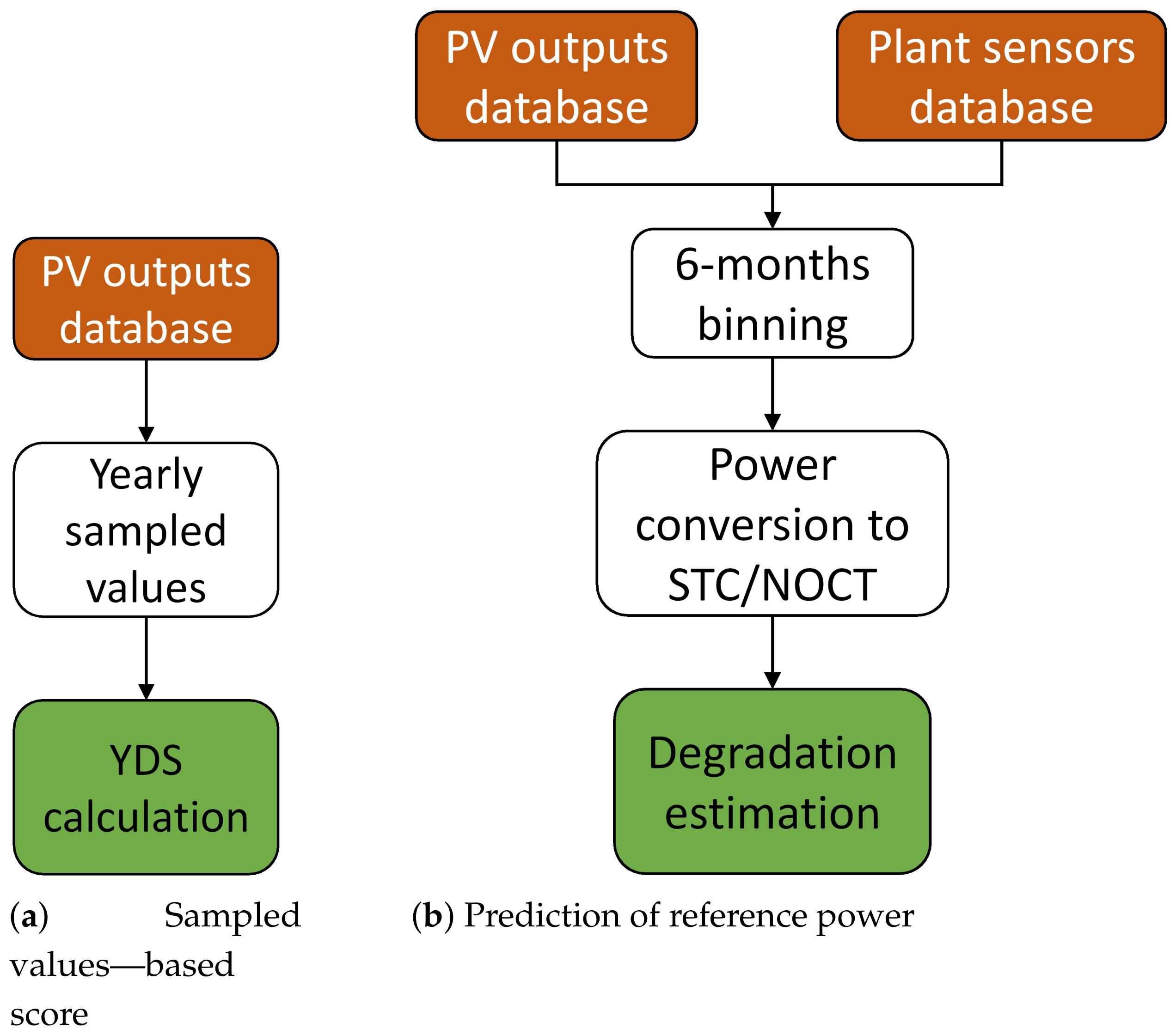
3.1.1. Sampled Values—Based Score
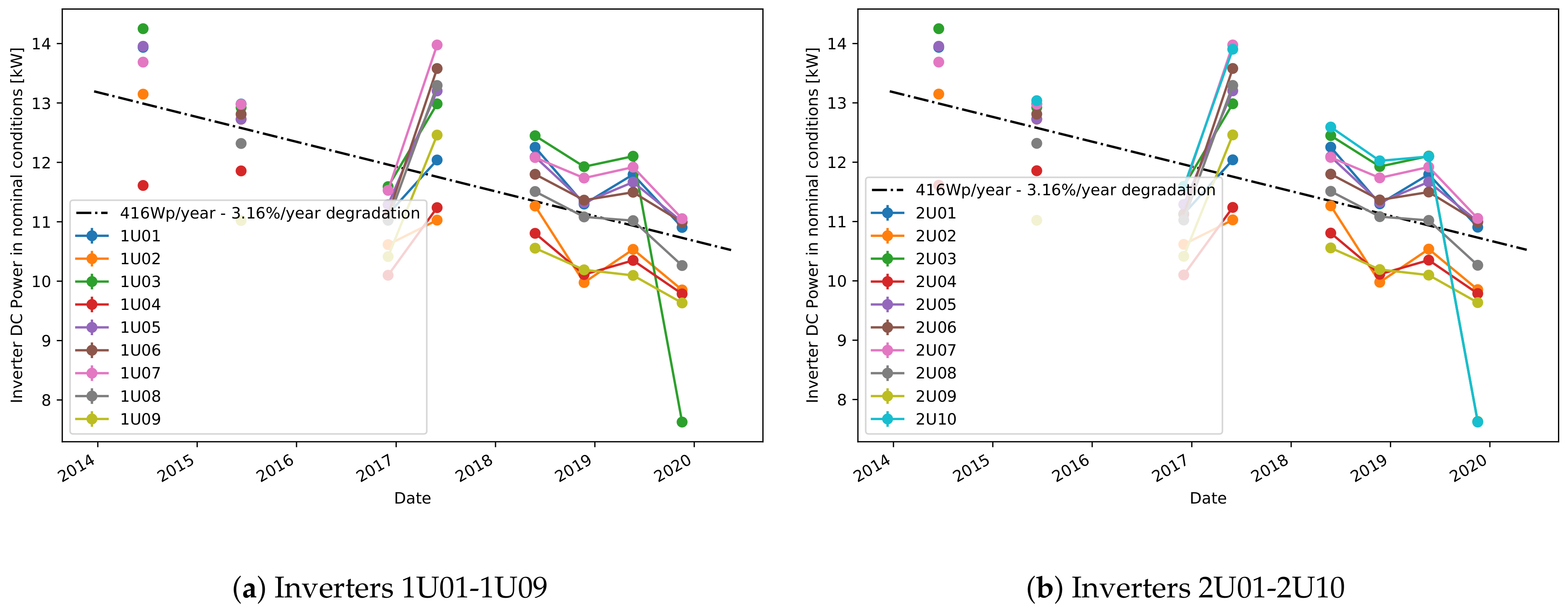
The estimation of the plant’s degradation using the sampled values-based method on the DC power is performed for all plants,
Figure 3 and
Table 1 and
Table 2. For each inverter, the sampled values taken for each year are shown in the plots, together with a linear fit showing the degradation. In
Figure 3c, the relative values in percentage are given for better clarity since the range of power values for inverters 97 and 98 is about 5 times higher than the one of the other inverters. For the other plots in
Figure 3, the absolute values expressed in Watts are given. The yearly degradation of the DC power for all inverters in plant C is on average 50 W per year, or 0.5% per year. Plants A and B have higher degradation. More precisely, on average there is a yearly degradation of 1.9% for plant B and 2.5% for plant A.
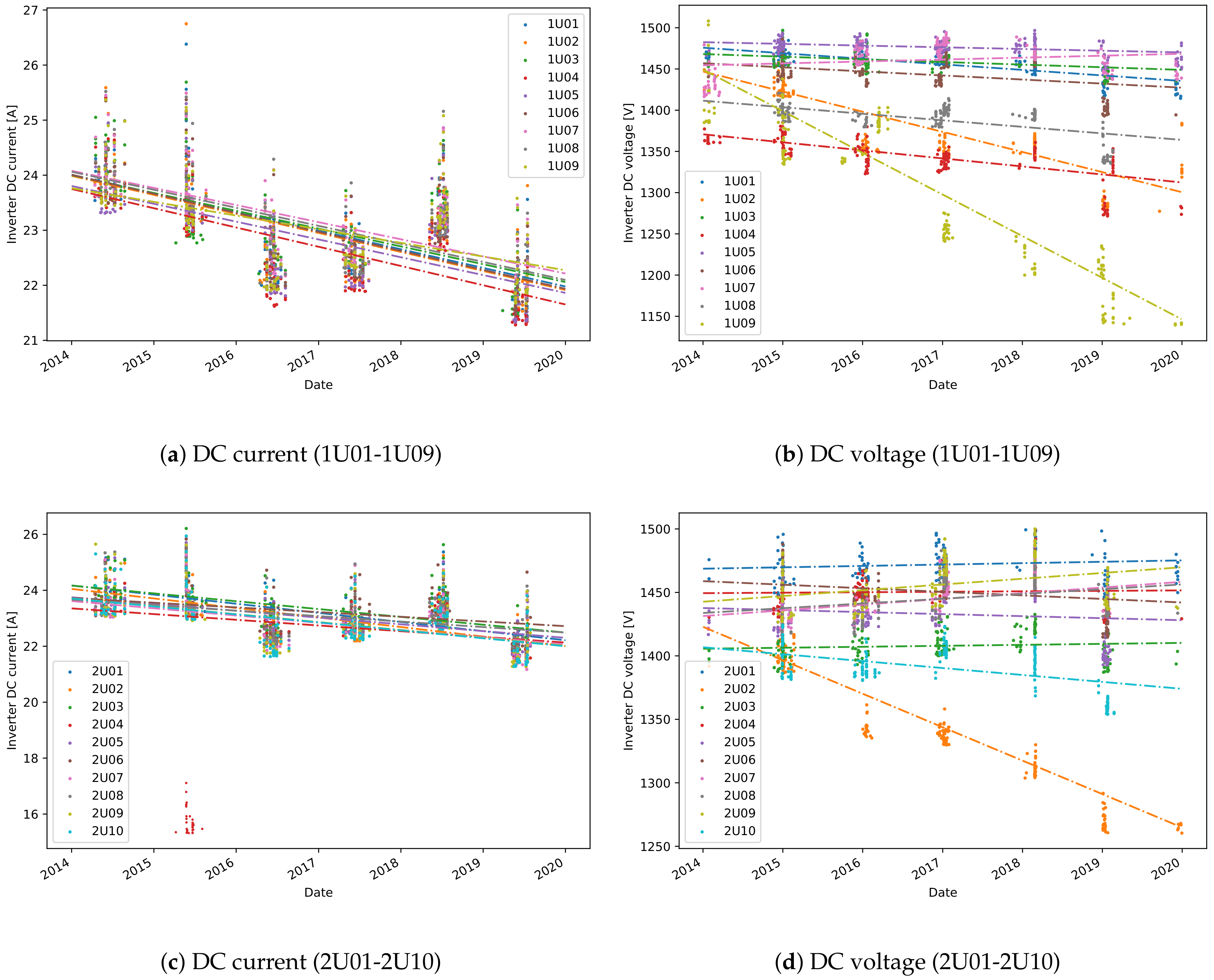
By comparing the degradation rates per inverter in one plant, interesting results can be observed. First, inverter 99 (
Figure 3c) has a higher degradation in power than the other inverters. Next, there is an unusual drop in the sampled values in 2016 shown in
Figure 3d, that has no significant effect on the linear degradation fit. Finally, there is a higher degradation in power for some of the inverters in plant A, such as 1U02, 1U04, 1U09, and 2U02 (
Figure 3a,b). A significant drop in DC power is seen for the inverter 2U04 in 2015, where the selected points deviate highly from all others. Including these sampled points in the degradation analysis affects highly the YDS. Hence, for better accuracy, these selected points are omitted from the degradation analysis.
One valuable feature of the sampled value-based approach is that the degradation in DC current and DC voltage can also be obtained. Consequently, the power degradation can be correlated to the degradation in DC current or DC voltage. One can observe that the higher degradation in power for some of the inverters in plant A, is related to a higher degradation in voltage (
Figure 4). A detailed comparison of the degradation rates, expressed in percentage, is shown in
Table 3. Although, theoretically a loss in voltage is not expected, for several inverters, like 1U02, 1U09 and 2U02, there is loss in voltage of above 1% per year. The average percentage of degradation in DC current for all inverters is 1.2%, but there is no significant difference between the degradation of different inverters. One explanation of such uniform degradation between the inverters is that it is a result of accelerated aging or soiling.
Similar analyses on the other datasets bring additional observations. First, the degradation in power for inverter 99 in plant B, is related to a loss in current. Next, the slight power degradation in a few of the inverters in plant C can be correlated to a higher degradation in DC voltage (
Figure 3d,
Table 2). Lower selected values for DC voltage of approximately 460 V is seen in the period 2015-2017, compared to 2011 when the values are approximately 480 V. The obtained degradation rates are in high correlation with the referenced degradation method based on PR (
Table 2). The advantage of using the sampling method is that it does not depend on either the temperature coefficient for the power or the nominal power used for a reliable PR calculation. During the on-site inspection of this system, it was found that a slight PID effect is distributed across the system, which has different effects on the various inverters.
3.1.2. Prediction of Reference Power
The second approach for estimating the plant’s degradation (
Section 2.1.2) has been applied instead only on plants A and C, due to the lack of the measured module temperature in plant B.
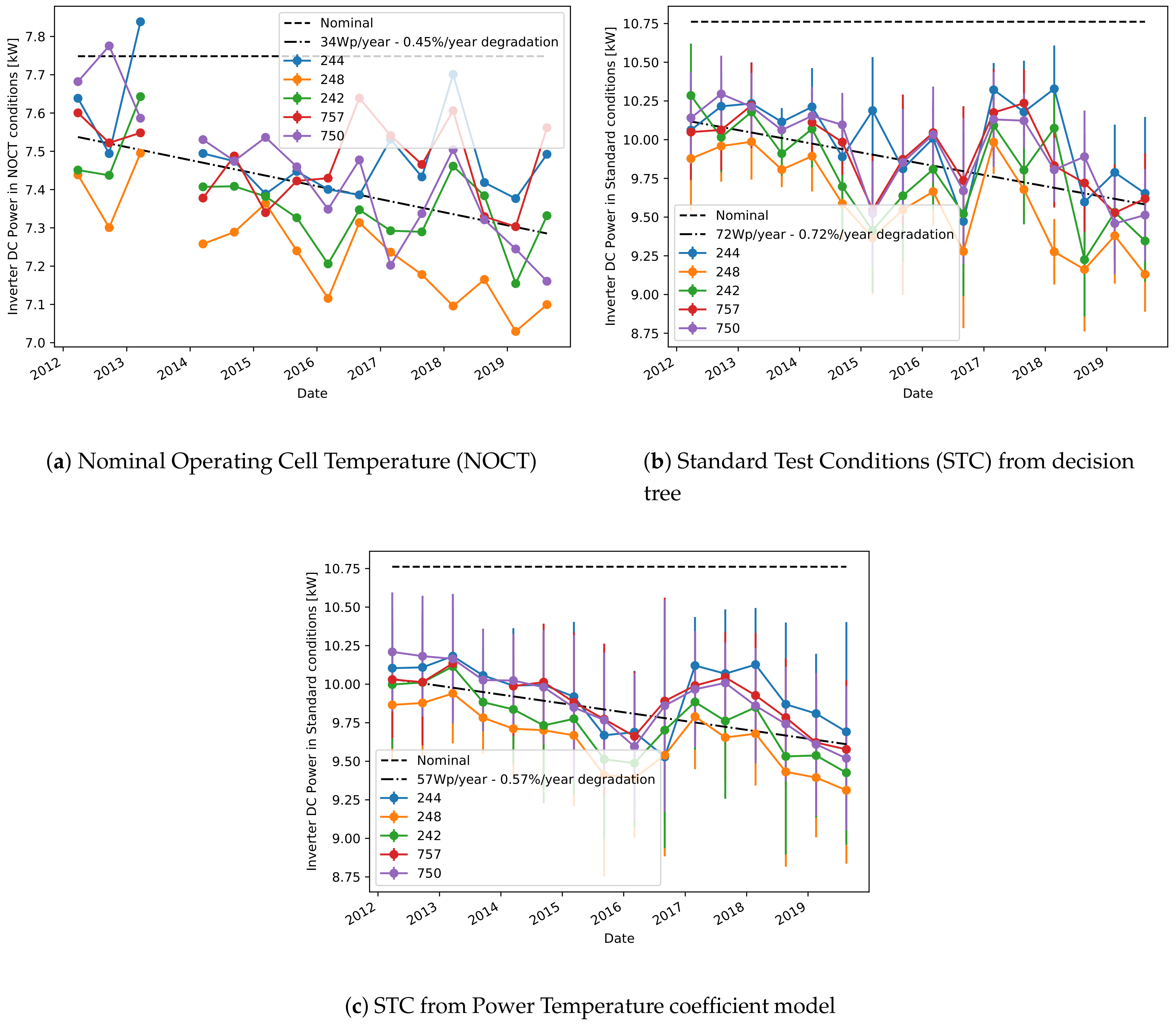
Figure 5 shows the predicted power in STC or NOCT conditions for each of the considered inverters in plant C. All curves are collectively fitted with a linear model, to have an estimate of the overall decreasing trend. Moreover, the dashed horizontal line shows the nominal power as communicated by the modules manufacturer. The vertical lines at each point estimate the uncertainty of the power estimates, and this is always much higher in STC because of the lack of one prediction input (the ambient temperature) and the lower amount of data available for training the models. Additionally,
Figure 5c shows the prediction of the STC power obtained using the standard Power Temperature coefficient model [
34] for the dependency of current and voltage with irradiance and temperature, which makes use of the coefficients communicated by the modules manufacturer. Also in this case, the results are in accordance with the previous estimates of power and degradation based on the decision tree model, therefore validating our approach. However, the uncertainty indicated by the error bars is even higher in
Figure 5b than the one in
Figure 5c, therefore showing how the Power Temperature coefficient model can provide good prediction results only on average, but it is not suitable for precise point-wise estimations.
For a more precise estimation of the degradation,
Table 2 shows the linear fit for the degradation obtained separately for each inverter and each operating conditions. As already observed, usually the estimates obtained in STC and NOCT conditions are rather different between each other. However, as the power estimation for NOCT is more reliable (as seen by the smaller uncertainty), we believe that these should be the conditions to be preferred, and we will just consider this case in the remaining of this work. Note also that the degradation estimation obtained from NOCT conditions is in good agreement with the one obtained using the sampled values model.
Moving then to plant A,
Figure 6 shows the predicted NOCT powers for all considered inverters, together with their collective linear fit. Unfortunately, as immediately evident, the missing data prevents from obtaining continuous curves, however the plant’s operational time is still well covered. It can also be observed that the yearly degradation of this plant is much higher than in the previous case.
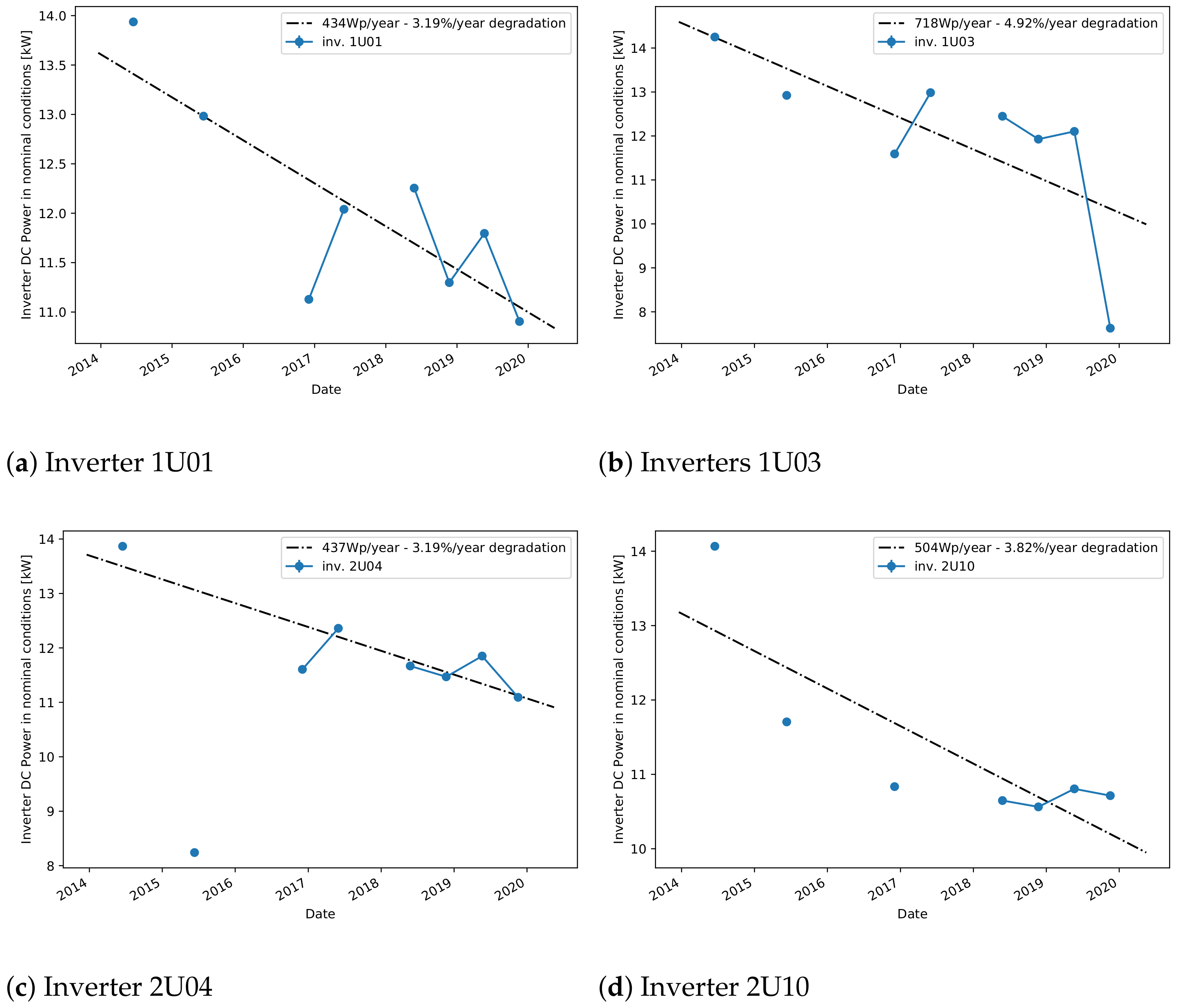
A more detailed comparison is shown in
Figure 7 where only four inverters are considered and individually fitted for linear degradation. The linear model is fitting the data very well, therefore reassuring about the validity of the proposed approach. The calculated yearly degradations are also relatively consistent between each other, showing that all these inverters are affected by the same phenomena. For a more detailed comparison,
Table 1 also shows the calculated degradation coefficients for all considered inverters of this plant. Note again the good agreement between this model and the one based on sampled values. Comparing the degradation scores with the reference score obtained from the PR-based method, one can observe that the degradation ranges are within a similar range of around 1.5% to 3% per year. This high degradation rate can be explained by problems in the plant that were discovered during an on-site inspection. More precisely, disconnected cell failure [
2] was found which was distributed throughout the system and affected all inverters, but each on a different scale. These findings were confirmed with thermal images. Although the PR method produces similar results, our methods are better adapted to typical data available for online monitoring where the information for the nominal power per inverter is normally absent or difficult to obtain. For instance, different inverters in plant A have different nominal powers that needs to be considered in the PR calculation, and this information might not be always available. Additionally, because the PR-based degradation rate was highly affected by the increasing trend present in the module temperature data from plant A, a recalculated module temperature obtained from the measured ambient temperature using a correction formula [
35] was used instead. On the other hand, our method is less affected by the problems in the module temperature data because the model learns to predict the reference power from data blocks of 6-month data where this increasing trend does not have a high impact, resulting therefore in a more robust model.
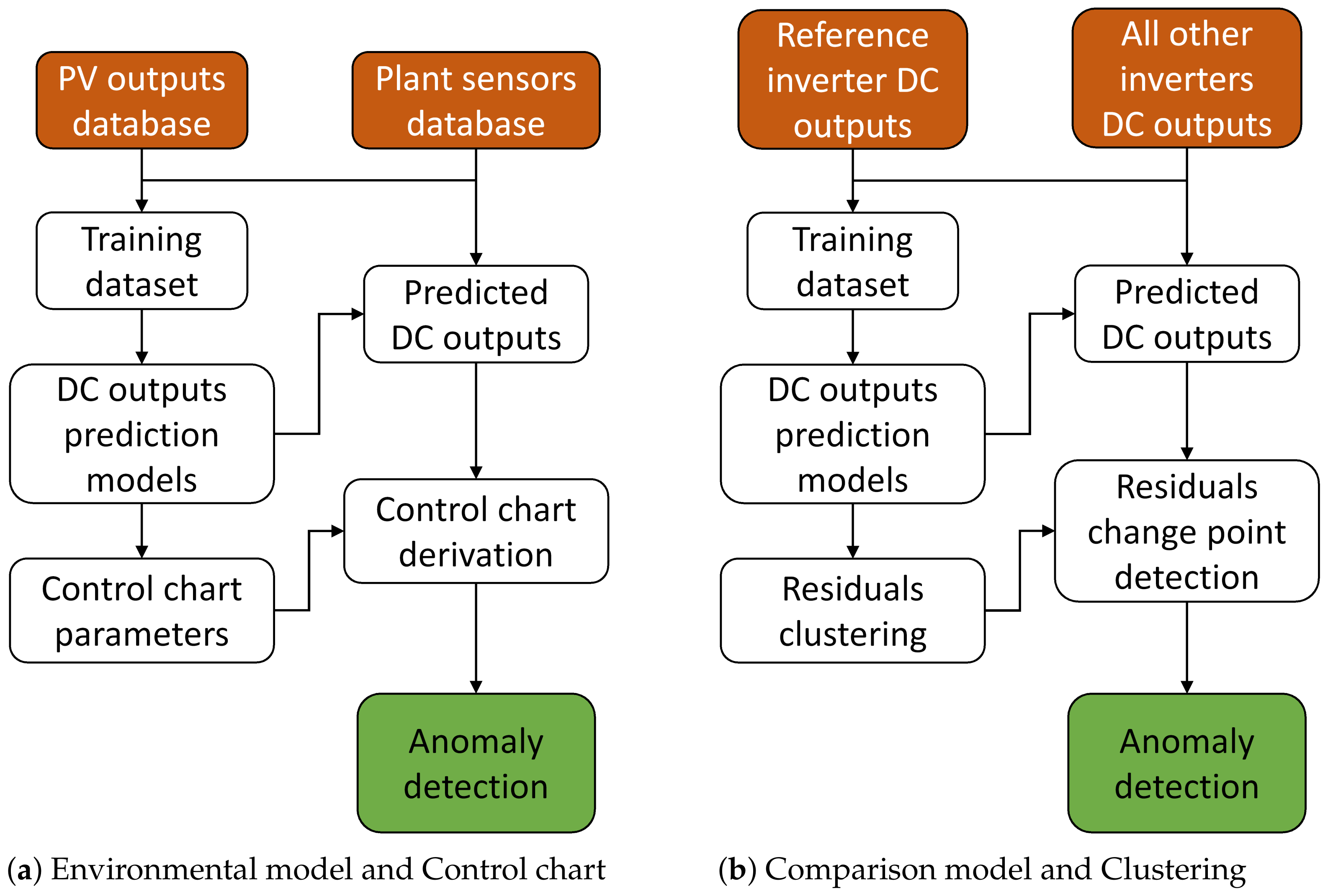
3.2. Anomaly Detection
As discussed in
Section 2.2, we have developed two approaches for anomaly detection, which both require as a first step the derivation of a regression model (
Section 3.2.1). The anomaly detection algorithms are then developed and compared between each other (
Section 3.2.2 and
Section 3.2.3).
3.2.1. Regression Models
Environmental Model
The first algorithm for the prediction of the inverters DC current and voltage uses the approach presented in
Section 2.2.1. In this case only plants A and B are considered, and the recorded data have been divided in two parts: the first one, composed of all data acquired before the 1st January 2018, constitutes the training set for our models, while the second one, composed of all data acquired after this date, constitutes the test set on which the models performance is assessed.
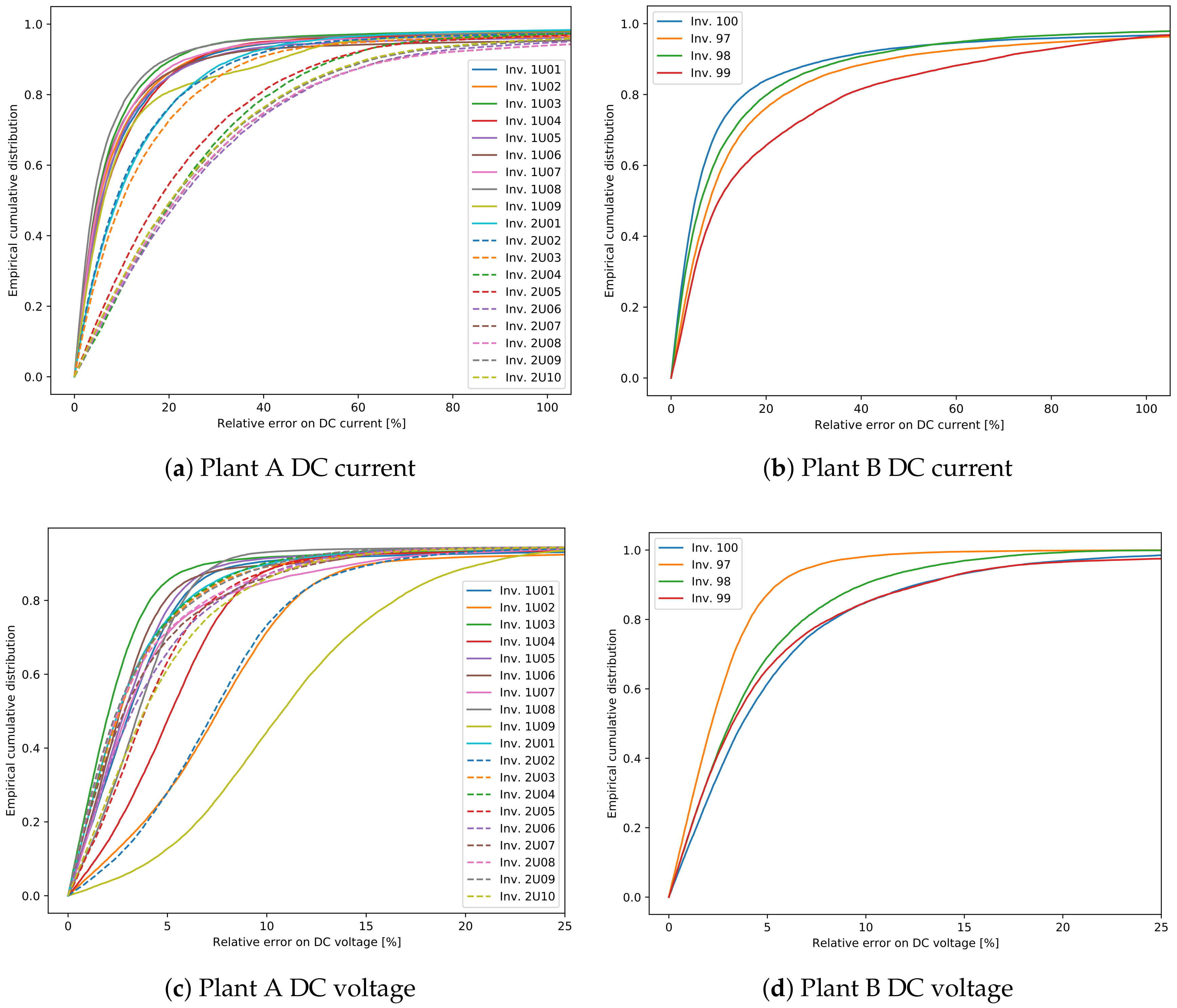
Figure 8 shows the cumulative distributions of the relative errors in the predicted voltage and current for each of the two plants and each inverter on the test set. For this plot only the points where the current is higher than 5% of the maximum measured inverter’s current are considered, in order to focus only on times of operation. As immediately apparent, the error on the voltage prediction is usually much lower than the one on the current, which is then the most important contribution to the error in predicted power. Noted that there is a relatively large difference in errors between the different inverters, which has to be investigated.
For this reason,
Figure 9 and
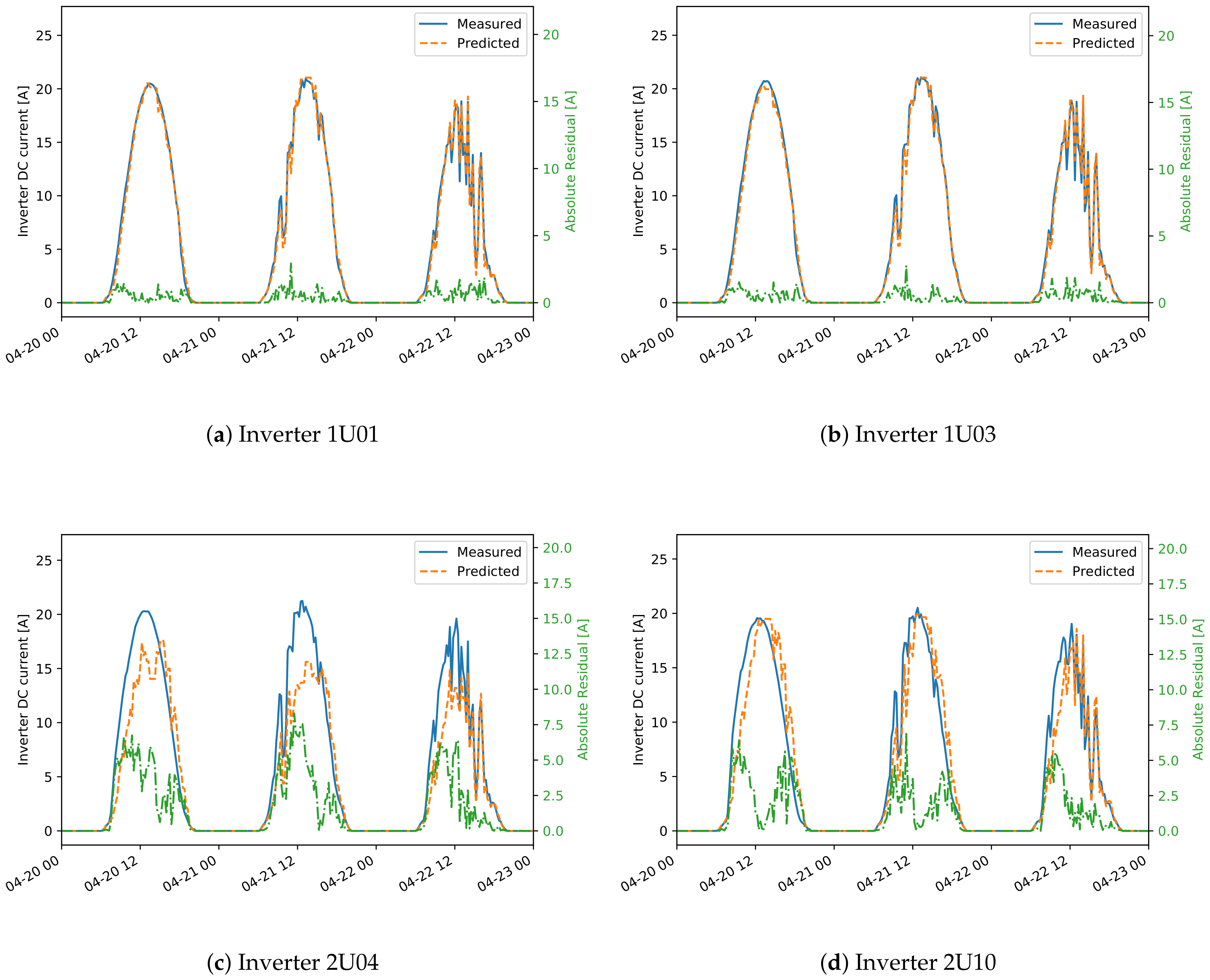
Figure 10 show comparisons between measured and predicted DC currents for some inverters of the two plants. For plant A (
Figure 9), it is apparent that the inverters 1U01 and 1U03 have conserved the same behavior between the training and test sets, and for this reason the predicted current is always very close to the measured one. On the other hand inverters 2U04 and 2U10 have deviated much more from this behavior, exhibiting both a small shift in time, due to the slightly different orientation between these modules and the irradiance sensor, and higher measured current for inverter 2U04, probably due to improvements in the PV panels or in the inverter. Note that the time shift for inverters 2U04 and 2U10 is just a systematic error, which can in principle be compensated, but it does not affect the results of anomaly detection. This happens because the derivation of the control chart limits takes already into account and compensates for any systematic error.
For plant B (
Figure 10), instead, the differences between the inverters is much smaller. It is, however, evident also in this case the time shift of inverter 99, which leads to a higher prediction error.
Comparison Model
The second approach for deriving a regression model of the inverter’s DC current and voltage involves the usage of a reference inverter (as explained in
Section 2.2.2). The easiest method for choosing a reference inverter is to select any one that does not show any evident anomaly in the recorded data, and this is the choice made in this work. For an application of this method to online monitoring, however, methods for checking whether the reference inverter is still operating normally need to be implemented. Such methods can make use, for instance, of a second reference inverter that could promptly signal if any anomaly occurred on the reference inverters. Another possibility would be to monitor whether suddenly all inverters signal an anomaly at the same time, indicating a possible failure on the reference inverter. These investigations would however require data where the anomalies are precisely characterized, and are therefore left for future work.
In the case presented here, the reference inverters chosen for the plants are: 1U01 for plant A, 100 for B, and 244 for C. Approximately one year of data, taking the data from the start date of plant operation is used for training. The starting dates of the test data are the following: 1.1.2015 for plant A, 1.7.2015 for plant B, and 1.1.2012 for C. The implementation for the prediction models is done using the Scikit-Learn library [
25]. The following algorithms were tested: “Linear regression”(LR), “Support vector regressor”(SVR), “Random forest regressor”(RFR), and “Decision tree”(DT). The parameters were set to their default values, except the maximal depth of the trees used in RFR that was set to 5, and the parameters for the DT models that were the same used in the approach in
Section 2.2.1. For training, 70% of the data is randomly chosen, while the other 30% was used for evaluation of the prediction model. The evaluation showed that a simple LR model can predict the DC current with high performance, featuring a
coefficient of around 0.97. On the other hand,
is only 0.47 for the models that predict DC voltage, showing a much lower performance. This result was expected since there is a strong linear dependency between the irradiance and DC current that would cause the DC current of two different inverters to be linearly dependent. On the other hand, this is not valid for the DC voltage.
To overcome the limitations of linear models for DC voltage prediction models, experiments were conducted to evaluate the models SVR, RFR and DT. For a better performance, the input data for SVR were standardized, while for RFR and DT the data were normalized to
. Later, the reverse process was done to get the prediction in the same range as the measurements. Adding the temporal features: “Time in the day”, expressed in hours, and “Day in year”, expressed as the index of the date, is also evaluated. The average value of the root mean square error (
) of the evaluation data, for all cases of models and input data, is shown in
Table 4. Results suggest that the best performance is achieved when using the SVR model with the additional temporal data include in the input. Therefore, for further investigations, the models for DC voltage prediction make use of this method.
3.2.2. Clustering
The daily residuals calculated from the comparison model, which employs a reference inverter (
Section 2.2.2), are used to run the clustering algorithm and find the meaningful clusters in the training data. The daily residuals are represented as multidimensional vectors, where each dimension matches a time in the day when a measurement is done. Only the dimensions with enough valid data are considered in the vector. Before clustering, missing data in the beginning and in the end of the day are replaced by 0-values, while the other missing data points are interpolated from the surrounding values. Daily residuals vectors with more than two consecutive missing points are discarded for the training process. The parameters used in the clustering (
Section 2.2.2) are set to
,
, and
.
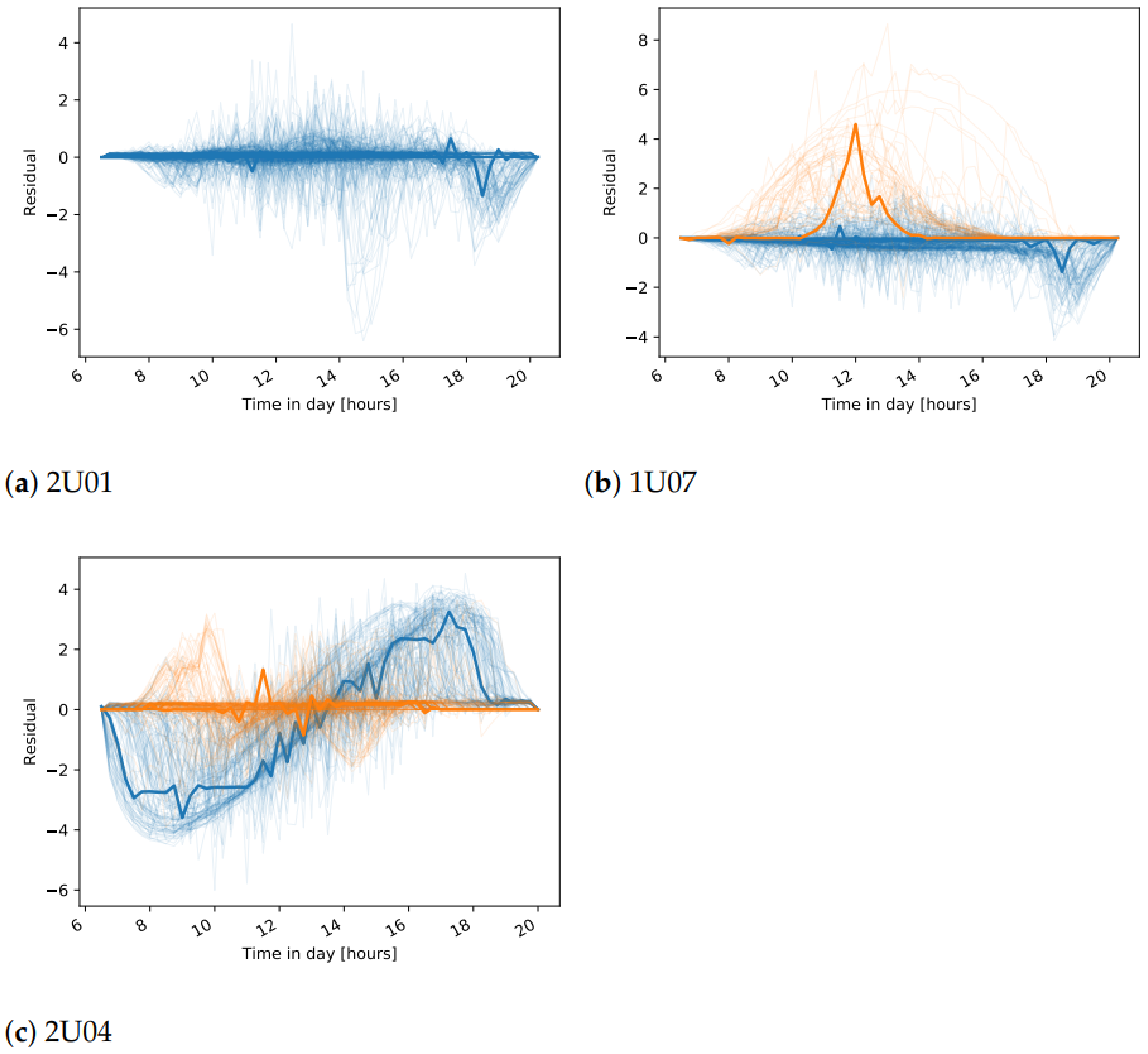
In many cases, as expected, only one meaningful cluster is found. In fact, if there are valid data from a well-operating plant, then the daily patterns of the residuals should be close to 0. Visualization of the daily residuals in a case where one cluster is identified, together with the cluster center, is seen in
Figure 11a. If different states of operation are present in the training data, we expect that more clusters will show up. One such example is inverter 1U07, where erroneous data are present in the training set (
Figure 11b), where two clusters are found. This is one drawback of the approach as there is no validation on the training data and we make an assumption that it does not include failures. Therefore, the final event detection for inverter 1U07 should be interpreted with caution. Another observation can be made for the inverters from plant A that have a different orientation than the reference inverter 1U01. For all inverters 2U04-2U10, two clusters are found in the DC current daily residuals, that are related to days in summer and winter seasons. The LR model cannot capture the shift in DC current seen for inverters with different orientation. Therefore, these shifts, that are different for the different seasons, are seen in the clusters (
Figure 11c). The final observation is that in a few of the cases on DC voltage daily residuals, except for the expected cluster around the 0-residuals, an additional one is found. One explanation is that natural shadows cause the modeled and reference inverter to start and end the daily operation at different times of the day. Hence, higher residuals are seen at the start or end of the day, which is later identified as a separate cluster. It can then be concluded that such a second cluster also shows a normal pattern since it represents a particular feature of the inverter.
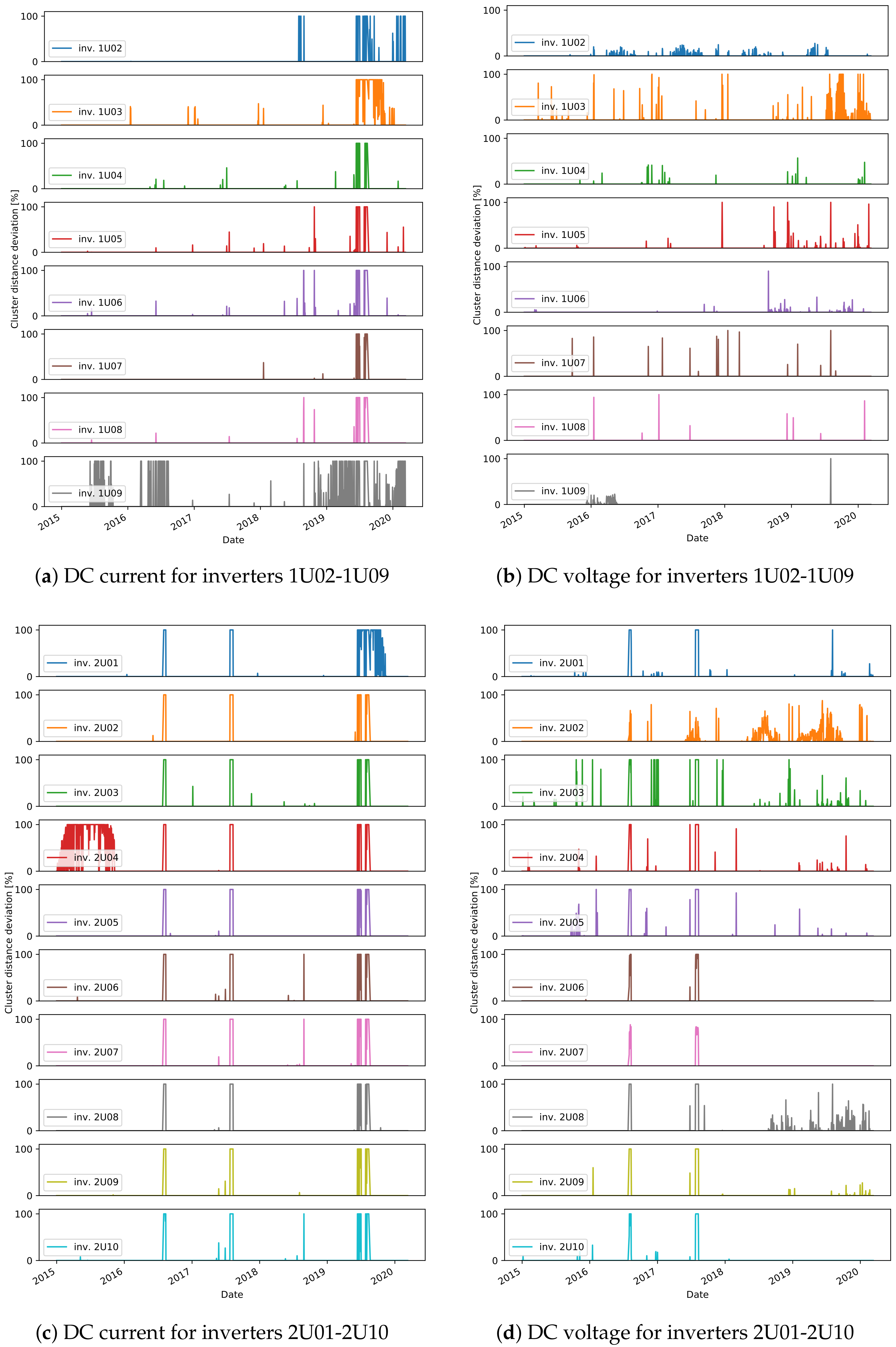
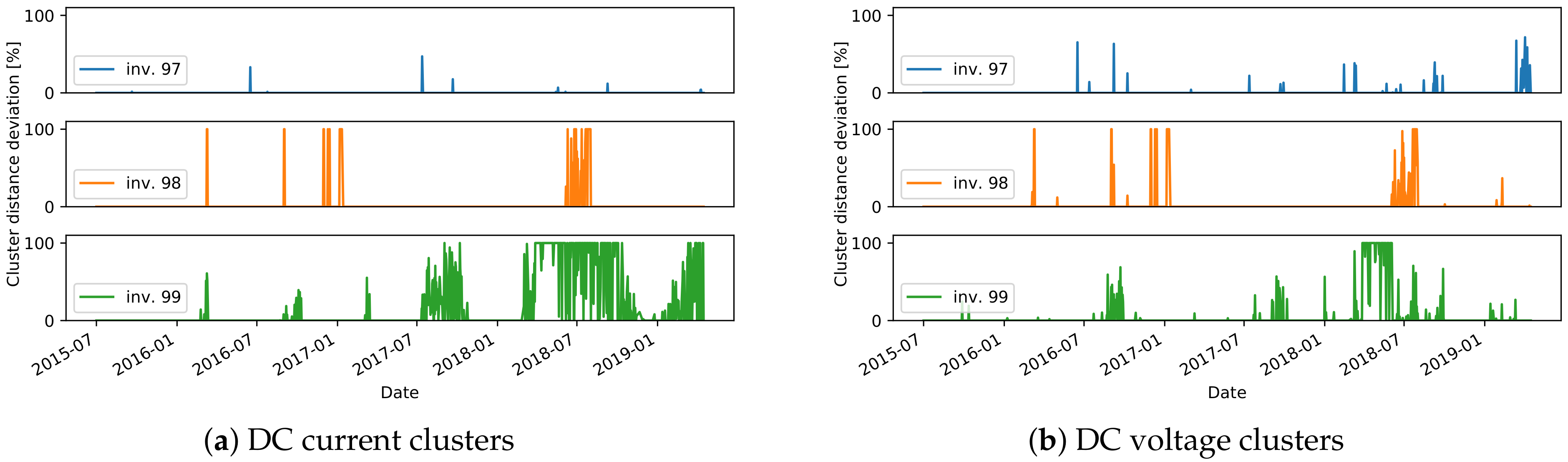
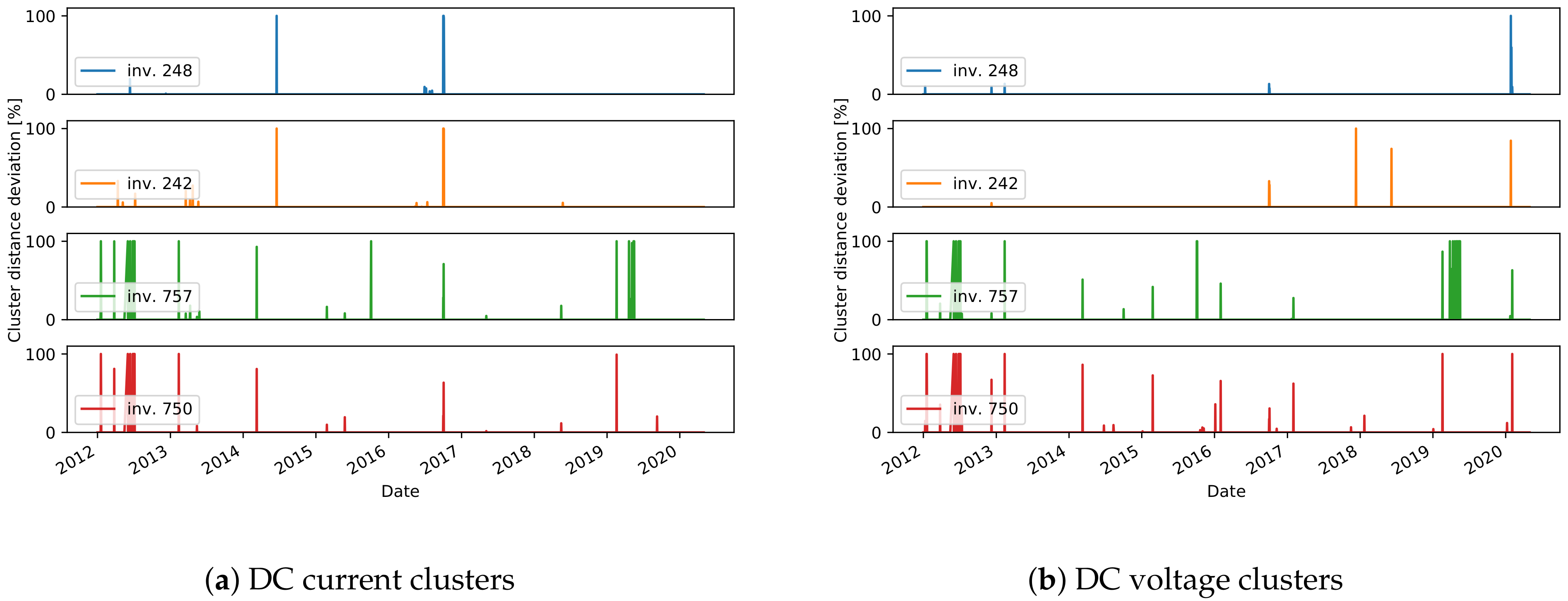
The final stage of the approach is to find the daily events that do not fit to any cluster. The relative distance of the daily residuals, for all days in the test data, are shown in
Figure 12,
Figure 13 and
Figure 14. We consider the days with a distance higher than 0 to detect an unusual daily pattern. On average, for all inverters, 4% (4% ) of the days in plant A, 11% (7%) in plant B, and only 0.7% (0.7%) in plant C are identified as DC current (DC voltage) unusual events. With the distinctions between unusual events in the residuals of DC current and DC voltage, one can find failures connected to DC voltage or DC current issues.
As the ground truth information of failures in the systems is not available, the evaluation of the proposed approach to detect unusual daily events is done qualitatively. The investigation of the daily events suggests different scenarios:
one-day events specific to one inverter;
long-term events specific to one inverter;
events occurring on all inverters, indicating either a plant-wide failure or a problem on the reference inverter;
events detected on both DC current and DC voltage.
For many of the detected one-day events, the relative distance to the nearest cluster is less than 50%. In these cases, the residuals show only a slight deviation with respect to the cluster centers (
Figure 13b). On the other hand, events with a higher distance usually represent more severe issues. Several events with high distances are detected in December in multiple years, for inverter 2U03 (
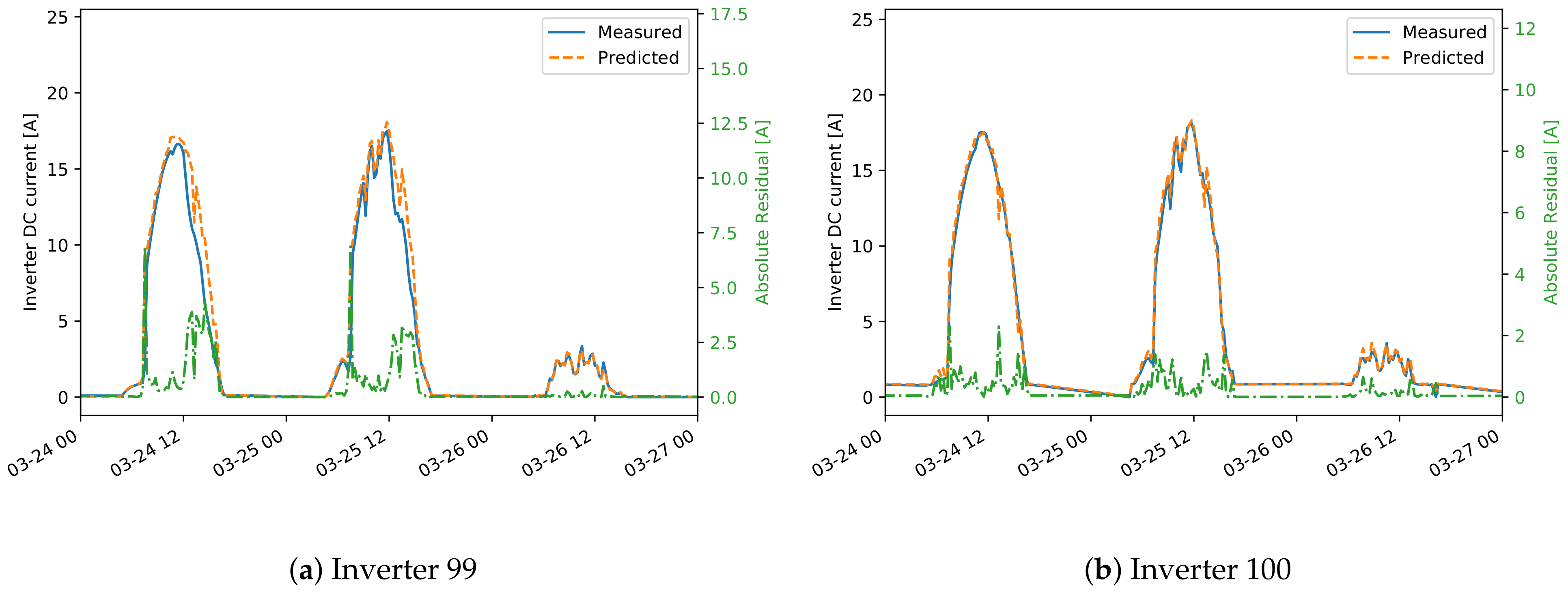
Figure 12d), which are related to short-term increase or decrease in voltage in several hours in the afternoon. In another example, current-related events are detected for inverter 99, where the current measured for short periods in the afternoon has lower values (
Figure 15).
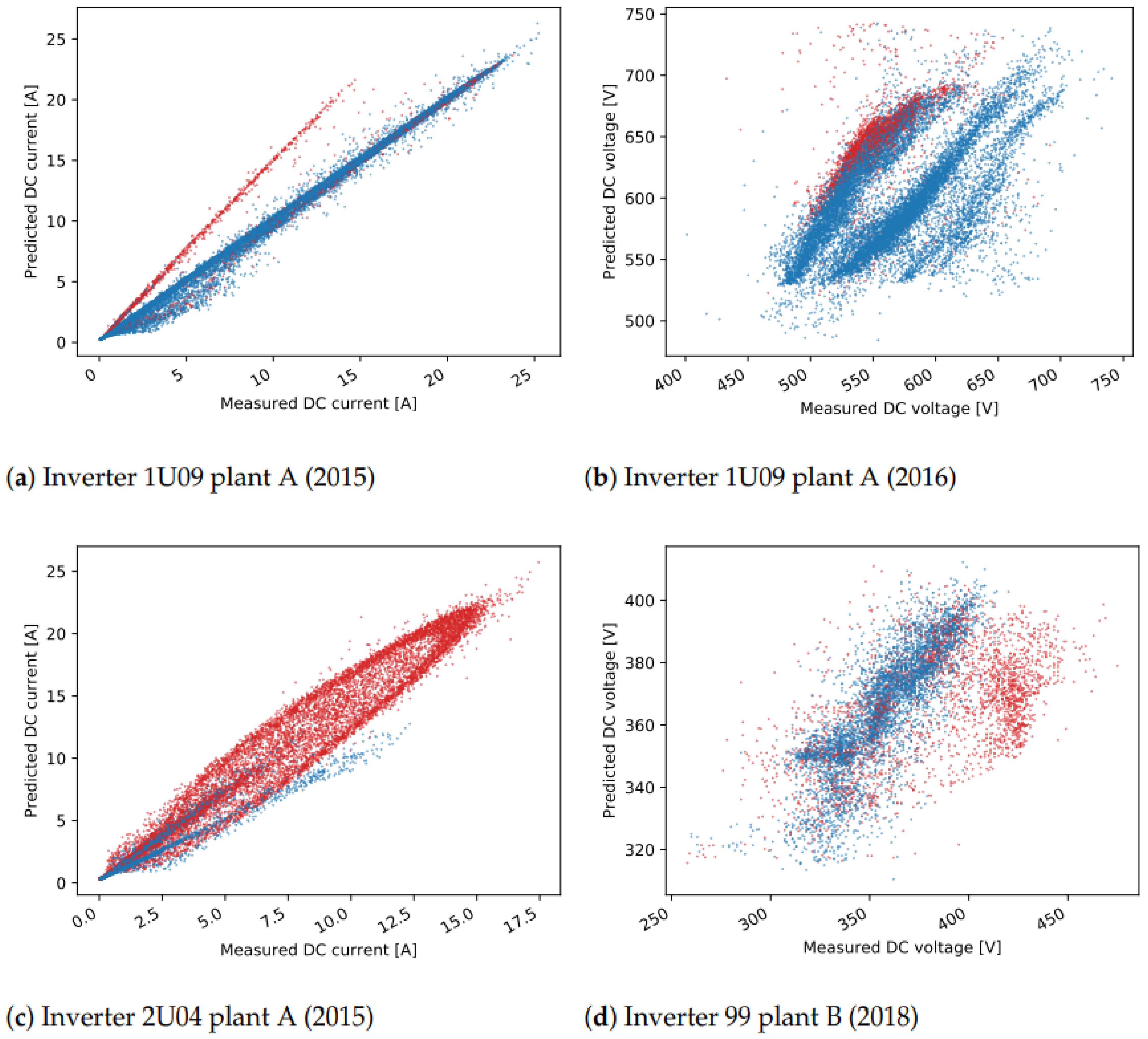
In some cases, events are detected in multiple days over a longer period of time. One such case is seen in mid-2015 (
Figure 12a) for inverter 1U09. A scatter plot of the measured values for DC current and the predicted values with the ML model is shown in
Figure 15a. The points in red show the values in the days detected as unusual events, where the measured values are lower than the predicted ones for about 5A. Similar scenarios are seen in mid-2016, and in most of the time in 2019 and 2020. The events seen in DC voltage in 2016 for the same inverter are caused by a slight increase in voltage in part or the whole day (
Figure 15b). Lower current is also behind the events in 2020 for inverter 1U02, the events in 2019 for 1U03 and 2U01, and finally the events in 2015 for 2U04 (
Figure 12). The dependency of the measured and predicted values in the case of inverter 2U04 is not linear, since the orientation of the modules is different than the orientation in inverter 1U01 (
Figure 15c). Most of the events detected in DC voltage daily residuals are caused by the high drop in voltage at approximately 19:00 for a short period of time (
Figure 12d). On the other hand, for inverter 2U08, the events in 2019 are related to an unusual increase in voltage seen in the morning.
The third scenario, where events in several inverters at the same time are seen, can be observed in a few examples, and they are a probable indication of an anomaly on the reference inverters. In one case, a deviation of the DC current of the reference inverter caused detection of events for all other inverters in plant C in 2017 (
Figure 14a). In another case, this time not indicating anomalies on the reference inverter but rather problems in the data collection, the DC current for all inverters in plant A goes to 0 at some times of the day, but also many missing data within the day are seen in the mid-2019 (
Figure 12).
Finally, one example of the fourth scenario can be seen for inverter 99 in plant B. In the first half of 2018, for the days detected as events for both DC current and DC voltage, lower DC current and higher DC voltage is observed. The measured and predicted DC voltage in 2018 is seen in
Figure 15d. The events of DC current residuals of the inverters 757 and 750 in plant C, detected in 2012 are connected to a drop of current to 0, while at the same time the measured voltage is higher (
Figure 14). A similar scenario is detected for inverters 2U01-2U10 in the periods of 8th–12th August 2016 and 25th July–10th August in 2017 (
Figure 12).
Overall, the analysis of the detected events shows a successful performance of the method to grasp many truly unusual patterns, especially in the cases where a high distance to the closest cluster is obtained (more than 50%). One limitation is that some events are detected in cases where only a slight deviation from the clusters exists. The sensitivity of the distance metric should be further investigated, and if necessary a different metric could be proposed in future work. Another limitation is that, for online monitoring, if a method for inspecting if the reference inverter itself is operating normally is not implemented, the interpretation of the events should be done with special care.
3.2.3. Control Chart
The second method for anomaly detection presented here makes use of the environmental model (
Section 2.2.1) to build a control chart on the test set. The model’s performance, as assessed in
Section 3.2.1, can be highly variable depending on the plant and the inverter, and therefore the limits for the control chart (Equation (
2)) need to be derived on a per-inverter basis.
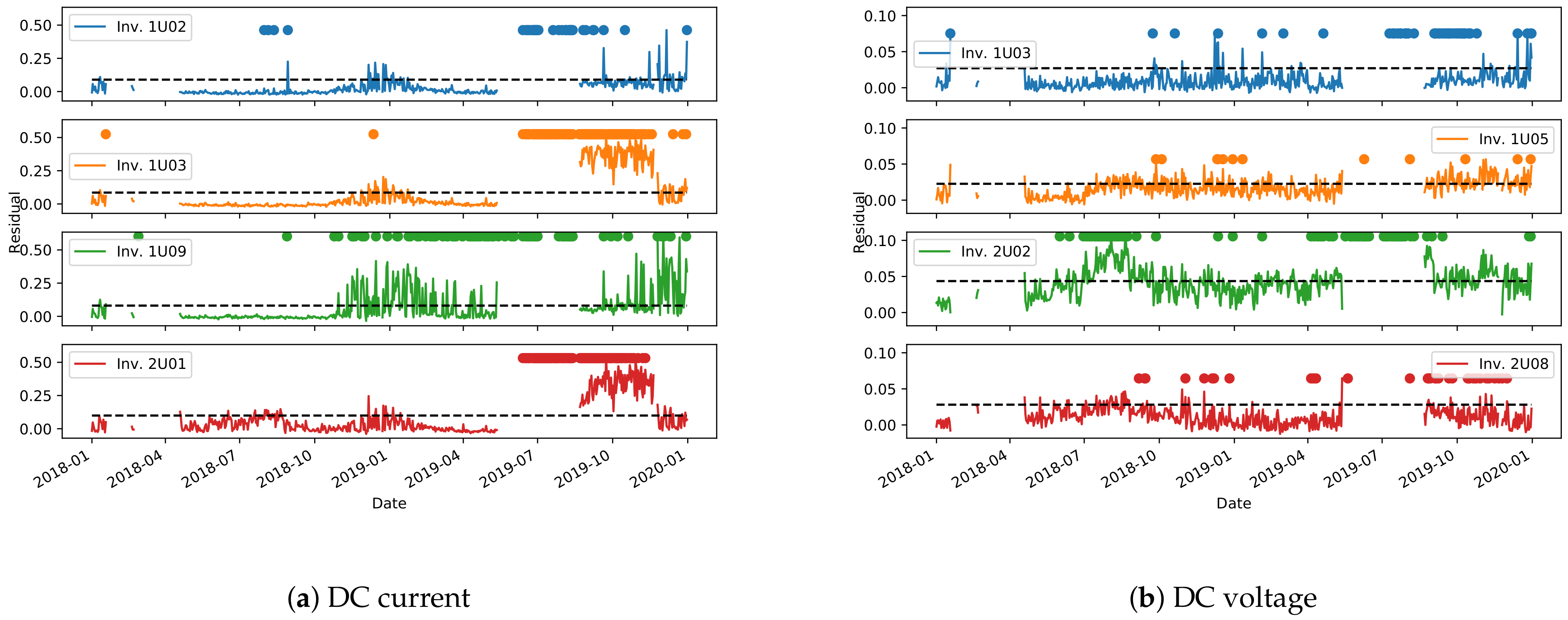
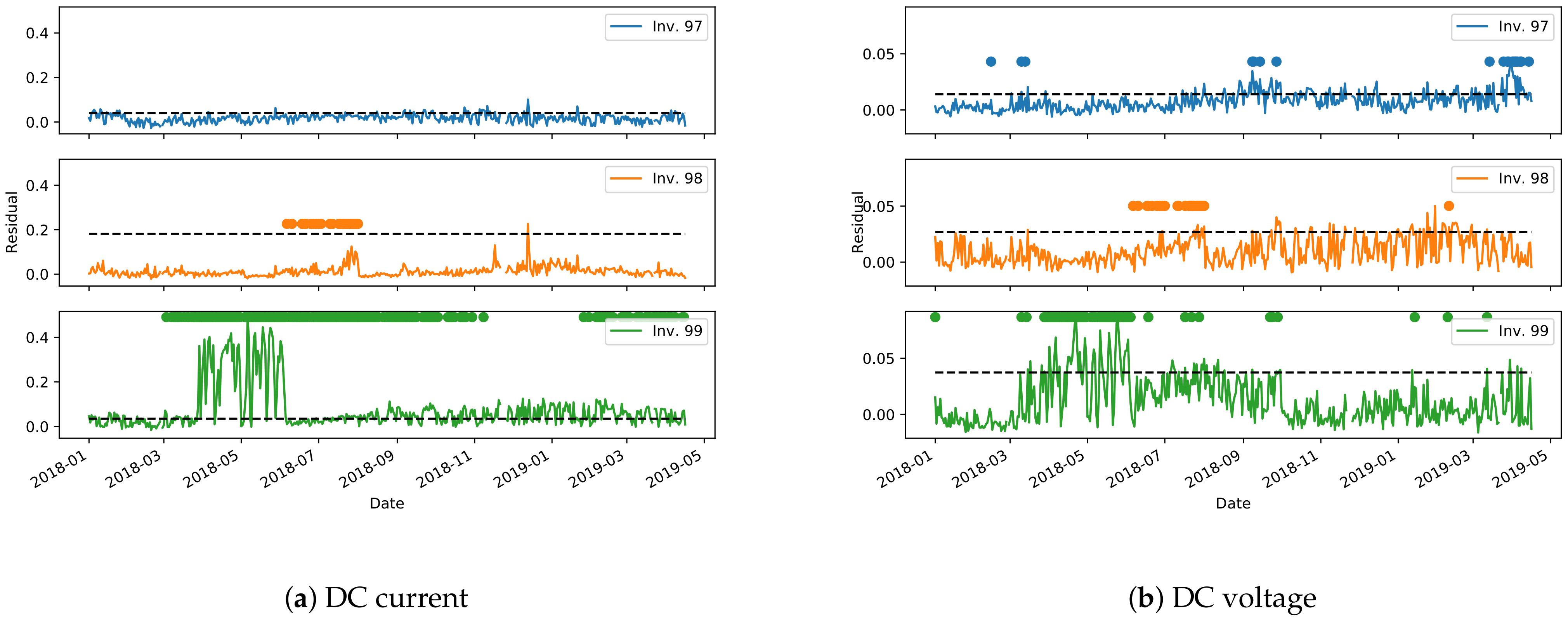
Figure 16 and
Figure 17 show the derived control charts for DC current and voltage on the most representative inverters of plants A and B. The dashed horizontal line is the limit defined by Equation (
2), while the dots are the points in which the clustering approach from
Section 3.2.2 detects an anomaly. Unfortunately, due to missing data, a non-negligible time period is unavailable to derive the control chart for plant A. It can be noted, however, that the two methods for anomaly detection have a good agreement in identifying long periods of anomalous behavior. More localized anomaly peaks, in one method or in the other, are instead most probably outliers, that need to be filtered out.
4. Conclusions
In this work, we have presented different data-driven approaches for the assessment of performance degradation in PV plants due to various conditions. The approaches target different data availability and operating conditions, showing a substantial agreement when a comparison is possible. Such methods can be extremely valuable for an efficient operation of a photovoltaic plant, allowing the prompt identification and correction of problems affecting the performance. We have shown that the great degree of variability on PV plants does not affect negatively the accuracy of the algorithms, provided that data of sufficient quality are available for the training phase. Our methods have been validated against some of the most popular methods in the literature, showing comparable performance. Our approaches, however, being data-driven, have the advantage of requiring neither in-depth knowledge of the plant nor specific and accurate physical measurements on-site, rather only the monitoring of the plant with high-level sensors for an adequate amount of time.
The next logical step with respect to anomaly detection would be to allow not just the identification of a failure, but also its characterization in terms of root causes. This, however, would require the collection of much more detailed datasets, where examples of many different kinds of failures would need to be recorded and manually characterized. Our results on the degradation estimation pave also the way for the derivation of predictive models, which can estimate the remaining useful life for all components before the need of replacement due to an unacceptable decrease in performance. Furthermore, for this application, though, the need for datasets with more specific and accurate information about each inverter is mandatory. These considerations reiterate the need for promoting the acquisition of increasingly accurate and detailed datasets monitoring the operation of photovoltaic plants.


 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}