NeuroVAD: Real-Time Voice Activity Detection from Non-Invasive Neuromagnetic Signals


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. MEG Methods
2.1. Data Collection
2.2. Participants and Stimuli
2.3. Protocol
2.4. Data Preprocessing
2.5. Data Labeling
3. Decoding Methods
3.1. Isolated Classification
3.2. Continuous Prediction
3.2.1. Feature Extraction
3.2.2. LSTM-RNN
4. Results and Discussions
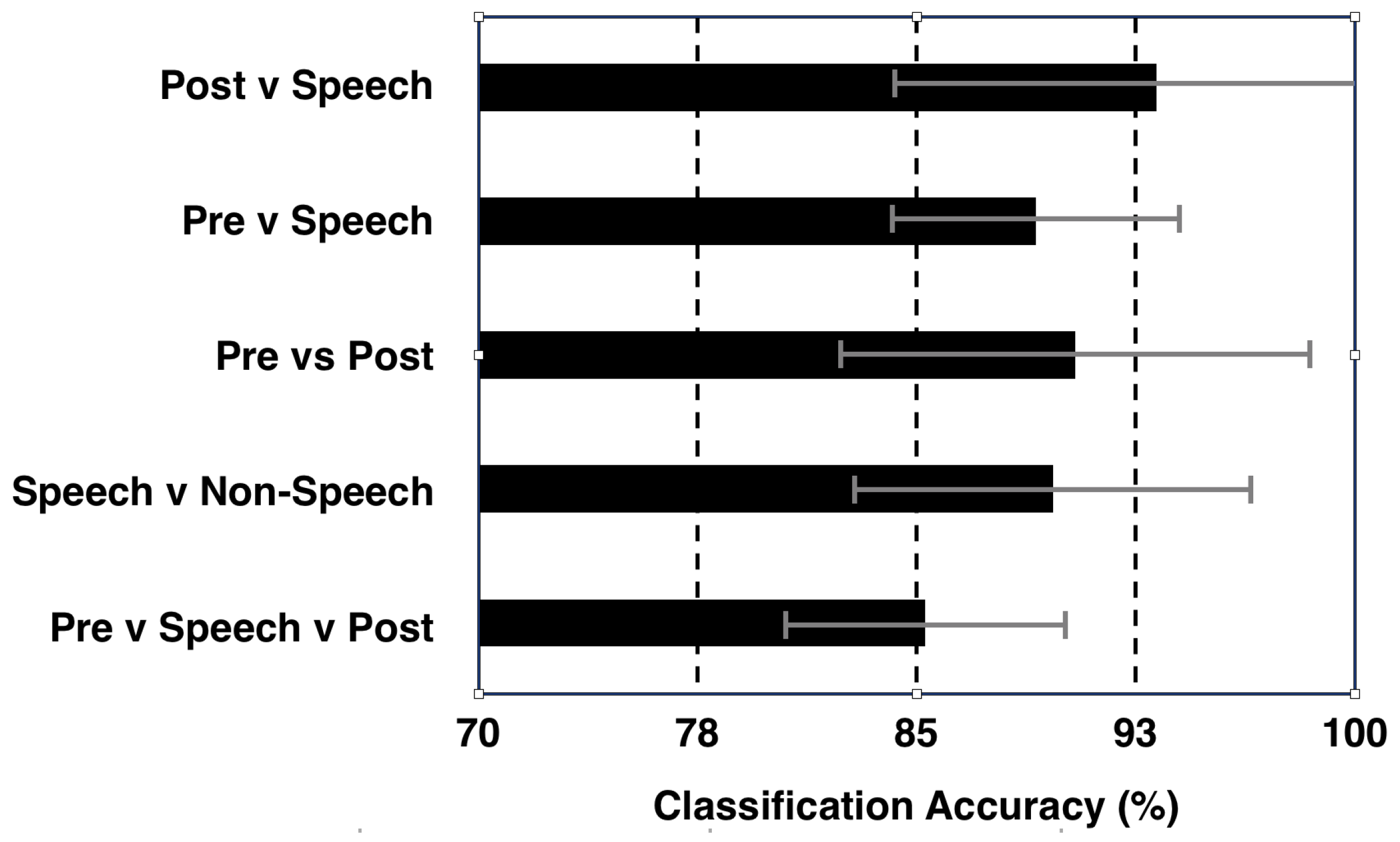
4.1. Isolated ‘Speech’ vs. ‘Non-Speech’ Classification
4.2. Real-Time NeuroVAD
4.3. Efficacy of LSTM-RNN for NeuroVAD
4.4. Future Work
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Laureys, S.; Pellas, F.; Eeckhout, P.; Ghorbel, S.; Schnakers, C.; Perrin, F.; Berre, J.; Faymonville, M.E.; Pantke, K.H.; Damas, F.; et al. The locked-in syndrome: What is it like to be conscious but paralyzed and voiceless? Prog. Brain Res. 2005, 150, 495–611. [Google Scholar]
- Brumberg, J.S.; Nieto-Castanon, A.; Kennedy, P.R.; Guenther, F.H. Brain-computer interfaces for speech communication. Speech Commun. 2010, 52, 367–379. [Google Scholar] [CrossRef] [PubMed]
- Wolpaw, J.R.; Birbaumer, N.; McFarland, D.J.; Pfurtscheller, G.; Vaughan, T.M. Brain computer interfaces for communication and control. Clin. Neurophysiol. 2002, 113, 767–791. [Google Scholar] [CrossRef]
- Birbaumer, N. Brain-computer-interface research: Coming of age. Clin. Neurophysiol. 2006, 117, 479–483. [Google Scholar] [CrossRef] [PubMed]
- Formisano, E.; De Martino, F.; Bonte, M.; Goebel, R. “who” is saying “what”? brain-based decoding of human voice and speech. Science 2008, 322, 970–973. [Google Scholar] [CrossRef] [PubMed]
- Herff, C.; Heger, D.; de Pesters, A.; Telaar, D.; Brunner, P.; Schalk, G.; Schultz, T. Brain-to-text: Decoding spoken phrases from phone representations in the brain. Front. Neurosci. 2015, 9, 217. [Google Scholar] [CrossRef]
- Dash, D.; Wisler, A.; Ferrari, P.; Wang, J. Towards a Speaker Independent Speech-BCI Using Speaker Adaptation. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 864–868. [Google Scholar] [CrossRef]
- Dash, D.; Ferrari, P.; Wang, J. Decoding Imagined and Spoken Phrases from Non-invasive Neural (MEG) Signals. Front. Neurosci. 2020, 14, 290. [Google Scholar] [CrossRef]
- Wang, J.; Kim, M.; Hernandez-Mulero, A.W.; Heitzman, D.; Ferrari, P. Towards decoding speech production from single-trial magnetoencephalography (MEG) signals. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 3036–3040. [Google Scholar]
- Dash, D.; Ferrari, P.; Heitzman, D.; Wang, J. Decoding speech from single trial MEG signals using convolutional neural networks and transfer learning. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 5531–5535. [Google Scholar] [CrossRef]
- Kellis, S.; Miller, K.; Thomson, K.; Brown, R.; House, P.; Greger, B. Decoding spoken words using local field potentials recorded from the cortical surface. J. Neural Eng. 2010, 7, 056007. [Google Scholar] [CrossRef]
- Rezazadeh Sereshkeh, A.; Trott, R.; Bricout, A.; Chau, T. EEG classification of covert speech using regularized neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2292–2300. [Google Scholar] [CrossRef]
- Angrick, M.; Herff, C.; Mugler, E.; Tate, M.C.; Slutzky, M.W.; Krusienski, D.J.; Schultz, T. Speech synthesis from ECoG using densely connected 3D convolutional neural networks. J. Neural Eng. 2019, 16, 036019. [Google Scholar] [CrossRef]
- Anumanchipalli, G.; Chartier, J.F.; Chang, E. Speech synthesis from neural decoding of spoken sentences. Nature 2019, 568, 493–498. [Google Scholar] [CrossRef]
- Tong, S.; Chen, N.; Qian, Y.; Yu, K. Evaluating VAD for automatic speech recognition. In Proceedings of the 2014 12th International Conference on Signal Processing (ICSP), Hangzhou, China, 19–23 October 2014; pp. 2308–2314. [Google Scholar]
- Kanas, V.G.; Mporas, I.; Benz, H.L.; Huang, N.; Thakor, N.V.; Sgarbas, K.; Bezerianos, A.; Crone, N.E. Voice activity detection from electrocorticographic signals. In Proceedings of the XIII Mediterranean Conference on Medical and Biological Engineering and Computing 2013, Seville, Spain, 25–28 September 2013; pp. 1643–1646. [Google Scholar]
- Kanas, V.G.; Mporas, I.; Benz, H.L.; Sgarbas, K.N.; Bezerianos, A.; Crone, N.E. Real-time voice activity detection for ECoG-based speech brain machine interfaces. In Proceedings of the 2014 19th International Conference on Digital Signal Processing, Hong Kong, China, 20–23 August 2014; pp. 862–865. [Google Scholar]
- Dash, D.; Ferrari, P.; Malik, S.; Wang, J. Automatic speech activity recognition from MEG signals using seq2seq learning. In Proceedings of the 9th International IEEE/EMBS Conference on Neural Engineering (NER), San Francisco, CA, USA, 20–23 March 2019; pp. 340–343. [Google Scholar]
- Memarian, N.; Ferrari, P.; Macdonald, M.J.; Cheyne, D.; Nil, L.F.D.; Pang, E.W. Cortical activity during speech and non-speech oromotor tasks: A magnetoencephalography (MEG) study. Neurosci. Lett. 2012, 527, 34–39. [Google Scholar] [CrossRef]
- Boto, E.; Holmes, N.; Leggett, J.; Roberts, G.; Shah, V.; Meyer, S.S.; Muñoz, L.D.; Mullinger, K.J.; Tierney, T.M.; Bestmann, S.; et al. Moving magnetoencephalography towards real-world applications with a wearable system. Nature 2018, 555, 657–661. [Google Scholar] [CrossRef] [PubMed]
- Grill-Spector, K.; Henson, R.; Martin, A. Repetition and the brain: Neural models of stimulus-specific effects. Trends Cogn. Sci. 2006, 10, 14–23. [Google Scholar] [CrossRef] [PubMed]
- Gross, J.; Baillet, S.; Barnes, G.R.; Henson, R.N.; Hillebrand, A.; Jensen, O.; Jerbi, K.; Litvak, V.; Maess, B.; Oostenveld, R.; et al. Good practice for conducting and reporting MEG research. NeuroImage 2013, 65, 349–363. [Google Scholar] [CrossRef] [PubMed]
- Dash, D.; Ferrari, P.; Malik, S.; Montillo, A.; Maldjian, J.A.; Wang, J. Determining the optimal number of MEG trials: A machine learning and speech decoding perspective. In Proceedings of the Brain Informatics and Health, Haikou, Chian, 7–9 December 2018; pp. 163–172. [Google Scholar]
- Plapous, C.; Marro, C.; Scalart, P. Improved signal-to-noise ratio estimation for speech enhancement. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 2098–2108. [Google Scholar] [CrossRef]
- Dash, D.; Ferrari, P.; Wang, J. Spatial and Spectral Fingerprint in the Brain: Speaker Identification from Single Trial MEG Signals. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 1203–1207. [Google Scholar] [CrossRef]
- Dash, D.; Ferrari, P.; Malik, S.; Wang, J. Overt speech retrieval from neuromagnetic signals using wavelets and artificial neural networks. In Proceedings of the 2018 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Anaheim, CA, USA, 26–29 November 2018; pp. 489–493. [Google Scholar]
- Ding, N.; Simon, J.Z. Emergence of neural encoding of auditory objects while listening to competing speakers. Proc. Natl. Acad. Sci. USA 2012, 109, 11854–11859. [Google Scholar] [CrossRef]
- Min, B.; Kim, J.; Park, H.J.; Lee, B. Vowel Imagery Decoding toward Silent Speech BCI Using Extreme Learning Machine with Electroencephalogram. BioMed Res. Int. 2016. [Google Scholar] [CrossRef]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In Proceedings of the INTERSPEECH-2014, Singapore, 14–18 September 2014; pp. 338–342. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. In Proceedings of the 1999 Ninth International Conference on Artificial Neural Networks ICANN 99. (Conf. Publ. No. 470), Edinburgh, UK, 7–10 September 1999; Volume 2, pp. 850–855. [Google Scholar]
- Bunton, K. Speech versus nonspeech: Different tasks, different neural organization. Semin. Speech Lang. 2008, 29, 267–275. [Google Scholar] [CrossRef]
- Chang, S.-E.; Kenney, M.K.; Loucks, T.M.J.; Poletto, C.J.; Ludlow, C.L. Common neural substrates support speech and non-speech vocal tract gestures. NeuroImage 2009, 47, 314–325. [Google Scholar] [CrossRef] [PubMed]
- Brumberg, J.S.; Krusienski, D.J.; Chakrabarti, S.; Gunduz, A.; Brunner, P.; Ritaccio, A.L.; Schalk, G. Spatio-temporal progression of cortical activity related to continuous overt and covert speech production in a reading task. PLoS ONE 2016, 11. [Google Scholar] [CrossRef] [PubMed]
- Shellikeri, S.; Yunusova, Y.; Thomas, D.; Green, J.R.; Zinman, L. Compensatory articulation in amyotrophic lateral sclerosis: Tongue and jaw in speech. Proc. Meet. Acoust. 2013, 19, 060061. [Google Scholar]
- Bamdadian, A.; Guan, C.; Ang, K.K.; Xu, J. Improving session-to-session transfer performance of motor imagery-based BCI using adaptive extreme learning machine. In Proceedings of the 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; pp. 2188–2191. [Google Scholar]
- Millan, J.R. On the need for on-line learning in brain-computer interfaces. In Proceedings of the IEEE International Joint Conference on Neural Networks (IEEE Cat. No.04CH37541), Budapest, Hungary, 25–29 July 2004; Volume 4, pp. 2877–2882. [Google Scholar]
- Haumann, N.T.; Parkkonen, L.; Kliuchko, M.; Vuust, P.; Brattico, E. Comparing the performance of popular MEG/EEG artifact correction methods in an evoked-response study. Intell. Neurosci. 2016, 2016, 7489108. [Google Scholar] [CrossRef]
- Sörös, P.; Schäfer, S.; Witt, K. Model-Based and Model-Free Analyses of the Neural Correlates of Tongue Movements. Front. Neurosci. 2020, 14, 226. [Google Scholar] [CrossRef]







© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dash, D.; Ferrari, P.; Dutta, S.; Wang, J. NeuroVAD: Real-Time Voice Activity Detection from Non-Invasive Neuromagnetic Signals. Sensors 2020, 20, 2248. https://doi.org/10.3390/s20082248
Dash D, Ferrari P, Dutta S, Wang J. NeuroVAD: Real-Time Voice Activity Detection from Non-Invasive Neuromagnetic Signals. Sensors. 2020; 20(8):2248. https://doi.org/10.3390/s20082248
Chicago/Turabian StyleDash, Debadatta, Paul Ferrari, Satwik Dutta, and Jun Wang. 2020. "NeuroVAD: Real-Time Voice Activity Detection from Non-Invasive Neuromagnetic Signals" Sensors 20, no. 8: 2248. https://doi.org/10.3390/s20082248
APA StyleDash, D., Ferrari, P., Dutta, S., & Wang, J. (2020). NeuroVAD: Real-Time Voice Activity Detection from Non-Invasive Neuromagnetic Signals. Sensors, 20(8), 2248. https://doi.org/10.3390/s20082248