Adversarial Networks for Scale Feature-Attention Spectral Image Reconstruction from a Single RGB


Abstract
1. Introduction
- (1)
- We present a novel end-to-end GAN-based approach for hyperspectral reconstruction that requires only a single RGB image. The proposed pipeline reconstructs the hyperspectral data without requiring of the spectral response function in advance.
- (2)
- We propose SAPUNet, which optimizes the U-Net architecture by using scale attention modules to fuse local and global information. The feature pyramid and attention mechanism inside the network for feature selection improves the accuracy of hyperspectral reconstruction.
- (3)
- We further designed the W-Net structure based on SAPUNet using boundary attention with a feature fusion scheme, deriving SAPWNet, which performed the best on the ICVL dataset.
2. Related Work
3. Adversarial Spectra Reconstruction via RGB
3.1. Analyzing the Physical Model of Natural Spectra Reflectance
3.2. Adversarial Learning
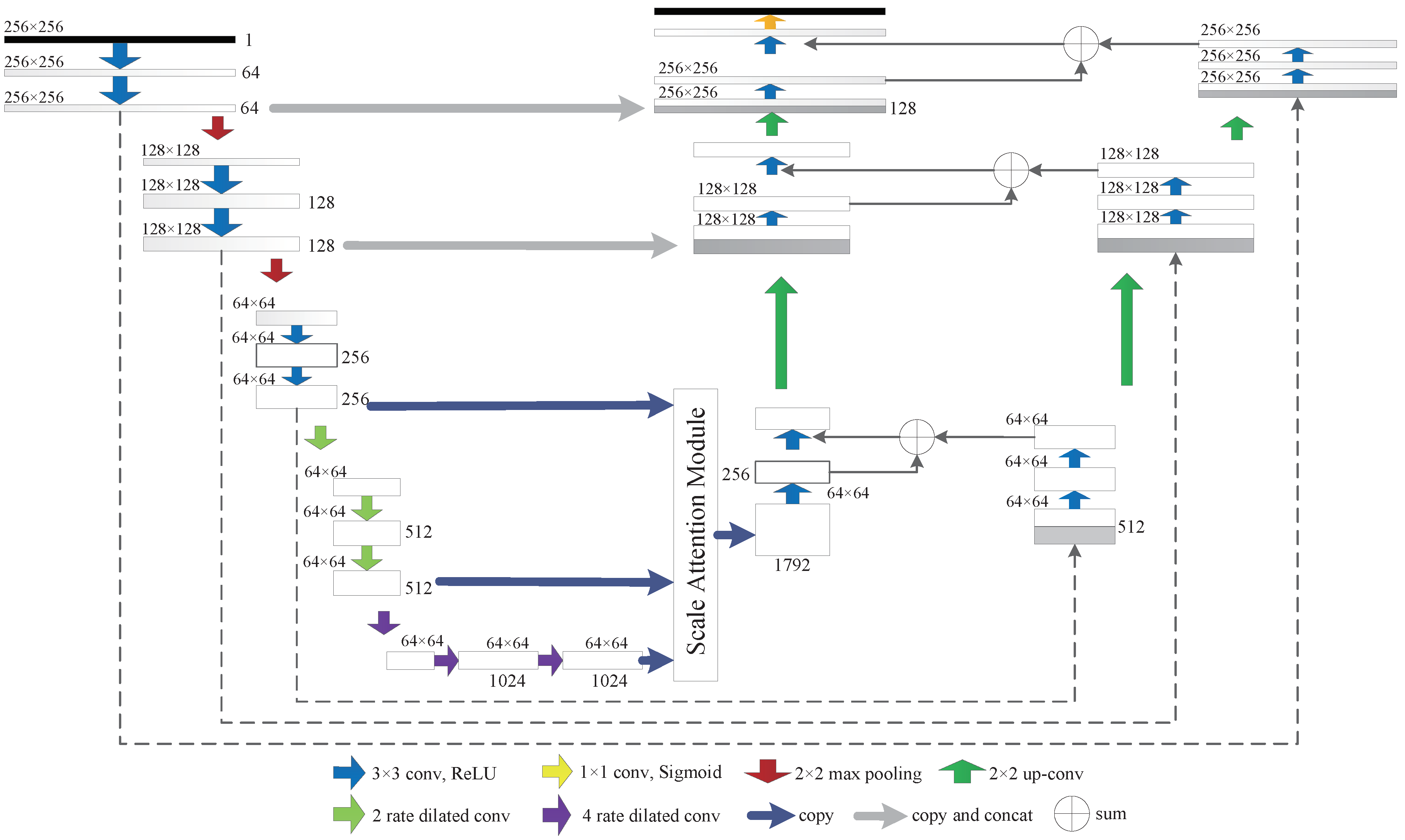
3.3. Generator: SAP-UNet Architecture
3.4. Generator: SAP-WNet Architecture
3.5. Markovian Discriminator
3.6. Materials and Implementation Details
3.7. Evaluation Metrics
4. Experimental Results and Discussion
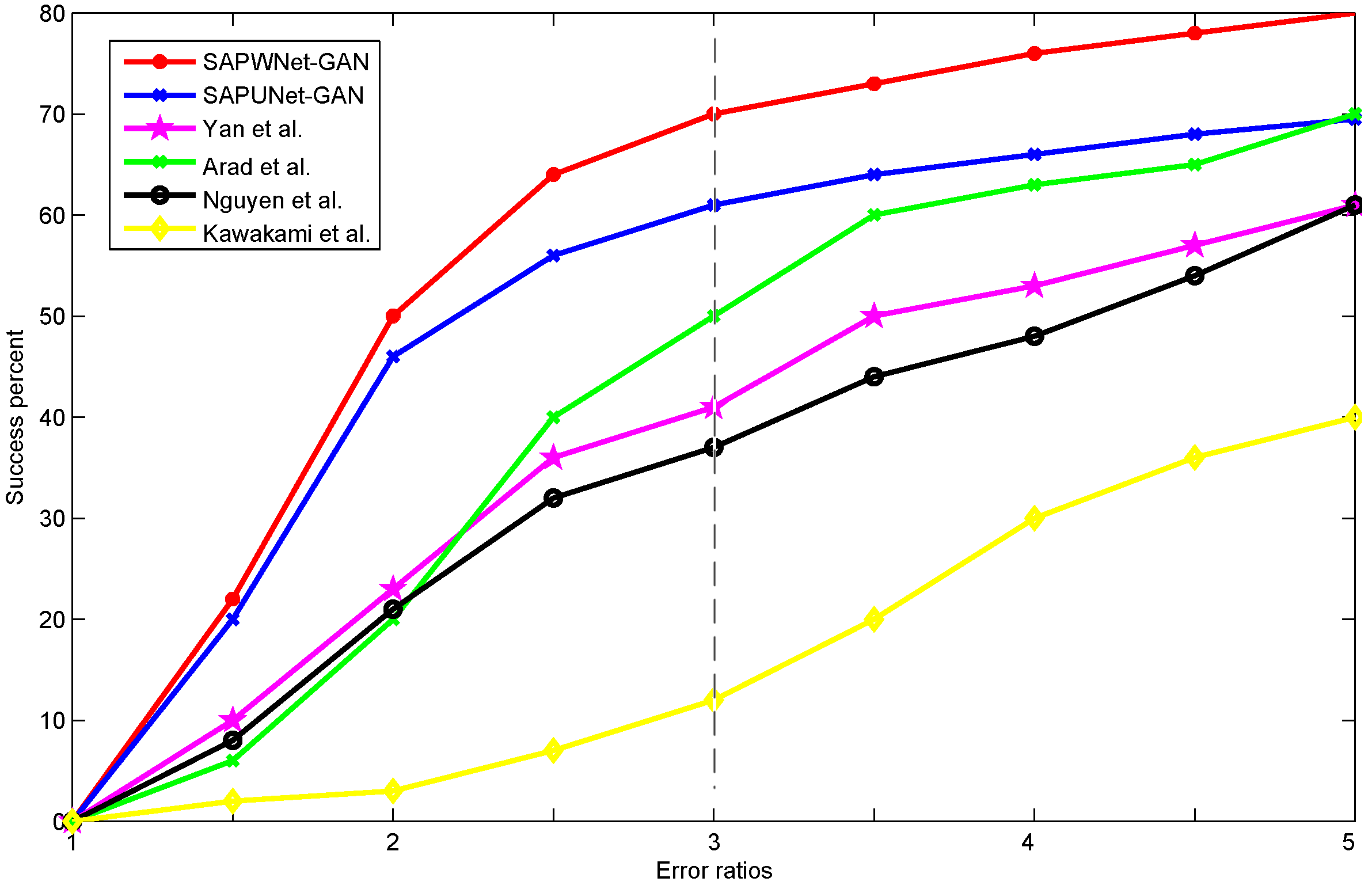
4.1. Evaluation on the ICVL Dataset
4.2. Chakrabarti Dataset
4.3. Ablation Study for SAPWNet
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Fang, B.; Li, Y.; Zhang, H.; Chan, J.C. Hyperspectral Images Classification Based on Dense Convolutional Networks with Spectral-Wise Attention Mechanism. Remote Sens. 2019, 11, 159. [Google Scholar] [CrossRef]
- Liang, G.; Kester, R.T.; Nathan, H.; Tkaczyk, T.S. Snapshot Image Mapping Spectrometer (IMS) with high sampling density for hyperspectral microscopy. Opt. Express 2010, 18, 14330. [Google Scholar]
- Arad, B.; Benshahar, O. Sparse Recovery of Hyperspectral Signal from Natural RGB Images. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 19–34. [Google Scholar]
- Xiong, Z.; Shi, Z.; Li, H.; Wang, L.; Liu, D.; Wu, F. HSCNN: CNN-Based Hyperspectral Image Recovery from Spectrally Undersampled projections. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV), Venice, Italy, 22–29 October 2017; pp. 518–525. [Google Scholar]
- He, Z.; Liu, L. Hyperspectral Image Super-Resolution Inspired by Deep Laplacian Pyramid Network. Remote Sens. 2018, 10, 1939. [Google Scholar] [CrossRef]
- Parmar, M.; Lansel, S.; Wandell, B.A. Spatio-spectral reconstruction of the multispectral datacube using sparse recovery. In Proceedings of the 2008 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 473–476. [Google Scholar]
- Wang, L.; Xiong, Z.; Gao, D.; Shi, G.; Feng, W. High-speed hyperspectral video acquisition with a dual-camera architecture. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4942–4950. [Google Scholar]
- Wagadarikar, A.A.; John, R.; Willett, R.; Brady, D.J. Single disperser design for coded aperture snapshot spectral imaging. Appl. Opt. 2008, 47, B44–B51. [Google Scholar] [CrossRef] [PubMed]
- Xun, C.; Xin, T.; Dai, Q.; Lin, S. High resolution multispectral video capture with a hybrid camera system. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011; pp. 297–304. [Google Scholar]
- Goel, M.; Patel, S.N.; Whitmire, E.; Mariakakis, A.; Borriello, G. HyperCam: Hyperspectral imaging for ubiquitous computing applications. In Proceedings of the 2015 ACM International Joint Conference, Osaka, Japan, 7–11 September 2015. [Google Scholar]
- Takatani, T.; Aoto, T.; Mukaigawa, Y. One-Shot Hyperspectral Imaging Using Faced Reflectors. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4039–4047. [Google Scholar]
- Oh, S.W.; Brown, M.S.; Pollefeys, M.; Kim, S.J. Do It Yourself Hyperspectral Imaging with Everyday Digital Cameras. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2461–2469. [Google Scholar]
- Akhtar, N.; Shafait, F.; Mian, A. Hierarchical Beta Process with Gaussian Process Prior for Hyperspectral Image Super Resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 103–120. [Google Scholar]
- Nguyen, R.M.H.; Prasad, D.K.; Brown, M.S. Training-Based Spectral Reconstruction from a Single RGB Image. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 186–201. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein GANs. In Proceedings of the Neural Information Processing Systems, Long Beach, LA, USA, 4–9 December 2017; pp. 5769–5779. [Google Scholar]
- Jia, Y.; Zheng, Y.; Gu, L.; Subpaasa, A.; Lam, A.; Sato, Y.; Sato, I. From RGB to Spectrum for Natural Scenes via Manifold-Based Mapping. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4715–4723. [Google Scholar]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Stephen, L. A Prism-Mask System for Multispectral Video Acquisition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2423–2435. [Google Scholar]
- Ma, C.; Cao, X.; Tong, X.; Dai, Q.; Lin, S. Acquisition of High Spatial and Spectral Resolution Video with a Hybrid Camera System. Int. J. Comput. Vis. 2014, 110, 141–155. [Google Scholar] [CrossRef]
- Kawakami, R.; Matsushita, Y.; Wright, J.; Benezra, M.; Tai, Y.; Ikeuchi, K. High-resolution hyperspectral imaging via matrix factorization. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2329–2336. [Google Scholar]
- Wu, J.; Aeschbacher, J.; Timofte, R. In Defense of Shallow Learned Spectral Reconstruction from RGB Images. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 471–479. [Google Scholar]
- Timofte, R.; Smet, V.D.; Gool, L.V. A+: Adjusted Anchored Neighborhood Regression for Fast Super-Resolution. In Proceedings of the Computer Vision—ACCV 2014: 12th Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 235–238. [Google Scholar]
- Robleskelly, A. Single Image Spectral Reconstruction for Multimedia Applications. ACM Multimed. 2015, 251–260. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Jian, S. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Laurens, E.A. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Qiu, Z.; Chen, J.; Zhao, Y.; Zhu, S.; He, Y.; Zhang, C. Variety Identification of Single Rice Seed Using Hyperspectral Imaging Combined with Convolutional Neural Network. Appl. Sci. 2018, 8, 212. [Google Scholar] [CrossRef]
- Shi, Z.; Chen, C.; Xiong, Z.; Liu, D.; Wu, F. HSCNN+: Advanced CNN-Based Hyperspectral Recovery from RGB Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 939–947. [Google Scholar]
- Galliani, S.; Lanaras, C.; Marmanis, D.; Baltsavias, E.P.; Schindler, K. Learned Spectral Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Alvarezgila, A.; De Weijer, J.V.; Garrote, E. Adversarial Networks for Spatial Context-Aware Spectral Image Reconstruction from RGB. In Proceedings of the EEE International Conference on Computer Vision Workshop (ICCVW 2017), Venice, Italy, 22–29 October 2017; pp. 480–490. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Liu, K.; He, L.; Ma, S.; Gao, S.; Bi, D. A Sensor Image Dehazing Algorithm Based on Feature Learning. Sensors 2018, 18, 2606. [Google Scholar] [CrossRef] [PubMed]
- Arjovsky, M.; Bottou, L. Towards Principled Methods for Training Generative Adversarial Networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. In Proceedings of the The 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Nah, S.; Kim, T.H.; Lee, K.M. Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 234–241. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 10–16 October 2016; pp. 630–645. [Google Scholar]
- Chen, L.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to Scale: Scale-Aware Semantic Image Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3640–3649. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid Attention Network for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–21 June 2018. [Google Scholar]
- Li, C.; Wand, M. Precomputed Real-Time Texture Synthesis with Markovian Generative Adversarial Networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 702–716. [Google Scholar]
- Chakrabarti, A.; Zickler, T. Statistics of real-world hyperspectral images. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 193–200. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Layer | Weight Dimension | Stride |
|---|---|---|---|
| 1 | Conv | 64×32×5×5 | 2 |
| 2 | Conv | 64×64×5×5 | 1 |
| 3 | Conv | 128×64×5×5 | 2 |
| 4 | Conv | 128×128×5×5 | 1 |
| 5 | Conv | 256×128×5×5 | 2 |
| 6 | Conv | 256×256×5×5 | 1 |
| 7 | Conv | 512×256×5×5 | 2 |
| 8 | Conv | 512×512×3×3 | 4 |
| 9 | Fc | 512×1×1×1 | 0 |
| 10 | Sigmoid | - | - |
| Metric | Arad et al. [3] | Alvarez-Gila et al. [30] | SAPUNet-GAN | SAPWNet-GAN |
|---|---|---|---|---|
| RMSE | 2.633 | 1.457 | 1.455 | 1.445 |
| RMSERel | 0.0756 | 0.0401 | 0.0398 | 0.0378 |
| PSNR | 27.641 | - | 31.647 | 32.532 |
| SSIM | 0.847 | - | 0.916 | 0.932 |
| Datasets | Metric | Arad et al. [3] | Yan et al. [16] | SAPUNet-GAN | SAPWNet-GAN |
|---|---|---|---|---|---|
| Outdoor subset | RMSE | 3.466 | 3.661 | 2.893 | 2.687 |
| PSNR | 24.225 | 26.024 | 26.131 | 26.316 | |
| SSIM | 0.769 | 0.805 | 0.817 | 0.835 | |
| Indoor subset | RMSE | 5.685 | 4.872 | 4.904 | 4.782 |
| PSNR | 18.323 | 22.146 | 22.173 | 22.468 | |
| SSIM | 0.696 | 0.717 | 0.721 | 0.757 |
| Network | RMSE | PSNR | SSIM |
|---|---|---|---|
| HSGAN | 2.586 | 27.224 | 0.756 |
| HSGAN(FP) | 2.155 | 29.463 | 0.817 |
| HSGAN(SAM) | 1.455 | 31.647 | 0.916 |
| HSGAN(W-Net) | 1.639 | 31.339 | 0.912 |
| HSGAN(SAM+W-Net) | 1.445 | 32.532 | 0.932 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, P.; Zhao, H. Adversarial Networks for Scale Feature-Attention Spectral Image Reconstruction from a Single RGB. Sensors 2020, 20, 2426. https://doi.org/10.3390/s20082426
Liu P, Zhao H. Adversarial Networks for Scale Feature-Attention Spectral Image Reconstruction from a Single RGB. Sensors. 2020; 20(8):2426. https://doi.org/10.3390/s20082426
Chicago/Turabian StyleLiu, Pengfei, and Huaici Zhao. 2020. "Adversarial Networks for Scale Feature-Attention Spectral Image Reconstruction from a Single RGB" Sensors 20, no. 8: 2426. https://doi.org/10.3390/s20082426
APA StyleLiu, P., & Zhao, H. (2020). Adversarial Networks for Scale Feature-Attention Spectral Image Reconstruction from a Single RGB. Sensors, 20(8), 2426. https://doi.org/10.3390/s20082426