Deep-Learning-Based Indoor Human Following of Mobile Robot Using Color Feature



Abstract
1. Introduction
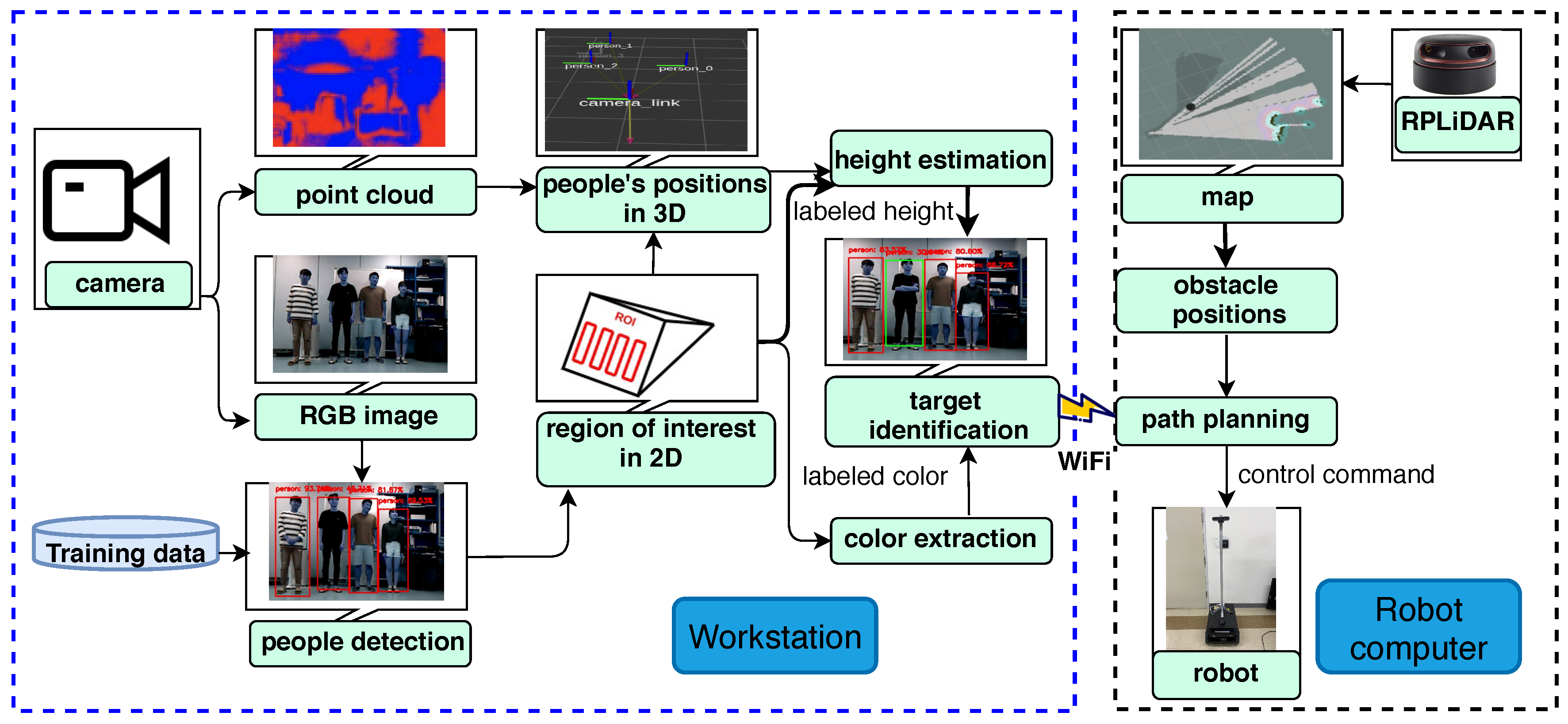
2. Human Following of Mobile Robot
2.1. Initialization State
2.2. Tracking State
2.2.1. Human Detection
2.2.2. Color Feature
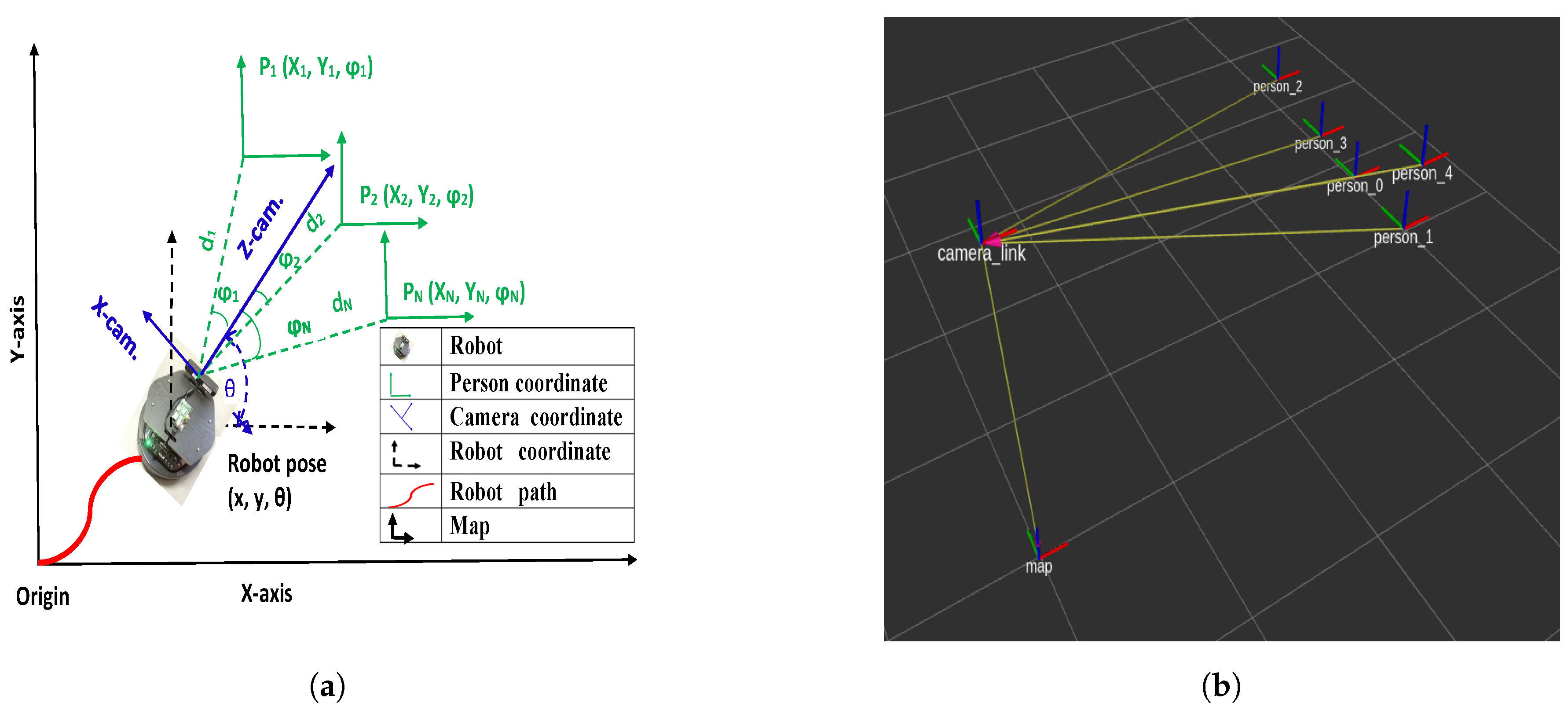
2.2.3. Depth Image and Estimating the Distance
2.3. Last Observed Position State
2.4. Searching State
3. Robot Controller
4. Results and Discussion
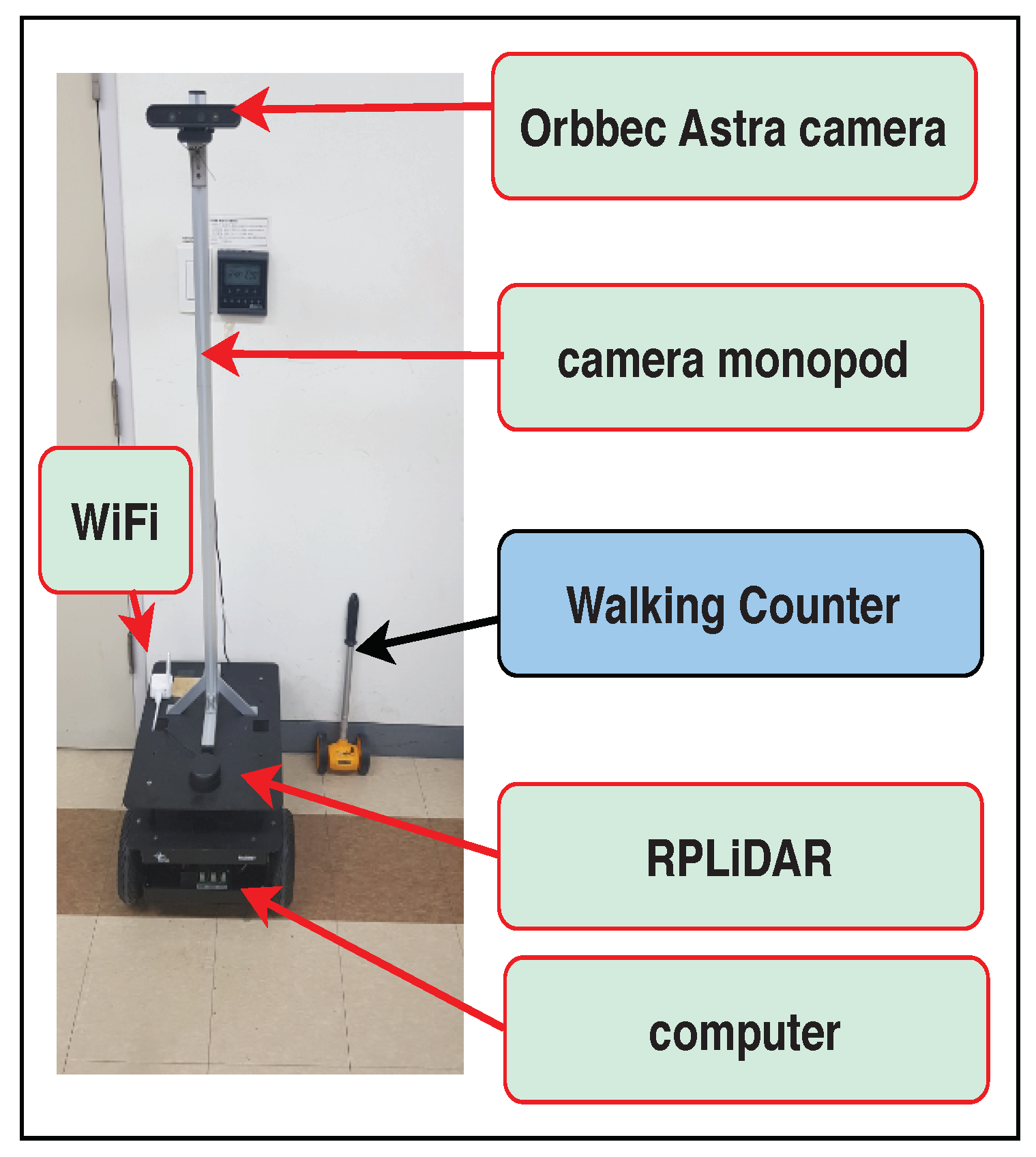
4.1. Infrastructure Setting
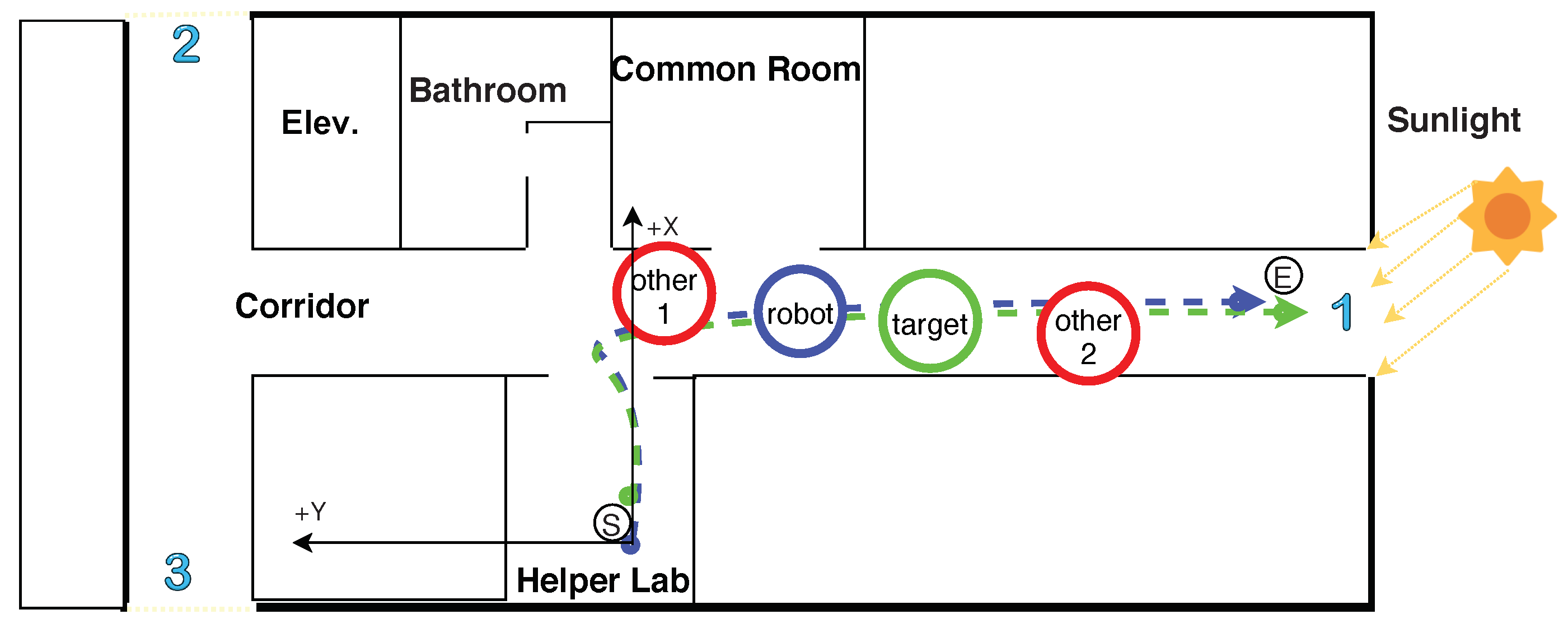
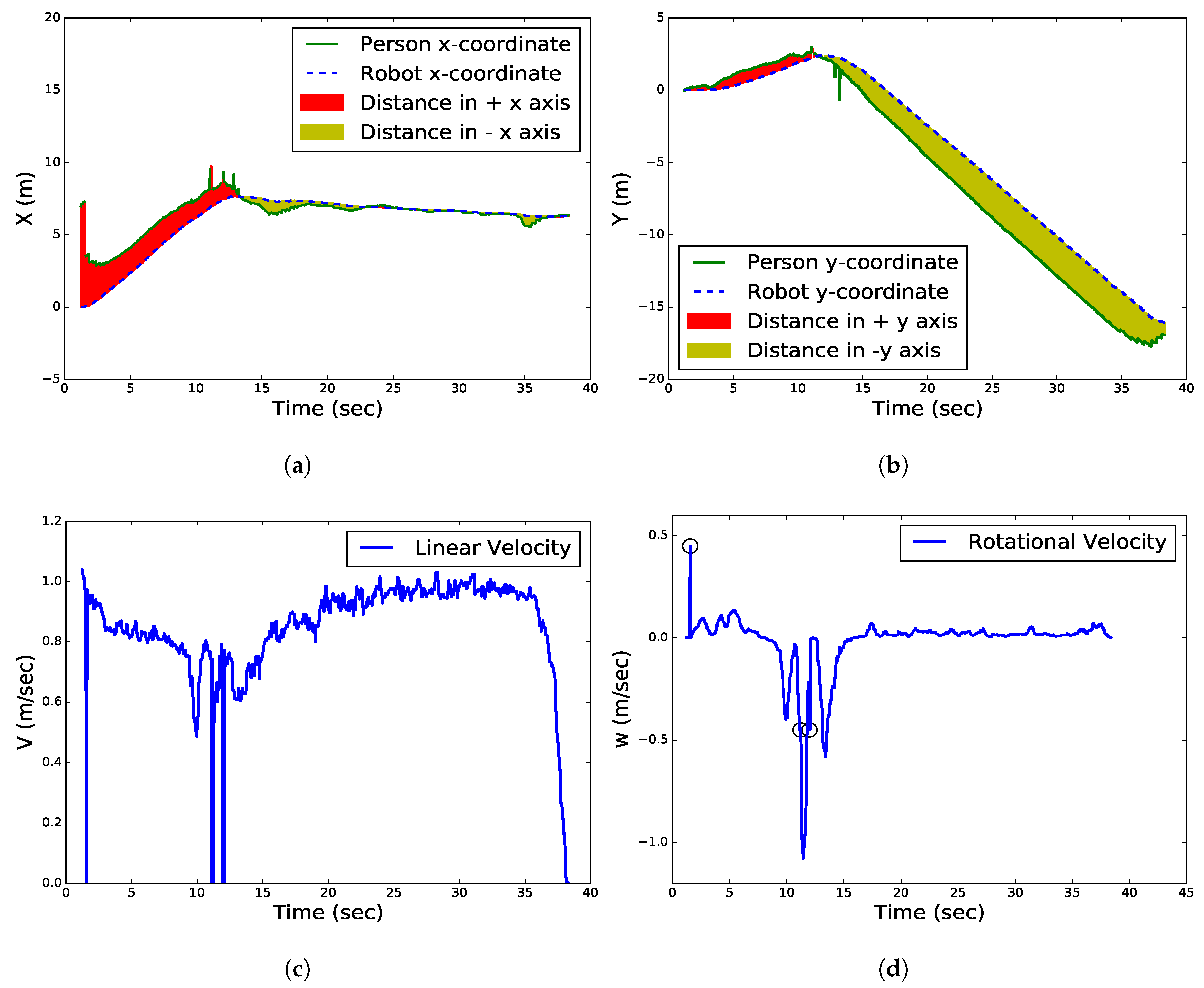
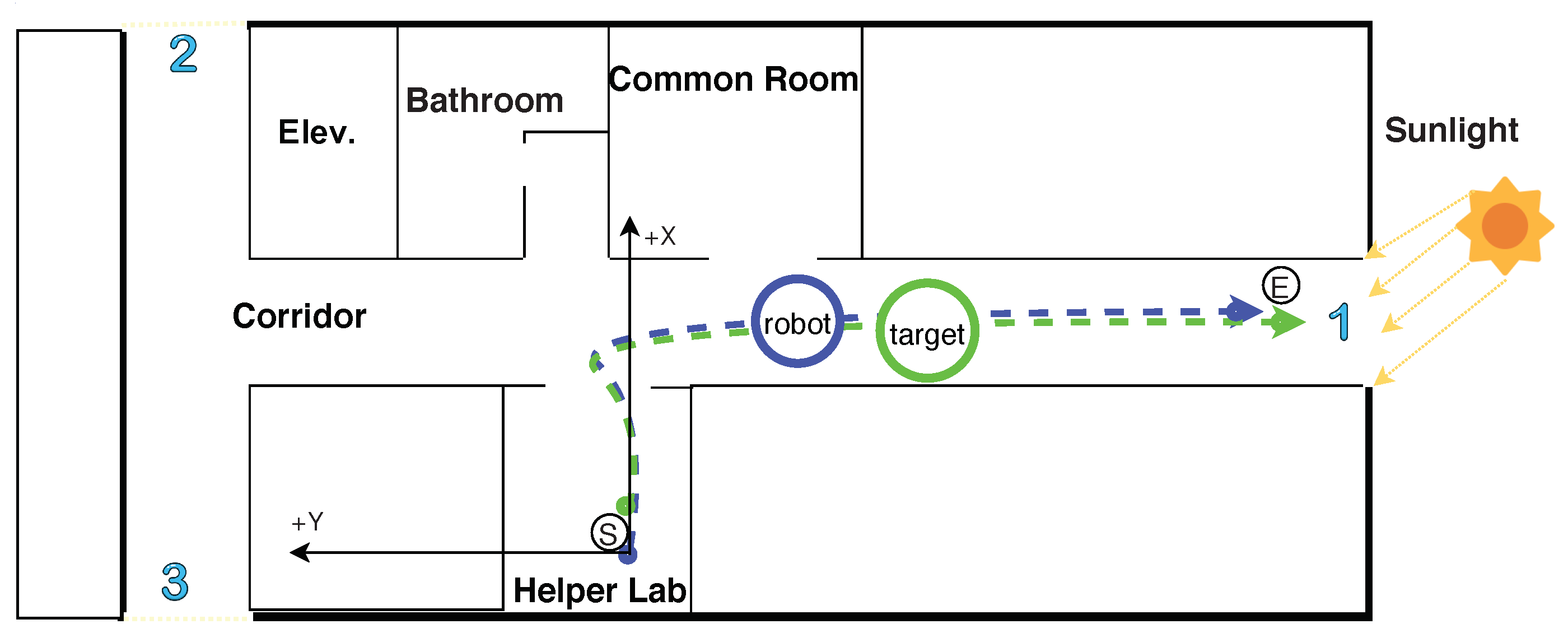
4.2. Human Following Experiments
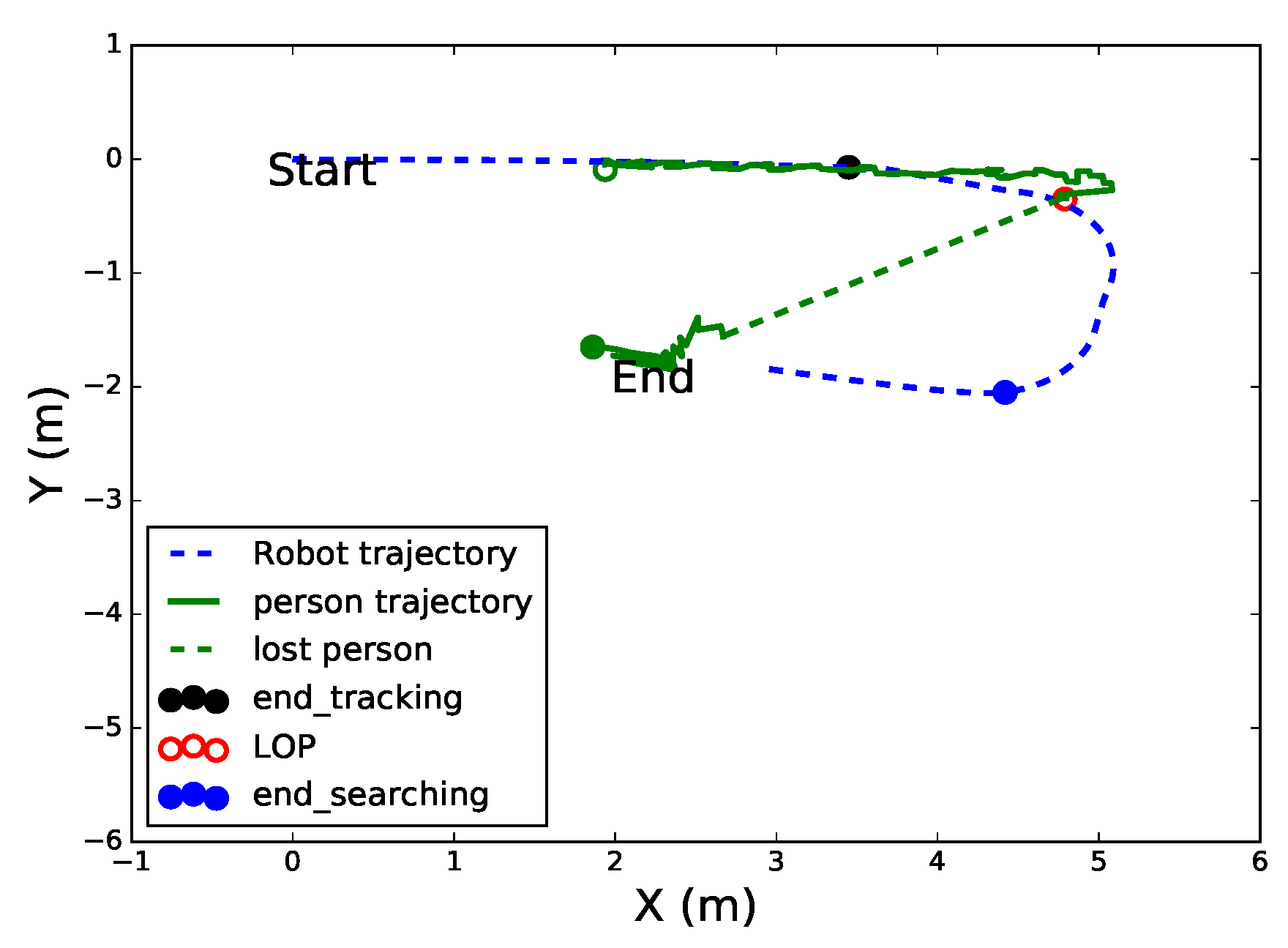
4.3. Target Recovery Experiments
4.4. Comparison with Previous Approaches
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| FRP | Freezing Robot Problem |
| RGB-D | Red, Green, Blue-Depth |
| HSV | Hue, Saturation, and Value |
| FoV | Field of View |
| SSD | Single Shot Detector |
| GPU | Graphics Processing Unit |
| CPU | Central Processing Unit |
| LOP | Last Observed Position |
| SLAM | Simultaneous Localization and Mapping |
| ROS | Robot Operating System |
| CNNs | Convolutional Neural Networks |
| YOLO | You Only Look Once |
| R-CNN | Regions with Convolutional Neural Network |
| SIFT | Scale Invariant Feature Transformation |
| HOG | Histograms of Oriented Gradient |
| ROI | Region of Interest |
| PID | Proportional Integral Derivative |
| WC | Walking Counter |
| Exp. | Experiment |
| Elev. | Elevator |
| lab | Laboratory |
| ADHD | Attention-Deficit Hyperactivity Disorder |
| fps | Frame per Second |
References
- Triebel, R.; Arras, K.; Alami, R.; Beyer, L.; Breuers, S.; Chatila, R.; Chetouani, M.; Cremers, D.; Evers, V.; Fiore, M.; et al. Spencer: A Socially Aware Service Robot for Passenger Guidance and Help in Busy Airports; Field and Service Robotics; Springer: Berlin, Germany, 2016; pp. 607–622. [Google Scholar]
- Tomoya, A.; Nakayama, S.; Hoshina, A.; Sugaya, M. A mobile robot for following, watching and detecting falls for elderly care. Procedia Comput. Sci. 2017, 112, 1994–2003. [Google Scholar] [CrossRef]
- Janai, J.; Güney, F.; Behl, A.; Geiger, A. Computer vision for autonomous vehicles: Problems, datasets and state-of-the-art. arXiv 2017, arXiv:1704.05519. [Google Scholar]
- Mabrouk, A.B.; Zagrouba, E. Abnormal behavior recognition for intelligent video surveillance systems: A review. Expert Syst. Appl. 2018, 91, 480–491. [Google Scholar] [CrossRef]
- Thomas, G.; Gade, R.; Moeslund, T.B.; Carr, P.; Hilton, A. Computer vision for sports: Current applications and research topics. Comput. Vis. Image Underst. 2017, 159, 3–18. [Google Scholar] [CrossRef]
- Trautman, P.; Ma, J.; Murray, R.M.; Krause, A. Robot navigation in dense human crowds: Statistical models and experimental studies of human–robot cooperation. Int. J. Robot. Res. 2015, 34, 335–356. [Google Scholar] [CrossRef]
- Schlegel, C.; Illmann, J.; Jaberg, H.; Schuster, M.; Wörz, R. Vision Based Person Tracking with a Mobile Robot; BMVC: London, UK, 1998; pp. 1–10. [Google Scholar]
- An, N.; Sun, S.Y.; Zhao, X.G.; Hou, Z.G. Online context-based person re-identification and biometric-based action recognition for service robots. In Proceedings of the 2017 29th Chinese Control And Decision Conference (CCDC), Istanbul, Turkey, 12–15 October 2017; pp. 3369–3374. [Google Scholar]
- Bellotto, N.; Hu, H. Multisensor-based human detection and tracking for mobile service robots. IEEE Trans. Syst. Man Cybern. Part B 2008, 39, 167–181. [Google Scholar] [CrossRef]
- Choi, M.T.; Yeom, J.; Shin, Y.; Park, I. Robot-Assisted ADHD Screening in Diagnostic Process. J. Intell. Robot. Syst. 2019, 95, 351–363. [Google Scholar] [CrossRef]
- Li, H.; Zhao, Q.; Li, X.; Zhang, X. Object detection based on color and shape features for service robot in semi-structured indoor environment. Int. J. Intell. Robot. Appl. 2019, 3, 430–442. [Google Scholar] [CrossRef]
- Ren, Q.; Zhao, Q.; Qi, H.; Li, L. Real-time target tracking system for person-following robot. In Proceedings of the 2016 35th Chinese Control Conference (CCC), Chengdu, China, 27–29 July 2016; pp. 6160–6165. [Google Scholar]
- Gupta, M.; Kumar, S.; Behera, L.; Subramanian, V.K. A novel vision-based tracking algorithm for a human-following mobile robot. IEEE Trans. Syst. Man Cybern. Syst. 2016, 47, 1415–1427. [Google Scholar] [CrossRef]
- Gross, H.M.; Scheidig, A.; Debes, K.; Einhorn, E.; Eisenbach, M.; Mueller, S.; Schmiedel, T.; Trinh, T.Q.; Weinrich, C.; Wengefeld, T.; et al. ROREAS: robot coach for walking and orientation training in clinical post-stroke rehabilitation—Prototype implementation and evaluation in field experiments. Auton. Robot. 2017, 41, 679–698. [Google Scholar] [CrossRef]
- Oishi, S.; Kohari, Y.; Miura, J. Toward a robotic attendant adaptively behaving according to human state. In Proceedings of the 2016 25th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), New York, NY, USA, 26–31 August 2016; pp. 1038–1043. [Google Scholar]
- Ferrer, G.; Zulueta, A.G.; Cotarelo, F.H.; Sanfeliu, A. Robot social-aware navigation framework to accompany people walking side-by-side. Auton. Robot. 2017, 41, 775–793. [Google Scholar] [CrossRef]
- Koide, K.; Miura, J. Identification of a specific person using color, height, and gait features for a person following robot. Robot. Auton. Syst. 2016, 84, 76–87. [Google Scholar] [CrossRef]
- Brunetti, A.; Buongiorno, D.; Trotta, G.F.; Bevilacqua, V. Computer vision and deep learning techniques for pedestrian detection and tracking: A survey. Neurocomputing 2018, 300, 17–33. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019. [Google Scholar] [CrossRef]
- Kim, P.; Chen, J.; Cho, Y.K. SLAM-driven robotic mapping and registration of 3D point clouds. Autom. Constr. 2018, 89, 38–48. [Google Scholar] [CrossRef]
- Abdelwhab, A.; Viriri, S. A survey on soft biometrics for human identification. Mach. Learn. Biom. 2018. [Google Scholar] [CrossRef]
- Rusu, R.B.; Cousins, S. 3d is here: Point cloud library (pcl). In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar]
- Balsa-Comerón, J.; Guerrero-Higueras, Á.M.; Rodríguez-Lera, F.J.; Fernández-Llamas, C.; Matellán-Olivera, V. Cybersecurity in Autonomous Systems: Hardening ROS Using Encrypted Communications and Semantic Rules; Iberian Robotics Conference; Springer: Berlin, Germany, 2017; pp. 67–78. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single Shot Multibox Detector; European Conference on Computer Vision; Springer: Berlin, Germany, 2016; pp. 21–37. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Munaro, M.; Menegatti, E. Fast RGB-D people tracking for service robots. Auton. Robot. 2014, 37, 227–242. [Google Scholar] [CrossRef]
- Lowe, D.G. Object Recognition From Local Scale-Invariant Features; ICCV: Piscataway, PA, USA, 1999; Volume 99, pp. 1150–1157. [Google Scholar]
- Satake, J.; Chiba, M.; Miura, J. Visual person identification using a distance-dependent appearance model for a person following robot. Int. J. Autom. Comput. 2013, 10, 438–446. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Cheng, X.; Jia, Y.; Su, J.; Wu, Y. Person-following for Telepresence Robots Using Web Cameras. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 2096–2101. [Google Scholar]
- Jangbari, P.; Patel, D. Review on region of interest coding techniques for medical image compression. Int. J. Comput. Appl. 2016, 134, 1–5. [Google Scholar] [CrossRef]
- Kim, M.; Arduengo, M.; Walker, N.; Jiang, Y.; Hart, J.W.; Stone, P.; Sentis, L. An architecture for person-following using active target search. arXiv 2018, arXiv:1809.08793. [Google Scholar]
- Zisserman, R.H.A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Henry, P.; Krainin, M.; Herbst, E.; Ren, X.; Fox, D. RGB-D mapping: Using Kinect-style depth cameras for dense 3D modeling of indoor environments. Int. J. Rob. Res. 2012, 31, 647–663. [Google Scholar] [CrossRef]
- Geng, J. Structured-light 3D surface imaging: A tutorial. Adv. Opt. Photonics 2011, 3, 128–160. [Google Scholar] [CrossRef]
- Foote, T. tf: The transform library. In Proceedings of the 2013 IEEE Conference on Technologies for Practical Robot Applications (TePRA), Woburn, MA, USA, 22–23 April 2013; pp. 1–6. [Google Scholar]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved techniques for grid mapping with rao-blackwellized particle filters. IEEE Trans. Robot. 2007, 23, 34. [Google Scholar] [CrossRef]
- O’Dwyer, A. Handbook of PI and PID Controller Tuning Rules; Imperial College Press: London, UK, 2009. [Google Scholar]
- Lee, B.J.; Choi, J.; Baek, C.; Zhang, B.T. Robust Human Following by Deep Bayesian Trajectory Prediction for Home Service Robots. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7189–7195. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Exp. 1 | Exp. 2 | Exp. 3 | Exp. 4 | Exp. 5 | Exp. 6 | Exp. 7 |
|---|---|---|---|---|---|---|---|
| Mission success rate (%) | O | O | O | O | O | O | x |
| Target’s travel distance (m) | 28.06 | 27.93 | 28.08 | 28.42 | 27.97 | 27.74 | 0.00 |
| Robot’s travel distance (m) | 25.77 | 26.95 | 26.86 | 27.65 | 26.88 | 26.46 | 18.58 |
| Robot’s travel time (s) | 44.28 | 42.16 | 43.44 | 45.68 | 42.18 | 42.39 | 68.96 |
| Robot’s average velocity (m/s) | 0.58 | 0.64 | 0.62 | 0.61 | 0.64 | 0.62 | 0.27 |
| # of frames | 1042 | 1024 | 1022 | 1120 | 932 | 992 | 1507 |
| Successfully tracked (frames) | 1030 | 997 | 1010 | 1108 | 928 | 982 | 679 |
| Lost track of the target (frames) | 12 | 27 | 12 | 12 | 4 | 10 | 828 |
| Successfully tracked (s) | 43.77 | 41.04 | 42.93 | 45.19 | 42.00 | 41.96 | 31.07 |
| Lost track of the target (s) | 0.51 | 1.11 | 0.51 | 0.49 | 0.18 | 0.43 | 37.89 |
| Lost track of the target rate (%) | 1.2 | 2.6 | 1.2 | 1.1 | 0.4 | 1.0 | 54.9 |
| Successful tracking rate (%) | 98.8 | 97.4 | 98.8 | 98.9 | 99.6 | 99.0 | 45.1 |
| Computation time (fps) | 23.53 | 24.29 | 23.53 | 24.52 | 22.10 | 23.40 | 21.85 |
| Parameters | Exp. 8 | Exp. 9 | Exp. 10 | Exp. 11 | Exp. 12 | Exp. 13 | Exp. 14 |
| Mission success rate (%) | x | O | O | O | O | O | O |
| Target’s travel distance (m) | 0.00 | 27.93 | 27.37 | 27.40 | 28.79 | 27.85 | 28.05 |
| Robot’s travel distance (m) | 10.94 | 27.08 | 26.43 | 25.89 | 27.21 | 26.45 | 25.82 |
| Robot’s travel time (s) | 39.93 | 44.53 | 44.27 | 41.22 | 42.82 | 44.58 | 42.90 |
| Robot’s average velocity (m/s) | 0.27 | 0.61 | 0.60 | 0.63 | 0.64 | 0.59 | 0.60 |
| # of frames | 961 | 1042 | 987 | 999 | 1026 | 1017 | 991 |
| Successfully tracked (frames) | 479 | 969 | 983 | 994 | 994 | 941 | 973 |
| Lost track of the target (frames) | 482 | 73 | 4 | 5 | 32 | 76 | 18 |
| Successfully tracked (s) | 19.90 | 41.41 | 44.09 | 41.01 | 41.48 | 41.25 | 42.12 |
| Lost track of the target (s) | 20.03 | 3.12 | 0.18 | 0.21 | 1.34 | 3.33 | 0.78 |
| Lost track of the target | 50.2 | 7.0 | 0.4 | 0.5 | 3.1 | 7.5 | 1.8 |
| Successful tracking rate (%) | 49.8 | 93.0 | 99.6 | 99.5 | 96.9 | 92.5 | 98.2 |
| Computation time (fps) | 24.07 | 23.40 | 22.29 | 24.24 | 23.96 | 22.81 | 23.10 |
| Parameters | Exp. 15 | Exp. 16 | Exp. 17 | Exp. 18 | Total | Average | Std |
| Mission success rate (%) | O | O | O | O | 88.9% | - | - |
| Target’s travel distance (m) | 26.68 | 28.17 | 28.08 | 26.37 | 444.89 | 24.72 | 9.01 |
| Robot’s travel distance (m) | 25.80 | 26.83 | 25.35 | 23.86 | 450.80 | 25.04 | 4.06 |
| Robot’s travel time (s) | 44.06 | 42.15 | 41.72 | 39.87 | 797.12 | 44.28 | 6.36 |
| Robot’s average velocity (m/s) | 0.59 | 0.64 | 0.61 | 0.60 | - | 0.57 | 0.11 |
| # of frames | 984 | 1029 | 940 | 948 | 18,563.0 | 1031.3 | 126.78 |
| Successfully tracked (frames) | 956 | 1003 | 923 | 908 | 16,857.0 | 936.5 | 141.83 |
| Lost track of the target (frames) | 28 | 26 | 17 | 40 | 1706.0 | 94.8 | 213.28 |
| Successfully tracked (s) | 42.81 | 41.09 | 40.96 | 38.18 | 722.27 | 40.13 | 5.86 |
| Lost track of the target (s) | 1.25 | 1.07 | 0.75 | 1.68 | 74.85 | 4.16 | 9.57 |
| Lost track of the target | 2.8 | 2.5 | 1.8 | 4.2 | - | 8.02 | 0.16 |
| Successful tracking rate (%) | 97.2 | 97.5 | 98.2 | 95.8 | - | 91.98 | 0.16 |
| Computation time (fps) | 22.33 | 24.41 | 22.53 | 23.78 | - | 23.34 | 0.85 |
| Parameters | Exp. 1 | Exp. 2 | Exp. 3 | Exp. 4 | Exp. 5 | Exp. 6 | Exp. 7 |
|---|---|---|---|---|---|---|---|
| Mission success rate (%) | O | O | O | O | O | O | x |
| Target’s travel distance (m) | 32.931 | 27.401 | 28.906 | 28.005 | 30.94 | 28.819 | 0.00 |
| Robot’s travel distance (m) | 30.152 | 26.649 | 27.455 | 27.162 | 27.931 | 27.522 | 14.641 |
| Robot’s travel time (s) | 77.567 | 52.433 | 64.566 | 61.687 | 71.067 | 62.706 | 44.984 |
| Robot’s average velocity (m/s) | 0.39 | 0.51 | 0.43 | 0.44 | 0.39 | 0.44 | 0.33 |
| # of frames | 1699 | 1341 | 1537 | 1537 | 1913 | 1502 | 1153 |
| Successfully tracked (frames) | 1280 | 805 | 624 | 727 | 663 | 840 | 214 |
| Lost track of the target (frames) | 419 | 536 | 913 | 810 | 1250 | 662 | 939 |
| Successfully tracked (s) | 58.438 | 31.475 | 26.213 | 29.178 | 24.630 | 35.069 | 8.349 |
| Lost track of the target (s) | 19.129 | 20.958 | 38.353 | 32.509 | 46.437 | 27.637 | 36.635 |
| Lost track of the target rate (%) | 0.25 | 0.40 | 0.59 | 0.53 | 0.65 | 0.44 | 0.81 |
| Successful tracking rate (%) | 0.75 | 0.60 | 0.41 | 0.47 | 0.35 | 0.56 | 0.19 |
| Computation time (fps) | 21.90 | 25.58 | 23.81 | 24.92 | 26.92 | 23.95 | 25.63 |
| Parameters | Exp. 8 | Exp. 9 | Exp. 10 | Exp. 11 | Total | Average | Std |
| Mission success rate (%) | O | O | O | O | 90.91% | - | - |
| Target’s travel distance (m) | 28.562 | 27.287 | 27.164 | 26.977 | 286.992 | 26.09 | 8.84 |
| Robot’s travel distance (m) | 27.435 | 26.492 | 26.345 | 26.214 | 287.998 | 26.18 | 3.98 |
| Robot’s travel time (s) | 71.974 | 59.975 | 51.331 | 55.327 | 673.617 | 61.24 | 9.84 |
| Robot’s average velocity (m/s) | 0.38 | 0.44 | 0.51 | 0.47 | - | 0.43 | 0.06 |
| # of frames | 1309 | 1333 | 1142 | 1096 | 15562 | 1414.73 | 251.87 |
| Successfully tracked (frames) | 1043 | 833 | 924 | 863 | 8816 | 801.45 | 266.45 |
| Lost track of the target (frames) | 266 | 500 | 218 | 233 | 6746 | 613.27 | 334.73 |
| Successfully tracked (s) | 57.348 | 37.479 | 41.532 | 43.565 | 393.276 | 35.75 | 14.51 |
| Lost track of the target (s) | 14.626 | 22.496 | 9.799 | 11.762 | 280.341 | 25.49 | 11.85 |
| Lost track of the target rate (%) | 0.20 | 0.38 | 0.19 | 0.21 | - | 0.42 | 0.21 |
| Successful tracking rate (%) | 0.80 | 0.62 | 0.81 | 0.79 | - | 0.58 | 0.21 |
| Computation time (fps) | 18.19 | 22.23 | 22.25 | 19.81 | - | 23.20 | 2.63 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Algabri, R.; Choi, M.-T. Deep-Learning-Based Indoor Human Following of Mobile Robot Using Color Feature. Sensors 2020, 20, 2699. https://doi.org/10.3390/s20092699
Algabri R, Choi M-T. Deep-Learning-Based Indoor Human Following of Mobile Robot Using Color Feature. Sensors. 2020; 20(9):2699. https://doi.org/10.3390/s20092699
Chicago/Turabian StyleAlgabri, Redhwan, and Mun-Taek Choi. 2020. "Deep-Learning-Based Indoor Human Following of Mobile Robot Using Color Feature" Sensors 20, no. 9: 2699. https://doi.org/10.3390/s20092699
APA StyleAlgabri, R., & Choi, M.-T. (2020). Deep-Learning-Based Indoor Human Following of Mobile Robot Using Color Feature. Sensors, 20(9), 2699. https://doi.org/10.3390/s20092699