Depth Image–Based Deep Learning of Grasp Planning for Textureless Planar-Faced Objects in Vision-Guided Robotic Bin-Picking

 , , ,
, , ,
Abstract
1. Introduction
- We propose a framework for automatically generating a training dataset in consideration of the grasp pattern for planar-faced object picking in Gazebo [39], which is more efficient and convenient than manual collection.
- We propose a DCNN model to simultaneously predict grasp point positions and their corresponding grasp patterns (vacuum-cup activation modes) for a two-vacuum-cup suction hand.
- We incorporate surface-feature descriptors for DCNN prediction refinement and feature extraction, allowing the system to be free of sim-to-real refinement for DCNN predictions, as well as texture features and goal images for VS.
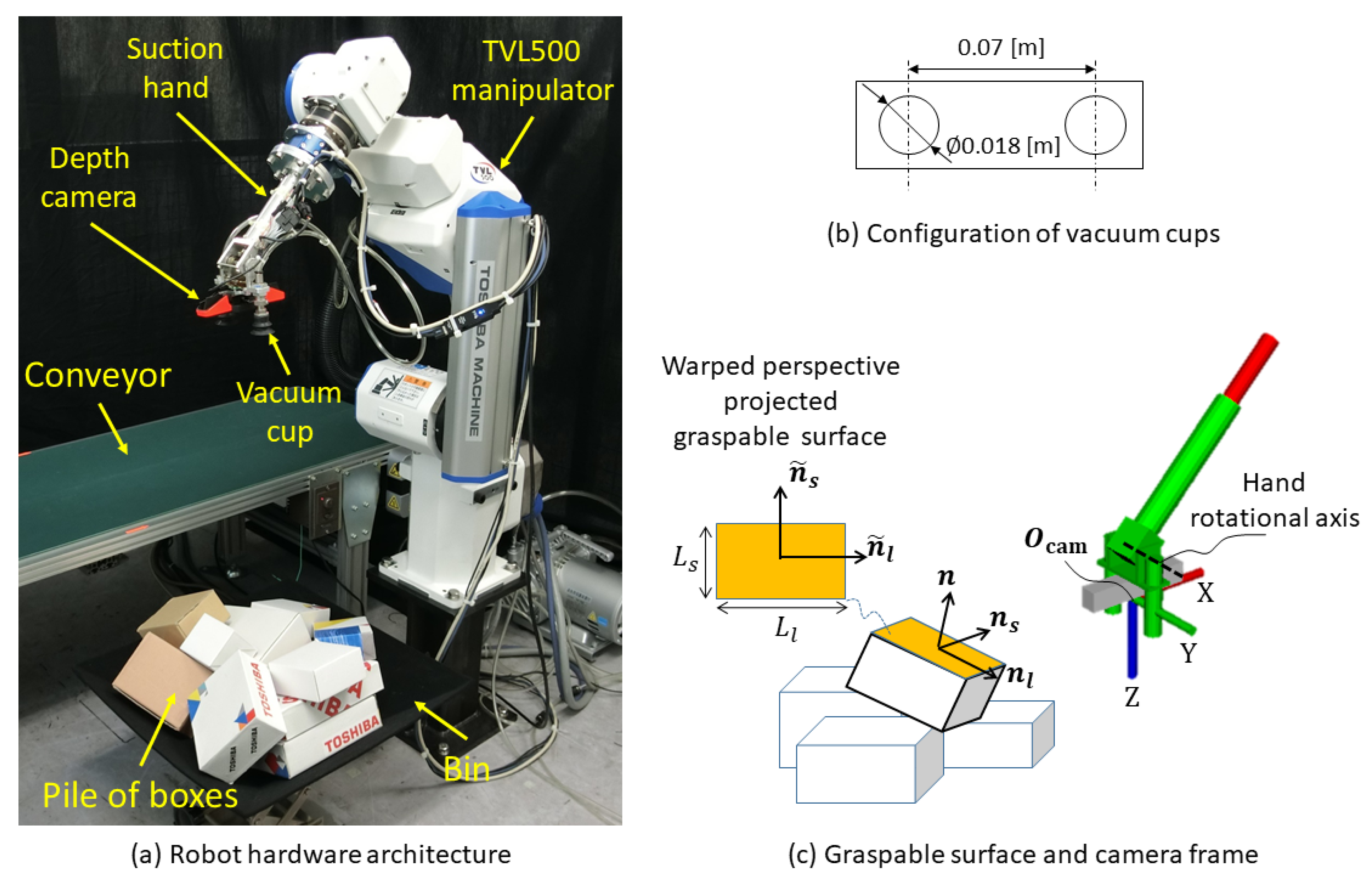
2. Picking Robot
3. Vision-Guided Robot Bin-Picking System
4. Learning-Based Grasp Planning for Textureless Planar-Faced Objects
4.1. DCNN Model
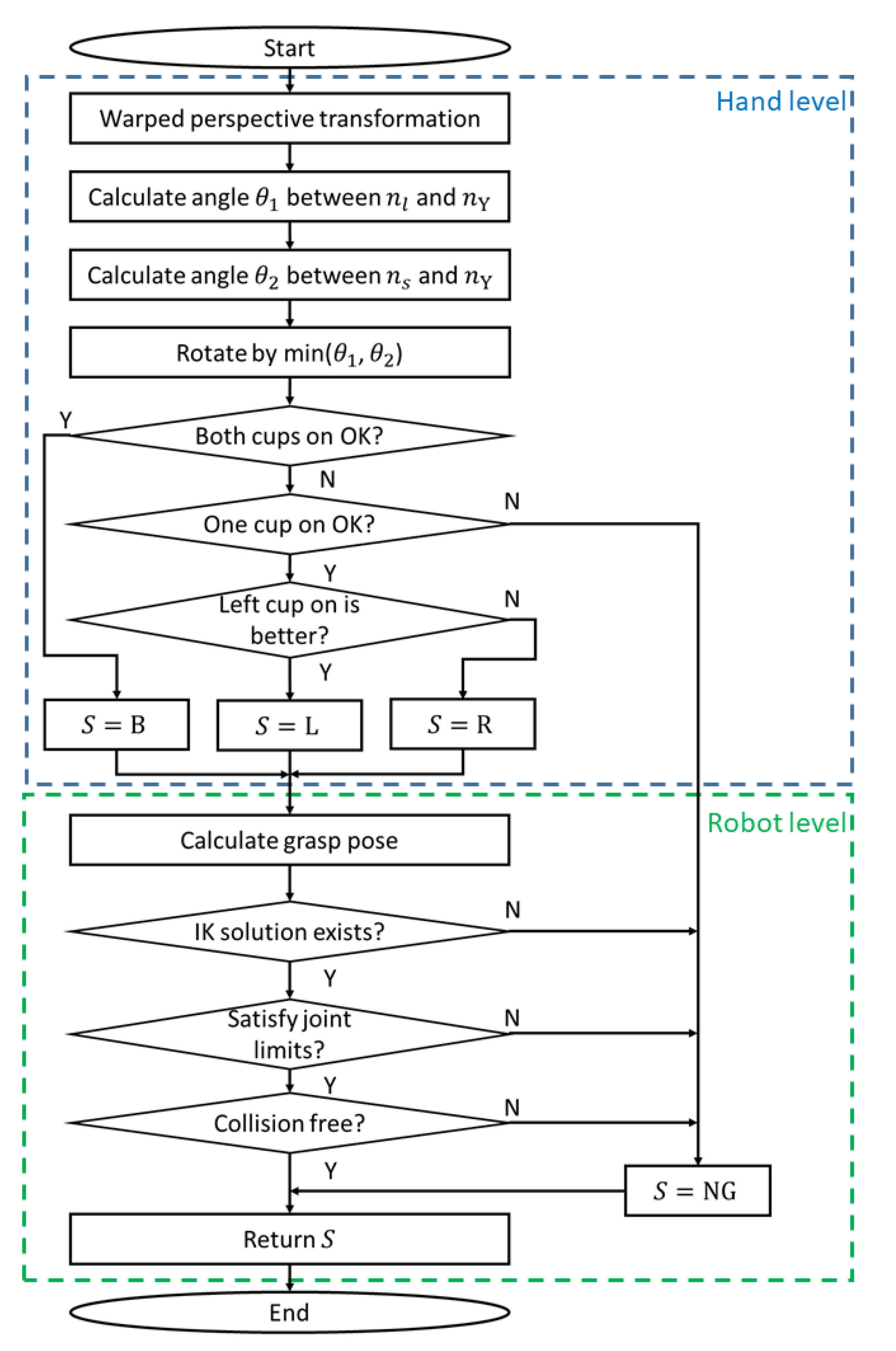
4.2. Grasp Point Score Ranking
4.3. Automatic Training Dataset Collection
5. Visual-Guided Robot Control
5.1. Surface Feature Descriptor
5.2. 2.5D Visual Servoing
6. Experiment
7. Results
8. Discussion
8.1. Comparison with Previously Proposed Bin-Picking Systems
8.1.1. Grasp Planning Performance
8.1.2. Overall System Efficiency
8.2. Benefits of Bin-Picking Policies Considering Grasp Pattern Prediction
8.3. Benefits of Depth-Image-Based Visual-Guided Bin-Picking System
8.4. Grasp Failure Analysis
8.5. Limitations and Future Work
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Yamaguchi, T. Japan’s robotic future. Crit. Asian Stud. 2019, 51, 134–140. [Google Scholar] [CrossRef]
- Janabi-Sharifi, F. Visual Servoing: Theory and applications. In Opto-Mechatronic Systems Handbook; Cho, H., Ed.; CRC: Boca Raton, FL, USA, 2002; pp. 15-1–15-24. [Google Scholar]
- Wilson, W.J.; Hulls, C.W.; Bell, G.S. Relative end-effector control using cartesian position based visual servoing. IEEE Trans. Robot. Autom. 1996, 12, 684–696. [Google Scholar] [CrossRef]
- Thuilot, B.; Martinet, P.; Cordesses, L.; Gallice, J. Position based visual servoing: Keeping the object in the field of vision. In Proceedings of the 2002 IEEE International Conference on Robotics and Automation (Cat. No. 02CH37292), Washington, DC, USA, 11–15 May 2002; Volume 2, pp. 1624–1629. [Google Scholar]
- Malis, E.; Chaumette, F.; Boudet, S. 2 1/2 D visual servoing. IEEE Trans. Robot. Autom. 1999, 15, 238–250. [Google Scholar] [CrossRef]
- Malis, E.; Chaumette, F. 2 1/2 D visual servoing with respect to unknown objects through a new estimation scheme of camera displacement. Int. J. Comput. Vis. 2000, 37, 79–97. [Google Scholar] [CrossRef]
- Malis, E.; Chaumette, F. Theoretical improvements in the stability analysis of a new class of model-free visual servoing methods. IEEE Trans. Robot. Autom. 2002, 18, 176–186. [Google Scholar] [CrossRef]
- Horaud, R.; Dornaika, F.; Espiau, B. Visually guided object grasping. IEEE Trans. Robot. Autom. 1998, 14, 525–532. [Google Scholar] [CrossRef]
- Mahler, J.; Goldberg, K. Learning deep policies for robot bin picking by simulating robust grasping sequences. Proc. Mach. Learn. Res. 2017, 78, 515–524. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Suga, A.; Fukuda, K.; Takiguchi, T.; Ariki, Y. Object recognition and segmentation using SIFT and Graph Cuts. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: better, faster, stronger. arXiv 2017, arXiv:1612.08242. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Chen, B. PointCNN. arXiv 2018, arXiv:1801.07791. [Google Scholar]
- Zhikai, D.; Sicheng, L.; Tao, Z.; Hui, C.; Long, Z.; Xingyao, Y.; Houde, L. PPR-Net:Point-wise Pose Regression Network for Instance Segmentation and 6D Pose Estimation in Bin-picking Scenarios. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 1773–1780. [Google Scholar]
- Drost, B.; Ulrich, M.; Navab, N.; Ilic, S. Model globally, match locally: Efficient and robust 3D object recognition. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 998–1005. [Google Scholar]
- Kruglyak, L.; Lander, E.S. Complete multipoint sib-pair analysis of qualitative and quantitative traits. Am. J. Hum. Genet. 1995, 57, 439. [Google Scholar] [PubMed]
- Vidal, J.; Lin, C.Y.; Martí, R. 6D pose estimation using an improved method based on point pair features. In Proceedings of the 2018 4th International Conference on Control, Automation and Robotics (ICCAR), Auckland, New Zealand, 20–23 April 2018; pp. 405–409. [Google Scholar]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes. arXiv 2017, arXiv:1711.00199. [Google Scholar]
- Sock, J.; Kim, K.I.; Sahin, C.; Kim, T.K. Multi-task deep networks for depth-based 6D object pose and joint registration in crowd scenarios. arXiv 2018, arXiv:1806.03891. [Google Scholar]
- Zeng, A.; Yu, K.T.; Song, S.; Suo, D.; Walker, E.; Rodriguez, A.; Xiao, J. Multi-view self-supervised deep learning for 6d pose estimation in the amazon picking challenge. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar]
- Sahbani, A.; El-Khoury, S.; Bidaud, P. An overview of 3D object grasp synthesis algorithms. Robot. Auton. Syst. 2012, 60, 326–336. [Google Scholar] [CrossRef]
- Bicchi, A.; Kumar, V. Robotic grasping and contact: A review. In Proceedings of the 2000 IEEE International Conference on Robotics and Automation (Cat. No. 00CH37065), San Francisco, CA, USA, 24–28 April 2000; Volume 1, pp. 348–353. [Google Scholar]
- Caldera, S.; Rassau, A.; Chai, D. Review of Deep Learning Methods in Robotic Grasp Detection. Multimodal Technol. Interact. 2018, 2, 57. [Google Scholar] [CrossRef]
- Kumra, S.; Kanan, C. Robotic grasp detection using deep convolutional neural networks. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 769–776. [Google Scholar]
- Levine, S.; Pastor, P.; Krizhevsky, A.; Ibarz, J.; Quillen, D. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. Int. J. Robot. Res. 2018, 37, 421–436. [Google Scholar] [CrossRef]
- Tobin, J.; Biewald, L.; Duan, R.; Andrychowicz, M.; Handa, A.; Kumar, V.; McGrew, B.; Ray, A.; Schneider, J.; Welinder, P.; et al. Domain randomization and generative models for robotic grasping. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 3482–3489. [Google Scholar]
- Bousmalis, K.; Irpan, A.; Wohlhart, P.; Bai, Y.; Kelcey, M.; Kalakrishnan, M.; Downs, L.; Ibarz, J.; Pastor, P.; Konolige, K.; et al. Using simulation and domain adaptation to improve efficiency of deep robotic grasping. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 4243–4250. [Google Scholar]
- Mahler, J.; Liang, J.; Niyaz, S.; Laskey, M.; Doan, R.; Liu, X.; Ojea, J.A.; Goldberg, K. Dex-net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics. arXiv 2017, arXiv:1703.09312. [Google Scholar]
- Mahler, J.; Matl, M.; Liu, X.; Li, A.; Gealy, D.; Goldberg, K. Dex-Net 3.0: Computing robust vacuum suction grasp targets in point clouds using a new analytic model and deep learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 1–8. [Google Scholar]
- Gariépy, A.; Ruel, J.C.; Chaib-draa, B.; Giguère, P. GQ-STN: Optimizing One-Shot Grasp Detection based on Robustness Classifier. arXiv 2019, arXiv:1903.02489. [Google Scholar]
- Viereck, U.; Pas, A.t.; Saenko, K.; Platt, R. Learning a visuomotor controller for real world robotic grasping using simulated depth images. arXiv 2017, arXiv:1706.04652. [Google Scholar]
- Morrison, D.; Corke, P.; Leitner, J. Closing the loop for robotic grasping: A real-time, generative grasp synthesis approach. arXiv 2018, arXiv:1804.05172. [Google Scholar]
- Zeng, A.; Song, S.; Yu, K.T.; Donlon, E.; Hogan, F.R.; Bauza, M.; Ma, D.; Taylor, O.; Liu, M.; Romo, E.; et al. Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 1–8. [Google Scholar]
- Johns, E.; Leutenegger, S.; Davison, A.J. Deep learning a grasp function for grasping under gripper pose uncertainty. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, South Korea, 9–14 October 2016; pp. 4461–4468. [Google Scholar]
- Koenig, N.P.; Howard, A. Design and use paradigms for Gazebo, an open-source multi-robot simulator. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No.04CH37566), Sendai, Japan, 28 September–2 October 2004; Volume 3, pp. 2149–2154. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, CA, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Rusu, R.B.; Cousins, S. 3D is here: Point cloud library (pcl). In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar]
- Yang, M.Y.; Förstner, W. Plane detection in point cloud data. In Proceedings of the 2nd International Conference on Machine Control Guidance, Bonn, Germany, 9–11 Mar 2010; Volume 1, pp. 95–104. [Google Scholar]
- Zhang, Z.; Huang, Y.; Zhang, W.; Luo, J. Comparisons of planar detection for service robot with RANSAC and region growing algorithm. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 11092–11097. [Google Scholar]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the ICRA Workshop on Open Source Software, Kobe, Japan, 12–17 May 2009; Volume 3, p. 5. [Google Scholar]
- Mahler, J.; Matl, M.; Satish, V.; Danielczuk, M.; DeRose, B.; McKinley, S.; Goldberg, K. Learning ambidextrous robot grasping policies. Sci. Robot. 2019, 4, eaau4984. [Google Scholar] [CrossRef]
- Zeng, A.; Song, S.; Yu, K.T.; Donlon, E.; Hogan, F.R.; Bauza, M.; Ma, D.; Taylor, O.; Liu, M.; Romo, E.; et al. Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching. Int. J. Robot. Res. 2019. [Google Scholar] [CrossRef]
- Tuan-Tang, L.; Chyi-Yeu, L. Bin-Picking for Planar Objects Based on a Deep Learning Network: A Case Study of USB Packs. Sensors 2019, 19, 3602. [Google Scholar]
- Talmi, I.; Mechrez, R.; Zelnik-Manor, L. Template matching with deformable diversity similarity. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 175–183. [Google Scholar]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Prakash, A.; Kohno, T.; Song, D. Robust physical-world attacks on deep learning models. arXiv 2017, arXiv:1707.08945. [Google Scholar]
- Zhang, F.; Leitner, J.; Ge, Z.; Milford, M.; Corke, P. Adversarial discriminative sim-to-real transfer of visuo-motor policies. Int. J. Robot. Res. 2019, 38, 1229–1245. [Google Scholar] [CrossRef]
- Du, G.; Zhang, P.; Li, D. Human–manipulator interface based on multisensory process via Kalman filters. IEEE Trans. Ind. Electron. 2014, 61, 5411–5418. [Google Scholar]
- Du, G.; Zhang, P. A markerless human–robot interface using particle filter and Kalman filter for dual robots. IEEE Trans. Ind. Electron. 2014, 62, 2257–2264. [Google Scholar] [CrossRef]
- Du, G.; Zhang, P.; Liu, X. Markerless human–manipulator interface using leap motion with interval Kalman filter and improved particle filter. IEEE Trans. Ind. Electron. 2016, 12, 694–704. [Google Scholar] [CrossRef]
- Cui, R.; Chen, L.; Yang, C.; Chen, M. Extended state observer-based integral sliding mode control for an underwater robot with unknown disturbances and uncertain nonlinearities. IEEE Trans. Ind. Electron. 2017, 64, 6785–6795. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Top 1 | Top 1% | Top 5% | Top 10% |
|---|---|---|---|
| Dex-Net 4.0 | Ours |
|---|---|
| System | Object Set | Robotic Hand | Input | Success Rate (%) | grasp Planning Time Cost (s) | Mean Piece per Hour (PPH) |
|---|---|---|---|---|---|---|
| Dex-Net 3.0 [33] | Prismatic solids | Suction (1 cup) | Depth | 98 | About 3.0 | - |
| Dex-Net 4.0 [46] | Level 1 objects | Suction (1 cup) + gripper (2 fingers) | Depth | 97 * | - | Over 300 |
| Zeng et al. [47] | APC dataset | Suction (1 cup) + gripper (2 fingers) | RGB + depth | 58.3 | 0.06 | - |
| Le et al. [48] | USB flash drive packs | Suction (1 cup) | RGB + point cloud | 99.6 | 0.862 | - |
| Ours | Boxes | Suction (2 cups) | Depth | 97.5 | 0.034 | Over 1000 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, P.; Ishihara, Y.; Sugiyama, N.; Oaki, J.; Tokura, S.; Sugahara, A.; Ogawa, A. Depth Image–Based Deep Learning of Grasp Planning for Textureless Planar-Faced Objects in Vision-Guided Robotic Bin-Picking. Sensors 2020, 20, 706. https://doi.org/10.3390/s20030706
Jiang P, Ishihara Y, Sugiyama N, Oaki J, Tokura S, Sugahara A, Ogawa A. Depth Image–Based Deep Learning of Grasp Planning for Textureless Planar-Faced Objects in Vision-Guided Robotic Bin-Picking. Sensors. 2020; 20(3):706. https://doi.org/10.3390/s20030706
Chicago/Turabian StyleJiang, Ping, Yoshiyuki Ishihara, Nobukatsu Sugiyama, Junji Oaki, Seiji Tokura, Atsushi Sugahara, and Akihito Ogawa. 2020. "Depth Image–Based Deep Learning of Grasp Planning for Textureless Planar-Faced Objects in Vision-Guided Robotic Bin-Picking" Sensors 20, no. 3: 706. https://doi.org/10.3390/s20030706
APA StyleJiang, P., Ishihara, Y., Sugiyama, N., Oaki, J., Tokura, S., Sugahara, A., & Ogawa, A. (2020). Depth Image–Based Deep Learning of Grasp Planning for Textureless Planar-Faced Objects in Vision-Guided Robotic Bin-Picking. Sensors, 20(3), 706. https://doi.org/10.3390/s20030706