Mixed YOLOv3-LITE: A Lightweight Real-Time Object Detection Method

 , ,
, ,
Abstract
:1. Introduction
- The proposed Mixed YOLOv3-LITE fuses deep and shallow features and output feature maps at different scales to maximize the utilization of the original features by incorporating ResBlocks and parallel structures.
- The convolution layers of the Mixed YOLOv3-LITE detector are shallower and narrower, which reduce the amount of computation and the number of trainable parameters to speed up the operation of the network.
- Mixed YOLOv3-LITE with fewer parameters—only about 5.089 million—is a lightweight real-time network that can be implemented on mobile terminals and other non-GPU based devices.
2. Related Work
2.1. Complex Networks with High Precision
2.1.1. Deep Residual Network (ResNet), DenseNet, and Dual-Path Network (DPN)
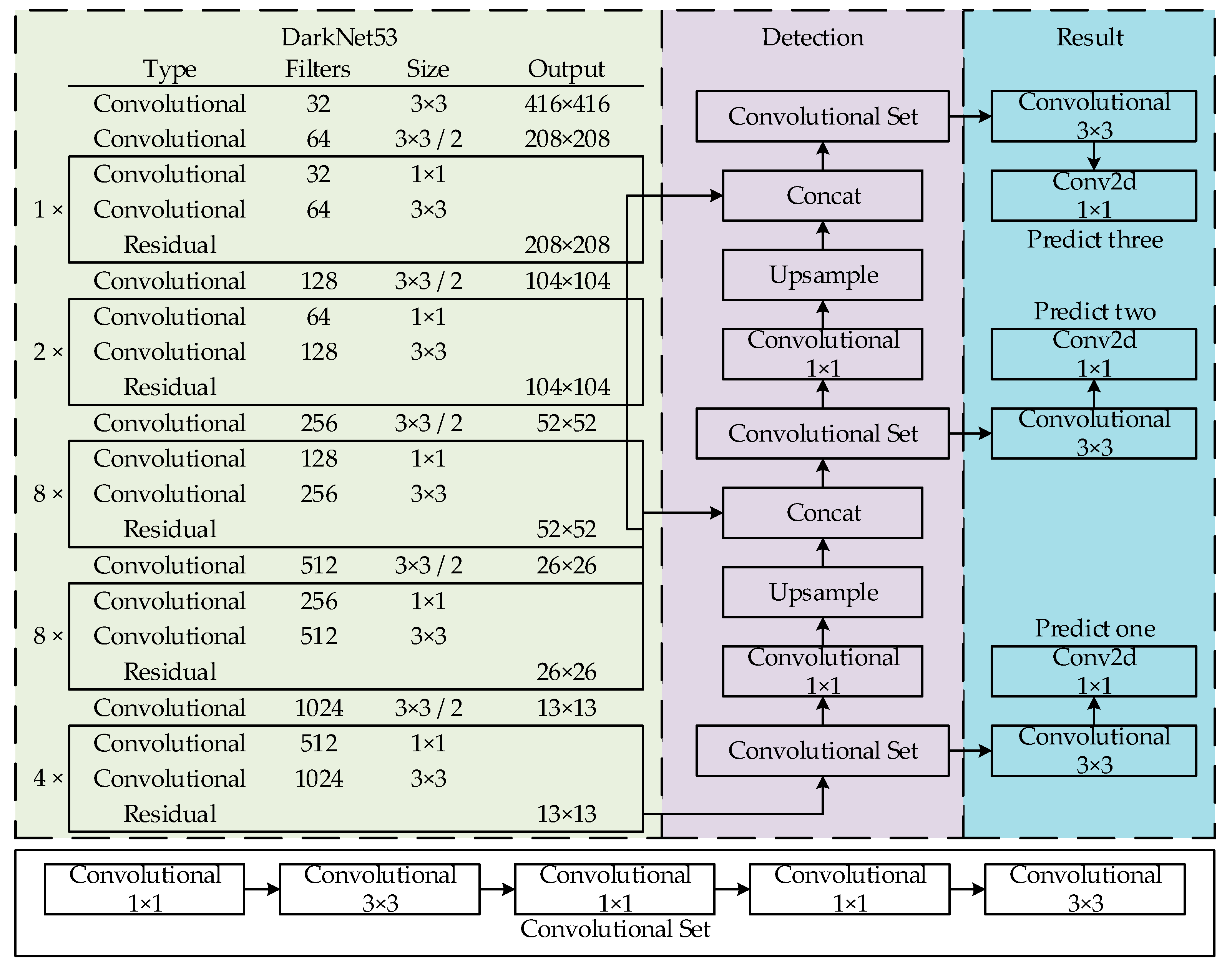
2.1.2. YOLOv3
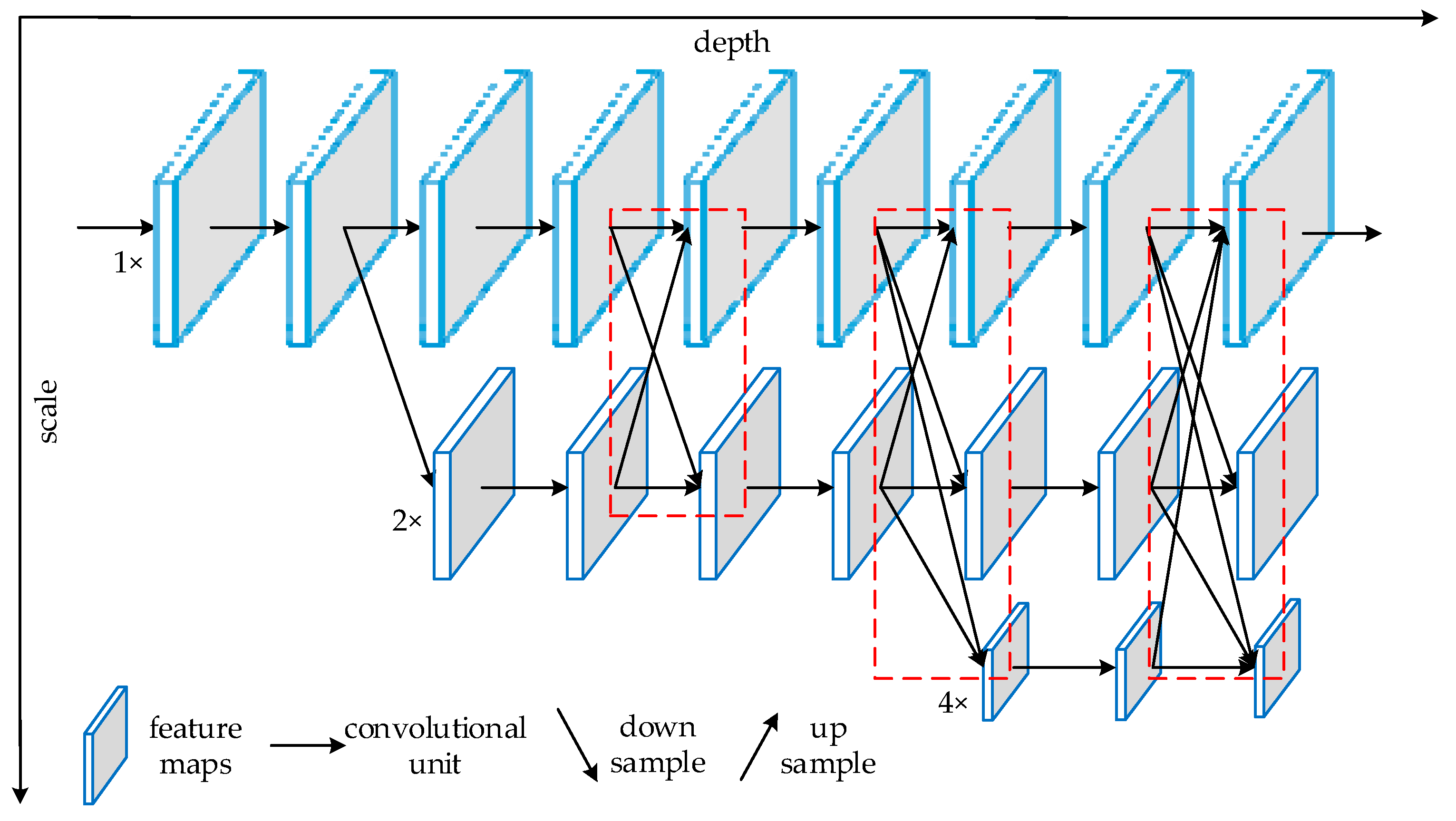
2.1.3. High-Resolution Network (HRNet)
2.2. Lightweight Networks
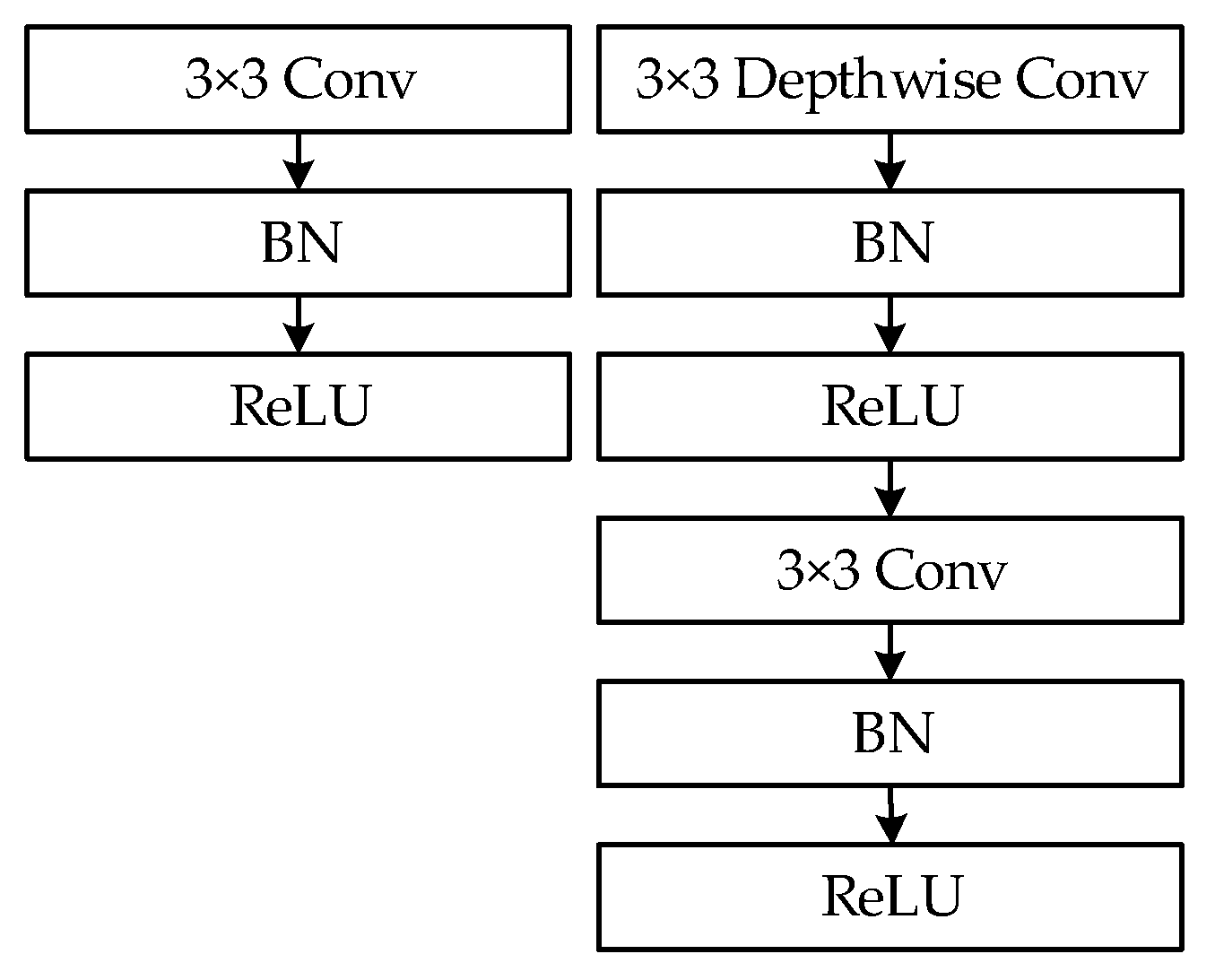
2.2.1. MobileNetV1 and MobileNetV2
2.2.2. Tiny-YOLO and YOLO-LITE
3. Mixed YOLOv3-LITE Network
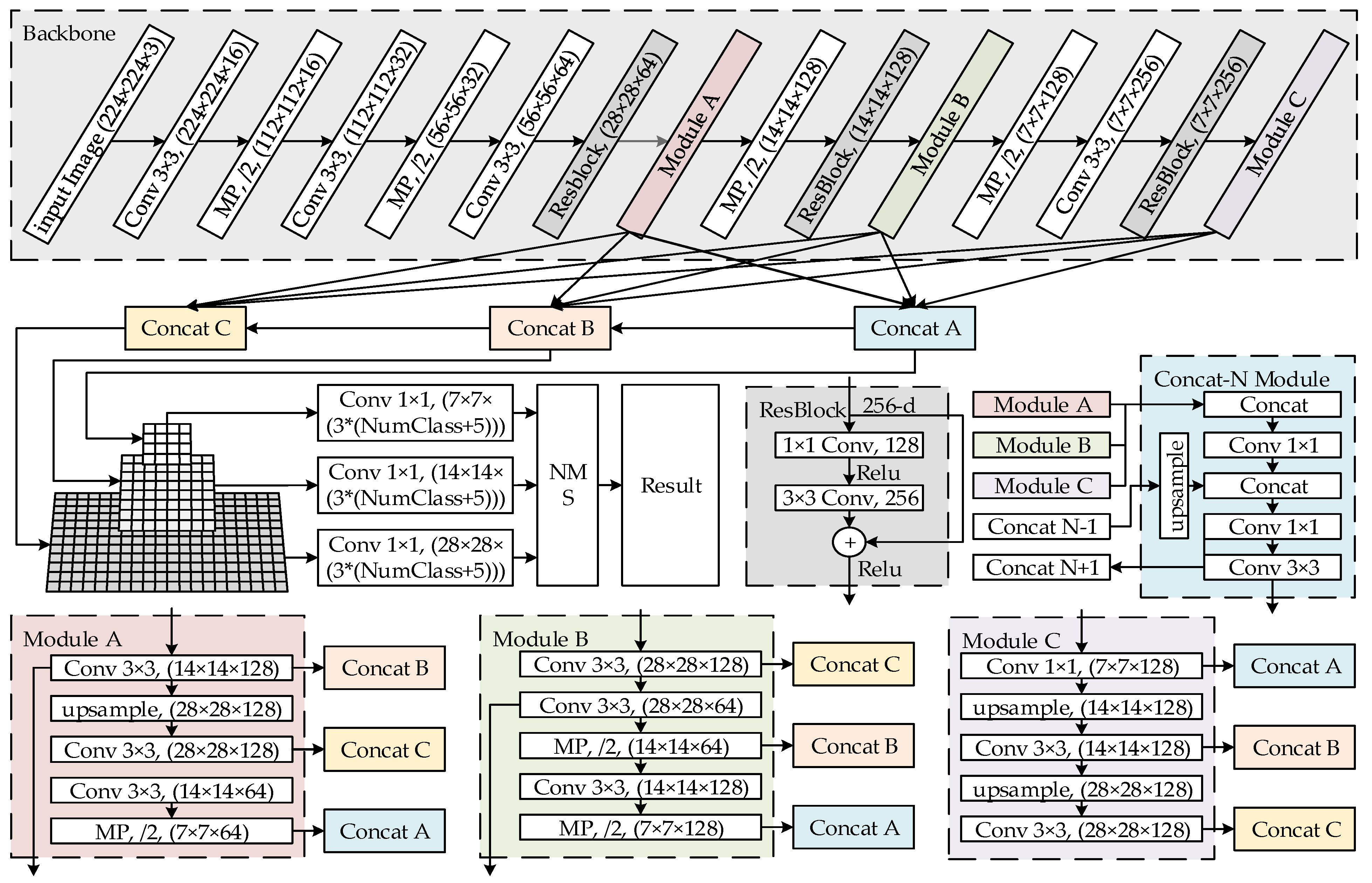
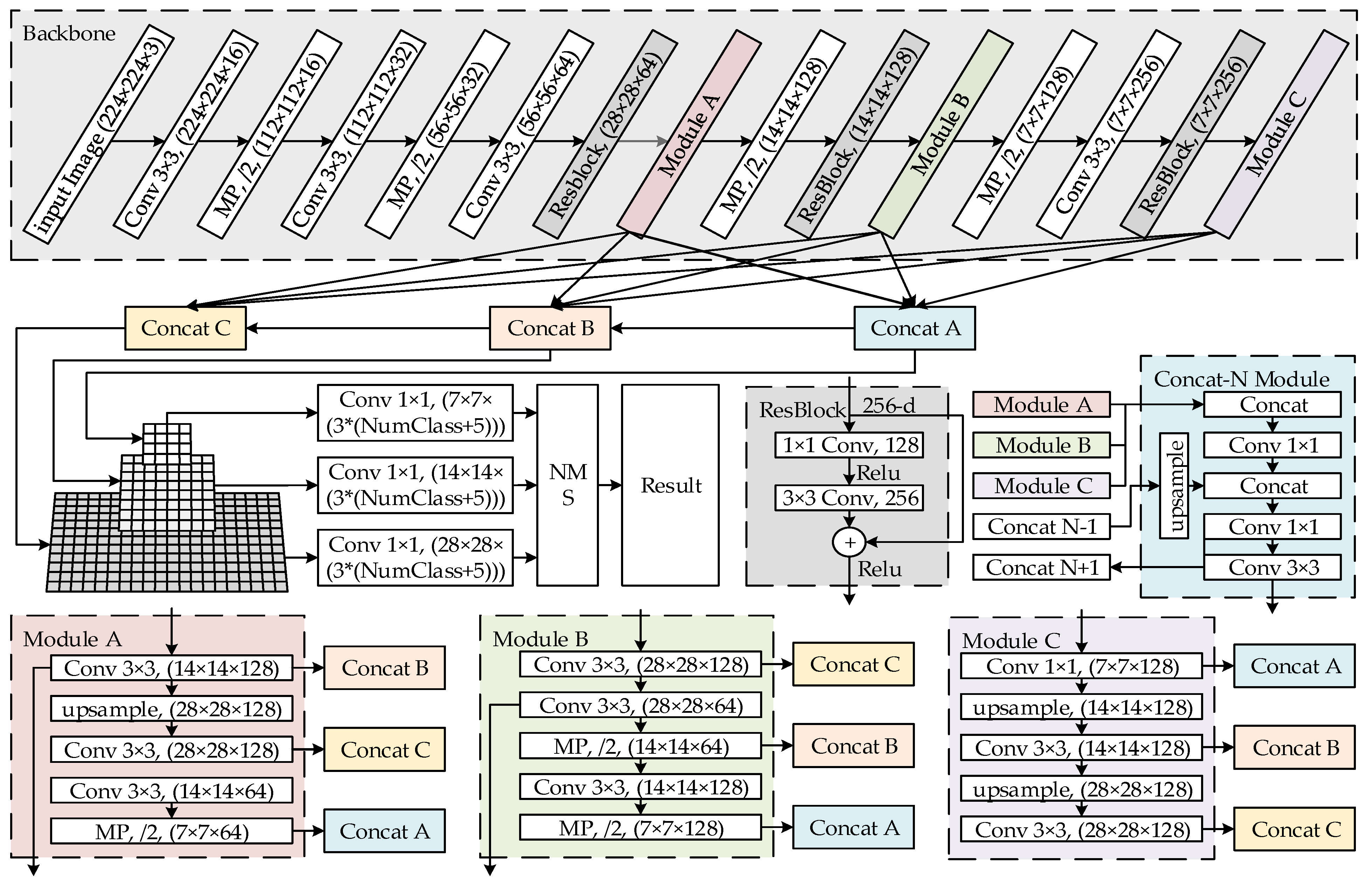
3.1. Mixed YOLOv3-LITE Network Structure
- For the feature extraction part, ResBlocks and the parallel high-to-low resolution subnetworks of HRNet are added based on the backbone network of YOLO-LITE, and the shallow and deep features are deeply integrated to maintain the high-resolution features of the input image. This improves the detection precision. This part includes four 3 × 3 standard convolution layers, four maximum pooling layers, three residual blocks, modules A, B, and C for reconstructing a multi-resolution pyramid, and concat modules A, B, and C. The concat-N module is located between the backbone network and the detector, and is used to reconstruct feature maps with the same resolution at different depths.
- For the detection part, a structure similar to that of YOLOv3 is used to reduce the number of convolution layers and channels. The detector detects the recombined feature maps of each concat-N module separately to improve the accuracy of detecting of small objects, and then selects the best detection result through maximum value suppression.
3.2. Mixed YOLOv3-LITE Network Module
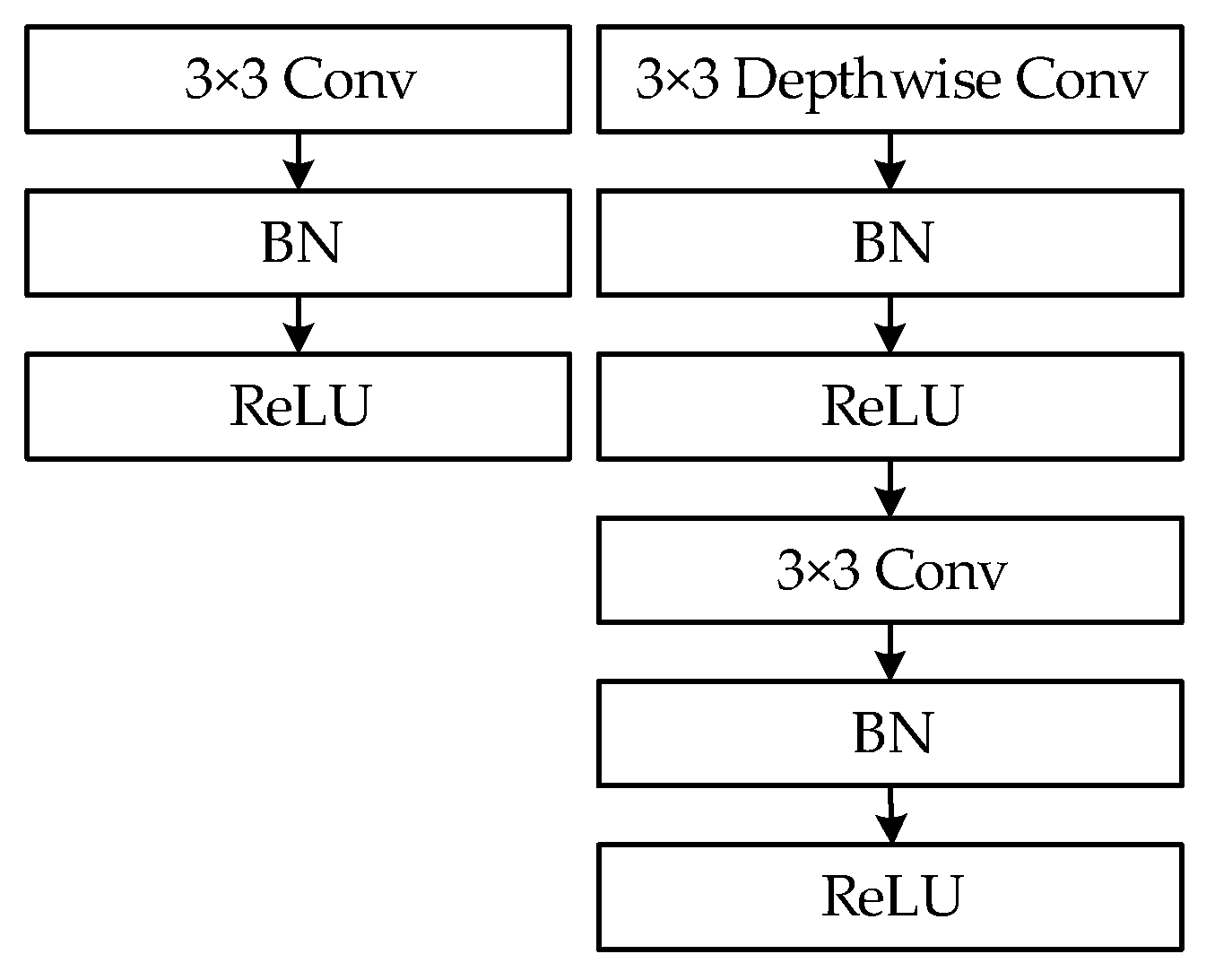
3.2.1. Shallow Network and Narrow Channel
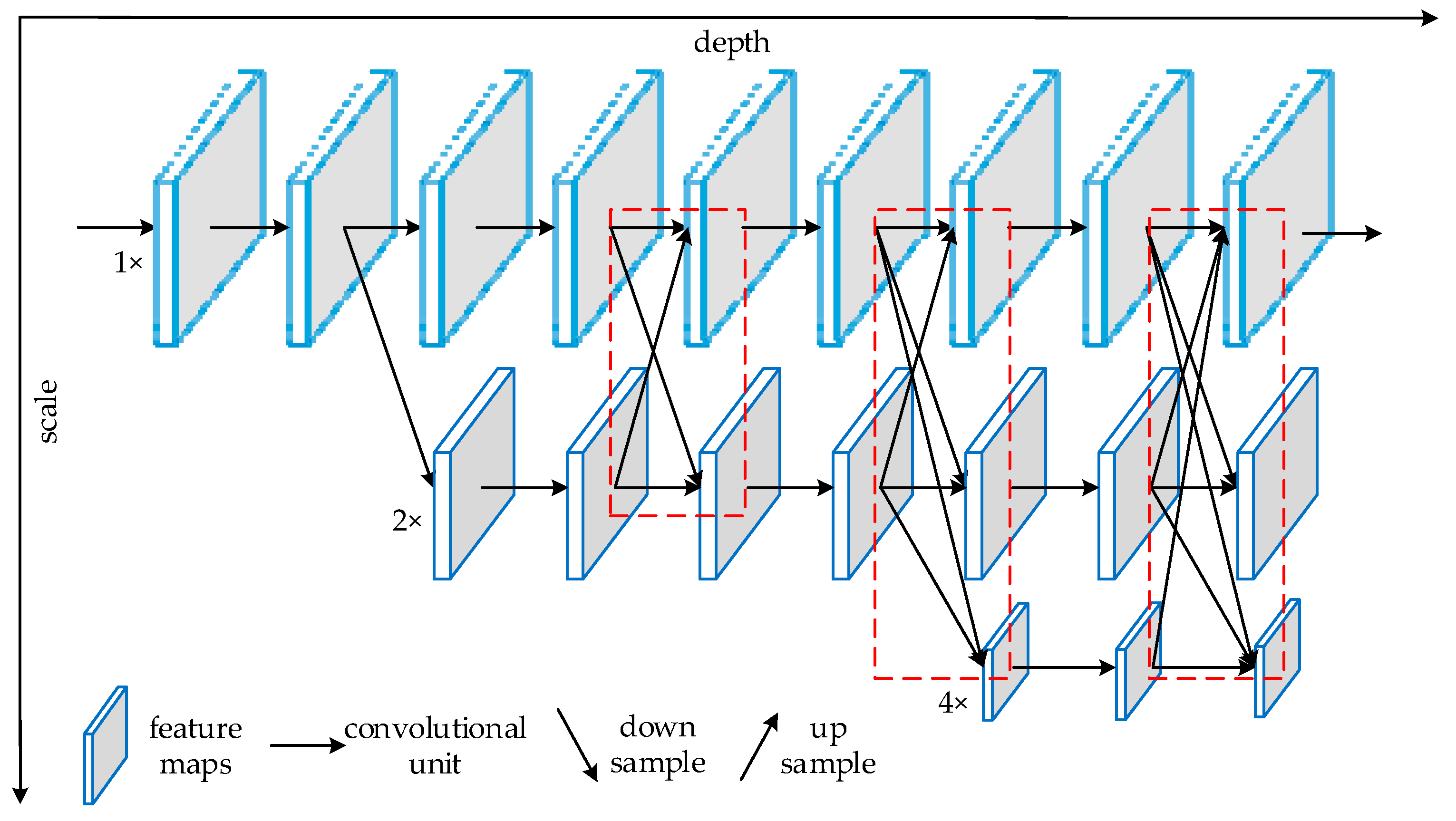
3.2.2. ResBlock and Parallel High-to-Low Resolution Subnetworks
4. Experiment and Discussion
4.1. Experimental Details
4.1.1. Experimental Environment Setup
4.1.2. Experimental Datasets
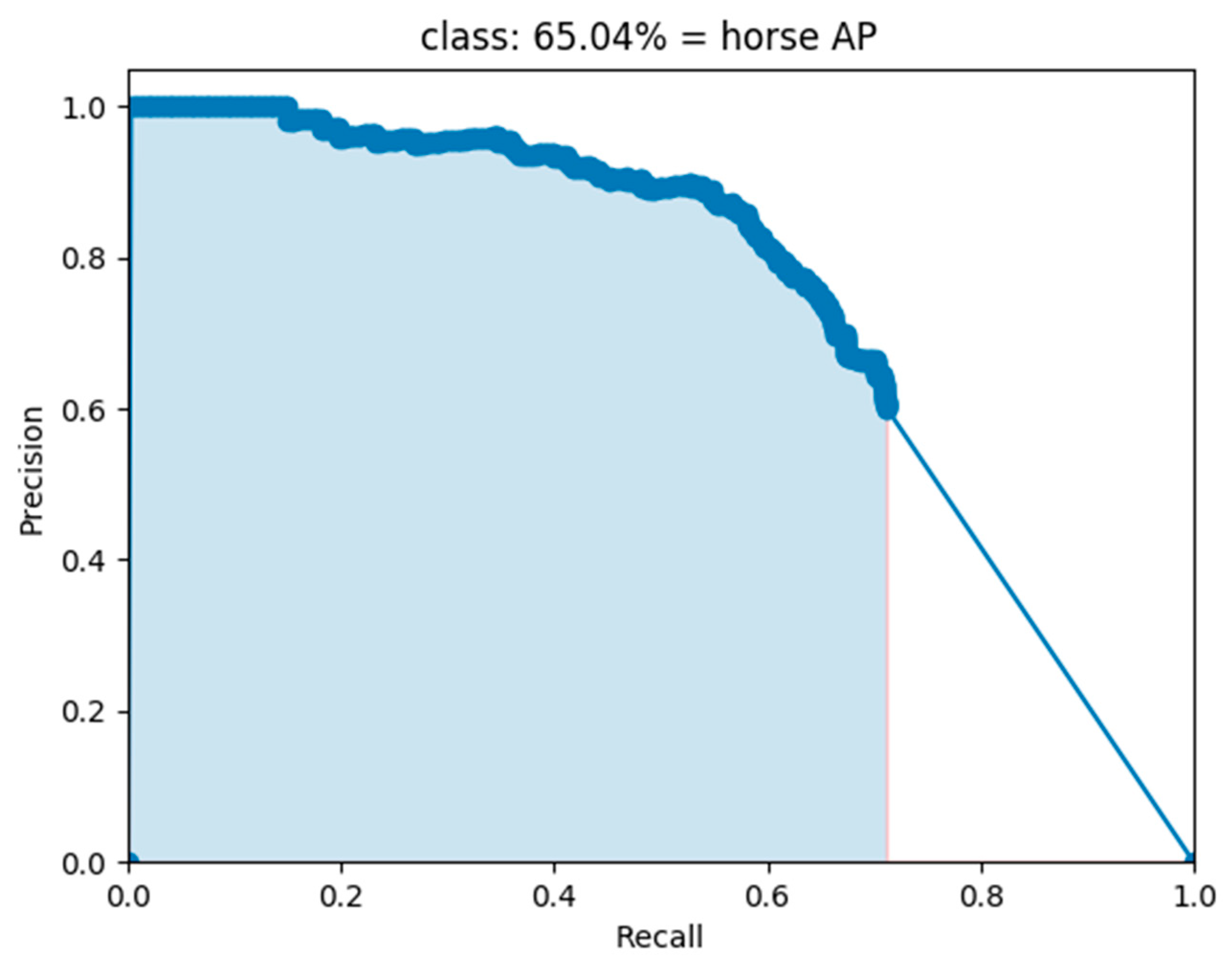
4.1.3. Evaluation Metrics
4.1.4. Experimental Setup
4.2. Experimental Results
4.2.1. PASCAL VOC
4.2.2. VisDrone 2018
4.2.3. ShipData Results
4.2.4. Performance Tests Based on Embedded Platform
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Masi, I.; Rawls, S.; Medioni, G.; Natarajan, P. Pose-Aware Face Recognition in the Wild. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4838–4846. [Google Scholar]
- Zhang, F.; Zhu, X.; Ye, M. Fast Human Pose Estimation. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3517–3526. [Google Scholar]
- Hossain, S.; Lee, D. Deep Learning-Based Real-Time Multiple-Object Detection and Tracking from Aerial Imagery via a Flying Robot with GPU-Based Embedded Devices. Sens. Basel 2019, 19, 3371. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lawrence, T.; Zhang, L. IoTNet: An Efficient and Accurate Convolutional Neural Network for IoT Devices. Sens. Basel 2019, 19, 5541. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Körez, A.; Barışçı, N. Object Detection with Low Capacity GPU Systems Using Improved Faster R-CNN. Appl. Sci. 2020, 10, 83. [Google Scholar] [CrossRef] [Green Version]
- Pan, J.; Sun, H.; Song, Z.; Han, J. Dual-Resolution Dual-Path Convolutional Neural Networks for Fast Object Detection. Sens. Basel 2019, 19, 3111. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xie, Z.; Wu, D.T.; Wu, K.W.; Li, Y. The Cascaded Rapid Object Detection with Double-Sided Complementary in Gradients. Acta Electron. Sin. 2017, 45, 2362–2367. [Google Scholar]
- Qin, X.Y.; Yuan, G.L.; Li, C.L.; Zhang, X. An Approach to Fast and Robust Detecting of Moving Target in Video Sequences. Acta Electron. Sin. 2017, 45, 2355–2361. [Google Scholar]
- Cui, J.H.; Zhang, Y.Z.; Wang, Z.; Li, Y. Light-Weight Object Detection Networks for Embedded Platform. Acta Opt. Sin. 2019, 39, 0415006. [Google Scholar]
- Wang, X.Q.; Wang, X.J. Real-Time Target Detection Method Applied to Embedded Graphic Processing Unit. Acta Opt. Sin. 2019, 39, 0315005. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Chen, Y.; Li, J.; Xiao, H.; Jin, X.; Yan, S.; Feng, J. Dual Path Networks. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, California, USA, 4–9 December 2017; pp. 4467–4475. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. arXiv 2019, arXiv:1902.09212. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Redmon, J. Darknet: Open Source Neural Networks in C. 2013–2016. Available online: http://pjreddie.com/darknet/ (accessed on 15 February 2020).
- Pedoeem, J.; Huang, R. YOLO-LITE: A Real-Time Object Detection Algorithm Optimized for Non-GPU Computers. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 2503–2510. [Google Scholar]
- Wong, A.; Famuori, M.; Shafiee, M.J.; Li, F.; Chwyl, B.; Chung, J. YOLO Nano: A Highly Compact You Only Look Once Convolutional Neural Network for Object Detection. arXiv 2019, arXiv:1910.01271. [Google Scholar]
- Heimer, R.Z.; Myrseth, K.O.R.; Schoenle, R.S. Yolo: Mortality beliefs and household finance puzzles. J. Financ. 2019, 74, 2957–2996. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Fu, C.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 2016 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Wong, A.; Shafiee, M.J.; Li, F.; Chwyl, B. Tiny SSD: A Tiny Single-shot Detection Deep Convolutional Neural Network for Real-time Embedded Object Detection. In Proceedings of the 2018 15th Conference on Computer and Robot Vision (CRV), Toronto, ON, Canada, 8–10 May 2018; pp. 95–101. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Zhu, P.; Wen, L.; Bian, X.; Ling, H.; Hu, Q. Vision Meets Drones: A Challenge. arXiv 2018, arXiv:1804.07437. [Google Scholar]
- Nvidia JETSON AGX XAVIER: The AI Platform for Autonomous Machines. Available online: https://www.nvidia.com/en-us/autonomous-machines/jetson-agx-xavier/ (accessed on 5 December 2019).
- Jetson AGX Xavier Developer Kit. Available online: https://developer.nvidia.com/embedded/jetson-agx-xavier-developer-kit (accessed on 5 December 2019).
- NVidia Jetson AGX Xavier Delivers 32 TeraOps for New Era of AI in Robotics. Available online: https://devblogs.nvidia.com/nvidia-jetson-agx-xavier-32-teraops-ai-robotics/ (accessed on 5 December 2019).
- Liu, D.; Hua, G.; Viola, P.; Chen, T. Integrated feature selection and higher-order spatial feature extraction for object categorization. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Zhang, P.; Zhong, Y.; Li, X. SlimYOLOv3: Narrower, Faster and Better for Real-Time UAV Applications. In Proceedings of the 2019 IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Filters | Size | Stride |
|---|---|---|---|
| C1 | 16 | 3 × 3 | 1 |
| MP | 2 × 2 | 2 | |
| C2 | 32 | 3 × 3 | 1 |
| MP | 2 × 2 | 2 | |
| C3 | 64 | 3 × 3 | 1 |
| MP | 2 × 2 | 2 | |
| C4 | 128 | 3 × 3 | 1 |
| MP | 2 × 2 | 2 | |
| C5 | 128 | 3 × 3 | 1 |
| MP | 2 × 2 | 2 | |
| C6 | 256 | 3 × 3 | 1 |
| C7 | 125 | 1×1 | 1 |
| The region |
| Operating System | Memory | CPU | Video Card | ||
|---|---|---|---|---|---|
| Training environment | Ubuntu 16.04 | 48 GB | Intel Core i7-9700k | GeForce RTX 2080Ti | |
| Testing environment | With GPU | Ubuntu 16.04 | 48 GB | Intel Core i7-9700k | GeForce RTX 2080Ti |
| Without GPU | Ubuntu 16.04 | 48 GB | Intel Core i7-9700k | without | |
| Dataset | Training Images | Test Images | Number of Classes |
|---|---|---|---|
| PASCAL VOC 2007 & 2012 | 16,511 | 4952 | 20 |
| VisDrone 2018-Det | 6471 | 548 | 10 |
| ShipData | 706(Subset A) | 303 (Subset B) | 1 |
| Predicted | 1 | 0 | Total | |
|---|---|---|---|---|
| Actual | ||||
| 1 | True Positive (TP) | False Negative (FN) | Actual Positive (TP + FN) | |
| 0 | False Positive (FP) | True Negative (TN) | Actual Negative (FP + TN) | |
| Total | Predicted Positive (TP + FP) | Predicted Negative (FN + TN) | TP + FN + FP + TN | |
| Model | Structure Description |
|---|---|
| YOLO-LITE | YOLO-LITE raw network structure [19], as shown in Table 1 |
| YOLOv3 | YOLOv3 raw network structure [14], as shown in Figure 1 |
| MobileNetV1-YOLOv3 | Backbone uses MobileNetV1 while using YOLOv3 detector part |
| MobileNetV2-YOLOv3 | Backbone uses MobileNetV2 while using YOLOv3 detector part |
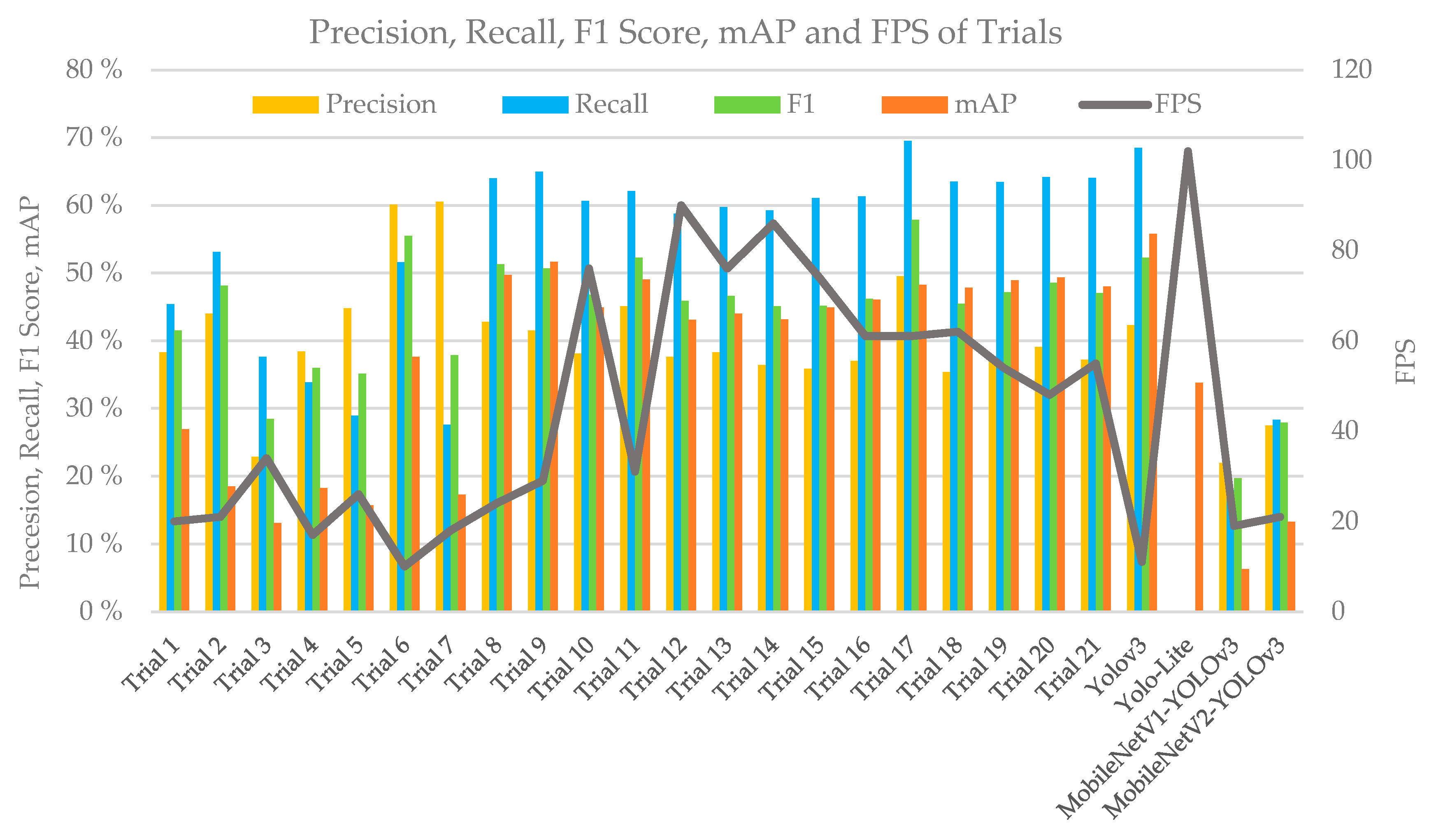
| Trial 1 | All convolution layers in YOLOv3 were replaced by depth-separable convolution, and the number of ResBlocks in Darknet53 was replaced from 1-2-8-8-4 to 1-2-4-6-4. |
| Trial 2 | The convolution layer was reduced in the detector part of Trial 1 by one layer. |
| Trial 3 | The number of ResBlocks in the backbone network of Trial 2 was reduced from 1-2-4-6-4 to 1-1-1-1-1. |
| Trial 4 | A parallel structure was added based on Trial 2, the resolution was reconstructed using a 1 × 1 convolutional kernel, and the channel was fused using a 3 × 3 convolutional kernel after the connection. |
| Trial 5 | Based on Trial 4, the number of ResBlocks in the backbone network was replaced by 1-1-2-4-2, and the resolution was reconstructed using a 3 × 3 convolutional kernel. |
| Trial 6 | A parallel structure was added based on YOLOv3, which used a 1 × 1 ordinary convolution. |
| Trial 7 | All convolutions in Trial 6 were replaced by depth-separable convolutions. |
| Trial 8 | The region was exactly the same as that of YOLOv3, and the last layer became wider when the backbone extracted features. |
| Trial 9 | The backbone was exactly the same as that in Trial 8, and three region levels were reduced by two layers for each. |
| Trial 10 | Three region levels were reduced by two layers for each, the region was narrowed simultaneously, and the backbone was exactly the same as that of YOLO-LITE. |
| Trial 11 | The backbone was exactly the same as that in Trial 8, and three region levels were reduced by four layers for each. |
| Trial 12 | The backbone was exactly the same as that of YOLO-LITE, three region levels were reduced by four layers for each, and the region was narrowed simultaneously (three region levels were reduced by two layers for each based on Trial 10). |
| Trial 13 | Three ResBlocks were added based on Trial 12. |
| Trial 14 | Three HR structures were added based on Trial 12. |
| Trial 15 | Based on Trial 14, the downsampling method was changed from the convolution step to the maximum pool, and a layer of convolution was added after the downsampling. |
| Trial 16 | The convolution kernel of the last layer of HR was changed from 1 × 1 to 3 × 3 based on Trial 15. |
| Trial 17 | Three ResBlocks were added to Trial 15. |
| Trial 18 | Nine layers of inverted-bottleneck ResBlocks were added to Trial 15. |
| Trial 19 | Based on Trial 18, the output layers of HR structure were increased by one 3 × 3 convolution layer for each, for a total of three layers. |
| Trial 20 | The number of ResBlocks per part was adjusted to three, based on Trial 17. |
| Trial 21 | The last ResBlocks was moved forward to reduce the number of channels, based on Trial 20. |
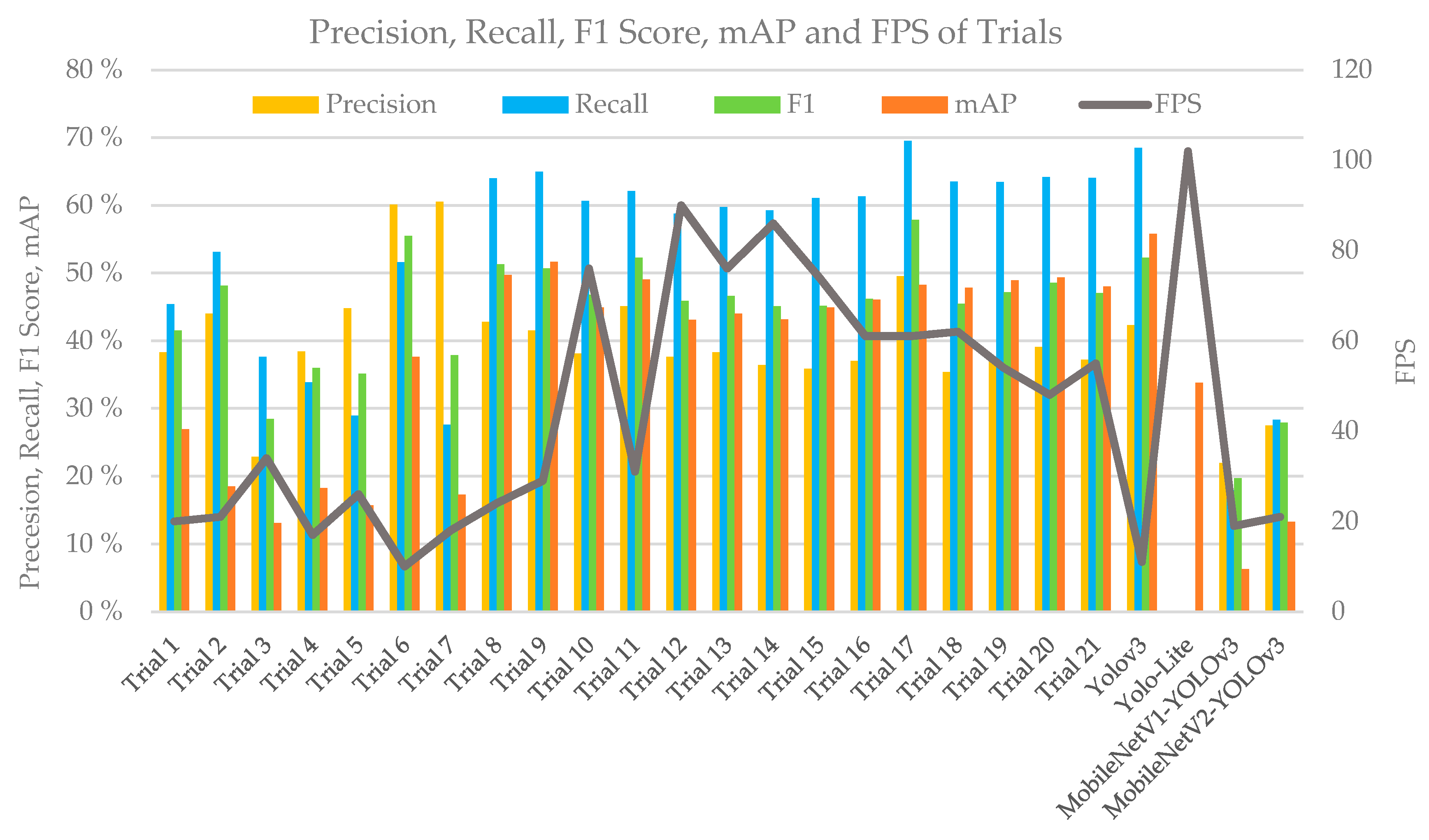
| Model | Layers | Model Size (MB) | GFLOPs | Params (M) | FPS | mAP | Precision | Recall | F1 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Backbone | The Region | |||||||||
| YOLO-LITE | 7 | 5 | 2.3 | 0.482 | not reported | 102 | 33.77 | not reported | not reported | not reported |
| YOLOv3 | 52 | 23 | 246.9 | 19.098 | 61.626 | 11 | 55.81 | 42.29 | 68.48 | 52.29 |
| MobileNetV1-YOLOv3 | 27 | 23 | 97.1 | 6.234 | 24.246 | 19 | 6.27 | 21.95 | 17.90 | 19.72 |
| MobileNetV2-YOLOv3 | 53 | 23 | 93.5 | 5.622 | 23.270 | 21 | 13.26 | 27.48 | 28.34 | 27.90 |
| Trial 1 | 43 | 23 | 20.8 | 2.142 | 5.136 | 20 | 26.87 | 38.27 | 45.4 | 41.53 |
| Trial 2 | 43 | 17 | 15.9 | 1.854 | 3.911 | 21 | 18.46 | 44 | 53.11 | 48.12 |
| Trial 3 | 19 | 11 | 7.7 | 1.091 | 1.908 | 34 | 13.01 | 22.86 | 37.65 | 28.45 |
| Trial 4 | 49 | 17 | 39.6 | 3.496 | 9.83 | 17 | 18.22 | 38.43 | 33.84 | 35.99 |
| Trial 5 | 34 | 17 | 35.1 | 2.832 | 8.714 | 26 | 15.69 | 44.77 | 28.91 | 35.13 |
| Trial 6 | 58 | 23 | 270.3 | 20.702 | 67.467 | 10 | 37.61 | 60.09 | 51.58 | 55.51 |
| Trial 7 | 58 | 23 | 76.3 | 5.737 | 19 | 18 | 17.29 | 60.53 | 27.58 | 37.89 |
| Trial 8 | 7 | 23 | 136.8 | 7.892 | 34.151 | 24 | 49.73 | 42.8 | 64.02 | 51.3 |
| Trial 9 | 7 | 17 | 109.2 | 6.337 | 27.265 | 29 | 51.69 | 41.53 | 64.95 | 50.67 |
| Trial 10 | 7 | 17 | 14.3 | 1.975 | 3.555 | 76 | 44.93 | 38.09 | 60.66 | 46.8 |
| Trial 11 | 7 | 11 | 81.6 | 4.782 | 20.378 | 31 | 49.07 | 45.12 | 62.08 | 52.26 |
| Trial 12 | 7 | 11 | 10.4 | 1.299 | 2.66 | 90 | 43.08 | 37.63 | 58.78 | 45.88 |
| Trial 13 | 13 | 11 | 17.3 | 1.688 | 4.293 | 76 | 43.99 | 38.26 | 59.72 | 46.64 |
| Trial 14 | 13 | 11 | 11 | 1.401 | 2.727 | 86 | 43.13 | 36.38 | 59.28 | 45.09 |
| Trial 15 | 16 | 11 | 13.6 | 2.091 | 3.366 | 74 | 44.93 | 35.85 | 61.06 | 45.18 |
| Trial 16 | 16 | 11 | 18.8 | 2.896 | 4.669 | 61 | 46.05 | 37.02 | 61.33 | 46.17 |
| Trial 17 | 23 | 11 | 20.5 | 2.480 | 5.089 | 61 | 48.25 | 49.53 | 69.54 | 57.85 |
| Trial 18 | 34 | 11 | 18 | 2.229 | 4.464 | 62 | 47.81 | 35.36 | 63.54 | 45.43 |
| Trial 19 | 37 | 11 | 22.1 | 2.935 | 5.483 | 54 | 48.94 | 37.52 | 63.45 | 47.15 |
| Trial 20 | 34 | 11 | 34.3 | 2.867 | 5.582 | 48 | 49.32 | 39.09 | 64.15 | 48.58 |
| Trial 21 | 34 | 11 | 21.7 | 2.808 | 5.387 | 55 | 48.01 | 37.17 | 64.03 | 47.03 |
| Model Name | Precision (%) | Recall (%) | F1 (%) | mAP (%) | GFLOPs | Model Size (MB) | FPS |
|---|---|---|---|---|---|---|---|
| Mixed YOLOv3-LITE | 39.19 | 37.80 | 37.99 | 28.50 | 2.48 | 20.5 | 47 |
| tiny-YOLOv3 | 23.40 | 20.10 | 21.00 | 11.00 | 21.82 | 33.1 | 52 |
| YOLOv3-spp1 | 42.90 | 36.70 | 39.20 | 25.50 | 262.84 | 239 | 15 |
| YOLOv3-spp3 | 43.50 | 38.00 | 40.20 | 26.40 | 284.10 | 243 | 14 |
| SlimYOLOv3-spp3-50 | 45.90 | 36.00 | 39.80 | 25.80 | 122 | 79.6 | 23 |
| SlimYOLOv3-spp3-90 | 36.90 | 33.80 | 34.00 | 23.90 | 39.89 | 30.6 | 24 |
| SlimYOLOv3-spp3-95 | 36.10 | 31.60 | 32.20 | 21.20 | 26.29 | 19.4 | 28 |
| Class | Images | Instances | Precision (%) | Recall (%) | F1 (%) | mAP (%) |
|---|---|---|---|---|---|---|
| awning-tricycle | 548 | 532 | 26.12 | 13.16 | 17.50 | 6.24 |
| bicycle | 548 | 1287 | 20.08 | 19.35 | 19.71 | 7.92 |
| bus | 548 | 251 | 47.60 | 47.41 | 47.50 | 40.87 |
| car | 548 | 14,064 | 61.36 | 76.54 | 68.11 | 70.79 |
| motor | 548 | 5125 | 44.08 | 43.61 | 43.85 | 32.74 |
| pedestrian | 548 | 8844 | 34.57 | 45.66 | 39.35 | 34.50 |
| people | 548 | 4886 | 42.32 | 35.45 | 38.58 | 23.39 |
| tricycle | 548 | 1045 | 33.38 | 24.69 | 28.38 | 15.25 |
| truck | 548 | 750 | 33.81 | 31.47 | 32.60 | 21.94 |
| van | 548 | 1975 | 48.55 | 40.71 | 44.29 | 31.31 |
| overall | 548 | 38,759 | 39.19 | 37.80 | 37.99 | 28.50 |
| Train Dataset | Test Dataset | Model Name | Precision (%) | Recall (%) | F1 (%) | mAP (%) |
|---|---|---|---|---|---|---|
| Subset A | Subset B | YOLOv3 | 98.83 | 98.68 | 97.24 | 98.60 |
| Mixed YOLOv3-LITE | 96.15 | 99.01 | 97.56 | 98.88 | ||
| Subset B | Subset A | YOLOv3 | 58.79 | 62.04 | 60.37 | 51.65 |
| Mixed YOLOv3-LITE | 31.03 | 83.29 | 45.21 | 64.68 |
| Model | Input Size | FPS |
|---|---|---|
| Mixed YOLOv3-LITE | 224 × 224 | 43 |
| Mixed YOLOv3-LITE | 832 × 832 | 13 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, H.; Zhou, Y.; Zhang, L.; Peng, Y.; Hu, X.; Peng, H.; Cai, X. Mixed YOLOv3-LITE: A Lightweight Real-Time Object Detection Method. Sensors 2020, 20, 1861. https://doi.org/10.3390/s20071861
Zhao H, Zhou Y, Zhang L, Peng Y, Hu X, Peng H, Cai X. Mixed YOLOv3-LITE: A Lightweight Real-Time Object Detection Method. Sensors. 2020; 20(7):1861. https://doi.org/10.3390/s20071861
Chicago/Turabian StyleZhao, Haipeng, Yang Zhou, Long Zhang, Yangzhao Peng, Xiaofei Hu, Haojie Peng, and Xinyue Cai. 2020. "Mixed YOLOv3-LITE: A Lightweight Real-Time Object Detection Method" Sensors 20, no. 7: 1861. https://doi.org/10.3390/s20071861
APA StyleZhao, H., Zhou, Y., Zhang, L., Peng, Y., Hu, X., Peng, H., & Cai, X. (2020). Mixed YOLOv3-LITE: A Lightweight Real-Time Object Detection Method. Sensors, 20(7), 1861. https://doi.org/10.3390/s20071861