A Self-Calibrating Probabilistic Framework for 3D Environment Perception Using Monocular Vision


Abstract
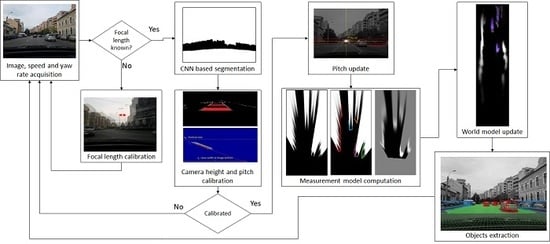
1. Introduction
2. Related Work
3. Materials and Methods
3.1. The Probabilistic World Model
3.2. Computing the Probabilistic Measurement Model
- Map the useful area mask to the grid space, using the transformation homography. Every grid area point that projects outside the perspective image, or projects in the black areas of the usefulness mask, will be set to the value 0, and all other points will be set to value 255. The result is the grid space visibility mask, shown in Figure 4d, and will be further denoted by M.
- Map the segmented perspective image to the grid space, using the transformation homography. The grid cells that overlap values of zero in the visibility mask will be set to zero, and the other will be set to their corresponding segmented perspective value. The result is shown in Figure 4e, and will be further denoted by B.
| Algorithm 1: Extraction of convex scan lines | |
| Input: bird eye view segmented image B Output: polar distances d(a), for each angle a = 0…180 | |
| 1. | For each a = 0…180 |
| 2. | d(a) := D_inf // Distance for each angle, initially infinity |
| 3. | End For |
| 4. | For each row r and column c of B // Compute distance to obstacle for each ray |
| 5. | If B(r,c)>TB |
| 6. | a(r, c) := atan2 (r-rcam, c-ccam) . 180/π // angle of the ray for the obstacle cell |
| 7. | ai := |
| 8. | di := // distance on the ray for the cell |
| 9. | d(ai) := min (d(ai), di) // keep minimum distance for a ray |
| 10. | End If |
| 11. | End For |
| 12. | For each a := 0…180 |
| 13. | K(a) := 0 // Cluster label for each angle a, initially 0 |
| 14. | End For |
| 15. | N := 0 // Number of clusters, initially 0 |
| 16. | Fora := 1…180 // Cluster the rays |
| 17. | If d(a)<D_inf |
| 18. | If |d(a)-d(a-1)|<TK and K(a-1)>0 // Distance test |
| 19. | K(a) := K(a-1) |
| 20. | Else |
| 21. | N := N+1 |
| 22. | K(a) := N |
| 23. | End If |
| 24. | End If |
| 25. | End For |
| 26. | Changed := true |
| 27. | WhileChanged // Convex hull generation, for each cluster |
| 28. | Changed := false |
| 29. | For a := 1…179 |
| 30. | If d(a)<d(a-1) and d(a)<d(a+1) and K(a)=K(a-1)=K(a+1) // If middle ray is longer |
| 31. | d(a) := (d(a-1) + d(a+1))/2 // Replace middle ray with neighbors mean |
| 32. | Changed := true // Scan again |
| 33. | End If |
| 34. | End For |
| 35. | End While |
| 36. | Returnd |
| Algorithm 2: Creation of the measurement probability grid | |
| Input: polar probabilities preal(a) visibility mask M Output: measurement grid probabilities pmeasured (r,c) | |
| 1. | For each grid row r |
| 2. | For each grid column c |
| 3. | If M(r,c)>0 // If cell is visible, compute probability |
| 4. | af := atan2 (r-rcam, c – ccam) . 180/π // Floating point value of the ray angle |
| 5. | a0 := // Lower integer bound of the ray angle |
| 6. | a1 := // Upper integer bound of the ray angle |
| 7. | zf := // Floating point value of distance on ray |
| 8. | z0 := // Lower integer bound of distance |
| 9. | z1 := // Upper integer bound of distance |
| 10. | pmeasured(r,c) := LinearInterpolation(preal, a0, a1, z0, z1, af, zf) // 4 point interpolation |
| 11. | Else |
| 12. | pmeasured(r,c) := 0.5 // Cell not visible, probability is default 0.5 |
| 13. | End if |
| 14. | End For |
| 15. | End For |
| 16. | Returnpmeasured |
3.3. Updating the World State
3.4. Identifying Individual Objects
- -
- The dynamic cells are not grouped together with static cells, and also they are not grouped together with cells that have a speed that differs significantly in magnitude or orientation.
- -
- The particles that are newly created in a cell that previously had no particles are not taken into consideration when the cell is judged to be occupied or free.
3.5. Automatic Camera Calibration
4. Evaluation and Performance
4.1. Data Acquisition
4.2. Segmentation Results
4.3. Calibration Results
4.4. Obstacle Detection Results
4.5. Running Time
4.6. Comparison with Other Obstacle Detection Techniques
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhu, H.; Yuen, K.-V.; Mihaylova, L.; Leung, H. Overview of Environment Perception for Intelligent Vehicles. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2584–2601. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Romera, E.; Alvarez, J.M.; Bergasa, L.M.; Arroyo, R. ERFNet: Efficient Residual Factorized ConvNet for Real-Time Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2018, 19, 263–272. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Xie, J.; Girshick, R.; Farhadi, A. Deep3d: Fully automatic 2d-to-3d video conversion with deep convolutional neural networks. In Proceedings of the European Conference on Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 842–857. [Google Scholar]
- Garg, R.; Kumar, V.; Reid, I. Unsupervised CNN for single view depth estimation: Geometry to the rescue. In Proceedings of the Computer Vision – ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 740–756. [Google Scholar]
- Godard, C.; Aodha, O.M.; Brostow, G.J. Unsupervised Monocular Depth Estimation with Left-Right Consistency. Computer Vision and Pattern Recognition. Available online: http://openaccess.thecvf.com/content_cvpr_2017/html/Godard_Unsupervised_Monocular_Depth_CVPR_2017_paper.html (accessed on 26 February 2020).
- Casser, V.; Pirk, S.; Mahjourian, R.; Angelova, A. Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 8001–8008. [Google Scholar]
- Chen, X.; Kundu, K.; Zhang, Z.; Ma, H.; Fidler, S.; Urtasun, R. Monocular 3D Object Detection for Autonomous Driving. Available online: https://www.cs.toronto.edu/~urtasun/publications/chen_etal_cvpr16.pdf (accessed on 26 February 2020).
- Mousavian, A.; Anguelov, D.; Flynn, J.; Kosecka, J. 3D Bounding Box Estimation Using Deep Learning and Geometry. Available online: https://zpascal.net/cvpr2017/Mousavian_3D_Bounding_Box_CVPR_2017_paper.pdf (accessed on 26 February 2020).
- Roddick, T.; Kendall, A.; Cipolla, R. Orthographic Feature Transform for Monocular 3D Object Detection. British Machine Vision Conference. arXiv 2019, arXiv:1811.08188. [Google Scholar]
- Wang, Y.; Chao, W.-L.; Garg, D.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-lidar from visual depth estimation: Bridging the gap in 3d object detection for autonomous driving. arXiv 2018, arXiv:1812.07179. [Google Scholar]
- Caltech Calibration Toolbox. Available online: http://www.vision.caltech.edu/bouguetj/calib_doc/ (accessed on 16 December 2019).
- Wang, K.; Huang, H.; Li, Y.; Wang, F.Y. Research on lane-marking line based camera calibration. In Proceedings of the 2007 IEEE International Conference on Vehicular Electronics and Safety, Beijing, China, 13–15 December 2007; pp. 1–6. [Google Scholar]
- Zhang, D.; Fang, B.; Yang, W.; Luo, X.; Tang, Y. Robust inverse perspective mapping based on vanishing point. In Proceedings of the 2014 IEEE International Conference on Security, Pattern Analysis, and Cybernetics (SPAC), Wuhan, China, 18–19 October 2014; pp. 458–463. [Google Scholar]
- Russmusen, C. Texture-Based Vanishing Point Voting for Road Shape Estimation. Available online: http://www.bmva.org/bmvc/2004/papers/paper_261.pdf (accessed on 26 February 2020).
- Kong, H.; Audibert, J.-Y.; Ponce, J. Vanishing Point Detection for Road Detection. Available online: https://www.di.ens.fr/willow/pdfs/cvpr09c.pdf (accessed on 26 February 2020).
- Tan, S.; Dale, J.; Anderson, A.; Johnston, A. Inverse perspective mapping and optic flow: A calibration method and a quantitative analysis. Image Vision Comput. 2006, 24, 153–165. [Google Scholar] [CrossRef]
- Kollnig, H.; Nagel, H.-H. 3d pose estimation by directly matching polyhedral models to gray value gradients. Int. J. Comput. Vision 1997, 23, 283–302. [Google Scholar] [CrossRef]
- Barth, A.; Franke, U. Where will the oncoming vehicle be the next second? In Proceedings of the IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 1068–1073. [Google Scholar]
- Hu, H.-N.; Cai, Q.-Z.; Wang, D.; Lin, J.; Sun, M.; Kraehenbuehl, P.; Darrell, T.; Yu, F. Joint Monocular 3D Vehicle Detection and Tracking. Available online: http://openaccess.thecvf.com/content_ICCV_2019/papers/Hu_Joint_Monocular_3D_Vehicle_Detection_and_Tracking_ICCV_2019_paper.pdf (accessed on 26 February 2020).
- Danescu, R.; Itu, R.; Petrovai, A. Generic Dynamic Environment Perception Using Smart Mobile Devices. Sensors 2016, 16, 1721. [Google Scholar] [CrossRef] [PubMed]
- Danescu, R.; Oniga, F.; Nedevschi, S. Modeling and Tracking the Driving Environment with a Particle-Based Occupancy Grid. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1331–1342. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the Computer Vision and Pattern Recognition, Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Yu, F.; Xian, W.; Chen, Y.; Liu, F.; Liao, M.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Video Database with Scalable Annotation Tooling. arXiv 2018, arXiv:1805.04687. [Google Scholar]
- Neuhold, G.; Ollmann, T.; Bulò, S.R.; Kontschieder, P. The Mapillary Vistas Dataset for Semantic Understanding of Street Scenes. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5000–5009. [Google Scholar]
- Danescu, R.; Itu, R. Camera Calibration for CNN-based Generic Obstacle Detection. In Proceedings of the 19th EPIA Conference on Artificial Intelligence, Vila Real, Portugal, 3–6 September 2019; pp. 623–636. [Google Scholar]
- Monocular Road Traffic Dataset. Available online: http://users.utcluj.ro/~razvanitu/dataset.html (accessed on 18 December 2019).
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. Available online: https://eccv2018.org/openaccess/content_ECCV_2018/papers/Liang-Chieh_Chen_Encoder-Decoder_with_Atrous_ECCV_2018_paper.pdf (accessed on 26 February 2020).
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- UGV Driver Assistant. Available online: https://play.google.com/store/apps/details?id=com.infocomltd.ugvassistant&hl=en (accessed on 10 February 2020).
- Chen, X.; Kundu, K.; Zhu, Y.; Berneshawi, A.G.; Ma, H.; Fidler, S.; Urtasun, R. 3D Object Proposals for Accurate Object Class Detection. Available online: https://papers.nips.cc/paper/5644-3d-object-proposals-for-accurate-object-class-detection (accessed on 26 February 2020).
- Li, B.; Zhang, T.; Xia, T. Vehicle detection from 3d lidar using fully convolutional network. Robotics: Science and Systems. arXiv 2016, arXiv:1608.07916. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CNN Model | IoU score (road class only) |
|---|---|
| DeepLab [29] | 0.986 |
| E-Net [30] | 0.974 |
| Proposed CNN-trained multi-class | 0.922 |
| Proposed CNN-trained single-class (road only) | 0.911 |
| Scenario | Estimated Camera Height (mm) | Ground Truth Camera Height (mm) | Pitch Angle (degrees) |
|---|---|---|---|
| Own setup test 1 | 1268 | 1250 | −1.68° |
| Own setup test 2 | 1234 | 1200 | −3.8° |
| Own setup test 3 | 1468 | 1480 | 2.97° |
| KITTI setup | 1649 | 1650 | −0.85° |
| Distance Range (m) | KITTI 0005 MAE (m) | KITTI 0010 MAE (m) | KITTI 0011 MAE (m) | KITTI 0018 MAE (m) |
|---|---|---|---|---|
| 0–10 | - | - | 0.8 | - |
| 10–20 | 1.30 | 2.6 | 3.29 | 3.91 |
| 20–30 | 3.65 | 2.74 | 5.59 | 5.59 |
| 30–40 | 2.07 | 6.03 | 11.72 | 6.2 |
| 40–50 | 2.08 | 4.35 | 19.06 | 9.32 |
| Distance Range (m) | KITTI 0005 Detection Rate (%) | KITTI 0010 Detection Rate (%) | KITTI 0011 Detection Rate (%) | KITTI 0018 Detection Rate (%) |
|---|---|---|---|---|
| 0–10 | - | - | 97.56 | - |
| 10–20 | 100 | 94.73 | 97.25 | 79.2 |
| 20–30 | 89.62 | 62.78 | 82.95 | 74.4 |
| 30–40 | 76.95 | 51.85 | 40.73 | 74.71 |
| 40–50 | 60 | 5.35 | 31.46 | 47.05 |
| Distance Range (m) | Mean Absolute Error (m) | Detection Rate (%) |
|---|---|---|
| 0–10 | 0.78 | 88.66 |
| 10–20 | 1.37 | 96.03 |
| 20–30 | 2.62 | 92.32 |
| 30–40 | 7.21 | 80.61 |
| 40–50 | 17.44 | 57.43 |
| Number of Vehicles Detected | Detection Rate (%) | Number of False Positive Detections | False Discovery Rate (%) | |
|---|---|---|---|---|
| Ours | 88 | 92.6 | 5 | 0.05 |
| UGV [31] | 87 | 91.5 | 49 | 34.0 |
| Method | Sensor | Self-Calibration | Detect Speed | Detect Orientation | Support Multiple Sensors | Generic Obstacle Detection |
|---|---|---|---|---|---|---|
| Mono 3D [9] | Monocular | No | No | Yes | No | No |
| OFT-Net [11] | Monocular | No | No | Yes | No | No |
| 3DOP [32] | Stereovision | No | No | Yes | No | No |
| Danescu et al. [23] | Stereovision | No | Yes | Yes | Yes | Yes |
| Li et al. [33] | Lidar | No | No | Yes | Yes | No |
| Hu et al. [21] | Monocular | No | No | Yes | No | No |
| Ours | Monocular | Yes | Yes | Yes | Yes | Yes |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Itu, R.; Danescu, R.G. A Self-Calibrating Probabilistic Framework for 3D Environment Perception Using Monocular Vision. Sensors 2020, 20, 1280. https://doi.org/10.3390/s20051280
Itu R, Danescu RG. A Self-Calibrating Probabilistic Framework for 3D Environment Perception Using Monocular Vision. Sensors. 2020; 20(5):1280. https://doi.org/10.3390/s20051280
Chicago/Turabian StyleItu, Razvan, and Radu Gabriel Danescu. 2020. "A Self-Calibrating Probabilistic Framework for 3D Environment Perception Using Monocular Vision" Sensors 20, no. 5: 1280. https://doi.org/10.3390/s20051280
APA StyleItu, R., & Danescu, R. G. (2020). A Self-Calibrating Probabilistic Framework for 3D Environment Perception Using Monocular Vision. Sensors, 20(5), 1280. https://doi.org/10.3390/s20051280