1. Introduction
Recently, reinforcement learning has been applied to various fields and shows better performance than humans. Reinforcement learning [
1] is how the agent observes the simulation or real environment and chooses an action that maximizes the cumulative future reward. In particular, after the development of Deep Q-Network (DQN) by Google DeepMind, reinforcement learning has been applied to Atari Games in 2015 [
2], Go in 2016 and in 2018 (AlphaGo and AlphaZero) [
3,
4], and StarCraft 2 in 2019 (AlphaStar) [
5]. As a result, the optimal control using reinforcement learning has been studied mostly in the area of game playing.
On the other hand, the real-world control systems, such as inverted pendulums, robot arms, quadcopters, continuum manipulators, chemical reactors, and so on, are of different categories of nonlinearities. One of the most effective ways to develop a nonlinear control strategy, reinforcement learning-based control schemes interact directly with these systems in a trial-and-error manner to train agents to learn optimal control policies [
6,
7,
8,
9]. In our previous work [
10], we also proved that a DQN agent can control a rotary inverted pendulum (RIP) successfully, even though the agent is deployed remotely from the pendulum. An imitation learning approach was applied to reduce the learning time and mitigate the instability problem in the previous study.
Multiple IoT devices of one type are often installed and utilized simultaneously in a domain. For example, in a factory that produces a large number of cars per day, many robotic arms of the same type assemble them precisely. In order to control such multiple robotic arms optimally, a reinforcement learning agent that controls one IoT device can collaborate with other agents that control the other IoT devices in order to learn its optimal control policy faster. Such a collaboration is able to accelerate the learning process and mitigate the instability problem for training multiple IoT devices.
Although multiple IoT devices of the same type are produced on the same manufacturing line, their physical dynamics are usually somewhat different. Therefore, there is no guarantee that an agent who interacts only with one IoT device and learns the optimal control policy will control another IoT device well. A simple copy of a mature control policy model to multiple devices cannot be a solution, but a kind of cooperative method is required to train multiple IoT devices efficiently. We consider that the cooperative reinforcement learning agents sharing learning outcomes can have more generalization capability than an agent that interacts only one IoT device.
Bonawitz et al. [
11] proposed a new machine learning system based on federated learning, which is a distributed deep learning approach to enable training on a large corpus of decentralized data residing in multiple IoT devices like a mobile phone. The federated reinforcement learning enables learning to be shared among other agents on IoT devices by conducting learning in separate environments through distributed multi-agents and collecting learning experiences through a broker. In this paper, we propose a new federated reinforcement learning scheme for controlling multiple IoT devices of the same type by borrowing the idea of the collaborative approach of the federated learning.
In the proposed scheme, each agent on multiple IoT devices shares its learning experiences, i.e., a gradient of loss function computed on each device, with each other. This strategy enhances the generalization ability of each agent. Each agent also transfers its deep learning model parameters into other agents when its learning process is finished, so that other workers can accelerate its learning process by utilizing the mature parameters. Therefore, the proposed federated learning scheme consists of two phases: (1) gradient sharing phase and (2) transfer learning phase. Inside the overall procedure of the proposed scheme, the actor–critic proximal policy optimization (Actor–Critic PPO) [
12,
13,
14] is incorporated instead of DQN. Actor–Critic PPO consists of the policy neural network (actor) that determines the optimal behavior of the agent, and the value neural network (critic) that serves to evaluate the policy. It is inspired by TRPO [
15], but is known to be simpler and provide superior performance in many domains [
7]. We evaluate the performance of our federated reinforcement learning scheme incorporating Actor–Critic PPO with the three RIP devices.
The contributions of this paper can be summarized as follows:
We propose a new federated reinforcement learning scheme to allow multiple agents to control their own devices of the same type but with slightly different dynamics.
We verify that the proposed scheme can expedite the learning process overall when the control policies are trained for the multiple devices.
The remainder of this paper is organized as follows. In
Section 2, we review related studies and state the motivation for our work. In
Section 3, we describe the overall system architecture and procedure of the proposed federated reinforcement learning scheme. In
Section 4, we explain the operation methods of the gradient sharing and model transfer, and present the details of the Actor–Critic PPO algorithm used for reinforcement learning. In
Section 5, we prove the effectiveness of the proposed scheme by applying it to three real RIP devices. Finally, we provide concluding remarks and future work in
Section 6.
3. System Architecture & Overall Procedure
In this section, we describe the proposed federated reinforcement learning system architecture and overall procedure to allow multiple agents to control their own IoT devices. The proposed system consists of one chief node and N worker nodes. The workers have their own independent environment (i.e., IoT device) and train its actor and critic models to control the environment optimally through its reinforcement algorithm. On the other hand, the chief node mediates the federated work across the N workers and ensures that each worker’s learning process is synchronized.
The reinforcement learning has been mostly researched in simulation environments to consist of software. In the simulation environment, most elements of the device are placed in cyberspace and implemented in software. However, as shown in
Figure 1, the manufactured real IoT devices are positioned in the physical space and the worker containing our reinforcement learning agent is usually placed in cyberspace because of the IoT device’s constrained resource. Therefore, the elements of cyberspace and physical space interact in real-time is important. Besides, it is vital that the reinforcement learning agent must not be broadly changed to control the real IoT device. In other words, the control task in the equivalent process irrespective of whether the environment to be controlled exists in the cyber or physical space should be performed by the reinforcement learning agent. We allow workers to set up a cyber environment to correspond with the physical environment, so that the state of the real IoT device can be observed and be controlled by the reinforcement learning agents only over the cyber environment. When observing and controlling the real IoT device, the reinforcement learning agent may not need to know that the real device is placed in the physical space.
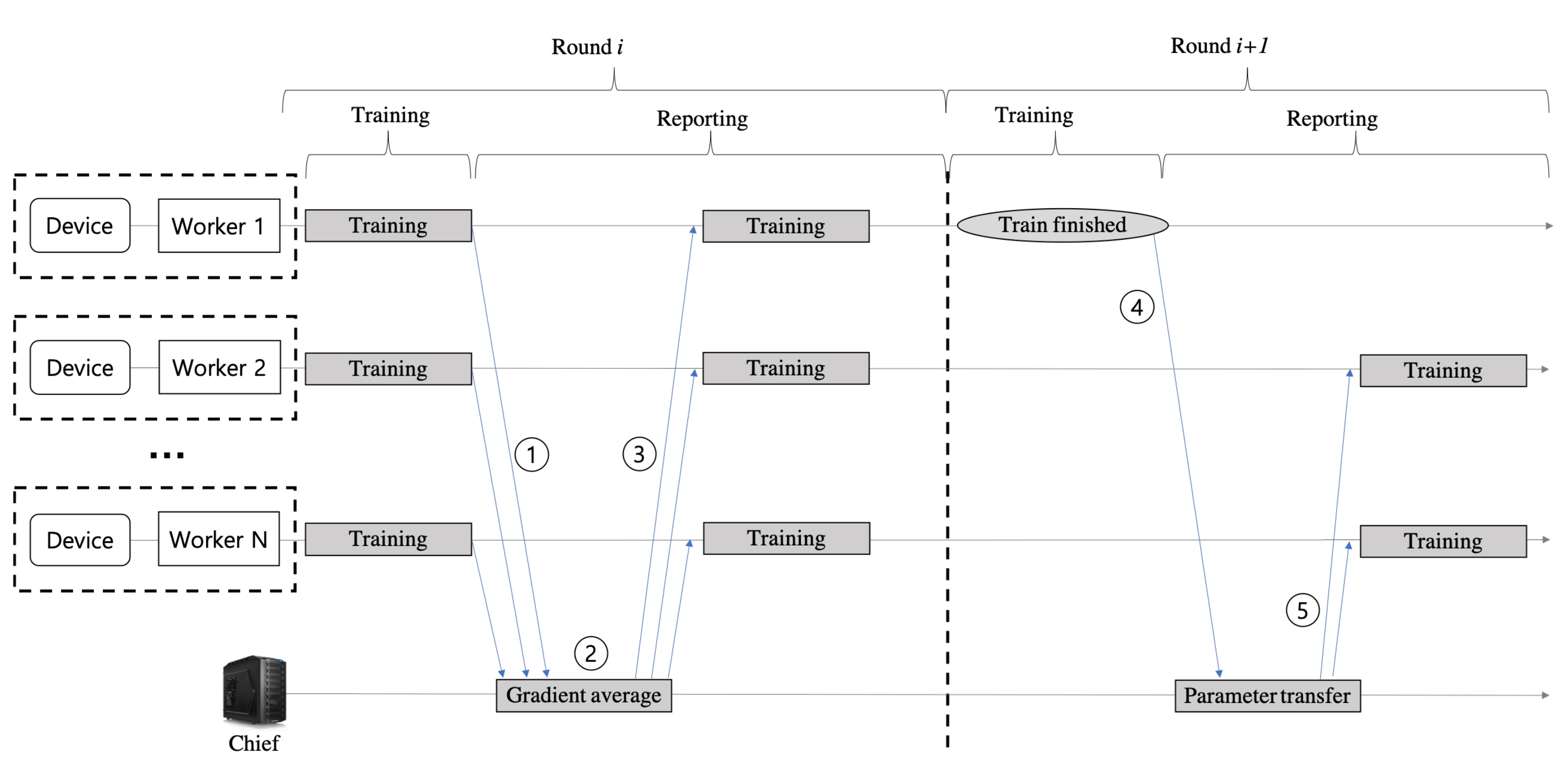
Figure 2 shows the system overall procedure for the proposed federated reinforcement learning scheme. The process where each worker sends and receives messages back to the chief is called
Round. For a round, each worker starts a sequential interaction (i.e., an episode) with its environment at the time step
t = 0, and finishes at the time step
T when the episode end condition is met (the episode end conditions vary according to the type of control IoT devices and the control objective). At every time step
t, the worker receives a representation
of the environment’s state and selects an action
that is executed in the environment which in turn provides a reward signal
and a representation
of the successor state. For every time step
t, the worker stores the tuple
as its experience into its trajectory memory. The tuples of trajectory memory are continuously maintained across every round. But, the size of trajectory memory is limited, so that the tuples are inserted and removed according to an organizing and manipulating rule, such as the first-in first-out (FIFO) rule.
In each round, each worker’s reinforcement learning algorithm calculates the gradients for the optimization of actor and critic models by using the tuples stored in the trajectory memory. For the deep learning models of a worker, the gradients are the vectors of partial derivatives with respect to the parameters of the models and they are used to find the optimal models to control the IoT device.
The two phases, (1) gradient sharing and (2) model transfer, are synchronized and mediated by the chief node. In the gradient sharing phase, the chief collects the actor model’s gradient produced by the learning process of workers (step ① in
Figure 2), averages them (step ②), and sends it back to the workers (step ③). The workers optimize the current actor model once more using the average gradient received from the chief. In our architecture, the gradient represents the experience of the learning task that a worker has made to control its IoT device. That is, workers share their experience with each other during the gradient sharing phase.
The idea of gradient sharing was first introduced by [
27]. However, it has been used asynchronously for the parallel or distributed SGD implementation, whereas we utilize it in a synchronous manner. Even though the asynchronous gradient sharing can minimize worker idle time, it is not recommended due to the added noise from stale gradients (referred to as the “delayed gradient problem”) [
28,
29]. With synchronous gradient sharing, the chief waits for all gradients to be available before computing the average and sending it back to the workers. The drawback is that some workers may be slower than others, so other workers may have to wait for them at every round. To reduce the waiting time, we could ignore the gradients from the slowest few workers (typically 10%).
After multiple rounds of the gradient sharing, a worker comes to satisfy the predefined criteria for completing the learning process. At this time, the next round is executed for the model transfer phase. During the model transfer phase, the worker completing its learning process sends its mature actor model parameters to the chief (step ④ in
Figure 2). When receiving the mature actor model parameters from a worker, the chief considers them the best ones, and it transfers them to the rest
workers (step ⑤). And then, the
workers replace their model parameters with the mature model parameters, so that the leaning time can be reduced for the workers with slow learning.
Although the mature actor model is incorporated to the
workers, several gradient sharing phases may be still needed among the workers, since the inherent dynamics of each IoT device are slightly different from each other. Therefore, the same procedure of the steps from ① to ⑤ in
Figure 2 is performed repeatedly between the rest of the workers. By continuously performing this procedure, the learning processes of all workers are completed when the predefined condition is satisfied at the last worker.
4. Federated Reinforcement Learning Algorithm
In our study, each worker conducts individual training with the Actor–Critic PPO algorithm on an independent IoT device. The key advantage of Actor–Critic PPO is that a new update of the policy model does not change it too much from the previous policy. It leads to less variance in learning, but ensures smoother policy update and also ensure that the worker does not go down an unrecoverable path of taking senseless actions. This feature is particularly important for optimal IoT device control because optimal control learning for IoT devices in the physical environment takes more time than software in the cyber environment.
An actor model (i.e., policy model) has its own model parameters . With an actor model, a worker performs the task of learning what action to take under a particular observed state of the IoT device. The worker sends the action predicted by the actor model to the IoT device and observes what happens in the IoT device. If something positive happens as a result of the action, then a positive response is sent back in the form of a reward. If a negative occurs due to the taken action, then the worker gets a negative reward. This reward is taken in by the critic model with its model parameter . The role of the critic model inside a worker is to learn to evaluate if the action taken by the actor model led the IoT device to be in a better state or not, and the critic model’s feedback is used to the actor model optimization.
Figure 3 shows the overall process of an Actor–Critic PPO algorithm conducted in a worker whenever every episode ends. First, the Actor–Critic PPO obtains a finite mini-batch of sequential samples (i.e., experience tuples) from the trajectory memory. In a mini-batch, the time step (
in
Figure 3) of starting tuple is chosen at random, but all subsequent tuples in the mini batch must be continuous.
In a general policy gradient reinforcement learning, the objective function
is as follows:
where
is the empirical average over a finite batch of samples, and
is an estimator of the advantage function at time step
t. With the discount factor
, we use the generalized advantage estimator (GAE) [
30] to calculate
. The GAE is
where
is the GAE parameter (
),
U is the sampled mini-batch size, and
. The objective (i.e., loss) function
is as follows:
where the target value of time-difference error (TD-Error)
. The parameters of
are updated by an SGD algorithm (i.e., Adam [
31]) with the gradient
:
where
is the learning rate for the critic model optimization.
In the actor model of TRPO and PPO, instead of the objective function presented in Equation (
1), the worker uses the importance sampling to obtain the expectation of samples gathered from an old policy
under the new policy
we want to refine. They maximize the following surrogate objective function
:
With a small value
, TRPO optimizes
subject to the constraint
on the amount of the policy update.
indicates the Kullback–Leibler divergence [
32]. PPO inherits the benefit from TRPO, but it is much simpler to implement, allows multiple optimization iterations, and empirically presents a better sample efficiency than TRPO. With the probability ratio
, the PPO objective function
is given by
where
is the clipping parameter. The clipped objective function
does not makes PPO greedy in favoring actions with positive advantage, and much quick to avoid actions with a negative advantage function from a mini-batch of samples. The parameters of
are updated by an SGD algorithm with the gradient
for the negative of the clipped objective function (i.e.,
):
where
is the learning rate for the actor model optimization.
With Actor–Critic PPO, our federated reinforcement learning algorithm is provided in Algorithms 1 and 2. The chief and all workers share the parameter M which indicates the maximum number of rounds (i.e., episodes). The chief maintains the set of all workers W. Whenever a chief receives the actor model parameter from a worker w, the chief removes it from W at the end of round. If W is empty, the chief finishes its task. In a worker, K is the number of model optimizations in one round. The multiple model optimizations are conducted to further improve sample efficiency.
5. Experiments
In this section, we apply the proposed federated reinforcement learning scheme to the real IoT devices. We validate the effectiveness of gradient sharing and transfer learning for our federated reinforcement learning in the real IoT devices. We also validate the effect of the number of workers on the performance of the proposed scheme.
| Algorithm 1: Federated RL (Chief) |
 |
| Algorithm 2: Federated RL (Worker w) |
 |
5.1. Experiment Configuration
As the real IoT device environment, we choose the RIP device (Quanser QUBE
TM-Servo 2 [
26]). It is a highly unstable nonlinear IoT device and has been used as a usual device in the nonlinear control engineering field.
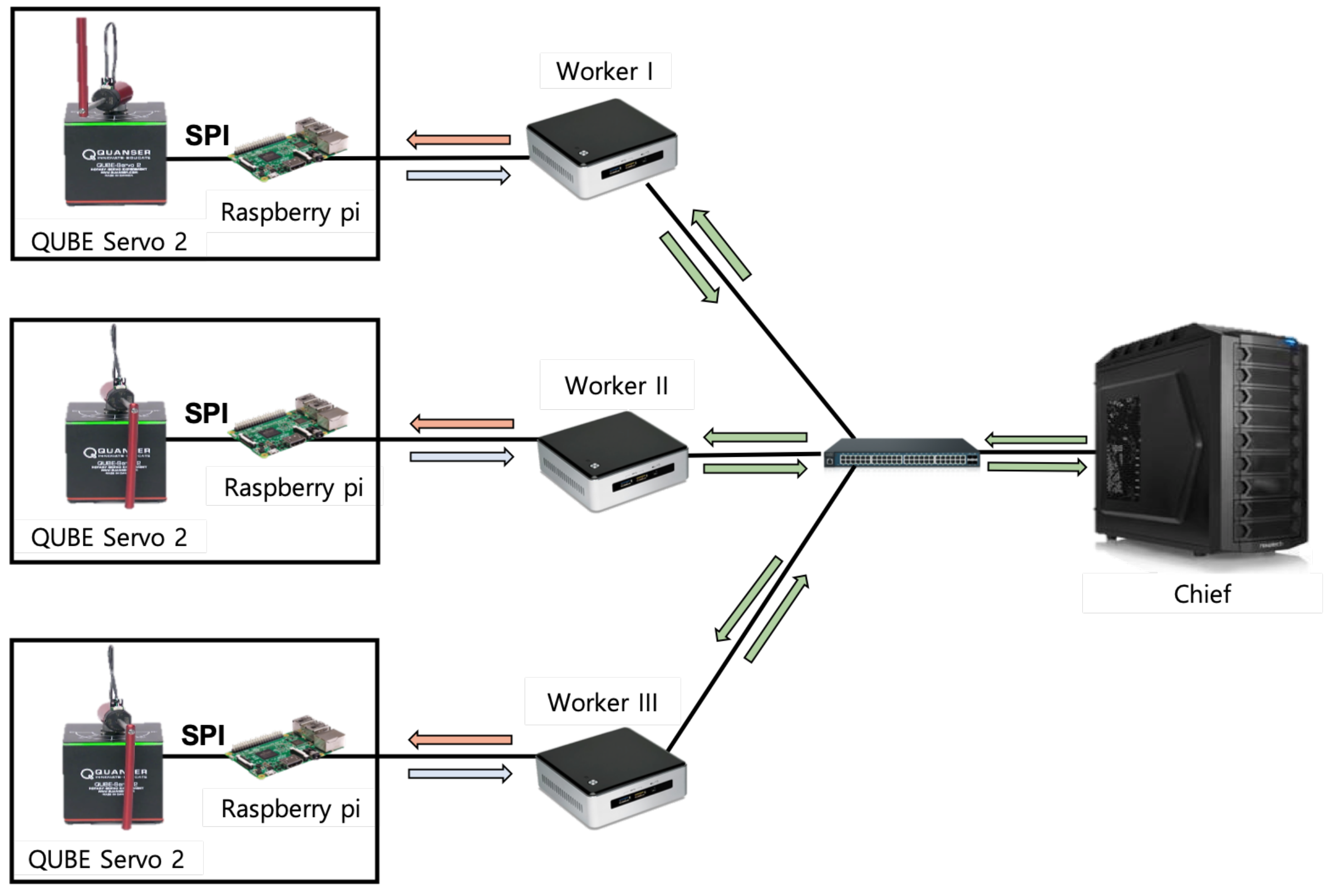
The experimental system configuration for controlling the real multiple IoT devices optimally is shown in
Figure 4. In the system, there are three workers and one chief, and each worker is connected with its RIP device. The RIP device is installed with an optical encoder that provides status information about each angular position and angular velocity of the pendulum and motor. The Raspberry Pi 3 Model B (Raspberry Pi) connects to RIP device and a worker through a serial peripheral interface (SPI). The Raspberry Pi takes the motor power index (i.e., control input) from the reinforcement learning agent in a worker, permutes it into a voltage value, and eventually sends it to the RIP device. Also, it takes observed state information (i.e., the angular position and angular velocity of the pendulum and the motor) from the RIP device, and sends them to the reinforcement learning agent in a worker. There is also a switch for the connection between the three workers and the chief. For the communication among the Raspberry Pi nodes, the workers, and the chief, the MQTT protocol is used.
The workers and the chief are deployed on Ubuntu 16.04 LTS. The proposed scheme using the Actor–Critic PPO algorithm is implemented using Python 3.6 and PyTorch 1.2. A multi-layer perceptron with the three hidden layers and two separate output layers is used to constitute the actor and critic models. The two models share the three hidden layers, where each layer includes 128 neurons. For the actor model, the first output layer yields three values (i.e., three types of actions) that sum to one. For the critic model, the second output layer yields a single value to evaluate the action selected by the actor model. The other hyper-parameters of the Actor–Critic PPO algorithm are listed in
Table 1.
5.2. State, Action, and Reward Formulation
First, we perform an upswing control at the beginning of each round. This process forces the motor to move until the pendulum is facing upwards. This process has been empirically implemented using existing control models in the mechanical field. The proposed Actor–Critic PPO reinforcement learning algorithm then tries to balance the pendulum.
For the proposed algorithm, the state of reinforcement learning consists of observed information from the environment. The observed information is as follows: (1) pendulum angle, (2) pendulum angular velocity, (3) motor angle, and (4) motor angular velocity. In an episode, at every step, a new state is provided for the actor and critic models.
The action is selected by each worker’s actor model and the RIP device controls the motor by the selected action. The selected actions are −60, 0 and 60 as the power of the motor. These values are the power to turn the motor. If the selected action is negative 60, the direction of turning is from right to left, whereas the direction of rotation is positive 60, the direction of turning is from left to right. On the Raspberry Pi, the motor power index is changed to the motor voltage value, which is fed to the RIP device.
Designing rewards is important for reinforcement learning challenges. At each step, the reward is calculated after applying the selected action in the current state by the cyber environment. The value of reward depends on each step of success or failure. If the pendulum of the RIP is within a range of ±7.5 degrees (i.e., the pendulum is standing upright) of the step, the step succeeds and the reinforcement learning agent is rewarded with . If the step fails, the reinforcement learning agent is rewarded with 0 and the episode is terminated. When the episode is terminated, the score is the sum of the reward for all steps of the episode. If the weighted moving average of the reward in the last 10 episodes is 2450, then the learning is determined to be complete.
5.3. Effect of Gradient Sharing & Transfer Learning
Figure 5 shows the effectiveness of the proposed federated reinforcement learning for the experimental system. In particular, the advantages of gradient sharing and model transfer are illustrated in the figure. For each of the three workers,
Figure 5a shows the change of the score and the loss values of the actor model when each worker performs the learning process individually, while
Figure 5b shows the change of the ones when the proposed scheme is applied. As known in the two figures, at about 300 episodes, the learning process of all workers is completed when the proposed federated learning scheme is applied. However, without the proposed scheme, the learning process of Worker I and II are completed at about 820 episodes and the one of worker III is completed at 571 episodes. Therefore, we can know that the learning speed becomes much higher and the variation in learning time for each RIP device is also reduced when the proposed scheme is applied.
It is also noted in
Figure 5b that the score value of Worker I and III increases suddenly at 287 episodes. It happens because Worker II transfers its mature actor model into Worker I and III. The model transfer plays a large role in shortening the learning time.
However, we can also know that the additional learning at Worker I and III are still needed over several episodes to complete the learning process, even though the mature model of Worker II is transferred to them. To find out the reason for additional learning, another experiment is conducted. We apply the exact same amount of force to each of three RIP devices (i.e., Quanser QUBE
TM-Servo 2) 100 times in different directions, and measure the Pearson correlation between the changes of the motor and the pendulum angles for the three devices. Pearson correlation [
33] is commonly used to find the relationship between two random variables. The Pearson correlation coefficient has
if the two variables X and Y are exactly the same, 0 if they are completely different, and
if they are exactly the same in the opposite direction.
Table 2 shows the results of the homogeneity test for the dynamics of three RIP devices of the same type. As known from the two tables, the angles of motor and pendulum are changed differently even though the forces applied in different directions are constant over 100 times. For each RIP device, in particular, the change in motor angle is more varied than the change in the pendulum angle. For multiple RIP devices of the same type, as a result, their dynamics are slightly different from each other, even though they are produced on the same manufacturing line. This means that the additional learning at Worker I and III is still needed even after receiving the mature model of Worker II.
Figure 6 shows the efficiency of the federated reinforcement learning according to the number of workers. For two workers and three workers, the experiments are conducted five times and the average score per episode is shown in the figure. As shown in the figure, the higher the number of workers, the faster the learning process. In the proposed scheme, each worker share its learning experiences, i.e., the gradient of loss function computed on each RIP device, with each other. Each agent also transfers its actor model parameters into other agents when its learning process is finished. As the number of workers increases, the effects of such two strategies increase.
In our previous study [
34], we validated the proposed federated reinforcement learning through the CartPole simulation software environment of the OpenAI Gym. We also found that the performance increases as the number of workers increases from one to eight in the simulation environment. The source code of the experiments is publicly available at
https://github.com/glenn89/FederatedRL (
Supplementary Material).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}