A Time-efficient Multi-Protocol Probe Scheme for Fine-grain IoT Device Identification

Abstract
1. Introduction
- We discuss for the first time the balance challenge between protocol probe overhead and identification fineness during banner-based device identification and design a time-efficient multi-protocol probe scheme for fine-grain IoT device identification to solve this challenge.
- We proposed a reinforcement learning method to model the banner-based device identification process into a Markov decision process, and introduce a new optimal strategy generation method to improve the value iteration algorithm so as to generate the optimal multi-protocol probe sequence, and further obtain the optimal multi-protocol probe sequence segment by introducing the gain threshold of identification accuracy.
- We implemented the time-efficient multi-protocol probe prototype system, and generated the optimal multi-protocol probe sequence segment for 132,835 webcams, which could reduce the webcams’ brand and model identification time by 50.76%, and achieved the identification accuracy of 90.5% and 92.3% respectively. Meanwhile, we also verified the scalability of our scheme by evaluating router and printer respectively.
2. Related Work
3. Time-Efficient Multi-Protocol Probe Scheme
3.1. Motivation
3.2. Time-efficient Multi-Protocol Probe Framework
4. Sample Data Collection and Analysis
4.1. Banner-Based Device Identification Process
4.2. Sample Data Collection
4.2.1. The Construction of an IoT Device Fingerprint Database
4.2.2. The Results of IoT Device Identification
4.3. Sample Data Analysis
- 1)
- Among the ten protocol banners to identify webcam, the contained attribute information is complementary. E.g. if a protocol banners does not contain one attribute of the device, the other nine protocol banners have a higher probability of containing this attribute.
- 2)
- The probability of identifying device brand and model by only one protocol banner is low. In the process of identifying IoT devices, multiple protocols probe packets are required to jointly probe devices, so as to obtain protocol banners with richer device attributes.
- 3)
- Without considering the banner acquisition rate, the corresponding to each protocol banner is different. The protocol banner of Http_80 contains device attribute with the probability of more than 80%, while the protocol banner of DaHua_37777 and Http_81 contains the device attribute with the probability of less than 30%.
5. Optimal Multi-Protocol Probe Sequence Generation
5.1. Scheduling Model of Multi-Protocol Probe Sequence
5.2. Value Iteration Algorithm
| Algorithm 1 Value iteration algorithm |
| Input: E(S, A, P, R); S’; ; |
| //E(S, A, P, R): MDP quad |
| //S’: Special Identifying status set |
| //: Discount factor |
| //: Convergence threshold |
| Output: Optimal_Sequence |
| 1 ∀s∊S:V(s)=0; |
| 2 for t=1,2,… do |
| 3 ; |
| 4 if max s∊S |V(s)-V’(s)|<θ then |
| 5 break; |
| 6 else |
| 7 V=V’; |
| 8 end if |
| 9 end for |
| 10 for i∊S’ do |
| 11 for j∊A do |
| 12 ; |
| 13 end for |
| 14 //Sort a by Q |
| 15 |
| 16 end for |
| 17 Sequence=combine; |
| 18 return Sequence; |
6. Results
6.1. Prototype System Implementation
6.2. Performance Evaluation
6.2.1. Identification Accuracy
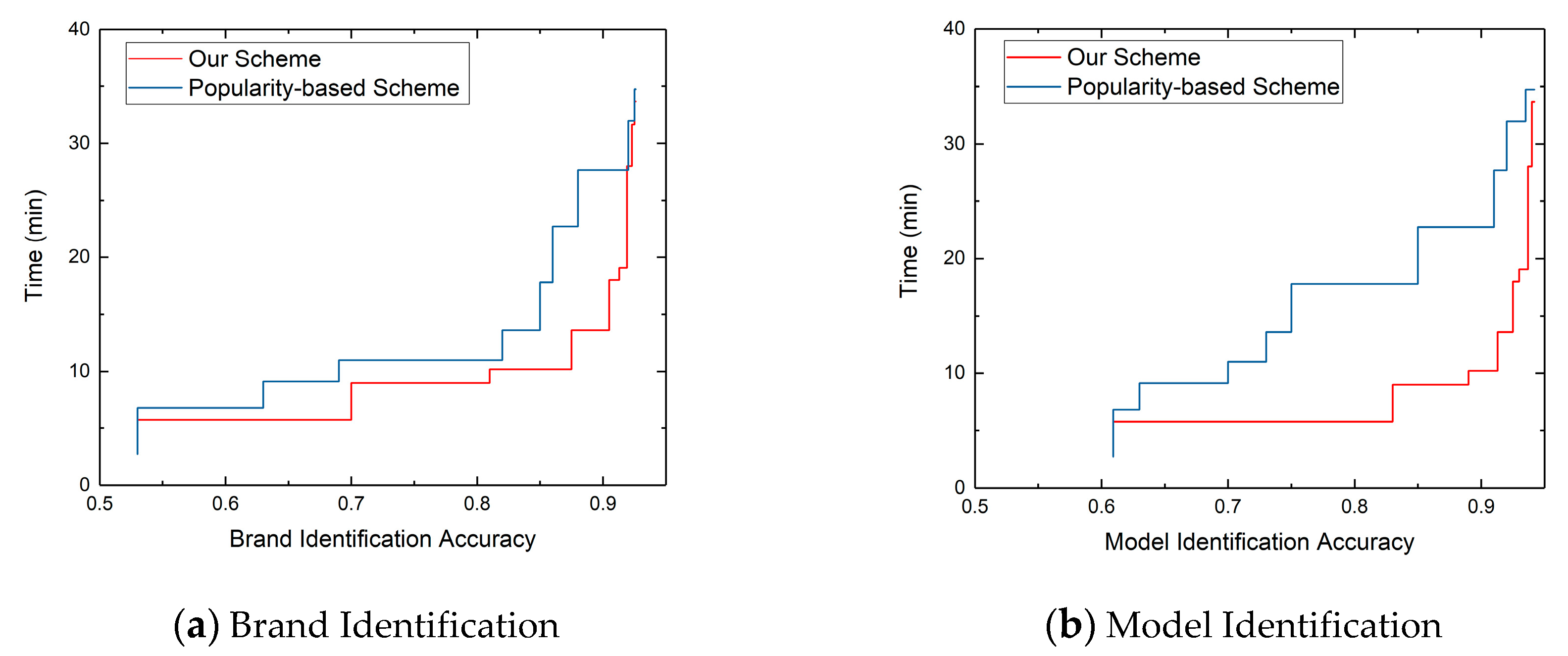
6.2.2. Time Efficiency
6.2.3. Scalability
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Huang, M.; Liu, A.; Xiong, N.; Wang, T.; Vasilakos, A. An Effective Service-Oriented Networking Management Architecture for 5G-Enabled Internet of Things. Comput. Netw. 2020, 107208. [Google Scholar] [CrossRef]
- Liu, X.; Zhao, S.; Liu, A.; Xiong, N.; Vasilakos, A.V. Knowledge-aware Proactive Nodes Selection approach for energy management in Internet of Things. Future Gener. Comput. Syst. 2019, 92, 1142–1156. [Google Scholar] [CrossRef]
- Internet of Things number of connected devices worldwide from 2015 to 2025. Available online: https://www.statista.com/statistics/471264/iot-number-of-connected-devices-worldwide/ (accessed on 6 February 2020).
- VPNFilter Malware Still Has Its Sights Set On Your Router. Available online: https://www.nextgov.com/ (accessed on 6 February 2020).
- Li, Q.; Feng, X.; Zhao, L.; Sun, L. A Framework for Searching Internet-Wide Devices. IEEE Netw. 2017, 31, 101–107. [Google Scholar] [CrossRef]
- Xuan, F.; Qiang, L.; Haining, W.; Limin, S. Characterizing industrial control system devices on the Internet. In Proceedings of the 2016 IEEE 24th International Conference on Network Protocols (ICNP), Singapore, 8–11 November 2016; pp. 1–10. [Google Scholar]
- Wang, S.; Bi, J.; Wu, J.; Vasilakos, A.V.; Fan, Q. VNE-TD: A virtual network embedding algorithm based on temporal-difference learning. Comput. Netw. 2019, 161, 251–263. [Google Scholar] [CrossRef]
- Huang, M.; Liu, A.; Xiong, N.N.; Wang, T.; Vasilakos, A.V. A Low-Latency Communication Scheme for Mobile Wireless Sensor Control Systems. IEEE Trans. 2019, 49, 317–332. [Google Scholar] [CrossRef]
- p0f v3 (version 3.09b). Available online: http://lcamtuf.coredump.cx/p0f3/ (accessed on 6 February 2020).
- Siswanto, A.; Syukur, A.; Kadir, E.A.; Suratin. Network Traffic Monitoring and Analysis Using Packet Sniffer. In Proceedings of the 2019 International Conference on Advanced Communication Technologies and Networking (CommNet), Rabat, Morocco, 12–14 April 2019; pp. 1–4. [Google Scholar]
- Auffret, P. SinFP, unification of active and passive operating system fingerprinting. J. Comput. Virology. 2010, 6, 197–205. [Google Scholar] [CrossRef]
- Xprobe2—A remote active operating system fingerprinting tool. Available online: https://linux.die.net/man/1/xprobe2 (accessed on 6 February 2020).
- Lyon, G.F. Nmap Network Scanning: The Official Nmap Project Guide to Network Discovery and Security Scanning; Insecure: Sunnyvale, CA, USA, 2009. [Google Scholar]
- Feng, X.; Li, Q.; Wang, H.; Sun, L. Acquisitional Rule-based Engine for Discovering Internet-of-Thing Devices. In Proceedings of the 27th USENIX Security, Baltimore, MD, USA, 15–17 August 2018; pp. 327–341. [Google Scholar]
- Li, Q.; Feng, X.; Wang, R.; Li, Z.; Sun, L. Towards Fine-grained Fingerprinting of Firmware in Online Embedded Devices. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 2537–2545. [Google Scholar]
- Li, Q.; Feng, X.; Zhi, L.; Wang, H.; Sun, L. GUIDE: Graphical user interface fingerprints physical devices. In Proceedings of the 2016 IEEE 24th International Conference on Network Protocols (ICNP), Singapore, 8–11 November 2016; pp. 1–2. [Google Scholar]
- Shaikh, F.; Bou-Harb, E.; Crichigno, J.; Ghani, N. A Machine Learning Model for Classifying Unsolicited IoT Devices by Observing Network Telescopes. In Proceedings of the 2018 14th International Wireless Communications & Mobile Computing Conference (IWCMC), Limassol, Cyprus, 25–29 June 2018; pp. 938–943. [Google Scholar]
- Shodan search engine. Available online: https://www.shodan.io (accessed on 6 February 2020).
- ZoomEye. Available online: https://www.zoomeye.org (accessed on 6 February 2020).
- Censys. Available online: https://censys.io/ (accessed on 6 February 2020).
- ModScan: A SCADA MODBUS Network Scanner. Available online: https://docplayer.net/9149440-Modscan-a-scada-modbus-network-scanner-mark-bristow-mark-bristow-gmail-com.html (accessed on 26 March 2020).
- Tool for scan PLC devices over s7comm or modbus protocols. Available online: https://code.google.com/archive/p/plcs-can/ (accessed on 6 February 2020).
- Wazid, M.; Das, A.K.; Kumar, N.; Vasilakos, A.V. Design of secure key management and user authentication scheme for fog computing services. Future Gener. Comput. Syst. 2019, 91, 475–492. [Google Scholar] [CrossRef]
- Scrapy. Available online: https://scrapy.org/ (accessed on 17 March 2020).
- Heydari, A. Stability Analysis of Optimal Adaptive Control under Value Iteration Using a Stabilizing Initial Policy. IEEE Trans. Neural Netw. Learn. Syst 2018, 29, 4522–4527. [Google Scholar] [CrossRef] [PubMed]
- Zidek, R.A.E.; Kolmanovsky, I.V. Drift counteraction optimal control for deterministic systems and enhancing convergence of value iteration. Automatica 2017, 83, 108–115. [Google Scholar] [CrossRef]
- Sun, G.; Xu, Z.; Yu, H.; Chen, X.; Chang, V.; Vasilakos, A.V. Low-latency and resource-efficient service function chaining orchestration in network function virtualization. IEEE Internet Things J. 2019, 1. [Google Scholar] [CrossRef]
- Sun, G.; Zhou, R.; Sun, J.; Yu, H.; Vasilakos, A.V. Energy-Efficient Provisioning for Service Function Chains to Support Delay-Sensitive Applications in Network Function Virtualization. IEEE Internet Things J. 2020, 1. [Google Scholar] [CrossRef]
- Durumeric, Z.; Wustrow, E.; Halderman, J.A. ZMap: Fast Internet-wide Scanning and Its Security Applications. In Proceedings of the 22th USENIX Security Symposium, Washington, DC, USA, 14–16 August 2013; pp. 605–620. [Google Scholar]
- Zgrab2. Available online: https://github.com/zmap/zgrab2 (accessed on 6 February 2020).
- Hamad, S.A.; Zhang, W.E.; Sheng, Q.Z.; Nepal, S. IoT Device Identification via Network-Flow Based Fingerprinting and Learning. In Proceedings of the 2019 18th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/13th IEEE International Conference On Big Data Science And Engineering (TrustCom/BigDataSE), Rotorua, New Zealand, 5–8 August 2019; pp. 103–111. [Google Scholar]
- Aksoy, A.; Gunes, M.H. Automated IoT Device Identification using Network Traffic. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar]
- Feng, X.; Li, Q.; Han, Q.; Zhu, H.; Liu, Y.; Cui, J.; Sun, L. Active Profiling of Physical Devices at Internet Scale. In Proceedings of the 2016 25th International Conference on Computer Communication and Networks (ICCCN), Waikoloa, HI, USA, 1–4 August 2016; pp. 1–9. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device Type | Protocol Type | Ports |
|---|---|---|
| Webcam | Http | 80,81,8000,8080,8081 |
| Telnet | 23 | |
| Rtsp | 554 | |
| Onvif | 3702 | |
| DaHua | 37777,37810 | |
| Router | FTP | 21 |
| SSH | 22 | |
| Telnet | 23 | |
| DNS | 53 | |
| Http | 80,8080,8081 | |
| UPnP | 1900 | |
| Printer | Http | 80,8000,8080,8081 |
| IPP | 631,4567 | |
| SNMP | 161 | |
| SSH | 22 | |
| Telnet | 23 | |
| PJL | 1900 |
| Next | ||||
|---|---|---|---|---|
| Start | ||||
| 0 | 0 | |||
| 0 | 0 | |||
| 0 | 0 | 0 | 1 | |
| Protocol Probe | Probability of Type | Probability of Brand | Probability of Model |
|---|---|---|---|
| Onvif_3702 | 91.00% | 54.00% | 34.9% |
| Http_80 | 92.97% | 56.25% | 65.16% |
| Author | Identification Objects | Method | Accuracy |
|---|---|---|---|
| Li et al. [15] | Firmware | Web Crawler & NLP | 90% |
| Hamad et al. [31] | Device Type | ML | 90.3% |
| Aksoy et al. [32] | Device Type | ML | 95% |
| Our Scheme | Device Brand & Model | Banner Grab | 90.5%, 92.3% |
| Device Type | Number of Probes | Identification Time after Scheduling(min) | Identification Time before Scheduling(min) | Time Reduction Ratio | Identification Accuracy |
|---|---|---|---|---|---|
| Router | 4 | 13.73 | 21.2 | 0.35 | 91.5% |
| Printer | 4 | 12.52 | 25.9 | 0.52 | 90.02% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, D.; Li, P.; Chen, Y.; Ma, Y.; Chen, J. A Time-efficient Multi-Protocol Probe Scheme for Fine-grain IoT Device Identification. Sensors 2020, 20, 1863. https://doi.org/10.3390/s20071863
Yu D, Li P, Chen Y, Ma Y, Chen J. A Time-efficient Multi-Protocol Probe Scheme for Fine-grain IoT Device Identification. Sensors. 2020; 20(7):1863. https://doi.org/10.3390/s20071863
Chicago/Turabian StyleYu, Dan, Peiyang Li, Yongle Chen, Yao Ma, and Junjie Chen. 2020. "A Time-efficient Multi-Protocol Probe Scheme for Fine-grain IoT Device Identification" Sensors 20, no. 7: 1863. https://doi.org/10.3390/s20071863
APA StyleYu, D., Li, P., Chen, Y., Ma, Y., & Chen, J. (2020). A Time-efficient Multi-Protocol Probe Scheme for Fine-grain IoT Device Identification. Sensors, 20(7), 1863. https://doi.org/10.3390/s20071863