1. Introduction
Despite the large existing literature, cloud detection from images taken by sensors onboard satellites is still an area of very active research. This is essentially due to three main reasons: (i) Cloud detection is an important preliminary step of remotely sensed image processing because clouds affect sensor measurements of radiance emitted by surface up to make data unreliable for a wide range of remote-sensing applications that use optical satellite images; (ii) Cloud detection by itself is a difficult problem (even for experts attempting to visually detect clouds from signatures and/or images) in some conditions as transparent or semi-transparent clouds and in general when the contrast between the cloud and the underlying surface is poor; and (iii) Despite consolidated guidelines for cloud detection algorithms (e.g., use of infrared bands, preliminary removal of noninformative bands), development of new sensors with different hardware capabilities in terms of spatial, spectral and temporal resolution claims for specific algorithms or adaption of existing ones (e.g., re-estimate of new thresholds). In particular, a dramatic progress in the technology was availability of hyper-spectral sensors able to take images up to 8K bands [
1,
2]. While these instruments promise to gather unprecedented information from surface and atmosphere, however, they challenge low-dimensional conventional algorithms for cloud detection not so much for scalability and computational resources required but as for physical and theoretical implications of hyper-spectrality. In particular, really informative bands must be selected in advance to face the curse of dimensionality inherent in statistical estimation (dimensionality reduction). Actually, a manual selection of spectral bands and estimate of thresholds for bands themselves or some couples of theirs is not conceivable anymore, therefore innovative methods for automatic feature extraction from the hyper-spectral images are sought.
In the case of low-dimensionality, as in PROBA-V considered in the present paper, the dimension reduction problem is generally not a concern and all spectral bands are considered (Experiments not reported in this paper confirm that best accuracy is achieved when all PROBA-V spectral bands are considered). However, due to the limited amount of information with a so reduced number of bands, it is important to extract relevant features for cloud detection as effectively as possible.
In all cases, also considering the recent explosive emerging methods, a problem of validation of methods arises that could help not only in comparing their accuracy but also to understand strengths and weaknesses of the general cloud detection problem.
Classification exercises are sometimes organized where different algorithms are challenged to estimate a cloud mask from radiance detected by a specific sensor. Radiance is endowed with labels on the Clear or Cloudy condition accurately assigned by experts that are blind to the algorithms, so to be used as a validation of the algorithms themselves. While the main purpose of such exercises is to develop accurate operational algorithms for specific sensors onboard satellites, an important side effect is comparison of state-of-art methods on a same, very accurate dataset. In this respect we mention the Landsat comparison exercise [
3] and the ESA Round Robin exercise for PROBA-V sensor [
4]. Such comparisons are an exceptional way not only to compare algorithms, but especially to discover their weakness in particular climatic/surface conditions and, finally, to progress knowledge of cloud mask detection.
One of the authors participated in the ESA Cloud Detection Round Robin exercise (
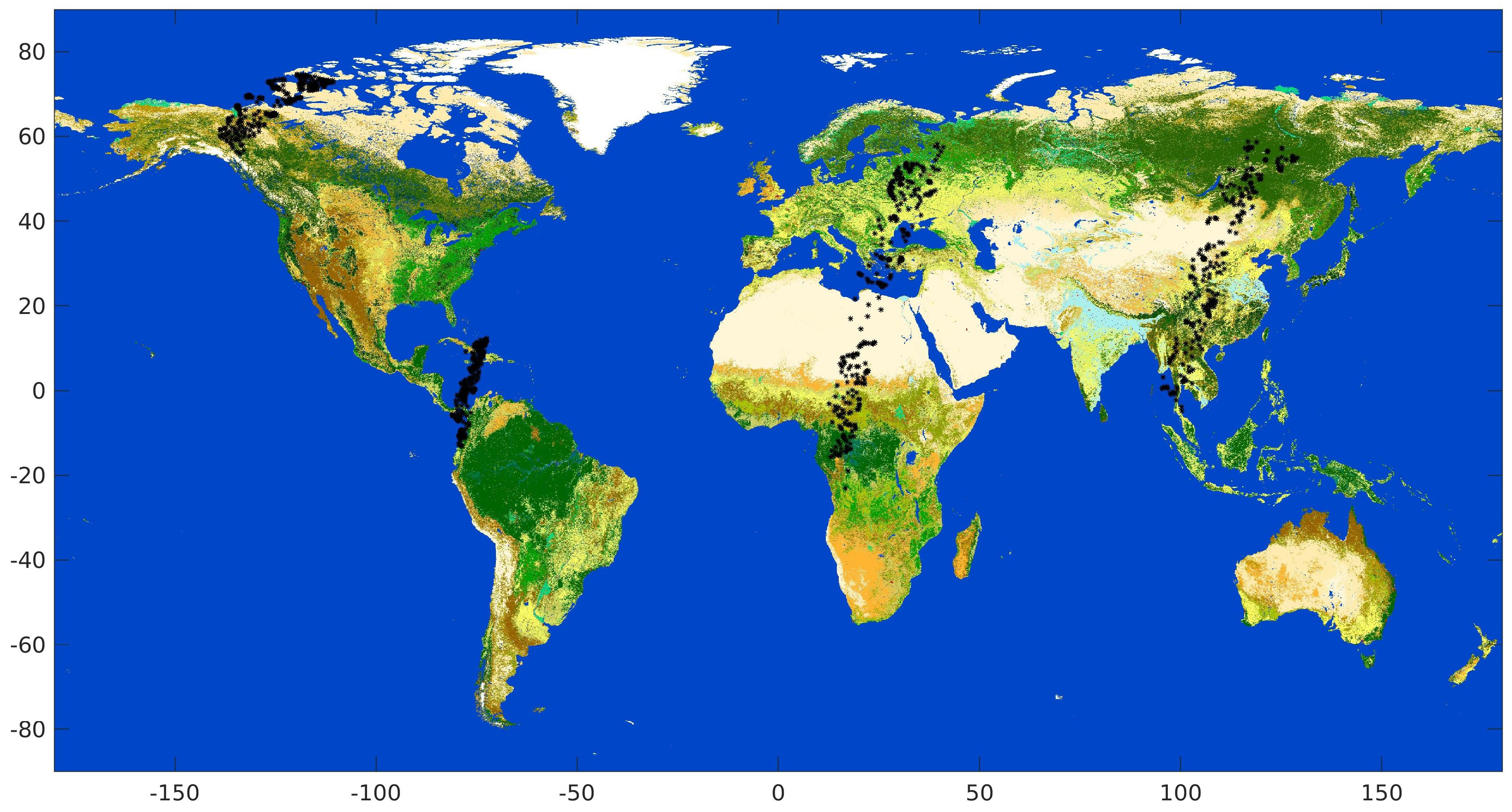
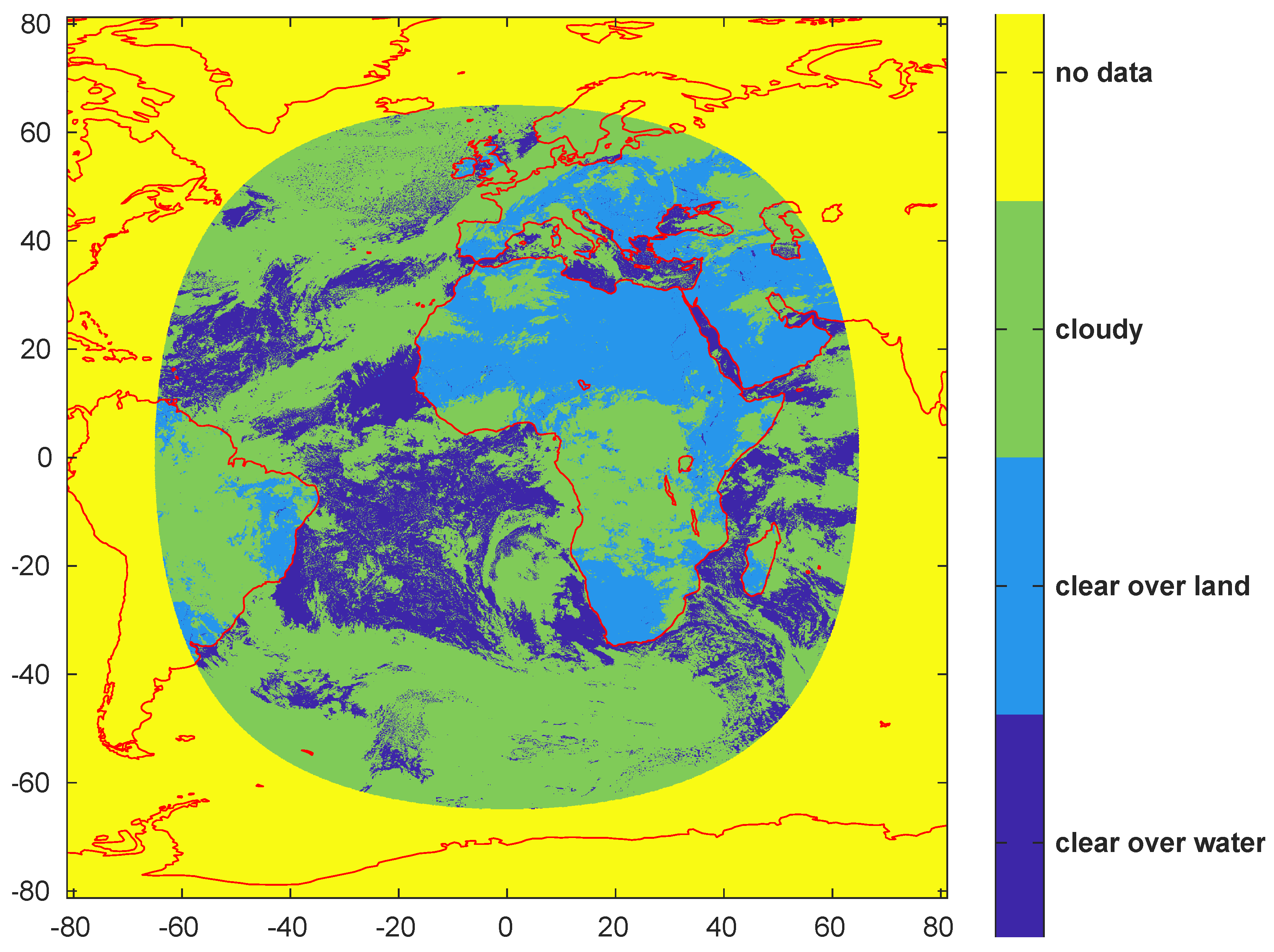
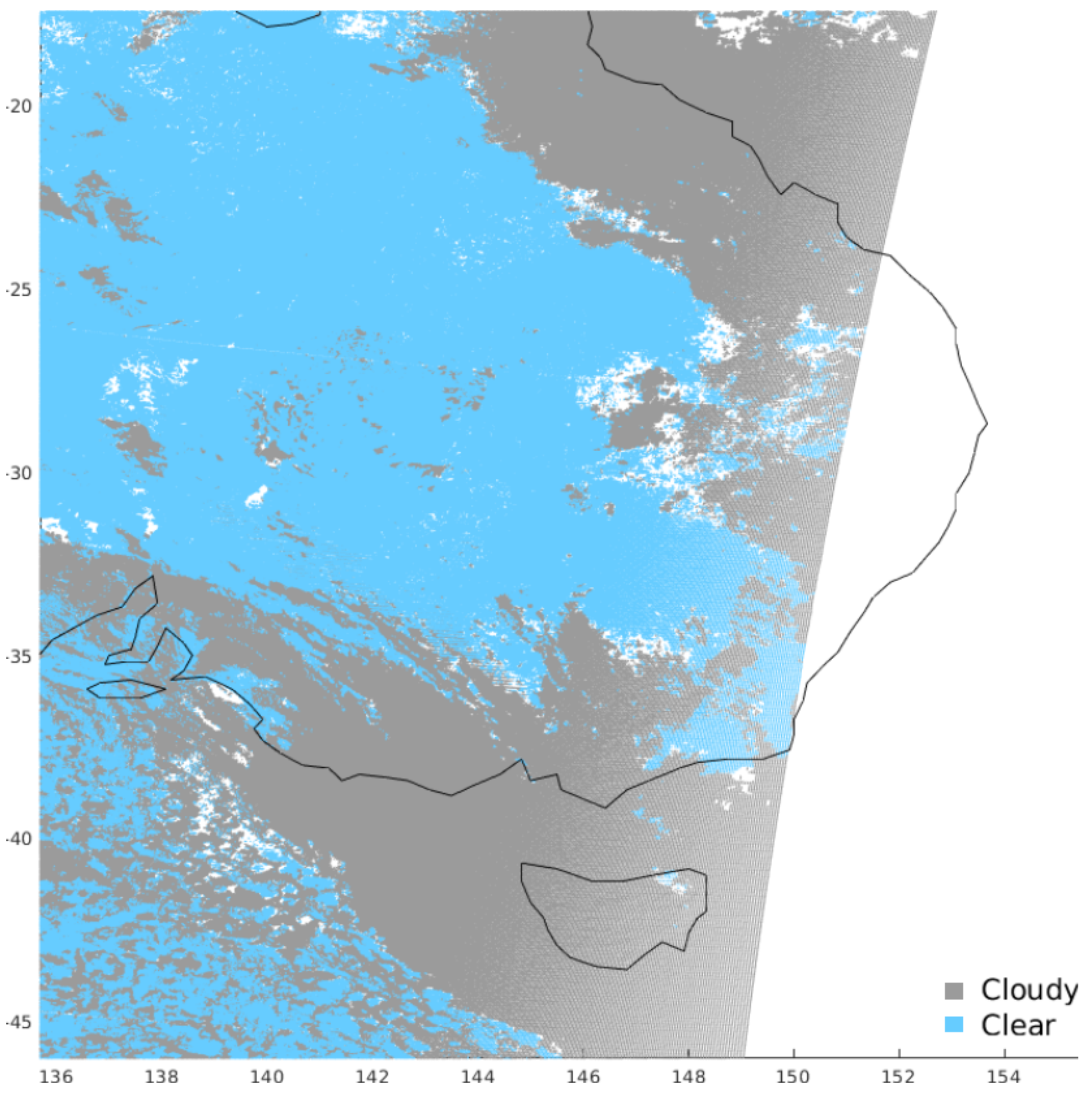
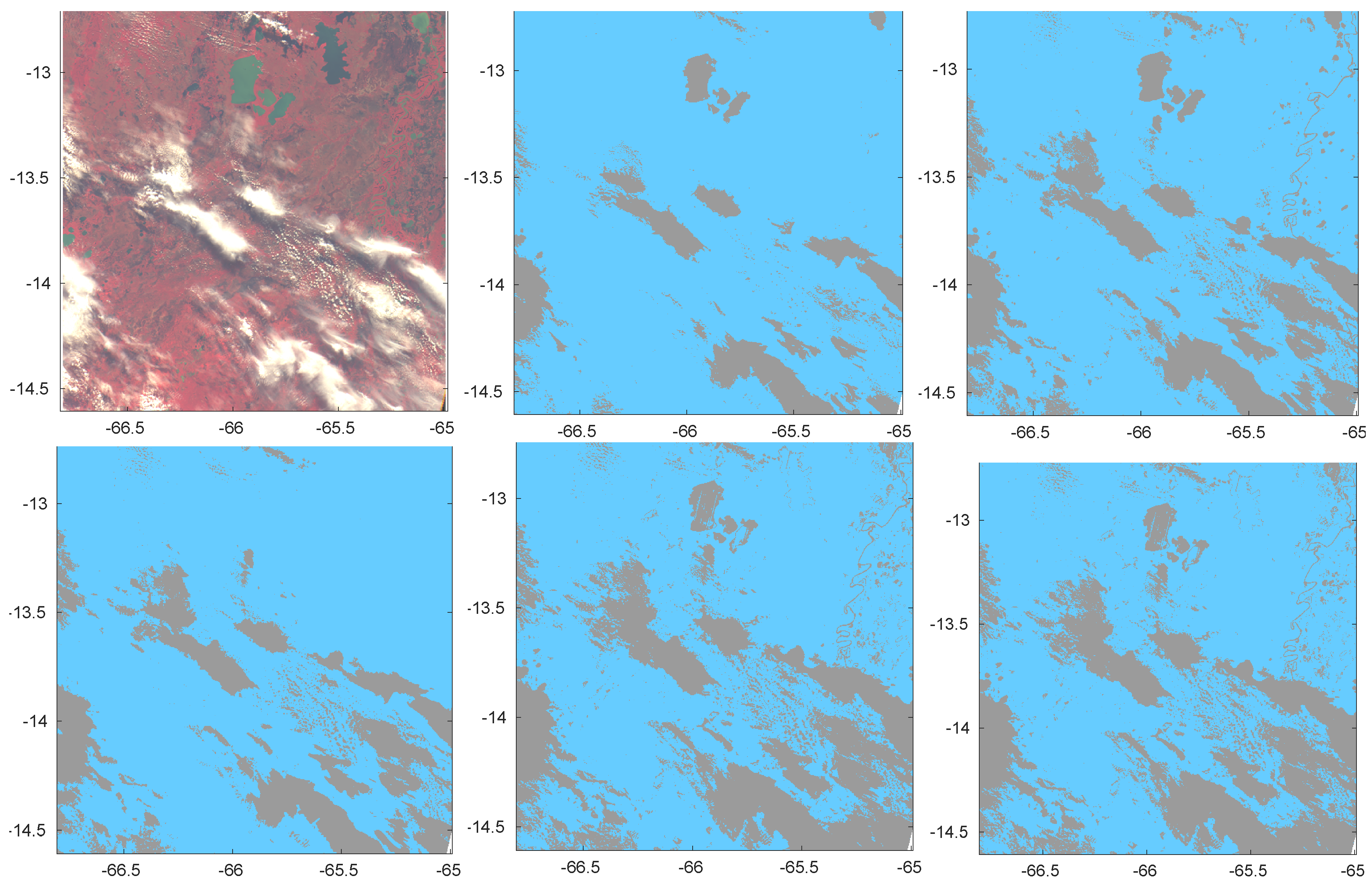
https://earth.esa.int/web/sppa/activities/instrument-characterization-studies/pv-cdrr). Such exercise was intended for the PROBA-V sensor onboard the PROBA ESA platforms and suited for land use and classification, including vegetation, crop monitoring, food security and scarcity prediction, disaster and biosphere monitoring. PROBA-V has a small number of spectral bands (Blue, Red, NIR and SWIR) and in particular it lacks a Thermal Infrared band that could have been useful to detect cirrus clouds. This makes cloud detection from its images challenging. ESA and the Belgian Science Policy Office organized a dedicated Round Robin exercise to inter-compare the performances of different cloud detection algorithms for PROBA-V. The Round Robin exercise provided the participants with a large dataset of PROBA-V images (331 for almost 8 Billion scenes) covering all seasons, most surface types, different world zones and most cloud types (In this paper, we shall refer to pixel as the single element of the image matrix provided by the sensor with its field of view, including the corresponding geographical coordinates, and to scene as the set of corresponding information for that pixel, namely spectral radiance, sky condition, surface, climatic zone). The key data of the exercise is a set of 1350 scenes, blind to participants that have been manually labelled by experts, claimed to sample the most important types of clouds (
gold standard). A more detailed description of the exercise and main conclusions are reported in [
4].
The framework proposed by the authors for the Round Robin exercise includes a statistical classification method (Cumulative Discriminant Analysis, CDA [
5]), a training set semi-automatically obtained from cloud masks estimated for concurrent sensors, and grouping data in almost homogeneous surface types. In particular, our framework was the only one within the exercise that did not use a manual dataset obtained by expert annotation to train the classification. Instead it was relying on a semi-automatic training obtained as the result of consolidated and acknowledged as reliable cloud masks with comparable spatial resolution as the target cloud mask (MODIS and SEVIRI). The only intervention required is spatial and temporal co-registration of the training cloud mask with the target cloud mask. In view of the fact that this training cloud mask is not obtained by expert judgement but by another algorithm, it will be defined as a
silver standard. On the one hand quality of the silver standard cannot be compared with the accuracy of a gold standard. However, in this respect we also recall that even very accurate cloud masks annotated by experts are affected by judgement error that in best cases is estimated around 4–7% [
3]. On the other hand, the much larger size of the training dataset and its wide coverage can represent a much larger number of cloud and surface conditions. This result cannot be obtained by manual training, naturally limited by human resources. This strategy appears in our opinion as a natural path when methods requiring large training datasets are involved. It is mainly the case of deep learning algorithms. In this respect we mention [
6] who use the results of an algorithm (CFMask [
3]) to train their deep RS-Net model for Landsat 8 images, and [
7] based on AVIRIS cloud mask. Massive use of such a silver standard dataset for cloud detection was pioneered in [
8] in our knowledge.
Another qualifying part of our framework was grouping of scenes into homogeneous zones selected basing on the surface type. It is frequent that algorithms for cloud detection are trained separately for different types of the underlying surface (e.g., land or water); other approaches are possible, for example introducing climatic information as in [
5].
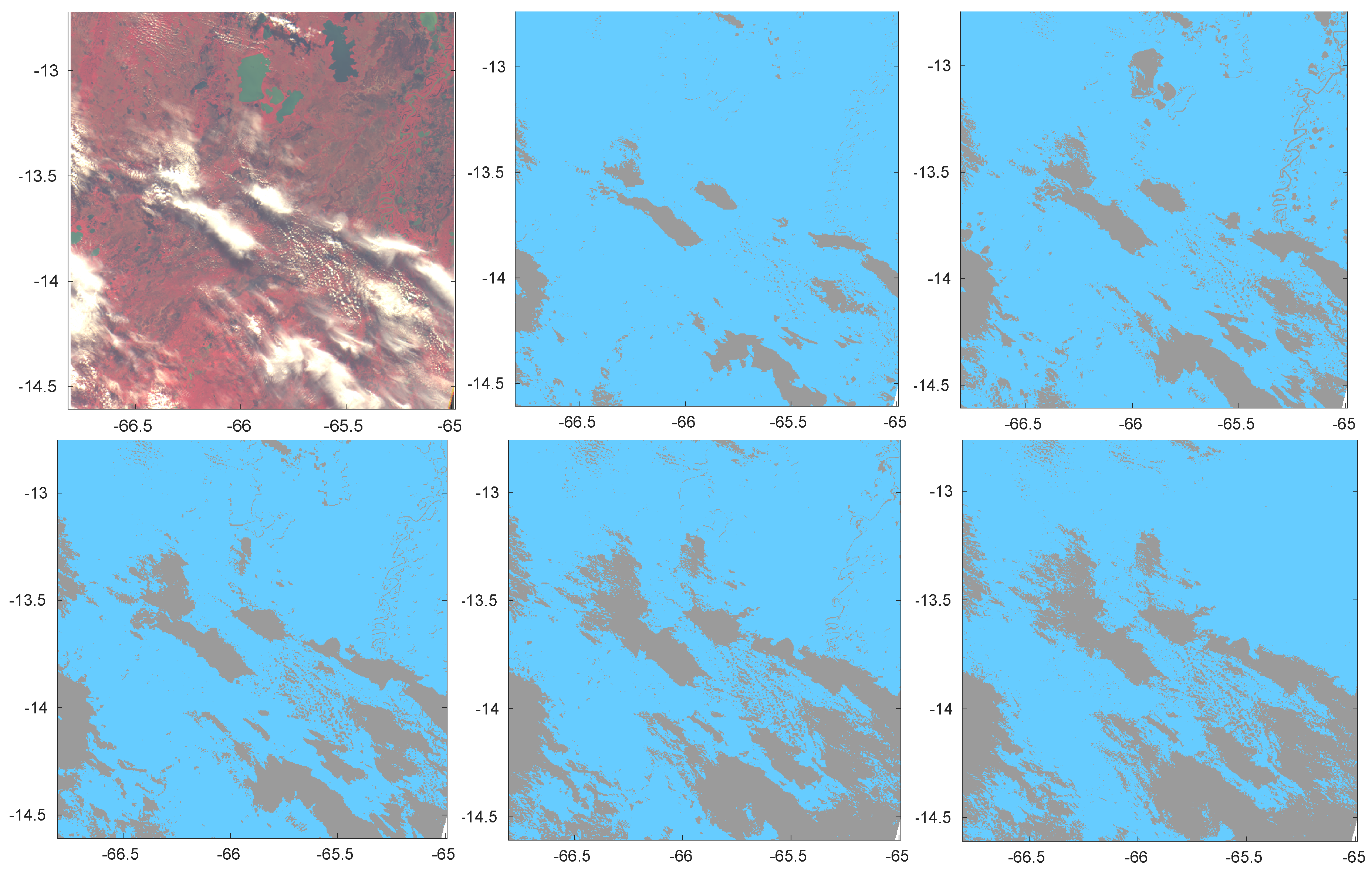
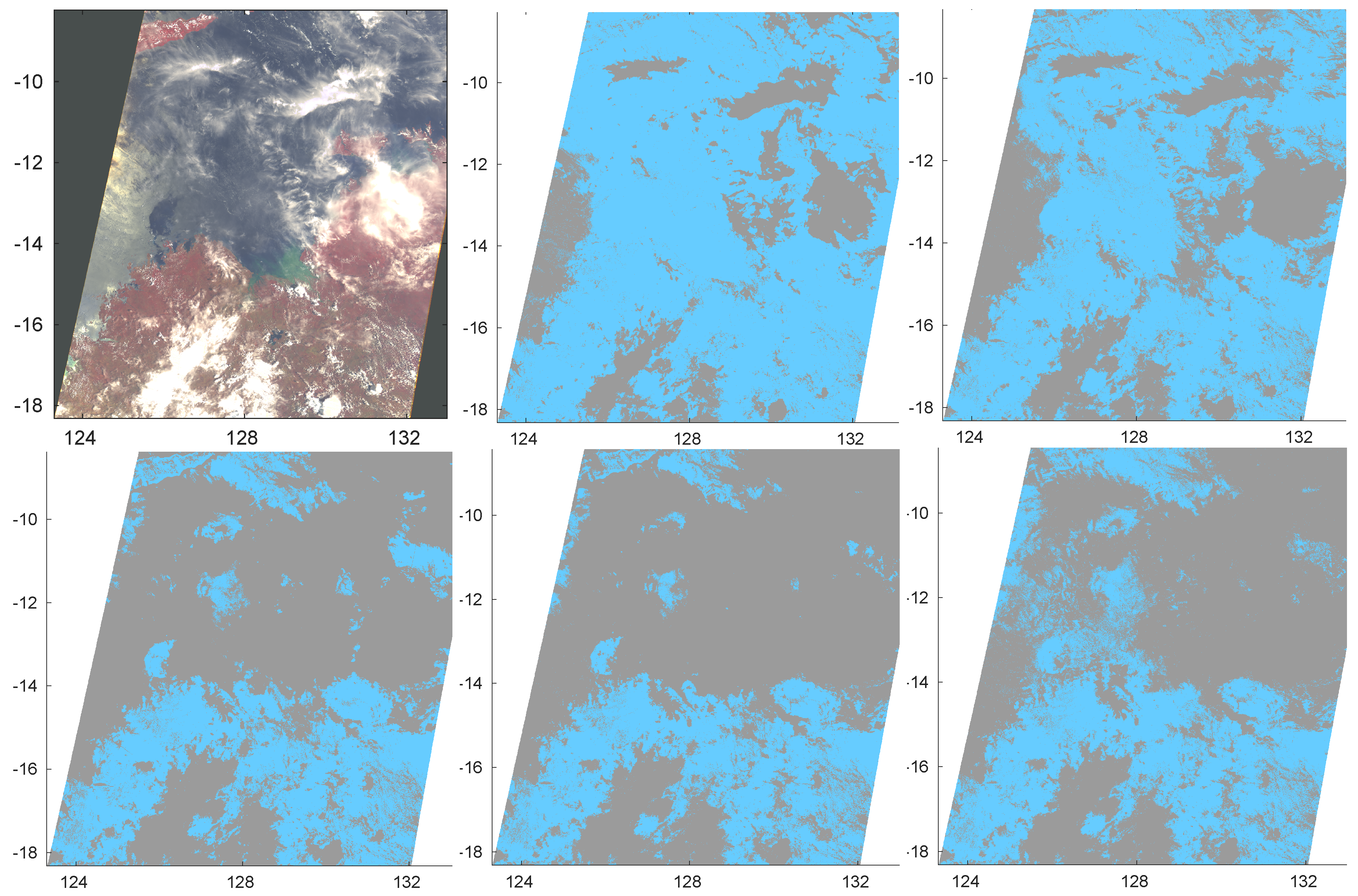
Aim of the present paper is first to show a full and detailed analysis of our framework and of the results within the Round Robin exercise, assessing its performance under several cloud and surface conditions.
In addition the availability of a very accurate gold standard allows one to quantitatively analyze weaknesses and strengths of cloud detection under a framework in which also the same training dataset is shared among classification methods. In particular, we address the following questions: (a) to compare prototypes of selected cloud detection algorithms well known in the literature; (b) to assess the feasibility of a silver standard to train cloud detection; (c) to assess the role of surface and/or climatic information on the accuracy of cloud detection. Finally, a consensus analysis is performed aimed at estimating the degree of mutual agreement among classification methods in detecting Clear or Cloudy sky conditions.
3. Classification Methods
Cloud detection can be formally considered to be a binary supervised classification problem. As such, methods for its solution need a representative set of data with labels considered to be “certain” (training dataset). They evaluate patterns in different features and assign data into one of the two classes (Clear or Cloudy). The classification procedure also involves collection and evaluation of a validation dataset. Once trained, each classifier applies a decision rule to determine if validation data are more likely to have originated from one class or another. This rule partitions the n-dimensional feature space into 2 regions corresponding to the Clear and Cloudy conditions.
Operational cloud-masking algorithms on low/moderate-resolution sensors such as AVHRR and MODIS were mainly based on empirically tuned thresholds from several spectral channels. Also, for higher spectral resolution sensors (Landsat), thermal channel-based spectral thresholding along with prior knowledge of land surface properties has been the most common approach for automatic cloud detection. However, the payload of several recent sensors does not include thermal channels in which cloud-masking strategies have previously relied, so that different approaches, somewhat relying on complementary information have been pursued. Among the many methods and available implementations from the recent literature, we mention here a few significant ones. Taravat et al. [
17] propose a Multilayer Perceptron for automatic classification of SEVIRI MSG images trained on the cloud mask by the European Organization for the Exploitation of Meteorological Satellites; Chen et al. [
18] implement a neural network classifier driven by extensive radiative transfer simulations and validate it through collocated CALIOP and MODIS data. In [
19], a Support Vector Machine classifier is trained on the Gabor energy characteristics of cloud superpixels from GF-1 images, while in [
20] algorithms for Sentinel-2 MSI focused on Decision Trees and classical Bayesian classification are considered. Sedano et al. [
21] propose a method based on the estimation of Clear/Cloudy radiance density distributions in a data fusion framework, followed by a region growing process and validate their results against both cloud masks generated by statistical methods and Landsat operational cloud mask. Finally, deep learning methods are increasingly considered, with several different approaches: in [
22] a multi-modal, pixel-level Convolutional Neural Network-based classifier is introduced for detecting clouds in medium- and high-resolution remote-sensing images, which relies on a large number of per-pixel cloud masks digitized by experts; Francis et al. [
23] use multi-scale features, based on a Fully Convolutional Network architecture, and report results on manually annotated images from two high-resolution sensors. An image-based approach is described in [
24], relying on multi-modal, high-resolution satellite imagery (PlanetScope, Sentinel-2) at the scene level. Many of these methods rely on expert intervention for labelling training data. As mentioned in the Introduction, we focus instead on automatic means of assigning labels to the training and validation datasets (silver standard), allowing for adjustments of decision boundaries independent of subjective and costly human intervention. In addition, they can cover more general cases than manually possible ones and with a much larger extent, of course to the detriment of the decreased accuracy of labels.
Among the different approaches reported in the literature, we consider and compare for the present study seven different supervised classifiers. They fall into the categories usually labelled as Statistical and Machine Learning and are based on different principles, as Discriminant Analysis, Neural Networks, Nearest Neighbor. We mention that Neural Networks are the basis of Artificial Intelligence methods of present strong interest when the number of features is very high. In the following we briefly describe them.
Linear Discriminant Analysis (LDA). It applies the Bayes rule to each scene to select the Clear/Cloudy class so to maximize the posterior probability of the class for a scene given the actual reflectance in that scene. LDA assumes that reflectance follows Gaussian distributions for the Clear and Cloudy classes sharing the same covariance matrix;
Quadratic Discriminant Analysis (QDA), which generalizes LDA assuming that also covariance matrix depends on the class (Clear or Cloudy);
Principal Component Discriminant Analysis (PCDA) [
25]: the hypothesis of Gaussian distribution of reflectance is released in favor of a generic distribution estimated by nonparametric regression; in addition the original reflectances are transformed into uncorrelated Principal Components before classification;
Independent Component Discriminant Analysis (ICDA) [
25]: similar to PCDA, but with the original reflectances transformed into Independent Components before nonparametric estimation of the densities; this makes such components independent also for non-Gaussian distributions;
Cumulative Discriminant Analysis (CDA) [
5]: the decision rule for classification depends on a single threshold for each feature (spectral band), based on the empirical distribution function, which discriminates scenes belonging to the Clear and Cloudy classes; the threshold is estimated so to minimize at the same time the false positive and false negative rates on the training or on a validation dataset.
Artificial Neural Networks (ANN) [
26,
27,
28]. We use a two-layer feed-forward network, with sigmoid hidden and SoftMax output neurons for pattern recognition. The network is trained with scaled conjugate gradient backpropagation.
K-Nearest Neighbor (KNN) [
28,
29] that labels each considered scene based on a voting strategy among the labels assigned to the
K closest neighboring scenes belonging to the training dataset. We used
K = 50 throughout this study.
Methods LDA, QDA, PCDA, ICDA and CDA require estimate of the statistical distribution of radiance. We mention that other methods are available in the literature; results of some of them have not been reported because of poor accuracy on other sensors (Logistic Regression) or unfeasible computational time (Support Vector Machine).
All the above methods are pixel-wise, i.e., they treat pixels separately without taking account of spatial correlations among them or local features that are instead typical of images. Among the classification methods that use spatial features of images we mention [
30] (Markov chains), [
31] (Discriminant Analysis), [
32] (relying on PCANet and SVM). We also mention the special case of Artificial Intelligence Deep Learning algorithms (e.g., [
6,
23]).
Finally, we mention that the method proposed for the Round Robin exercise was CDA [
4].
5. Conclusions
The paper shows a detailed analysis of the method presented by one the authors in a Round Robin exercise organized by ESA for detecting clouds from images taken by the PROBA-V sensor. Availability of a common high-quality dataset of scenes labelled as Clear or Cloudy by experts (gold standard) is a unique benchmark for comparing different methods for detecting clouds and investigating on questions still open.
We considered some prototypes of methods and compared them under different frameworks but using a common training dataset for all of them. We demonstrated that CDA, chosen for participating in the Round Robin, was adequate yielding good accuracy. However, ANN and, particularly, KNN can both improve accuracy and better detect scenes with semi-transparent clouds. In addition, a silver standard training dataset, semi-automatically obtained by algorithms developed for other sensors, was proved to be effective in detecting clouds, yielding high accuracy. We stress that the silver standard dataset considered in this paper covers only a portion of the globe and that the majority of gold standard pixels are outside the region covered by the silver standard. Indeed a silver standard dataset is the only feasible solution to get very large training datasets needed to train Artificial Intelligence methods (see, e.g., [
7]).
Then, even though it was not possible to give a conclusive quantitative answer whether separate classifications based on ancillary information as surface types and/or climatic zones improve accuracy, a qualitative analysis shows that introducing such information reduces probability to misinterpret Clear/Cloudy condition on Water.
Finally, we performed a consensus analysis aimed at estimating the degree of mutual agreement among classification methods in detecting Clear or Cloudy sky. The result was that a selection of 4 classification methods agree on the status of Clear or Cloudy sky for about 83% of scenes. PCDA and CDA show the highest disagreement with the consensus of the other 3 methods and KNN the lowest disagreement. This result is consistent with the findings on accuracy.
Results shown in the paper strictly refer to sensors with a very low number of spectral bands. Other sensors, especially hyper-spectral, or at higher/lower spatial resolutions need a specific similar analysis that will probably give very different results.
Results of the paper suggest possible future investigations. a) The use of different methods for different surfaces or climatic zones: this study demonstrated that some methods could be more suited for particular surfaces or climatic zones when we consider global accuracy or specific accuracy for Clear or Cloudy conditions. b) Balancing of cloud/Clear conditions: this largely depends on the training dataset and on the fraction of Clear/Cloudy scenes included. Then the classification methods will generally and naturally favor the most populated class when Clear and Cloudy features overlap, so to improve global accuracy. However commonly remotely sensed images can refer to conditions that are prevalently Clear or prevalently Cloudy that could benefit from a training dataset or a classification method that weights scenes according to the different proportion of Clear/Cloudy conditions in the region. CDA is an attempt into this direction, even though in a global way, and Discriminant Analysis is naturally prone to include such weights, simulating a balancing of Clear and Sky conditions different from the training dataset. c) To use images instead of independent pixels in the classification, so to exploit spatial correlation (that clouds indeed possess) and/or equivalently spatial features. In this respect Artificial Intelligence methods, already available in the literature but not considered in this paper, become interesting also for a small number of spectral bands.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}