A Unified Deep Framework for Joint 3D Pose Estimation and Action Recognition from a Single RGB Camera

 , ,
, ,  ,
,  and
and
Abstract
1. Introduction
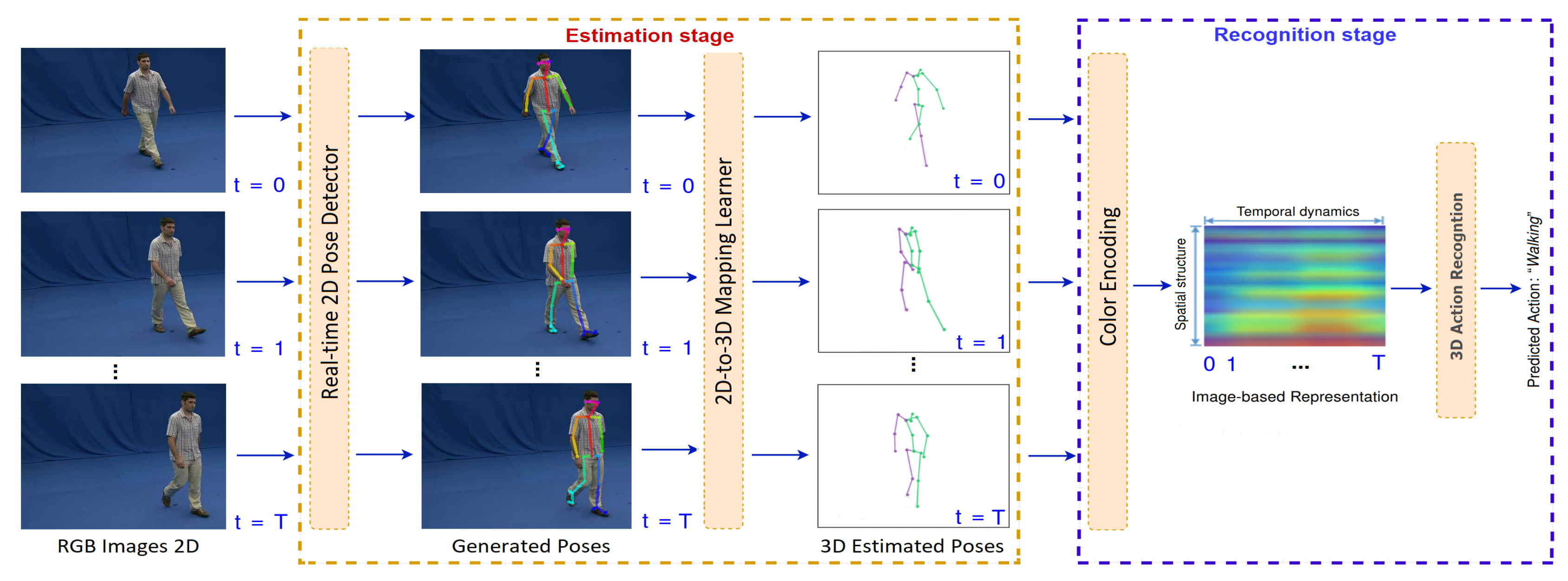
- First, we present a two-stream, lightweight neural network to recover 3D human poses from RGB images provided by a monocular camera. The proposed method achieves state-of-the-art result on 3D human pose estimation task and benefits action recognition. The novelty of the study is that a very simple deep neural network could be trained effectively to learn a 2D-to-3D mapping for the task of 3D human estimation from color sensors.
- Second, we propose to put an action recognition approach on top of the 3D pose estimator to form a unified framework for 3D pose-based action recognition. It takes the 3D estimated poses as inputs, encodes them into a compact image-based representation and finally feeds to a deep convolutional network, which is designed automatically by using a neural architecture search algorithm. Surprisingly, the experiments show that we reached state-of-the-art results on this task, even when compared with methods using depth cameras.
2. Related Work
2.1. 3D Human Pose Estimation
2.2. 3D Pose-Based Action Recognition
3. Proposed Method
3.1. Problem Definition
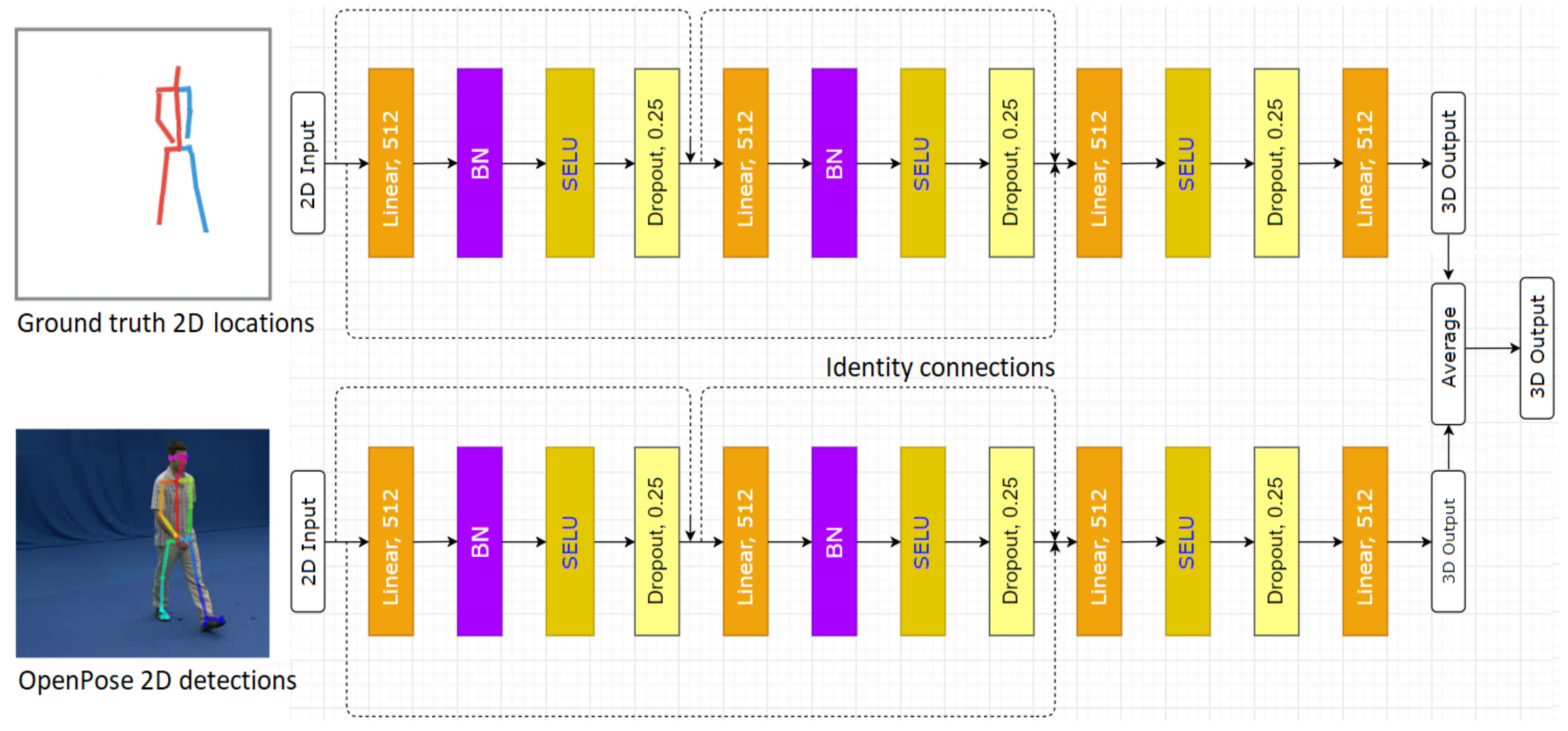
3.2. 3D Human Pose Estimation
Network Design
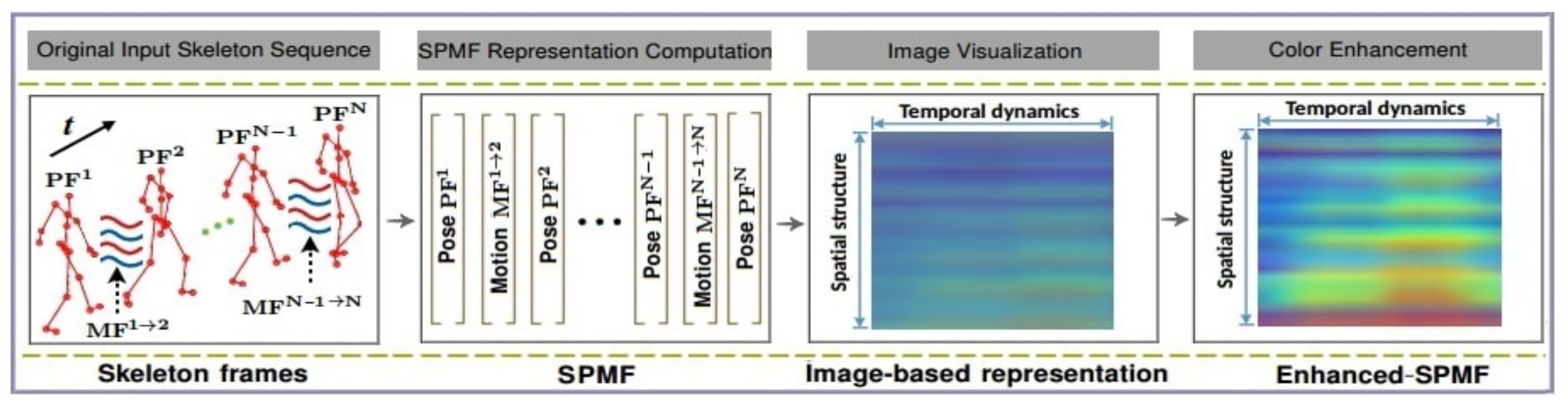
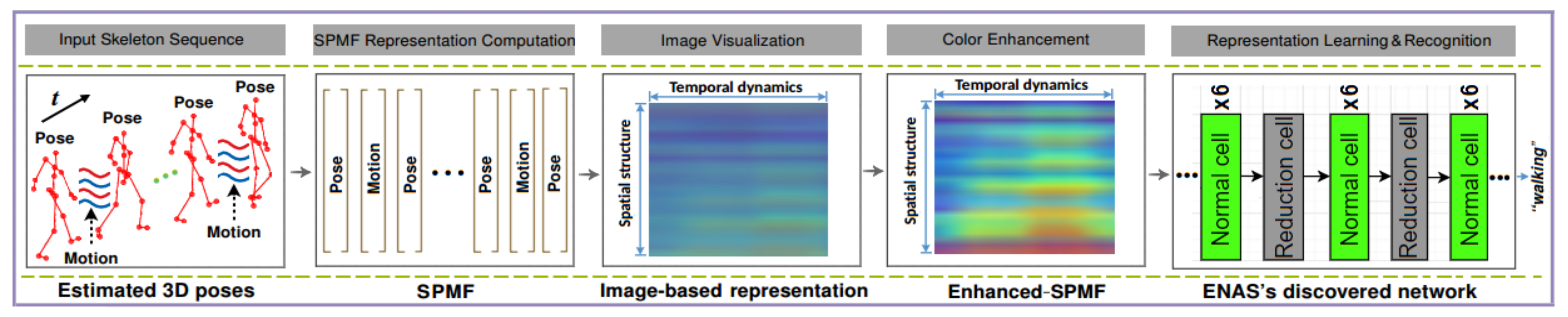
3.3. 3D Pose-Based Action Recognition
4. Experiments
4.1. Datasets and Settings
4.2. Implementation Details
4.3. Experimental Results and Comparison
4.3.1. Evaluation on 3D Pose Estimation
4.3.2. Evaluation on Action Recognition
4.4. Computational Efficiency Evaluation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Weinland, D.; Ronfard, R.; Boyer, E. A Survey of Vision-based Methods for Action Representation, Segmentation and Recognition. CVIU 2011, 115, 224–241. [Google Scholar] [CrossRef]
- Lowe, D. Distinctive Image Features from Scale-invariant Keypoints. IJCV 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Laptev, I.; Marszalek, M.; Schmid, C.; Rozenfeld, B. Learning Realistic Human Actions from Movies. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AL, USA, 24–26 June 2008; pp. 1–8. [Google Scholar]
- Dollár, P.; Rabaud, V.; Cottrell, G.; Belongie, S. Behavior Recognition via Sparse Spatio-temporal Features. In Proceedings of the IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance (VS-PETS), Breckenridge, CO, USA, 7 January 2005; pp. 65–72. [Google Scholar]
- Ye, M.; Yang, R. Real-time Simultaneous Pose and Shape Estimation for Articulated Objects using a Single Depth Camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 2345–2352. [Google Scholar]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Mining Actionlet Ensemble for Action Recognition with Depth Cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 18–20 June 2012; pp. 1290–1297. [Google Scholar]
- Xia, L.; Chen, C.; Aggarwal, J.K. View-Invariant Human Action Recognition using Histograms of 3D Joints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 18–20 June 2012; pp. 20–27. [Google Scholar]
- Chaudhry, R.; Ofli, F.; Kurillo, G.; Bajcsy, R.; Vidal, R. Bio-inspired Dynamic 3D Discriminative Skeletal Features for Human Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 471–478. [Google Scholar]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human Action Recognition by Representing 3D Skeletons as Points in a Lie Group. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 588–595. [Google Scholar]
- Ding, W.; Liu, K.; Fu, X.; Cheng, F. Profile HMMs for Skeleton-based Human Action Recognition. Signal Process. Image Commun. 2016, 42, 109–119. [Google Scholar] [CrossRef]
- Zhang, Z. Microsoft Kinect Sensor and Its Effect. IEEE Multimed. 2012, 19, 4–10. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.; Sheikh, Y. Realtime Multi-person 2D Pose Estimation using Part Affinity Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 7291–7299. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. RMPE: Regional Multi-person Pose Estimation. ICCV. 2017. Available online: https://github.com/MVIG-SJTU/AlphaPose (accessed on 23 March 2020).
- Pham, H.; Guan, M.; Zoph, B.; Le, Q.; Dean, J. Efficient Neural Architecture Search via Parameters Sharing. In Proceedings of the International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; pp. 4095–4104. [Google Scholar]
- Johansson, G. Visual Motion Perception. Sci. Am. 1975, 232, 76–89. [Google Scholar] [CrossRef] [PubMed]
- Gu, J.; Ding, X.; Wang, S.; Wu, Y. Action and Gait Recognition from Recovered 3D Human Joints. IEEE Trans. Syst. Man Cybern. 2010, 40, 1021–1033. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 483–499. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2014, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Zhang, Z.; Liu, Z. Action Recognition Based on a Bag of 3D Points. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 9–14. [Google Scholar]
- Yun, K.; Honorio, J.; Chattopadhyay, D.; Berg, T.L.; Samaras, D. Two-person Interaction Detection using Body-pose Features and Multiple Instance Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 18–20 June 2012; pp. 28–35. [Google Scholar]
- Nikolaos, S.; Bogdan, B.; Bogdan, I.; Ioannis, A.K. 3D Human Pose Estimation: A Review of the Literature and Analysis of Covariates. CVIU 2016, 152, 1–20. [Google Scholar]
- Presti, L.; La Cascia, M. 3D Skeleton-based Human Action Classification: A Survey. Pattern Recognit. 2016, 53, 130–147. [Google Scholar] [CrossRef]
- Sminchisescu, C. 3D Human Motion Analysis in Monocular Video Techniques and Challenges. In Proceedings of the IEEE International Conference on Video and Signal Based Surveillance (ICVSBS), Sydney, Australia, 22–24 November 2006; p. 76. [Google Scholar]
- Ramakrishna, V.; Kanade, T.; Sheikh, Y. Reconstructing 3D Human Pose from 2D Image Landmarks. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 573–586. [Google Scholar]
- Li, S.; Chan, A.B. 3D Human Pose Estimation from Monocular Images with Deep Convolutional Neural Network. In Proceedings of the Asian Conference on Computer Vision (ACCV), Singapore, 1–5 November 2014; pp. 332–347. [Google Scholar]
- Tekin, B.; Rozantsev, A.; Lepetit, V.; Fua, P. Direct Prediction of 3D Body Poses from Motion Compensated Sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 991–1000. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Derpanis, K.G.; Daniilidis, K. Coarse-to-fine Volumetric Prediction for Single-image 3D Human Pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 7025–7034. [Google Scholar]
- Pavllo, D.; Feichtenhofer, C.; Grangier, D.; Auli, M. 3D Human Pose Estimation in Video with Temporal Convolutions and Semi-supervised Training. arXiv 2018, arXiv:1811.11742. [Google Scholar]
- Mehta, D.; Sridhar, S.; Sotnychenko, O.; Rhodin, H.; Shafiei, M.; Seidel, H.P.; Xu, W.; Casas, D.; Theobalt, C. VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera. ACM TOG 2017, 36, 44. [Google Scholar] [CrossRef]
- Katircioglu, I.; Tekin, B.; Salzmann, M.; Lepetit, V.; Fua, P. Learning Latent Representations of 3D Human Pose with Deep Neural Networks. IJCV 2018, 126, 1326–1341. [Google Scholar] [CrossRef]
- Fisher, Y.; Vladlen, K. Multi-scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Sepp, H.; Jürgen, S. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar]
- Martinez, J.; Hossain, R.; Romero, J.; Little, J. A Simple Yet Effective Baseline for 3D Human Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2640–2649. [Google Scholar]
- Lv, F.; Nevatia, R. Recognition and Segmentation of 3D Human Action Using HMM and Multi-class AdaBoost. In Proceedings of the European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006; pp. 359–372. [Google Scholar]
- Han, L.; Wu, X.; Liang, W.; Hou, G.; Jia, Y. Discriminative Human Action Recognition in the Learned Hierarchical Manifold Space. Image Vis. Comput. 2010, 28. [Google Scholar] [CrossRef]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-temporal LSTM with Trust Gates for 3D Human Action Recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 816–833. [Google Scholar]
- Du, Y.; Wang, W.; Wang, L. Hierarchical Recurrent Neural Network for Skeleton based Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 1110–1118. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+ D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1010–1019. [Google Scholar]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, Long Short-Term Memory, Fully Connected Deep Neural Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 4580–4584. [Google Scholar]
- Chéron, G.; Laptev, I.; Schmid, C. P-CNN: Pose-based CNN Features for Action Recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 3218–3226. [Google Scholar]
- Yao, B.; Fei-Fei, L. Modeling Mutual Context of Object and Human Pose in Human-object Interaction Activities. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 17–24. [Google Scholar]
- Nie, B.X.; Xiong, C.; Zhu, S. Joint Action Recognition and Pose Estimation from Video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 1293–1301. [Google Scholar]
- Luvizon, D.C.; Picard, D.; Tabia, H. 2D/3D Pose Estimation and Action Recognition using Multitask Deep Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5137–5146. [Google Scholar]
- Huber, P.J. Robust Estimation of a Location Parameter. In Breakthroughs in Statistics; Springer: New York, NY, USA, 1992; pp. 492–518. [Google Scholar]
- Christian, S.; Sergey, I.; Vincent, V. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Phoenix, AR, USA, 12–17 February 2016. [Google Scholar]
- Gao, H.; Zhuang, L.; Laurens van der, M.; Kilian, Q.W. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Barret, Z.; Quoc, V.L. Neural Architecture Search with Reinforcement Learning. arXiv 2017, arXiv:1611.01578. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Improving Neural Networks by Preventing Co-adaptation of Feature Detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-Normalizing Neural Networks. Adv. Neural Inf. Process. Syst. (NIPS) 2017, 971–980. [Google Scholar]
- Pham, H.; Khoudour, L.; Crouzil, A.; Zegers, P.; Velastin, S.A. Exploiting Deep Residual Networks for Human Action Recognition from Skeletal Data. CVIU 2018, 170, 51–66. [Google Scholar] [CrossRef]
- Pham, H.; Khoudour, L.; Crouzil, A.; Zegers, P.; Velastin, S.A. Skeletal Movement to Color Map: A Novel Representation for 3D Action Recognition with Inception Residual Networks. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3483–3487. [Google Scholar]
- Pham, H.; Salmane, H.; Khoudour, L.; Crouzil, A.; Zegers, P.; Velastin, S.A. Spatio-Temporal Image Representation of 3D Skeletal Movements for View-Invariant Action Recognition with Deep Convolutional Neural Networks. Sensors 2019, 19, 1932. [Google Scholar] [CrossRef]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive Histogram Equalization and Its Variations. Comput. Vision, Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Pham, H.H.; Salmane, H.; Khoudour, L.; Crouzil, A.; Zegers, P.; Velastin, S.A. A Deep Learning Approach for Real-Time 3D Human Action Recognition from Skeletal Data. In Proceedings of the International Conference on Image Analysis and Recognition. Springer, Waterloo, Canada, 27–29 August 2019; pp. 18–32. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 1026–1034. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Yurii, N. A Method for Solving a Convex Programming Problem with Convergence Rate O(1/K2). Sov. Math. Dokl. 1983, 372–377. [Google Scholar]
- Ilya, L.; Frank, H. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Du, Y.; Wong, Y.; Liu, Y.; Han, F.; Gui, Y.; Wang, Z.; Kankanhalli, M.; Geng, W. Marker-less 3D Human Motion Capture with Monocular Image Sequence and Height-maps. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 20–36. [Google Scholar]
- Park, S.; Hwang, J.; Kwak, N. 3D Human Pose Estimation using Convolutional Neural Networks with 2D Pose Information. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 156–169. [Google Scholar]
- Zhou, X.; Zhu, M.; Leonardos, S.; Derpanis, K.G.; Daniilidis, K. Sparseness Meets Deepness: 3D Human Pose Estimation from Monocular Video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4966–4975. [Google Scholar]
- Xingyi, Z.; Xiao, S.; Wei, Z.; Shuang, L.; Yichen, W. Deep Kinematic Pose Regression. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 186–201. [Google Scholar]
- Mehta, D.; Rhodin, H.; Casas, D.; Fua, P.; Sotnychenko, O.; Xu, W.; Theobalt, C. Monocular 3D Human Pose Estimation in the Wild using Improved CNN Supervision. In Proceedings of the International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 506–516. [Google Scholar]
- Shuang, L.; Xiao, S.; Yichen, W. Compositional Human Pose Regression. Comput. Vis. Image Underst. 2018, 176–177, 1–8. [Google Scholar]
- Chen, C.; Liu, K.; Kehtarnavaz, N. Real-time Human Action Recognition based on Depth Motion Maps. J. -Real-Time Image Process. 2016, 12. [Google Scholar] [CrossRef]
- Wang, P.; Yuan, C.; Hu, W.; Li, B.; Zhang, Y. Graph Based Skeleton Motion Representation and Similarity Measurement for Action Recognition. In Proceedings of the British Machine Vision Conference (BMVC), York, UK, 19–22 September 2016. [Google Scholar]
- Weng, J.; Weng, C.; Yuan, J. Spatio-Temporal Naive-Bayes Nearest-Neighbor (ST-NBNN) for Skeleton-Based Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–26 July 2017. [Google Scholar]
- Xu, H.; Chen, E.; Liang, C.; Qi, L.; Guan, L. Spatio-temporal Pyramid Model based on Depth Maps for Action Recognition. In Proceedings of the IEEE International Workshop on Multimedia Signal Processing (MMSP), Xiamen, China, 19–21 October 2015; pp. 1–6. [Google Scholar]
- Lee, I.; Kim, D.; Kang, S.; Lee, S. Ensemble Deep Learning for Skeleton-based Action Recognition using Temporal Sliding LSTM Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1012–1020. [Google Scholar]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. An End-to-End Spatio-Temporal Attention Model for Human Action Recognition from Skeleton Data. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Weng, J.; Weng, C.; Yuan, J.; Liu, Z. Discriminative Spatio-Temporal Pattern Discovery for 3D Action Recognition. IEEE Trans. Circuits Syst. Video Technol. (TCCVT) 2019, 29, 1077–1089. [Google Scholar] [CrossRef]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A New Representation of Skeleton Sequences for 3D Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4570–4579. [Google Scholar]
- Yusuf, T.; Piotr, K. CNN-based Action Recognition and Supervised Domain Adaptation on 3D Body Skeletons via Kernel Feature Maps. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018; p. 158. [Google Scholar]
- Wang, H.; Wang, L. Modeling Temporal Dynamics and Spatial Configurations of Actions Using Two-Stream Recurrent Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3633–3642. [Google Scholar]
- Liu, J.; Wang, G.; Duan, L.; Abdiyeva, K.; Kot, A.C. Skeleton-Based Human Action Recognition With Global Context-Aware Attention LSTM Networks. IEEE Trans. Image Process. (TIP) 2018, 27, 1586–1599. [Google Scholar] [CrossRef]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View Adaptive Neural Networks for High Performance Skeleton-based Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2019, 1963–1978. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
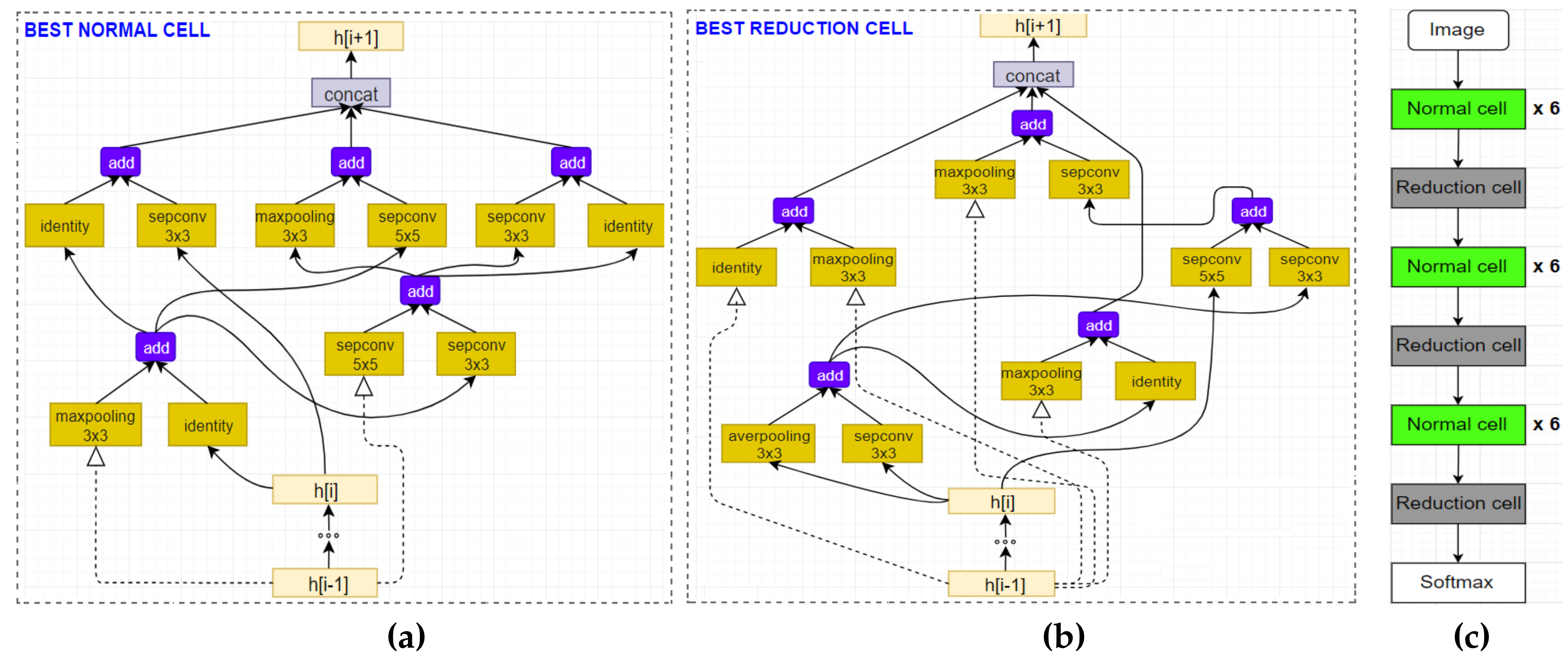{kind=link}
| Method | Direct. | Disc. | Eat | Greet | Phone | Photo | Pose | Purch. | Sit | SitD | Smoke | Wait | WalkD | Walk | WalkT | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ionescu et al. [18]† | 132.7 | 183.6 | 132.3 | 164.4 | 162.1 | 205.9 | 150.6 | 171.3 | 151.6 | 243.0 | 162.1 | 170.7 | 177.1 | 96.6 | 127.9 | 162.1 |
| Du et al. [61] | 85.1 | 112.7 | 104.9 | 122.1 | 139.1 | 135.9 | 105.9 | 166.2 | 117.5 | 226.9 | 120.0 | 117.7 | 137.4 | 99.3 | 106.5 | 126.5 |
| Tekin et al. [26] | 102.4 | 147.2 | 88.8 | 125.3 | 118.0 | 182.7 | 112.4 | 129.2 | 138.9 | 224.9 | 118.4 | 138.8 | 126.3 | 55.1 | 65.8 | 125.0 |
| Park et al. [62] | 100.3 | 116.2 | 90.0 | 116.5 | 115.3 | 149.5 | 117.6 | 106.9 | 137.2 | 190.8 | 105.8 | 125.1 | 131.9 | 62.6 | 96.2 | 117.3 |
| Zhou et al. [63] | 87.4 | 109.3 | 87.1 | 103.2 | 116.2 | 143.3 | 106.9 | 99.8 | 124.5 | 199.2 | 107.4 | 118.1 | 114.2 | 79.4 | 97.7 | 113.0 |
| Zhou et al. [64] | 91.8 | 102.4 | 96.7 | 98.8 | 113.4 | 125.2 | 90.0 | 93.8 | 132.2 | 159.0 | 107.0 | 94.4 | 126.0 | 79.0 | 99.0 | 107.3 |
| Pavlakos et al. [27] | 67.4 | 71.9 | 66.7 | 69.1 | 72.0 | 77.0 | 65.0 | 68.3 | 83.7 | 96.5 | 71.7 | 65.8 | 74.9 | 59.1 | 63.2 | 71.9 |
| Mehta et al. [65] | 67.4 | 71.9 | 66.7 | 69.1 | 71.9 | 65.0 | 68.3 | 83.7 | 120.0 | 66.0 | 79.8 | 63.9 | 48.9 | 76.8 | 53.7 | 68.6 |
| Martinez et al. [34] | 51.8 | 56.2 | 58.1 | 59.0 | 69.5 | 55.2 | 58.1 | 74.0 | 94.6 | 62.3 | 78.4 | 59.1 | 49.5 | 65.1 | 52.4 | 62.9 |
| Liang et al. [66] | 52.8 | 54.2 | 54.3 | 61.8 | 53.1 | 53.6 | 71.7 | 86.7 | 61.5 | 53.4 | 67.2 | 54.8 | 53.4 | 47.1 | 61.6 | 59.1 |
| Luvizon et al. [44] | 49.2 | 51.6 | 47.6 | 50.5 | 51.8 | 48.5 | 51.7 | 61.5 | 70.9 | 53.7 | 60.3 | 48.9 | 44.4 | 57.9 | 48.9 | 53.2 |
| Martinez et al. [34]† | 37.7 | 44.4 | 40.3 | 42.1 | 48.2 | 54.9 | 44.4 | 42.1 | 54.6 | 58.0 | 45.1 | 46.4 | 47.6 | 36.4 | 40.4 | 45.5 |
| Ours🟉 | 36.6 | 43.2 | 38.1 | 40.8 | 44.4 | 51.8 | 43.7 | 38.4 | 50.8 | 52.0 | 42.1 | 42.2 | 44.0 | 32.3 | 35.9 | 42.4 |
| Method | AS1 | AS2 | AS3 | Aver. |
|---|---|---|---|---|
| Li et al. [19] | 72.90 | 71.90 | 71.90 | 74.70 |
| Chen et al. [67] | 96.20 | 83.20 | 92.00 | 90.47 |
| Vemulapalli et al. [9] | 95.29 | 83.87 | 98.22 | 92.46 |
| Du et al. [38] | 99.33 | 94.64 | 95.50 | 94.49 |
| Liu et al. [37] | N/A | N/A | N/A | 94.80 |
| Wang et al. [68] | 93.60 | 95.50 | 95.10 | 94.80 |
| Wang et al. [69] | 91.50 | 95.60 | 97.30 | 94.80 |
| Xu et al. [70] | 99.10 | 92.90 | 96.40 | 96.10 |
| Lee et al. [71] | 95.24 | 96.43 | 100.0 | 97.22 |
| Pham et al. [54] | 98.83 | 99.06 | 99.40 | 99.10 |
| Ours | 97.87 | 96.81 | 99.27 | 97.98 |
| Method | Acc. |
|---|---|
| Song et al. [72] | 91.51 |
| Liu et al. [37] | 93.30 |
| Weng et al. [73] | 93.30 |
| Ke et al. [74] | 93.57 |
| Tas et al. [75] | 94.36 |
| Wang et al. [76] | 94.80 |
| Liu et al. [77] | 94.90 |
| Zang et al. [78] (using VA-RNN) | 95.70 |
| Zhang et al. [78] (using VA-CNN) | 97.50 |
| Pham et al. [54] | 97.86 |
| Ours | 96.30 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pham, H.H.; Salmane, H.; Khoudour, L.; Crouzil, A.; Velastin, S.A.; Zegers, P. A Unified Deep Framework for Joint 3D Pose Estimation and Action Recognition from a Single RGB Camera. Sensors 2020, 20, 1825. https://doi.org/10.3390/s20071825
Pham HH, Salmane H, Khoudour L, Crouzil A, Velastin SA, Zegers P. A Unified Deep Framework for Joint 3D Pose Estimation and Action Recognition from a Single RGB Camera. Sensors. 2020; 20(7):1825. https://doi.org/10.3390/s20071825
Chicago/Turabian StylePham, Huy Hieu, Houssam Salmane, Louahdi Khoudour, Alain Crouzil, Sergio A. Velastin, and Pablo Zegers. 2020. "A Unified Deep Framework for Joint 3D Pose Estimation and Action Recognition from a Single RGB Camera" Sensors 20, no. 7: 1825. https://doi.org/10.3390/s20071825
APA StylePham, H. H., Salmane, H., Khoudour, L., Crouzil, A., Velastin, S. A., & Zegers, P. (2020). A Unified Deep Framework for Joint 3D Pose Estimation and Action Recognition from a Single RGB Camera. Sensors, 20(7), 1825. https://doi.org/10.3390/s20071825