1. Introduction
The practical application of binocular stereo vision (BSV) rig in the market of unmanned vehicles and mobile robots as sensing equipment has been greatly challenged [
1,
2]. There is still room for further improvement in the practicability and durability of the BSV rig. The lack of practicality is mainly reflected in its structural form. The positions of two cameras for most existing BSV rigs are relatively fixed, which means the operators can hardly adjust the baseline. This form makes it difficult for binocular vision to be installed in different sized spaces and cannot satisfy the measurement and sensing range requirements when the robot faces different scale scenes. The drawback of durability is mainly reflected in the fact that BSV rig is often deformed due to temperature, vibration, etc., resulting in changes in the parameters calibrated at the factory. For example, to keep the calibration parameters from deviations, the structure of the rig is usually made of special materials and needs to be firmly connected with robots or cars. As a result, the university research team, autopilot company, and automotive aftermarket industry have to recalibrate the BSV rig frequently for the result accuracy. It is well known that calibration and recalibration of the rig have always been a burden for each user, which requires expertise, specialized equipment and many hours of work [
3]. Consequently, it is necessary to study an automatic, robust, real-time calibration algorithm without prior information of the environment, human supervision and auxiliary equipment.
With the popular application of BSV rig in computer vision [
4], many methods have been proposed to calibrate them. Most existing calibration methods are based on manual off-line calibration algorithms for specific reference targets or patterns, such as the traditional calibration methods, planar template methods [
5], 3D-object-based calibration methods [
6]. Typical algorithms of traditional calibration methods include the direct linear transformation algorithm (DLT) [
7], the nonlinear optimization algorithm [
8], and the Tsai’s radial alignment constraint algorithm (RAC) [
9]. Deng et al. [
10] proposed a relational model for camera calibration, which takes into account the camera’s geometric parameters and lens distortion effects. The combination of differential evolution and particle swarm optimization algorithm can effectively calibrate camera parameters. Batista et al. [
11] used monoplane calibration points to achieve camera calibration. To avoid the singularity obtained by the calibration equation when using monoplane calibration points, a multi-step procedure combined with a nonlinear optimization iterative process is used to solve these parameters and improve the precision. Zhuang et al. [
12] used an RAC method to calibrate the camera through a 2D planar calibration plate parallel to the camera plane. This method combines the advantages of traditional linear and non-linear optimization algorithms to simplify the parameter solving process, so the calibration results are relatively accurate. The traditional calibration method can accurately calibrate the camera parameters utilizing precisely fabricated planar or stereo targets [
13]. However, the calibration algorithms and procedures are complex and time-consuming, so they are suitable for where camera parameters are not changed often.
To avoid the shortcomings of traditional methods, the planar template method has been extensively studied. Zhang [
14] proposed to calibrate the camera with a checkerboard, which is widely used. The camera is required to view the displayed checkerboard pattern in several different directions. Yu et al. [
15] proposed a robust recognition method of checkerboard pattern detection for camera calibration, which is based on Zhang’s method. Chen et al. [
16] described a novel camera calibration method that used only a single image of two coplanar circles with arbitrary radii to estimate the camera’s extrinsic parameters and focal length. Kumar et al. [
17] proposed a technique for camera calibration using a planar mirror. By allowing all cameras to see multiple fields of view through the mirror, it is possible to overcome the need for all cameras to see a common calibration object directly.
The 3D target-based method makes the calibration procedure more simplified by placing the target in the camera field of view once to obtain calibration parameters. Su et al. [
18] used a spherical calibration object as a specialized reference pattern to calibrates the geometric parameters between any number of cameras on the network. Zhen et al. [
19] proposed a method for calibrating extrinsic parameters of BSV rig based on double-ball targets. A target consisting of two identical spheres fixed at a known distance is freely placed in different positions and orientations. With the aid of markers, the calibration precision is high, and the calibration process is simpler, but the calibration method is still not flexible enough. Since it is difficult to machine 3D targets and keep the calibration images of all feature points at the same sharpness, therefore, their practical application is limited.
Unlike the above-mentioned calibration methods, the self-calibration method only requires a constraint from the image sequence without any special reference objects or patterns designed in advance, which may allow online calibration of camera parameters in real-time. Luong et al. [
20] proposed earlier to calibrate the extrinsic parameters of BSV rig by point-matching methods in general unknown situations. Using the SIFT [
21] feature point correspondence and bundle adjustment (BA) algorithm, Tang et al. [
22] proposed a local-global hybrid iterative optimization method for calibration of BSV rig. Wang et al. [
23] proposed a self-calibration method using sea surface images, which can estimate the rotation matrix of a BSV rig with a wide baseline. Boudine et al. [
24] proposed a self-calibration technology for BSV rig with variable intrinsic parameters, which is based on the relationship between two matching terms (i.e., the projection of two points representing the vertices of the triangle isosceles rectangular triangle) and the absolute cone image. Ji et al. [
25] introduced a calibration model for the multiple fisheye camera rig which combines a generic polynomial and an equidistance projection model to achieve high-accuracy calibration from the fisheye camera to an equivalent ideal frame camera. Wang et al. [
26] proposed a self-calibration method that uses a single feature point and converts the pitch and yaw imaging model into a quadratic equation of the pitch tangent value. However, the calibration process for the above work still requires complex user intervention. Some methods require the user to manually specify the point correspondence between the two camera views of BSV rig, which seems inconvenient in practice.
So far, we have found the work of Carrera et al. [
27] is closer to ours. They used the improved monocular vision Mono-SLAM algorithm to process the video sequence of each camera separately, then robustly match and fuse the maps obtained by each camera based on the corresponding SURF [
28] features. Finally, the extrinsic parameters between multiple cameras can be calibrated through matching the global map with the SURF features extracted from cameras. However, this method does not provide real-scale information on the surrounding environment, and its calibration accuracy and efficiency have yet to be further verified. Heng et al. [
29] also used the visual SLAM-based self-calibration method to calibrate the BSV rig extrinsic parameters fixed on the aircraft and provide the scale information through the three-axis gyroscope. Heng et al. [
30] further applied a similar idea and method to the calibration of the BSV rig mounted on car platforms and provided the scale information through the odometer to make the algorithm applicable to large scenes. However, the calibration efficiency of this method limits its practical application.
Based on the summary analysis of related research fields, there are still some problems in the calibration work of the BSV rig. The calibration process employing the auxiliary device is complicated and inconvenient for the users to personally operate. The self-calibration method is still in the research and exploration stage, and its calibration efficiency and accuracy have yet to be further verified. To the best of our knowledge, there is no existing self-calibration method that can be practically applied to the calibration of BSV rig in a wide range and achieve commercial value.
In this paper, we propose a novel SLAM-based self-calibration method for the BSV rig. The purpose is to achieve real-time, automatic and accurate calibration of the BSV rig’s extrinsic parameters in a short period. The intrinsic parameters of the left and right cameras are estimated in advance using Zhang’s method. And as far as possible, this calibration method can be used for large-scale practical applications on arbitrary BSV rigs, such as a car or mobile robot.
The main contributions of our work are reflected in the following aspects:
1. Our proposed SLAM-based self-calibration method can estimate the extrinsic parameters of the BSV rig without auxiliary equipment and special calibration markers.
2. Once the baseline is determined, a fully automatic calibration process can be implemented in real-time during the normal driving of the platform, without complex requirements for rig movement and prior information about the environment.
3. In the experimental part, the proposed self-calibration method was applied to the mobile platform where the BSV module is installed. Our method can accurately calibrate the BSV rig in a short period. As far as we know, there are few existing methods to perform the self-calibration of BSV rig in such high efficiency, thereby achieving the effect of practical application.
The rest of the paper is organized as follows:
Section 2 describes our SLAM-based self-calibration pipeline.
Section 3 discusses the SLAM-based construction pipeline of a 3D scene point map that used to generate a calibration area map.
Section 4 introduces the extrinsic parameter calibration algorithm of BSV rig.
Section 5 explains the experimental setup and verification results. Conclusions and future work are presented in
Section 6.
2. SLAM-Based Self-Calibration Pipeline
This section describes our SLAM-based self-calibration pipeline as a whole, which can estimate the extrinsic parameters of the BSV rig. Here, the main contents of the pipeline are briefly summarized and described in the following sections.
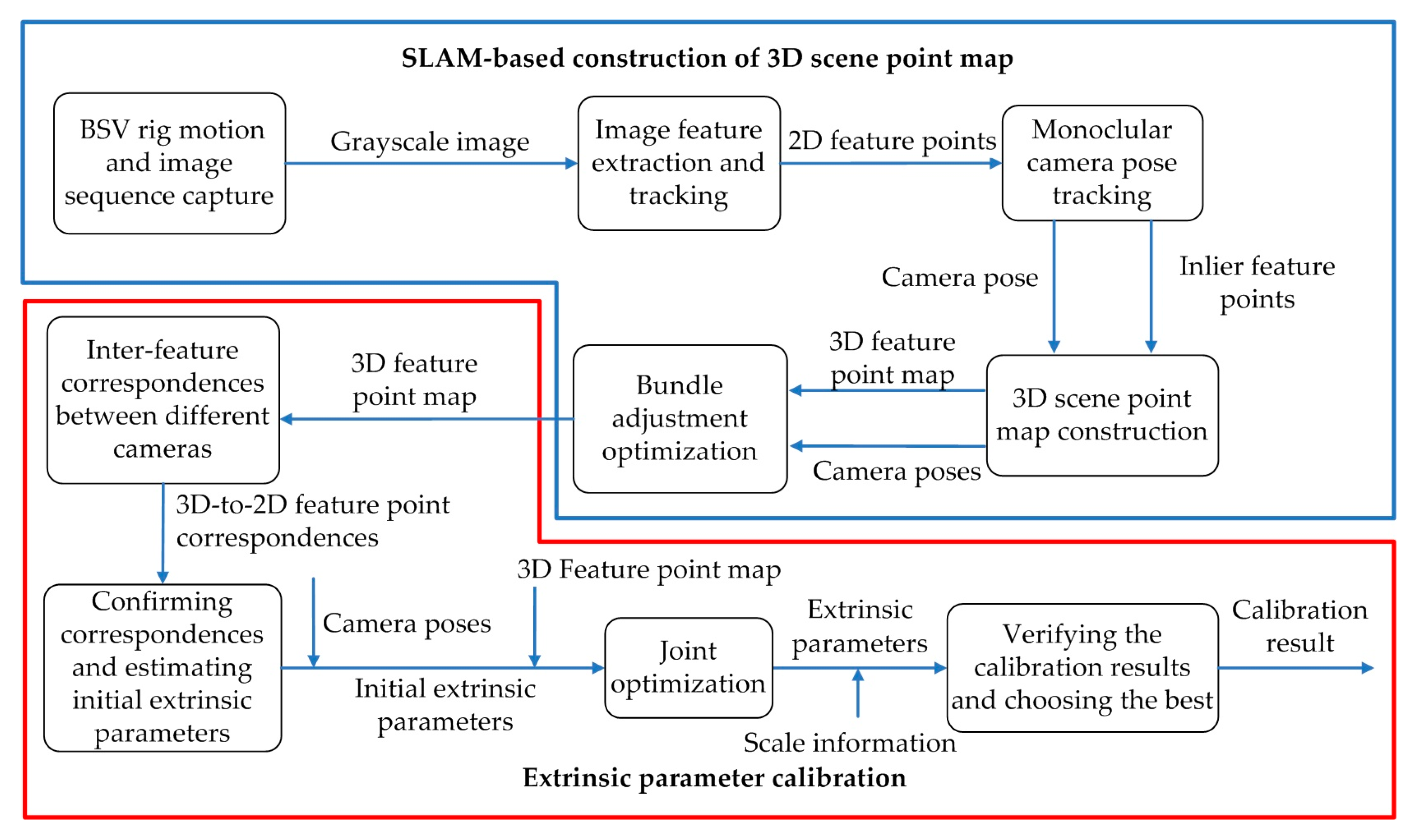
Figure 1 shows our SLAM-based self-calibration pipeline. The method is mainly divided into two parts: SLAM-based construction of a 3D feature point map of the natural environment (also called 3D scene point map) and extrinsic parameter calibration. SLAM-based construction of the 3D scene point map is mainly introduced throughout
Section 3. To improve the efficiency of calibration, a lightweight, real-time visual SLAM system is built in
Section 3.1. The image sequence is captured in the process of BSV rig motion and converted to Grayscale image before being fed to the SLAM process described in
Section 3.2. The monocular camera pose tracking step detailed in
Section 3.3 estimates camera poses and track inlier feature points extracted from the image. Then, the tracked inlier feature points together with camera poses are used to construct the 3D scene point map of the natural environment described in
Section 3.4. The scene point map is composed of a series of 3D feature points, so we also call it a 3D feature point map. To improve the precision of the algorithm, the BA is used to optimize the established 3D feature point map described in
Section 3.5.
At that time, an accurate 3D scene point map will be obtained, which can be used as a calibration area. The pipeline then goes into the extrinsic parameter calibration phase detailed in
Section 4. The 3D-2D correspondences between the 3D scene points associated with the 2D feature points in the left camera and the 2D feature points in the right camera are obtained through inter-feature correspondences between two binocular cameras described in
Section 4.1. Further, the Perspective-n-Point (PnP) method combined with the random sample consensus (RANSAC) algorithm is used to confirm correspondences and estimate the initial extrinsic parameters of BSV rig described in
Section 4.2. Subsequently, this initial estimation is used together with the camera poses and 3D feature point map by the joint optimization described in
Section 4.3 to acquire accurate extrinsic parameters. Finally, the scale information is given in
Section 4.4 and the calibration results are verified to select the optimal result.
3. SLAM-Based Construction of 3D Scene Point Map
This section describes our SLAM-based construction of the natural environment that used to produce a map of the calibration area.
3.1. Lightweight Monocular Visual SLAM System
Garrigues et al. [
31] proposed a features from accelerated segment test (FAST)-based optical flow method whose efficiency and performance are better compared to the feature corresponding methods based on slow corner points such as Harris [
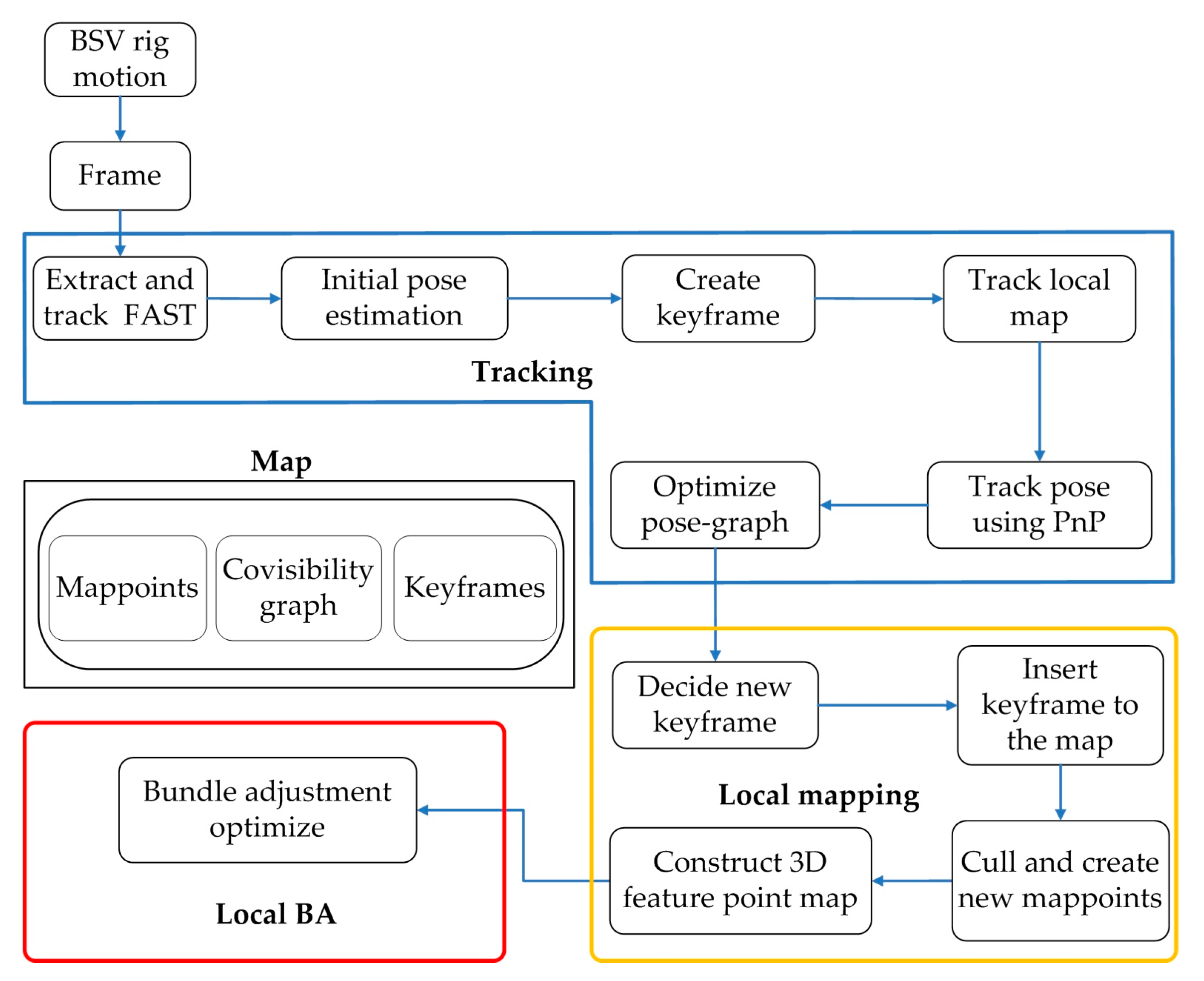
32], SIFT, and SURF. Therefore, the FAST-based optical flow method is chosen as the basic framework of our SLAM algorithm. However, the existing SLAM algorithm framework is more complicated, it is difficult to directly apply to solve our problems and meet the requirements for calibration efficiency. Therefore, a lightweight monocular vision SLAM system is built as shown in
Figure 2. The system is already reflected in
Figure 1, and the key points in the framework are detailed in the following sections. Therefore, only further supplements to the SLAM system are made here.
The system is mainly composed of four parts: tracking, local mapping, local BA and map. The tracking part locates each frame by extracting and tracking feature points on the image and finds local map features for matching. The local mapping part determines the new keyframes, decides to delete or add new mappoints, and builds a 3D feature point map accordingly. The local BA part manages and optimizes the local map by performing BA. The map part is used to maintain all mappoints, covisibility graph, and keyframes.
The loop-closing detection part like most SLAM algorithms is not performed, because the BSV rig can be calibrated in a shorter path. If the loop-closing detection is added, the place recognition part also needs to be further added, which will increase the complexity of the algorithm.
3.2. BSV Rig Motion and Image Sequence Capture
In this step, the sequence of the monocular camera image is captured during camera motion and begins as a SLAM algorithm. To ensure the convenience and practicability, the self-calibration method can be fully automated in real-time during the normal driving of the platform, without complex requirements for rig movement. The movement form of BSV rig is to include as much translation movement as possible along the opposite direction of the camera’s optical axis, and this kind of movement is also a common action on mobile platforms. Here, it is assumed that the two monocular cameras of the BSV rig has at most a minimum overlapping field of view. For example, the calibration can be performed during the normal forward or backward movement of the car or mobile robot. Aircraft operating in tight spaces can also be calibrated during vertical movement. Of course, this form of movement is ideal, which can ensure the precision and efficiency of the calibration to the greatest extent. This point is analyzed during the initialization of the camera pose tracking in
Section 3.3. But it is not limited to this way. This is mainly since the calibration is only performed when a keyframe is encountered. At this time, the local mapping part has already saved the feature point map and image feature points required for calibration.
The image sequences are captured by two monocular cameras of identical configuration while ensuring time synchronization. The algorithm does not require any prior information about the environment, nor does it need to set special markers or patterns in the scene. The image sequence should be converted from RGB to Grayscale before being fed to SLAM.
3.3. Monocular Camera Pose Tracking
The monocular camera poses and inlier feature points are tracked in the camera pose tracking step. The inlier feature points are required for 3D scene point map construction in
Section 3.4.
To decrease the time to track the monocular camera pose, the optical flow method is employed to track the FAST detectors as the feature points. In this paper, optical flow information is used for feature corresponding, mappoint selection, outlier feature points culling and pose estimation. The calculation of partial pixel optical flow is referred to as a sparse optical flow, and the sparse optical flow is represented by a Lucas-Kanade optical flow [
33]. The FAST detector is a kind of corner point, which mainly detects the obvious change of local pixel grayscale, and is known for its fast speed [
34]. The 16-dimensional grayscale description, block optical flow estimation, and gradient descent search for each FAST corner point are the highlights of its success. Therefore, the LK optical flow method is used to track FAST detectors as feature points in this paper. Besides, this paper adopts the classic corner extraction and optical flow tracking strategies in [
31]. However, they do not pay attention to the distribution of corners, but the uniform distribution of corners is intuitively important for us to obtain accurate and fast calibration results.
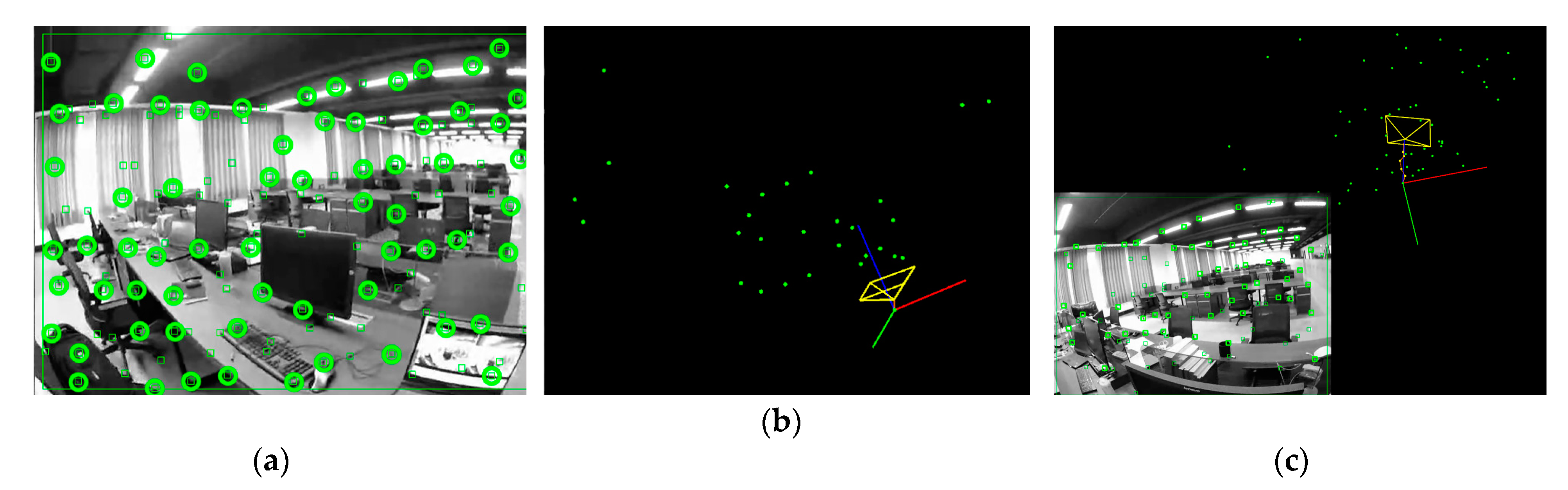
The feature points we extracted on the grayscale image are represented by green rectangles in
Figure 3a. They are mainly located in areas where the grayscale values are relatively changed, and most of them are located in the corner points. However, they often appear to be "get together" as shown in
Figure 3a. That is, the distribution of feature points is too crowded in a certain local area. This problem is easy to cause feature tracking errors, resulting in feature mismatch, which in turn affects camera pose tracking and 3D scene point map construction. Therefore, we added a sparse and uniform distribution strategy for feature points and hope to distribute the corner points as accurately as possible in all areas of the image.
In terms of feature points sparseness, the non-maximal suppression method [
35] is used to filter local non-maximal points. The effect of the FAST corner distribution after sparse processing is shown in
Figure 3b. To improve the feature corresponding performance, a gridded map management strategy similar to the method proposed in [
36] is used to maximize the chance of detecting a significant number of corresponding features between the overlapping view of two monocular cameras. The strategy procedure is described as follows: 1. Mesh the feature point map; 2. Count the number of feature points in each grid; 3. Delete the feature points that are too close; 4. If there are no feature points in the grid, select the most significant FAST feature extracted in the region as the new feature point. Thereby, the density under sparseness can be maintained, and the desired number of seed feature points can be ensured for subsequent tracking.
Figure 4a shows a feature point map managed by the gridded map, in which a blue rectangle represents an added feature point. The optical flow method is then used to track the feature points processed by the sparse and uniform distribution strategy. The tracking effect is shown in
Figure 4b.
Before tracking the monocular camera pose, the SLAM needs to be initialized first for tracking. The initialization task includes selecting two suitable monocular frames as the initial frames, estimating the relative pose of the initial frames, creating a local map, and creating a keyframe. According to our usage scenario, the initialization can be divided into the following three stages:
(1) Two initial frames that can be used as the first two frames are selected by feature point corresponding. When selecting the initial frames, it is necessary not only to ensure there are enough corresponding feature point pairs in the current and the last frames but also ensure there are as many co-vision feature points as possible on the two monocular cameras. The specific implementation algorithm is that when the BSV rig moves roughly in the opposite direction of the monocular camera’s optical axis, the camera frame sequence is queried from the current frame in reverse order. When the motion of more than N ∈ Z corresponding feature point pairs is greater than M ∈ Z pixels, it is considered that the pixel moving distance is large enough. The frame that is queried in reverse order at this time is taken as a reference frame. The current frame and the reference frame are selected as the initial frames and are used for initialization. The M is related to image resolution, and there is a proportional relationship between them.
(2) The co-vision feature points set
Pc of the current frame and the reference frame is taken out, and the corresponding feature point pairs set
P1 and
P2 between the two frames are obtained. The co-vision feature points represented by circles in the current frame are shown in
Figure 5a. Combining the Perspective-3-Points [
37] with the random sample consensus (RANSAC) [
38] algorithm, the essential matrix
E between two frames is calculated. Singular Value Decomposition is then used to calculate the camera motion
TIni between two frames. The reference frame is set to the world frame. The camera pose estimation of the current frame is set to the initial frame pose. As shown in
Figure 5b, the world frame is represented by three orthogonal axes (red, green, and blue axes), and the initial camera pose is represented by a yellow cube.
(3) The initial feature point depth is obtained by triangulation, thereby obtaining an initial local map. The resulting local feature points map is represented in
Figure 5b by a series of green dots.
After the initialization is completed, the current frame is used as the keyframe, and the initial frame pose and local map are optimized using BA optimization. Our algorithm will perform BA as soon as a new keyframe is obtained, which will be described in detail in
Section 3.5. In the camera pose tracking process after obtaining the keyframes, the subsequent frames are corresponded with the local map to calculate the camera poses. The PnP method combined with the RANSAC algorithm is used to estimate camera pose. Here, the Levenberg–Marquardt algorithm [
39] is used to minimize the distance between corresponding feature point pairs to calculate the pose of each frame.
However, the RANSAC uses only a few random points to determine the inliers, this method is susceptible to noise. To make the joint optimization more likely converge to the correct solution, the RANSAC solution is used as the initial value, and the camera poses are optimized using the pose-graph method to acquire a globally consistent camera pose estimation. In the pose graph optimization, nodes are used to represent the absolute poses to be optimized, expressed in
c0, …
ci,…
cm.
m ∈
Z is the total number of nodes. An absolute pose
ci describes the transformation from the world frame to the camera frame
i ∈
Z. Edges are used to represent relative pose constraints between two pose nodes. A relative pose constraint
between two camera frames
i and
j ∈
Z is defined as
. Using
as the set of all edges, the objective function in the optimization can be expressed as:
where
C is the current set of all camera poses that need to be optimized;
is the relative pose constraint error in the tangent space of SE(3);
is an information matrix, which is an inverse matrix of the covariance matrix of relative pose constraint. Rather than using appropriate marginalization to accurately estimate this uncertainty, it is better to approximate the information matrix roughly as a diagonal matrix in the way proposed in [
40]:
where the
and
are the rotational component and the translational component of
, respectively. It can be considered the camera pose constraints generated during the optimization are similar in accuracy [
41]. Therefore,
is set to a constant
= 1.
Figure 5c shows the results of inlier feature points and camera poses tracking. The brown line connected to the origins from the world frame to the current frame represents the tracked camera poses, and the yellow dot on the brown line represents the keyframe poses.
3.4. 3D Scene Point Map Construction
This step is used to construct the 3D feature point map of the natural environment which is used as a calibration area. The monocular camera poses and inlier feature points are input in this step, the output is 3D scene point map of the tracked inlier feature points in the keyframe. Note that the new keyframes are not determined due to the reduction of tracked feature points in consecutive frames. On the contrary, the new keyframe in the local map must have as many common views with other keyframes as possible to increase the number of 3D scene points required for calibration.
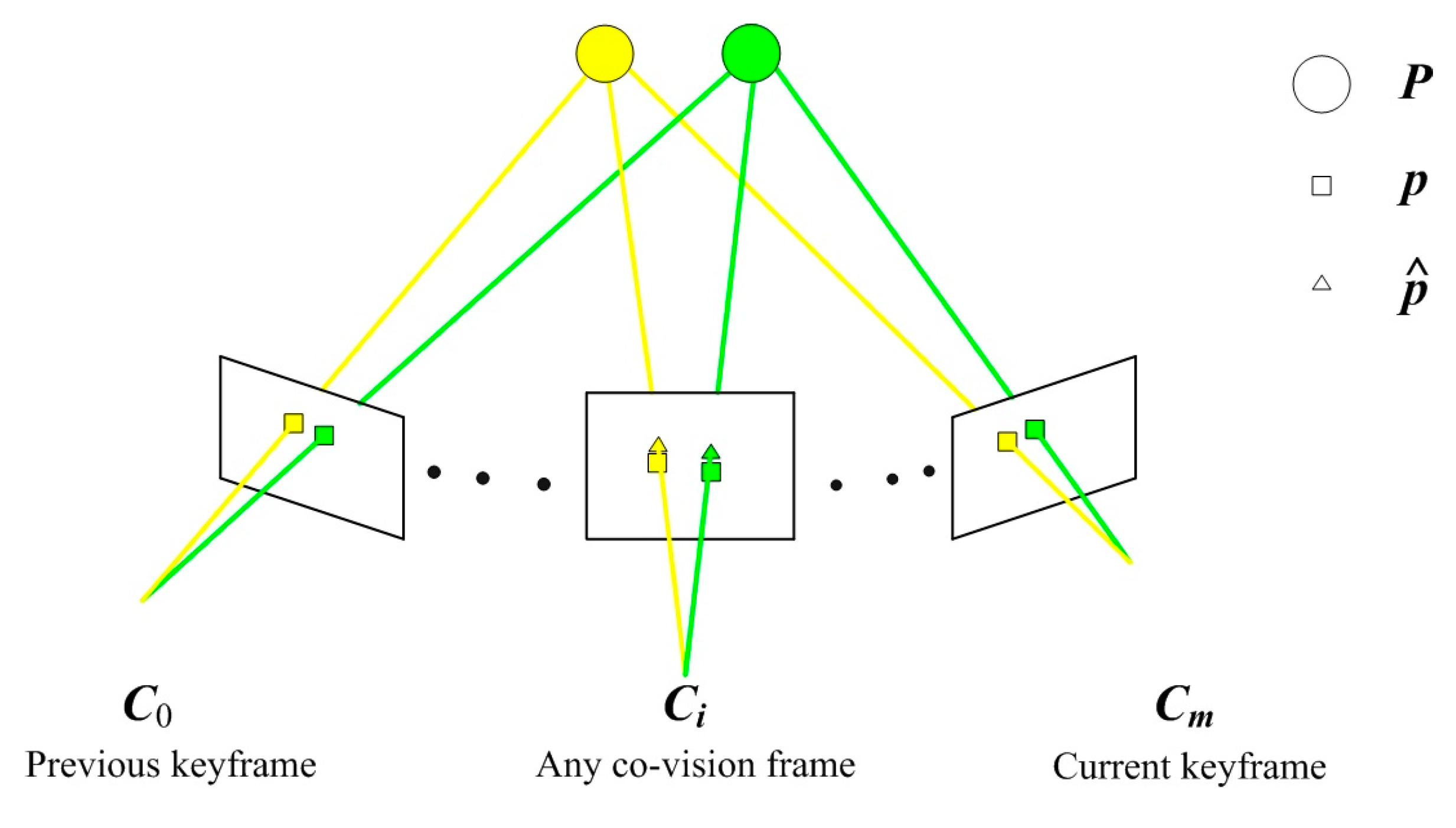
Figure 6 is a schematic diagram of our 3D feature point map construction. The Vector
C represents the camera pose set of all co-view frames between the current keyframe and the previous keyframe; The vector
P represents a 3D scene point map, which is represented by circles; The vector
p represents the set of 2D feature points extracted and tracked in the image, and is represented by rectangles; The vector
represents the set of 2D points projected from the local map onto the co-view frames, and is represented by triangles; The connection between the 3D feature points and the 2D feature points indicates the co-view relationship, and the yellow and green lines are used to distinguish them.
where
is the absolute pose of co-view frame
i ∈
Z,
m is the total number of co-view frames;
Pj is the coordinate of 3D feature point
j ∈
Z in the world frame,
n is the total number of 3D feature points;
pij is the observed image coordinate corresponding to 3D feature point
j in the co-view frame
i;
is the estimated image coordinate of 3D feature point
j projected in co-view frame
i.
When the SLAM creates a new keyframe, triangulation is used to build a local map. To reduce the inaccurate map caused by false tracking and noise, 3D feature points are projected onto any co-vision frame. When the reprojection error exceeds T ∈ Z times average error, the 3D feature point Pj is considered to be mismatched and deleted. This can improve the calibration precision to a certain extent.
3.5. Bundle Adjustment of Camera Pose and 3D Scene Point Map
The camera pose obtained in
Section 3.3 and the 3D feature point map obtained in
Section 3.4 are jointly optimized in this step for 3D scene point map refinement. The cost function of this optimization can be regarded as a nonlinear least-squares problem. In Formula (5), the cost function corresponds to the reprojection errors of the feature observations across all keyframes:
where
is the absolute pose of keyframe
i ∈
Z,
m is the total number of keyframes;
Pj is the coordinate of 3D feature point
j ∈
Z in the world frame,
n is the total number of 3D feature points;
pij is the observed image coordinate corresponding to 3D feature point
j in the keyframe
i;
is a standard camera projection function that predicts the image coordinates of the 3D feature point
j given the camera’s intrinsic parameters and the estimated camera pose
;
is a robust kernel used for reducing the effects of outliers. The Huber kernel [
42] is used here.
6. Conclusions and Future Work
In this paper, a novel SLAM-based self-calibration method for the BSV rig was proposed. The proposed method was enabled to estimate the extrinsic parameters of the BSV rig without auxiliary equipment and special calibration markers. Further, the calibration process can be fully automated in real-time during the normal driving of the platform, without complex requirements for rig movement and prior information about the environment.
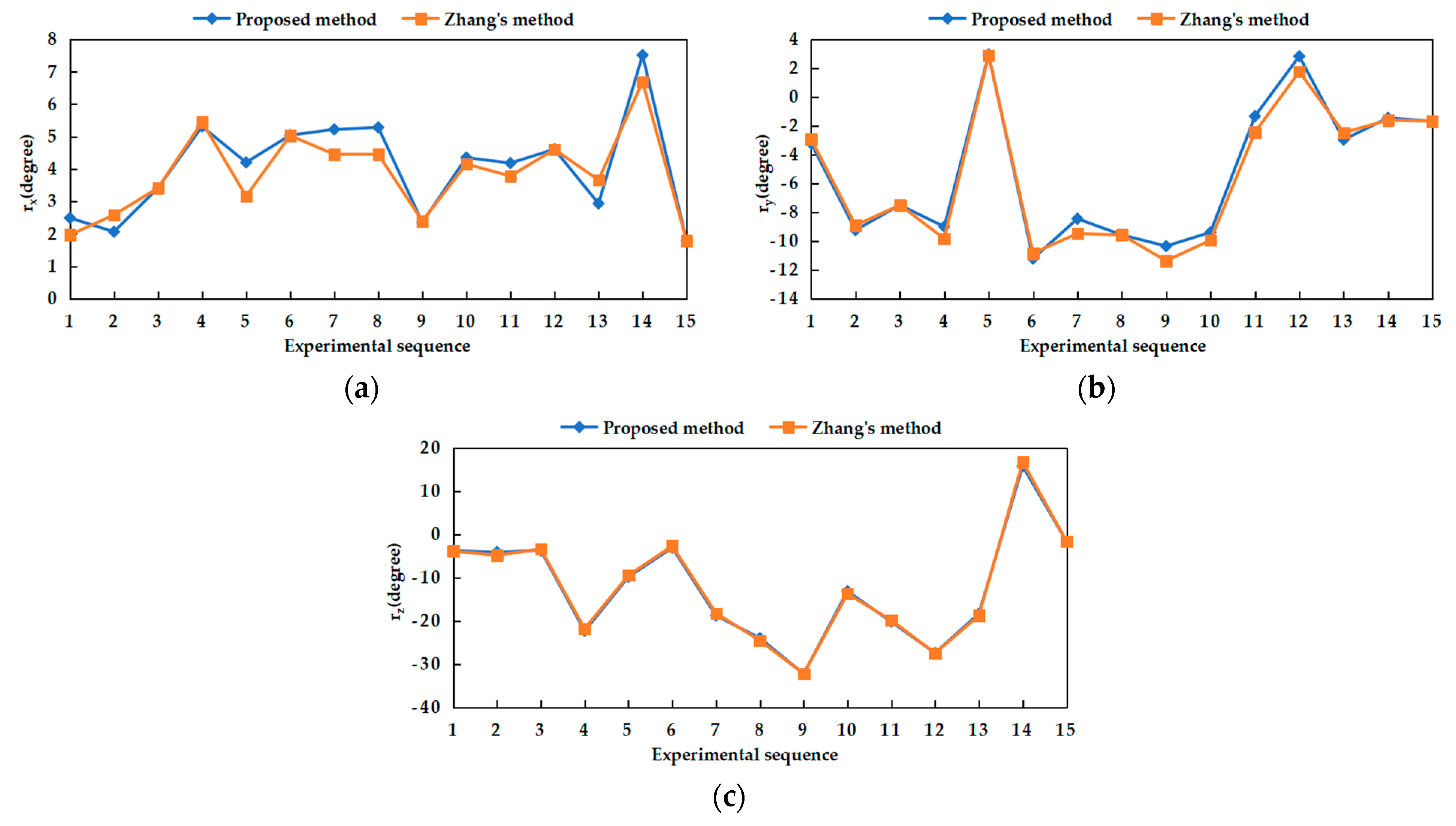
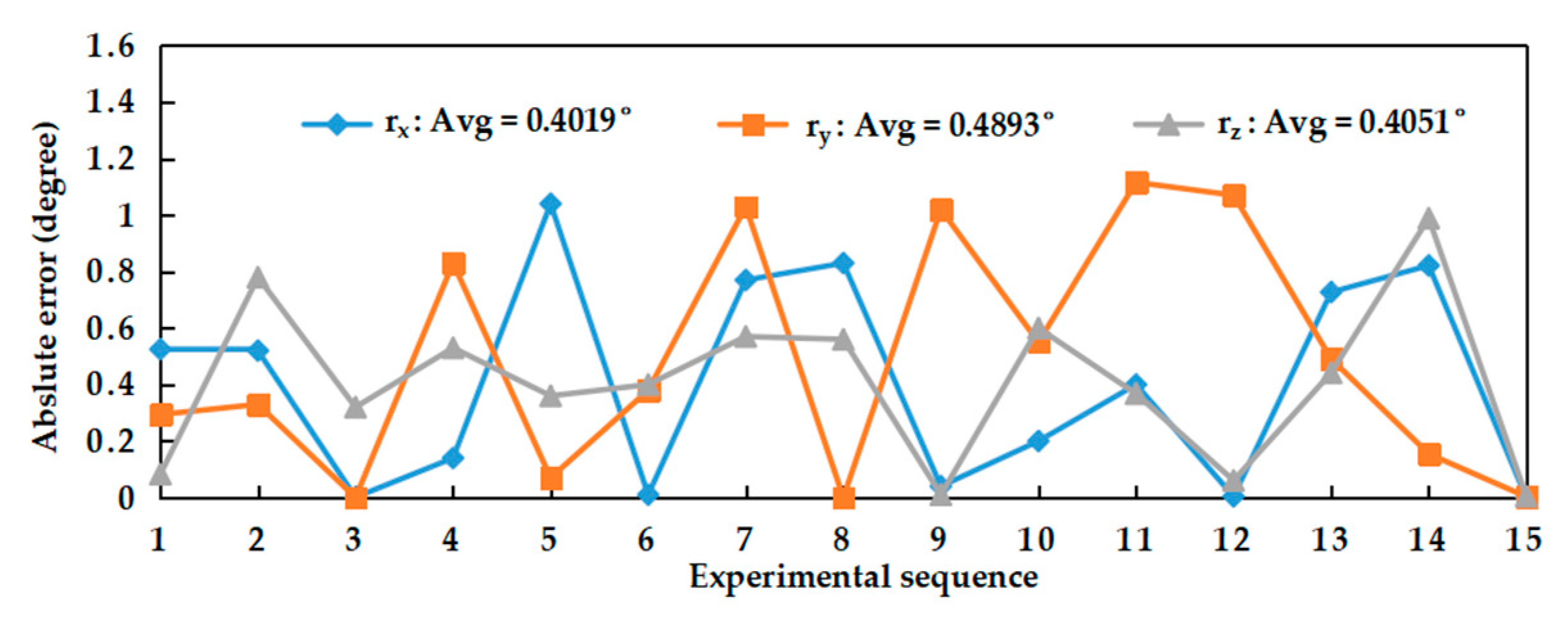
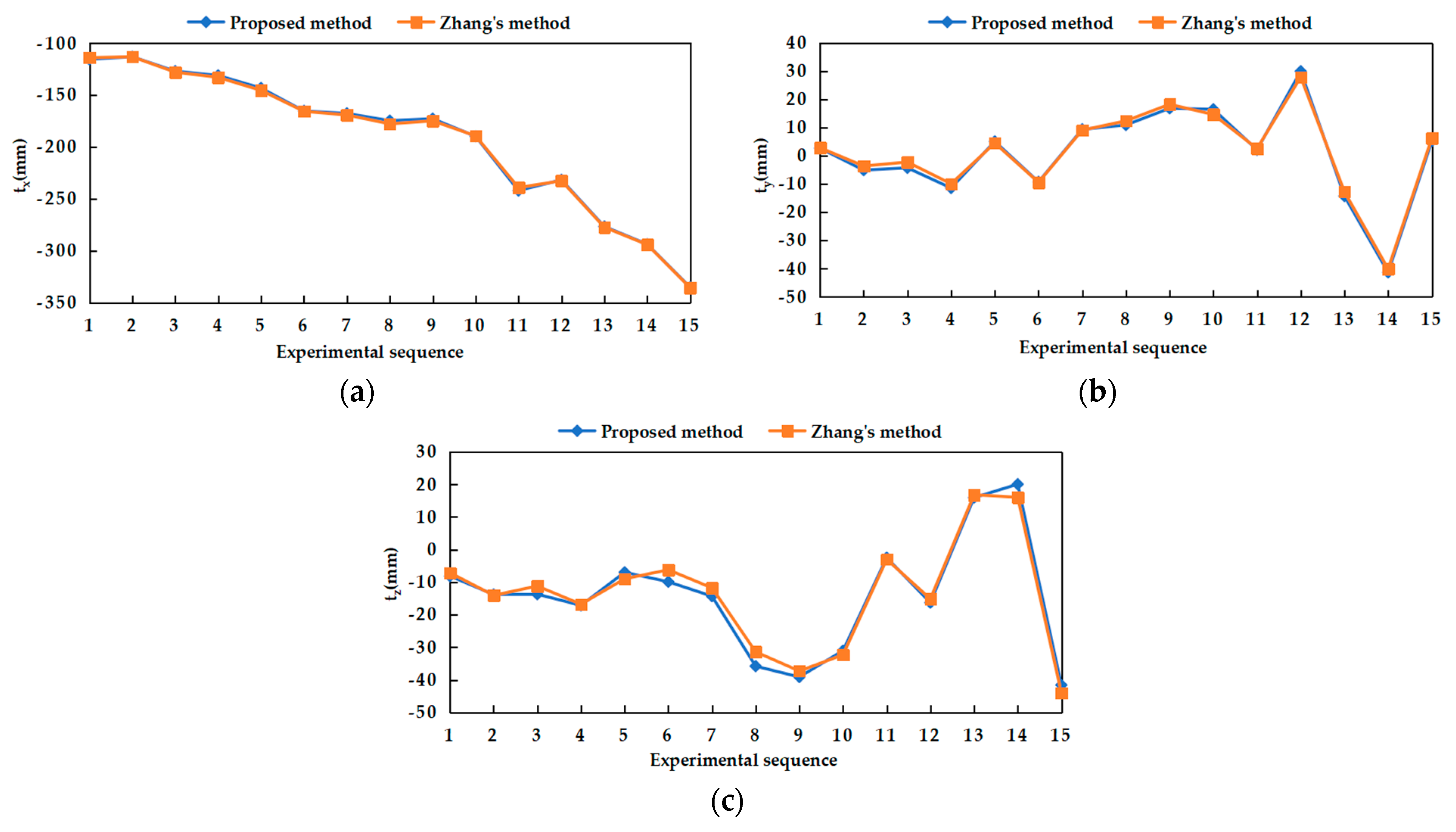
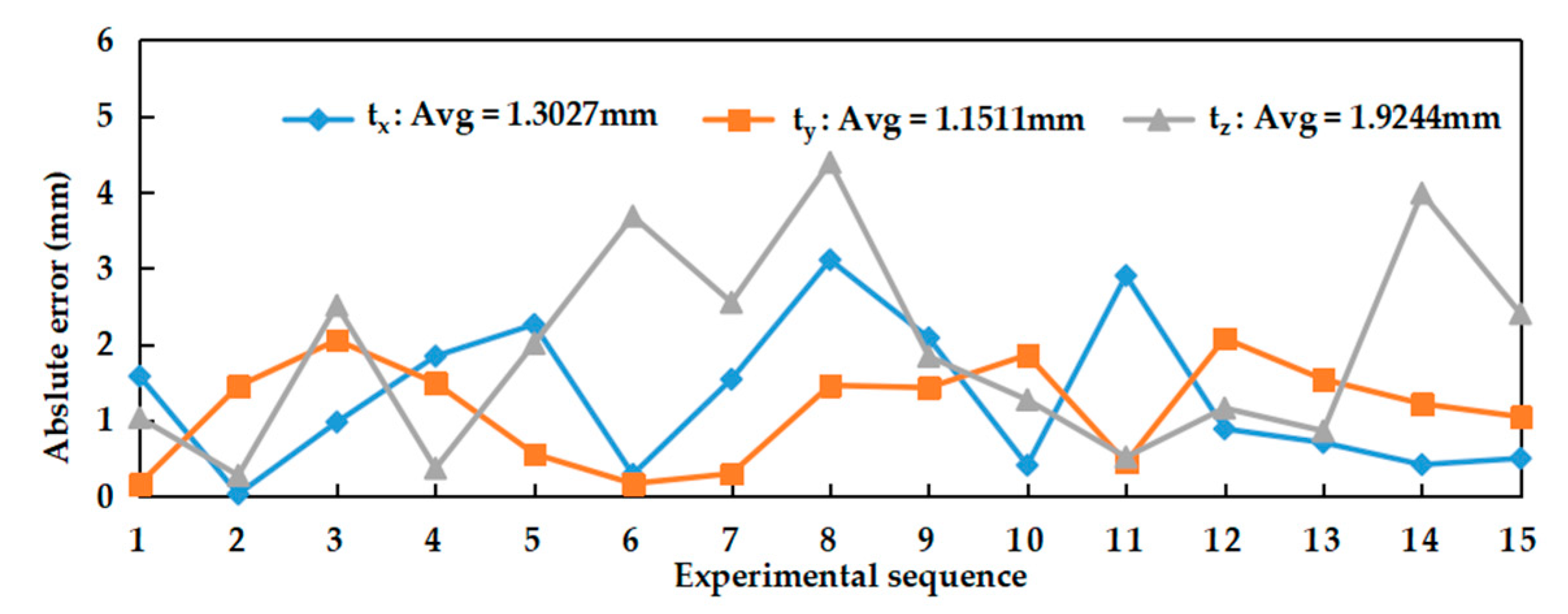
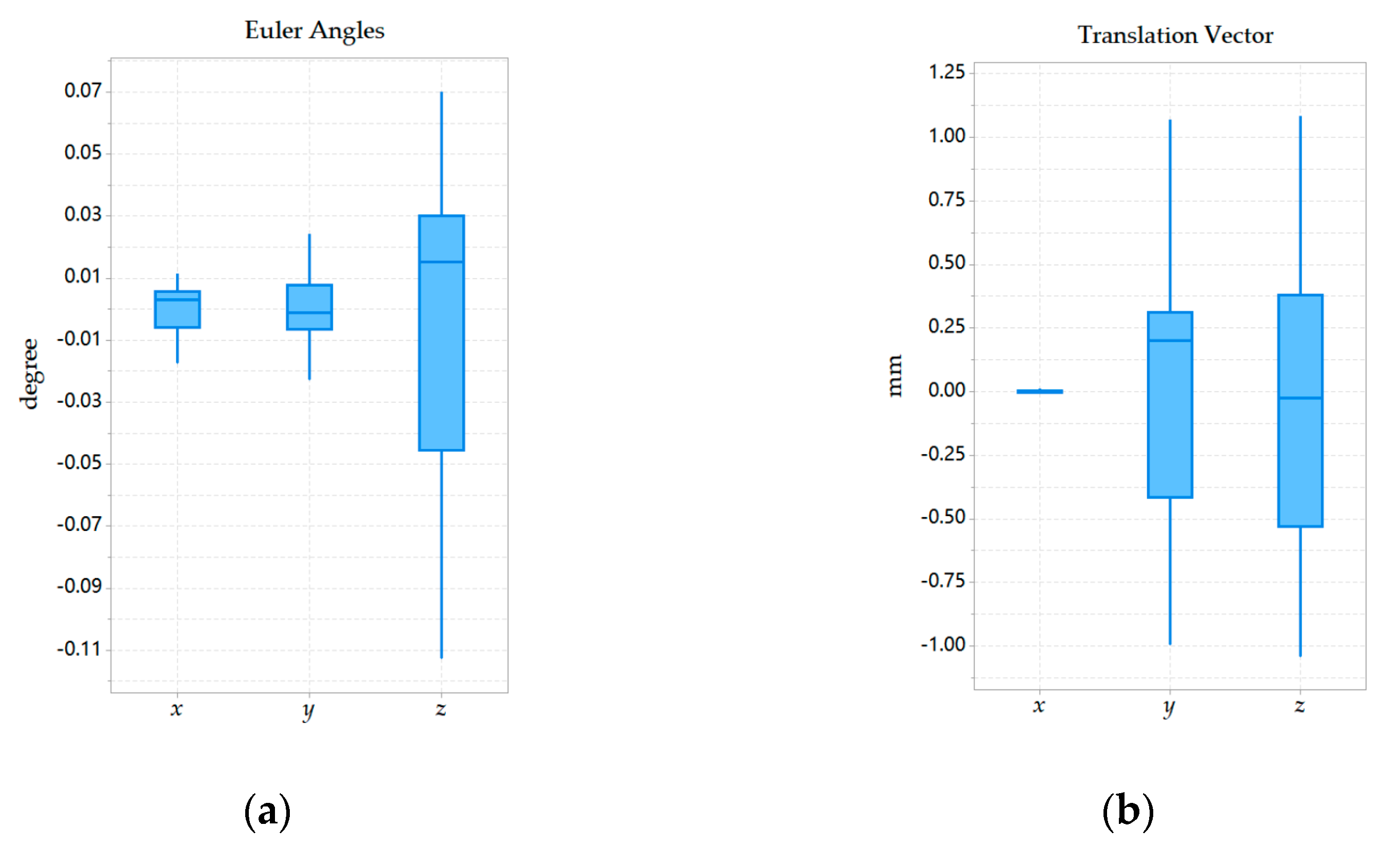
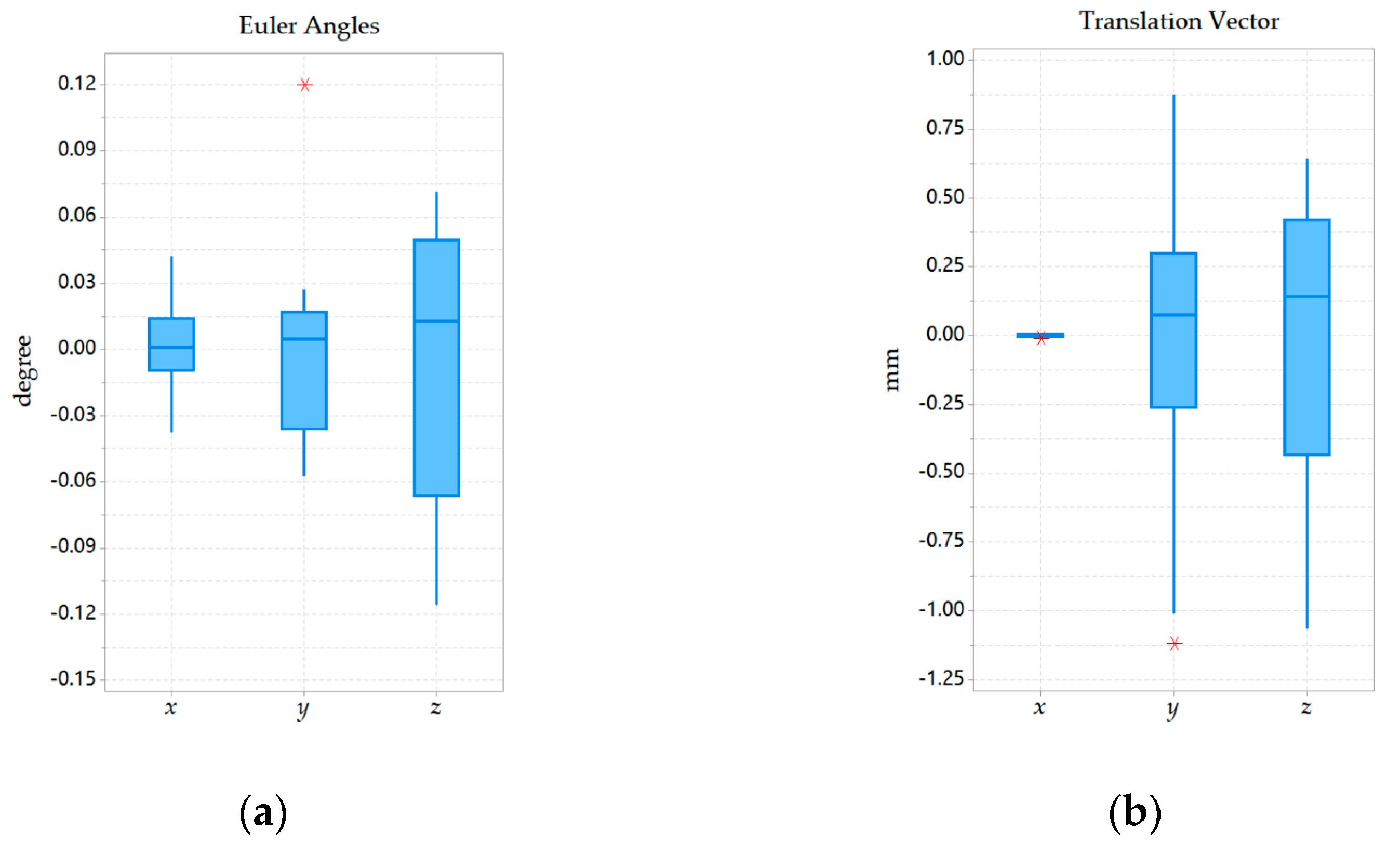
Field experiments were performed to evaluate the feasibility, repeatability of the calibration parameter estimation by our self-calibration method. In terms of feasibility experiments, it can be seen from the experimental data that the results obtained by our proposed and Zhang’s calibration method were close, which could prove that our method was reliable. In the repeatability experiment, 20 experiments performed under general and weak texture environments respectively showed that our calibration method can both obtain relatively compact distribution results. Under the general texture scene and the normal driving speed of the robot, the calibration time can be generally maintained within 10 s, which was more efficient. In short, the experiment results showed that the precision and efficiency of the proposed SLAM-based self-calibration method have reached a relatively high level. This calibration method can be used for large-scale practical applications on arbitrary BSV rigs, such as a car or mobile robot.
However, the calibration method still has shortcomings in the following cases. Firstly, incorrect feature correspondences in a dynamic environment could cause an erroneous 3D scene point map and further lead to unreliable calibration results. Secondly, the baseline length obtained by measurement equipment is adopted as the scale information of the method currently. Although in a more accurate situation, the calibration results can meet the requirements of the advanced driving assistant system. However, calibration precision is still affected by external human factors. Therefore, a suitable method that can automatically calculate the baseline will make the calibration more convenient. In the future, the solution in the dynamic environment and other scale information is the next work we need to focus on.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}