Toward Flexible and Efficient Home Context Sensing: Capability Evaluation and Verification of Image-Based Cognitive APIs †



Abstract
:1. Introduction
2. Related Work
3. Methodology
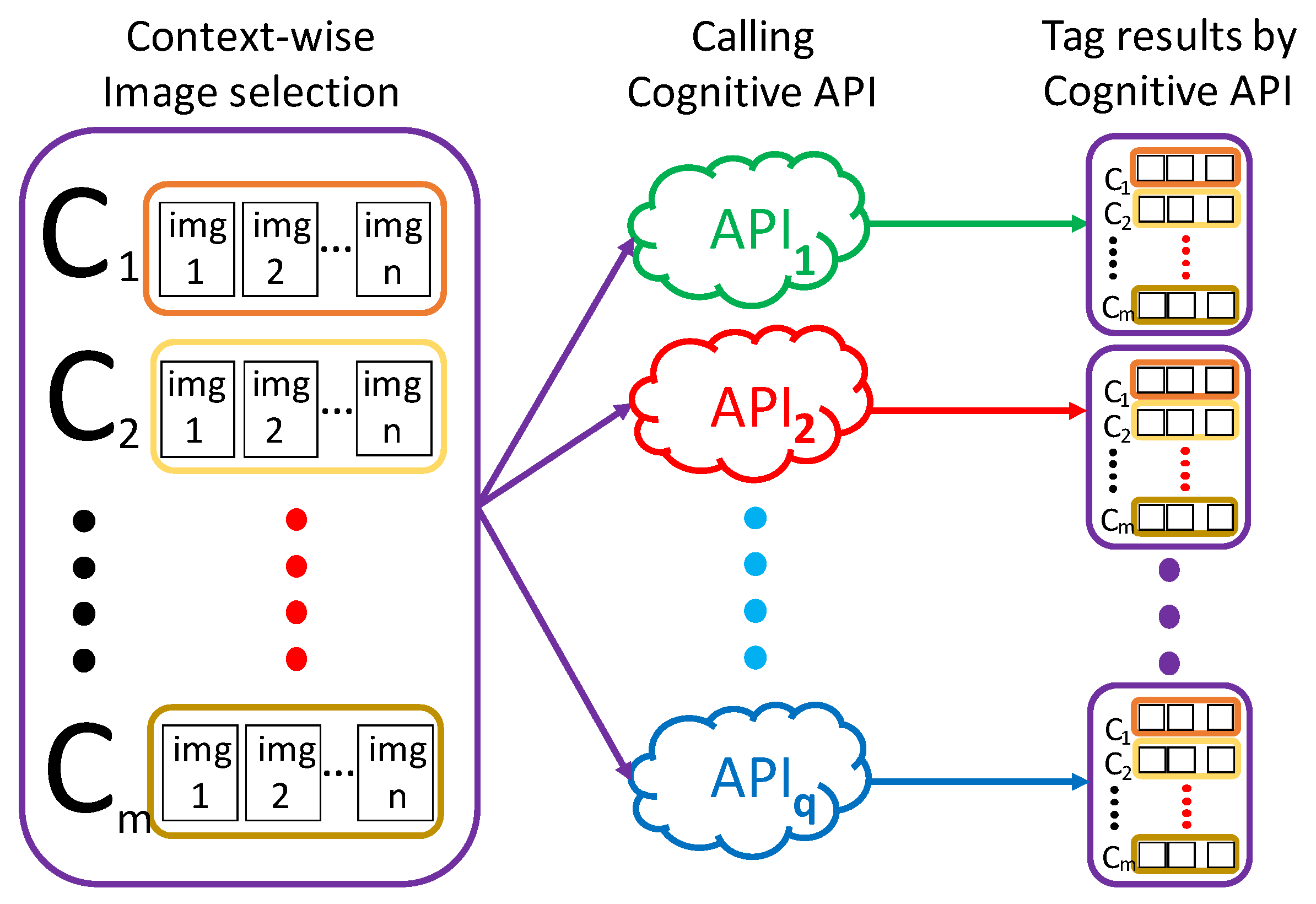
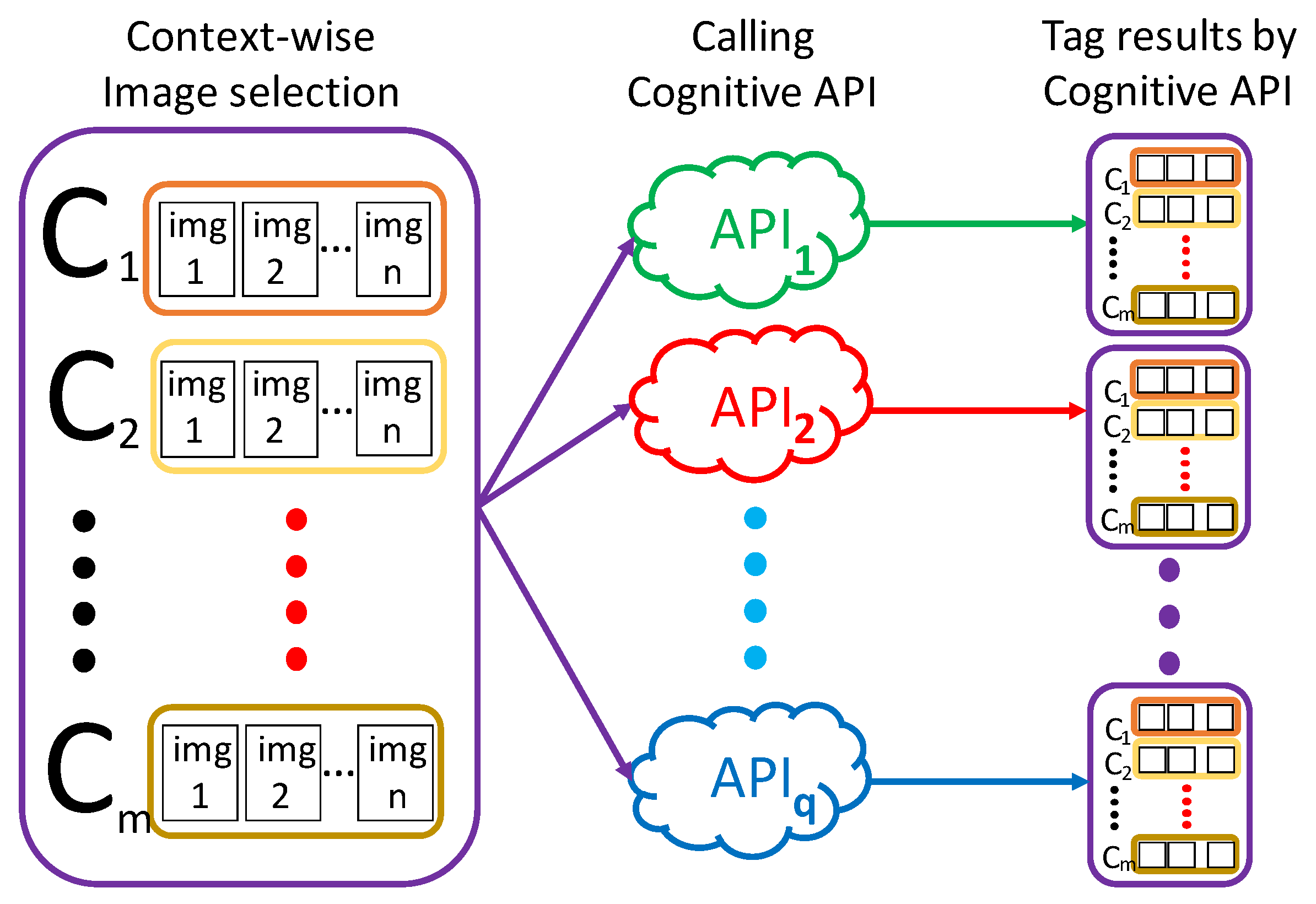
3.1. Previous Method
- Step 1:
- Acquiring images
- Step 2:
- Defining home contexts to recognize
- Step 3:
- Selecting representative images
- Step 4:
- Calling cognitive API
- Step 5:
- Analyzing output tagsStep 5-1: Encoding output tagsThe vector is a numerical representation of the document, where each component of the vector refers to a tag. It shows the presence or importance of that tag in the document. More specifically, regarding every set of output tags as a document corpus, the user can extract features from each document, by converting every set into a document vector , using a document vectorizing technique, such as TF-IDF [34], Word2Vec [35], Doc2Vec [36], GloVe [37], fastText [38] and so on. Listing 1 shows an example of encoding output tags by the TF-IDF method with python.Step 5-2: Document similarity measureRegarding each document vector in of each , the method calculates the similarity or distance, which is denoted as ‘≈’, between any two of documents using a certain method of the document similarity measure. Regarding the calculation of document similarity, there exists a variety of methods in the field of natural language processing, such as Cosine Similarity [39], Euclidean Distance [40], Pearson Correlation Coefficient [41] and so on.Step 5-3: Analyzing document similarityFor each , the user evaluates the performance of of context recognition, with respect to internal cohesion and external isolation. The internal cohesion represents a capability that can produce similar output tags for images in the same context. That is, for , we evaluate ≈. On the other hand, the external isolation represents a capability that can produce dissimilar output tags for images in different contexts. That is, for , we evaluate .

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| from sklearn.feature_extraction.text import TfidfVectorizer |
| import numpy as np |
| import pandas as pd |
| for api in ["API_name"]: |
| tags = np.array(tags_labels_pd[api]) |
| contexts = np.array(tags_labels_pd["labels"]) |
| vectorizer = TfidfVectorizer(use_idf=True) |
| vecs_tfidf = vectorizer.fit_transform(tags) |
| np.set_printoptions(precision=3) |
| np.set_printoptions(threshold=np.inf) |
| tfidf_vectors = vecs_tfidf.toarray() |
| feature_names = vectorizer.get_feature_names() |
| feature_names = list(feature_names) |
| feature_names.append("labels") |
| vectors_pd = pd.DataFrame(tfidf_vectors) |
| vectors_pd = vectors_pd.round(3) |
| labels_pd = pd.DataFrame(contexts) |
| vectors_labels_pd = pd.concat([vectors_pd,labels_pd],axis=1) |
| vectors_labels_pd.columns = [feature_names] |
| vectors_labels_pd |
3.2. Proposed Method
- Step 5:
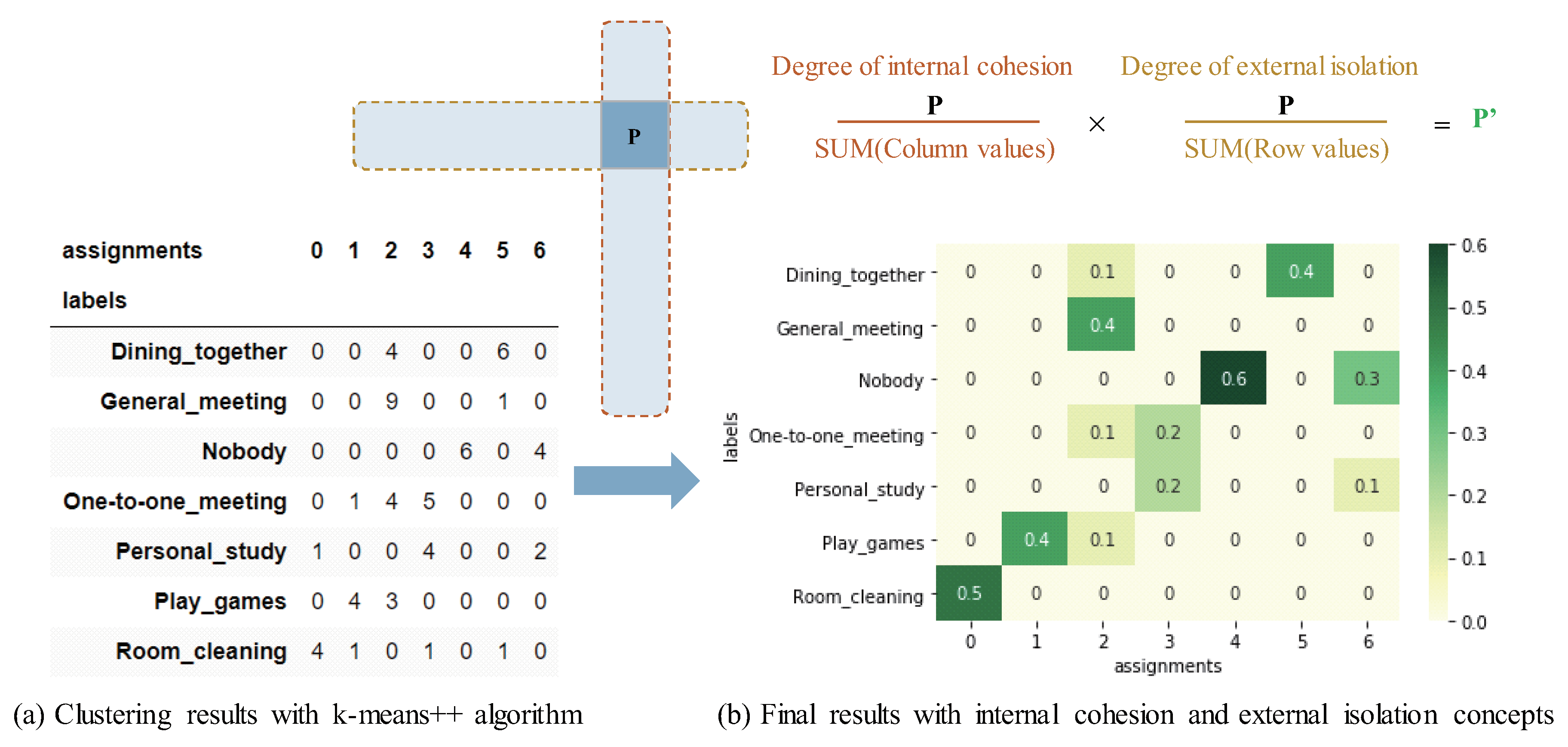
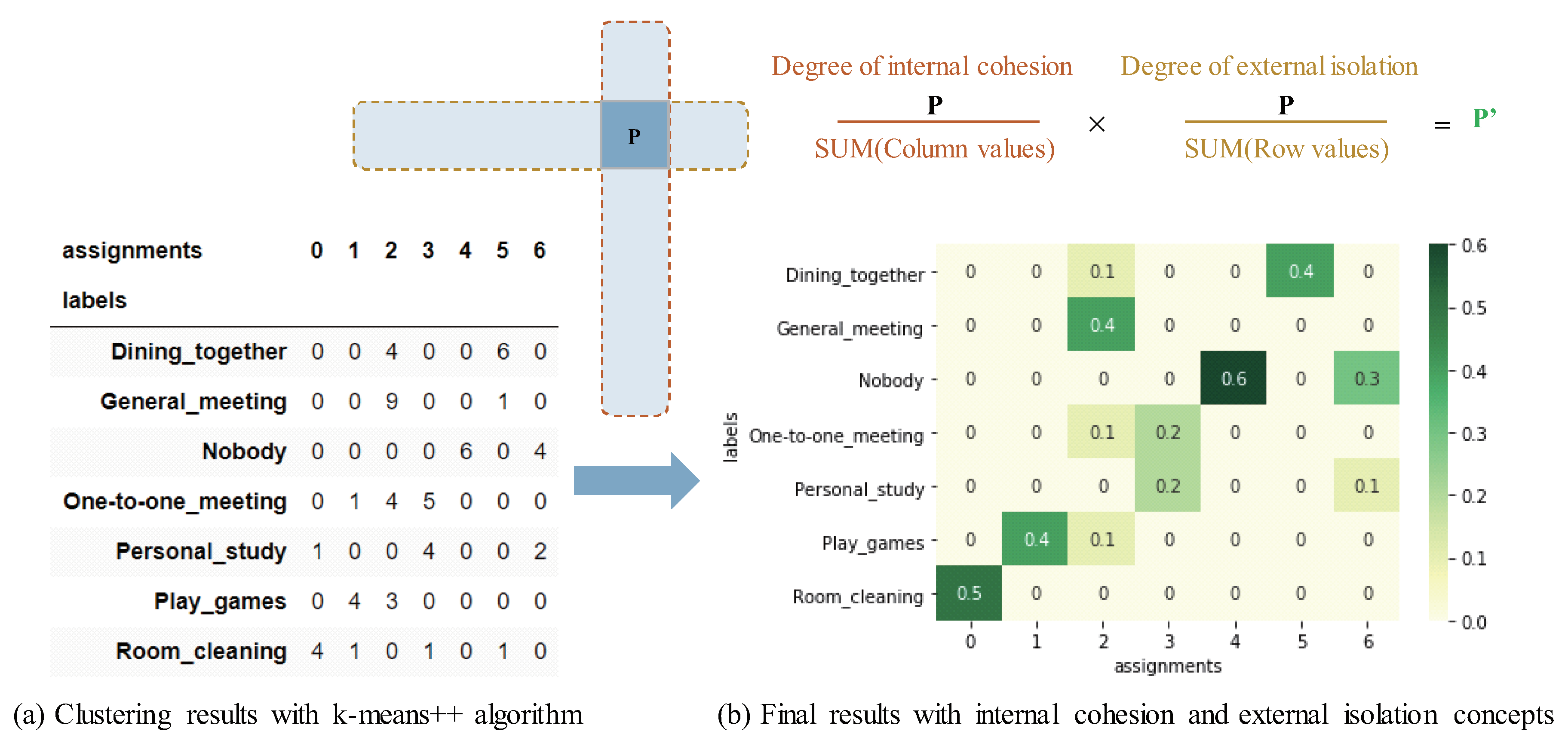
- Analyzing output tagsNew Step 5-2: Clustering document vectorsThe user first randomizes the order of all document vectors of each along with the corresponding labels, then split them into the non-labeled document vectors and the known labels. After that, the user applies a clustering algorithm W into the randomized non-labeled document vectors of each . The algorithm W include k-means [27], Partitioning Around Medoids (PAM) [42], Clustering Large Applications (CLARA) [43] and so on. This step is a process of automatic classification, which requires the user to define the number of clusters to classify in advance. By using the clustering algorithm, it returns the integer labels corresponding to the different clusters in the results. Listing 2 shows an example of applying k-means++ algorithm into document vectors with python. Further more, an example of the clustering results in cross-tab is shown in Figure 2a, which produced by integrating the known labels and the returned integer labels. The evaluation key is the number of all labels more concentrated in the different classes of both rows and columns, the better the classification effect. Since the naive clustering algorithm cannot show the classification effect well to a small scale of data in general, the new Step 5-3 improves it.Listing 2. Example of applying k-means++ algorithm into document vectors with python
from sklearn.metrics.pairwise import cosine_similarity from sklearn.cluster import kmeans import numpy as np import pandas as pd random_vectors_labels_pd = vectors_labels_pd.sample(frac=1) random_vectors_np = random_vectors_labels_pd.iloc[:,:-1].values random_labels_np = random_vectors_labels_pd.iloc[:,-1:].values kmeans.euclidean_distances = cosine_similarity model = kmeans(n_clusters=len(sorted(list(set(random_labels_np)))), init=’k-means++’) model_output_labels_np = model.fit_predict(non_labels_random_vectors_pd) model_output_labels_pd = pd.DataFrame(model_output_labels_np, columns=[’Assignments’]) random_labels_pd = pd.DataFrame(random_labels_np, columns=[’labels’]) labels_concat_pd = pd.concat([random_labels_pd, model_output_labels_pd], axis=1) result_crosstab_pd = pd.crosstab(labels_concat_pd[’assignments’], labels_concat_pd[’labels’]) result_crosstab_pd New Step 5-3: Analyzing clustering resultsFrom the results of automatic classification of each , the user evaluates the recognition capability of . The core of the evaluation method is to integrate the internal cohesion and external isolation concepts into the clustering results. Specifically, Listing 3 shows an example of the key method for evaluating the capability of cognitive APIs with python. Further more, an example of the process for evaluating the capability of cognitive APIs shown in Figure 2, including a calculation formula and the principles. As the evaluation description of this step, refer to the cross-tab of Figure 2b, the capability evaluation method includes two points:(1) The maximum value in each row shows the capability of for the row . Note, it cannot conduct the evaluation using this score if no maximum value in that row.(2) The more there are other values in the row or column of the maximum value of each row, the lower the capability of for of the row where the maximum value is.Here, with low scores may be regarded as difficult-to-train contexts.
| import numpy as np |
| import pandas as pd |
| import seaborn as sns |
| sum_row_values = result_crosstab_pd.sum(axis=1) |
| sum_column_values = result_crosstab_pd.sum(axis=0) |
| final_results_list = [] |
| for i in range(len(result_crosstab_pd)): |
| this_row_results = [] |
| this_row = result_crosstab_pd.iloc[i:i+1,:] |
| sum_this_row_values = float(sum_row_values[i]) |
| for j in range(len(result_crosstab_pd)): |
| this_value = this_row.iloc[:,j:j+1] |
| this_value = float(this_value.values) |
| sum_this_column_values = float(sum_column_values[j]) |
| if this_value != 0: |
| this_value = ((this_value/sum_this_row_values) |
| *(this_value/sum_this_column_values)) |
| else:pass |
| this_row_results.append(round(this_value,1)) |
| final_results_list.append(this_row_results) |
| final_results_pd = pd.DataFrame(final_results_list, |
| index=result_crosstab_pd.index, |
| columns=result_crosstab_pd.columns) |
| sns.load_dataset(’iris’) |
| plt.figure() |
| sns.heatmap(final_results_pd,cmap="YlGn", annot=True, cbar=True) |
- Step 6:
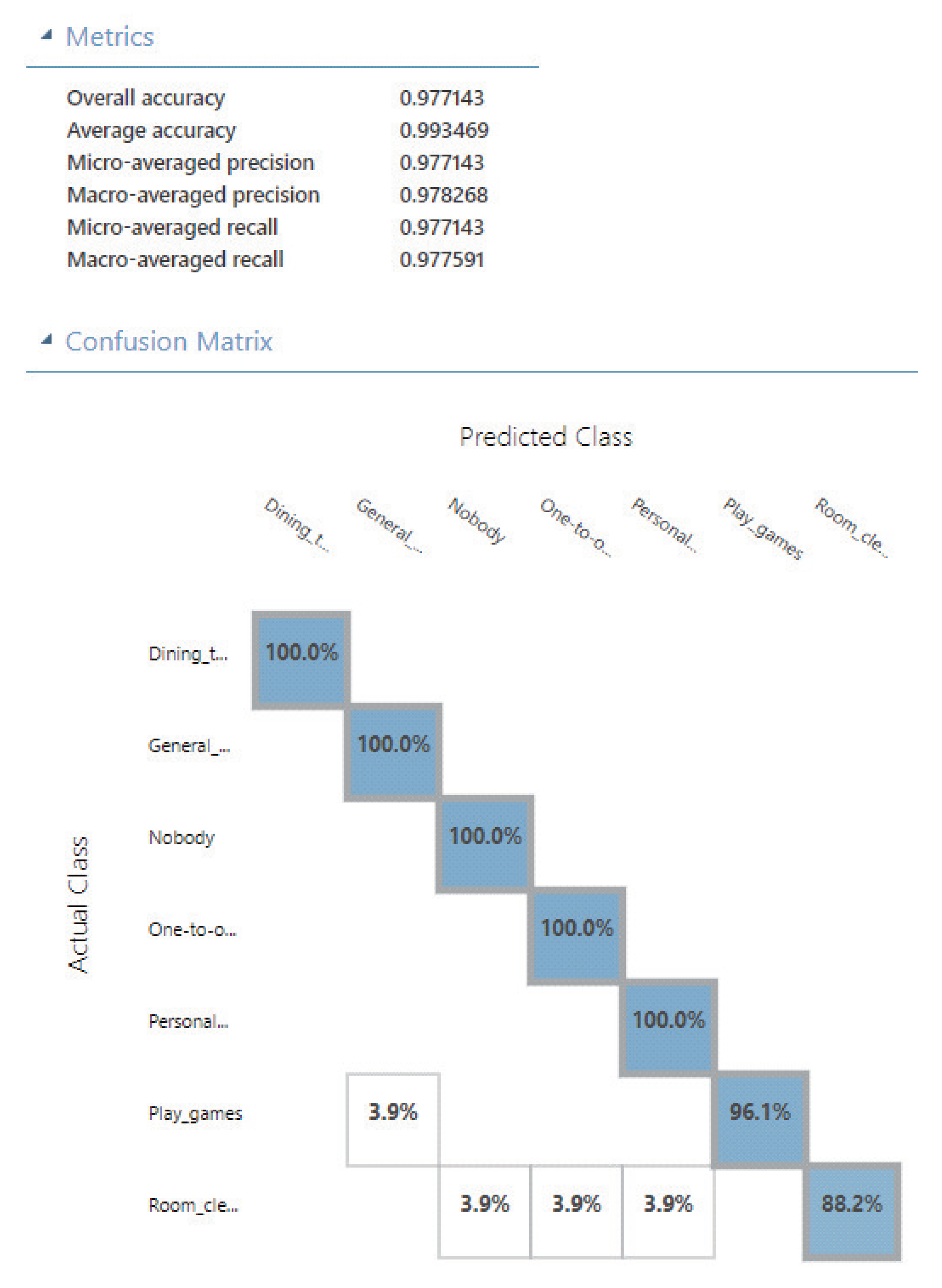
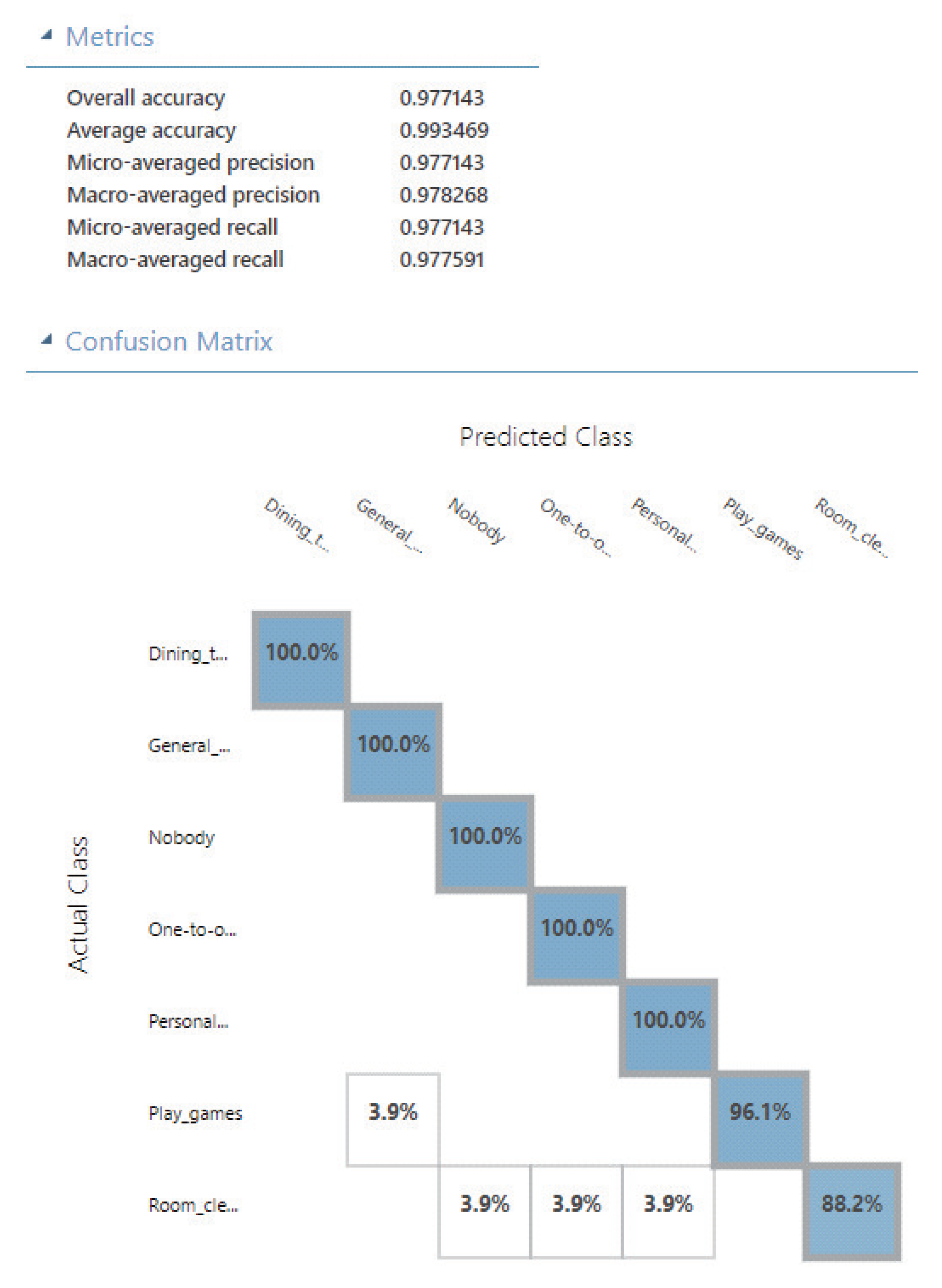
- Selectively building ModelIn this Step, based on the evaluation results in Step 5, the user can select high-capability APIs, for improving the difficult-to-train contexts in the built model, and produce an efficient process.Step 6-1: Preparing labeled image dataFollow Step 1 to Step 3 in Section 3.1, the user collects and labels a moderate scale of image data required for building a model with machine learning (Generally, ). The user also selects the original image data with more prominent features for the previously known difficult-to-training contexts (), which may bring a buffer value to the accuracy of other contexts.Step 6-2: Selecting high-capability APIs to callAs a addition in Step 4 in Section 3.1, the user first determine the difficult-to-train contexts , and to select multiple high capability () from evaluation results of the new Step 5-3. The selection approach as follows.(1) The user can select that with maximum total scores of contexts, to ensure the built model with high overall accuracy.(2) The user can also select with high complementarity of context evaluation results, to ensure the built model with high average accuracy.The approach (2) for home context sensing in most cases better than the (1), because of too much or too little will have an effect on the accuracy, efficiency, and complexity. Therefore, to select the small number of high-capability APIs rather than reduce the dimension of features can produce more applicable features related to , for improving the process efficiency.Then, for every , , and , is invoked, and a set of output tags is obtained. represents a recognition result for for an image belonging to a context . The size of varies for and . Since there are m contexts, images for each context, and g APIs, this step creates totally sets of output tags.Step 6-3: Encoding and combining featuresFollow Step 5-1 in Section 3.1, regarding every set of output tags as a document corpus, the user can first extract features from each document, by converting every set into a document vector (see Listing 1). Then, for each , the user combines all into .Certainly, the another approach is to combine all into in first, then converting them to document vectors. However, in this way, it could have influenced encoding results if there are the same tags output by . We do not think that it means the features are highlighted in the related .Step 6-4: Building a model and Verifying resultsFor each context , the user split into training data and test data. The user first applies a supervised machine learning algorithm A into the training data and corresponding labels for building a model M. The algorithm A include Support Vector Machine (SVM) [44], Neural Network (NN) [45], Decision Tree [46] and so on. Then, using the test data, the user evaluates the built model M, by checking the output with the labeled test(). The more M outputs the correct contexts, the M is more accurate.As the verification approach, the user can verify if the capability of the selected APIs the same as expected, by checking the accuracy of overall, average, context-wise and so on. The user can also check if the difficult-to-training contexts evaluated from the new Step 5-3 indeed difficult to recognize, and if the accuracy of them is improved.
4. Experimental Evaluation and Verification
4.1. Experimental Setup
4.2. Evaluating Capability of Cognitive APIs
4.3. Building a Model to Verify
4.4. Results
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mai, T.; Morihiko, T.; Keiichi, Y. A Monitoring Support System for Elderly Person Living Alone through Activity Sensing in Living Space and Its Evaluation. IPSJ SIG Notes 2014, 2014, 1–7. [Google Scholar]
- Tamamizu, K.; Sakakibara, S.; Saiki, S.; Nakamura, M.; Yasuda, K. Capturing Activities of Daily Living for Elderly at Home based on Environment Change and Speech Dialog. IEICE Tech. Rep. 2017, 116, 7–12. [Google Scholar]
- Alam, M.A.U. Context-aware multi-inhabitant functional and physiological health assessment in smart home environment. In Proceedings of the 2017 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kona, HI, USA, 13–17 March 2017; pp. 99–100. [Google Scholar]
- Gochoo, M.; Tan, T.H.; Liu, S.H.; Jean, F.R.; Alnajjar, F.S.; Huang, S.C. Unobtrusive activity recognition of elderly people living alone using anonymous binary sensors and DCNN. IEEE J. Biomed. Health Inform. 2018, 23, 693–702. [Google Scholar] [CrossRef] [PubMed]
- Ni, Q.; Garcia Hernando, A.B.; la Cruz, D.; Pau, I. The elderly’s independent living in smart homes: A characterization of activities and sensing infrastructure survey to facilitate services development. Sensors 2015, 15, 11312–11362. [Google Scholar] [CrossRef] [PubMed]
- Sharmila; Kumar, D.; Kumar, P.; Ashok, A. Introduction to Multimedia Big Data Computing for IoT. In Multimedia Big Data Computing for IoT Applications: Concepts, Paradigms and Solutions; Tanwar, S., Tyagi, S., Kumar, N., Eds.; Springer Singapore: Singapore, 2020; pp. 3–36. [Google Scholar] [CrossRef]
- Singh, A.; Mahapatra, S. Network-Based Applications of Multimedia Big Data Computing in IoT Environment. In Multimedia Big Data Computing for IoT Applications; Springer: Berlin/Heidelberg, Germany, 2020; pp. 435–452. [Google Scholar]
- Talal, M.; Zaidan, A.; Zaidan, B.; Albahri, A.; Alamoodi, A.; Albahri, O.; Alsalem, M.; Lim, C.; Tan, K.L.; Shir, W.; et al. Smart home-based IoT for real-time and secure remote health monitoring of triage and priority system using body sensors: Multi-driven systematic review. J. Med. Syst. 2019, 43, 42. [Google Scholar] [CrossRef] [PubMed]
- Microsoft Azure. Object detection - Computer Vision—Azure Cognitive Services | Microsoft Docs. Available online: https://docs.microsoft.com/en-us/azure/cognitive-services/computer-vision/concept-object-detection (accessed on 9 January 2020).
- IBM Cloud. Speech to Text - IBM Cloud API Docs. Available online: https://cloud.ibm.com/apidocs/speech-to-text/speech-to-text (accessed on 9 January 2020).
- Google Cloud. Cloud Natural Language API documentation. Available online: https://cloud.google.com/natural-language/docs/ (accessed on 9 January 2020).
- Triemvitaya, N.; Butsri, S.; Temtanapat, Y.; Suksudaj, S. Sound Tooth: Mobile Oral Health Exam Recording Using Individual Voice Recognition. In Proceedings of the 2019 4th International Conference on Information Technology (InCIT), Bangkok, Thailand, 24–25 October 2019; pp. 243–248. [Google Scholar]
- Alexakis, G.; Panagiotakis, S.; Fragkakis, A.; Markakis, E.; Vassilakis, K. Control of Smart Home Operations Using Natural Language Processing, Voice Recognition and IoT Technologies in a Multi-Tier Architecture. Designs 2019, 3, 32. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.T.; Chen, R.C.; Chung, W.H. Combining Voice and Image Recognition for Smart Home Security System. In International Conference on Frontier Computing; Springer: Berlin/Heidelberg, Germany, 2018; pp. 212–221. [Google Scholar]
- Microsoft. Computer Vision | Microsoft Azure. Available online: https://azure.microsoft.com/en-us/services/cognitive-services/face/ (accessed on 26 December 2019).
- IBM. Watson Visual Recognition. Available online: https://www.ibm.com/watson/services/visual-recognition/ (accessed on 23 July 2018).
- Chen, S.; Saiki, S.; Nakamura, M. Integrating Multiple Models Using Image-as-Documents Approach for Recognizing Fine-Grained Home Contexts. Sensors 2020, 20, 666. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, S.; Saiki, S.; Nakamura, M. Towards Affordable and Practical Home Context Recognition: - Framework and Implementation with Image-based Cognitive API-. Int. J. Netw. Distrib. Comput. (IJNDC) 2019, 8, 16–24. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Saiki, S.; Nakamura, M. Evaluating Feasibility of Image-Based Cognitive APIs for Home Context Sensing. In Proceedings of the International Conference on Signal Processing and Information Security (ICSPIS 2018), Dubai, UAE, 7–8 November 2018; pp. 5–8. [Google Scholar]
- Kamishima, T. Clustering. Available online: http://www.kamishima.net/archive/clustering.pdf (accessed on 23 July 2018).
- Muflikhah, L.; Baharudin, B. Document clustering using concept space and cosine similarity measurement. In Proceedings of the 2009 International Conference on Computer Technology and Development, Kota Kinabalu, Malaysia, 13–15 November 2009; Volume 1, pp. 58–62. [Google Scholar]
- Lee, L.H.; Wan, C.H.; Rajkumar, R.; Isa, D. An enhanced Support Vector Machine classification framework by using Euclidean distance function for text document categorization. Appl. Intell. 2012, 37, 80–99. [Google Scholar] [CrossRef]
- Cormack, R.M. A review of classification. J. R. Stat. Soc. Ser. A Gen. 1971, 134, 321–353. [Google Scholar] [CrossRef]
- Milligan, G.W. An examination of the effect of six types of error perturbation on fifteen clustering algorithms. Psychometrika 1980, 45, 325–342. [Google Scholar] [CrossRef]
- Milligan, G.W. A Monte Carlo study of thirty internal criterion measures for cluster analysis. Psychometrika 1981, 46, 187–199. [Google Scholar] [CrossRef]
- Milligan, G.W. An algorithm for generating artificial test clusters. Psychometrika 1985, 50, 123–127. [Google Scholar] [CrossRef]
- Wagstaff, K.; Cardie, C.; Rogers, S.; Schrödl, S. Constrained k-means clustering with background knowledge. In Proceedings of the Eighteenth International Conference on Machine Learning (ICML 2001), Williamstown, MA, USA, 28 June–1 July 2001; Volume 1, pp. 577–584. [Google Scholar]
- Cheng, Y. Mean shift, mode seeking, and clustering. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 790–799. [Google Scholar] [CrossRef] [Green Version]
- Tax, N.; Sidorova, N.; Haakma, R.; van der Aalst, W.M. Mining local process models with constraints efficiently: Applications to the analysis of smart home data. In Proceedings of the 2018 14th International Conference on Intelligent Environments (IE), Rome, Italy, 25–28 June 2018; pp. 56–63. [Google Scholar]
- Hu, S.; Tang, C.; Liu, F.; Wang, X. A distributed and efficient system architecture for smart home. Int. J. Sens. Netw. 2016, 20, 119–130. [Google Scholar] [CrossRef]
- Xu, K.; Wang, X.; Wei, W.; Song, H.; Mao, B. Toward software defined smart home. IEEE Commun. Mag. 2016, 54, 116–122. [Google Scholar] [CrossRef]
- Copos, B.; Levitt, K.; Bishop, M.; Rowe, J. Is anybody home? Inferring activity from smart home network traffic. In Proceedings of the 2016 IEEE Security and Privacy Workshops (SPW), San Jose, CA, USA, 22–26 May 2016; pp. 245–251. [Google Scholar]
- Stojkoska, B.R.; Trivodaliev, K. Enabling internet of things for smart homes through fog computing. In Proceedings of the 2017 25th Telecommunication Forum (TELFOR), Belgrade, Serbia, 21–22 November 2017; pp. 1–4. [Google Scholar]
- Roelleke, T.; Wang, J. TF-IDF Uncovered: A Study of Theories and Probabilities. In Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval; ACM: New York, NY, USA, 2008; SIGIR ’08; pp. 435–442. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the Workshop at International Conference on Learning Representations (ICLR 2013), Scottsdale, Arizona, 2–4 May 2013. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the ICML’14—31st International Conference on International Conference on Machine Learning—Volume 32, Bejing, China, 22–24 June 2014; pp. II–1188–II–1196. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. Available online: https://nlp.stanford.edu/projects/glove/ (accessed on 15 April 2019).
- Research, F. fastText: A library for efficient learning of word representations and sentence classification. Available online: https://github.com/facebookresearch/fastText (accessed on 15 April 2019).
- Ye, J. Cosine similarity measures for intuitionistic fuzzy sets and their applications. Math. Comput. Model. 2011, 53, 91–97. [Google Scholar] [CrossRef]
- Yen, L.; Vanvyve, D.; Wouters, F.; Fouss, F.; Verleysen, M.; Saerens, M. Clustering using a random walk based distance measure. In Proceedings of the ESANN, Bruges, Belgium, 27–29 April 2005; pp. 317–324. [Google Scholar]
- Huang, A. Similarity measures for text document clustering. In Proceedings of the Sixth New Zealand Computer Science Research Sudent Conference (NZCSRSC2008), Christchurch, New Zealand, 14–18 April 2008; Volume 4, pp. 9–56. [Google Scholar]
- Van der Laan, M.; Pollard, K.; Bryan, J. A new partitioning around medoids algorithm. J. Stat. Comput. Simul. 2003, 73, 575–584. [Google Scholar] [CrossRef] [Green Version]
- Sheikholeslami, G.; Chatterjee, S.; Zhang, A. Wavecluster: A multi-resolution clustering approach for very large spatial databases. In Proceedings of the VLDB, New York, NY, USA, 24–27 August 1998; Volume 98, pp. 428–439. [Google Scholar]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef] [PubMed]
- Baum, E.B.; Wilczek, F. Supervised Learning of Probability Distributions by Neural Networks. In Neural Information Processing Systems; Anderson, D.Z., Ed.; American Institute of Physics: College Park, MD, USA, 1988; pp. 52–61. [Google Scholar]
- Geurts, P.; Irrthum, A.; Wehenkel, L. Supervised learning with decision tree-based methods in computational and systems biology. Mol. Biosyst. 2009, 5, 1593–1605. [Google Scholar] [CrossRef] [PubMed]
- Microsoft. Computer Vision | Microsoft Azure. Available online: https://azure.microsoft.com/en-us/services/cognitive-services/computer-vision/ (accessed on 27 November 2019).
- Clarifai. Enterprise AI Powered Computer Vision Solutions | Clarifai. Available online: https://clarifai.com/ (accessed on 15 April 2019).
- Imagga. Imagga API. Available online: https://docs.imagga.com/ (accessed on 15 April 2019).
- ParallelDots. Image Recognition. Available online: https://www.paralleldots.com/object-recognizer (accessed on 15 April 2019).
- Arthur, D.; Vassilvitskii, S. k-Means++: The advantages of Careful Seeding; Technical Report, Stanford; Stanford InfoLab Publication Server: Stanford, CA, USA, 2006. [Google Scholar]
- Azure Machine Learning Studio. Available online: https://azure.microsoft.com/ja-jp/services/machine-learning-studio/ (accessed on 1 February 2019).

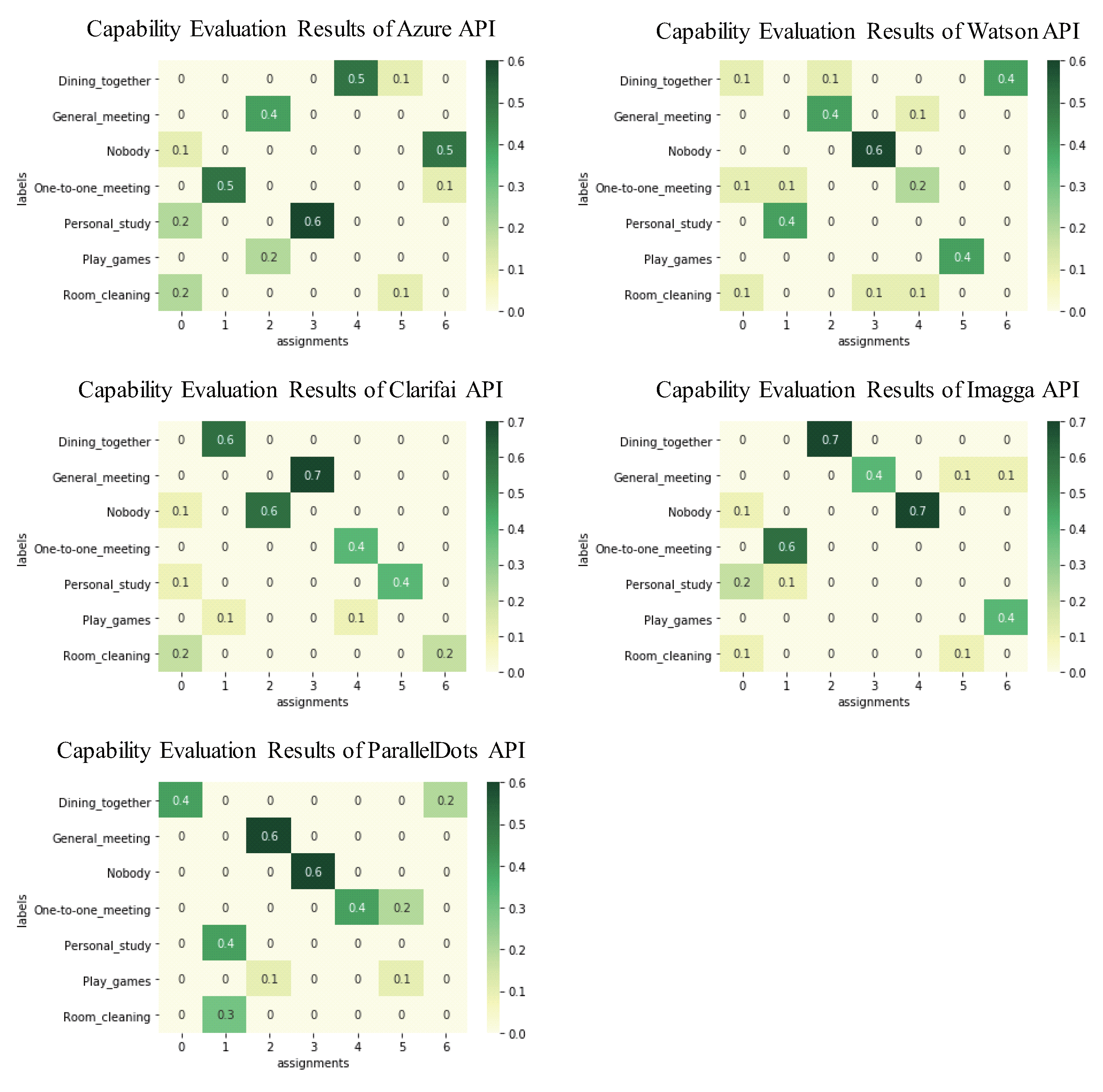
| Context Names | Azure API | Watson API | Clarifai API | Imagga API | ParallelDots API | Total |
|---|---|---|---|---|---|---|
| Dining together | 0.5 | 0.4 | 0.6 | 0.7 | 0.4 | 2.6 |
| General meeting | 0.4 | 0.4 | 0.7 | 0.4 | 0.6 | 2.5 |
| Nobody | 0.5 | 0.6 | 0.6 | 0.7 | 0.6 | 3 |
| One-to-one meeting | 0.5 | 0.2 | 0.4 | 0.6 | 0.4 | 2.1 |
| Personal study | 0.6 | 0.4 | 0.4 | 0.2 | 0.4 | 2 |
| Play games | 0.2 | 0.4 | 0.1 | 0.4 | 0.1 | 1.2 |
| Room cleaning | 0.2 | 0.1 | 0.2 | 0.1 | 0.3 | 0.9 |
| Total | 2.9 | 2.5 | 3 | 3.1 | 2.8 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Saiki, S.; Nakamura, M. Toward Flexible and Efficient Home Context Sensing: Capability Evaluation and Verification of Image-Based Cognitive APIs. Sensors 2020, 20, 1442. https://doi.org/10.3390/s20051442
Chen S, Saiki S, Nakamura M. Toward Flexible and Efficient Home Context Sensing: Capability Evaluation and Verification of Image-Based Cognitive APIs. Sensors. 2020; 20(5):1442. https://doi.org/10.3390/s20051442
Chicago/Turabian StyleChen, Sinan, Sachio Saiki, and Masahide Nakamura. 2020. "Toward Flexible and Efficient Home Context Sensing: Capability Evaluation and Verification of Image-Based Cognitive APIs" Sensors 20, no. 5: 1442. https://doi.org/10.3390/s20051442
APA StyleChen, S., Saiki, S., & Nakamura, M. (2020). Toward Flexible and Efficient Home Context Sensing: Capability Evaluation and Verification of Image-Based Cognitive APIs. Sensors, 20(5), 1442. https://doi.org/10.3390/s20051442