1. Introduction
StarCraft is a Real-Time Strategy (RTS) game that was released by Blizzard Entertainment in 1998.
Figure 1 shows a screenshot of StarCraft. Similar to other RTS games, the core tasks in StarCraft are gathering resources, training the military, and using them to defeat the opponent’s army. When compared with traditional board games or Atari games, StarCraft has a larger state space and more high-dimensional control interfaces. In addition, the states of this game are partially observable. Although AlphaStar [
1] can reach the human level in the game of StarCraft II, its success is extremely dependent on huge computing resources. It is worth studying how to decompose the complex problem of the StarCraft game into several sub-problems, so as to solve it more efficiently [
2,
3,
4].
Macromanagement is one of the most important sub-problems. Macromanagement aims at deciding what to build or which combat units to produce, depending on the current state including buildings and units of both sides, the resources and the technologies of our side. In StarCraft, each unit has its own strengths and weaknesses, while each type of building has its own unique function. Making the appropriate selection based on the current state is the foundation of victory. Thus, we focus on macromanagement tasks.
Using hand-coded strategies is a common method of macromanagement, and it is widely applied in the StarCraft bots coding in AI competitions [
2,
5]. Obviously, this method needs the designers’ professional knowledge and a large amount of time. With the development of computational intelligence in recent years, machine learning [
6], deep learning [
7,
8], and reinforcement learning [
9,
10] have been introduced into the field of StarCraft AI design [
11]. Tree search is applied for optimizing build orders to reach a specific goal [
12]. The replay data of the professional players provide valuable training samples, thus Supervised Learning (SL) methods can learn macromanagement decisions from these data [
13]. SL methods can obtain the decision models without many hand-crafted rules, but they also rely on labeled data. It should be noted that human players’ decision is based on their ability to solve other sub-problems, such as micromanagement and resource management. For the AI bots, the capability of the modules that are designed to solve these sub-problems are poorer than humans. For instance, professional players prefer strong but complex army units, while most of the bots are unable to control these units effectively. Thus, the choices made by human players may be inappropriate for the other modules. Evolutionary Computation (EC) can produce the optimal solutions under a wide range of problem settings and it does not need labeled data. Some methods use the win rate or the in-game scores as the fitness metrics and apply EC to evolve the complete building plan [
14,
15]. Reinforcement Learning (RL) methods are designed to solve sequential decision problems and they are more sample-efficient than EC methods, so RL methods are very suitable for solving the macromanagement task [
16]. We select RL to learn macromanagement in order to reduce the dependence on professional knowledge and enhance the adaptability to other modules.
Reinforcement learning (RL) is a powerful tool for solving sequential decision-making problems and it has been widely used in various fields. The recent research work on the combination of reinforcement learning and deep learning has made tremendous achievements. Mnih et al. [
17] proposed Deep Q-Network (DQN) and trained an agent that performs comparably to human players on Atari games. AlphaGo [
18] won the Go competition to a world champion for the first time. In addition, an extraordinary amount of novel algorithms [
10,
19,
20,
21,
22,
23,
24,
25] are proposed for improving the stability and performance of deep reinforcement learning algorithms, reduce training time, and expand the scope of application. In the context of StarCraft micromanagement, researchers have proposed a series of deep reinforcement learning methods and they have achieved the desired results [
26,
27,
28].
For the problem of macromanagement, the rewards of victory or defeat can be obtained without any expert knowledge. The environment can be considered to be composed of the game and the bots of two sides. To obtain as many rewards as possible, the RL agent would choose the units to build that not only can restrict the opponent’s army, but can also be controlled by the micromanagement module. In this way, the learned macromanagement is adapted to not only the external environment, the game, and the opponent bot, but also the ability of the other modules in the bot.
However, there are still some technical difficulties in practice. Firstly, the agent can only obtain partial information of the full game state due to the ‘fog-of-war’. Secondly, the environment is stochastic for the agent to a certain extent, due to the problem of partial information and the uncertainty of other modules. Even the same states and actions may lead to different results. Finally, the training time is very long on account of that each match would take a relatively long time, approximately 3–10 min.
Essentially, the first issue is Partially Observable Markov Decision Processes (POMDPs) problem, which means that the states of the environment are only partially observable. Hausknecht and Stone [
21] attempt to solve it through extracting state feature from the observation queue. However, the action queue of our agent also influences the actual game state. Thus, we use LSTM [
29,
30] to extract the feature of history queue combined with all observations and actions. The extracted feature can improve the precision of evaluation on the true state. Being inspired by [
25], we update the policy utilizing the advantage function
instead of the TD-error signal
. The former one can be considered as the expectation of the latter one. Finally, we train multiple agents in parallel to shorten the training time and update the parameters of these agents using asynchronous gradient descent [
24].
The main contributions of this paper are: (i) we introduce the RL method to solve the problem of macromanagement; (ii) we propose a novel deep RL method, Mean Asynchronous Advantage Actor-Critic (MA3C), which can solve the problem of imperfect information, the uncertainty of state transition, and the matter of long training time; and, (iii) we present an approach to visualize the policy learned by deep RL method.
2. Related Works
There are many challenges in designing AI bots for StarCraft, such as resource management, decision-making under uncertainty, adversarial real-time planning, and so on. Alphastar [
1] uses massive computing resources to solve the problem of StarCraft as a whole to a certain extent, but it is also concerned to decompose the problem into multiple subproblems to solve it more efficiently. Many research works decompose designing AI bots into a series of subtasks: strategy, tactics, reactive control, terrain analysis, and intelligence gathering [
2]. This paper focuses on macromanagement, which is one of the core problems in the ‘strategy’ subtask.
Hand-coding is the earliest solution of macromanagement and it has been widely applied in AI competitions [
2,
5]. These methods require considerable professional knowledge and need generous time for coding and debugging. To reduce the dependence on this knowledge, ref. [
13] directly learns how macromanagement decisions from game replays using Supervised Learning (SL). When the learned network is integrated into a StarCraft bot, the system outperforms the game’s built-in bot. However, the macromanagement of human players is highly related to their unique micromanagement, resource management, etc. Thus, the network that is learned by SL may be inappropriate for the other modules of the bot that it integrated. Evolutionary Computation (EC) and Reinforcement Learning (RL) can avoid this problem. Ref. [
14] presents a framework to evolve a complete strategy for StarCraft from the building plan to the composition of squads. Ref. [
15] proposes an online evolutionary planning method to enable the algorithm to adapt to new situations. RL is more sample efficient when compared with EC. Ref. [
16] utilizes the RL method, Double Q-Learning [
23], to obtain some rational build-order arrangements according to the real-time situation in the game and fight against the built-in AI in simple maps. Ref. [
1] proposes AlphaStar, which trains the policy network with imitation learning and then uses league style reinforcement learning to optimize the network further. AlphaStar is rated above 99.8% of officially ranked human players. However, AlphaStar is required to train on hundreds of TPUs for months. In order to reduce the computation needed, ref. [
31] optimizes the network architecture and training methods, like reducing the input minimap size and adding the agent branching approach. Ref. [
32] also proposes new league training methods and lightweight neural network architecture to train a competitive AI agent with limited computation resources.
Our method is most similar to [
16]. The main goals of both [
16] and our method are using RL to learn which unit should be built out. The main difference is the RL algorithms and the networks [
16] selects Double Q-Learning to their network, while we propose a novel RL algorithm, MA3C, which runs multiple RL processes in parallel to reduce the training time and computes the approximate expected gradient to improve the stability of the algorithm. Besides, we add LSTM unit to our network to tackle the POMDP problem.
We compare these works in
Table 1 from the following aspects, the category of the algorithm, training time, the learned policy appropriated for other modules, the required computing resource, the magnitude of parameters, and the opponent selected in evaluation.
4. Approach
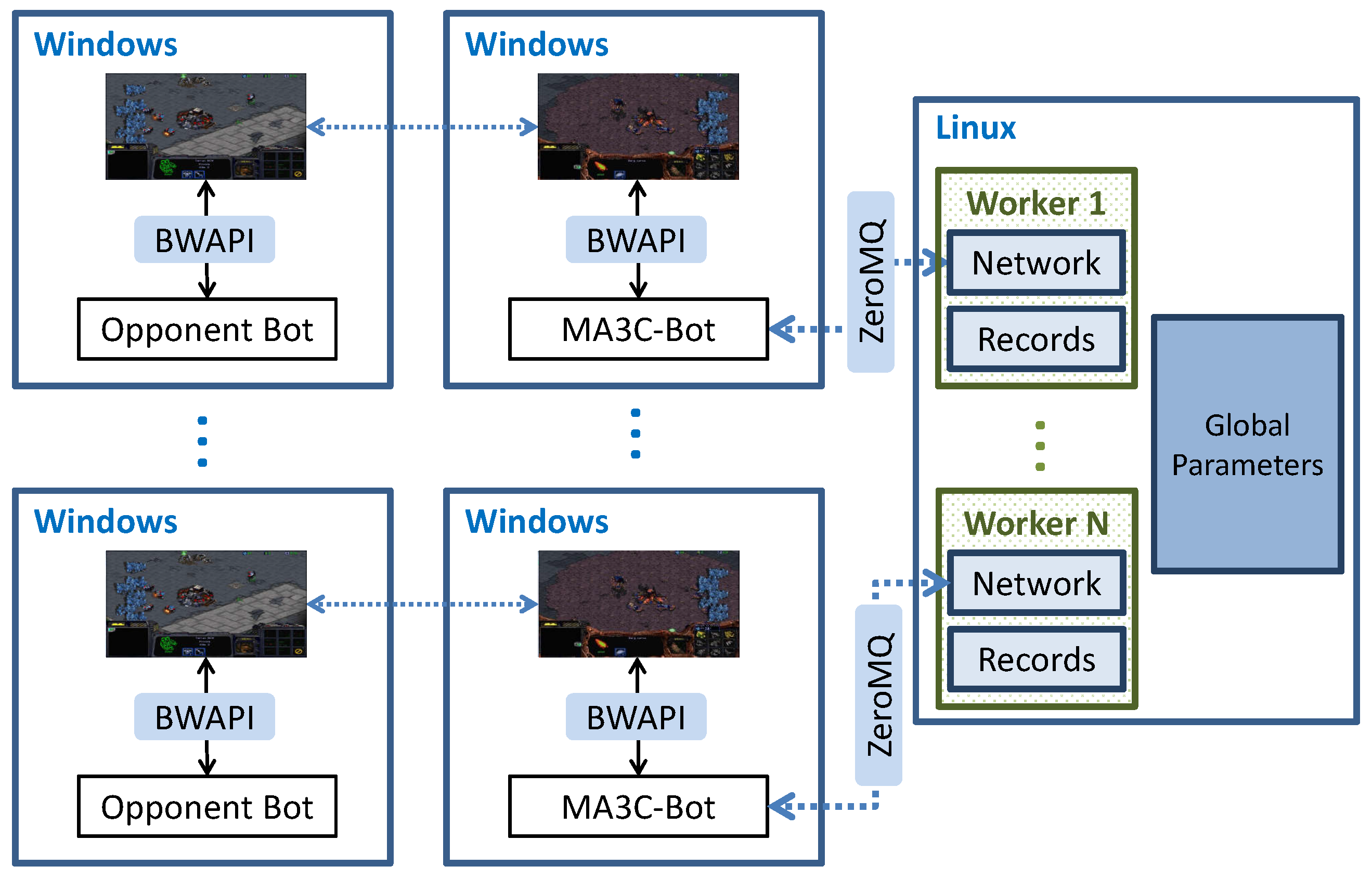
Figure 2 shows the architecture of the whole training system. The game platform, the opponent bot, and MA3C-bot run in the machines or virtual machines with Windows system, where MA3C-Bot is a bot developed to interact with our RL agent. The algorithm of MA3C that was proposed by us runs in the machine with a Linux system. They communicate with each other by using ZeroMQ (
https://zeromq.org/, accessed 10 April 2021).
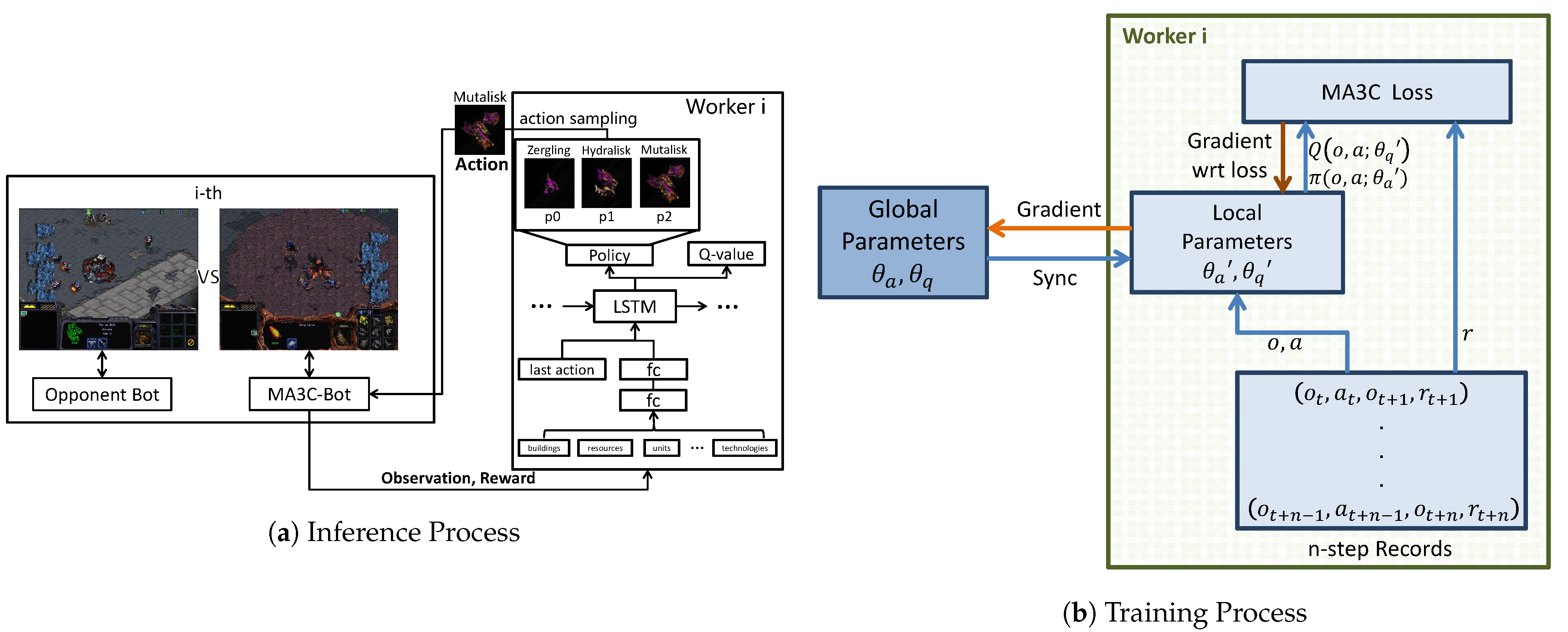
Figure 3 shows the inference and training processes of the algorithm, MA3C. Next, we will introduce this framework in details.
4.1. MA3C-Bot
MA3C-Bot uses a fixed opening strategy in the earlier period of a match. After finishing the opening build queue, the MA3C-Bot selects a kind of army unit every 24 frames and continuously produces this unit as long as the resources are enough. The selection is obtained by interacting with the RL agent. In detail, MA3C-Bot fetches the visible parts of the game state through BWAPI (
https://github.com/bwapi/bwapi/tree/v4.1.2, accessed 10 April 2021), the API for interacting with Starcraft: Broodwar. Subsequently, it sends the observation to the RL agent and receives the decision from the agent by using ZeroMQ, a high-performance asynchronous messaging library. It is noted that MA3C-Bot and the agent are running separately, which is convenient for training multiple agents in parallel.
4.2. Rewards
The rewards are kept to be 0 except when the game ends. When the bot wins, the agent gets a positive reward, ‘+1’. And when the bot loses, the agent gets a negative reward, ‘−1’. To reduce the dependence on expert knowledge, we do not introduce other rewards.
4.3. Action Space
Although macromanagement means selecting which buildings or units to produce depending on the current state, the action space in this paper does not include any buildings. Because the MA3C-Bot is not able to efficiently use the complex army units, like Queens, and it does not need to produce the relevant buildings, like Queen’s Nest. Thus, the construction of buildings mainly occurs in the earlier period. For the selection of buildings in the earlier period, we directly select a fixed opening strategy. The is because seeking a novel and useful opening strategy by RL is difficult and time-consuming. There is an enormous amount of opening strategies explored by human players, so we can easily obtain an opening strategy that is appropriate to the MA3C-Bot.
The action space is reduced to three important army units: Zergling, Hydralisk, and Mutalisk. The reduction of the action space results in the reduction of the space of feasible policy, and so the algorithm can learn the appropriate policy more efficiently.
4.4. Observations
In this problem, the main factors affecting decision-making are the number of different types of buildings, units, and resources (mineral, gas, and supply), the level of different technologies, the races of both sides, the map size, and the current time.
We encode the “discrete” features, the tech levels, and the races using the binary code. Additionally, we encode the “continuous” features using the raw value, like the map size and the number of different types of buildings, units, and resources. For continuous features, we keep the moving averages and variances and normalize the features when the RL agent obtains them from MA3C-Bot. The discrete features and normalized continuous features are concatenated as the observations and are fed to the deep neural network.
All of the features that we selected are shown in
Table 2. In the table, ‘Our
X’ or ‘Enemy
X’ means the number of the units/buildings ‘
X’ in our or enemy’s side. Additionally, ‘has
X’ means whether the buildings or technology, named ‘
X’, exist on our side. In order to enhance the scalability of our algorithm, we select all the possible units, buildings, and technologies as the futures. Even so, the dimension of features is only about 580, which would not reduce the training efficiency.
4.5. Policy Network
The RL agent can obtain full information of our side, but it cannot obtain accurate information of the opponent’s side. To solve the POMDP problem, we utilize LSTM to extract feature of the history queue, , which is combined with all observations and actions from the beginning of a match to current time. The knowledge that is extracted from the history queue can improve the precision of evaluation on the real state. Take a simple example: a number of army units of the opponent are found a few seconds ago, but then they are invisible for ’fog-of-war’. The history queue could make the agent aware of the existence of them.
More concretely, the observation vector that is received from MA3C-Bot is fed into a two-layer fully-connected network. The output, a 512-D vector, is concatenated with the last action vector and fed into an LSTM layer. The action vector is encoded using the “one-hot” coding. Subsequently, the 512-D output of LSTM is fed into two fully-connected layers, respectively. One of them outputs Q-values for all possible actions, . For the other one, a softmax function is employed and the final output is the probabilities for each action, . and share the weights of the two-layer fully-connected network and the LSTM layer. Additionally, they also contain the parameters of two output layers, respectively.
Although the network can only calculate the Q-value
and the policy
, the value of the current state can be calculated through:
4.6. Mean Asynchronous Advantage Actor-Critic
Now, we introduce how to optimize the policy net by our proposed Mean Asynchronous Advantage Actor-Critic (MA3C). One match of StarCraft takes a relatively long time, about 3–10 min., thus training the policy net would take much time. To reduce the training time, we train
N agents in parallel and update the parameters of the network using asynchronous gradient descent [
24]. Each agent runs on a separate thread, interacts with a corresponding MA3C-Bot, and has its own copy of the policy net. The parameters of the policy net are denoted as
,
. The main process saves the global shared parameters
,
. The gradients calculated in all threads would be used to update the shared parameters
,
.
MA3C uses the n-step returns to update the policy network. For computing a single update, MA3C first copies the parameters of the network from the main process and then selects actions for
n steps. The n-step Q-loss is
The term
would be used as a constant value when the algorithm takes the derivative of this loss with respect to
.
For the same current observation
and action
, the next observation
is still nondeterministic. The history queue is short in the early stage of a match, so LSTM only reduces uncertainty to a certain extent. To improve the stability of our algorithm, we replace the TD-error signal
in the Actor–Critic method with its approximate expectation on the distribution of
like [
25]. We also add the entropy of the policy to avoid it converging to a sub-optimal deterministic one. The policy gradient is
The hyperparameter is the weight of the entropy term.
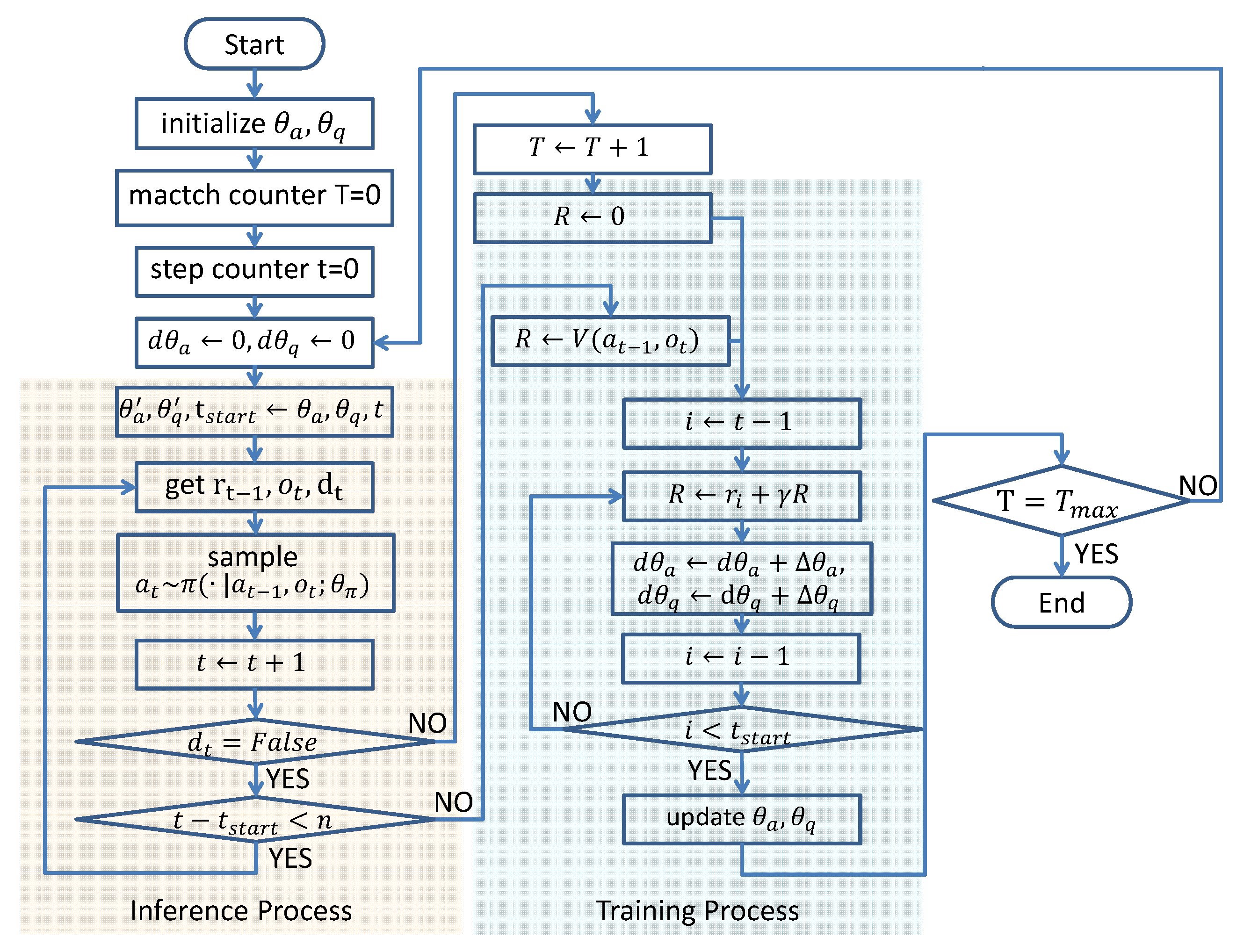
Algorithm 1 shows the complete algorithm. Additionally,
Figure 4 shows the algorithm flow chart.
| Algorithm 1. Mean Asynchronous Advantage Actor-Critic (pseudo code for each thread) |
- 1:
Assume global shared counter - 2:
Randomly initialize global shared parameter vectors , and thread-specific parameter vectors , - 3:
Initialize step counter - 4:
Set - 5:
whiledo - 6:
Set the gradients and - 7:
Set the parameter , and - 8:
Get observation - 9:
repeat - 10:
Sample according to policy - 11:
Receive reward and observation from MA3C-Bot - 12:
- 13:
until terminal or - 14:
if terminal then - 15:
- 16:
- 17:
else - 18:
- 19:
end if - 20:
for do - 21:
- 22:
//Compute the gradient of the n-step Q-loss - 23:
- 24:
//Compute the policy gradient using Equation ( 5) - 25:
- 26:
end for - 27:
Update , with and update , with - 28:
end while
|
5. Experiments
5.1. Experimental Settings
The action space contains three actions, producing three different army units: Zergling, Hydralisk, and Mutalisk. Every 24 frames, MA3C-Bot requests a decision after it finishes a fixed opening build queue, ‘10HatchMuta’. Additionally, the actions are repeatedly executed in the 24 frames if the resources are sufficient.
We select Steamhammer-1.2.3 (
http://satirist.org/ai/starcraft/steamhammer/1.2.3/, accessed 10 April 2021), an open-source StarCraft bot, as the opponent bot. It can play all three races in StarCraft and have dozens of opening build orders. As a full-featured starter bot, many bots descended from it. In order to facilitate the analysis, the opening build order of Steamhammer is fixed as the one of ‘11Rax’, ‘9HatchMain9Pool9Gas’, and ‘9PoolSpeed’. The first opening build order corresponds to the race of Terran, and the latter two correspond to the race of Zerg. In order to facilitate the description following, we name Steamhammer with the three opening strategies as ‘Steamhammer-a’, ‘Steamhammer-b’, and ‘Steamhammer-c’, respectively. For each opening build order of Steamhammer, MA3C-Bot plays 1000 matches against it in a map named ‘Benzene’. The RL model is trained during this process.
We select the random policy, randomly selecting an action from the action space, as the baseline. Besides, in order to evaluate the performance of MA3C, we make a comparison with Overkill (
https://github.com/sijiaxu/Overkill/tree/v1.2, accessed 10 April 2021), which is designed to solve the macromanagement problem by the traditional Q-learning method. In order to compare our method fairly with it and evaluate its effectiveness, Overkill has the same opening build queue and action space with MA3C-Bot.
We initialize the weights of our RL network with standard normal distribution and utilize the Adam optimizer [
35] to train it with the learning rate of 0.0001. The discount factor
is set as 0.99 to increase the weight of future rewards. The number of parallel actor-learners in this experiment is 4.
5.2. Analysis on Learned Strategies
In this section, we visualize the macromanagement that is learned by MA3C through exhibiting the trend of the values and the policies varying with time t. Subsequently, we analyze the learned macromanagement through the visualized results and the snapshots of games.
We train the MA3C agent playing against Steamhammer-a with 1000 matches and then test the agent 100 matches against Steamhammer-a. The outputs of the LSTM layer at each time are recorded as the state feature
. Subsequently, we use t-SNE [
36] to project the state feature
on a 2D space and color these projected points according to the time
t, the policy
, and the value
evaluated by MA3C, respectively.
is the output of the policy network at the time
t and it means the probabilities of selecting Zergling, Hydralisk, or Mutalisk to produce.
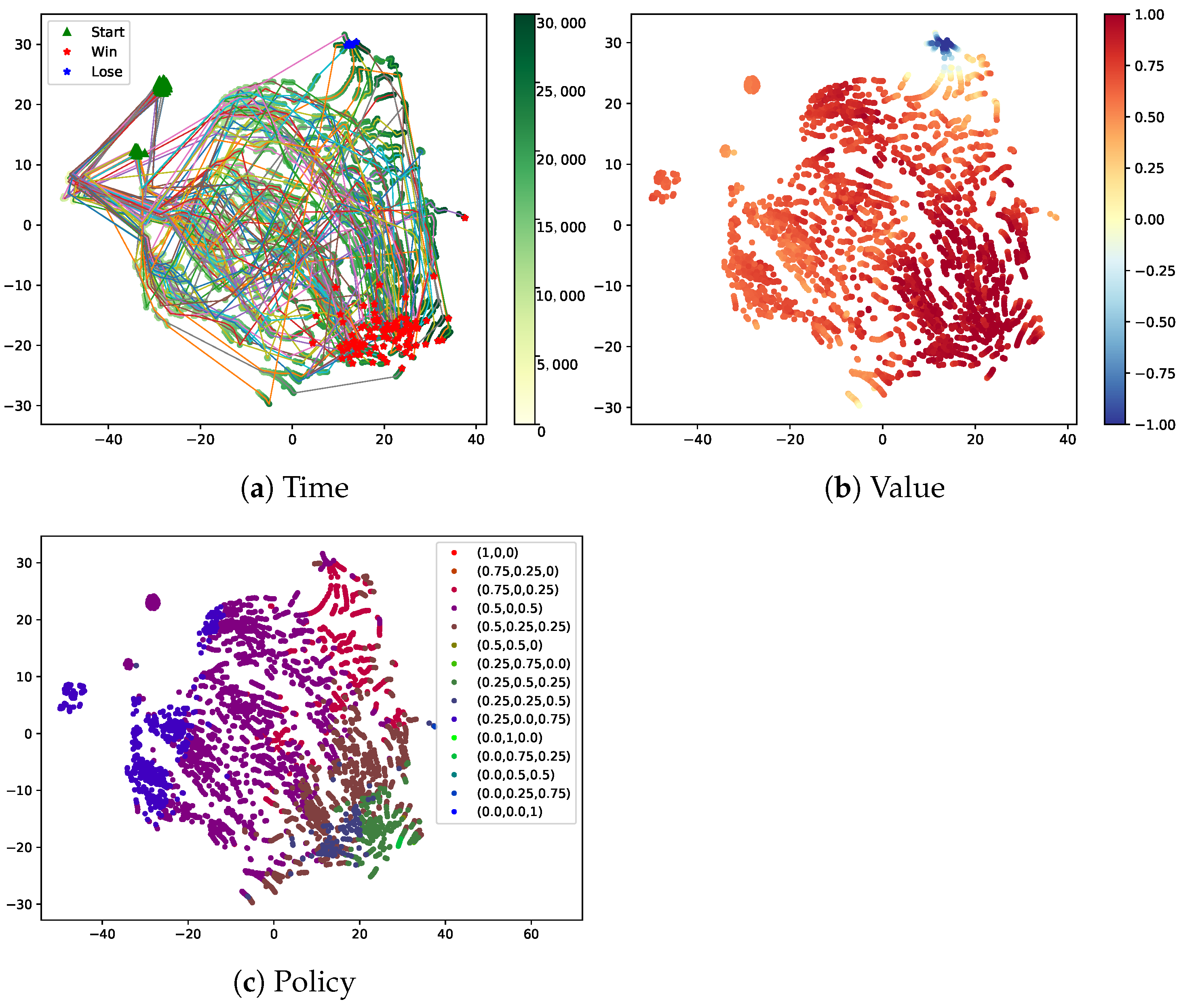
In order to facilitate the visualization, we mark the beginning states, the winning end states and losing end states as green triangles, red asterisks, and blue asterisks, respectively, and connect the points of the same match with thin lines in
Figure 5a.
For clarity, we divide all of the available policies into 15 classes and color points based on the class. We select 15 basic policy vectors, , and assign the policy to the according class based on the closest basic vector from it.
Next, we analyze the learned policies by combining the t-SNE graphics and the snapshots of games or the charts of the main army over time. While explaining the policies, we will point out the special benefit brought by MA3C.
From
Figure 5a, we can observe that the time of states is increasing from left to right. In the early stage (from 0-th to 12,000-th frame), MA3C-Bot implements the total actions in the opening strategy and then executes a few decisions made by the RL agent. The trajectories in this stage are very dense. In the medium stage (from 12,000-th to 20,000-th frame), the trajectories are loose and chaotic for the randomness of policies and the uncertainty of state transition. In the final stage (from 20,000-th to 30,000-th frame), the trajectories gather in several areas. Combined with
Figure 5b, the color of these points becomes deeper over time and the value estimations of states become more accurate. Through
Figure 5c, we observe that the policy
is changed from
to
and to the mixtures of
,
, and
. In other words, the trained agent tends to mainly produce Mutalisk in the early stage, produce Mutalisk and Zergling equitably in the middle stage, and produce each unit equitably in the final stage.
Combining with some snapshots of one match that is shown in
Figure 6, we have a better understanding of those policies mentioned in the previous paragraph. In the early stage, a few Zerglings of ours and the marines of opponent’s are locked in a face-off (
Figure 6a), while the Mutalisks attack the opponent’s relief troops (
Figure 6b). For the help of defense construction, the defensive battle is not difficult. Thus, most of the resources are used to produce Mutalisks rather than Zerglings. In the medium stage, the number of our army increases sharply and the Mutalisks’ target is changed to the opponent’s bases (
Figure 6c). The marines pull back to defeat the bases, but they are pursued by massive Zerglings (
Figure 6d). In order to effectively eliminate the marines, more Zerglings should be produced. In the final stage, there are few opponent’s army left (
Figure 6e), and our army destroys the opponent’s buildings completely (
Figure 6f). Because a few in the opponent’s army are left, any kind of army unit can be produced to destroy the opponent’s buildings. In a word, the learned macromanagement can adjust the proportion of different units to cope with the demands of tactic and resource management modules. Thus, the victory is attributed to not only the MA3C’s decision-making, but also its outstanding coordination with tactic and micromanagement modules.
Specially, there are some red points (the label of them is
) in the right upper corner of
Figure 5c, which means that the agent would change its policy in some particular situations. When combining with
Figure 5a, most of the trajectories according to these red points are ended with winning. That is to say, the agent averts failure to some extent through switching the policy to
.
In a word, the learned macromanagement is not only adapted to the game rules and the policy of the opponent bot, but it also cooperates well with the other modules of MA3C-Bot.
5.3. Results Comparison
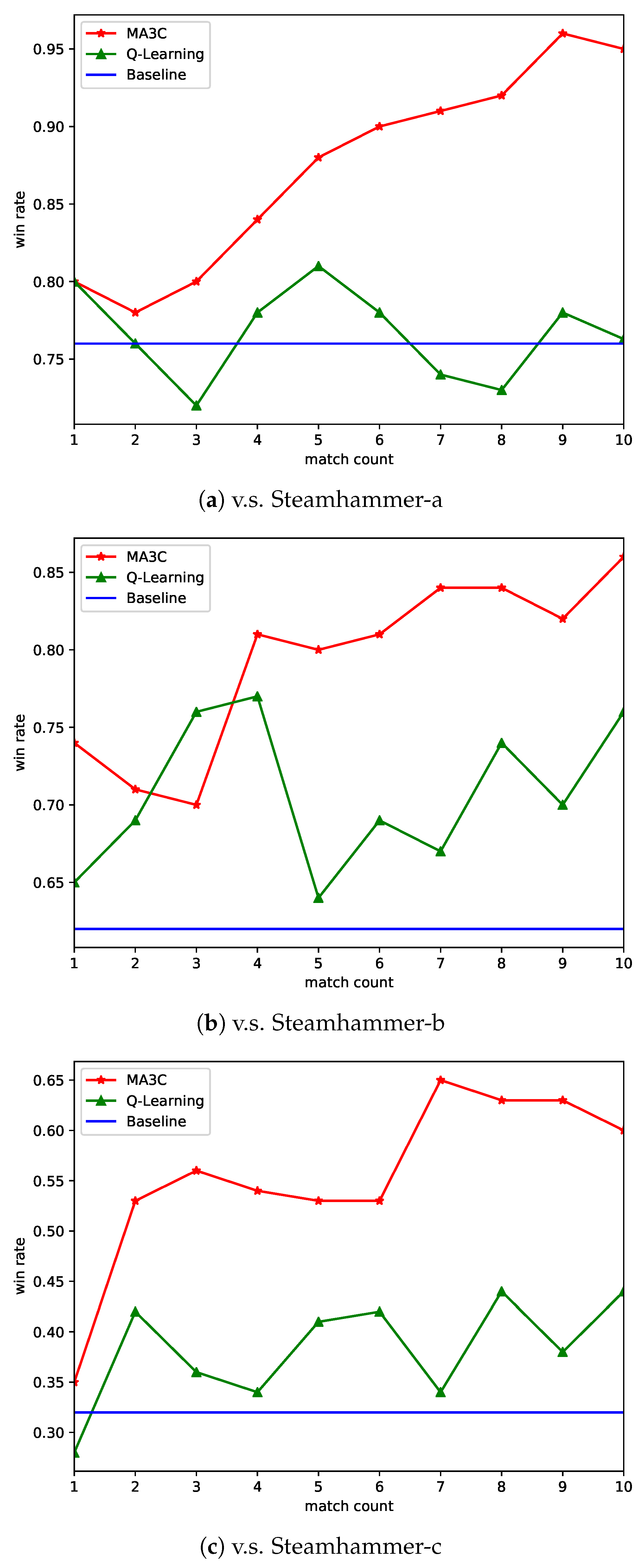
Figure 7 shows the win rates in the training processes of MA3C-bot playing against Steamhammer-a,b,c. The baseline is the win rate of Overkill with random policy playing 100 matches against Steamhammer. The baseline in three different cases are decreased from 76% to 62%, and to 32%, which means that Steamhammer-a is the weakest opponent, followed by Steamhammer-b, and the strongest is Steamhammer-c.
We record the average win rate of each 100 matches in the training procedure of MA3C and the Q-learning method implemented in Overkill. The results show that the performance of the Q-learning method is very unstable. While the win rate of our method steadily increases and it shows a tendency toward stabilization, excluding the instability of early stage. When comparing with the baseline and the Q-learning method, our method significantly improves the performance. Against the weaker two opponents, our agent achieves a very high rate of winning, approximately 90%. For the hardest case, the learned policy still improves a win rate of about 30%.
5.4. The Generalization Ability of Our Method
To evaluate the generalization ability of our method, we select a RL agent that is trained against Steanhammer-b and test it against six different Steamhammer bots. These Steamhammer bots is the same as Steanhammer-b, but the opening strategies of them are replaced with 9PoolSpeed, OverhatchLing, OverhatchMuta, OverpoolSpeedling, Overgas11Pool, and Overpool9Gas, respectively. The RL agent plays 100 matches against each Steamhammer bot, and the win rates against different bots are shown in
Table 3. We also test the random policy against these bots as the baseline.
When comparing with the baseline, the trained agent significantly improves the win rate. This result shows that the learned macromanagement can make reasonable decision for the situations that are unseen in the training process and can adapt the change of the opponent policy to a certain extent.
6. Discussion
Generally, the experimental results demonstrate that MA3C can efficiently solve the POMDP and the uncertainty problem in StarCraft, and it has high sample efficiency. The policy learned by MA3C from playing against the strong opponent can deal with the unseen opponents’ policy well to a certain extent.
The benefit from the calculation method of the policy gradient, the variance of the gradient is smaller, so the training process is more stable and efficient. The win-rate curves that are shown in
Figure 7 can confirm this point. The nearby points correspond to similar values and similar policies, but they do not always correspond to similar times, as shown in
Figure 5. This phenomenon shows that the encoder in MA3C can encode the historical observation sequence well and prepare for the subsequent processes of value estimation and behavioral decision-making. The snapshots of a match in
Figure 6 can help us to understand the reasons behind the learned policy. It is worth noting that this policy is learned through trial and error, rather than the information of other modules. Thus, when other modules are updated or replaced, it is still possible for MA3C-bot to obtain an appropriate policy through training. Although there is a cycle of restraint between strategies in the game of StarCraft, it seems that the learned policy still has a certain generalization ability, as shown in
Table 3. This means that MA3C-bot has learned some general decisions to deal with the states that it has never seen before.
However, the algorithm MA3C also has several disadvantages: firstly, the effectiveness of Equation (
5) is related to the accuracy of the Q-value estimation. When the biases of the estimated Q-values and the real values are large, the policy gradient that is computed by MA3C would have greater bias than the one computed by the original A3C. Secondly, the exploration ability of MA3C is limited. If the capacity of the opponent bot is very highly capable, the macromanagement task would be hard and the learned policy would be extremely complex. In this case, the exploration ability provided by entropy regularization is difficult to assist MA3C to learn the appropriate policy.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}