Implicit Stochastic Gradient Descent Method for Cross-Domain Recommendation System



Abstract
1. Introduction
- We propose an efficient framework for a cross-domain recommendation system based on a constrained optimization model. In our model, the optimal solution and computation time are simultaneously taken into consideration.
- We devise an approximation algorithm that is suitable for objective function optimization in a cross-domain related problem. In particular, an implicit updating technique is applied to improve convergence time.
- We conduct extensive experiments on two real-world datasets to validate the effectiveness and efficiency of our method. The results demonstrate that the proposed framework can achieve better performance in comparison with the previous approach.
2. Related Work and Background
2.1. Related Work
2.2. Background
3. Problem Formulation
3.1. Definition of User-Preference Matrix
3.2. Algorithm for Prediction Error Minimization
| Algorithm 1: Iterative algorithm for the prediction error optimization. |
| 1 Initialization: Set := +∞, := |
| 2 for each k {solving subproblem (19)} |
| 3 Generating an initial points: Set k:= 0 and solve (20) to generate (). |
| 4 repeat |
| 5 Solve (21) to obtain () and . |
| 6 Update ():=(). |
| 7 Set . |
| 8 until Convergence |
| 9 if |
| 10 Update := and ():=(). |
| 11 end if |
| 12 end for |
4. CDRS Framework
5. Experiments
5.1. Dataset
5.2. Evaluation Metric
5.3. Baseline
5.4. Experiment Parameters
5.5. Evaluation and Discussions
6. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Ricci, F.; Rokach, L.; Shapira, B. Introduction to recommender systems handbook. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2011; pp. 1–35. [Google Scholar] [CrossRef]
- Huang, Z.; Chen, H.; Zeng, D.D. Applying associative retrieval techniques to alleviate the sparsity problem in collaborative filtering. ACM Trans. Inf. Syst. 2004, 22, 116–142. [Google Scholar] [CrossRef]
- Lika, B.; Kolomvatsos, K.; Hadjiefthymiades, S. Facing the cold start problem in recommender systems. Expert Syst. Appl. 2014, 41, 2065–2073. [Google Scholar] [CrossRef]
- Li, X.; Wang, M.; Liang, T. A multi-theoretical kernel-based approach to social network-based recommendation. Decis. Support Syst. 2014, 65, 95–104. [Google Scholar] [CrossRef]
- Li, Y.; Wu, C.; Lai, C. A social recommender mechanism for e-commerce: Combining similarity, trust, and relationship. Decis. Support Syst. 2013, 55, 740–752. [Google Scholar] [CrossRef]
- McAuley, J.J.; Yang, A. Addressing Complex and Subjective Product-Related Queries with Customer Reviews. In Proceedings of the 25th International Conference on World Wide Web (WWW 2016), Montreal, QC, Canada, 11–15 April 2016; Bourdeau, J., Hendler, J., Nkambou, R., Horrocks, I., Zhao, B.Y., Eds.; ACM: Montreal, QC, Canada, 2016; pp. 625–635. [Google Scholar] [CrossRef]
- Hong, M.; Jung, J.J. Multi-Sided recommendation based on social tensor factorization. Inf. Sci. 2018, 447, 140–156. [Google Scholar] [CrossRef]
- Fernández-Tobías, I.; Cantador, I.; Kaminskas, M.; Ricci, F. Cross-domain recommender systems: A survey of the state of the art. In Spanish Conference on Information Retrieval; ACM: Valencia, Spain, 2012; pp. 1–12. [Google Scholar]
- Cremonesi, P.; Tripodi, A.; Turrin, R. Cross-Domain Recommender Systems. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining Workshops (ICDMW), Vancouver, BC, Canada, 11 December 2011; Spiliopoulou, M., Wang, H., Cook, D.J., Pei, J., Wang, W., Zaïane, O.R., Wu, X., Eds.; IEEE Computer Society: Vancouver, BC, Canada, 2011; pp. 496–503. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R.M.; Volinsky, C. Matrix Factorization Techniques for Recommender Systems. IEEE Comput. 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Cantador, I.; Cremonesi, P. Tutorial on cross-domain recommender systems. In Proceedings of the Eighth ACM Conference on Recommender Systems (RecSys ’14), Foster City, Silicon Valley, CA, USA, 6–10 October 2014; Kobsa, A., Zhou, M.X., Ester, M., Koren, Y., Eds.; ACM: Foster City, CA, USA, 2014; pp. 401–402. [Google Scholar] [CrossRef]
- Zhang, Q.; Lu, J.; Wu, D.; Zhang, G. A Cross-Domain Recommender System With Kernel-Induced Knowledge Transfer for Overlapping Entities. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 1998–2012. [Google Scholar] [CrossRef]
- Lu, J.; Behbood, V.; Hao, P.; Zuo, H.; Xue, S.; Zhang, G. Transfer learning using computational intelligence: A survey. Knowl. Based Syst. 2015, 80, 14–23. [Google Scholar] [CrossRef]
- Pan, W. A survey of transfer learning for collaborative recommendation with auxiliary data. Neurocomputing 2016, 177, 447–453. [Google Scholar] [CrossRef]
- Zhao, L.; Pan, S.J.; Yang, Q. A unified framework of active transfer learning for cross-system recommendation. Artif. Intell. 2017, 245, 38–55. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, J.; Gao, J.; Hu, S.; Sun, H.; Wang, Y. Cross-Domain Recommendation System Based on Tensor Decomposition for Cybersecurity Data Analytics. In Proceedings of the Second International Conference on Science of Cyber Security (SciSec 2019), Nanjing, China, 9–11 August 2019; Liu, F., Xu, J., Xu, S., Yung, M., Eds.; Revised Selected Papers; Springer: Nanjing, China, 2019; Volume 11933. [Google Scholar] [CrossRef]
- Hong, M.; Akerkar, R.; Jung, J.J. Improving Explainability of Recommendation System by Multi-sided Tensor Factorization. Cybern. Syst. 2019, 50, 97–117. [Google Scholar] [CrossRef]
- Li, B.; Yang, Q.; Xue, X. Can Movies and Books Collaborate? Cross-Domain Collaborative Filtering for Sparsity Reduction. In Proceedings of the 21st International Joint Conference on Artificial Intelligence (IJCAI 2009), Pasadena, CA, USA, 11–17 July 2009; Boutilier, C., Ed.; IJCAI Organization: Pasadena, CA, USA, 2009; pp. 2052–2057. [Google Scholar]
- Kumar, A.; Kumar, N.; Hussain, M.; Chaudhury, S.; Agarwal, S. Semantic clustering-based cross-domain recommendation. In Proceedings of the 2014 IEEE Symposium on Computational Intelligence and Data Mining (CIDM 2014), Orlando, FL, USA, 9–12 December 2014; IEEE: Orlando, FL, USA, 2014; pp. 137–141. [Google Scholar] [CrossRef]
- Tang, J.; Wu, S.; Sun, J.; Su, H. Cross-domain collaboration recommendation. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’12), Beijing, China, 12–16 August 2012; Yang, Q., Agarwal, D., Pei, J., Eds.; ACM: Beijing, China, 2012; pp. 1285–1293. [Google Scholar] [CrossRef]
- Karatzoglou, A.; Amatriain, X.; Baltrunas, L.; Oliver, N. Multiverse recommendation: n-dimensional tensor factorization for context-aware collaborative filtering. In Proceedings of the 2010 ACM Conference on Recommender Systems (RecSys 2010), Barcelona, Spain, 26–30 September 2010; Amatriain, X., Torrens, M., Resnick, P., Zanker, M., Eds.; ACM: Barcelona, Spain, 2010; pp. 79–86. [Google Scholar] [CrossRef]
- Enrich, M.; Braunhofer, M.; Ricci, F. Cold-Start Management with Cross-Domain Collaborative Filtering and Tags. In Proceedings of the 14th International Conference on E-Commerce and Web Technologies (EC-Web 2013), Prague, Czech Republic, 27–28 August 2013; Huemer, C., Lops, P., Eds.; Springer: Prague, Czech Republic, 2013; Volume 152. [Google Scholar] [CrossRef]
- Li, B.; Yang, Q.; Xue, X. Transfer learning for collaborative filtering via a rating-matrix generative model. In Proceedings of the 26th Annual International Conference on Machine Learning (ICML 2009), Montreal, QC, Canada, 14–18 June 2009; Danyluk, A.P., Bottou, L., Littman, M.L., Eds.; ACM: Montreal, QC, Canada, 2009; Volume 382, pp. 617–624. [Google Scholar] [CrossRef]
- Taneja, A.; Arora, A. Cross domain recommendation using multidimensional tensor factorization. Expert Syst. Appl. 2018, 92, 304–316. [Google Scholar] [CrossRef]
- Shi, Y.; Larson, M.A.; Hanjalic, A. Tags as Bridges between Domains: Improving Recommendation with Tag-Induced Cross-Domain Collaborative Filtering. In Proceedings of the 19th International Conference on User Modeling, Adaption and Personalization (UMAP 2011), Girona, Spain, 11–15 July 2011; Konstan, J.A., Conejo, R., Marzo, J., Oliver, N., Eds.; Springer: Girona, Spain, 2011; Volume 6787, pp. 305–316. [Google Scholar] [CrossRef]
- Gao, S.; Luo, H.; Chen, D.; Li, S.; Gallinari, P.; Guo, J. Cross-Domain Recommendation via Cluster-Level Latent Factor Model. In Proceedings of the European Conference on Machine Learning and Knowledge Discovery in Databases (ECML PKDD 2013), Prague, Czech Republic, 23–27 September 2013; Blockeel, H., Kersting, K., Nijssen, S., Zelezný, F., Eds.; Proceedings, Part II; Springer: Prague, Czech Republic, 2013; Volume 8189, pp. 161–176. [Google Scholar] [CrossRef]
- Gogna, A.; Majumdar, A. Matrix completion incorporating auxiliary information for recommender system design. Expert Syst. Appl. 2015, 42, 5789–5799. [Google Scholar] [CrossRef]
- Xu, Z.; Jiang, H.; Kong, X.; Kang, J.; Wang, W.; Xia, F. Cross-domain item recommendation based on user similarity. Comput. Sci. Inf. Syst. 2016, 13, 359–373. [Google Scholar] [CrossRef]
- Farseev, A.; Samborskii, I.; Filchenkov, A.; Chua, T. Cross-Domain Recommendation via Clustering on Multi-Layer Graphs. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Shinjuku, Tokyo, Japan, 7–11 August 2017; Kando, N., Sakai, T., Joho, H., Li, H., de Vries, A.P., White, R.W., Eds.; ACM: Tokyo, Japan, 2017; pp. 195–204. [Google Scholar] [CrossRef]
- Loni, B.; Shi, Y.; Larson, M.A.; Hanjalic, A. Cross-Domain Collaborative Filtering with Factorization Machines. In Advances in Information Retrieval, Proceedings of the 36th European Conference on IR Research (ECIR 2014), Amsterdam, The Netherlands, 13–16 April 2014; de Rijke, M., Kenter, T., de Vries, A.P., Zhai, C., de Jong, F., Radinsky, K., Hofmann, K., Eds.; Springer: Amstecdam, The Netherlands, 2014. [Google Scholar] [CrossRef]
- Salakhutdinov, R.; Mnih, A. Probabilistic Matrix Factorization. In Advances in Neural Information Processing Systems 20, Proceedings of the Twenty-First Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; Platt, J.C., Koller, D., Singer, Y., Roweis, S.T., Eds.; Curran Associates, Inc.: New York, NY, USA, 2007; pp. 1257–1264. [Google Scholar]
- Ma, H.; Yang, H.; Lyu, M.R.; King, I. SoRec: Social recommendation using probabilistic matrix factorization. In Proceedings of the 17th ACM Conference on Information and Knowledge Management (CIKM 2008), Napa Valley, CA, USA, 26–30 October 2008; Shanahan, J.G., Amer-Yahia, S., Manolescu, I., Zhang, Y., Evans, D.A., Kolcz, A., Choi, K., Chowdhury, A., Eds.; ACM: Foster City, CA, USA, 2008; pp. 931–940. [Google Scholar] [CrossRef]
- Sendov, H.S. Generalized Hadamard Product and the Derivatives of Spectral Functions. SIAM J. Matrix Anal. Appl. 2006, 28, 667–681. [Google Scholar] [CrossRef]
- Pu, S.; Shi, W.; Xu, J.; Nedic, A. A Push-Pull Gradient Method for Distributed Optimization in Networks. In Proceedings of the 57th IEEE Conference on Decision and Control (CDC 2018), Miami, FL, USA, 17–19 December 2018; IEEE: Miami, FL, USA, 2018; pp. 3385–3390. [Google Scholar] [CrossRef]
- Tawarmalani, M.; Sahinidis, N.V.; Sahinidis, N. COnvexification and Global Optimization in Continuous and Mixed-Integer Nonlinear Programming: Theory, Algorithms, Software, and Applications; Springer Science & Business Media: Heidelberg, Germany, 2002; Volume 65. [Google Scholar]
- Marks, B.R.; Wright, G.P. Technical Note—A General Inner Approximation Algorithm for Nonconvex Mathematical Programs. Oper. Res. 1978, 26, 681–683. [Google Scholar] [CrossRef]
- Nguyen, H.V.; Nguyen, V.; Dobre, O.A.; Nguyen, D.N.; Dutkiewicz, E.; Shin, O. Joint Power Control and User Association for NOMA-Based Full-Duplex Systems. IEEE Trans. Commun. 2019, 67, 8037–8055. [Google Scholar] [CrossRef]
- Toh, K.C.; Todd, M.J.; Tütüncü, R.H. SDPT3—A MATLAB software package for semidefinite programming, version 1.3. Optim. Methods Softw. 1999, 11, 545–581. [Google Scholar] [CrossRef]
- ApS, M. The MOSEK Optimization Toolbox for MATLAB Manual, Version 7.1 (Revision 28); MOSEK ApS: Copenhagen, Denmark, 2015; Volume 5. [Google Scholar]
- Peaucelle, D.; Henrion, D.; Labit, Y.; Taitz, K. User’s Guide for SeDuMi Interface 1.04; LAAS-CNRS: Toulouse, France, 2002. [Google Scholar]
- Bestuzheva, K.; Hijazi, H. Invex optimization revisited. J. Glob. Optim. 2019, 74, 753–782. [Google Scholar] [CrossRef]
- Vo, N.D.; Jung, J.J. Towards Scalable Recommendation Framework with Heterogeneous Data Sources: Preliminary Results. In Proceedings of the 14th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS 2018), Las Palmas de Gran Canaria, Spain, 26–29 November 2018; pp. 632–636. [Google Scholar] [CrossRef]
- Singh, M. Scalability and sparsity issues in recommender datasets: A survey. Knowl. Inf. Syst. 2020, 62, 1–43. [Google Scholar] [CrossRef]
- Webb, B. Netflix Update: Try This at Home. 2006. Available online: https://sifter.org/simon/journal/20061211.html (accessed on 20 March 2020).
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; Li, Y., Liu, B., Sarawagi, S., Eds.; ACM: Las Vegas, NV, USA, 2008; pp. 426–434. [Google Scholar] [CrossRef]
- Liu, X.; Liu, Y.; Aberer, K.; Miao, C. Personalized point-of-interest recommendation by mining users’ preference transition. In Proceedings of the 22nd ACM International Conference on Information and Knowledge Management (CIKM’13), San Francisco, CA, USA, 27 October–1 November 2013; He, Q., Iyengar, A., Nejdl, W., Pei, J., Rastogi, R., Eds.; ACM: San Francisco, CA, USA, 2013; pp. 733–738. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: Heidelberg, Germany, 2013; Volume 26. [Google Scholar]
- Tuy, H.; Hoang, T.; Hoang, T.; Mathématicien, V.n.; Hoang, T.; Mathematician, V. Convex Analysis and Global Optimization; Springer: Heidelberg, Germany, 1998. [Google Scholar] [CrossRef]
- Toulis, P.; Airoldi, E.M. Implicit stochastic gradient descent. arXiv 2014, arXiv:1408.2923. [Google Scholar]
- Yin, P.; Pham, M.; Oberman, A.M.; Osher, S.J. Stochastic Backward Euler: An Implicit Gradient Descent Algorithm for k-Means Clustering. J. Sci. Comput. 2018, 77, 1133–1146. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Movielens100k | Amazon Food | |
|---|---|---|
| #user | 943 | 1072 |
| #item | 1675 | 1819 |
| #rating | 90,570 | 113,895 |
| rating range | 1–5 | 1–5 |
| Parameters | Values |
|---|---|
| Regularization parameter | 0.01–0.1 |
| K | 10–50 |
| Learning rate | 50 |
| Initial value of | random |
| Number of iterations | 10 |
| K Value | GD Method | ISGD Method |
|---|---|---|
| K = 10 | 452 | 389 |
| K = 20 | 583 | 476 |
| K = 30 | 697 | 595 |
| K = 40 | 812 | 699 |
| SVD_GD | SVD_ISGD | SVD++_GD | SVD++_ISGD | RMGM_GD | RMGM_ISGD | |
|---|---|---|---|---|---|---|
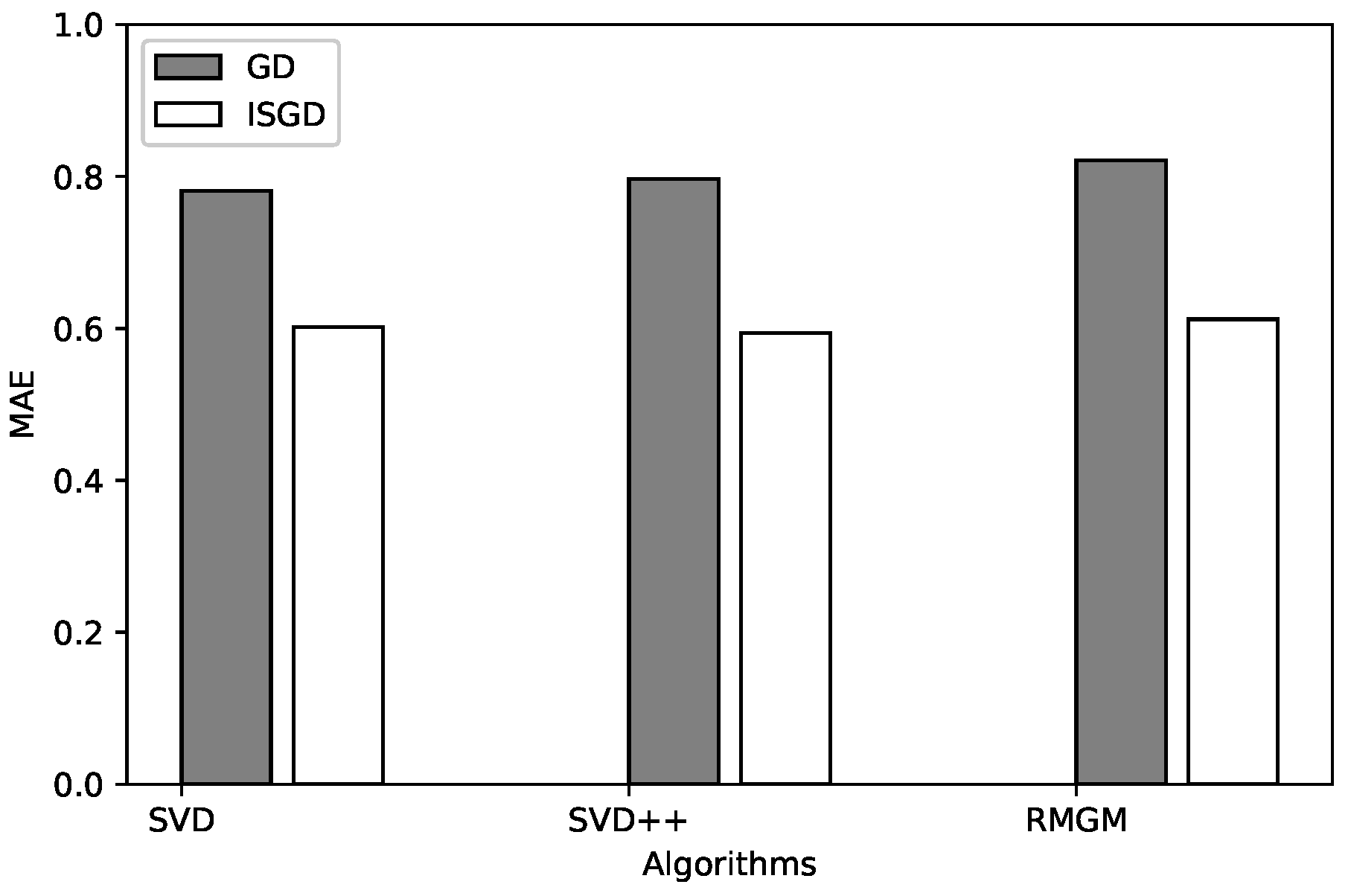
| MAE | 0.7812 | 0.6019 | 0.7964 | 0.5938 | 0.8211 | 0.612 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vo, N.D.; Hong, M.; Jung, J.J. Implicit Stochastic Gradient Descent Method for Cross-Domain Recommendation System. Sensors 2020, 20, 2510. https://doi.org/10.3390/s20092510
Vo ND, Hong M, Jung JJ. Implicit Stochastic Gradient Descent Method for Cross-Domain Recommendation System. Sensors. 2020; 20(9):2510. https://doi.org/10.3390/s20092510
Chicago/Turabian StyleVo, Nam D., Minsung Hong, and Jason J. Jung. 2020. "Implicit Stochastic Gradient Descent Method for Cross-Domain Recommendation System" Sensors 20, no. 9: 2510. https://doi.org/10.3390/s20092510
APA StyleVo, N. D., Hong, M., & Jung, J. J. (2020). Implicit Stochastic Gradient Descent Method for Cross-Domain Recommendation System. Sensors, 20(9), 2510. https://doi.org/10.3390/s20092510