Photo Composition with Real-Time Rating

Abstract
1. Introduction
2. Related Work
3. Composition Analysis
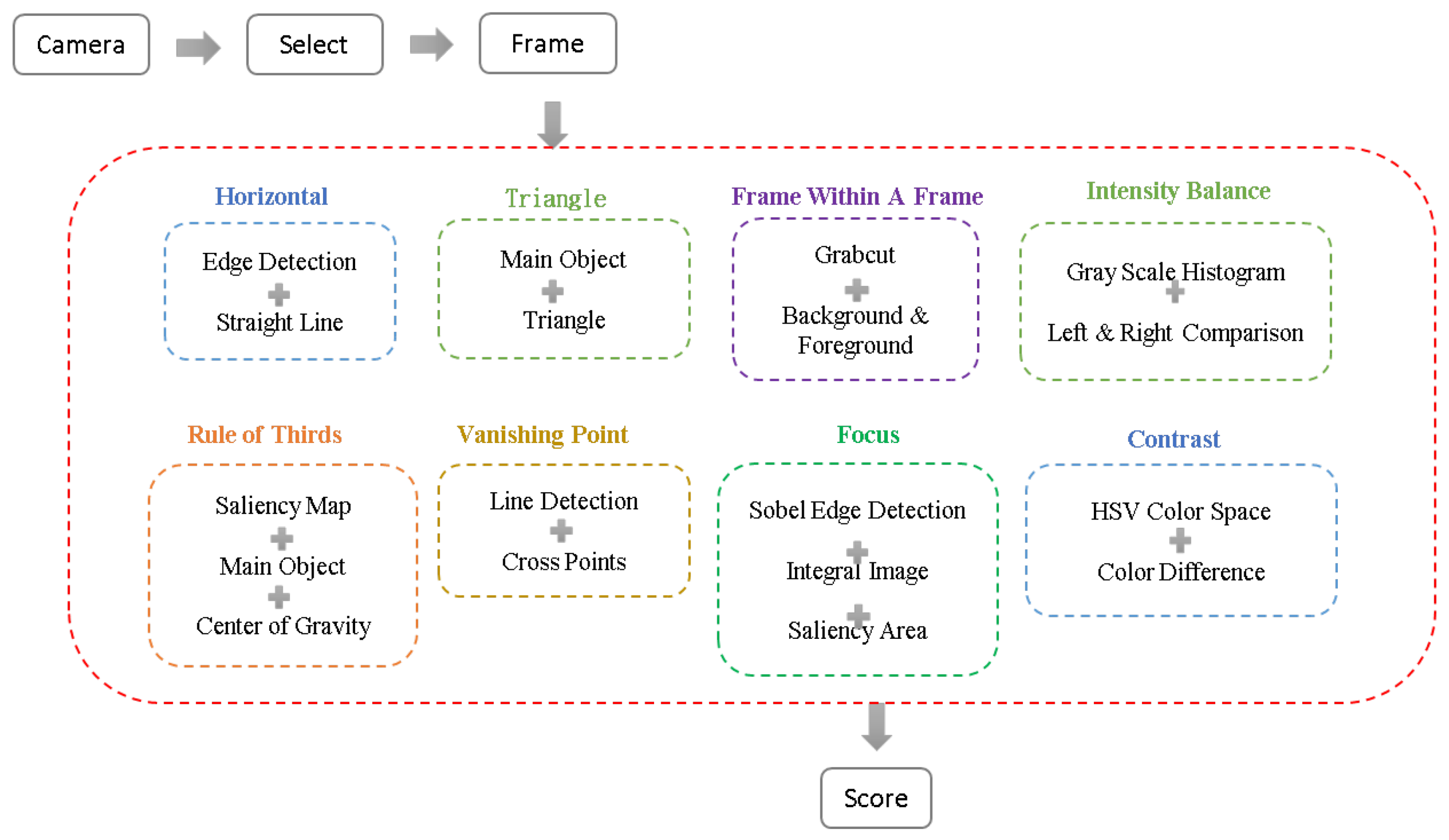
3.1. System Overview
3.2. Composition Analysis
3.2.1. Horizontal Composition
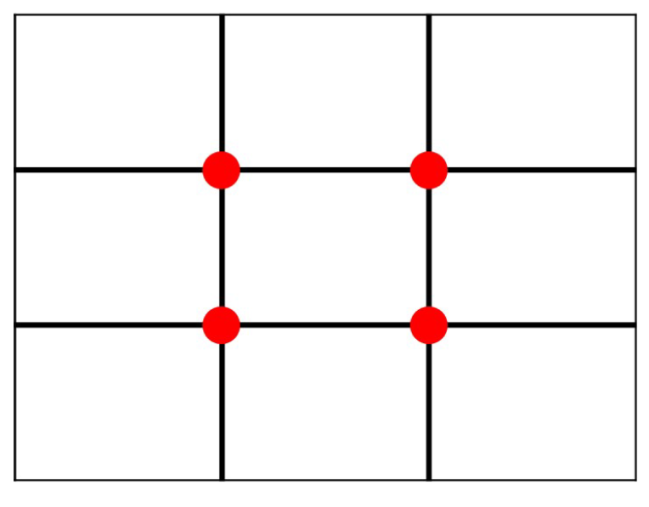
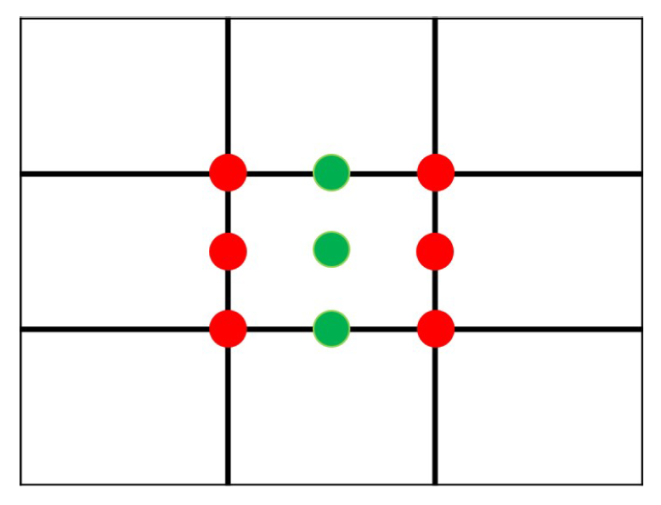
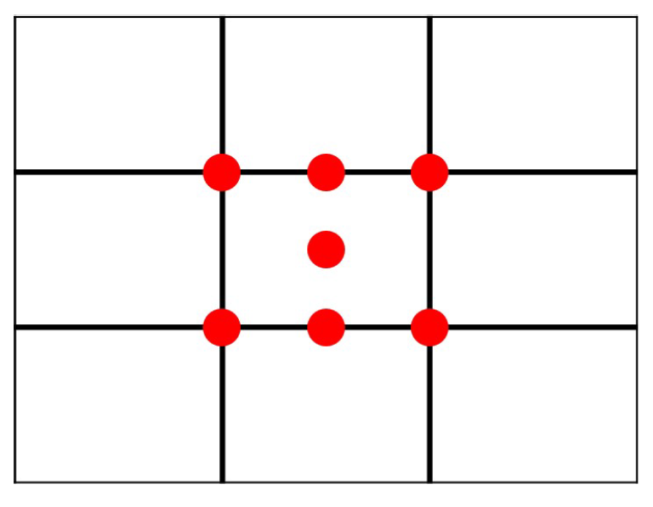
3.2.2. Rule of Thirds
3.2.3. Triangle Composition
3.2.4. Vanishing Point
3.2.5. Frame within a Frame
3.2.6. Focus
3.2.7. Intensity Balance
3.2.8. Contrast
3.3. Weighted Combination
3.4. Acceleration
3.4.1. Multi-Threading
3.4.2. Downsampling
3.4.3. Saliency Extraction
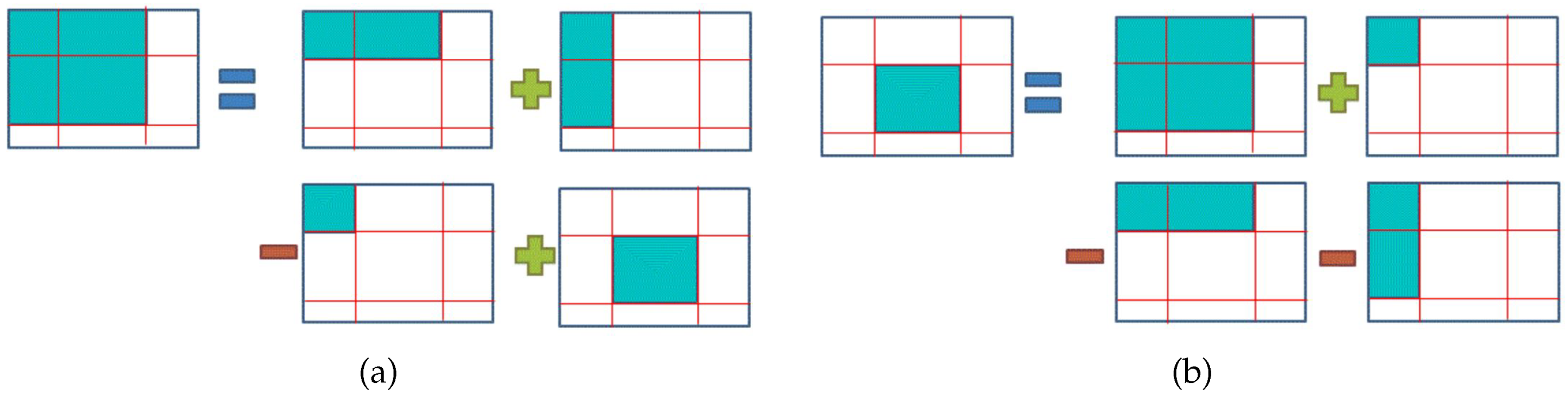
3.4.4. Image Integration
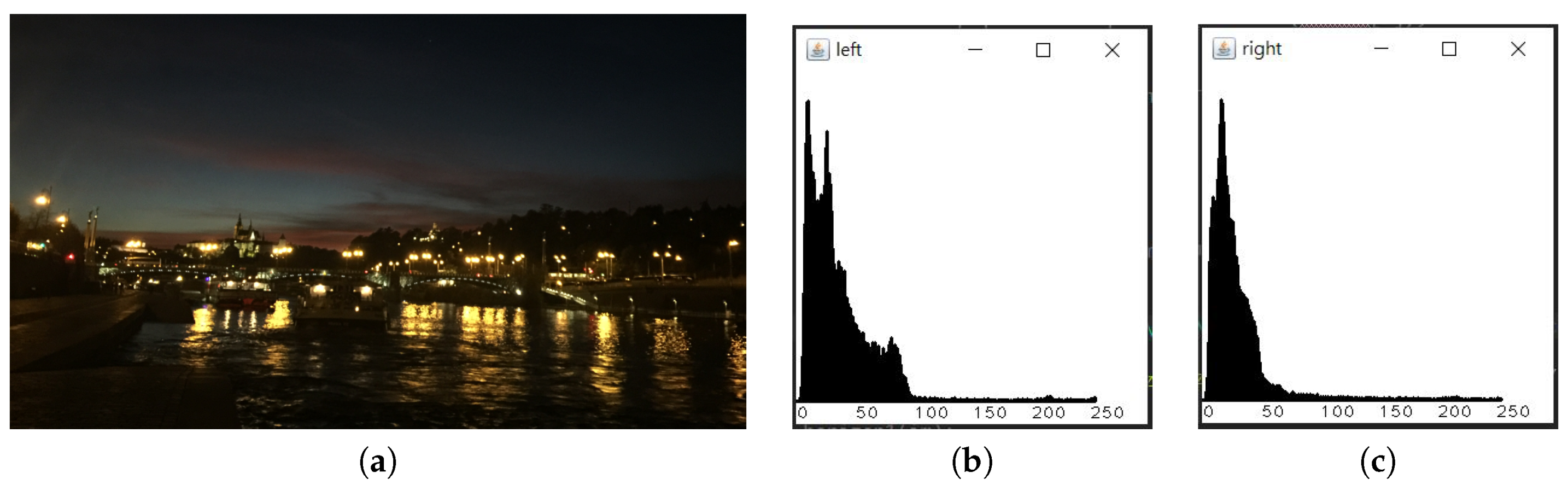
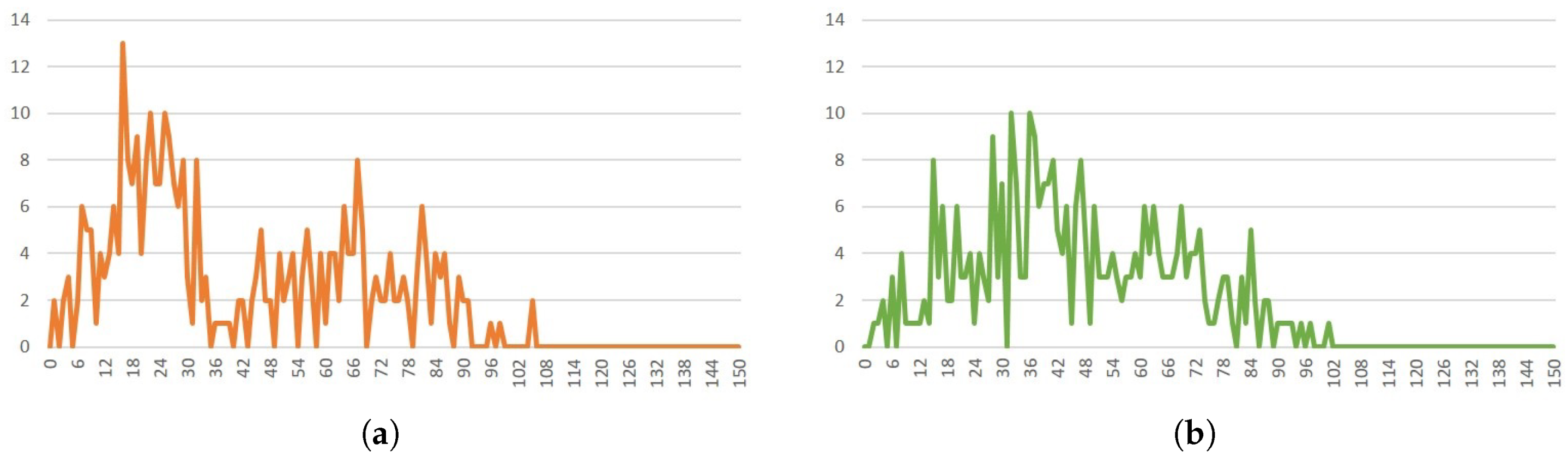
3.4.5. Histogram Computation
4. Results
4.1. System Environment
4.2. Parameter Setting
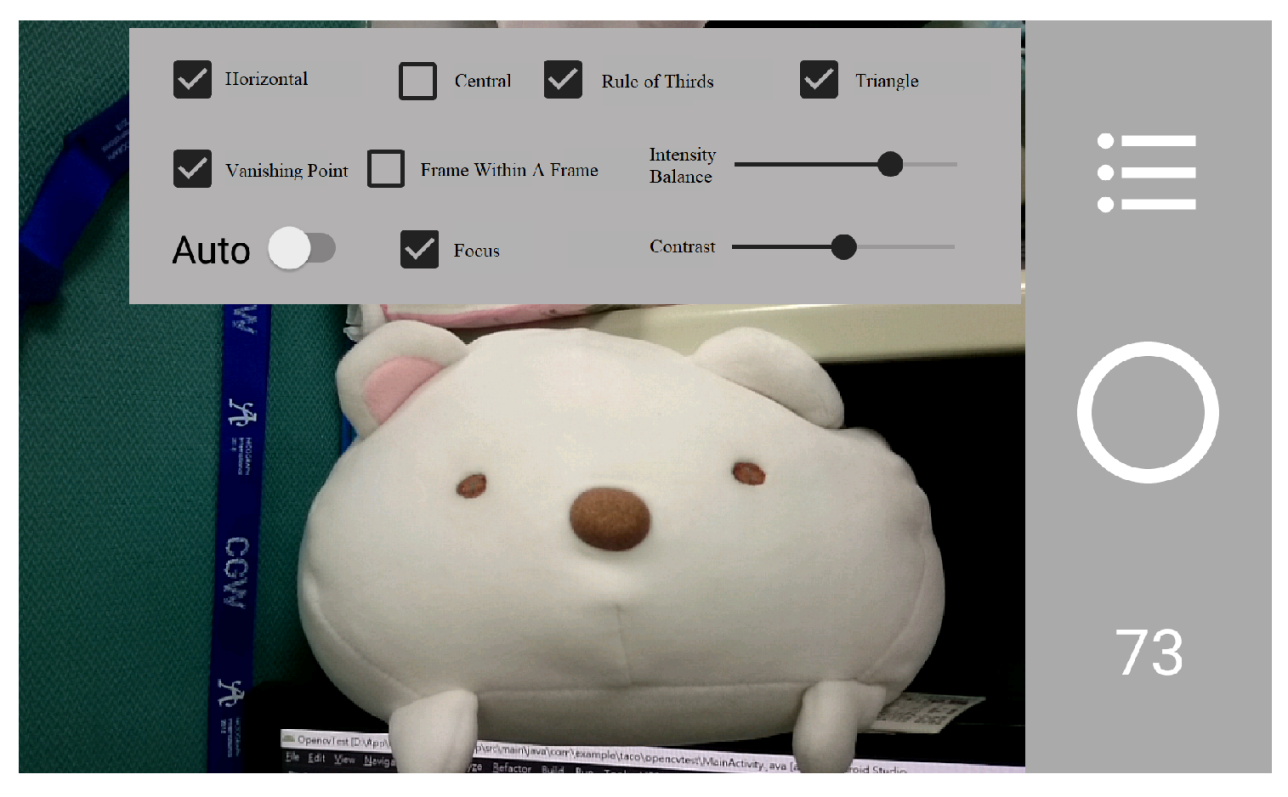
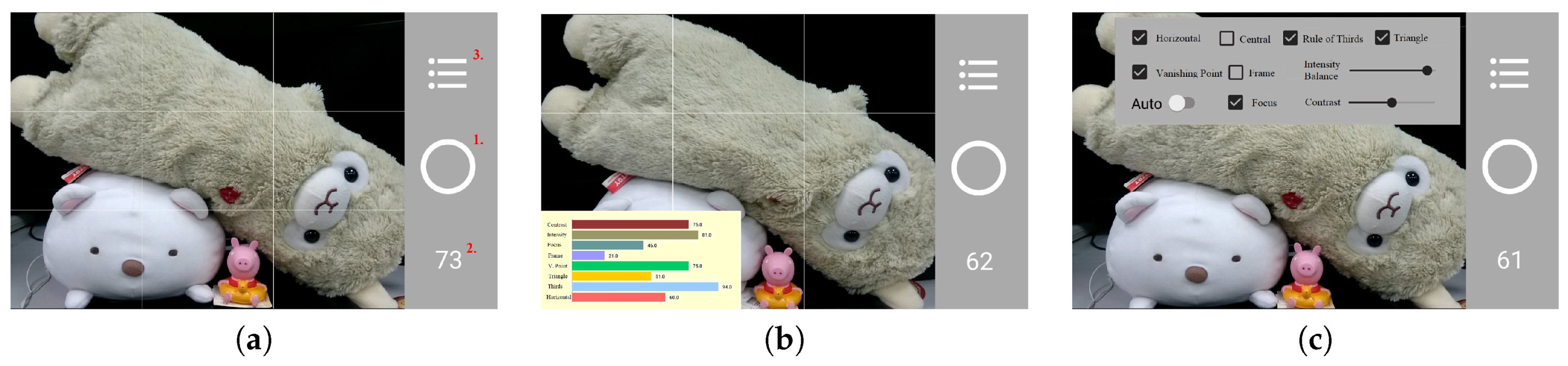
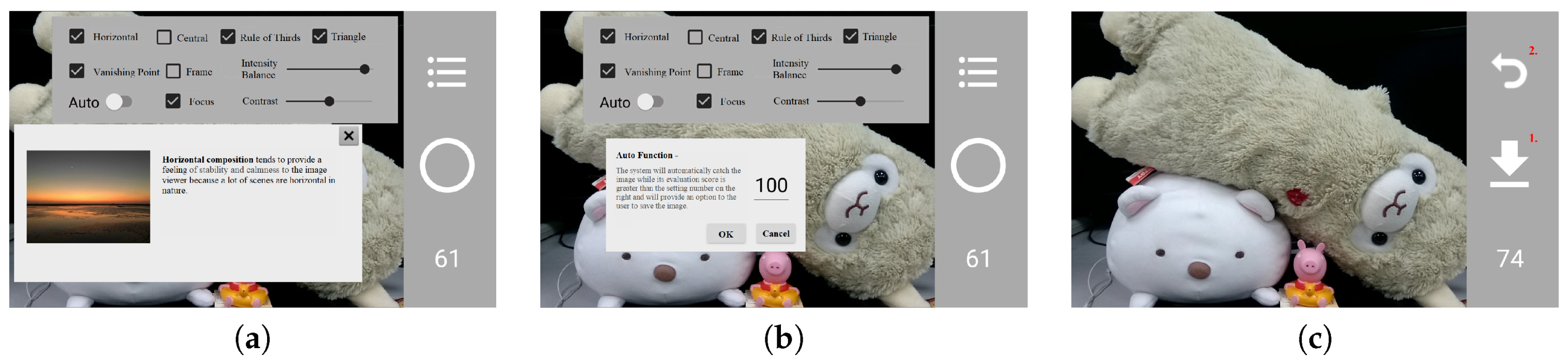
4.3. System Interface
4.4. Results
4.5. Limitations
5. Evaluation
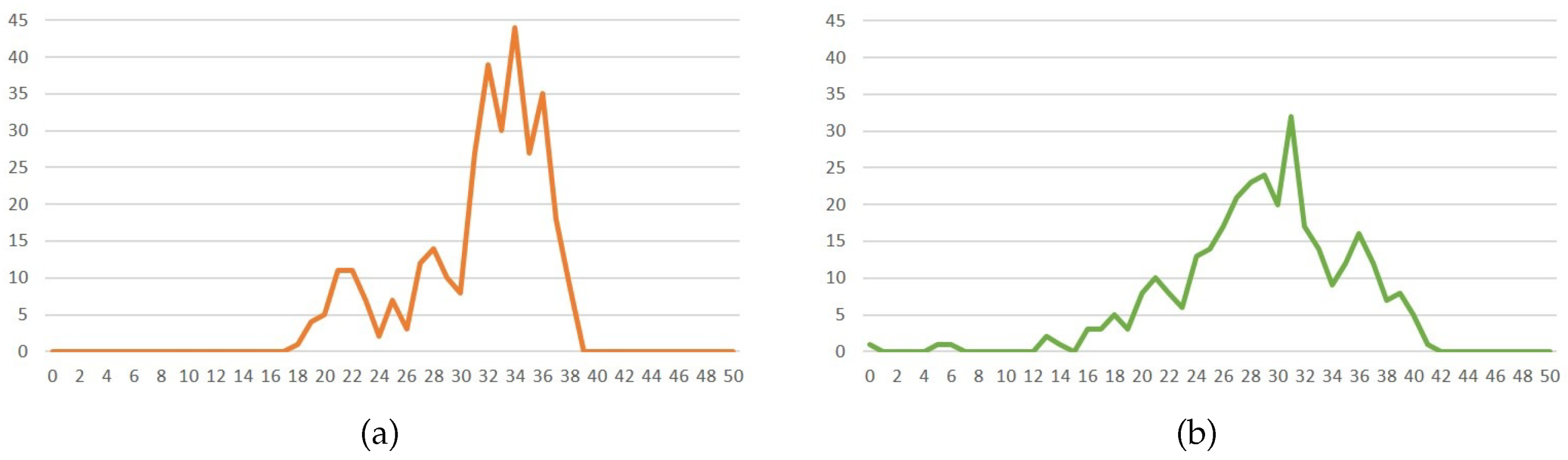
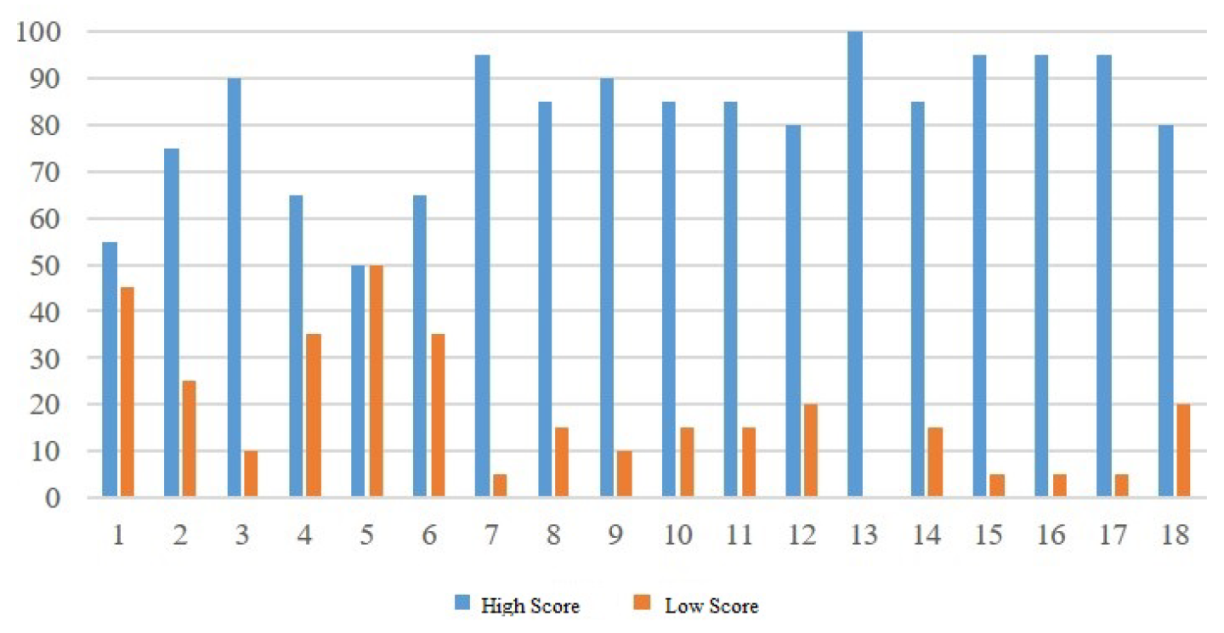
5.1. Score Distribution
5.1.1. Experiment Environment
5.1.2. Experiment Analysis
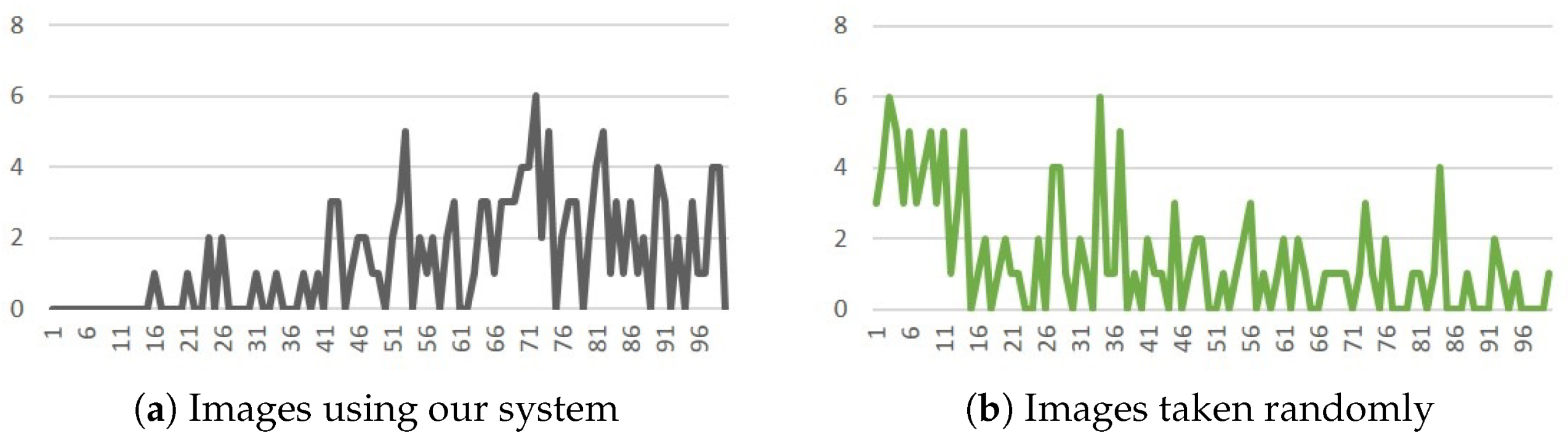
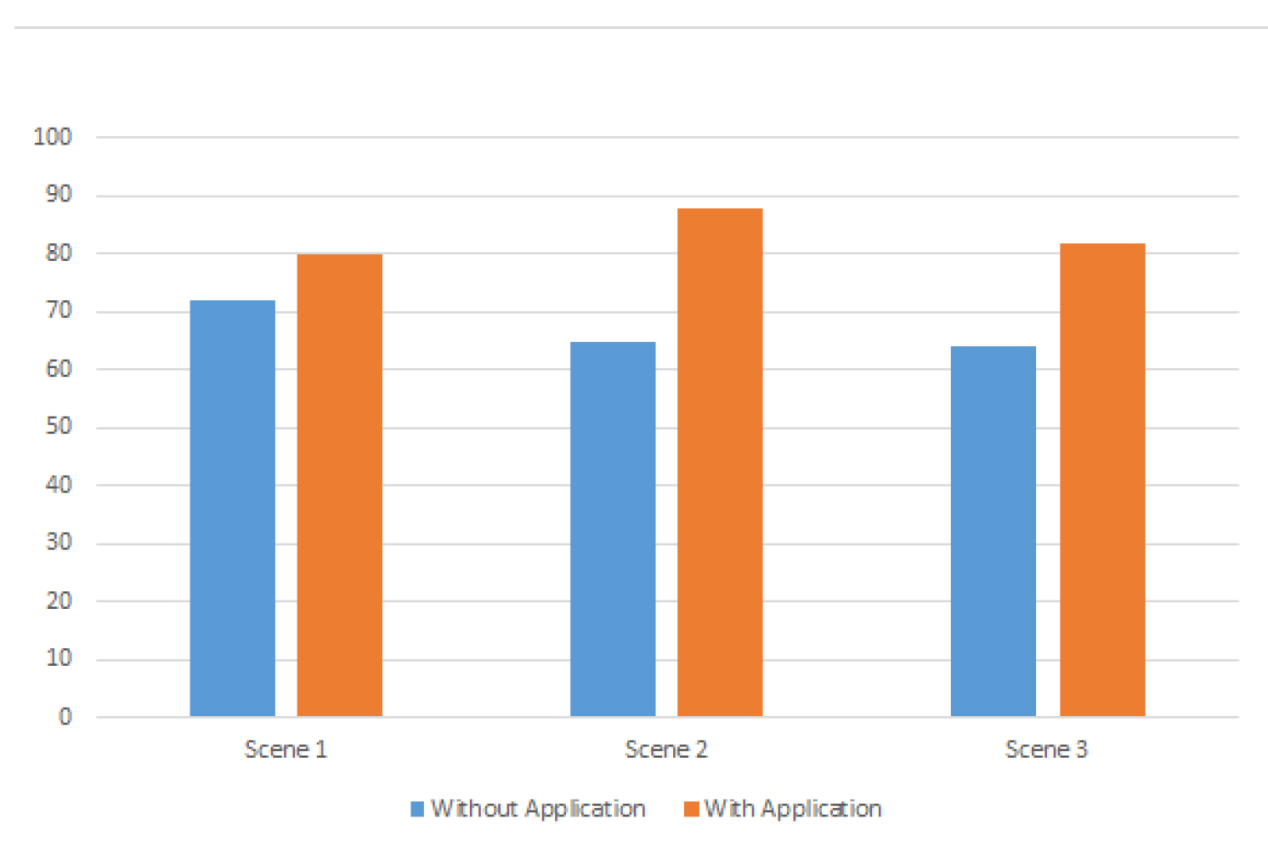
5.2. Result Preference
5.3. With/Without our system
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Tom Grill, M.S. Photographic Composition; Amphoto Books: New York, NY, USA, 1990. [Google Scholar]
- Yeh, C.H.; Ho, Y.C.; Barsky, B.A.; Ouhyoung, M. Personalized photograph ranking and selection system. In Proceedings of the 18th ACM international conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 211–220. [Google Scholar] [CrossRef]
- Cao, Z.; Qin, T.; Liu, T.Y.; Tsai, M.F.; Li, H. Learning to Rank: From Pairwise Approach to Listwise Approach. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 20–24 June 2007; ACM: New York, NY, USA, 2007; pp. 129–136. [Google Scholar] [CrossRef]
- Yeh, C.H.; Barsky, B.A.; Ouhyoung, M. Personalized Photograph Ranking and Selection System Considering Positive and Negative User Feedback. ACM Trans. Multimed. Comput. Commun. Appl. 2014, 10, 36. [Google Scholar] [CrossRef]
- Carballal, A.; Perez, R.; Santos, A.; Castro, L. A Complexity Approach for Identifying Aesthetic Composite Landscapes. In Evolutionary and Biologically Inspired Music, Sound, Art and Design; Romero, J., McDermott, J., Correia, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 50–61. [Google Scholar]
- Obrador, P.; Schmidt-Hackenberg, L.; Oliver, N. The role of image composition in image aesthetics. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 3185–3188. [Google Scholar] [CrossRef]
- Deng, Y.; Loy, C.C.; Tang, X. Image Aesthetic Assessment: An experimental survey. IEEE Signal Process. Mag. 2017, 34, 80–106. [Google Scholar] [CrossRef]
- Wu, M.T.; Pan, T.Y.; Tsai, W.L.; Kuo, H.C.; Hu, M.C. High-level semantic photographic composition analysis and understanding with deep neural networks. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 279–284. [Google Scholar] [CrossRef]
- Luo, Y.; Tang, X. Photo and Video Quality Evaluation: Focusing on the Subject; Springer: Berlin/Heidelberg, Germany, 2008; pp. 386–399. [Google Scholar]
- Abdullah, R.; Christie, M.; Schofield, G.; Lino, C.; Olivier, P. Advanced Composition in Virtual Camera Control; Smart Graphics; Springer: Berlin/Heidelberg, Germany, 2011; pp. 13–24. [Google Scholar]
- Xu, Y.; Ratcliff, J.; Scovell, J.; Speiginer, G.; Azuma, R. Real-time Guidance Camera Interface to Enhance Photo Aesthetic Quality. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; pp. 1183–1186. [Google Scholar] [CrossRef]
- Anon, J. Automatic Real-Time Composition Feedback for Still and Video Cameras. U.S. Patent 8,508,622 B1, 9 October 2001. [Google Scholar]
- Composition Basics: 20 Ways to Create Aesthetically Pleasing Photos. Available online: https://www.canva.com/learn/composition-basics-20-ways-create-aesthetically-pleasing-photos/ (accessed on 1 February 2018).
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Ro, D.; Pe, H. Use of the Hough transformation to detect lines and curves in pictures. Commun. ACM 1972, 15, 11–15. [Google Scholar] [CrossRef]
- Ocarroll, B. 20 Composition Techniques That Will Improve Your Photos. Available online: https://petapixel.com/2016/09/14/20-composition-techniques-will-improve-photos/ (accessed on 1 February 2018).
- Palad, V. 23 Composition Techniques for Travel Photography. Available online: https://pixelsandwanderlust.com/composition-techniques-travel-photography/ (accessed on 1 June 2019).
- Basic Photography Composition Techniques. Available online: https://www.adorama.com/alc/basic-photography-composition-techniques (accessed on 1 July 2018).
- Rother, C.; Kolmogorov, V.; Blake, A. “GrabCut”—Interactive foreground extraction using iterated graph cuts. In ACM SIGGRAPH 2004 Papers; ACM: New York, NY, USA, 2004; Volume 23, pp. 309–314. [Google Scholar]
- Gildenblat, J. Simple Image Saliency Detection from Histogram Backprojection. Available online: https://jacobgil.github.io/computervision/saliency-from-backproj (accessed on 1 February 2018).
- Cheng, Y. Mean shift, mode seeking, and clustering. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 790–799. [Google Scholar] [CrossRef]
- Suzuki, S.; Abe, K. Topological Structural Analysis of Digitized Binary Images by Border Following. Comput. Vis. Graph. Image Process. 1985, 30, 32–46. [Google Scholar] [CrossRef]
- Plant, I. Using Triangles in Landscape Photography. Available online: https://www.outdoorphotographyguide.com/article/using-triangles-in-landscape-photography/# (accessed on 1 February 2018).
- Ahn, H.K.; Bae, S.W.; Cheong, O.; Gudmundsson, J.; Tokuyama, T.; Vigneron, A. A generalization of the convex Kakeya problem. Algorithmica 2014, 70, 152–170. [Google Scholar] [CrossRef][Green Version]
- Lu, K.; Li, J.; An, X.; He, H. Road vanishing-point detection: A multi-population genetic algorithm based approach. In Proceedings of the 2013 Chinese Automation Congress, Changsha, China, 7–8 November 2013; pp. 415–419. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–12 December 2001; Volume 1, pp. 1511–1518. [Google Scholar] [CrossRef]
- Sharma, G.; Wu, W.; Dalal, E.N. The CIEDE2000 color-difference formula: Implementation notes, supplementary test data, and mathematical observations. Color Res. Appl. 2005, 30, 21–30. [Google Scholar] [CrossRef]
- BURST. Available online: https://burst.shopify.com/ (accessed on 1 February 2018).
- Sachs, T.S.; Kakarala, R.; Castleman, S.L.; Rajan, D. A Data-driven Approach to Understanding Skill in Photographic Composition. In Proceedings of the Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010; Springer: Berlin/Heidelberg, Germany, 2011; pp. 112–121. [Google Scholar]



















































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resolution | Time |
|---|---|
| 960 × 720 | 5.658 |
| 320 × 240 | 0.207 |
| 192 × 144 | 0.073 |
| Operating System | Windows 10 64bit |
| Processor | Intel(R) Core(TM)i7-6700 CPU 3.40GHz |
| Display card | NVIDIA GeForce GTX 960 |
| Memory | 32GB |
| Development Platform | Android Studio, Eclipse |
| Mobile Device | Sony Xperia Z2 |
| Programming Language | Java |
| Library | OpenCV-3.4.1, Jama |
| Composition Method | Score | Composition Method | Score |
|---|---|---|---|
| horizontal | 100 | rule of thirds | 98 |
| triangle | 91 | focus | 75 |
| intensity (90) | 76 | contrast (50) | 98 |
| Composition Method | Score | Composition Method | Score |
|---|---|---|---|
| central | 98 | triangle | 89 |
| vanishing | 97 | focus | 47 |
| intensity (90) | 91 | contrast (50) | 95 |
| Composition Method | Score | Composition Method | Score |
|---|---|---|---|
| Horizontal | 100 | vanishing | 91 |
| Frame within a Frame | 71 | focus | 83 |
| intensity (90) | 94 | contrast (50) | 96 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.-F.; Yang, C.-K.; Chang, Y.-Z. Photo Composition with Real-Time Rating. Sensors 2020, 20, 582. https://doi.org/10.3390/s20030582
Li Y-F, Yang C-K, Chang Y-Z. Photo Composition with Real-Time Rating. Sensors. 2020; 20(3):582. https://doi.org/10.3390/s20030582
Chicago/Turabian StyleLi, Yi-Feng, Chuan-Kai Yang, and Yi-Zhen Chang. 2020. "Photo Composition with Real-Time Rating" Sensors 20, no. 3: 582. https://doi.org/10.3390/s20030582
APA StyleLi, Y.-F., Yang, C.-K., & Chang, Y.-Z. (2020). Photo Composition with Real-Time Rating. Sensors, 20(3), 582. https://doi.org/10.3390/s20030582