Evaluating the Impact of a Two-Stage Multivariate Data Cleansing Approach to Improve to the Performance of Machine Learning Classifiers: A Case Study in Human Activity Recognition


 ,
,  ,
,
Abstract
1. Introduction
2. Literature Review
2.1. Human Activity Recognition
2.2. Multivariate Outlier Detection
2.2.1. Robust Distance Methods
- The Mahalanobis robust distance:
2.2.2. Non-Traditional Methods Based on Robust PCA (Principal Component Analysis)
3. Methodology
3.1. Feature Extraction
3.2. Process Stages
- Stage 1: In this first stage, an evaluation of different classifiers in order to determine the two most suitable for the HAR with the collected data. The output confirmed the fact that random forest and KNN are the most resilient classifier when working with noisy data [38]. This stage was useful only to determine the classifiers that were going to be used to evaluate the proposed data cleansing approach (see Section 4.1).
- Stage 2: Once it was clear that the best classifiers were KNN and random forest, the generated database is managed and split in order to obtain two sets. Set 1 containing two-thirds of the observations. This set will be used for data cleansing approach evaluation, model creation, and evaluation. This means that from this set, the process of training and evaluating using the 10-fold cross validation will be performed. Set 2 will remain with raw data in order to test the classifiers against unseen data. This stage is depicted on Figure 1A.
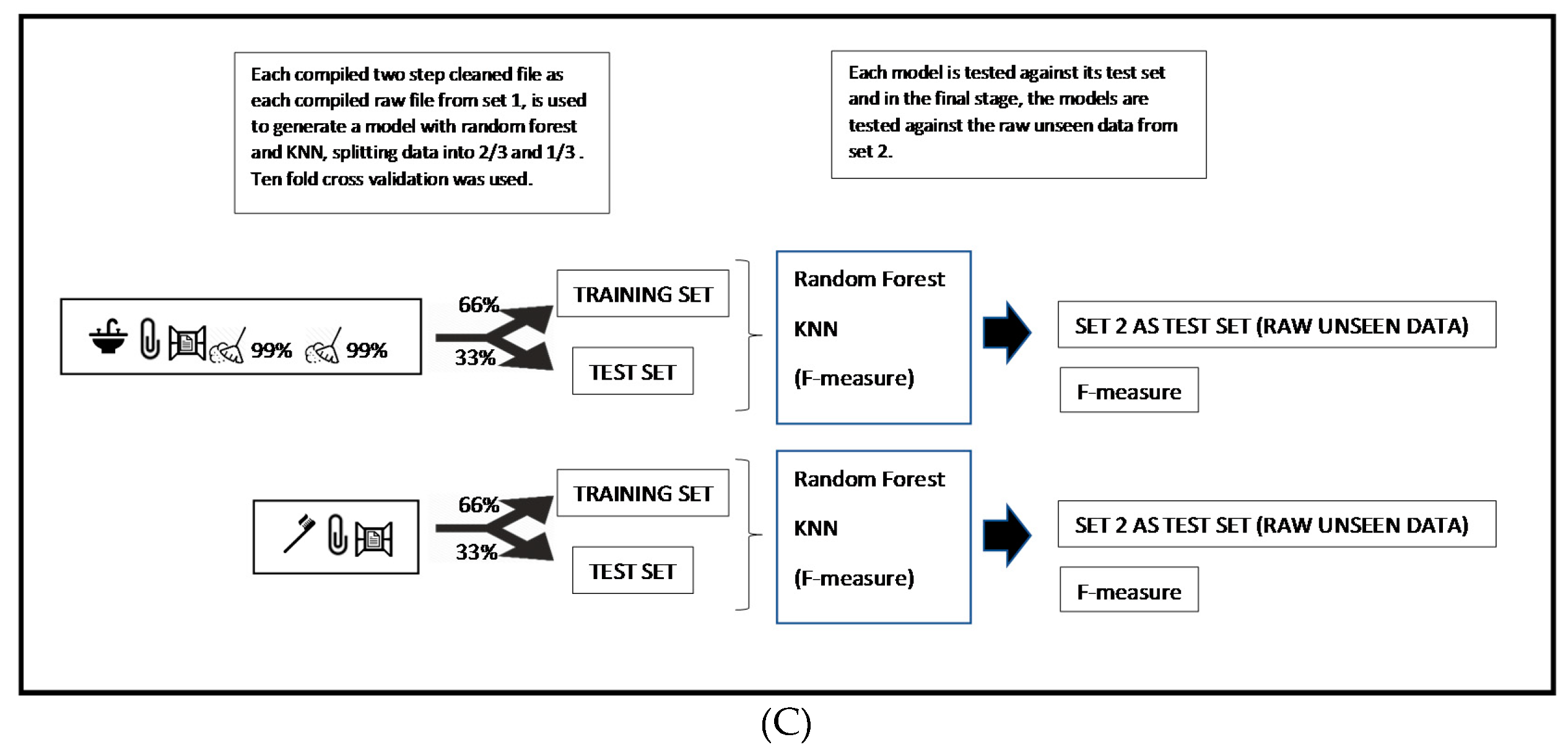
- Stage 3: Once the two sets are obtained in stage 2, set 1 was used to train the classifiers with noisy data. The purpose of this, is to evaluate the performance measures of the classifiers when trained with noisy data and compared it with the performance when trained with cleaned data. In this case, clean data refers to the resulting set once the proposed cleansing approach is implemented to this set 1. The detailed process in this stage is described in phases 1 to 8 and on Figure 1B (Phases 1 to 5) and on Figure 1C (phases 6 to 8).The phases carried out in this stage are:
- Phase 1: Feature calculation and windowing of the data.
- Phase 2: Multivariate outlier detection in the particular windowed data of each student. This outlier detection was made with the two proposed levels of 95% and 99% confidence levels. This means working with alpha levels of 0.01 and 0.05. These two levels are the most widely used for this kind of tests [61]. To perform this multivariate outlier analysis, the MD was computed using the mean of windowed data from acceleration across x, y, and z-axes.
- Phase 3: Compilation of the cleaned data in 18 files (one for each activity). Phase 3A: On the other hand, the raw files were compiled in 18 raw files too. One for each activity.
- Phase 4: Multivariate outlier detection of the compiled data. This outlier detection was made with 95% and 99% confidence levels.
- Phase 5: Compilation of the cleaned 18 files. Considering the previous cleaning processes and the different cleansing levels, up to this point four files were obtained. One with 95% confidence level in step 1 and 99% confidence level in step 2, one with 95–95%, one with 99–95%, and the fourth file with 99–99%.Phase 5A: Compilation of the 18 raw files in one file.
- Phase 6: Load the compiled files to Weka®.
- Phase 7: Apply a supervised attribute selection technique D1–N5 from Weka® (3.8.3 version).
- Phase 8: Create the model (KNN or random forest). The model was created using a 10-fold cross validation with a two-thirds training and one-third testing purposes. All steps were performed with set 1. F-measure values were extracted for each model. Considering that the data were cleaned with different levels in step 1 (Phase 2) and step 2 (Phase 4), four models were created for KNN and four for RF.Phase 8A: A similar way to the described in Phase 8 was followed with the raw data. In this case, a model with KNN and a model with RF were generated.
- Stage 4: Repeat stage 2 and stage 3 10 times. So, in the end, 100 models will be generated.
- Stage 5: Analysis of results. This analysis will be performed once the approach is applied to the study case data.
4. Study Case
4.1. Stage 1
4.2. Application of Mahalanobis Distance-Based Multivariate Data Cleansing (Stages 2, 3, and 4)
5. Analysis of Results
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Prins, J.; Mader, D. Multivariate Control Charts for Grouped and Individual Observations. Manuf. Syst. 2007, 37–41. [Google Scholar] [CrossRef]
- Fallon, A.; Spada, C. Detection and accommodation of outliers. Environ. Sampl. Monit. Primer 1997, 6, 217–230. [Google Scholar]
- Mahmoud, S.; Lotfi, A.; Langensiepen, C. User activities outliers detection; Integration of statistical and computational intelligence techniques. Comput. Intell. 2016, 32, 49–71. [Google Scholar] [CrossRef]
- Aparisi, F.; Carlos, J.; Díaz, G. Aumento de la potencia del gráfico de control multivariante T 2 de Hotelling utilizando señales adicionales de falta de control. Estadística Española 2001, 43, 171–188. [Google Scholar]
- Bauder, R.A.; Khoshgoftaar, T.M. Multivariate anomaly detection in medicare using model residuals and probabilistic programming. In Proceedings of the FLAIRS 2017—30th International Florida Artificial Intelligence Research Society Conference, Marco Island, FL, USA, 22–24 May 2017; pp. 417–422. [Google Scholar]
- Shabbak, A.; Midi, H. An Improvement of the Hotelling T 2 Statistic in Monitoring Multivariate Quality Characteristics. Math. Probl. Eng. 2012, 2012, 1–15. [Google Scholar] [CrossRef]
- Hubert, M.; Rousseeuw, P.J.; van Aelst, S. Multivariate Outlier Detection and Robustness. Handb. Stat. 2004, 24, 263–302. [Google Scholar]
- Noor, M.H.M.; Salcic, Z.; Wang, K.I.K. Adaptive sliding window segmentation for physical activity recognition using a single tri-axial accelerometer. Pervasive Mob. Comput. 2017, 38, 41–59. [Google Scholar] [CrossRef]
- Cerasuolo, J.O.; Cipriano, L.E.; Sposato, L.A.; Kapral, M.K.; Fang, J.; Gill, S.S.; Hackam, D.G.; Hachinski, V. Population-based stroke and dementia incidence trends: Age and sex variations. Alzheimer’s Dement. 2017, 13, 1081–1088. [Google Scholar] [CrossRef]
- Ni, Q.; Hernando, A.G.; de la Cruz, I. The Elderly’s Independent Living in Smart Homes: A Characterization of Activities and Sensing Infrastructure Survey to Facilitate Services Development. Sensors 2015, 15, 11312–11362. [Google Scholar] [CrossRef]
- Cleland, I.; Donnelly, M.P.; Nugent, C.D.; Hallberg, J.; Espinilla, M.; Garcia-Constantino, M. Collection of a Diverse, Realistic and Annotated Dataset for Wearable Activity Recognition. In Proceedings of the 2018 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Athens, Greece, 19–23 March 2018; pp. 555–560. [Google Scholar]
- Kleinberger, T.; Becker, M.; Ras, E.; Holzinger, A.; Müller, P. LNCS 4555-Ambient Intelligence in Assisted Living: Enable Elderly People to Handle Future Interfaces; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Irvine, N.; Nugent, C.; Zhang, S.; Wang, H.; Ng, W.W.; Cleland, I.; Espinilla, M. The impact of dataset quality on the performance of data-driven approaches for human activity recognition. In Data Science and Knowledge Engineering for Sensing Decision Support; World Scientific: Singapore, 2018; pp. 1300–1308. [Google Scholar]
- Aggarwal, J.K.; Xia, L. Human activity recognition from 3D data: A review. Pattern Recognit. Lett. 2014, 48, 70–80. [Google Scholar] [CrossRef]
- Chen, Y.; Xue, Y. A Deep Learning Approach to Human Activity Recognition Based on Single Accelerometer. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Kowloon, China, 9–12 October 2015; pp. 1488–1492. [Google Scholar]
- Qi, W.; Su, H.; Yang, C.; Ferrigno, G.; De Momi, E.; Aliverti, A. A Fast and Robust Deep Convolutional Neural Networks for Complex Human Activity Recognition Using Smartphone. Sensors 2019, 19, 3731. [Google Scholar] [CrossRef]
- Mukhopadhyay, S.C. Wearable Sensors for Human Activity Monitoring: A Review. IEEE Sens. J. 2015, 15, 1321–1330. [Google Scholar] [CrossRef]
- Chen, L.; Hoey, J.; Chris, N.; Cook, D.; Yu, Z. Sensor-based Activity Recognition. IEEE Trans. Syst. Man Cybern. Part C 2012, 42, 790–808. [Google Scholar] [CrossRef]
- Gu, T.; Wang, L.; Wu, Z.; Tao, X.; Lu, J. A Pattern Mining Approach to Sensor-Based Human Activity Recognition. IEEE Trans. Knowl. Data Eng. 2011, 23, 1359–1372. [Google Scholar] [CrossRef]
- Cornacchia, M.; Ozcan, K.; Zheng, Y.; Velipasalar, S. A Survey on Activity Detection and Classification Using Wearable Sensors. IEEE Sens. J. 2017, 17, 386–403. [Google Scholar] [CrossRef]
- Nweke, H.F.; Teh, Y.W.; Al-Garadi, M.A.; Alo, R. Deep learning algorithms for human activity recognition using mobile and wearable sensor networks: State of the art and research challenges. Expert Syst. Appl. 2018, 105, 233–261. [Google Scholar] [CrossRef]
- Alsheikh, M.A.; Selim, A.; Niyato, D.; Doyle, L.; Lin, S.; Tan, H.-P. Deep Activity Recognition Models with Triaxial Accelerometers. arXiv 2015, arXiv:1511.04664. [Google Scholar]
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv. 2014, 46, 1–33. [Google Scholar] [CrossRef]
- Figo, D.; Diniz, P.C.; Ferreira, R.D.; Cardoso, J.M.P. Preprocessing Techniques for Context Recognition from Accelerometer Data. Pers. Ubiquitous Comput. 2010, 14, 645–662. [Google Scholar] [CrossRef]
- Pires, I.; Garcia, N.M.; Pombo, N.; Flórez-Revuelta, F. From Data Acquisition to Data Fusion: A Comprehensive Review and a Roadmap for the Identification of Activities of Daily Living Using Mobile Devices. Sensors 2016, 16, 184. [Google Scholar] [CrossRef]
- Domingos, P. A Few Useful Things to Know About Machine Learning. Commun. ACM 2012, 55, 78–87. [Google Scholar] [CrossRef]
- Yang, J.H.; Xi, Z. A Study on the Effect of Entrepreneurship of Korean and Chinese University Students on Entrepreneurial Intention: Focused on Mediating of Self-efficacy. Int. Bus. Rev. 2015, 19, 25–53. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the ISCAS 2010–2010 IEEE International Symposium on Circuits and Systems: Nano-Bio Circuit Fabrics and Systems, Paris, France, 30 May–2 June 2010; pp. 253–256. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2323. [Google Scholar] [CrossRef]
- Baccouche, M.; Mamalet, F.; Wolf, C.; Garcia, C.; Baskurt, A. Sequential deep learning for human action recognition. In Lecture Notes in Computer Science; Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2011; Volume 7065, pp. 29–39. [Google Scholar]
- Wang, K.; Wang, X.; Lin, L.; Wang, M.; Zuo, W. 3D Human activity recognition with reconfigurable convolutional neural networks. In Proceedings of the 2014 ACM Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 97–106. [Google Scholar]
- Veeriah, V.; Zhuang, N.; Qi, G.-J. Differential Recurrent Neural Networks for Action Recognition. arXiv 2015, arXiv:1504.06678. [Google Scholar]
- Morales, J.; Akopian, D. Physical activity recognition by smartphones, a survey. In Biocybernetics and Biomedical Engineering; PWN-Polish Scientific Publishers: Warszawa, Poland, 2017; Volume 37, pp. 388–400. [Google Scholar]
- Gjoreski, H.; Bizjak, J.; Gjoreski, M.; Gams, M. Comparing Deep and Classical Machine Learning Methods for Human Activity Recognition using Wrist Accelerometer. In Proceedings of the IJCAI 2016 Workshop on Deep Learning for Artificial Intelligence, New York, NY, USA, 9–15 July 2016; Volume 10. [Google Scholar]
- Maimon, O.; Rokach, L. (Eds.) Data Mining and Knowledge Discovery Handbook; Springer: Boston, MA, USA, 2010. [Google Scholar]
- Gorunescu, F. Data Mining: Concepts, Models and Techniques; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011; Volume 12. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining. Concepts and Techniques, 3rd ed.; The Morgan Kaufmann Series in Data Management Systems; Morgan Kaufmann: Burlington, MA, USA, 2011. [Google Scholar]
- Zhu, X.; Wu, X. Class Noise vs. Attribute Noise: A Quantitative Study. Artif. Intell. Rev. 2004, 22, 177–210. [Google Scholar] [CrossRef]
- Folleco, A.A.; Khoshgoftaar, T.M.; van Hulse, J.; Napolitano, A. Identifying Learners Robust to Low Quality Data. Informatica 2009, 33, 245–259. [Google Scholar]
- Li, D.-F.; Hu, W.-C.; Xiong, W.; Yang, J.-B.; Alimi, A.M. Fuzzy relevance vector machine for learning from unbalanced data and noise. Pattern Recognit. Lett. 2008, 29, 1175–1181. [Google Scholar] [CrossRef]
- van Hulse, J.; Khoshgoftaar, T.M. Class noise detection using frequent itemsets. Intell. Data Anal. 2006, 10, 487–507. [Google Scholar] [CrossRef]
- Majewska, J. Identification of Multivariate Outliers–Problems and Challenges. Studia Ekonomiczne. 2015, 247, 69–83. [Google Scholar]
- Iglewicz, B.; Martinez, J. Outlier detection using robust measures of scale. J. Stat. Comput. Simul. 1982, 15, 285–293. [Google Scholar] [CrossRef]
- Becker, C.; Gather, U. The Masking Breakdown Point of Multivariate Outlier Identification Rules The Masking Breakdown Point of Multivariate Outlier Identification Rules. J. Am. Stat. Assoc. 2012, 94, 37–41. [Google Scholar]
- Identifying multivariate outliers, Stata Technical Bulletin STB-11. September 1993. Available online: https://www.researchgate.net/publication/24136964_Identifying_multivariate_outliers (accessed on 27 March 2020).
- Penny, K.I.; Jolliffe, I.T. A Comparison of Multivariate Outlier Detection Methods for Clinical Laboratory Safety Data. J. R. Stat. Soc. Ser. D (Stat.) 2001, 50, 295–308. [Google Scholar] [CrossRef]
- Rousseeuw, P.J.; Leroy, A.M. Robust Regression and Outlier Detection; Wiley: Hoboken, NJ, USA, 1987. [Google Scholar]
- Butler, R.W.; Davies, P.L.; Jhun, M. Asymptotics for the Minimum Covariance Determinant Estimator. Ann. Stat. 1993, 21, 1385–1400. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Ullah, M.S. Robust forecasting of mortality and fertility rates: A functional data approach. Comput. Stat. Data Anal. 2007, 51, 4942–4956. [Google Scholar] [CrossRef]
- Meng, L.; Miao, C.; Leung, C. Towards Online and Personalized Daily Activity Recognition, Habit Modeling, and Anomaly Detection for the Solitary Elderly through Unobtrusive Sensing. Multimed. Tools Appl. 2017, 76, 10779–10799. [Google Scholar] [CrossRef]
- Gopalakrishnan, N.; Krishnan, V. Improving data classification accuracy in sensor networks using hybrid outlier detection in HAR. J. Intell. Fuzzy Syst. 2019, 37, 771–782. [Google Scholar] [CrossRef]
- Jones, P.J.; James, M.K.; Davies, M.J.; Khunti, K.; Catt, M.; Yates, T.; Rowlands, A.V.; Mirkes, E.M. FilterK: A new outlier detection method for k-means clustering of physical activity. J. Biomed. Inform. 2020, 104, 103397. [Google Scholar] [CrossRef]
- Munoz-Organero, M. Outlier Detection in Wearable Sensor Data for Human Activity Recognition (HAR) Based on DRNNs. IEEE Access 2019, 7, 74422–74436. [Google Scholar] [CrossRef]
- Sunderland, K.M.; Beaton, D.; Fraser, J.; Kwan, D.; McLaughlin, P.M.; Montero-Odasso, M.; Peltsch, A.J.; Pieruccini-Faria, F.; Sahlas, D.J.; Swartz, R.H.; et al. The utility of multivariate outlier detection techniques for data quality evaluation in large studies: An application within the ONDRI project. BMC Med. Res. Methodol. 2019, 19, 102. [Google Scholar] [CrossRef]
- Zhao, S.; Li, W.; Cao, J. A user-adaptive algorithm for activity recognition based on K-means clustering, local outlier factor, and multivariate gaussian distribution. Sensors 2018, 18, 1850. [Google Scholar] [CrossRef] [PubMed]
- Marubini, E.; Orenti, A. Detecting outliers and/or leverage points: A robust two-stage procedure with bootstrap cut-off points. Epidemiol. Biostat. Public Health 2014, 11. [Google Scholar] [CrossRef]
- Dehghani, A.; Sarbishei, O.; Glatard, T.; Shihab, E. A Quantitative Comparison of Overlapping and Non-Overlapping Sliding Windows for Human Activity Recognition Using Inertial Sensors. Sensors 2019, 19, 5026. [Google Scholar] [CrossRef] [PubMed]
- Mannini, A.; Rosenberger, M.; Haskell, W.L.; Sabatini, A.M.; Intille, S.S. Activity recognition in youth using single accelerometer placed at wrist or ankle. Med. Sci. Sports Exerc. 2017, 49, 801–812. [Google Scholar] [CrossRef]
- De-La-Hoz-Franco, E.; Ariza-Colpas, P.; Quero, J.M.; Espinilla, M. Sensor-based datasets for human activity recognition—A systematic review of literature. IEEE Access 2018, 6, 59192–59210. [Google Scholar] [CrossRef]
- Croux, C.; Ruiz-Gazen, A. High breakdown estimators for principal components: The projection-pursuit approach revisited. J. Multivar. Anal. 2005, 95, 206–226. [Google Scholar] [CrossRef]
- Qi, W.; Aliverti, A. A Multimodal Wearable System for Continuous and Real-time Breathing Pattern Monitoring During Daily Activity. IEEE J. Biomed. Health Inform. 2019. [Google Scholar] [CrossRef]
- Lentzas, A.; Vrakas, D. Non-intrusive human activity recognition and abnormal behavior detection on elderly people: A review. Artif. Intell. Rev. 2019, 53, 1–47. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Authors | Outlier Approach | Scope | Relevant Topics |
|---|---|---|---|
| Meng et al. [51] | Heuristic based on statistical hierarchy | Activities of daily living | The model looks for the detection of abnormal behavior once the classifier is trained. Aims to the detect changes in patients’ behavior. No description of data cleaning process. |
| Gopalakrishnan and Krishnan [52] | Hybrid approach, combining outliers scores | Activities of daily living (ADL) | Improvement of 6% in F-measure, in SVM and RBFN. Database with six activities. |
| Jones et al. [53] | Hybrid approach using different outlier detection techniques. | Physical activity | Improvement in the performance of the k-means in 4%. |
| Muñoz-Organero [54] | ANN | ADL | They look for a specific type of outlier data, related with the cessation of movement. |
| Sunderland et al. [55] | Hybrid approach using simulation and minimum covariance determinant | Database of neurodegenerative disease | They succeeded on the detection of error in the database. |
| Li et al. [41] | Hybrid approach based on KNN and kernel-target alignment | Not specific | Slight Improvement on the performance of the classifier. Tested in two-class scenarios. |
| Hyndman and Ullah [50] | Principal component analysis | Forecasting mortality and fertility rates | Reduction of the forecast error. |
| Penny and Jollyffe [47] | Comparison between different techniques | Laboratory safety data | Concludes that the best approaches for high dimensional data are Mahalanobis distance and Hadi method. |
| Zhao et al. [56] | Hybrid approach | ADL | Improvement in classifier performance. Tested in data with four activities. |
| Marubini and Orenti [57] | Minimum covariance determinant | Linear regression prediction | Reduction of the prediction error. |
| No. | Scenario | Activities | Number of Files |
|---|---|---|---|
| 1 | Self-care | Hair grooming, washing hands, brushing teeth | 24 (72 files) |
| 2 | Exercise (cardio) | Walking, jogging, stepping-up. | 23 (69 files) |
| 3 | House cleaning | Ironing clothes, washing windows, washing dishes | 25 (75 files) |
| 4 | Exercise (weights) | Arm curls, dead lift, lateral arm raise | 21 (63 files) |
| 5 | Sport | Bounce ball, catch ball, pass ball | 25 (75 files) |
| 6 | Food preparation | Mixing food, chopping vegetables, sieving flour | 23 (69 files) |
| Total | 141 (423 files) | ||
| Feature Number | Feature Name | Feature Description |
|---|---|---|
| 1–3 | Mean acceleration | Mean acceleration in x, y, and z, in the time window. |
| 4 | Mean SMV | Mean SMV in the time window. SMV was calculated with the relation: where , denote the acceleration in each axis of the i-th observation. |
| 5–7 | Mean logarithm | Mean logarithm in x, y and z in the time window. |
| 8–10 | Mean exponential | Mean value of the exponential function powered at the value of the acceleration in each axis. This was also calculated in the corresponding time window. |
| 11–13 | Mean exponential squared | Mean value of the exponential function powered at the squared value of the acceleration in each axis. This was also calculated in the corresponding time window. |
| 14–16 | Mean squared acceleration | Mean of the squared values of the acceleration in x, y and z, in the time window. |
| 17–20 | Trapezoidal rule | Trapezoidal rule of acceleration in each axis and SMV, in the time window. |
| 21–24 | Minimum | Minimum value of the acceleration in each axis, and SMV in each time window. |
| 25–28 | Maximum | Maximum value of the acceleration in each axis, and SMV in each time window. |
| 29–32 | Range | Range of the values of acceleration in each axis and SMV in the time window. |
| 33–36 | Standard deviation | Standard deviation of the values of SMV and acceleration in the three axis, in the time window. |
| 37–40 | Root mean square (RMS) | Root mean square of the values of SMV, and acceleration in each axis, in the time window. RMS is calculated according to the relation |
| 41 | Signal magnitude area (SMA) | Signal magnitude area in the time window. It is calculated with the equation where, corresponds to the absolute value of the i-th observation of the acceleration across x-axis in the time window. |
| 42–44 | Mean square | Mean of the square values of individual observations in the time window. |
| 45–48 | Entropy | Fast Fourier transform of SMV, and across x, y, and z-axis, in the time window. |
| 49–51 | Median | Median of the acceleration values across x, y, and z-axis in the time window. |
| Activity | No. of Files |
|---|---|
| Arm curls | 21 |
| Bounce | 25 |
| Catch | 25 |
| Chopping | 23 |
| Deadlift | 21 |
| Dishwashing | 25 |
| Hair grooming | 25 |
| Handwashing | 24 |
| Ironing | 24 |
| Jogging | 23 |
| Lateral arm raise | 21 |
| Mixing food in bowl | 23 |
| Pass | 25 |
| Sieving flour | 23 |
| Stepping | 23 |
| Teeth brushing | 24 |
| Walking | 23 |
| Window washing | 25 |
| TOTAL | 423 |
| Classifier | F-Measure |
|---|---|
| KNN | 84.00% |
| SVM | 73.60% |
| Random forest | 89.40% |
| Neural networks | 78.00% |
| Regression | 72.10% |
| F-Measure | |||
|---|---|---|---|
| Scenario | KNN | RF | Kept Instances (%) |
| Case 1 | 95.80% | 96.00% | 84.07% |
| Case 2 | 94.70% | 95.70% | 92.99% |
| Case 3 | 94.10% | 93.80% | 88.52% |
| Case 4 | 81.20% | 93.90% | 98.16% |
| Case 5 | 52.20% | 92.10% | 100% |
| Scenario | KNN (27 Features) | KNN (3 Features) | Kept Instances |
|---|---|---|---|
| Scenario 1 | 92.90% | 63.80% | 98.5% |
| Scenario 2 | 94.20% | 64.00% | 88.7% |
| KNN | Cleaning Levels | |||
|---|---|---|---|---|
| Fold | 95_95 | 95_99 | 99_95 | 99_99 |
| 1 | 0.940 | 0.925 | 0.938 | 0.921 |
| 2 | 0.935 | 0.922 | 0.929 | 0.914 |
| 3 | 0.935 | 0.923 | 0.936 | 0.922 |
| 4 | 0.939 | 0.867 | 0.930 | 0.860 |
| 5 | 0.941 | 0.936 | 0.936 | 0.842 |
| 6 | 0.949 | 0.842 | 0.936 | 0.855 |
| 7 | 0.935 | 0.860 | 0.932 | 0.838 |
| 8 | 0.936 | 0.866 | 0.934 | 0.833 |
| 9 | 0.937 | 0.926 | 0.938 | 0.924 |
| 10 | 0.933 | 0.849 | 0.933 | 0.846 |
| RF | 95_95 | 95_99 | 99_95 | 99_99 |
|---|---|---|---|---|
| 1 | 0.953 | 0.948 | 0.946 | 0.946 |
| 2 | 0.952 | 0.948 | 0.949 | 0.944 |
| 3 | 0.952 | 0.951 | 0.949 | 0.946 |
| 4 | 0.952 | 0.948 | 0.947 | 0.946 |
| 5 | 0.950 | 0.951 | 0.948 | 0.944 |
| 6 | 0.954 | 0.946 | 0.946 | 0.946 |
| 7 | 0.950 | 0.948 | 0.942 | 0.947 |
| 8 | 0.950 | 0.951 | 0.948 | 0.945 |
| 9 | 0.952 | 0.949 | 0.946 | 0.944 |
| 10 | 0.953 | 0.946 | 0.945 | 0.943 |
| RF | KNN | |
|---|---|---|
| 1 | 0.939 | 0.557 |
| 2 | 0.942 | 0.556 |
| 3 | 0.945 | 0.555 |
| 4 | 0.941 | 0.562 |
| 5 | 0.941 | 0.561 |
| 6 | 0.937 | 0.549 |
| 7 | 0.938 | 0.543 |
| 8 | 0.941 | 0.551 |
| 9 | 0.94 | 0.559 |
| 10 | 0.94 | 0.557 |
| Repetition | Models | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| KNN raw | RF raw | 95_95 KNN | 95_99 KNN | 99_95 KNN | 99_99 KNN | 95_95 RF | 95_99 RF | 99_95 RF | 99_99 RF | |
| 1 | 55.91% | 94.35% | 55.61% | 56.34% | 55.63% | 56.17% | 88.15% | 90.80% | 88.34% | 90.92% |
| 2 | 55.04% | 94.47% | 73.13% | 75.26% | 73.01% | 75.38% | 88.2% | 90.30% | 87.80% | 90.73% |
| 3 | 55.72% | 94.09% | 59.51% | 60.17% | 59.06% | 60.31% | 87.54% | 90.14% | 87.35% | 90.47% |
| 4 | 55.56% | 94.44% | 63.39% | 62.56% | 63.43% | 62.65% | 87.51% | 90.71% | 87.91% | 91.30% |
| 5 | 56.67% | 94.73% | 57.43% | 57.99% | 57.40% | 58.07% | 87.73% | 90.87% | 88.03% | 89.97% |
| 6 | 56.27% | 94.61% | 69.16% | 66.34% | 69.51% | 66.86% | 87.89% | 90.82% | 88.17% | 91.75% |
| 7 | 57.05% | 95.15% | 63.86% | 61.28% | 64.71% | 61.24% | 88.91% | 91.56% | 88.58% | 92.05% |
| 8 | 55.56% | 94.44% | 68.00% | 69.09% | 68.28% | 69.11% | 88.10% | 90.42% | 88.48% | 91.23% |
| 9 | 56.17% | 94.47% | 64.69% | 65.45% | 65.28% | 65.71% | 87.63% | 90.78% | 87.80% | 91.11% |
| 10 | 55.87% | 95.1% | 59.67% | 59.67% | 59.56% | 59.44% | 88.08% | 91.11% | 88.55% | 90.78% |
| 95_95 KNN | 95_99 KNN | 99_95 KNN | 99_99 KNN | |
|---|---|---|---|---|
| Mean | 93.8% | 89.2% | 93.4% | 87.6% |
| Standard Deviation | 0.46% | 3.76% | 0.32% | 3.93% |
| P-Value | 0.0763 | 0.0189 | 0.4524 | 0.0128 |
| 95_95 KNN | 95_99 KNN | 99_95 KNN | 99_99 KNN | |
|---|---|---|---|---|
| Mean | 95.2% | 94.9% | 94.7% | 94.5% |
| Standard Deviation | 0.14% | 0.19% | 0.21% | 0.13% |
| P-Value | 0.083 | 0.0789 | 0.0.3061 | 0.1096 |
| KNN raw | RF raw | 95_95 KNN | 95_99 KNN | 99_95 KNN | 99_99 KNN | 95_95 RF | 95_99 RF | 99_95 RF | 99_99 RF | |
|---|---|---|---|---|---|---|---|---|---|---|
| Mean | 55.98% | 94.58% | 63.40% | 63.42% | 63.59% | 63.49% | 87.97% | 90.75% | 88.10% | 91.03% |
| Standard Deviation | 0.58% | 0.33% | 5.59% | 5.72% | 5.66% | 5.82% | 0.42% | 0.41% | 0.40% | 0.60% |
| P-Value | 0.8347 | 0.1165 | 0.8579 | 0.5615 | 0.8644 | 0.6167 | 0.2539 | 0.5110 | 0.6290 | 0.9490 |
| Model 1 | Model 2 | p-Value |
|---|---|---|
| 95_95_KNN | 95_99_ KNN | 0.003 |
| 95_95_ KNN | 99_95 _ KNN | 0.047 |
| 95_95_ KNN | 99_99_ KNN | 0.0007 |
| 95_99_ KNN | 99_95 _ KNN | 0.006 |
| 95_99_ KNN | 99_99_ KNN | 0.361 |
| 99_95 _ KNN | 99_99_ KNN | 0.001 |
| Model 1 | Model 2 | p-Value |
|---|---|---|
| 95_95_RF | 95_99_ RF | 0.0 |
| 95_95_ RF | 99_95 _ RF | 0.0 |
| 95_95_ RF | 99_99_ RF | 0.0 |
| 95_99_ RF | 99_95 _ RF | 0.039 |
| 95_99_ RF | 99_99_ RF | 0.0 |
| 99_95 _ RF | 99_99_ RF | 0.07 |
| Model 1 | Model 2 | p-Value |
|---|---|---|
| 95_95_RF | 95_99_ RF | 0.000 |
| 95_95_RF | 99_95 _RF | 0.494 |
| 95_95_RF | 99_99_RF | 0.000 |
| 95_99_ RF | 99_95 _RF | 0.000 |
| 95_99_ RF | 99_99_RF | 0.243 |
| 99_95 _RF | 99_99_RF | 0.000 |
| Raw Data Model | Clean Data Model | p-Value |
|---|---|---|
| KNN | 95_95_KNN | 0.002 |
| KNN | 95_99_ KNN | 0.003 |
| KNN | 99_95 _KNN | 0.002 |
| KNN | 99_99_KNN | 0.003 |
| Raw Data Model | Clean Data Model | p-Value |
|---|---|---|
| RF | 95_95_RF | 0.000 |
| RF | 95_99_ RF | 0.000 |
| RF | 99_95 _RF | 0.000 |
| RF | 99_99_RF | 0.000 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Neira-Rodado, D.; Nugent, C.; Cleland, I.; Velasquez, J.; Viloria, A. Evaluating the Impact of a Two-Stage Multivariate Data Cleansing Approach to Improve to the Performance of Machine Learning Classifiers: A Case Study in Human Activity Recognition. Sensors 2020, 20, 1858. https://doi.org/10.3390/s20071858
Neira-Rodado D, Nugent C, Cleland I, Velasquez J, Viloria A. Evaluating the Impact of a Two-Stage Multivariate Data Cleansing Approach to Improve to the Performance of Machine Learning Classifiers: A Case Study in Human Activity Recognition. Sensors. 2020; 20(7):1858. https://doi.org/10.3390/s20071858
Chicago/Turabian StyleNeira-Rodado, Dionicio, Chris Nugent, Ian Cleland, Javier Velasquez, and Amelec Viloria. 2020. "Evaluating the Impact of a Two-Stage Multivariate Data Cleansing Approach to Improve to the Performance of Machine Learning Classifiers: A Case Study in Human Activity Recognition" Sensors 20, no. 7: 1858. https://doi.org/10.3390/s20071858
APA StyleNeira-Rodado, D., Nugent, C., Cleland, I., Velasquez, J., & Viloria, A. (2020). Evaluating the Impact of a Two-Stage Multivariate Data Cleansing Approach to Improve to the Performance of Machine Learning Classifiers: A Case Study in Human Activity Recognition. Sensors, 20(7), 1858. https://doi.org/10.3390/s20071858