1. Introduction
The rapid growth of devices and widespread internet connectivity and automation has generated data drastically like never before. In addition to textual data, video streaming contents are the main contributor in data generation, which demands a larger space and bandwidths to store and stream. The web pages with video content are more engaging and seem informative than that of only showing the text. Video processing, monitoring, summarizing, and broadcasting are snowballing with the introduction of live broadcast apps and the provision of live streaming on existing major video hosting websites. Therefore, the video processing is gaining the attention of the computer vision and deep-learning researchers. Video content searching, video description, and video summarization are the hot topics of the times. They are high-level tasks in the field of video processing. On the other hand, shot classification, scene classification, shot-boundary detection, and action recognition are the building blocks for those high-level tasks.
Sports videos are the most engaging and contributive content and have enormous commercial aspects. Sports video scenes are usually repetitive; because every sport has its predefined camera positions, zooming protocols, and action replay strategies. Sports videos are usually long in duration; therefore, it is not always possible for the offline audience to watch full contents of the recorded video for a specific event. Due to the longer duration of the recorded video and busier life of the audience, researchers are actively working on automatic video summarization, and scene classification is the core component for the sports video summarization. Since sports videos have known rules for video capturing and have a particular scene protocol, a sport-specific scene classifier can produce better results in comparison to generalized scene classifier. Sports video covers all the events, including exciting as well as boring events, and some of the events are less exciting, i.e., breaks, tedious parts of the game, and other activities where a viewer loses interest. It produces the opportunity to publish the videos consisting of only the best parts of the game. Therefore, accurate and high quality of scene classification can help to produce a high-quality video summary.
The objective of our proposed method is to present a high-performance method to achieve high-quality summarization. The lower error rate in classification ensures the high reliability of the classification and hence high reliability of the dependent processes that consume scene classification building block. We achieve this objective by introducing a three-step upgrade to the state-of-the-art method proposed by [
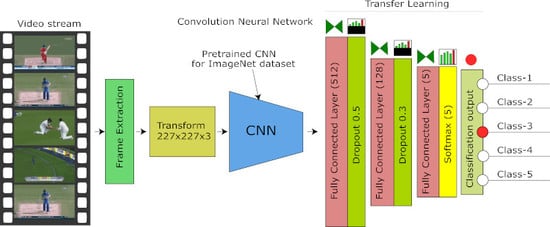
1], i.e., proposed a particular transfer learning architecture, introducing the pre-trained weights for training the model and applying data augmentation for training data. The architecture of the proposed model for scene classification is shown in
Figure 1. Our proposed model focuses on cricket as a case study, and we carry out our experiments on recorded videos taken from publicly available YouTube source.
The sports audience is more interested in meaningful content, and analyzing and summarizing the video content is a substantial labor task. Computers are helping humans more promising than ever before, and particularly with the evolution of machine learning and other methods of artificial intelligence (AI) in almost every domain of the life sciences. Therefore, researchers are proposing novel techniques almost all the time. Since scene classification if a fundamental building block, it requires significant attention to improve the performance over the existing research state-of-the-art level. Previously, several researchers proposed generalized schemes for shot classification, shot-boundary detection, and scene classification; however, generalized proposals are less helpful for a specific domain. Proposing a specialized technique has its significance and achieves superiority over the existing generalized proposals.
Many researchers proposed excellent methods recently with significant improvements. Minhas et al. [
1] proposed a method based on deep learning techniques and presented a bunch of improvements. However, a quality gap is still present, and a requirement exists to fulfill this gap in addition to practical implementation limitations. Due to the non-availability of labeled sports datasets in this domain and context, improvement is necessary to produce high-quality classification on a smaller dataset in practically less time.
In this paper, we propose a model for sports video scene classification with the particular intention of sports video summarization. The proposed method contributes a combination of three techniques over the existing state-of-the-art technique [
1]: the proposed architecture for the classification model, incorporating the pre-trained weights and training data augmentation. In the proposed architecture, we present a set of new layers for the transfer learning of AlexNet CNN. The proposed architecture is designed to support five critical scene classes required in the sport of cricket. We introduced additional fully connected layers with dropout and activation functions. We prepare the cricket sports dataset from YouTube cricket sports recorded videos from the past events. We label the five most frequent and essential scenes from the videos, i.e., batting, bowling, boundary, close-up, and the crowd, to evaluate it to be the best fit for video summarization of cricket sport.
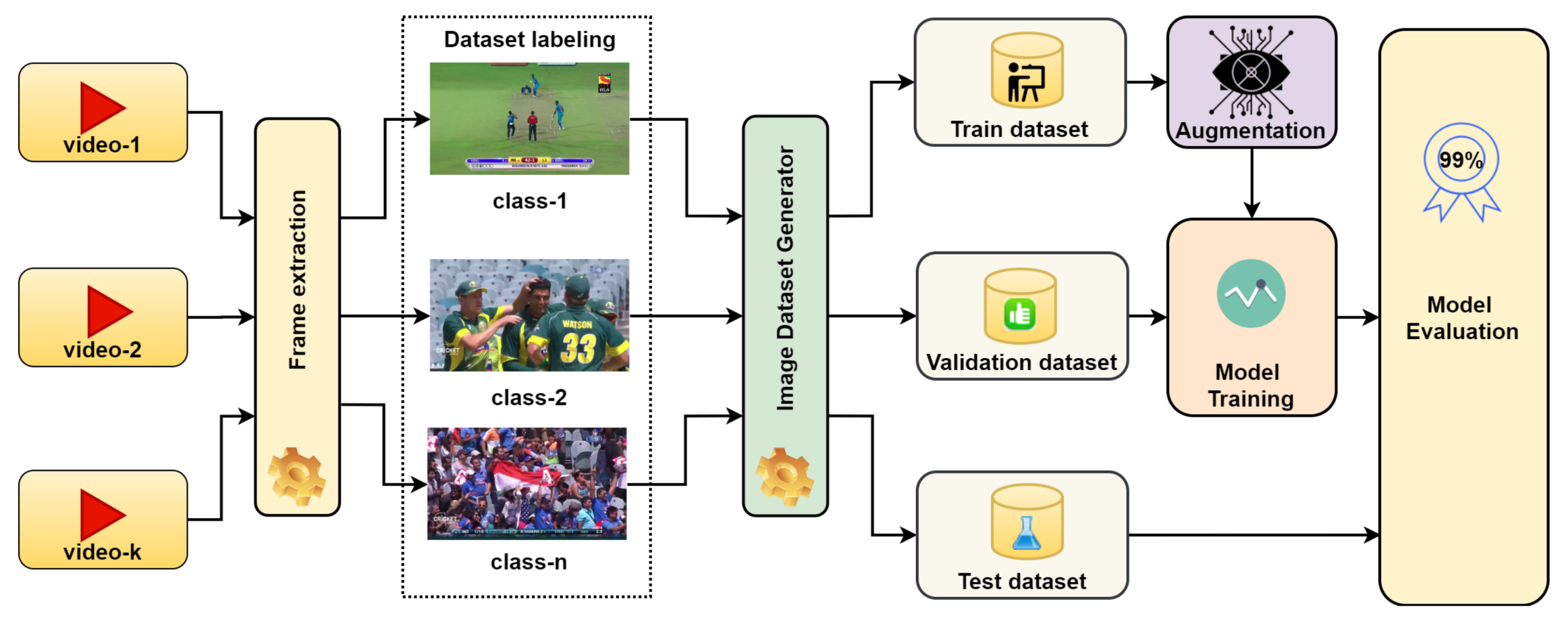
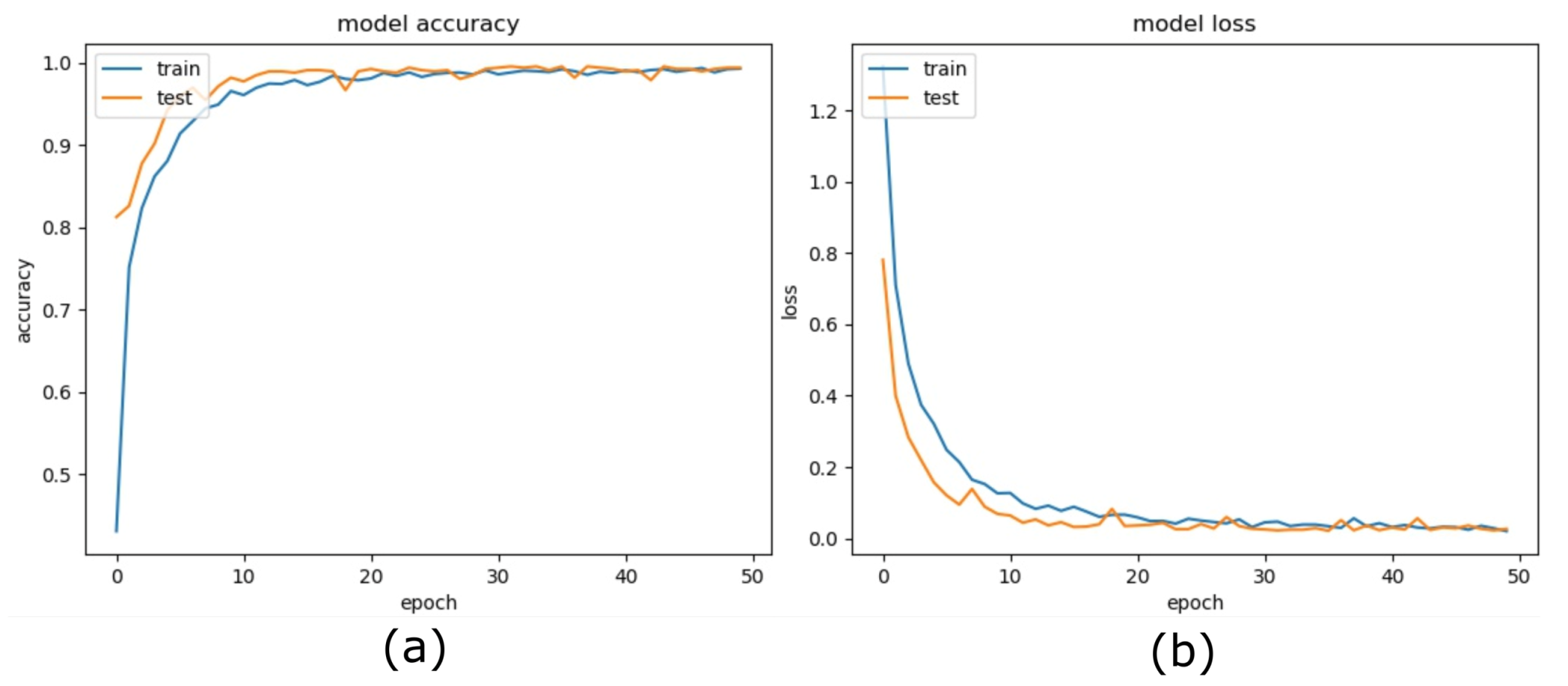
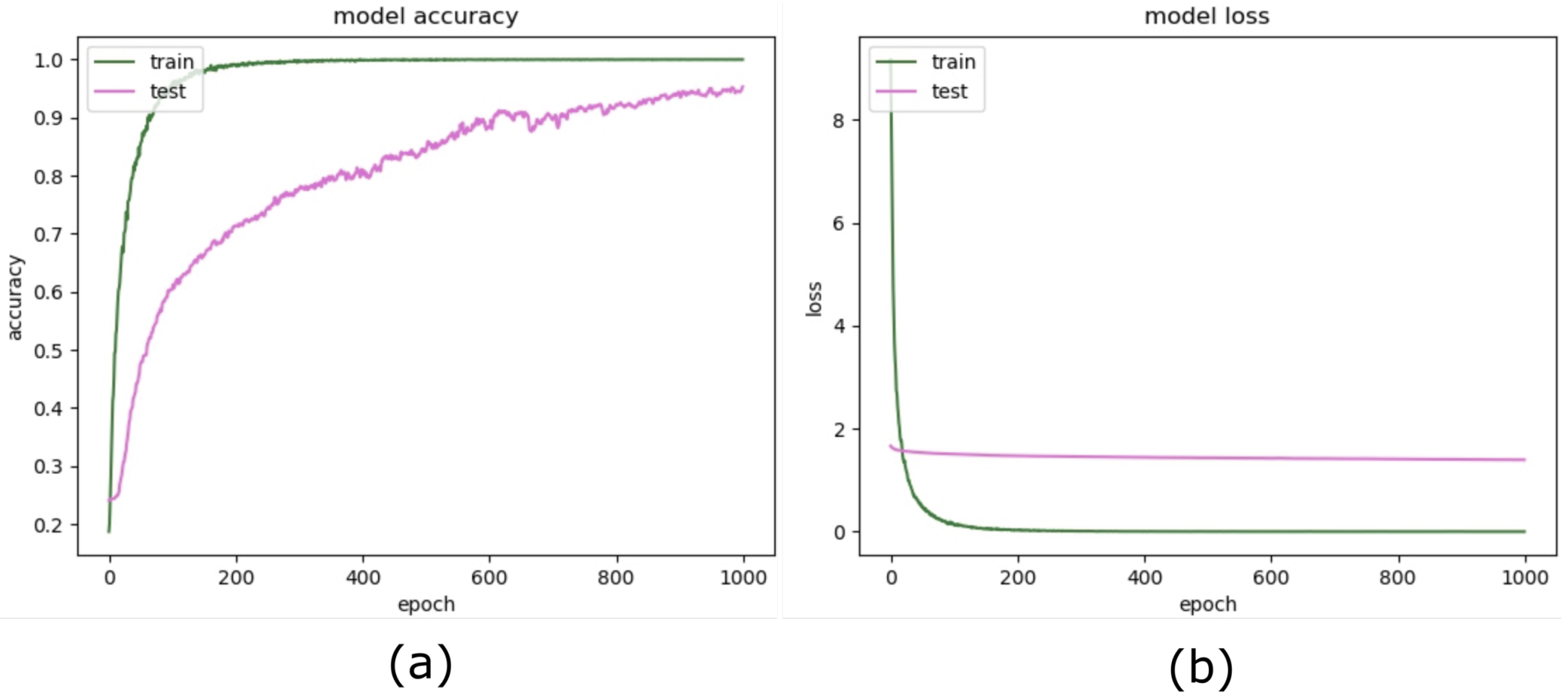
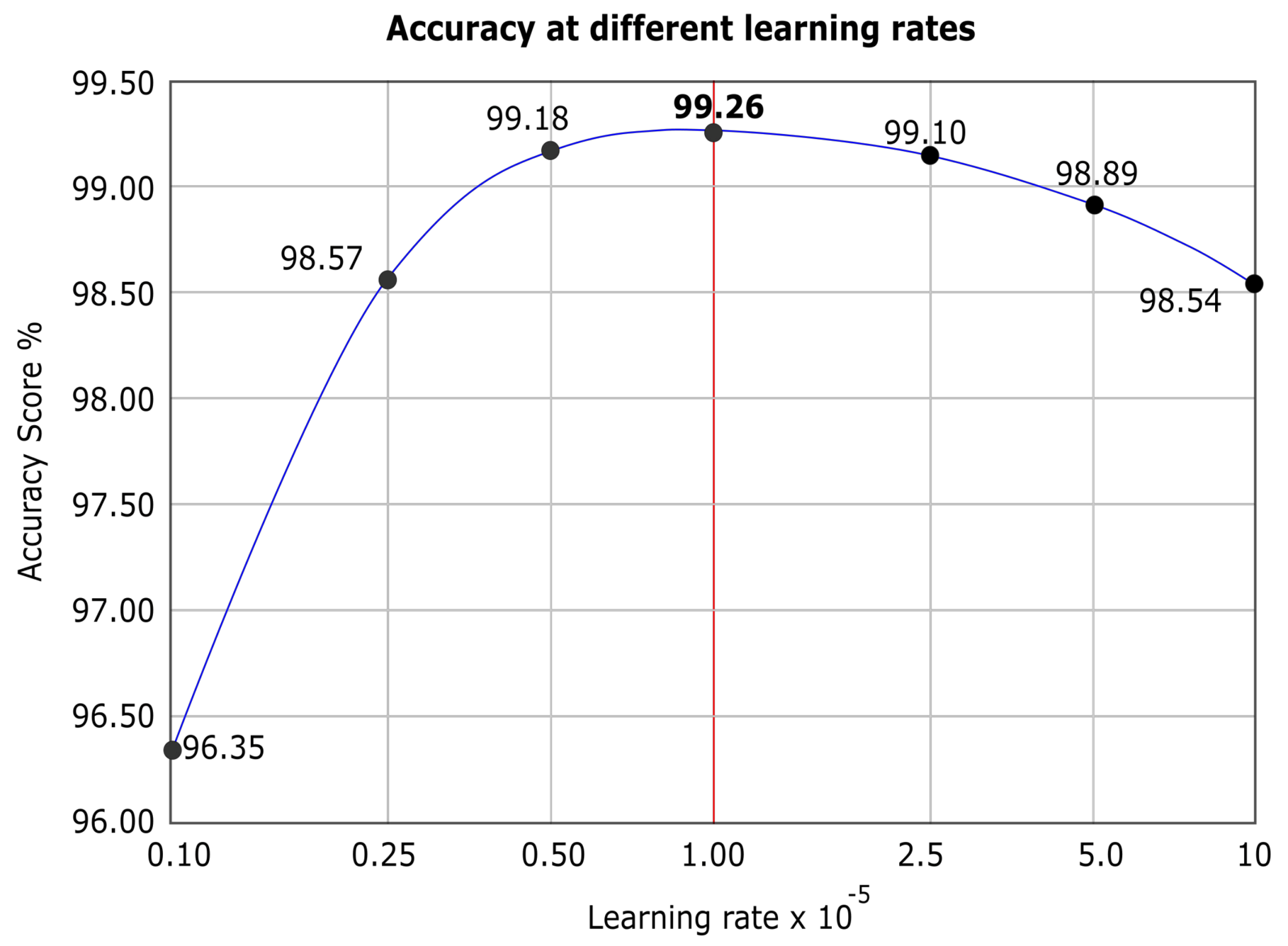
Figure 2 shows the training procedure. We load the model with pre-trained weights on ImageNet challenge with 1000 classes and then confined the feature map to our five classes by using the additional proposed layers. We split the training image data into the thee subsets for training, validation, and test. We augment the training data using geometric transformations. We employ the in-place data augmentation technique and introduce a large image repository using batches of 32 images at a time. In-place transformations do not increase the size of the training data; hence control over training time is achieved, whereas increasing training dataset size potentially increases the training time for the model. We iterate several learning rates to find the best learning rate to achieve peak accuracy. We perform our experiments using the best learning for the latest deep-learning models on the same dataset.
We compare the model with the existing state-of-the-art models, particularly deep-learning models, e.g., Inception V3, VGGNET16, VGGNET19, ResNet50, and from non-deep-learning models like SVM to present a performance evaluation. We also compare the model with existing models in the field of sports video summarization and scene classification. We focus on scene classification with a primary intention of video summarization using deep-learning methods, and we have selected the sport of cricket as a case study.
Our proposed methodology demonstrates a 5% better performance over the existing method proposed by [
1] and supersedes the accuracy, precision, and recall with a significant margin of 4–5% in all parameters. We achieve a mean accuracy of 99.26% with a stable precision of 99.27% and a reliable recall of 99.26%, which yields the F1-measure of 99.26% to show the high quality of the classification. Furthermore, since we incorporate pre-trained CNN in the proposed method, consequently, it reduces the training time of the model drastically. On the other hand, pre-processing of the training data by introducing augmentation, eliminates the overfitting, and helps to achieve the high quality of the model state. We introduce three fully connected layers appended to pre-trained CNN and applied the best learning rate during our extensive experiments. Our methodology shows superior performance over existing methods during our experiments.
The primary audience of the proposed method is the video summarization and video description researcher community. However, classification, in general, can also be employed in several other domains, i.e., medical image analysis [
2,
3], agriculture classification [
4], biological organism classification, self-driving vehicles [
5], video captioning and other similar domains.
The rest of the paper is organized into the following four sections,
Section 2 covers the related work in the subject domain. The proposed method is presented in
Section 3. The experimental results and discussion is detailed in the
Section 4 and finally the
Section 5 conclude the work and suggest the future aspects.
3. Proposed Method
This section provides a detailed methodology of the proposed method. The core of the proposed method is AlexNet CNN, which is pre-trained on ImageNet [
22] weights.
Figure 1 shows the architecture of the proposed model. We employed AlexNet CNN as a foundation with pre-trained weights and employed transfer learning by adding three fully connected layers and trained our model on the labeled sports dataset. The proposed method consists of five steps. In step 1 we prepared the dataset from publicly available sports videos, then in step 2, we employed AlexNet CNN and added three additional fully connected layers. First two layers appended with dropout and last layer activated with SoftMax, as shown in
Figure 1, and after the layer configuration, we compiled the model with extended layers. In step 3, we loaded pre-trained weights to the model. In step 4, we split the dataset for training, validation, and testing, and applied augmentation on training data. Finally, in step 5, we trained the model.
Figure 2 shows the block diagram of the training and evaluation procedure.
3.1. Proposed Model Architecture
In the proposed method, we employed AlexNet CNN deep-learning architecture for scene classification and evaluated using Keras application 2.0 and Tensor Flow backend in Python. Keras provides a variety of deep-learning application layers.
Table 1 enlists the complete layer configuration of the proposed model.
3.1.1. Application Layers
We employed Keras layers to construct AlexNet and extended the codebase from the ConvNet library [
23]. AlexNet CNN then loaded pre-trained weights from [
24]. The proposed layer architecture consists of Keras ConvNet AlexNet model from layers 1 to 32 and the transfer learning from layers 33 to 38. Layer 37 consists of five neurons to match our classification task. The dense layer with five output classes confines the probabilities received from the dropout-5 layer, and then output is activated with SoftMax activation. Final classification based on probabilities obtained from SoftMax activation is done to find the exact association from the output heat-map. The AlexNet CNN model requires input as a 3D tensor with a size
for color images to be introduced to the model for training and classification.
3.1.2. Convolutional Layers
Convolution is the primary process of any neural network model required for learning and classification using feature maps. In this layer, a kernel (a small matrix with specialized values to extract features) is convoluted over layer input tensor to obtain feature maps and forwarded to output tensor. We obtain an output feature map
T from the Equation (
1) and (
2).
Where
T is the output tensor with
width and
height of the feature map of the previous layer.
K denotes the kernel with size
and
and filter slides with stride
S to
and
horizontal and vertical directions with padding
P. Similarly,
r indicates the layer of operation. Output feature map tensor is obtained by applying a convolution process on the input layer
X by kernel
K such that
where
is the output feature map tensor and product of the input tensor
X and the kernel
K with
x and
y spatial indices. The convolution is represented here with standard notation by symbol ∗. Equation (3) shows the detail expression of convolution in Equation (3)
The proposed framework consists of five convolutional layers with three split convolutional layers to load balance on multiple GPUs. We have eliminated batch normalization after convolutional layers since we have not observed any accuracy improvements during our experiments. Convolutional Layers’ output was activated using Rectified Linear Unit (ReLU)
3.1.3. Transfer Learning Layers
A fully connected layer cross-connects every neuron from the input tensor to every neuron in the output tensor, with an activation function at the output layer. The fully connected layer flattens the input tensor if the input shape rank is higher than 2. Hence a fully connected layer is a dot product of the input tensor by the applied kernel.
Fully connected layers generate probabilities in a wide range; therefore, to reduce the noise level, it is essential to eliminate the weaker predictions. To perform this operation, a dropout process is carried out with a certain threshold of usually 0.5. This less densifies the neurons after removing the value of lesser probabilities. The dropout layer helps to avoid a model overfitting and significantly improves the validation accuracy. A dropout layer reduces the functional size of the process by removing unproductive neuron outputs. It is a regularization technique and filters out complex co-adaptation during the training phase.
3.1.4. Activation Function
Rectified Linear Unit (ReLU) is a tensor output activation function and makes the model training process non-linear. During the convolution process output, tensor may contain positive and negative values; therefore, before forwarding the output to the next layer, an activation function is applied. A ReLU function converts the values lower than zero to a zero value, and positive values leave unchanged. This process is called rectification. A non-saturating function
returns zero or positive values from a range of negative and positive values. The output feature map is cleaned out of negative values. It increases the non-linearity of the model without compromising the quality of classification in receptive fields during the convolution process. We can express ReLU function mathematically, as shown in Equation (
4).
Where is the input of ReLU, and is computed output from ReLU activation for a specific neuron at x and y position.
3.2. Data Augmentation
In the proposed method, data augmentation plays a significant role in improving the performance of the model. Data augmentation relates to modifying the image data and perform a series of operations, such that the modified image remains in the same class. Data augmentation helps to generalize the input data, which, as a result, reflects a better test accuracy. There are three main techniques while augmenting training data: expanding dataset, in-place or on the fly augmentation, combining dataset with in-place augmentation. In our experiments, we employed in-place data augmentation.
In-place augmentation relates to modifying the original data by applying a series of transforms and returns the transformed data only. It exceptionally means that the size of the data is not changed, and source data is not permanently modified, hence, it is not an additive process. Therefore, in repeating experiments, the training dataset is always different from the previous training since the data is transformed in-memory batch by batch with random transformations before inputting for the training of the model.
We employed Keras ImageDataGenerator to augment our training data. It provides various transforms to augment the image data such that scale, rotate, shear, brightness, zoom, channel shift, width and height shift, and horizontal and vertical shift. In the proposed method, we applied geometric transforms like rescale, rotation, width shift, height shift, and horizontal shift to augment our source data for our experiments. In our experimental setup, on each input batch, we applied the rotation angle of 30 degrees, width, and height shift each 20% and horizontal flip randomly.
The augmentation block in fig-training accepts training source data from the data generator as a batch. It applies a series of random transformations as described above on each image in the batch. The transformed image batch replaces the original image batch and is presented to input for the training generator.
3.3. Implementation Details
In the proposed model, we introduced additional fully connected layers for the fine-tuning of the model. Configuration and implementation of the complete AlexNet CNN as a foundation model helped to load pre-trained weights, and appending additional layers does not disturb the carefully trained ImageNet weights. We employed three fully connected layers, i.e., dense-4 and dense-5 layers followed by dropout of 50% and 30% respectively, and the last, i.e., dense-6 layer, followed by a SoftMax activation layer. The fully connected layers were employed in an encoder fashion, with layer shapes 512, 128, and five, respectively. Training time was observed to be quite low with respect to the time for training the network from scratch.
Table 2 shows the transfer learning layers configuration. We employed additional layers to tackle more classes with inter-class similarities and intra-class differences.
Deep learning has rapidly taken over the complex classification tasks for intelligent applications [
25]. In the image classification domain [
26], it requires enormous time to train a network up-to its optimal weights; however, transfer learning [
27] has shown promising improvements in training time and contextual classification. Transfer learning can be adapted in three ways. 1: Fixed feature extractor, in which last fully connected layer is replaced to classify frames based on trained network, 2: Fine-Tuning of the CNN relates to adjusting the weights to fit the model in the custom scenario; this is done using backpropagation, which can be applied on almost any layer of the AlexNet CNN, 3: Partial Pre-trained models are shared by the community. Checkpoints during the model training are obtained, which are shared with other researchers to save time. Transfer learning reduces the training time, in most of the cases. In the proposed scenario, all the layers of AlexNet pre-trained network remained unchanged and employed the complete model. We employed the model adapted from AlexNet, loaded the pre-trained weights, and appended new fully connected layers.
Training a model from scratch requires a large dataset to obtain reasonable accuracy, which, however, requires a significant time and processing cost, whereas using a small dataset causes the model overfitting. Introducing data augmentation strategy boosts the model validation accuracy by approximately 10% [
28], and combining data augmentation with pre-trained weights, trains a model near-perfect even if the dataset is not very large. It reduces the training time and achieves higher evaluation scores.
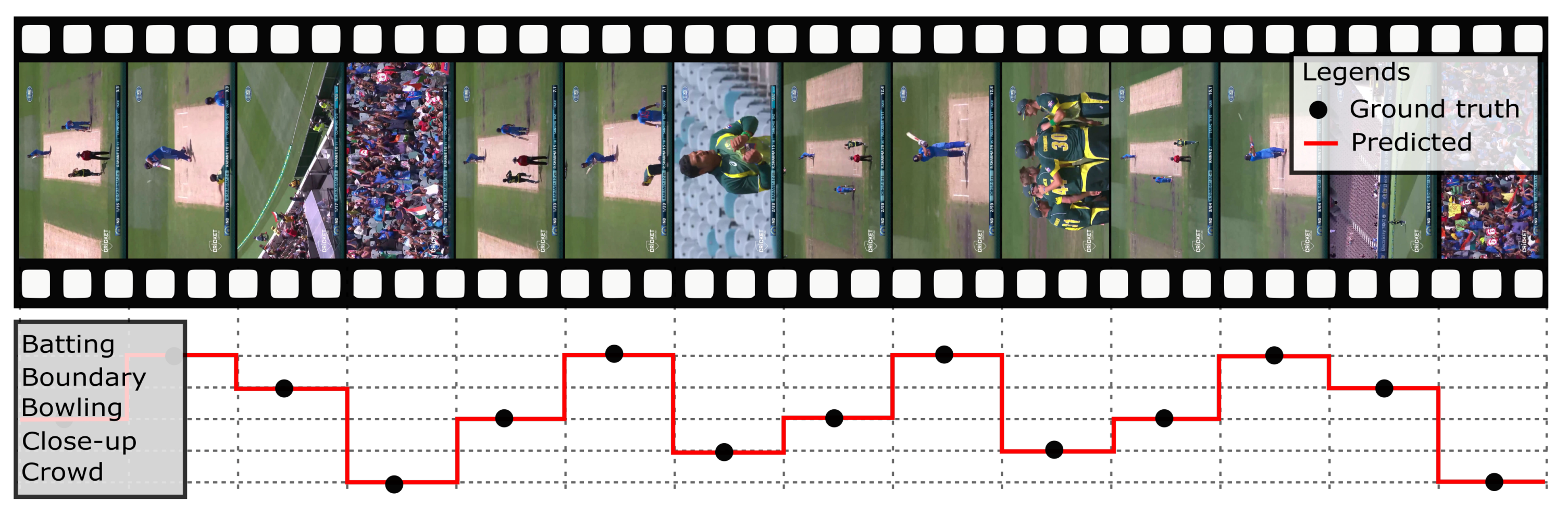
Video Source is an MPEG-4 digital video of the full-length recorded match. It contains all the features that a live stream represents. A video is a composition or group of frames, and a frame is an image with the same size as the source video display size. The frame extraction process takes one frame at a time for further processing. We extracted frames at six frames per second from the video, such that we picked every fifth frame from a video with a frame rate of 30 frames per second. A large number of frames are obtained from a video of a full event. The frames obtained from the video are high resolution and landscape. So before feeding a frame to the classification system, frames were resized to match the input shape of the model, i.e., . The pre-conditioned frames with RGB color space were fed into the input layer of the classifier model.
Pre-conditioned frames are introduced to input in the proposed CNN model, which classifies the input frame to a target class. Labeling the classes correctly for event detection is particularly important since the classification results highly depend on the model training accuracy. Scene classification is based on frame classification and is performed over a range of frames detected for a certain predefined class. A temporal similarity between consecutive frames results in the same class until there is a significant change in the scene.
5. Conclusions and Future Work
In this paper, we proposed a model for sports video scene classification with the particular intention of sports video summarization. Our findings demonstrated that our proposed model performed best against state-of-the-art models and existing recent research level. We evaluated our proposed model on cricket as a case study and obtained videos from publicly available YouTube source. We labeled the five most frequent scenes from the videos, i.e., batting, bowling, boundary, close-up, and the crowd to evaluate it to be the best fit for video summarization. We compared our proposed model with the existing state-of-the-art models, particularly deep-learning models, e.g., Inception V3, VGGNET16, VGGNET19, ResNet50, and from non-deep-learning models like SVM to present a performance evaluation. We also compared our proposed model with recently proposed models in the field of sports video summarization, and scene classification; the performance results showed a remarkable improvement.
Although the proposed methodology is evaluated over sports video data to provide a building block for video summarization; however, it can also be used for medical image analysis, agriculture classification, biological organism classification, self-driving vehicles and various other fields where classification requires respectively higher accuracy and the error rate is a critical constraint. The proposed model produced excellent performance indicators over previously proposed models, which makes it a strong candidate to be a reusable building block. Scene classification can be further extended to research on video description and medical video analysis and event description. Similarly, sports video to text summarization is a hot topic of the times and requires researchers to improve the quality of the task.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}