Jellytoring: Real-Time Jellyfish Monitoring Based on Deep Learning Object Detection



Abstract
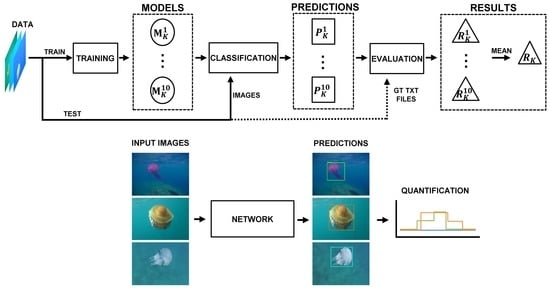
1. Introduction
2. Related Work and Contributions
2.1. State-of-the-Art
2.2. Main Contributions
- A real-time jellyfish monitoring system based on deep learning object detection named Jellytoring, which provides highly valuable information to biologists, ecologists and conservationists on the presence and occurrence of different species of jellyfish in an studied area.
- The usage of a deep CNN, trained several times to fine tune its hyperparameters to detect and classify up to three different species of jellyfish on underwater images. We evaluated the network on a test set of images, comparing its results to other neural networks.
- First system to achieve real-time automatic quantification and identification of different species of jellyfish. We designed and tested an algorithm that can be executed in real-time and uses the network detection to quantify and monitor jellyfish presence on video sequences.
- The creation of a publicly available dataset used for the training and testing of the neural network and the quantification algorithm, containing the original images and corresponding annotations.
3. Deep Learning Approach
3.1. Framework and Network Selection
3.2. Training Details
4. Methodology
4.1. Workflow
4.2. Data Collection
4.3. Hyperparameter Selection
- Data augmentation: it is a technique that consists of applying random rotations and horizontal and vertical transformations to the training images in order to train over more diverse data, helping to reduce overfitting [62].
- Learning rate: this hyperparameter modifies the training step size the network uses when searching for an optimal solution. We also studied the effect of applying a decay learning rate, which consists of lowering the learning rate value as the training progresses [63].
- Number of iterations: this hyperparameter sets the number of times the network back-propagates and trains [63].
4.4. Validation
4.5. Model Evaluation
4.6. Real-Time Quantification
5. Results and Discussion
5.1. Experiment Performance
5.2. Real-Time Quantification
5.3. Neural Network Performance Comparison
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pauly, D.; Watson, R.; Alder, J. Global trends in world fisheries: Impacts on marine ecosystems and food security. Philos. Trans. R. Soc. B Biol. Sci. 2005, 360, 5–12. [Google Scholar] [CrossRef] [PubMed]
- Kaiser, M.; Collie, J.; Hall, S.; Jennings, S.; Poiner, I. Modification of marine habitats by trawling activities: Prognosis and solutions. Fish Fish. 2002, 3, 114–136. [Google Scholar] [CrossRef]
- Galil, B.S. Loss or gain? Invasive aliens and biodiversity in the Mediterranean Sea. Mar. Pollut. Bull. 2007, 55, 314–322. [Google Scholar] [CrossRef]
- Islam, M.S.; Tanaka, M. Impacts of pollution on coastal and marine ecosystems including coastal and marine fisheries and approach for management: A review and synthesis. Mar. Pollut. Bull. 2004, 48, 624–649. [Google Scholar] [CrossRef]
- Hughes, T.; Baird, A.; Bellwood, D.; Card, M.; Connolly, S.; Folke, C.; Grosberg, R.; Hoegh-Guldberg, O.; Jackson, J.; Kleypas, J.; et al. Climate change, human impacts, and the resilience of coral reefs. Science 2003, 301, 929–933. [Google Scholar] [CrossRef]
- Perry, A.L.; Low, P.J.; Ellis, J.R.; Reynolds, J.D. Ecology: Climate change and distribution shifts in marine fishes. Science 2005, 308, 1912–1915. [Google Scholar] [CrossRef]
- Halpern, B.; Walbridge, S.; Selkoe, K.; Kappel, C.; Micheli, F.; D’Agrosa, C.; Bruno, J.; Casey, K.; Ebert, C.; Fox, H.; et al. A Global Map of Human Impact on Marine Ecosystems. Science 2008, 319, 948–952. [Google Scholar] [CrossRef]
- Millennium Ecosystem Assessment. Ecosystems and Human Well-Being: A Framework Working Group for Assessment Report of the Millennium Ecosystem Assessment; Island Press: Washington, DC, USA, 2005; p. 245. [Google Scholar]
- Caughlan, L. Cost considerations for long-term ecological monitoring. Ecol. Indic. 2001, 1, 123–134. [Google Scholar] [CrossRef]
- Del Vecchio, S.; Fantinato, E.; Silan, G.; Buffa, G. Trade-offs between sampling effort and data quality in habitat monitoring. Biodivers. Conserv. 2019, 28, 55–73. [Google Scholar] [CrossRef]
- Moniruzzaman, M.; Islam, S.; Bennamoun, M.; Lavery, P. Deep Learning on Underwater Marine Object Detection: A Survey. In Proceedings of the Advanced Concepts for Intelligent Vision Systems (ACIVS), Antwerp, Belgium, 18–21 September 2017; pp. 150–160. [Google Scholar]
- Borowicz, A.; McDowall, P.; Youngflesh, C.; Sayre-McCord, T.; Clucas, G.; Herman, R.; Forrest, S.; Rider, M.; Schwaller, M.; Hart, T.; et al. Multi-modal survey of Adélie penguin mega-colonies reveals the Danger Islands as a seabird hotspot. Sci. Rep. 2018, 8, 3926. [Google Scholar] [CrossRef]
- Gomez Villa, A.; Salazar, A.; Vargas, F. Towards automatic wild animal monitoring: Identification of animal species in camera-trap images using very deep convolutional neural networks. Ecol. Inf. 2017, 41, 24–32. [Google Scholar] [CrossRef]
- Hong, S.J.; Han, Y.; Kim, S.Y.; Lee, A.Y.; Kim, G. Application of Deep-Learning Methods to Bird Detection Using Unmanned Aerial Vehicle Imagery. Sensors 2019, 19, 1651. [Google Scholar] [CrossRef]
- Valletta, J.J.; Torney, C.; Kings, M.; Thornton, A.; Madden, J. Applications of machine learning in animal behaviour studies. Anim. Behav. 2017, 124, 203–220. [Google Scholar] [CrossRef]
- Li, X.; Shang, M.; Qin, H.; Chen, L. Fast accurate fish detection and recognition of underwater images with Fast R-CNN. In Proceedings of the OCEANS 2015-MTS/IEEE, Washington, DC, USA, 19–22 October 2015; pp. 1–5. [Google Scholar]
- Li, X.; Shang, M.; Hao, J.; Yang, Z. Accelerating fish detection and recognition by sharing CNNs with objectness learning. In Proceedings of the OCEANS 2016, Shanghai, China, 10–13 April 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Villon, S.; Chaumont, M.; Subsol, G.; Villéger, S.; Claverie, T.; Mouillot, D. Coral Reef Fish Detection and Recognition in Underwater Videos by Supervised Machine Learning: Comparison Between Deep Learning and HOG+SVM Methods. In Proceedings of the Advanced Concepts for Intelligent Vision Systems, Lecce, Italy, 24–27 October 2016; pp. 160–171. [Google Scholar]
- Levy, D.; Levy, D.; Belfer, Y.; Osherov, E.; Bigal, E.; Scheinin, A.P.; Nativ, H.; Tchernov, D.; Treibitz, T. Automated Analysis of Marine Video with Limited Data. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1466–14668. [Google Scholar] [CrossRef]
- Gray, P.C.; Fleishman, A.B.; Klein, D.J.; McKown, M.W.; Bézy, V.S.; Lohmann, K.J.; Johnston, D.W. A Convolutional Neural Network for Detecting Sea Turtles in Drone Imagery. Methods Ecol. Evol. 2019, 10, 345–355. [Google Scholar] [CrossRef]
- Py, O.; Hong, H.; Zhongzhi, S. Plankton classification with deep convolutional neural networks. In Proceedings of the 2016 IEEE Information Technology, Networking, Electronic and Automation Control Conference, Chongqing, China, 20–22 May 2016; pp. 132–136. [Google Scholar]
- O’Mahony, N.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Hernandez, G.V.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep Learning vs. Traditional Computer Vision. Adv. Comput. Vis. 2020, 128–144. [Google Scholar] [CrossRef]
- Lowe, D. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Lienhart, R.; Maydt, J. An Extended Set of Haar-like Features for Rapid Object Detection. In Proceedings of the International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. Int. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.A.; Ramanan, D. Object Detection with Discriminatively Trained Part Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 91–99. [Google Scholar] [CrossRef]
- Lee, J.; Choi, H.-W.; Chae, J.; Kim, D.; Lee, S. Performance analysis of intake screens in power plants on mass impingement of marine organisms. Ocean Polar Res. 2006, 28, 385–393. [Google Scholar]
- Matsumura, K.; Kamiya, K.; Yamashita, K.; Hayashi, F.; Watanabe, I.; Murao, Y.; Miyasaka, H.; Kamimura, N.; Nogami, M. Genetic polymorphism of the adult medusae invading an electric power station and wild polyps of Aurelia aurita in Wakasa Bay, Japan. J. Mar. Biol. Assoc. UK 2005, 85, 563–568. [Google Scholar] [CrossRef]
- Purcell, J.E.; Baxter, E.J.; Fuentes, V.L. Jellyfish as products and problems of aquaculture. Adv. Aquacult. Hatch. Technol. 2013, 404–430. [Google Scholar] [CrossRef]
- Merceron, M.; Le Fevre-Lehoerff, G.; Bizouarn, Y.; Kempf, M. Fish and jellyfish in Brittany (France). Equinoxe 1995, 56, 6–8. [Google Scholar]
- Purcell, J.E.; Uye, S.i.I.; Lo, W.T.T. Anthropogenic causes of jellyfish blooms and their direct consequences for humans: A review. Mar. Ecol. Prog. Ser. 2007, 350, 153–174. [Google Scholar] [CrossRef]
- Fenner, P.J.; Lippmann, J.; Gershwin, L. Fatal and Nonfatal Severe Jellyfish Stings in Thai Waters. J. Travel Med. 2010, 17, 133–138. [Google Scholar] [CrossRef]
- Pierce, J. Prediction, location, collection and transport of jellyfish (Cnidaria) and their polyps. Zoo Biol. 2009, 28, 163–176. [Google Scholar] [CrossRef]
- Graham, W.M.; Martin, D.L.; Martin, J.C. In situ quantification and analysis of large jellyfish using a novel video profiler. Mar. Ecol. Prog. Ser. 2003, 254, 129–140. [Google Scholar] [CrossRef]
- Houghton, J.; Doyle, T.; Davenport, J.; Hays, G. Developing a simple, rapid method for identifying and monitoring jellyfish aggregations from the air. Mar. Ecol. Prog. Ser. 2006, 314, 159–170. [Google Scholar] [CrossRef]
- Langlois, T.J.; Harvey, E.S.; Fitzpatrick, B.; Meeuwig, J.J.; Shedrawi, G.; Watson, D.L. Cost-efficient sampling of fish assemblages: Comparison of baited video stations and diver video transects. Aquat. Biol. 2010, 9, 155–168. [Google Scholar] [CrossRef]
- Holmes, T.H.; Wilson, S.K.; Travers, M.J.; Langlois, T.J.; Evans, R.D.; Moore, G.I.; Douglas, R.A.; Shedrawi, G.; Harvey, E.S.; Hickey, K. A comparison of visual- and stereo-video based fish community assessment methods in tropical and temperate marine waters of Western Australia. Limnol. Oceanogr. Methods 2013, 11, 337–350. [Google Scholar] [CrossRef]
- Rife, J.; Rock, S.M. Segmentation methods for visual tracking of deep-ocean jellyfish using a conventional camera. IEEE J. Ocean. Eng. 2003, 28, 595–608. [Google Scholar] [CrossRef]
- Wäldchen, J.; Mäder, P. Machine learning for image based species identification. Methods Ecol. Evol. 2018, 9, 2216–2225. [Google Scholar] [CrossRef]
- Willi, M.; Pitman, R.T.; Cardoso, A.W.; Locke, C.; Swanson, A.; Boyer, A.; Veldthuis, M.; Fortson, L. Identifying animal species in camera trap images using deep learning and citizen science. Methods Ecol. Evol. 2018, 2018, 1–12. [Google Scholar] [CrossRef]
- Kim, H.; Koo, J.; Kim, D.; Jung, S.; Shin, J.; Lee, S.; Myung, H. Image-Based Monitoring of Jellyfish Using Deep Learning Architecture. IEEE Sens. J. 2016, 16, 2215–2216. [Google Scholar] [CrossRef]
- French, G.; Mackiewicz, M.; Fisher, M.; Challis, M.; Knight, P.; Robinson, B.; Bloomfield, A. JellyMonitor: Automated detection of jellyfish in sonar images using neural networks. In Proceedings of the 14th IEEE International Conference on Signal Processing, Beijing, China, 12–16 August 2018; pp. 406–412. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. arXiv 2017, arXiv:1703.06870. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the NIPS, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Adebayo, J.; Gilmer, J.; Muelly, M.; Goodfellow, I.; Hardt, M.; Kim, B. Sanity Checks for Saliency Maps. In Proceedings of the Advances in Neural Information Processing Systems 31, Montreal, QC, Canada, 2–8 December 2018; pp. 9505–9515. [Google Scholar]
- Google-Tensorflow. COCO-Trained Models. 2018. Available online: https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md (accessed on 30 January 2020).
- Lin, T.Y.; Maire, M.; Belongie, S.J.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Cadiz, Spain, 9–11 May 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the Difficulty of Training Recurrent Neural Networks. In Proceedings of the 30th International Conference on International Conference on Machine Learning-Volume 28, Atlanta, GA, USA, 16–21 June 2013; pp. III-1310–III-1318. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient Non-Maximum Suppression. In Proceedings of the International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006; pp. 850–855. [Google Scholar]
- Tzutalin, D. LabelImg. 2018. Available online: https://github.com/tzutalin/labelImg (accessed on 10 November 2018).
- Taylor, L.; Nitschke, G. Improving Deep Learning using Generic Data Augmentation. arXiv 2017, arXiv:1708.06020. [Google Scholar]
- Bengio, Y. Practical Recommendations for Gradient-Based Training of Deep Architectures. In Neural Networks: Tricks of the Trade; Springer: Berlin, Germany, 2012. [Google Scholar]
- Geisser, S. The Predictive Sample Reuse Method with Applications. J. Am. Stat. Assoc. 1975, 70, 320–328. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving Object Detection with One Line of Code. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5562–5570. [Google Scholar]
- Buil, M.D. NON-MAXIMA SUPRESSION; Technical Report, Computer Graphics and Vision; Graz University of Technology: Graz, Austria, August 2011. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Zhu, M. Recall, Precision and Average Precision; Technical Report; Department of Statistics and Actuarial Science, University of Waterloo: Waterloo, ON, Canada, September 2004. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- F1 Score. Wikipedia, the Free Encyclopedia. 2018. Available online: https://en.wikipedia.org/wiki/F1_score (accessed on 23 March 2019).
- Martin-Abadal, M.; Ruiz-Frau, A.; Gonzalez-Cid, Y. Video: Real-time Jellyfish Detection and Quantification. 2019. Available online: http://srv.uib.es/jellyfish-quantification/ (accessed on 17 March 2020).
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Martin-Abadal, M. Jellyfish Object Detection. 2019. Available online: https://github.com/srv/jf_object_detection (accessed on 17 March 2020).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1|c|Index | Data Aug. | Learn. Rate | Iterations |
|---|---|---|---|
| 1 | No | 5 × | 10k |
| 2 | 20k | ||
| 3 | 40k | ||
| 4 | decay | 10k | |
| 5 | 20k | ||
| 6 | 40k | ||
| 7 | Yes | 5 × | 10k |
| 8 | 20k | ||
| 9 | 40k | ||
| 10 | decay | 10k | |
| 11 | 20k | ||
| 12 | 40k |
| Exp. | D. aug. | Lr. | Iter. | AP | mAP | F1 Score | |||
|---|---|---|---|---|---|---|---|---|---|
| P. noct. | R. pulmo | C. tuber. | |||||||
| 1 | No | 0.0005 | 10k | 85.3% | 98.2% | 97.2% | 93.6% | 85% | 93.7% |
| 2 | 20k | 86.3% | 97.7% | 97.3% | 93.8% | 85% | 94.0% | ||
| 3 | 40k | 86.1% | 97.6% | 97.1% | 93.6% | 93% | 94.1% | ||
| 4 | decay | 10k | 86.5% | 98.1% | 97.5% | 94.0% | 82% | 94.1% | |
| 5 | 20k | 86.3% | 98.4% | 97.3% | 94.0% | 95% | 94.2% | ||
| 6 | 40k | 85.8% | 98.9% | 96.6% | 93.8% | 91% | 94.2% | ||
| 7 | Yes | 0.0005 | 10k | 84.4% | 97.5% | 96.7% | 92.9% | 79% | 93.6% |
| 8 | 20k | 86.5% | 98.8% | 96.7% | 94.0% | 91% | 94.5% | ||
| 9 | 40k | 86.8% | 99.0% | 96.5% | 94.1% | 89% | 94.8% | ||
| 10 | decay | 10k | 87.1% | 98.5% | 96.9% | 94.1% | 69% | 94.6% | |
| 11 | 20k | 87.6% | 99.0% | 97.5% | 94.7% | 86% | 95.0% | ||
| 12 | 40k | 88.2% | 99.0% | 97.7% | 95.0% | 90% | 95.2% | ||
| Similarity | ||||
|---|---|---|---|---|
| 4 | 25% | 1.87 | 11% | 87.7% |
| 50% | 1.25 | 12% | 87.9% | |
| 75% | 0.62 | 20% | 87.5% | |
| 8 | 25% | 3.75 | 36% | 90.5% |
| 50% | 2.50 | 36% | 92.2% | |
| 75% | 1.25 | 36% | 90.5% | |
| 12 | 25% | 5.62 | 20% | 93.8% |
| 50% | 3.75 | 27% | 92.7% | |
| 75% | 1.87 | 27% | 92.1% |
| Architecture | mAP | F1 Score |
|---|---|---|
| Inception V2 | 76.5% | 80.2% |
| ResNet | 93.9% | 94.2% |
| Incep.-ResNet V2 | 95.2% | 95.2% |
| Inception-V2 fps achieved: 25.2 | ResNet101 fps achieved: 10.0 | Inception-ResNet V2 fps achieved: 1.6 | ||||||||
| Similarity | Similarity | Similarity | ||||||||
| 63 | 25% | 70.3% | 25 | 25% | 90.0% | 4 | 25% | 87.7% | ||
| 50% | 70.7% | 50% | 89.3% | 50% | 87.9% | |||||
| 75% | 72.1% | 75% | 89.0% | 75% | 87.5% | |||||
| 126 | 25% | 70.0% | 50 | 25% | 87.8% | 8 | 25% | 90.5 | ||
| 50% | 72.0% | 50% | 87.5% | 50% | 92.2% | |||||
| 75% | 71.3% | 75% | 86.7% | 75% | 90.5% | |||||
| 189 | 25% | 69.9% | 75 | 25% | 87.8% | 12 | 25% | 93.8% | ||
| 50% | 73.3% | 50% | 86.3% | 50% | 92.7% | |||||
| 75% | 70.9% | 75% | 84.8% | 75% | 92.1% | |||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martin-Abadal, M.; Ruiz-Frau, A.; Hinz, H.; Gonzalez-Cid, Y. Jellytoring: Real-Time Jellyfish Monitoring Based on Deep Learning Object Detection. Sensors 2020, 20, 1708. https://doi.org/10.3390/s20061708
Martin-Abadal M, Ruiz-Frau A, Hinz H, Gonzalez-Cid Y. Jellytoring: Real-Time Jellyfish Monitoring Based on Deep Learning Object Detection. Sensors. 2020; 20(6):1708. https://doi.org/10.3390/s20061708
Chicago/Turabian StyleMartin-Abadal, Miguel, Ana Ruiz-Frau, Hilmar Hinz, and Yolanda Gonzalez-Cid. 2020. "Jellytoring: Real-Time Jellyfish Monitoring Based on Deep Learning Object Detection" Sensors 20, no. 6: 1708. https://doi.org/10.3390/s20061708
APA StyleMartin-Abadal, M., Ruiz-Frau, A., Hinz, H., & Gonzalez-Cid, Y. (2020). Jellytoring: Real-Time Jellyfish Monitoring Based on Deep Learning Object Detection. Sensors, 20(6), 1708. https://doi.org/10.3390/s20061708