A Model-Based Design Floating-Point Accumulator. Case of Study: FPGA Implementation of a Support Vector Machine Kernel Function †



Abstract
1. Introduction
2. Related Works
3. Materials and Methods
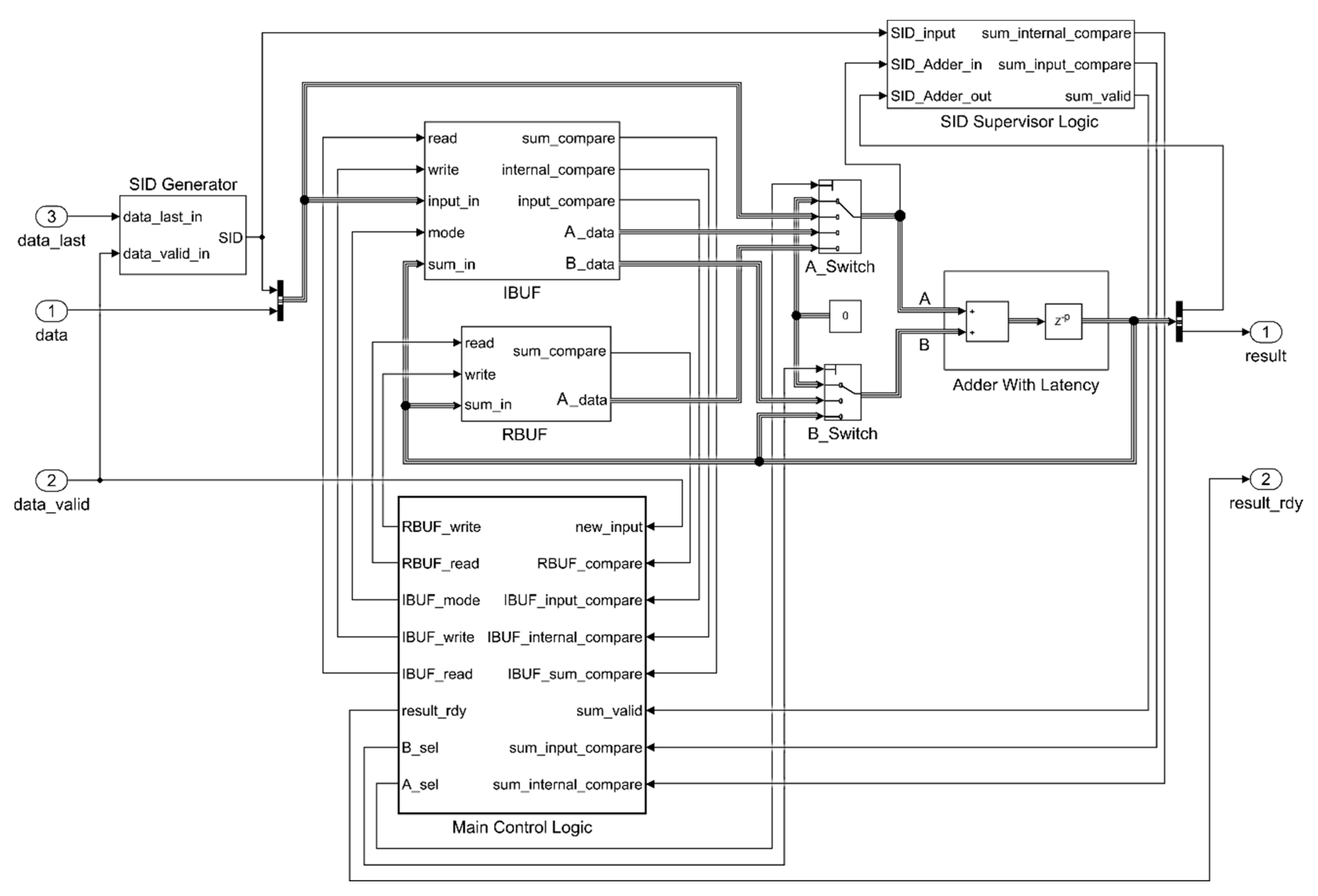
3.1. Accumulator Architecture
3.2. Kernel Architecture
4. Results and Discussion
4.1. Stand-Alone Model-Based Accumulator
4.2. Evaluation of the Proposed Model in a Practical Context: The Case of SVM Kernel Function
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bassoli, M.; Bianchi, V.; De Munari, I. A plug and play IoT wi-fi smart home system for human monitoring. Electronics 2018, 7, 200. [Google Scholar] [CrossRef]
- Petrosanu, D.M.; Carutasu, G.; Carutasu, N.L.; Pîrjan, A. A review of the recent developments in integrating machine learning models with sensor devices in the smart buildings sector with a view to attaining enhanced sensing, energy efficiency, and optimal building management. Energies 2019, 12, 4745. [Google Scholar] [CrossRef]
- Marin, I.; Vasilateanu, A.; Molnar, A.J.; Bocicor, M.I.; Cuesta-Frau, D.; Molina-Picó, A.; Goga, N. I-light—intelligent luminaire based platform for home monitoring and assisted living. Electronics 2018, 7, 220. [Google Scholar] [CrossRef]
- Rana, S.P.; Dey, M.; Ghavami, M.; Dudley, S. Signature inspired home environments monitoring system using IR-UWB technology. Sensors 2019, 19, 385. [Google Scholar] [CrossRef]
- Ghayvat, H.; Awais, M.; Pandya, S.; Ren, H.; Akbarzadeh, S.; Mukhopadhyay, S.C.; Chen, C.; Gope, P.; Chouhan, A.; Chen, W. Smart aging system: Uncovering the hidden wellness parameter for well-being monitoring and anomaly detection. Sensors 2019, 19, 766. [Google Scholar] [CrossRef]
- Guerra, C.; Bianchi, V.; De Munari, I.; Ciampolini, P. CARDEAGate: Low-cost, ZigBee-based localization and identification for AAL purposes. In Proceedings of the 2015 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Pisa, Italy, 11–14 May 2015; pp. 245–249. [Google Scholar]
- Grossi, F.; Matrella, G.; De Munari, I.; Ciampolini, P. A Flexible Home Automation System Applied to Elderly Care. In Proceedings of the 2007 Digest of Technical Papers IEEE International Conference on Consumer Electronics, Las Vegas, NV, USA, 10–14 January 2007. [Google Scholar]
- Leitao, J.; Gil, P.; Ribeiro, B.; Cardoso, A. A survey on home energy management. IEEE Access 2020, 8, 5699–5722. [Google Scholar] [CrossRef]
- Son, H.; Kim, H. A pilot study to test the feasibility of a home mobility monitoring system in community-dwelling older adults. Int. J. Environ. Res. Public Health 2019, 16, 1512. [Google Scholar] [CrossRef]
- Haratian, R. Assistive Wearable Technology for Mental Wellbeing: Sensors and Signal Processing Approaches. In Proceedings of the 2019 5th International Conference on Frontiers of Signal Processing (ICFSP), Marseille, France, 18–20 September 2019; pp. 7–11. [Google Scholar]
- Montalto, F.; Guerra, C.; Bianchi, V.; De Munari, I.; Ciampolini, P. MuSA: Wearable multi sensor assistant for human activity recognition and indoor localization. Biosyst. Biorobotics 2015, 11, 81–92. [Google Scholar]
- Moufawad El Achkar, C.; Lenoble-Hoskovec, C.; Paraschiv-Ionescu, A.; Major, K.; Büla, C.; Aminian, K. Physical behavior in older persons during daily life: Insights from instrumented shoes. Sensors 2016, 16, 1225. [Google Scholar] [CrossRef]
- Yang, S.; Gao, B.; Jiang, L.; Jin, J.; Gao, Z.; Ma, X.; Woo, W.L. IoT structured long-term wearable social sensing for mental wellbeing. IEEE Internet Things J. 2019, 6, 3652–3662. [Google Scholar] [CrossRef]
- Bianchi, V.; Bassoli, M.; Lombardo, G.; Fornacciari, P.; Mordonini, M.; De Munari, I. IoT wearable sensor and deep learning: An integrated approach for personalized human activity recognition in a smart home environment. IEEE Internet Things J. 2019, 6, 8553–8562. [Google Scholar] [CrossRef]
- Ahmed, N.; Rafiq, J.I.; Islam, M.R. Enhanced human activity recognition based on smartphone sensor data using hybrid feature selection model. Sensors 2020, 20, 317. [Google Scholar] [CrossRef] [PubMed]
- Irvine, N.; Nugent, C.; Zhang, S.; Wang, H.; Ng, W.W.Y. Neural network ensembles for sensor-based human activity recognition within smart environments. Sensors 2020, 20, 216. [Google Scholar] [CrossRef] [PubMed]
- Manjarres, J.; Narvaez, P.; Gasser, K.; Percybrooks, W.; Pardo, M. Physical workload tracking using human activity recognition with wearable devices. Sensors 2019, 20, 39. [Google Scholar] [CrossRef] [PubMed]
- Janidarmian, M.; Fekr, A.R.; Radecka, K.; Zilic, Z. A comprehensive analysis on wearable acceleration sensors in human activity recognition. Sensors 2017, 17, 529. [Google Scholar] [CrossRef]
- Ravi, D.; Wong, C.; Lo, B.; Yang, G.Z. Deep learning for human activity recognition: A resource efficient implementation on low-power devices. In BSN 2016-13th Annual Body Sensor Networks Conference; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2016; pp. 71–76. [Google Scholar]
- Mikos, V.; Heng, C.H.; Tay, A.; Yen, S.C.; Chia, N.S.Y.; Koh, K.M.L.; Tan, D.M.L.; Au, W.L. A wearable, patient-adaptive freezing of gait detection system for biofeedback cueing in Parkinson’s disease. IEEE Trans. Biomed. Circuits Syst. 2019, 13, 503–515. [Google Scholar] [CrossRef] [PubMed]
- De Venuto, D.; Annese, V.F.; Mezzina, G.; Defazio, G. FPGA-based embedded cyber-physical platform to assess gait and postural stability in parkinson’s disease. IEEE Trans. Compon. Packag. Manuf. Technol. 2018, 8, 1167–1179. [Google Scholar] [CrossRef]
- Wang, H.; Shi, W.; Choy, C.S. Hardware design of real time epileptic seizure detection based on STFT and SVM. IEEE Access 2018, 6, 67277–67290. [Google Scholar] [CrossRef]
- Gaikwad, N.B.; Tiwari, V.; Keskar, A.; Shivaprakash, N.C. Efficient FPGA implementation of multilayer perceptron for real-time human activity classification. IEEE Access 2019, 7, 26696–26706. [Google Scholar] [CrossRef]
- Wisniewski, R.; Bazydlo, G.; Szczesniak, P. Low-cost FPGA hardware implementation of matrix converter switch control. IEEE Trans. Circuits Syst. II Express Briefs 2019, 66, 1177–1181. [Google Scholar] [CrossRef]
- Giardino, D.; Matta, M.; Re, M.; Silvestri, F.; Spanò, S. IP generator tool for efficient hardware acceleration of self-organizing maps. Lect. Notes Electr. Eng. 2019, 550, 493–499. [Google Scholar]
- Hai, J.C.T.; Pun, O.C.; Haw, T.W. Accelerating Video and Image Processing Design for FPGA Using HDL Coder and Simulink. In Proceedings of the 2015 IEEE Conference on Sustainable Utilization and Development in Engineering and Technology (CSUDET 2015), Selangor, Malaysia, 15–17 October 2015; pp. 28–32. [Google Scholar]
- Michael, T.; Reynolds, S.; Woolford, T. Designing a generic, software-defined multimode radar simulator for FPGAs using simulink® HDL coder and speedgoat real-time hardware. In 2018 International Conference on Radar, RADAR 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2018. [Google Scholar]
- Bassoli, M.; Bianchi, V.; De Munari, I. A Simulink Model-based Design of a Floating-point Pipelined Accumulator with HDL Coder Compatibility for FPGA Implementation. Appl. Electron. Pervading Ind. Environ. Soc. ApplePies 2019. Lect. Notes Electr. Eng. 2019, 1–9, in press. [Google Scholar]
- Perry, S. Model Based Design Needs High Level Synthesis: A Collection of High Level Synthesis Techniques to Improve Productivity and Quality of Results for Model Based Electronic Design. In Proceedings of the 2009 Design, Automation and Test in Europe (DATE; 2009), Nice, France, 20–24 April 2009; pp. 1202–1207. [Google Scholar]
- Choe, J.M.; Arnedo, L.; Lee, Y.; Sorchini, Z.; Mignogna, A.; Agirman, I.; Kim, H. Model-Based Design and DSP Code Generation using Simulink® for Power Electronics Applications. In Proceedings of the 10th International Conference on Power Electronics and ECCE Asia (ICPE 2019-ECCE Asia), Busan, Korea, 27–30 May 2019; pp. 923–926. [Google Scholar]
- Ghosh, S.; Dasgupta, A.; Swetapadma, A. A study on support vector machine based linear and non-linear pattern classification. In Proceedings of the International Conference on Intelligent Sustainable Systems, ICISS 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019; pp. 24–28. [Google Scholar]
- Wang, A.N.; Zhao, Y.; Hou, Y.T.; Li, Y.L. A Novel Construction of SVM Compound Kernel Function. In Proceedings of the 2010 International Conference on Logistics Systems and Intelligent Management (ICLSIM 2010), Harbin, China, 9–10 January 2010; Volume 3, pp. 1462–1465. [Google Scholar]
- De Dinechin, F.; Pasca, B.; Creţ, O.; Tudoran, R. An FPGA-Specific Approach to Floating-Point Accumulation and Sum-of-Products. In Proceedings of the 2008 International Conference on Field-Programmable Technology (ICFPT 2008), Taipei, Taiwan, 8–10 December 2008; pp. 33–40. [Google Scholar]
- Flynn, M.J.; Oberman, S.F. Advanced Computer Arithmetic Design; Wiley: New York, NY, USA, 2001. [Google Scholar]
- Hallin, T.G.; Flynn, M.J. Pipelining of arithmetic functions. IEEE Trans. Comput. 1972, 100, 880–886. [Google Scholar]
- Zhou, L.; Morris, G.R.; Prasanna, V.K. High-performance reduction circuits using deeply pipelined operators on FPGAs. IEEE Trans. Parallel Distrib. Syst. 2007, 18, 1377–1392. [Google Scholar] [CrossRef]
- Luo, Z.; Martonosi, M. Accelerating pipelined integer and floating-point accumulations in configurable hardware with delayed addition techniques. IEEE Trans. Comput. 2000, 49, 208–218. [Google Scholar] [CrossRef]
- Nagar, K.K.; Bakos, J.D. A High-Performance Double Precision Accumulator. In Proceedings of the 2009 International Conference on Field-Programmable Technology (FPT’09), Sydney, NSW, Australia, 9–11 December 2009; pp. 500–503. [Google Scholar]
- Kuck, D.J. The Structure of Computers and Computations; Wiley: New York, NY, USA, 1978; ISBN 9780471027164. [Google Scholar]
- Kogge, P.M. The Architecture of Pipelined Computers; Hemisphere Pub. Corp.: Washington, DC, USA, 1981; ISBN 9780891164944. [Google Scholar]
- Ni, L.M.; Hwang, K. Vector-reduction techniques for arithmetic pipelines. IEEE Trans. Comput. 1985, 100, 404–411. [Google Scholar] [CrossRef]
- Sips, H.J.; Lin, H. An improved vector-reduction method. IEEE Trans. Comput. 1991, 40, 214–217. [Google Scholar] [CrossRef]
- Tai, Y.G.; Lo, C.T.D.; Psarris, K. Accelerating matrix operations with improved deeply pipelined vector reduction. IEEE Trans. Parallel Distrib. Syst. 2012, 23, 202–210. [Google Scholar] [CrossRef]
- Huang, M.; Andrews, D. Modular design of fully pipelined reduction circuits on FPGAs. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 1818–1826. [Google Scholar] [CrossRef]
- Wei, M.; Huang, Y.H. A Tag Based Vector Reduction Circuit. In Proceedings of the 2015 IEEE High Performance Extreme Computing Conference (HPEC 2015), Waltham, MA, USA, 15–17 September 2015; pp. 1–6. [Google Scholar]
- Tang, L.; Cai, G.; Yin, T.; Zheng, Y.; Chen, J. A Resource Consumption and Performance Overhead Optimized Reduction Circuit on FPGAs. In Proceedings of the 2019 International Conference on Field-Programmable Technology (ICFPT), Tianjin, China, 9–13 December 2019; pp. 287–290. [Google Scholar]
- Hofmann, T.; Schölkopf, B.; Smola, A.J. Kernel methods in machine learning. Ann. Stat. 2008, 36, 1171–1220. [Google Scholar] [CrossRef]
- Wu, D.; Wang, Z.; Chen, Y.; Zhao, H. Mixed-kernel based weighted extreme learning machine for inertial sensor based human activity recognition with imbalanced dataset. Neurocomputing 2016, 190, 35–49. [Google Scholar] [CrossRef]
- Althloothi, S.; Mahoor, M.H.; Zhang, X.; Voyles, R.M. Human activity recognition using multi-features and multiple kernel learning. Pattern Recognit. 2014, 47, 1800–1812. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accumulator Latency | ||
|---|---|---|---|
| Generic | p = 14, n = 16 | ||
| SSA [36] | 257 | 408 | |
| FCBT [36] | 85 | 100 | |
| AM [41] | 64 | 83 | |
| MA [42] | 58 | 71 | |
| A2eMFPA [44] | 81 | 100 | |
| [45] | 60 | 104 | |
| SBM [46] | not available | - | 75 |
| DB [43] | 57 | 71 | |
| Proposed Model | Simulink IP | |
|---|---|---|
| Slice LUTs | 1643 | 40198 |
| Slice registers | 1239 | 33450 |
| DSPs | 0 | 0 |
| BRAM | 0 | 0 |
| Fmax (MHz) | 105 | 109 |
| Latency (cycles) | 49 | 989 |
| Proposed Model | Simulink IP | |
|---|---|---|
| Logic Elements | 2483 | 47430 |
| DSPs | 0 | 0 |
| Memory (bits) | 154 | 436648 |
| Fmax (MHz) | 108 | N.A. |
| Latency (cycles) | 49 | 989 |
| Proposed Accumulator | Single-Set DB [28] | Iterative [33] | SBM [46] | Vivado IP | |
|---|---|---|---|---|---|
| Slice LUTs | 1643 | 749 | 658 | 1411 | 3245 |
| Slice registers | 1239 | 811 | 534 | 1027 | 3120 |
| DSPs | 0 | 0 | 0 | 0 | 0 |
| BRAM | 0 | 8.5 | 8.5 | 0 | 0 |
| Fmax (MHz) | 105 | 112 | 126 | 102 | 134 |
| Latency (cycles) | 49 | 9800 | 200,200 | 54 | 23 |
| Proposed Accumulator | Simulink IP | |
|---|---|---|
| Slice LUTs | 3266 | 41,354 |
| Slice registers | 2791 | 34,700 |
| DSPs | 3 | 3 |
| BRAM | 0 | 0 |
| Fmax (MHz) | 106 | 106 |
| Latency (clock cycles) | 161 | 1002 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bassoli, M.; Bianchi, V.; De Munari, I. A Model-Based Design Floating-Point Accumulator. Case of Study: FPGA Implementation of a Support Vector Machine Kernel Function. Sensors 2020, 20, 1362. https://doi.org/10.3390/s20051362
Bassoli M, Bianchi V, De Munari I. A Model-Based Design Floating-Point Accumulator. Case of Study: FPGA Implementation of a Support Vector Machine Kernel Function. Sensors. 2020; 20(5):1362. https://doi.org/10.3390/s20051362
Chicago/Turabian StyleBassoli, Marco, Valentina Bianchi, and Ilaria De Munari. 2020. "A Model-Based Design Floating-Point Accumulator. Case of Study: FPGA Implementation of a Support Vector Machine Kernel Function" Sensors 20, no. 5: 1362. https://doi.org/10.3390/s20051362
APA StyleBassoli, M., Bianchi, V., & De Munari, I. (2020). A Model-Based Design Floating-Point Accumulator. Case of Study: FPGA Implementation of a Support Vector Machine Kernel Function. Sensors, 20(5), 1362. https://doi.org/10.3390/s20051362