
Semantic Evidential Grid Mapping Using Monocular and Stereo Cameras †



Abstract
1. Introduction
1.1. Dempster–Shafer Theory of Evidence (DST)
1.2. Related Work
1.3. Goals of This Work
2. Materials and Methods
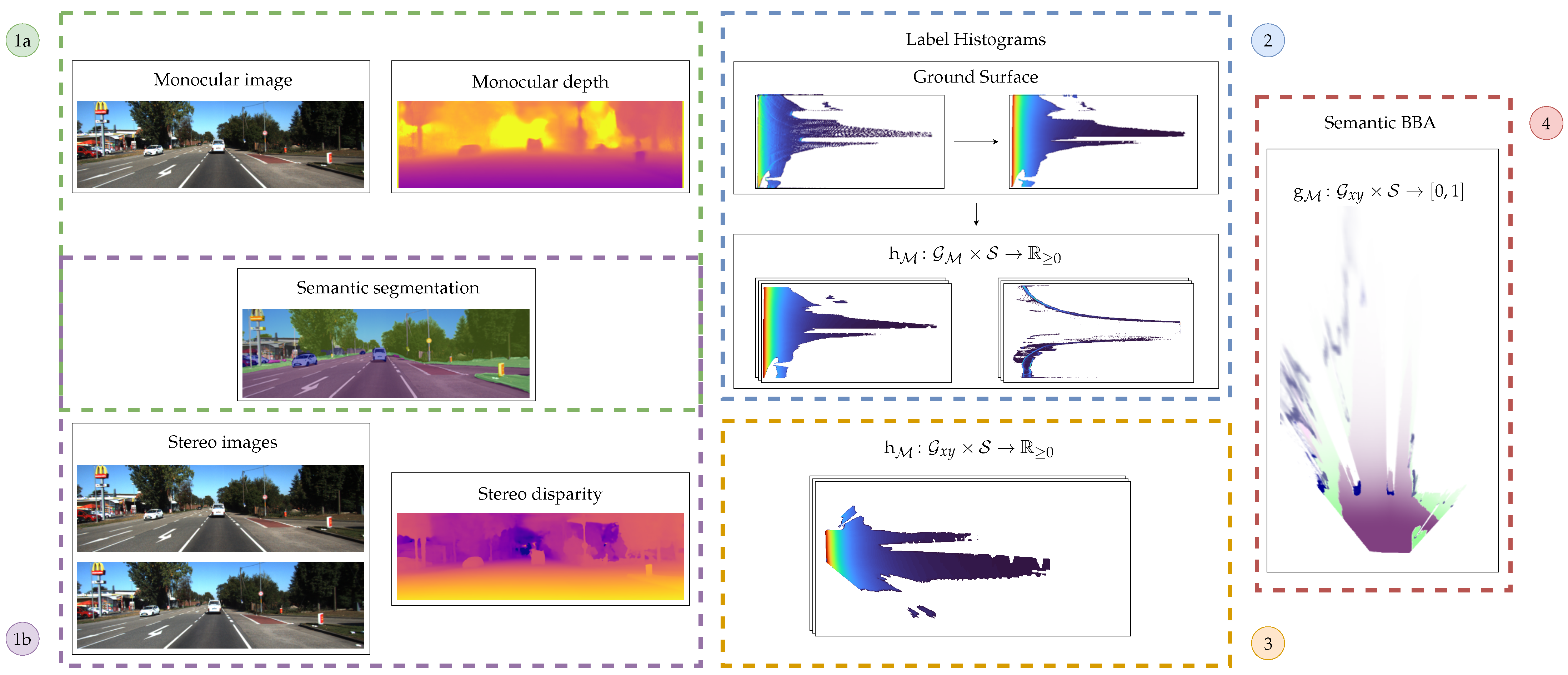
2.1. Semantic Evidential Framework
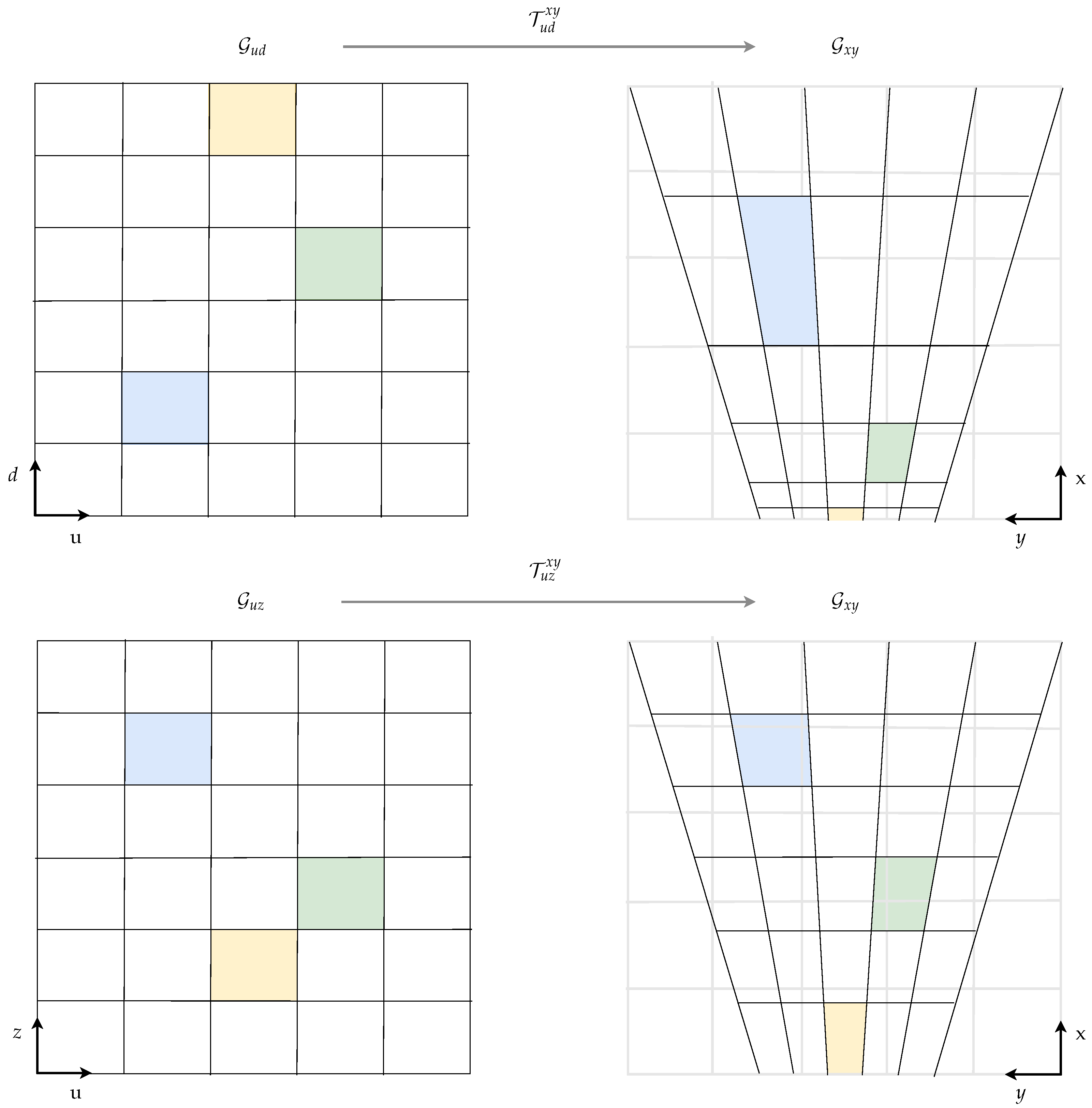
2.2. Coordinate Systems
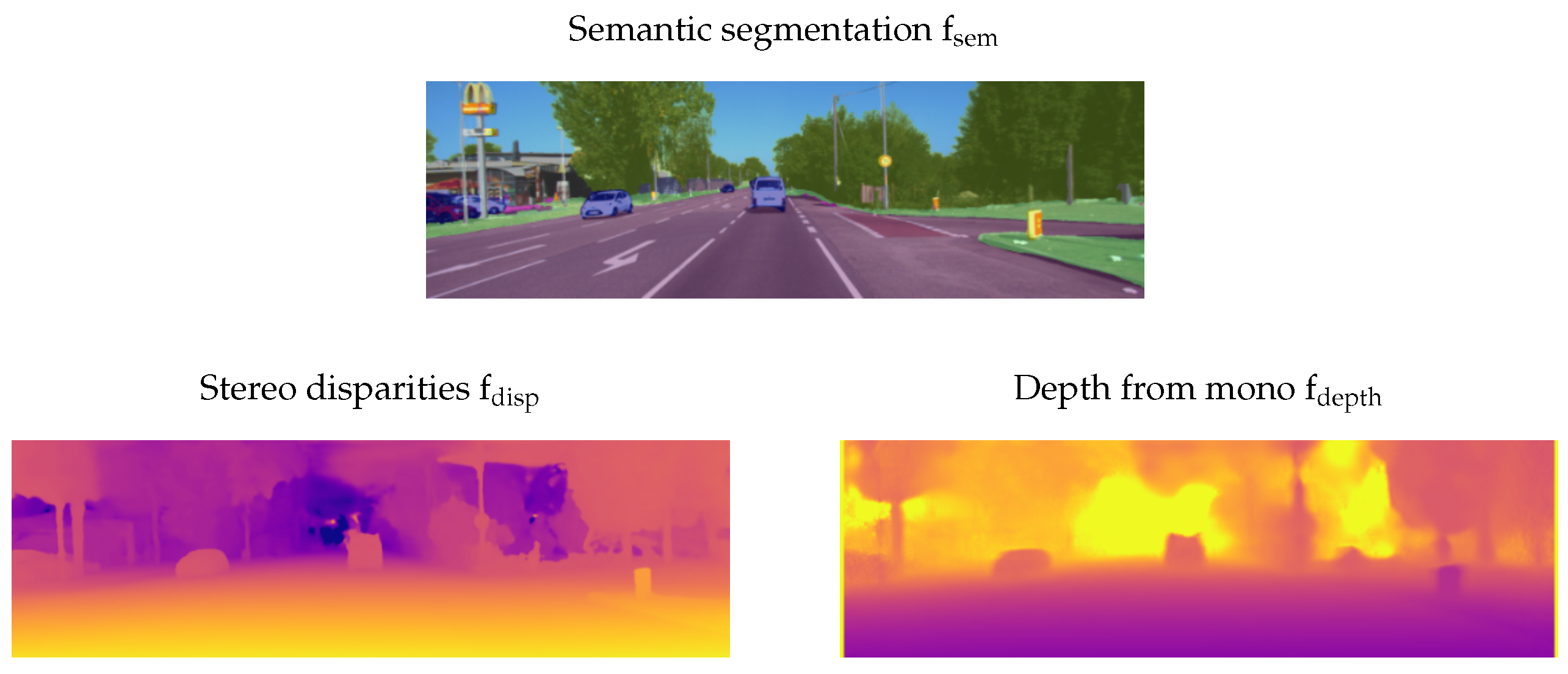
2.3. Input Representation
2.4. Label Histogram Calculation
2.4.1. Ground Surface Estimation
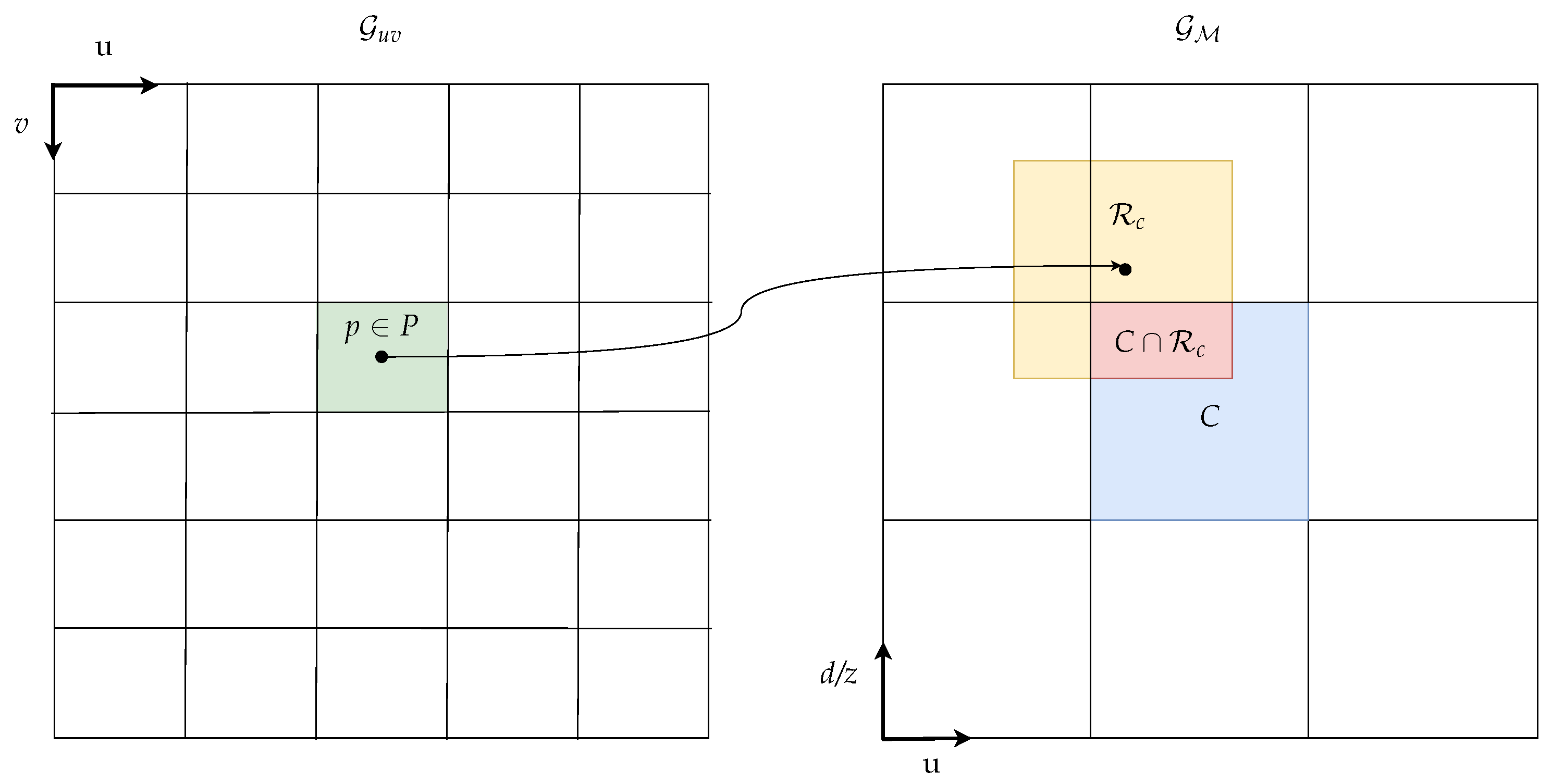
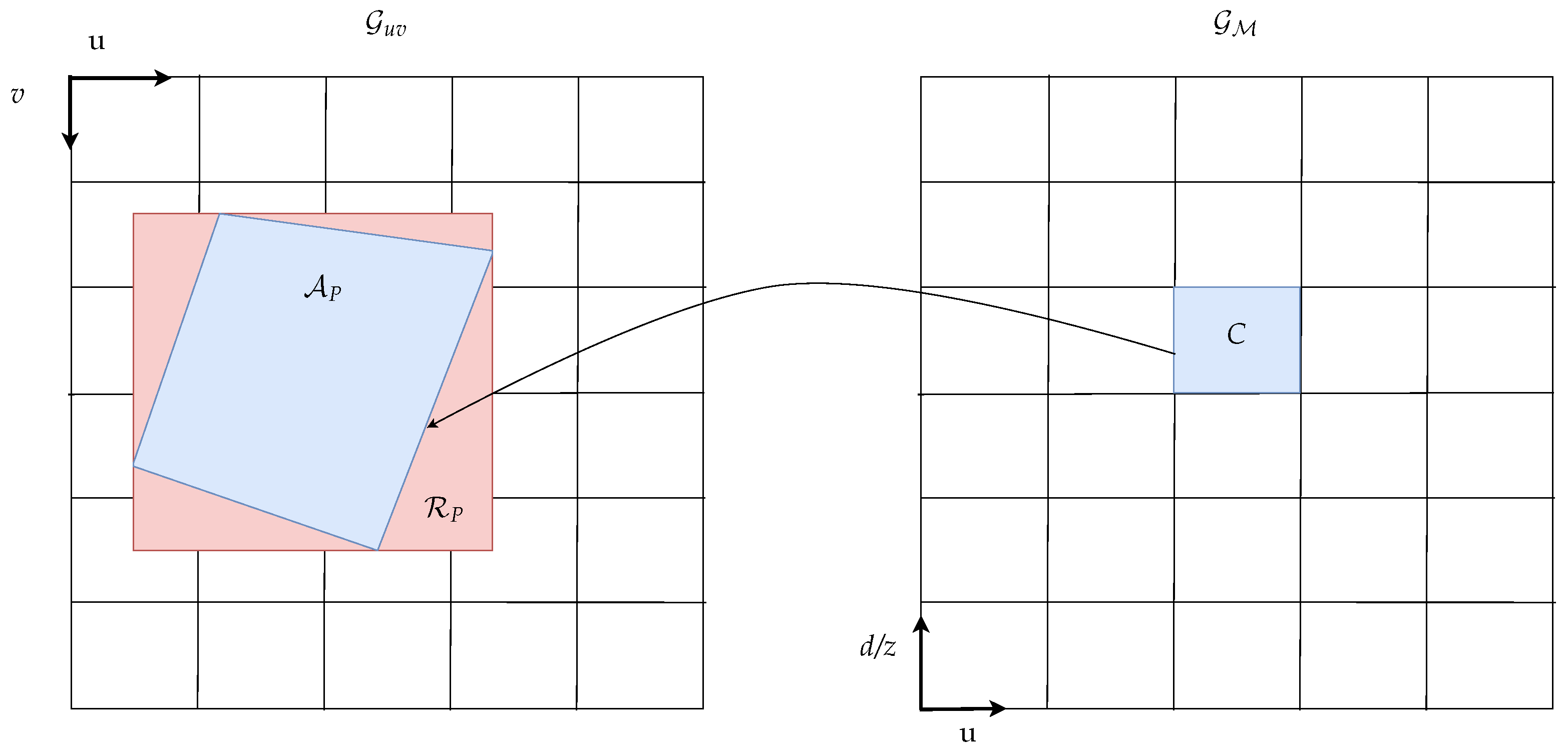
2.4.2. Pixel Area Approximation
2.4.3. Area Integral Calculation
2.5. Grid Transformation to Cartesian Space
2.6. Basic Belief Assignment
3. Results
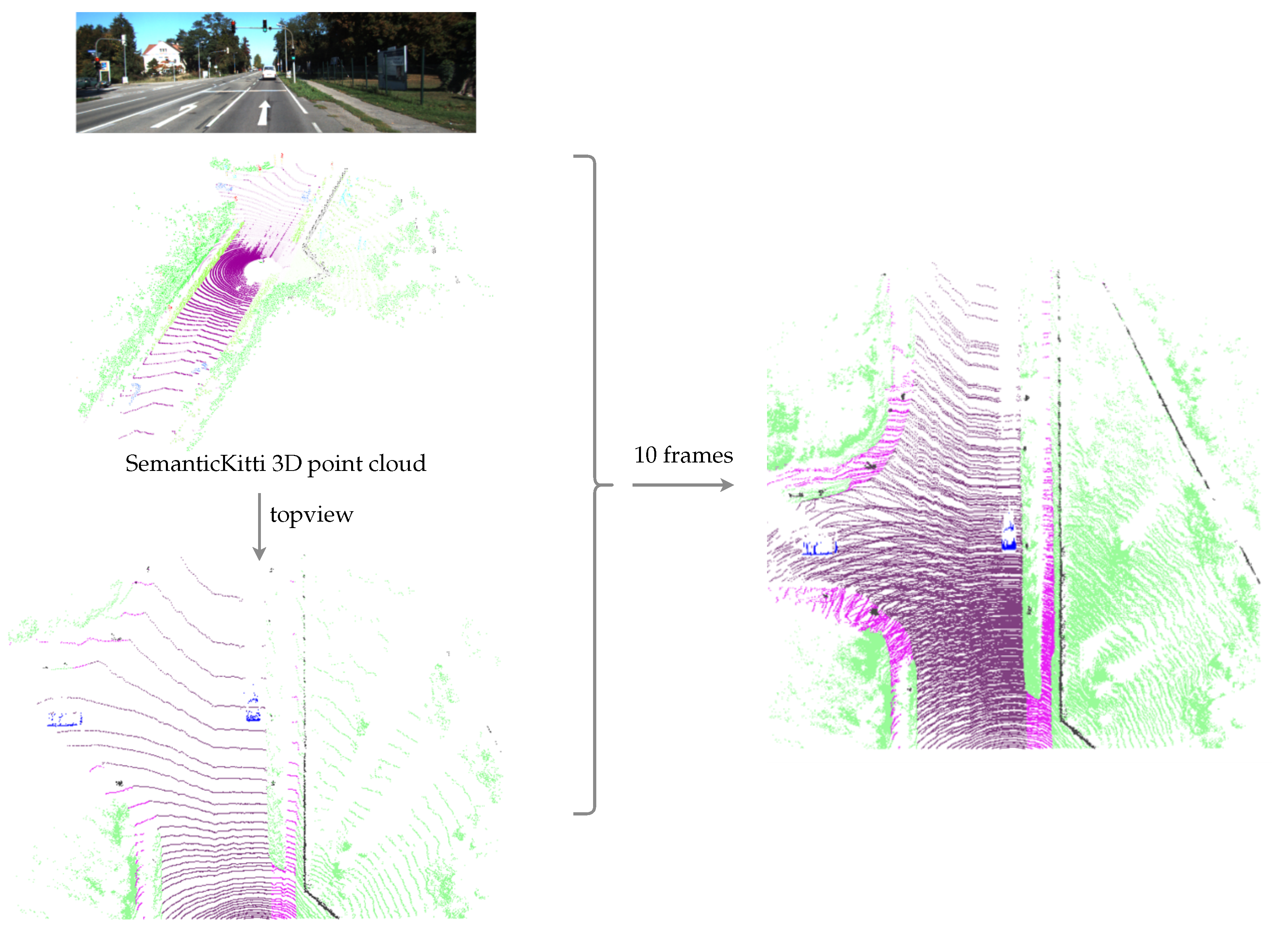
3.1. Ground Truth Generation
3.2. Visual Evaluation
3.3. Quantitative Evaluation
3.3.1. Intersection over Union
3.3.2. Ratio of Correct Labels
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Richter, S.; Wirges, S.; Königshof, H.; Stiller, C. Fusion of range measurements and semantic estimates in an evidential framework/Fusion von Distanzmessungen und semantischen Größen im Rahmen der Evidenztheorie. Tm-Tech. Mess. 2019, 86, 102–106. [Google Scholar] [CrossRef]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976; Volume 42. [Google Scholar]
- Elfes, A. Using Occupancy Grids for Mobile Robot Perception and Navigation. Computer 1989, 22, 46–57. [Google Scholar] [CrossRef]
- Nuss, D.; Reuter, S.; Thom, M.; Yuan, T.; Krehl, G.; Maile, M.; Gern, A.; Dietmayer, K. A Random Finite Set Approach for Dynamic Occupancy Grid Maps with Real-time Application. Int. J. Robot. Res. 2018, 37, 841–866. [Google Scholar] [CrossRef]
- Steyer, S.; Tanzmeister, G.; Wollherr, D. Grid-Based Environment Estimation Using Evidential Mapping and Particle Tracking. IEEE Trans. Intell. Veh. 2018, 3, 384–396. [Google Scholar] [CrossRef]
- Badino, H.; Franke, U. Free Space Computation Using Stochastic Occupancy Grids and Dynamic Programming; Technical Report; Citeseer: University Park, PA, USA, 2007. [Google Scholar]
- Perrollaz, M.; Spalanzani, A.; Aubert, D. Probabilistic Representation of the Uncertainty of Stereo-Vision and Application to Obstacle Detection. In Proceedings of the IEEE Intelligent Vehicles Symposium, La Jolla, CA, USA, 21–24 June 2010; pp. 313–318. [Google Scholar] [CrossRef]
- Pocol, C.; Nedevschi, S.; Meinecke, M.M. Obstacle Detection Based on Dense Stereovision for Urban ACC Systems. In Proceedings of the 5th International Workshop on Intelligent Transportation, Hamburg, Germany, 18–19 March 2008. [Google Scholar]
- Danescu, R.; Pantilie, C.; Oniga, F.; Nedevschi, S. Particle Grid Tracking System Stereovision Based Obstacle Perception in Driving Environments. IEEE Intell. Transp. Syst. Mag. 2012, 4, 6–20. [Google Scholar] [CrossRef]
- Yu, C.; Cherfaoui, V.; Bonnifait, P. Evidential Occupancy Grid Mapping with Stereo-Vision. In Proceedings of the IEEE Intelligent Vehicles Symposium, Seoul, Korea, 28 June–1 July 2015; pp. 712–717. [Google Scholar] [CrossRef]
- Giovani, B.V.; Victorino, A.C.; Ferreira, J.V. Stereo Vision for Dynamic Urban Environment Perception Using Semantic Context in Evidential Grid. In Proceedings of the IEEE Conference on Intelligent Transportation Systems, Gran Canaria, Spain, 15–18 September 2015; pp. 2471–2476. [Google Scholar] [CrossRef]
- Valente, M.; Joly, C.; de la Fortelle, A. Fusing Laser Scanner and Stereo Camera in Evidential Grid Maps. In Proceedings of the 2018 15th International Conference on Control, Automation, Robotics and Vision (ICARCV), Singapore, 18–21 November 2018. [Google Scholar]
- Thomas, J.; Tatsch, J.; Van Ekeren, W.; Rojas, R.; Knoll, A. Semantic grid-based road model estimation for autonomous driving. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019. [Google Scholar] [CrossRef]
- Erkent, O.; Wolf, C.; Laugier, C.; Gonzalez, D.S.; Cano, V.R. Semantic Grid Estimation with a Hybrid Bayesian and Deep Neural Network Approach. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 888–895. [Google Scholar]
- Lu, C.; van de Molengraft, M.J.G.; Dubbelman, G. Monocular Semantic Occupancy Grid Mapping With Convolutional Variational Encoder–Decoder Networks. IEEE Robot. Autom. Lett. 2019, 4, 445–452. [Google Scholar] [CrossRef]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. Advances in neural information processing systems. arXiv 2014, arXiv:1406.2283. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G.; Reid, I. Learning depth from single monocular images using deep convolutional neural fields. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2024–2039. [Google Scholar] [CrossRef] [PubMed]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2002–2011. [Google Scholar]
- Alhashim, I.; Wonka, P. High quality monocular depth estimation via transfer learning. arXiv 2018, arXiv:1812.11941. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1851–1858. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar]
- Qiao, S.; Zhu, Y.; Adam, H.; Yuille, A.; Chen, L.C. ViP-DeepLab: Learning Visual Perception with Depth-aware Video Panoptic Segmentation. arXiv 2020, arXiv:2012.05258. [Google Scholar]
- Richter, S.; Beck, J.; Wirges, S.; Stiller, C. Semantic Evidential Grid Mapping based on Stereo Vision. In Proceedings of the 2020 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), Karlsruhe, Germany, 14–16 September 2020; pp. 179–184. [Google Scholar] [CrossRef]
- Bertalmio, M.; Bertozzi, A.; Sapiro, G. Navier-Stokes, Fluid Dynamics, and Image and Video Inpainting. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, pp. 1–355. [Google Scholar] [CrossRef]
- Yguel, M.; Aycard, O.; Laugier, C. Efficient GPU-based construction of occupancy grids using several laser range-finders. Int. J. Veh. Auton. Syst. 2008, 6, 48–83. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Zhang, F.; Prisacariu, V.; Yang, R.; Torr, P.H.S. GA-Net: Guided Aggregation Net for End-To-End Stereo Matching. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 185–194. [Google Scholar] [CrossRef]
- Zhu, Y.; Sapra, K.; Reda, F.A.; Shih, K.J.; Newsam, S.; Tao, A.; Catanzaro, B. Improving semantic segmentation via video propagation and label relaxation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8856–8865. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Bieder, F.; Wirges, S.; Janosovits, J.; Richter, S.; Wang, Z.; Stiller, C. Exploiting Multi-Layer Grid Maps for Surround-View Semantic Segmentation of Sparse LiDAR Data. arXiv 2020, arXiv:2005.06667. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Seq. | Car | Cyclist | Pedestrian | Non Movable | Street | Sidewalk | Terrain | ⌀ |
|---|---|---|---|---|---|---|---|---|
| 00 | 51.0 (65.7) | 5.4 (6.3) | 3.4 (4.7) | 40.6 (50.9) | 92.3 (95.6) | 64.4 (72.7) | 29.0 (35.3) | 40.9 (47.3) |
| 01 | 22.8 (45.8) | 10. 3(8.8) | - | 27.0 (36.6) | 85.3 (92.8) | - | 59.2 (66.5) | 29.2 (35.8) |
| 02 | 48.9 (66.7) | 3.0 (2.9) | 0.3 (0.3) | 17.4 (23.8) | 86.5 (91.4) | 49.8 (60.3) | 56.2 (57.0) | 37.4 (43.2) |
| 03 | 33.8 (54.1) | 2.0 (3.2) | - | 26.2 (33.6) | 84.7 (88.4) | 60.5 (67.0) | 82.6 (85.2) | 41.4 (47.4) |
| 04 | 45.7 (64.0) | - | - | 26.7 (31.0) | 90.1 (92.9) | 34.9 (43.7) | 64.2 (67.4) | 37.4 (42.7) |
| 05 | 43.6 (60.4) | 3.3 (5.2) | 6.0 (8.2) | 32.4 (43.3) | 88.8 (93.1) | 57.7 (67.5) | 20.0 (23.5) | 36.0 (43.0) |
| 06 | 31.7 (49.1) | 4.2 (4.9) | 1.5 (1.6) | 28.0 (39.8) | 80.8 (88.9) | 50.2 (62.3) | 79.1 (84.4) | 39.4 (47.3) |
| 07 | 44.2 (61.6) | 5.7 (7.1) | 15.6 (17.8) | 43.0 (52.3) | 89.3 (93.7) | 61.9 (69.4) | 71.7 (76.2) | 47.3 (54.0) |
| 08 | 37.5 (56.1) | 8.3 (12.4) | 6.6 (10.2) | 33.5 (46.7) | 87.1 (91.9) | 57.0 (67.1) | 72.1 (75.2) | 43.2 (51.4) |
| 09 | 37.7 (57.7) | 5.0 (6.1) | 5.7 (15.7) | 29.3 (41.7) | 85.4 (90.7) | 53.4 (64.9) | 60.3 (65.7) | 39.5 (49.0) |
| 10 | 33.4 (50.8) | - | 4.6 (7.2) | 28.2 (36.4) | 80.6 (85.2) | 45.3 (52.5) | 48.8 (53.5) | 34.4 (40.8) |
| all | 40.8 (59.0) | 5.0 (6.7) | 5.5 (8.1) | 30.7 (41.4) | 85.9 (91.3) | 54.2 (64.2) | 65.1 (69.9) | 41.0 (48.7) |
| Seq. | Car | Cyclist | Pedestrian | Non Movable | Street | Sidewalk | Terrain | ⌀ |
|---|---|---|---|---|---|---|---|---|
| 00 | 40.6 (51.5) | 3.5 (3.6) | 0.4 (0.7) | 42.4 (59.1) | 89.9 (92.8) | 60.4 (71.2) | 30.7 (43.3) | 38.3 (46.0) |
| 01 | 15.4 (25.0) | 7.1 (9.0) | - | 18.3 (13.1) | 82.8 (90.9) | - | 63.4 (72.6) | 26.7 (30.1) |
| 02 | 35.6 (50.4) | 3.2 (3.9) | 0.1 (0.1) | 16.1 (22.6) | 84.7 (88.9) | 46.8 (54.9) | 56.9 (60.8) | 34.8 (40.2) |
| 03 | 21.9 (31.7) | 2.1 (3.4) | - | 16.9 (18.9) | 79.6 (83.8) | 49.2 (55.9) | 75.6 (81.8) | 35.0 (39.4) |
| 04 | 15.6 (30.6) | - | - | 31.6 (36.4) | 86.9 (90.3) | 35.0 (41.2) | 65.1 (70.6) | 33.5 (38.4) |
| 05 | 25.5 (39.5) | 4.5 (5.6) | 1.6 (2.6) | 31.4 (45.6) | 86.9 (90.4) | 54.2 (65.1) | 20.3 (34.1) | 32.1 (40.4) |
| 06 | 19.2 (30.4) | 4.0 (5.0) | 1.0 (1.7) | 32.3 (49.0) | 77.8 (84.8) | 46.7 (57.9) | 79.6 (86.0) | 37.2 (45.0) |
| 07 | 32.5 (46.5) | 5.3 (6.4) | 4.3 (7.4) | 44.0 (57.9) | 85.9 (90.3) | 57.6 (68.2) | 70.5 (81.0) | 42.9 (51.1) |
| 08 | 24.9 (37.8) | 6.7 (8.8) | 1.6 (2.0) | 35.8 (54.2) | 85.0 (89.1) | 53.4 (62.8) | 71.0 (77.9) | 39.8 (47.5) |
| 09 | 26.1 (40.8) | 2.6 (2.7) | 3.8 (7.1) | 32.9 (44.9) | 83.5 (88.4) | 49.5 (60.6) | 62.4 (72.1) | 37.3 (45.2) |
| 10 | 19.9 (31.7) | - | 3.0 (3.9) | 25.2 (34.4) | 76.2 (80.6) | 40.7 (48.1) | 47.4 (61.2) | 30.4 (37.1) |
| all | 27.7 (41.2) | 4.2 (5.2) | 2.0 (3.0) | 29.5 ( 41.7) | 83.2 (88.3) | 49.9 (59.6) | 65.0 (74.1) | 37.4 (44.7) |
| Seq. | 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 10 | All |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 81.5 | 81.1 | 78.6 | 86.7 | 83.7 | 73.6 | 82.5 | 83.9 | 82.9 | 79.3 | 73.4 | 80.8 | |
| 87.0 | 87.9 | 84.2 | 89.3 | 87.9 | 81.3 | 88.2 | 88.4 | 87.8 | 85.9 | 78.8 | 86.2 |
| Seq. | 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 10 | All |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 80.3 | 81.0 | 77.7 | 81.5 | 83.1 | 71.9 | 81.9 | 81.6 | 81.5 | 78.9 | 70.1 | 79.3 | |
| 87.8 | 88.9 | 83.8 | 86.3 | 87.7 | 83.4 | 88.1 | 88.3 | 87.5 | 86.2 | 78.5 | 86.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Richter, S.; Wang, Y.; Beck, J.; Wirges, S.; Stiller, C. Semantic Evidential Grid Mapping Using Monocular and Stereo Cameras. Sensors 2021, 21, 3380. https://doi.org/10.3390/s21103380
Richter S, Wang Y, Beck J, Wirges S, Stiller C. Semantic Evidential Grid Mapping Using Monocular and Stereo Cameras. Sensors. 2021; 21(10):3380. https://doi.org/10.3390/s21103380
Chicago/Turabian StyleRichter, Sven, Yiqun Wang, Johannes Beck, Sascha Wirges, and Christoph Stiller. 2021. "Semantic Evidential Grid Mapping Using Monocular and Stereo Cameras" Sensors 21, no. 10: 3380. https://doi.org/10.3390/s21103380
APA StyleRichter, S., Wang, Y., Beck, J., Wirges, S., & Stiller, C. (2021). Semantic Evidential Grid Mapping Using Monocular and Stereo Cameras. Sensors, 21(10), 3380. https://doi.org/10.3390/s21103380