Bearing Fault Diagnosis of Induction Motors Using a Genetic Algorithm and Machine Learning Classifiers




Abstract
1. Introduction
- (i)
- Condition monitoring and fault classification of induction motors utilizing motor current signal analysis approach
- (ii)
- Utilization of GA to select significant features from a collection of time-domain features and ensure acceptable results from the reduced feature set with the inclusive model.
- (iii)
- This work investigates optimization parameters for GA as well as for the three different classifiers, k-nearest neighbor (KNN), decision trees (DT), and random forest (RF), to achieve good performance in comparison with other researches.
2. Materials and Methods
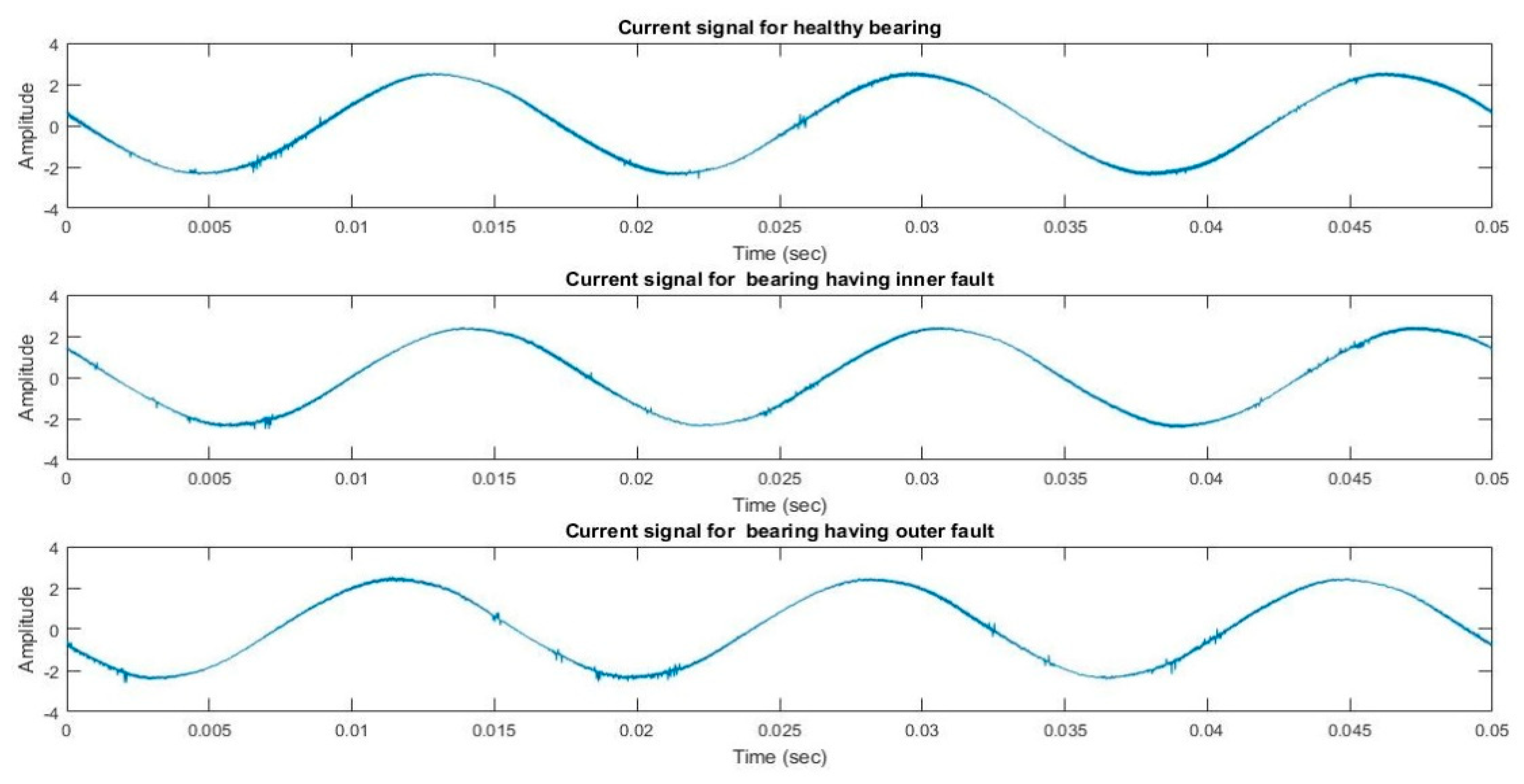
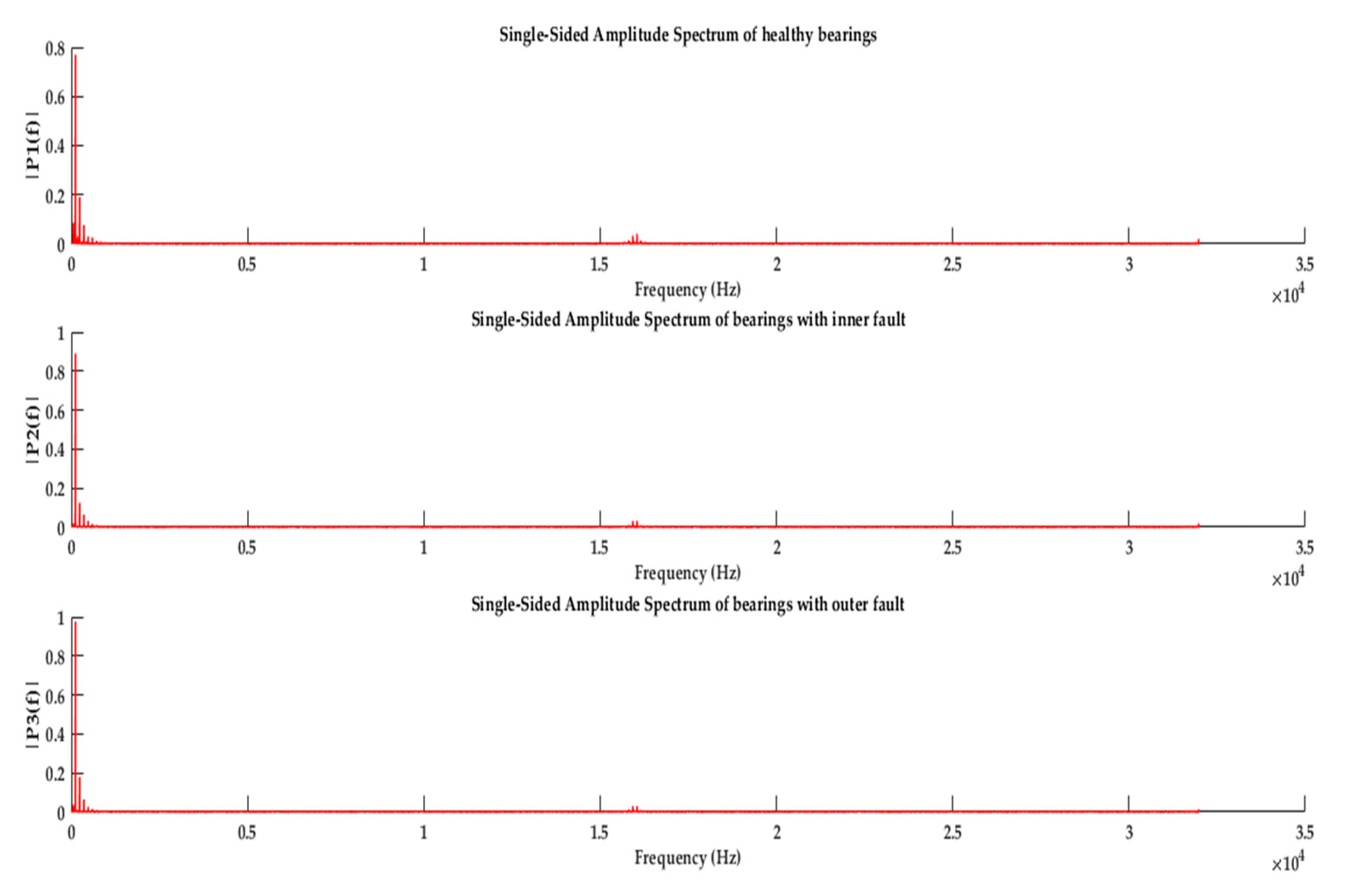
2.1. Bearing Fault Signatures
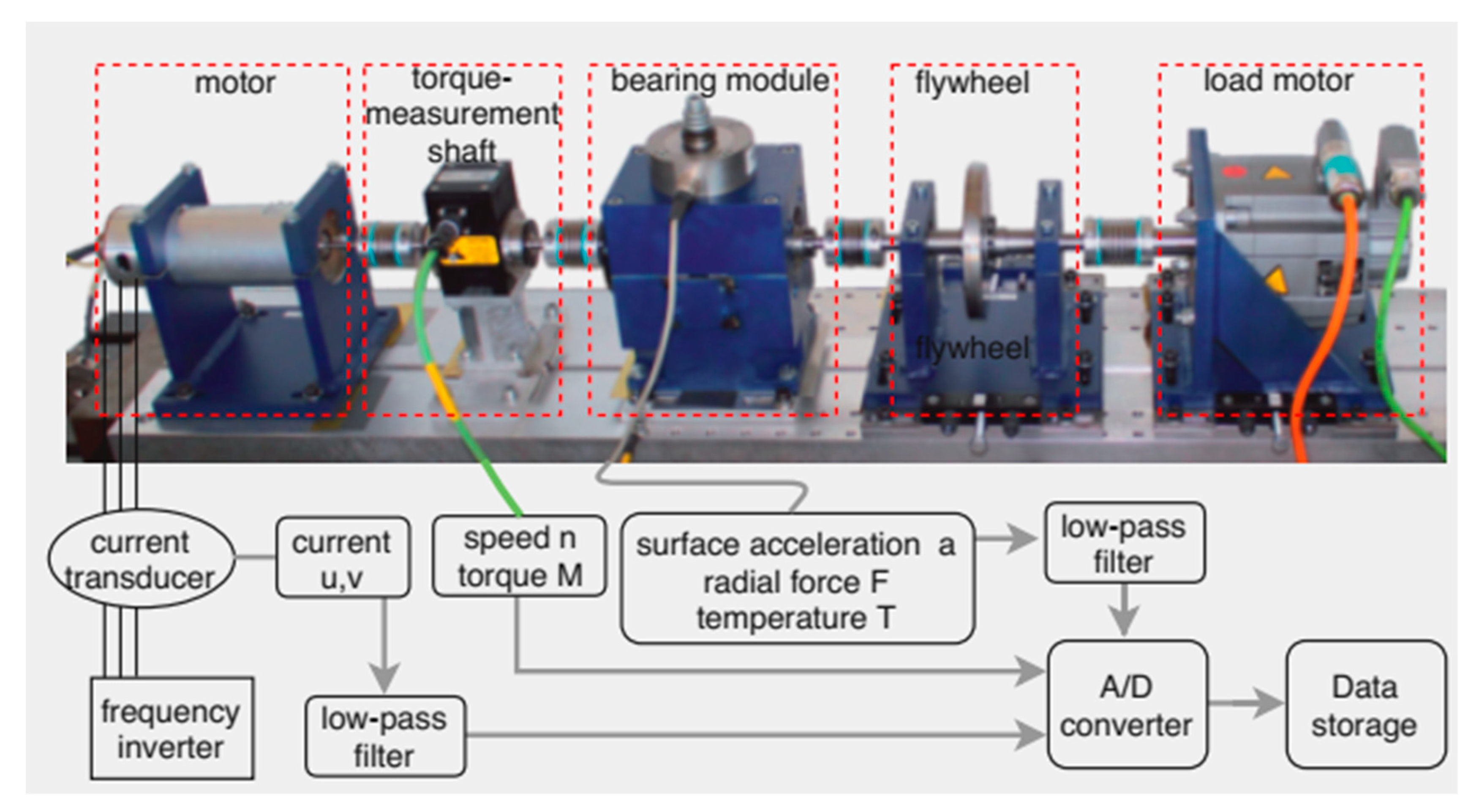
2.2. Experimental Testbed and Dataset Acquisition
2.3. Feature Extraction
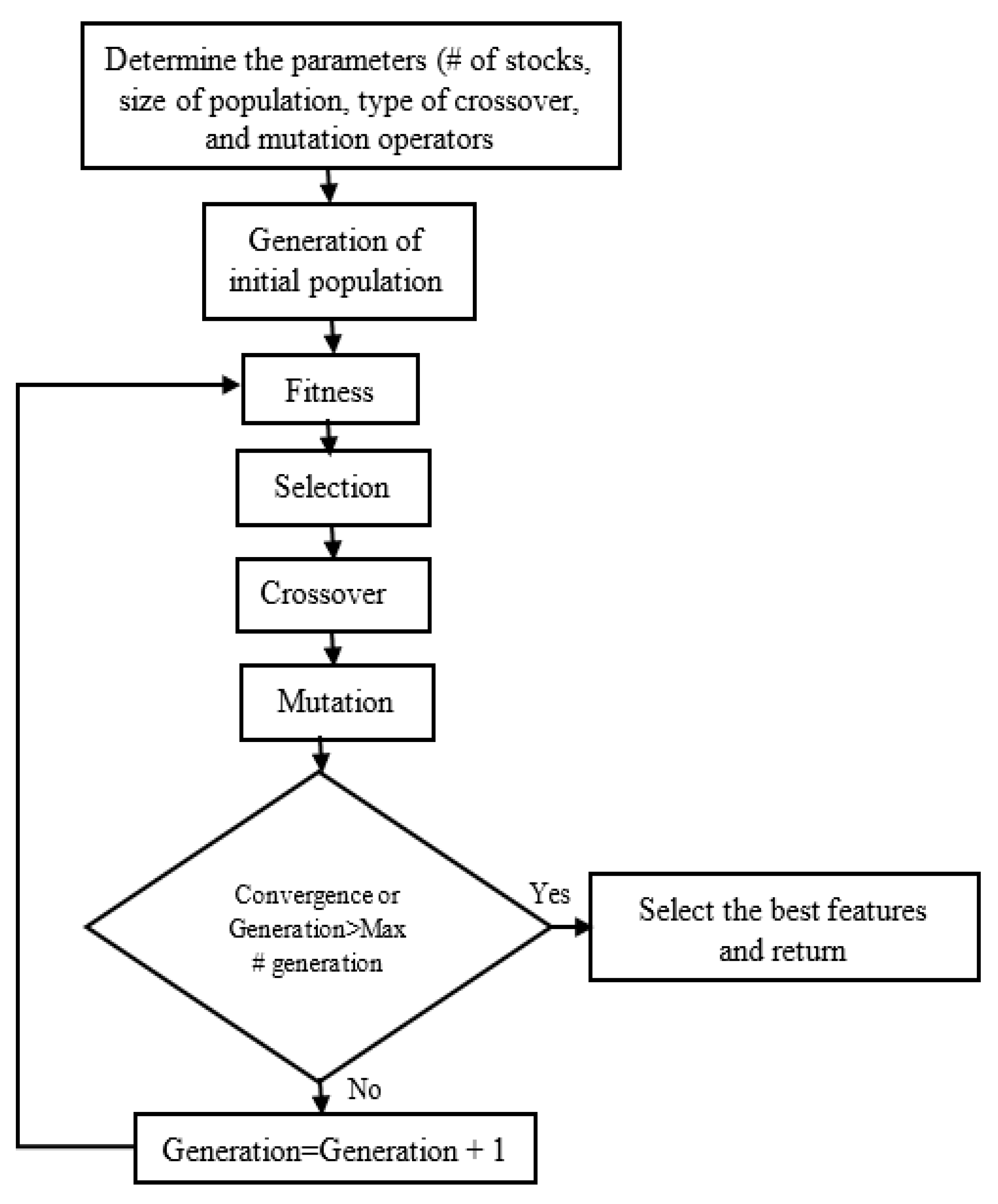
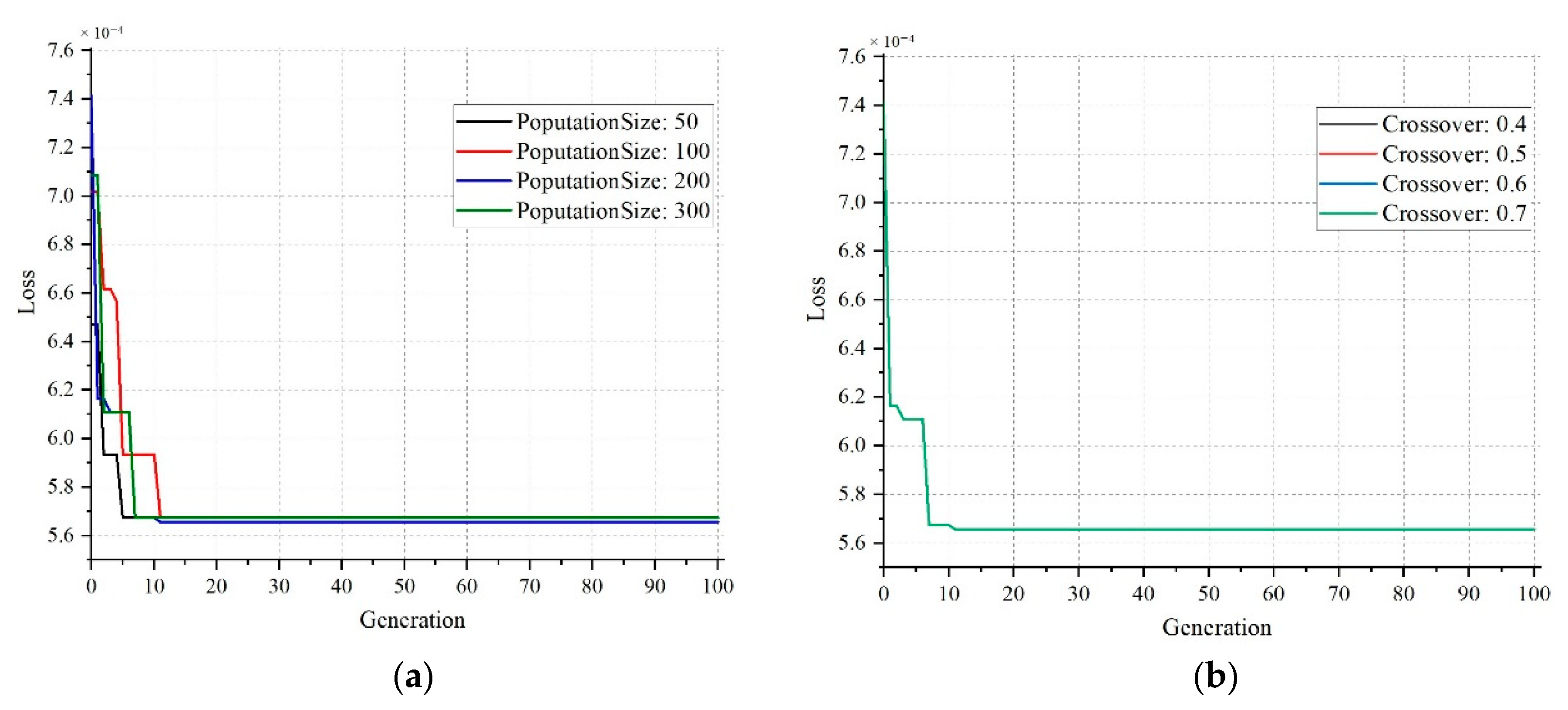
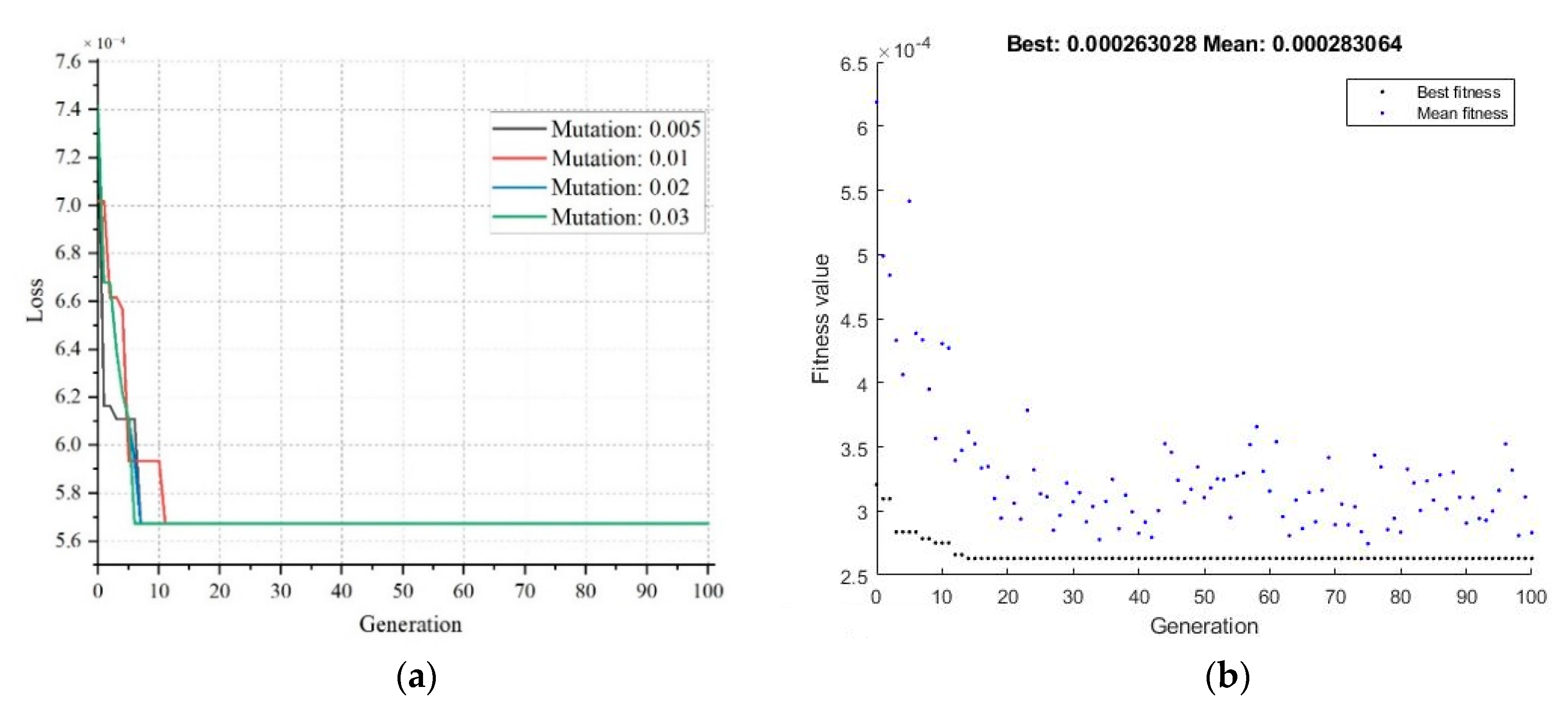
2.4. Feature Selection with Genetic Algorithm
2.5. K-nearest Neighbor (KNN)
2.6. Decision Tree
2.7. Random Forest
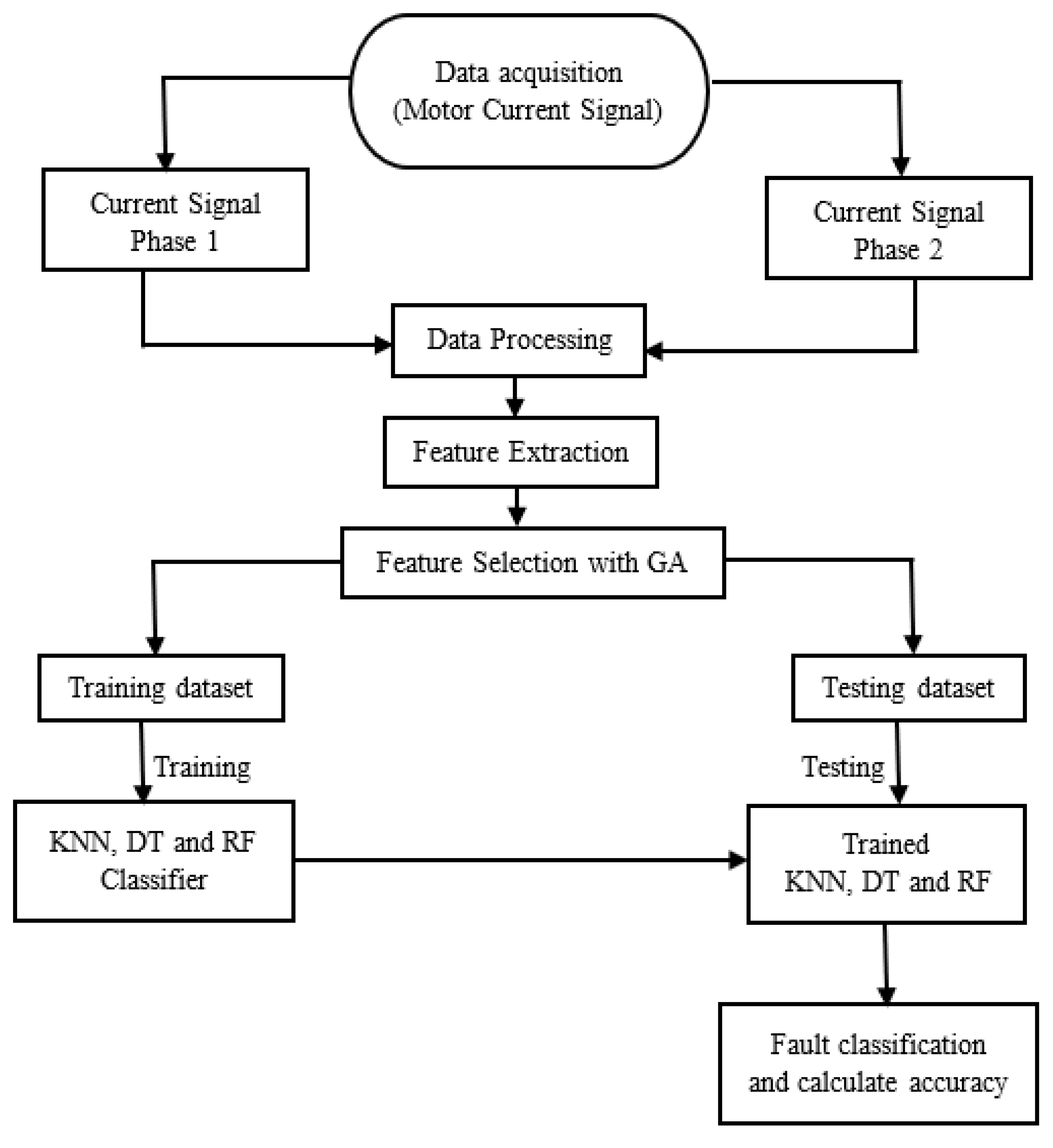
2.8. Proposed Method
2.9. Model Evaluation
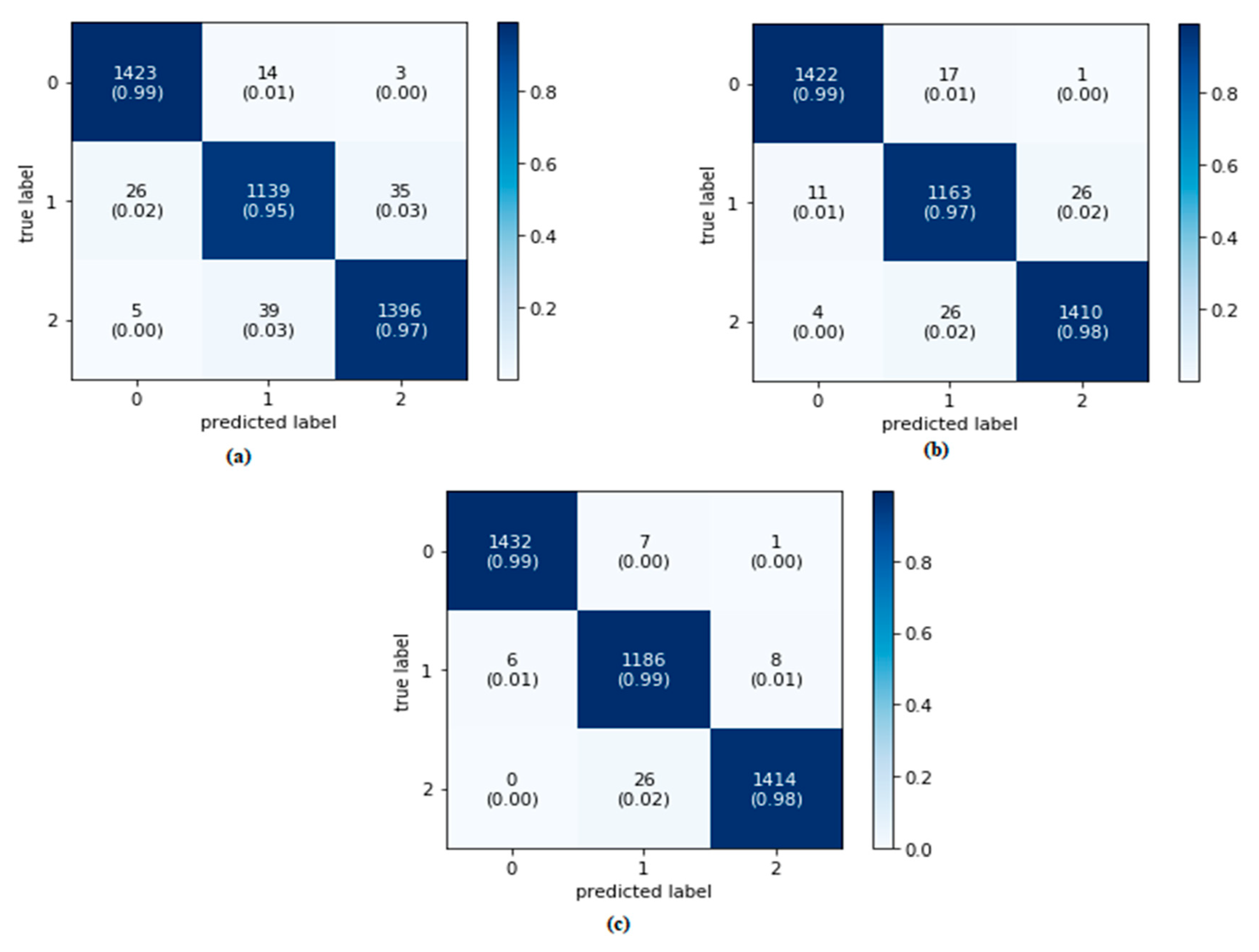
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Abd-el-Malek, M.; Abdelsalam, A.K.; Hassan, O.E. Induction motor broken rotor bar fault location detection through envelope analysis of start-up current using Hilbert transform. Mech. Syst. Signal Process. 2017, 93, 332–350. [Google Scholar] [CrossRef]
- Mehrjou, M.R.; Mariun, N.; Marhaban, M.H.; Misron, N. Rotor fault condition monitoring techniques for squirrel-cage induction machine—A review. Mech. Syst. Signal Process. 2011, 25, 2827–2848. [Google Scholar] [CrossRef]
- Han, T.; Yang, B.-S.; Choi, W.-H.; Kim, J.-S. Fault diagnosis system of induction motors based on neural network and genetic algorithm using stator current signals. Int. J. Rotat. Mach. 2006, 2006, 61690. [Google Scholar] [CrossRef]
- Mbo’o, C.P.; Hameyer, K. Fault diagnosis of bearing damage by means of the linear discriminant analysis of stator current features from the frequency selection. IEEE Trans. Ind. Appl. 2016, 52, 3861–3868. [Google Scholar] [CrossRef]
- Singh, G. Induction machine drive condition monitoring and diagnostic research—A survey. Electr. Power Syst. Res. 2003, 64, 145–158. [Google Scholar] [CrossRef]
- Randall, R.B.; Antoni, J. Rolling element bearing diagnostics—A tutorial. Mech. Syst. Signal Process. 2011, 25, 485–520. [Google Scholar] [CrossRef]
- Sinha, J.K.; Elbhbah, K. A future possibility of vibration based condition monitoring of rotating machines. Mech. Syst. Signal Process. 2013, 34, 231–240. [Google Scholar] [CrossRef]
- Siegel, D.; Ly, C.; Lee, J. Methodology and framework for predicting helicopter rolling element bearing failure. IEEE Trans. Reliab. 2012, 61, 846–857. [Google Scholar] [CrossRef]
- Zhen, L.; Zhengjia, H.; Yanyang, Z.; Xuefeng, C. Bearing condition monitoring based on shock pulse method and improved redundant lifting scheme. Math. Comput. Simul. 2008, 79, 318–338. [Google Scholar] [CrossRef]
- Cabal-Yepez, E.; Garcia-Ramirez, A.G.; Romero-Troncoso, R.J.; Garcia-Perez, A.; Osornio-Rios, R.A. Reconfigurable monitoring system for time-frequency analysis on industrial equipment through STFT and DWT. IEEE Trans. Ind. Inform. 2012, 9, 760–771. [Google Scholar] [CrossRef]
- Lau, E.C.; Ngan, H. Detection of motor bearing outer raceway defect by wavelet packet transformed motor current signature analysis. IEEE Trans. Instrum. Meas. 2010, 59, 2683–2690. [Google Scholar] [CrossRef]
- Obeid, Z.; Poignant, S.; Régnier, J.; Maussion, P. Stator current based indicators for bearing fault detection in synchronous machine by statistical frequency selection. In Proceedings of the IECON 2011—37th Annual Conference of the IEEE Industrial Electronics Society, Melbourne, Australia, 7–10 November 2011; pp. 2036–2041. [Google Scholar]
- Wang, Z.; Chang, C. Online fault detection of induction motors using frequency domain independent components analysis. In Proceedings of the 2011 IEEE International Symposium on Industrial Electronics, Gdansk, Poland, 27–30 June 2011; pp. 2132–2137. [Google Scholar]
- Tian, J.; Morillo, C.; Azarian, M.H.; Pecht, M. Motor bearing fault detection using spectral kurtosis-based feature extraction coupled with K-nearest neighbor distance analysis. IEEE Trans. Ind. Electr. 2015, 63, 1793–1803. [Google Scholar] [CrossRef]
- Delgado, M.; Cirrincione, G.; Garcia, A.; Ortega, J.; Henao, H. A novel condition monitoring scheme for bearing faults based on curvilinear component analysis and hierarchical neural networks. In Proceedings of the 2012 XXth International Conference on Electrical Machines, Marseille, France, 2–5 September 2012; pp. 2472–2478. [Google Scholar]
- Jin, X.; Zhao, M.; Chow, T.W.; Pecht, M. Motor bearing fault diagnosis using trace ratio linear discriminant analysis. IEEE Trans. Ind. Electr. 2013, 61, 2441–2451. [Google Scholar] [CrossRef]
- Zhou, W.; Lu, B.; Habetler, T.G.; Harley, R.G. Incipient bearing fault detection via motor stator current noise cancellation using wiener filter. IEEE Trans. Ind. Appl. 2009, 45, 1309–1317. [Google Scholar] [CrossRef]
- Thollon, F.; Grellet, G.; Jammal, A. Asynchronous motor cage fault detection through electromagnetic torque measurement. Eur. Trans. Electr. Power 1993, 3, 375–378. [Google Scholar] [CrossRef]
- Elasha, F.; Greaves, M.; Mba, D.; Addali, A. Application of acoustic emission in diagnostic of bearing faults within a helicopter gearbox. Procedia CIRP 2015, 38, 30–36. [Google Scholar] [CrossRef]
- Stone, G. The use of partial discharge measurements to assess the condition of rotating machine insulation. IEEE Electr. Insul. Mag. 1996, 12, 23–27. [Google Scholar] [CrossRef]
- Beguenane, R.; Benbouzid, M.E.H. Induction motors thermal monitoring by means of rotor resistance identification. IEEE Trans. Energy Convers. 1999, 14, 566–570. [Google Scholar] [CrossRef]
- Naha, A.; Samanta, A.K.; Routray, A.; Deb, A.K. A method for detecting half-broken rotor bar in lightly loaded induction motors using current. IEEE Trans. Instrum. Meas. 2016, 65, 1614–1625. [Google Scholar] [CrossRef]
- Pons-Llinares, J.; Antonino-Daviu, J.A.; Riera-Guasp, M.; Pineda-Sanchez, M.; Climente-Alarcon, V. Induction motor diagnosis based on a transient current analytic wavelet transform via frequency B-splines. IEEE Trans. Ind. Electr. 2010, 58, 1530–1544. [Google Scholar] [CrossRef]
- Xu, B.; Sun, L.; Ren, H. A new criterion for the quantification of broken rotor bars in induction motors. IEEE Trans. Energy Convers. 2009, 25, 100–106. [Google Scholar] [CrossRef]
- Nejjari, H.; Benbouzid, M.E.H. Monitoring and diagnosis of induction motors electrical faults using a current Park’s vector pattern learning approach. IEEE Trans. Ind. Appl. 2000, 36, 730–735. [Google Scholar] [CrossRef]
- Ondel, O.; Boutleux, E.; Blanco, E.; Clerc, G. Coupling pattern recognition with state estimation using Kalman filter for fault diagnosis. IEEE Trans. Ind. Electr. 2011, 59, 4293–4300. [Google Scholar] [CrossRef]
- Ariff, M.; Pal, B.C. Coherency identification in interconnected power system—An independent component analysis approach. IEEE Trans. Power Syst. 2012, 28, 1747–1755. [Google Scholar] [CrossRef]
- Mehrabian, H.; Chopra, R.; Martel, A.L. Calculation of intravascular signal in dynamic contrast enhanced-MRI using adaptive complex independent component analysis. IEEE Trans. Med. Imaging 2012, 32, 699–710. [Google Scholar] [CrossRef]
- Razavian, M.; Hosseini, M.H.; Safian, R. Time-reversal imaging using one transmitting antenna based on independent component analysis. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1574–1578. [Google Scholar] [CrossRef]
- Widodo, A.; Yang, B.-S.; Han, T. Combination of independent component analysis and support vector machines for intelligent faults diagnosis of induction motors. Expert Syst. Appl. 2007, 32, 299–312. [Google Scholar] [CrossRef]
- Altaf, S.; Soomro, M.W.; Mehmood, M.S. Fault diagnosis and detection in industrial motor network environment using knowledge-level modelling technique. Model. Simul. Eng. 2017, 2017, 1292190. [Google Scholar] [CrossRef]
- Skowron, M.; Wolkiewicz, M.; Orlowska-Kowalska, T.; Kowalski, C.T. Application of self-organizing neural networks to electrical fault classification in induction motors. Appl. Sci. 2019, 9, 616. [Google Scholar] [CrossRef]
- Samanta, B.; Al-Balushi, K. Artificial neural network based fault diagnostics of rolling element bearings using time-domain features. Mech. Syst. Signal Process. 2003, 17, 317–328. [Google Scholar] [CrossRef]
- Puche-Panadero, R.; Pons-Llinares, J.; Climente-Alarcon, V.; Pineda-Sanchez, M. Review diagnosis methods of induction electrical machines based on steady state current. Phys. Rev. D 2004, 1–5. [Google Scholar]
- Appana, D.K.; Prosvirin, A.; Kim, J.-M. Reliable fault diagnosis of bearings with varying rotational speeds using envelope spectrum and convolution neural networks. Soft Comput. 2018, 22, 6719–6729. [Google Scholar] [CrossRef]
- Sohaib, M.; Kim, C.-H.; Kim, J.-M. A hybrid feature model and deep-learning-based bearing fault diagnosis. Sensors 2017, 17, 2876. [Google Scholar] [CrossRef] [PubMed]
- Chuanlei, Z.; Shanwen, Z.; Jucheng, Y.; Yancui, S.; Jia, C. Apple leaf disease identification using genetic algorithm and correlation based feature selection method. Int. J. Agric. Biol. Eng. 2017, 10, 74–83. [Google Scholar]
- Aalaei, S.; Shahraki, H.; Rowhanimanesh, A.; Eslami, S. Feature selection using genetic algorithm for breast cancer diagnosis: Experiment on three different datasets. Iran. J. Basic Med. Sci. 2016, 19, 476. [Google Scholar] [PubMed]
- Noori, F.M.; Naseer, N.; Qureshi, N.K.; Nazeer, H.; Khan, R.A. Optimal feature selection from fNIRS signals using genetic algorithms for BCI. Neurosci. Lett. 2017, 647, 61–66. [Google Scholar] [CrossRef]
- Bidi, N.; Elberrichi, Z. Feature selection for text classification using genetic algorithms. In Proceedings of the 2016 8th International Conference on Modelling, Identification and Control (ICMIC), Algiers, Algeria, 15–17 November 2016; pp. 806–810. [Google Scholar]
- Cerrada, M.; Zurita, G.; Cabrera, D.; Sánchez, R.-V.; Artés, M.; Li, C. Fault diagnosis in spur gears based on genetic algorithm and random forest. Mech. Syst. Signal Process. 2016, 70, 87–103. [Google Scholar] [CrossRef]
- Fred, B.; Oswald, E.V.Z.; Poplawski, J. Effect of internal clearance on load distribution and life of radially loaded ball and roller bearings. Tribol. Trans. 2012, 55, 245–265. [Google Scholar] [CrossRef]
- Cerrada, M.; Sánchez, R.-V.; Li, C.; Pacheco, F.; Cabrera, D.; de Oliveira, J.V.; Vásquez, R.E. A review on data-driven fault severity assessment in rolling bearings. Mech. Syst. Signal Process. 2018, 99, 169–196. [Google Scholar] [CrossRef]
- Blodt, M.; Granjon, P.; Raison, B.; Rostaing, G. Models for bearing damage detection in induction motors using stator current monitoring. IEEE Trans. Ind. Electr. 2008, 55, 1813–1822. [Google Scholar] [CrossRef]
- Jung, J.-H.; Lee, J.-J.; Kwon, B.-H. Online diagnosis of induction motors using MCSA. IEEE Trans. Ind. Electr. 2006, 53, 1842–1852. [Google Scholar] [CrossRef]
- Yang, T.; Pen, H.; Wang, Z.; Chang, C.S. Feature knowledge based fault detection of induction motors through the analysis of stator current data. IEEE Trans. Instrum. Meas. 2016, 65, 549–558. [Google Scholar] [CrossRef]
- Lessmeier, C.; Kimotho, J.K.; Zimmer, D.; Sextro, W. Condition monitoring of bearing damage in electromechanical drive systems by using motor current signals of electric motors: A benchmark data set for data-driven classification. In Proceedings of the European Conference of the Prognostics and Health Management Society, Bilbao, Spain, 5–8 July 2016; pp. 5–8. [Google Scholar]
- Kang, M.; Islam, M.R.; Kim, J.; Kim, J.-M.; Pecht, M. A hybrid feature selection scheme for reducing diagnostic performance deterioration caused by outliers in data-driven diagnostics. IEEE Trans. Ind. Electr. 2016, 63, 3299–3310. [Google Scholar] [CrossRef]
- Hasan, M.J.; Kim, J.-M. Fault detection of a spherical tank using a genetic algorithm-based hybrid feature pool and k-nearest neighbor algorithm. Energies 2019, 12, 991. [Google Scholar] [CrossRef]
- Islam, R.; Khan, S.A.; Kim, J.-M. Discriminant feature distribution analysis-based hybrid feature selection for online bearing fault diagnosis in induction motors. J. Sens. 2016, 2016, 7145715. [Google Scholar] [CrossRef]
- Moosavian, A.; Ahmadi, H.; Tabatabaeefar, A.; Khazaee, M. Comparison of two classifiers; K-nearest neighbor and artificial neural network, for fault diagnosis on a main engine journal-bearing. Shock Vib. 2013, 20, 263–272. [Google Scholar] [CrossRef]
- Hoang, D.T.; Kang, H.J. A motor current signal based bearing fault diagnosis using deep learning and information fusion. IEEE Trans. Instrum. Meas. 2019. [Google Scholar] [CrossRef]
- Hsueh, Y.-M.; Ittangihal, V.R.; Wu, W.-B.; Chang, H.-C.; Kuo, C.-C. Fault diagnosis system for induction motors by CNN using empirical wavelet transform. Symmetry 2019, 11, 1212. [Google Scholar] [CrossRef]
- Suh, S.; Lee, H.; Jo, J.; Lukowicz, P.; Lee, Y.O. Generative oversampling method for imbalanced data on bearing fault detection and diagnosis. Appl. Sci. 2019, 9, 746. [Google Scholar] [CrossRef]
- Lee, J.-H.; Pack, J.-H.; Lee, I.-S. Fault diagnosis of induction motor using convolutional neural network. Appl. Sci. 2019, 9, 2950. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Rotational Speed (S) [rpm] | Load Torque (M) [Nm] | Radial Force (F) [N] |
|---|---|---|---|
| 1 | 1500 | 0.7 | 1000 |
| 2 | 900 | 0.7 | 1000 |
| 3 | 1500 | 0.1 | 1000 |
| 4 | 1500 | 0.7 | 400 |
| Type of Bearing | Bearing Code | Label | |
|---|---|---|---|
| Healthy Bearing Data | K001 | 0 | |
| K002 | |||
| K003 | |||
| K004 | |||
| K005 | |||
| K006 | |||
| Naturally Damaged Bearing Data | Outer Ring | KA04 | 1 |
| KA15 | |||
| KA16 | |||
| KA22 | |||
| KA30 | |||
| Inner Ring | KI04 | 2 | |
| KI14 | |||
| KI16 | |||
| KI17 | |||
| KI18 | |||
| KI21 | |||
| Statistical Feature | Equation | Statistical Feature | Equation | ||
|---|---|---|---|---|---|
| Mean: | (7) | Skewness: | (8) | ||
| Median: | (9) | Kurtosis: | (10) | ||
| Standard Deviation: | (11) | Energy: | E = | (12) | |
| Variance: | (13) | RMS: | (14) | ||
| Sum: | (15) | Crest factor: | (16) |
| (18) | (19) | ||
| (20) | (21) | ||
| (22) |
| Parameter Name. | Types/Values |
|---|---|
| Population Size. | 200 |
| Genome Length | 20 |
| Selection type | Roulette wheel |
| Crossover | 0.7 (Simple one-point crossover) |
| Mutation Probability | 0.03 (Uniform probability distribution) |
| Maximum Generation No. | 100 |
| Precision | F1-Score | Sensitivity | Specificity | Accuracy (%) | |
|---|---|---|---|---|---|
| KNN | 0.97 | 0.97 | 0.989 | 0.988 | 97.0 |
| DT | 0.98 | 0.98 | 0.989 | 0.994 | 98.0 |
| RF | 0.99 | 0.99 | 0.994 | 0.997 | 99.7 |
| KNN | DT | RF | ||||
|---|---|---|---|---|---|---|
| 2-phase signal | 1-phase signal | 2-phase signal | 1-phase signal | 2-phase signal | 1-phase signal | |
| Precision | 0.97 | 0.90 | 0.98 | 0.91 | 0.99 | 0.91 |
| F1-score | 0.97 | 0.90 | 0.98 | 0.91 | 0.99 | 0.91 |
| Sensitivity | 0.989 | 0.86 | 0.989 | 0.91 | 0.994 | 0.92 |
| Specificity | 0.998 | 0.95 | 0.994 | 0.96 | 0.997 | 0.96 |
| Accuracy (%) | 97 | 89.70 | 98 | 91.03 | 99.7 | 91.12 |
| Diagnosis Methods | Classification Accuracy (%) |
|---|---|
| MLP-based IF [52] | 98.3 |
| SVM-based IF [52] | 98.0 |
| KNN-based IF [52] | 97.7 |
| CNN with EWT [53] | 97.37 |
| CNN with generative oversampling (vibration signal) [54] | 88.0–99.0 |
| CNN (vibration signal) [55] | 98.0–100 |
| WPD + Ensemble learning [47] | 86.03 |
| GA + KNN | 97.0 |
| GA + DT | 98.0 |
| GA + RF | 99.7 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Toma, R.N.; Prosvirin, A.E.; Kim, J.-M. Bearing Fault Diagnosis of Induction Motors Using a Genetic Algorithm and Machine Learning Classifiers. Sensors 2020, 20, 1884. https://doi.org/10.3390/s20071884
Toma RN, Prosvirin AE, Kim J-M. Bearing Fault Diagnosis of Induction Motors Using a Genetic Algorithm and Machine Learning Classifiers. Sensors. 2020; 20(7):1884. https://doi.org/10.3390/s20071884
Chicago/Turabian StyleToma, Rafia Nishat, Alexander E. Prosvirin, and Jong-Myon Kim. 2020. "Bearing Fault Diagnosis of Induction Motors Using a Genetic Algorithm and Machine Learning Classifiers" Sensors 20, no. 7: 1884. https://doi.org/10.3390/s20071884
APA StyleToma, R. N., Prosvirin, A. E., & Kim, J.-M. (2020). Bearing Fault Diagnosis of Induction Motors Using a Genetic Algorithm and Machine Learning Classifiers. Sensors, 20(7), 1884. https://doi.org/10.3390/s20071884