Automatic Tunnel Crack Detection Based on U-Net and a Convolutional Neural Network with Alternately Updated Clique


Abstract
1. Introduction
1.1. Motivation
1.2. Related Works
1.3. Contribution
- A new deep learning network based on Clique-net and U-net called U-CliqueNet is proposed for semantic segmentation of tunnel cracks from images.
- The proposed model integrates clique block and into U-net and adds an attention mechanism in the process of down-sampling, which makes it better than U-net in dealing with crack segmentation noises.
- A tunnel crack dataset is established, including various cracks and disturbances. The proposed model is tested on this dataset, and the length and mean width of cracks can be calculated automatically.
2. Methodology
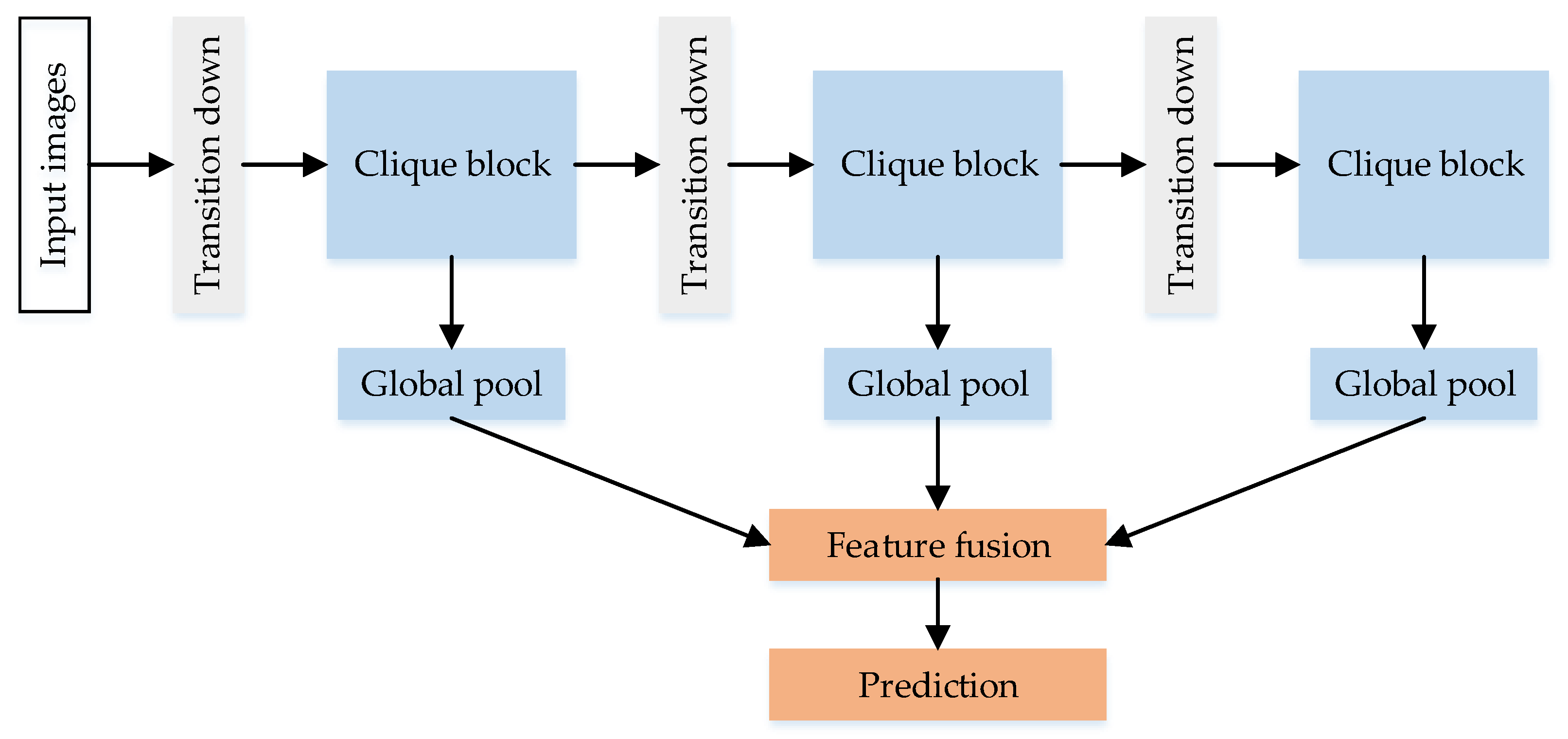
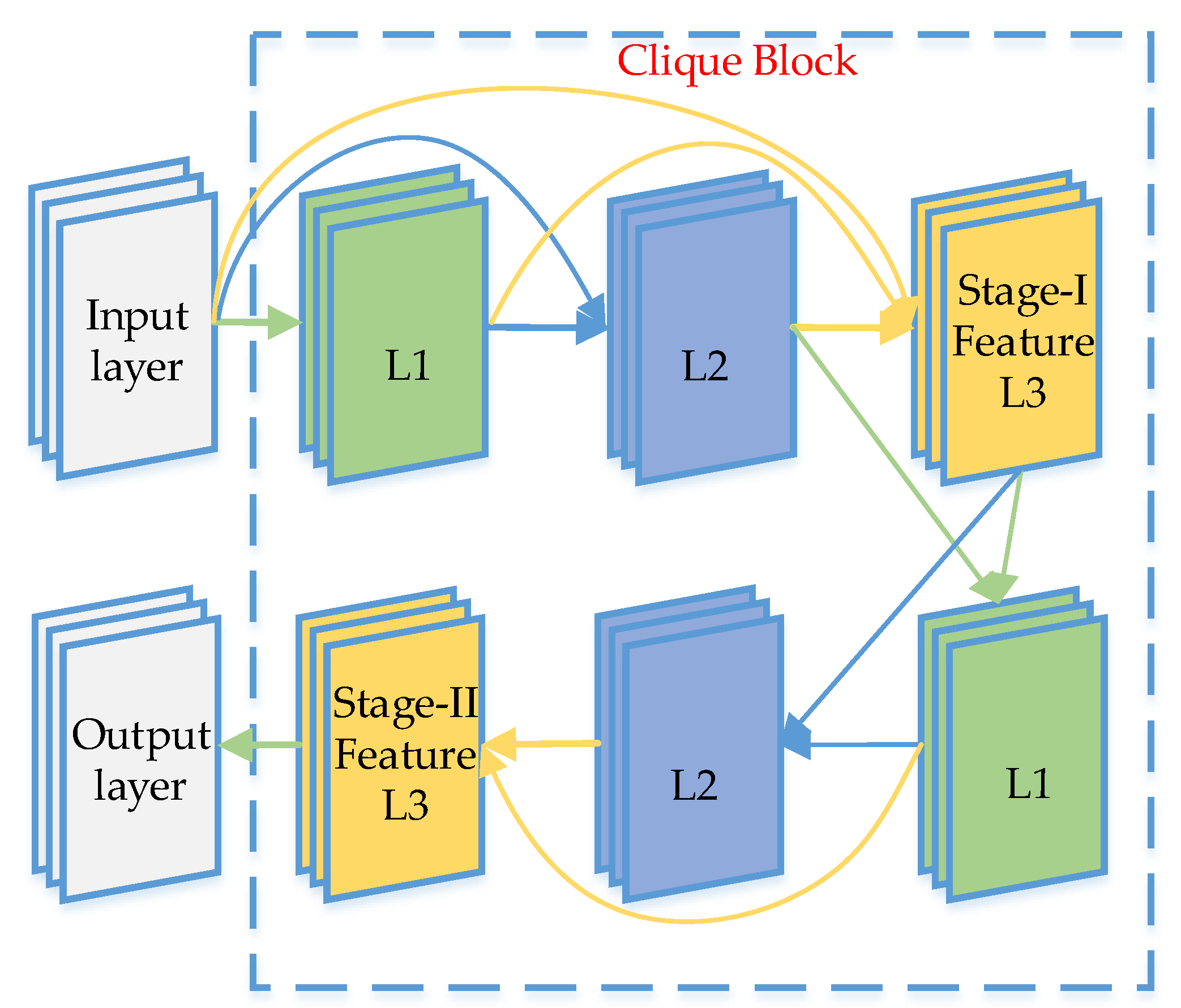
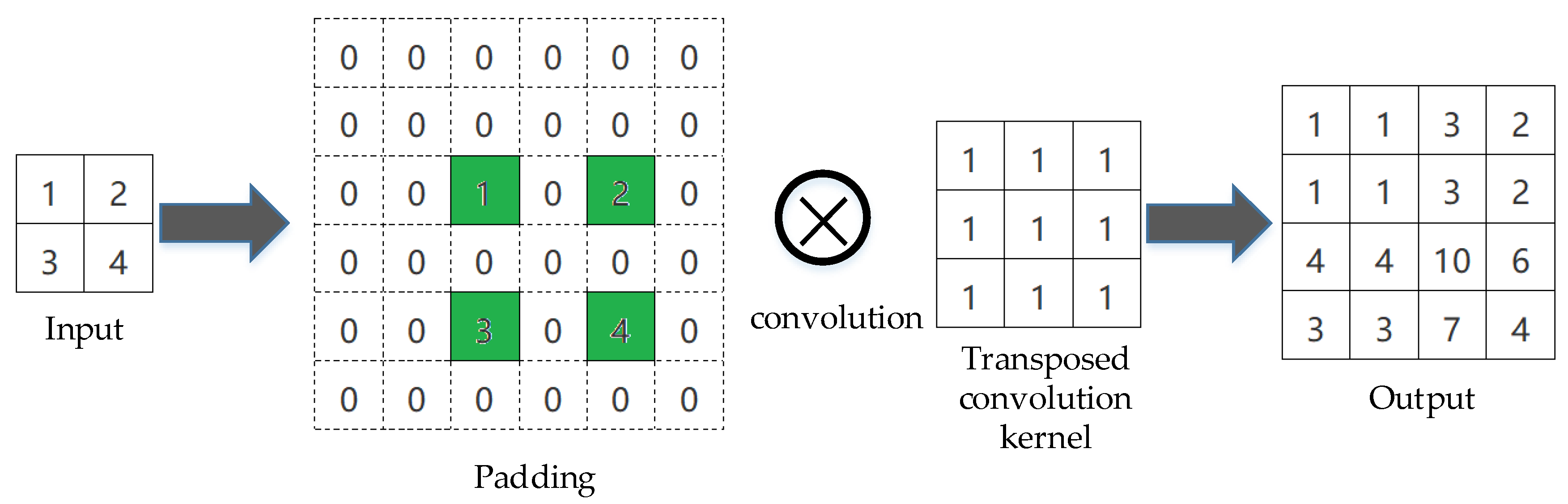
2.1. Review of U-net and CliqueNet
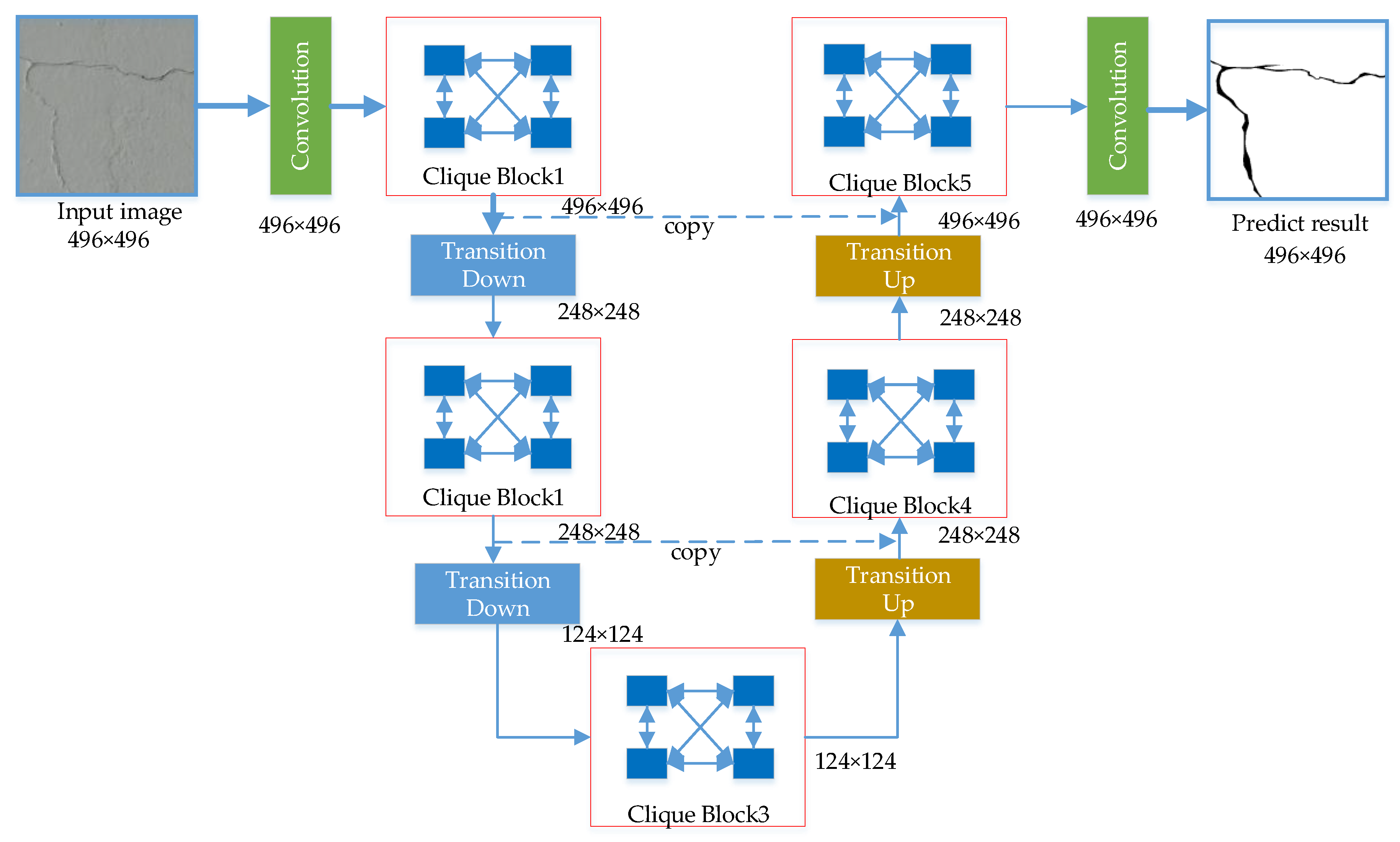
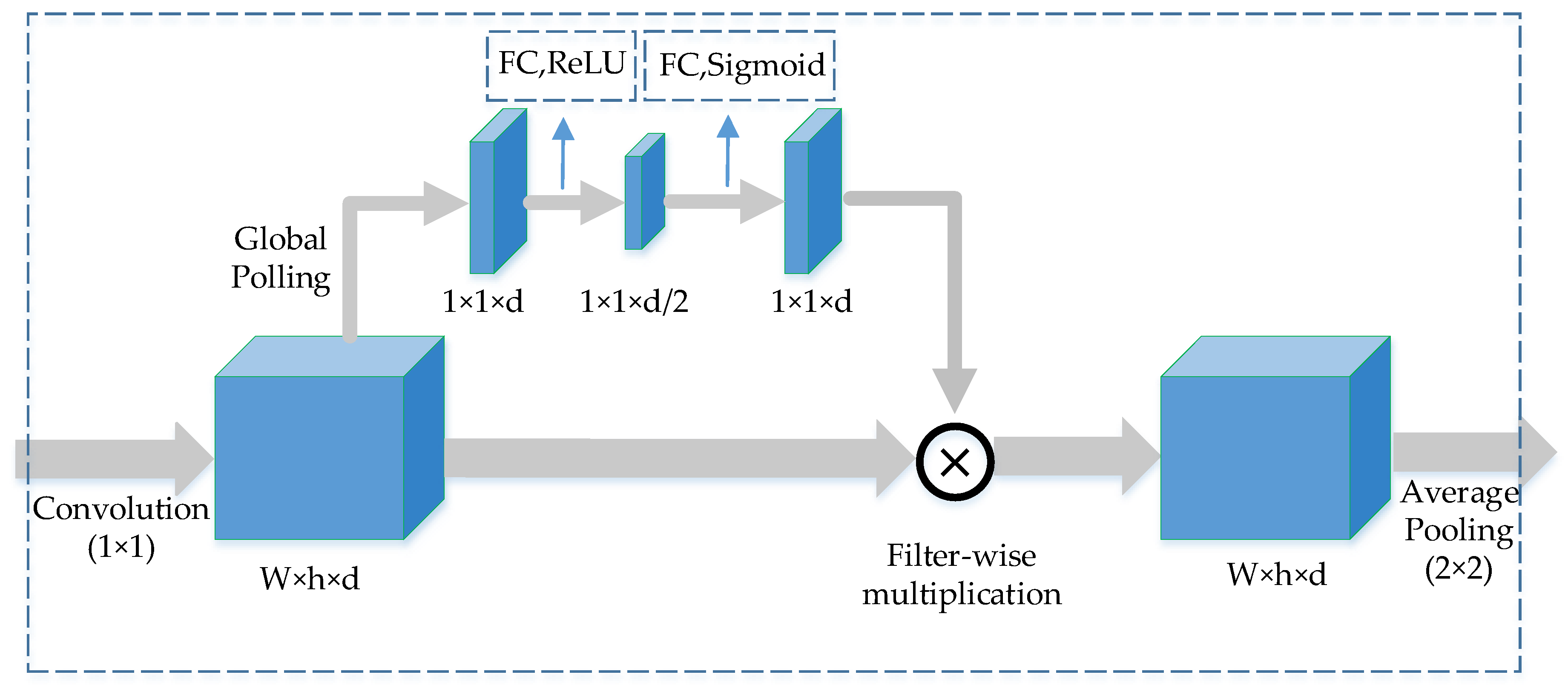
2.2. Overall Architecture of U-CliqueNet
3. Implementation Details
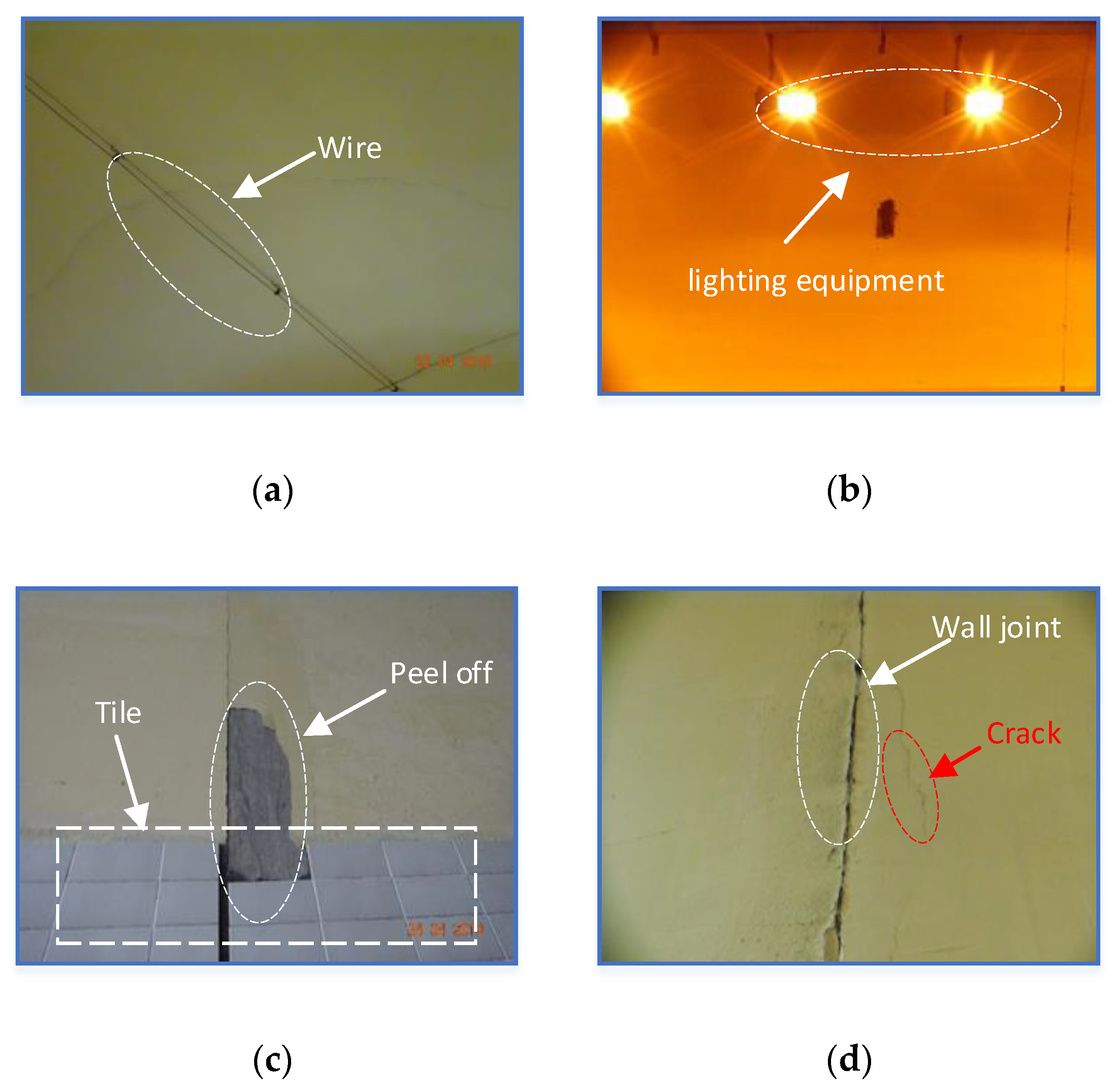
3.1. Image Acquisition Mechanism
3.2. Data Structure
3.3. Training Details
3.4. Performance Evaluation Indicators
4. Experimental Results
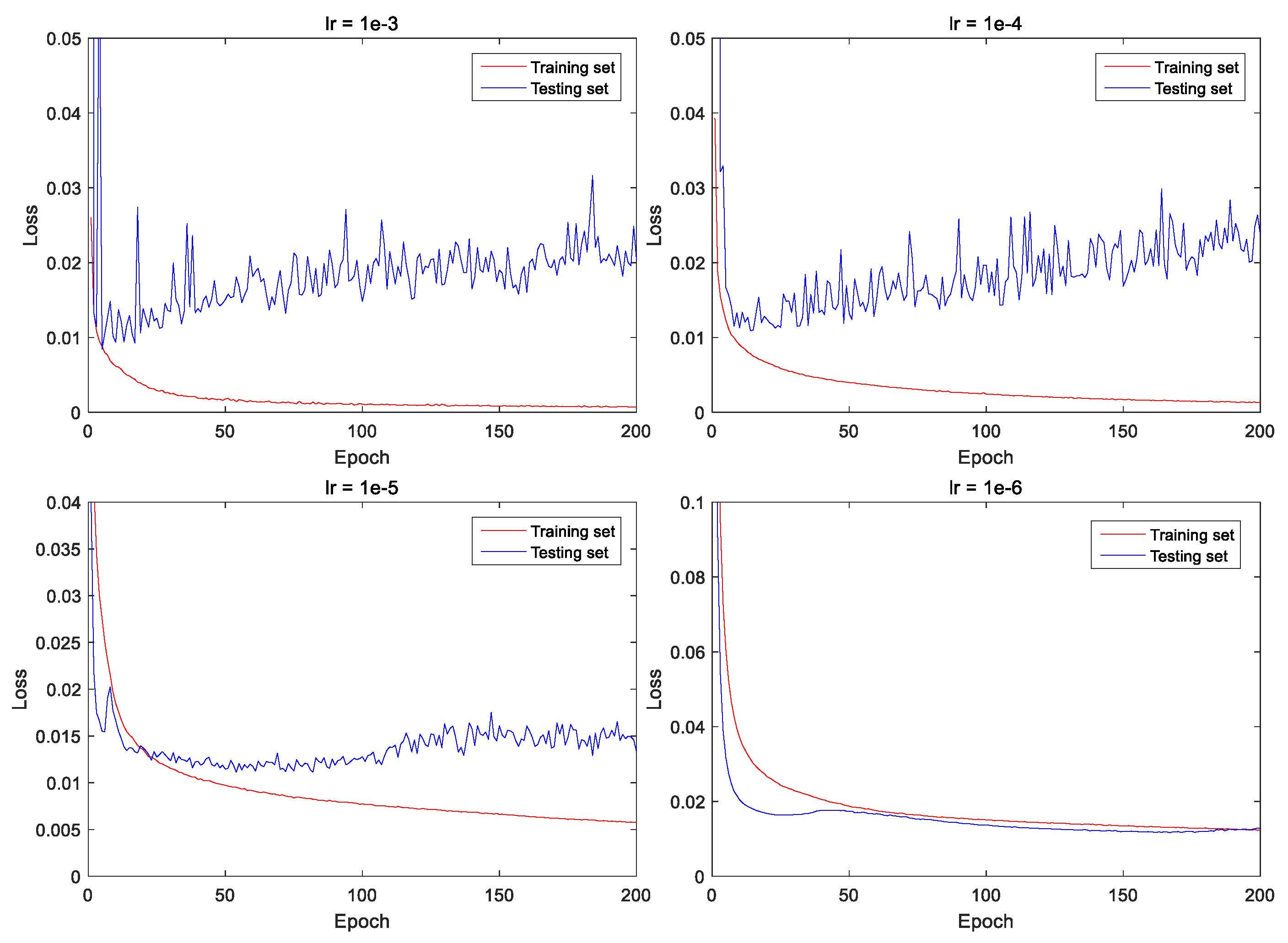
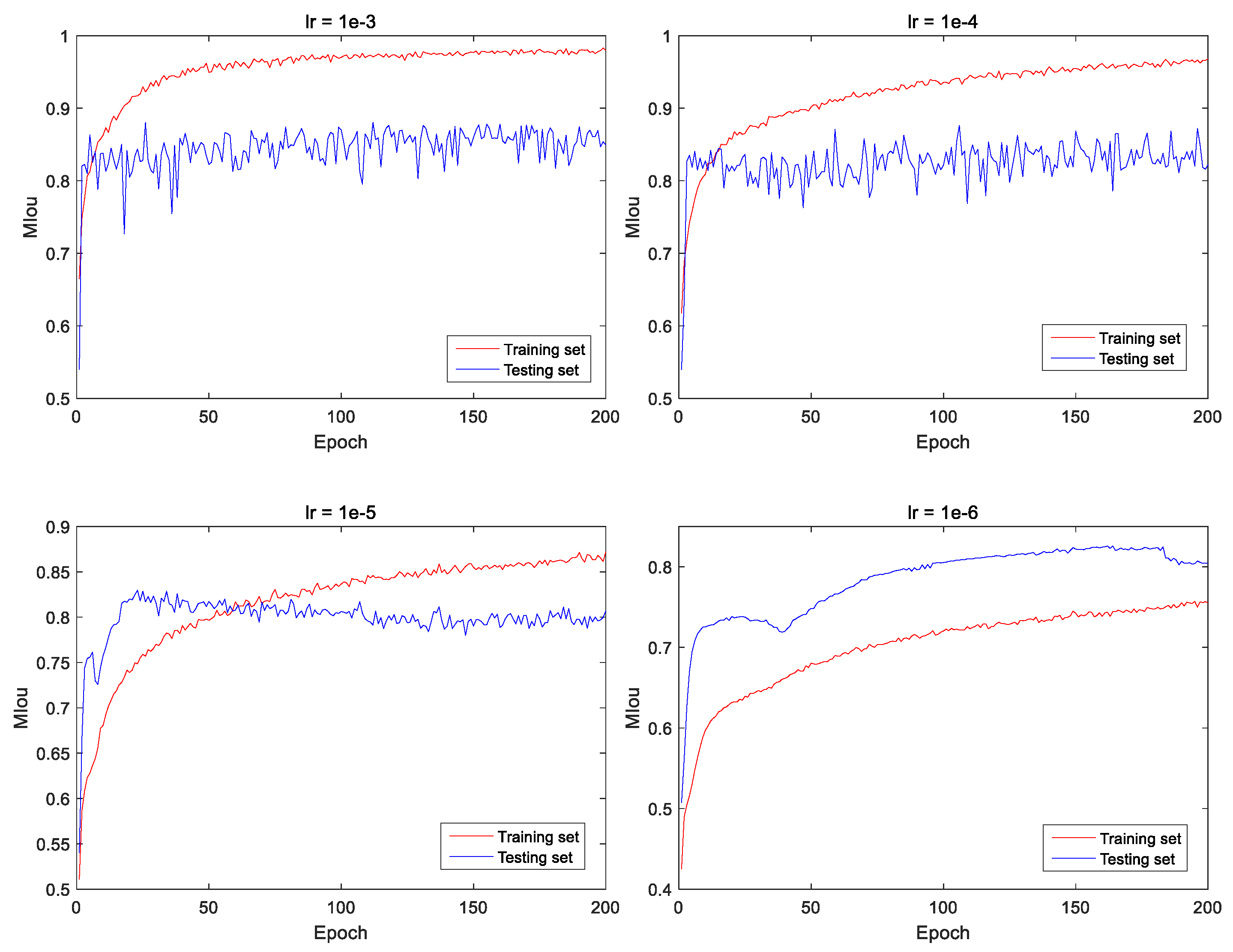
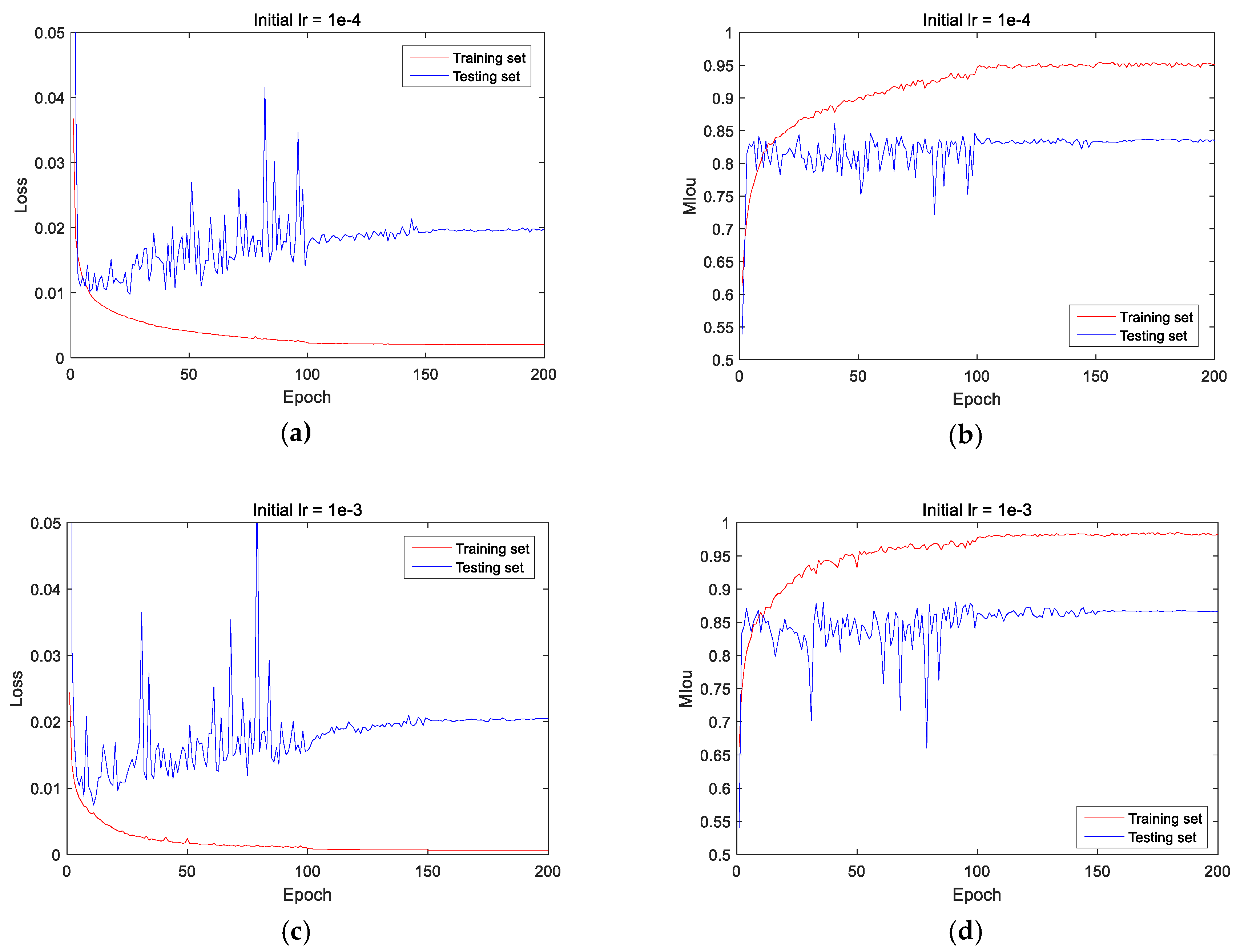
4.1. Selection of learning rate
4.2. Comparison of Prediction Results
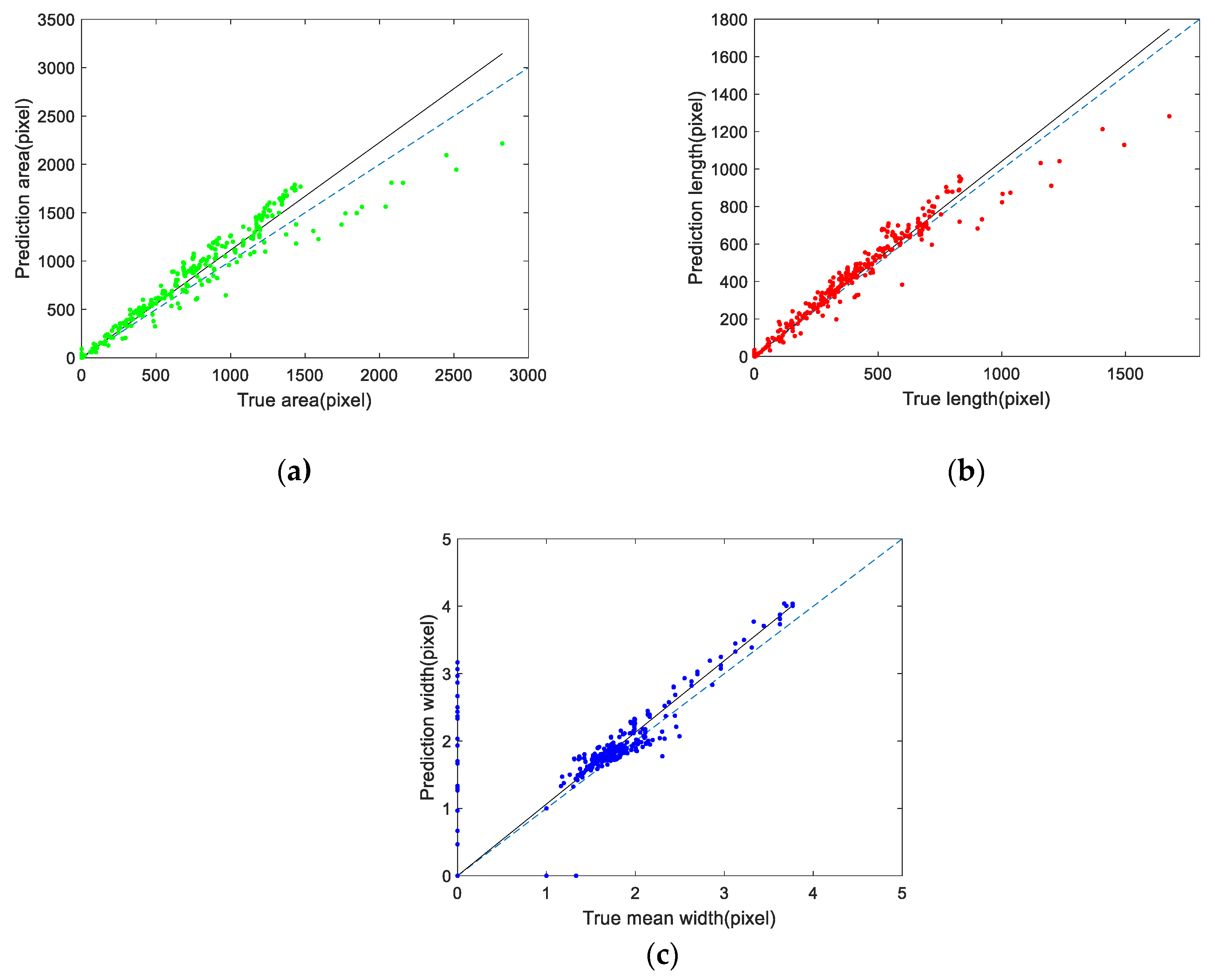
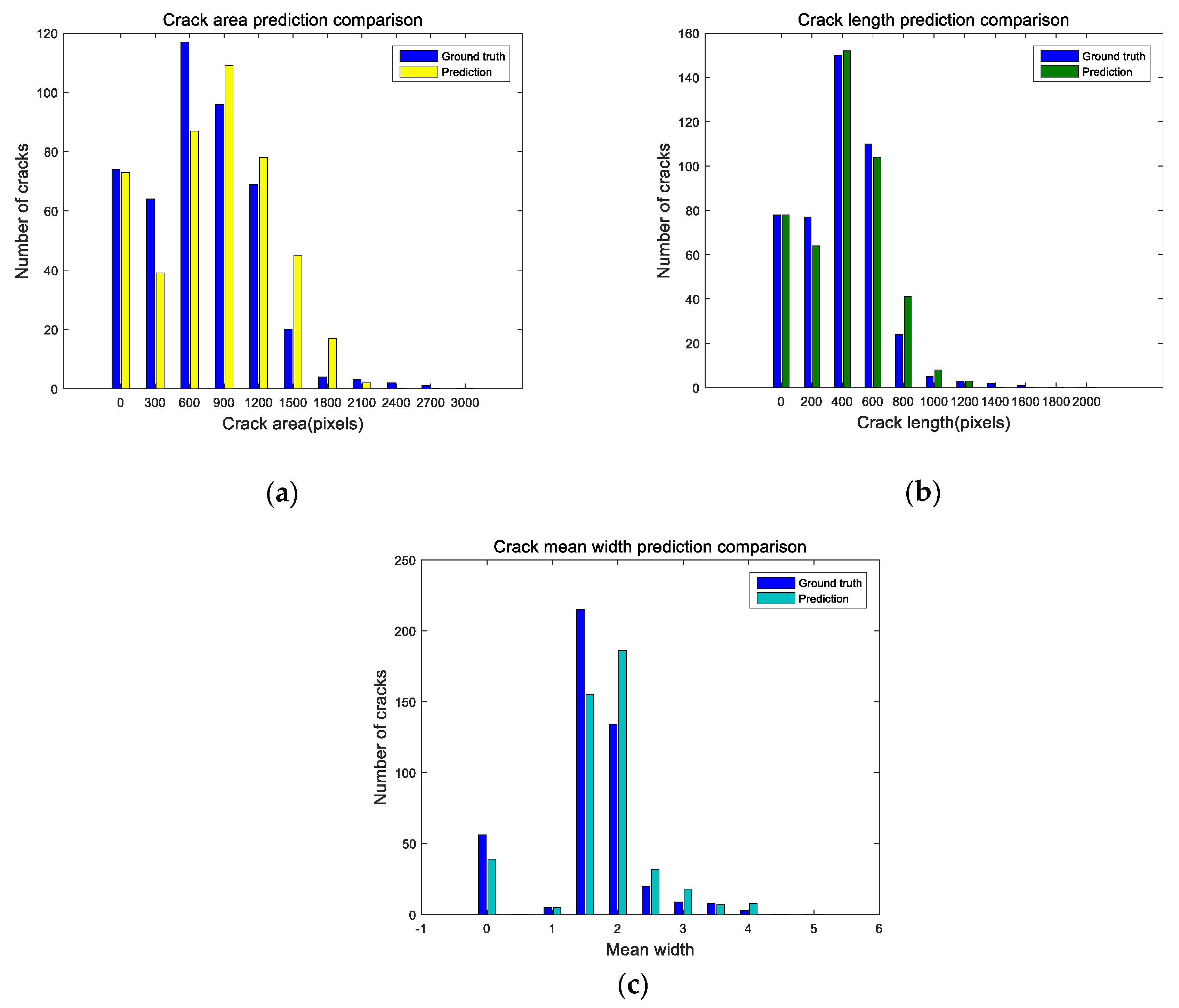
4.3. Crack Skeleton Extraction and Measurement
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ding, H.; Li, K.; Xiayang, Y.; Bi, J. Study on the Grade Evaluation of Highway Tunnel Cracks Based on PFC Simulation and BP Neural Network. Proceedings of GeoShanghai 2018 International Conference: Tunnelling and Underground Construction; Zhang, D., Huang, X., Eds.; Springer Singapore: Singapore, 2018; pp. 605–611. [Google Scholar]
- Yu, S.-N.; Jang, J.-H.; Han, C.-S. Auto inspection system using a mobile robot for detecting concrete cracks in a tunnel. Automat. Constr. 2007, 16, 255–261. [Google Scholar] [CrossRef]
- Lee, S.Y.; Lee, S.H.; Shin, D.I.; Son, Y.K.; Han, C.S. Development of an inspection system for cracks in a concrete tunnel lining. Can. J. Civ. Eng. 2007, 34, 966–975. [Google Scholar] [CrossRef]
- Montero, R.; Victores, J.G.; Martínez, S.; Jardón, A.; Balaguer, C. Past, present and future of robotic tunnel inspection. Automat. Constr. 2015, 59, 99–112. [Google Scholar] [CrossRef]
- Shen, B.; Zhang, W.-Y.; Qi, D.-P.; Wu, X.-Y. Wireless Multimedia Sensor Network Based Subway Tunnel Crack Detection Method. Int. J. Distrib. Sens. Netw. 2015, 11, 184639. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, Z.; Qi, D.; Liu, Y. Automatic Crack Detection and Classification Method for Subway Tunnel Safety Monitoring. Sensors 2014, 14, 19307–19328. [Google Scholar] [CrossRef]
- Ronny Salim, L.; La, H.M.; Zeyong, S.; Weihua, S. Developing a crack inspection robot for bridge maintenance. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 6288–6293. [Google Scholar]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly Michael, E. Analysis of Edge-Detection Techniques for Crack Identification in Bridges. J Comput Civil Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. Comparison of deep convolutional neural networks and edge detectors for image-based crack detection in concrete. Constr. Build. Mater. 2018, 186, 1031–1045. [Google Scholar] [CrossRef]
- Oliveira, H.; Correia, P.L. Automatic road crack segmentation using entropy and image dynamic thresholding. In Proceedings of the 17th European Signal Processing Conference, Glasgow, Scotland, 24–28 August 2009; pp. 622–626. [Google Scholar]
- Tang, J.; Gu, Y. Automatic Crack Detection and Segmentation Using a Hybrid Algorithm for Road Distress Analysis. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 3026–3030. [Google Scholar]
- Hu, Y.; Zhao, C.X. A Novel LBP Based Methods for Pavement Crack Detection. J. Pattern Recognit. Res. 2010, 5, 140–147. [Google Scholar] [CrossRef]
- Akagic, A.; Buza, E.; Omanovic, S.; Karabegovic, A. Pavement crack detection using Otsu thresholding for image segmentation. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018. [Google Scholar]
- Li, H.; Song, D.; Liu, Y.; Li, B. Automatic pavement crack detection by multi-scale image fusion. Ieee T Intell Transp 2018, 20, 2025–2036. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.P.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J.Q.; Chen, C. Automated Pixel-Level Pavement Crack Detection on 3D Asphalt Surfaces Using a Deep-Learning Network. Comput Aided Civ Inf. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.; Fei, Y.; Liu, Y.; Tao, S.; Chen, C.; Li, J.Q.; Li, B. Deep learning–based fully automated pavement crack detection on 3D asphalt surfaces with an improved CrackNet. J Comput Civil Eng. 2018, 32, 04018041. [Google Scholar] [CrossRef]
- Zhang, K.; Cheng, H.; Zhang, B. Unified approach to pavement crack and sealed crack detection using preclassification based on transfer learning. J Comput Civil Eng. 2018, 32, 04018001. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput Aided Civ inf. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Xu, Y.; Bao, Y.; Chen, J.; Zuo, W.; Li, H. Surface fatigue crack identification in steel box girder of bridges by a deep fusion convolutional neural network based on consumer-grade camera images. Struct. Health Monit. 2019, 18, 653–674. [Google Scholar] [CrossRef]
- Chen, F.-C.; Jahanshahi, M.R. NB-CNN: deep learning-based crack detection using convolutional neural network and Naïve Bayes data fusion. IEEE T Ind Electron. 2018, 65, 4392–4400. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image computing and computer-assisted intervention, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic pixel-level crack detection and measurement using fully convolutional network. Comput. Aided Civ. Inf. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Huang, H.-w.; Li, Q.-t.; Zhang, D.-m. Deep learning based image recognition for crack and leakage defects of metro shield tunnel. Tunn. Undergr. Space Technol. 2018, 77, 166–176. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Automat. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Yang, Y.; Zhong, Z.; Shen, T.; Lin, Z. Convolutional neural networks with alternately updated clique. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2413–2422. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th international conference on machine learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, Chia Laguna, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE international conference on computer vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1139–1147. [Google Scholar]
- Cotter, A.; Shamir, O.; Srebro, N.; Sridharan, K. Better mini-batch algorithms via accelerated gradient methods. In Proceedings of the 24th International Conference on Neural Information Processing Systems (NIPS’11), Red Hook, NY, USA, 12–17 December 2011; pp. 1647–1655. [Google Scholar]
- Bengio, Y. Practical recommendations for gradient-based training of deep architectures. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 437–478. [Google Scholar]
- Wager, S.; Wang, S.; Liang, P.S. Dropout training as adaptive regularization. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 351–359. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: a simple way to prevent neural networks from overfitting. J Mach Learn Res 2014, 15, 1929–1958. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Nhat-Duc, H.; Nguyen, Q.-L.; Tran, V.-D. Automatic recognition of asphalt pavement cracks using metaheuristic optimized edge detection algorithms and convolution neural network. Automat. Constr. 2018, 94, 203–213. [Google Scholar] [CrossRef]
- Bang, S.; Park, S.; Kim, H.; Kim, H. Encoder–decoder network for pixel-level road crack detection in black-box images. Comput. Aided Civ. Inf. 2019, 34, 713–727. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Block | Layers | Output Size | Operator | Height | Width | Depth | No. |
|---|---|---|---|---|---|---|---|
| Input | Input | - | - | - | - | - | |
| Conv1 | conv | 3 | 3 | 3 | 36 | ||
| CliqueBlock1 | conv | 3 | 3 | 36 | 36 | ||
| TD1 (transition down) | conv | 1 | 1 | 36 | 36 | ||
| avp | 2 | 2 | - | - | |||
| CliqueBlock2 | conv | 3 | 3 | 36 | 36 | ||
| TD2 | conv | 1 | 1 | 36 | 36 | ||
| avp | 2 | 2 | - | - | |||
| CliqueBlock3 | conv | 3 | 3 | 36 | 36 | ||
| TU1 | deconv | 3 | 3 | 36 | 36 | ||
| CliqueBlock4 | conv | 3 | 3 | 36 | 36 | ||
| TU2 | deconv | 3 | 3 | 36 | 36 | ||
| CliqueBlock5 | conv | 3 | 3 | 36 | 36 | ||
| Conv2 | conv | 1 | 1 | 36 | 2 | ||
| Output | - | - | - | - | - |
| Original Images | Ground Truth | Sub-Images |
|---|---|---|
 |  |  |
 |  |  |
| Ground Truth | Crack (True) | Noncrack (False) | |
|---|---|---|---|
| Prediction | |||
| Crack (positive) | TP (True positive) | FP (False positive) | |
| Noncrack (negative) | FN (False negative) | TN (True negative) | |
| Method | PA | MPA | MIoU (Mean Intersection over Union) | Precision | Recall | F1 |
|---|---|---|---|---|---|---|
| FCN | 0.9538 | 0.8825 | 0.8391 | 0.8269 | 0.7966 | 0.7854 |
| U-net | 0.9642 | 0.9059 | 0.8403 | 0.8457 | 0.8068 | 0.7967 |
| SegNet | 0.9385 | 0.8677 | 0.8050 | 0.7968 | 0.7495 | 0.7536 |
| MFCD | 0.9574 | 0.8850 | 0.7987 | 0.7937 | 0.8125 | 0.7808 |
| U-CliqueNet | 0.9661 | 0.9225 | 0.8696 | 0.8632 | 0.8028 | 0.8340 |
| Image | FCN | U-net | SegNet | MFCD | U-CliqueNet |
|---|---|---|---|---|---|
| 1.png | 0.838 | 0.799 | 0.816 | 0.772 | 0.861 |
| 2.png | 0.836 | 0.820 | 0.828 | 0.779 | 0.862 |
| 3.png | 0.763 | 0.754 | 0.711 | 0.696 | 0.765 |
| 4.png | 0.748 | 0.780 | 0.771 | 0.758 | 0.803 |
| 5.png | 0.819 | 0.758 | 0.775 | 0.761 | 0.813 |
| 6.png | 0.717 | 0.778 | 0.702 | 0.744 | 0.773 |
| 7.png | 0.802 | 0.795 | 0.798 | 0.767 | 0.847 |
| 8.png | 0.834 | 0.799 | 0.808 | 0.775 | 0.856 |
| 9.png | 0.843 | 0.821 | 0.792 | 0.797 | 0.870 |
| 10.png | 0.892 | 0.890 | 0.838 | 0.790 | 0.885 |
| 11.png | 0.832 | 0.909 | 0.836 | 0.813 | 0.901 |
| 12.png | 0.863 | 0.865 | 0.890 | 0.791 | 0.890 |
| 13.png | 0.909 | 0.903 | 0.953 | 0.863 | 0.943 |
| 14.png | 0.919 | 0.900 | 0.871 | 0.947 | 0.949 |
| 15.png | 0.910 | 0.914 | 0.877 | 0.855 | 0.953 |
| 16.png | 0.900 | 0.942 | 0.921 | 0.896 | 0.964 |
| 17.png | 0.867 | 0.820 | 0.790 | 0.783 | 0.866 |
| 18.png | 0.798 | 0.759 | 0.747 | 0.763 | 0.817 |
| 19.png | 0.813 | 0.836 | 0.820 | 0.862 | 0.853 |
| 20.png | 0.777 | 0.851 | 0.777 | 0.762 | 0.841 |
| average | 0.834 | 0.835 | 0.816 | 0.799 | 0.866 |
| variance | 0.00305 | 0.00361 | 0.00393 | 0.00328 | 0.00306 |
| Sub-images | Ground Truth | U-Clique Net | FCN | U-Net | |
|---|---|---|---|---|---|
| Crack with handwriting |  |  |  |  |  |
| Crack with wire |  |  |  |  |  |
| Crack with spots |  |  |  |  |  |
| Crack with wall joint |  |  |  |  |  |
| Crack near the light |  |  |  |  |  |
| Ground Truth Masks | Ground Truth Skeleton | Prediction Masks | Prediction Skeleton | |
|---|---|---|---|---|
| Transverse crack |  |  |  |  |
| Diagonal crack |  |  |  |  |
| Reticular crack |  |  |  |  |
| Diagonal crack |  |  |  |  |
| Transverse crack |  |  |  |  |
| Area | Length | Mean Width | |
|---|---|---|---|
| slope | 1.11 | 1.04 | 1.06 |
| confidence intervals | [1.097, 1.130] | [1.029, 1.055] | [1.036, 1.092] |
| statistic | 0.922 | 0.943 | 0.706 |
| F-statistic | 100 | 743 | 531 |
| p-value | <0.001 | <0.001 | <0.001 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, G.; Ma, B.; He, S.; Ren, X.; Liu, Q. Automatic Tunnel Crack Detection Based on U-Net and a Convolutional Neural Network with Alternately Updated Clique. Sensors 2020, 20, 717. https://doi.org/10.3390/s20030717
Li G, Ma B, He S, Ren X, Liu Q. Automatic Tunnel Crack Detection Based on U-Net and a Convolutional Neural Network with Alternately Updated Clique. Sensors. 2020; 20(3):717. https://doi.org/10.3390/s20030717
Chicago/Turabian StyleLi, Gang, Biao Ma, Shuanhai He, Xueli Ren, and Qiangwei Liu. 2020. "Automatic Tunnel Crack Detection Based on U-Net and a Convolutional Neural Network with Alternately Updated Clique" Sensors 20, no. 3: 717. https://doi.org/10.3390/s20030717
APA StyleLi, G., Ma, B., He, S., Ren, X., & Liu, Q. (2020). Automatic Tunnel Crack Detection Based on U-Net and a Convolutional Neural Network with Alternately Updated Clique. Sensors, 20(3), 717. https://doi.org/10.3390/s20030717