A Neural Network with Convolutional Module and Residual Structure for Radar Target Recognition Based on High-Resolution Range Profile


Abstract
1. Introduction
2. One-Dimensional Convolutional Neural Network
- Normalize the amplitude of HRRP. The data after amplitude normalization of the nth HRRP is expressed as , where denotes the maximum absolute value of all elements in HRRP.
- Subtract the mean value of the normalized HRRP data from the respective element.
3. Model Analysis and Design
3.1. Design of Convolutional Module
3.2. Design of Loss Function
| Algorithm 1. The neural network algorithm with convolution module and residual structure |
| Input: Training samples . Initialized parameters in convolution kernel. Weight matrix . The class center of features. Hyper-parameter , in . Learning rate for feature center in . Weight and learning rate in network. The number of iteration . |
| Output: The parameters . |
| Step 1: while not converge do |
| Step 2: . |
| Step 3: compute the joint loss by . |
| Step 4: compute the backpropagation error for each by . |
| Step 5: update the parameters by . |
| Step 6: update the parameters by . |
| Step 7: update the parameters by . |
| Step 8: end while |
3.3. Design of Model Structure
4. Experimental Simulation and Analysis
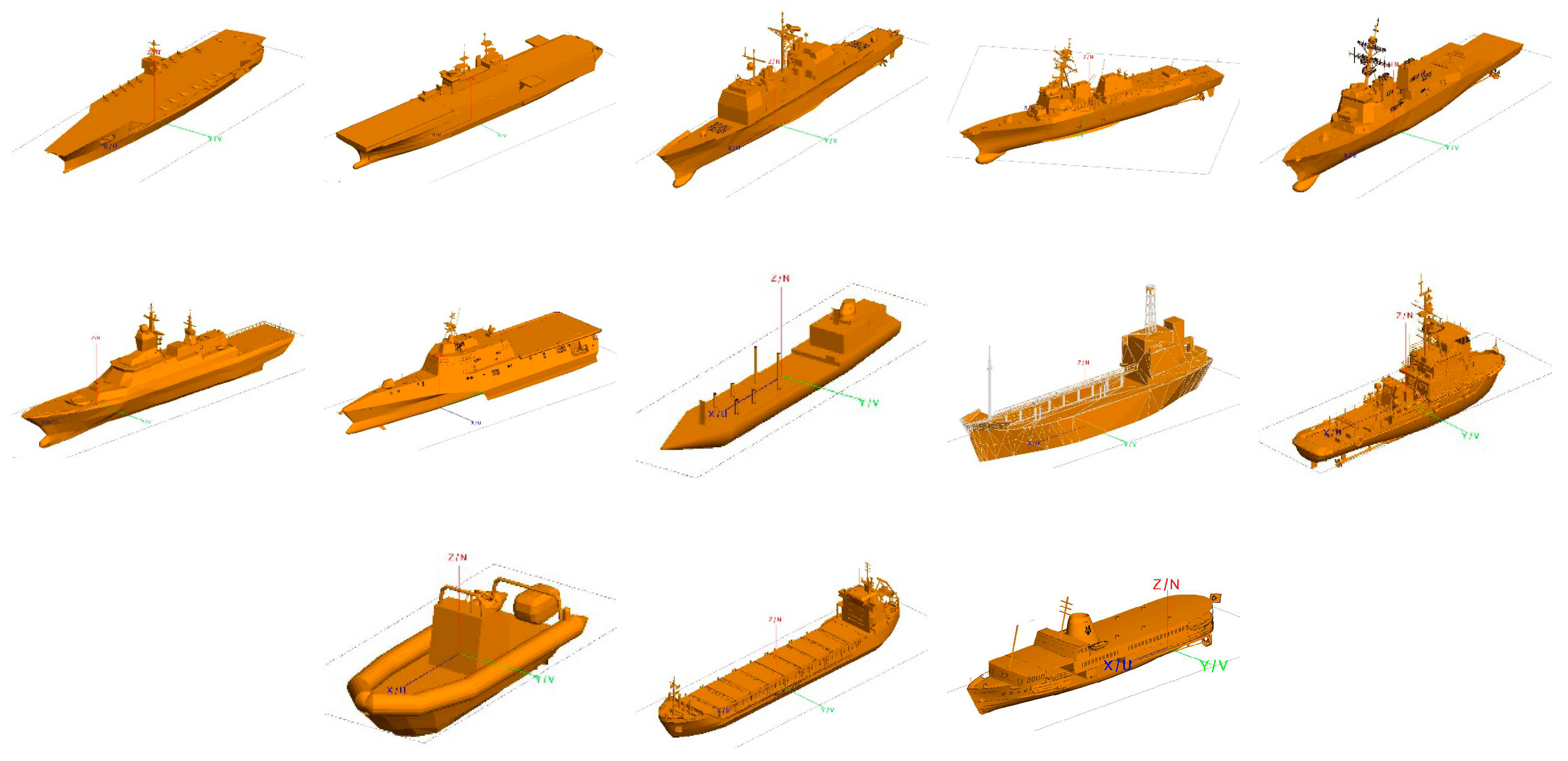
4.1. Data Set Construction
4.2. Model Identification Performance Analysis
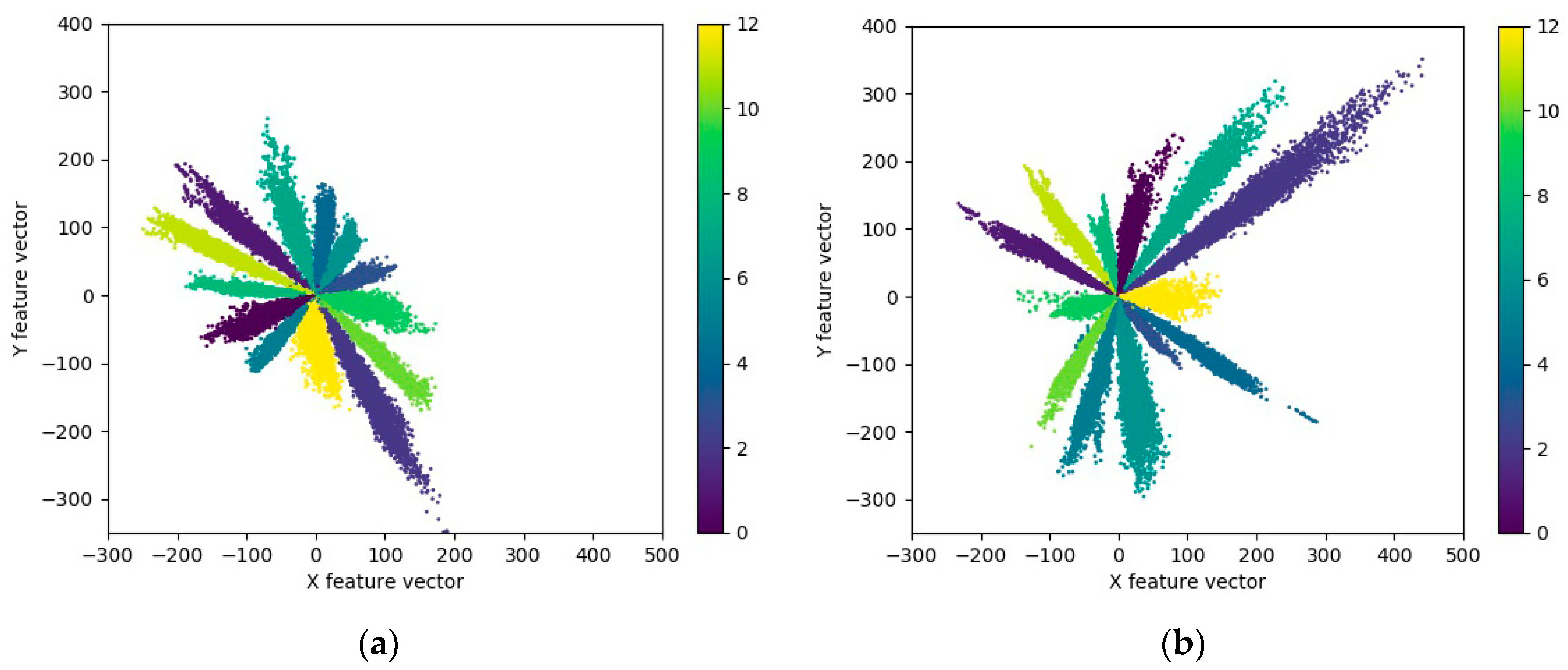
4.2.1. Effect of Loss Function on Recognition Effect
Classification Effect Comparison of Loss Function and Loss Function
Classification Effect Comparison of Loss Function and Loss Function
Classification Effect Comparison between Loss Function and Others
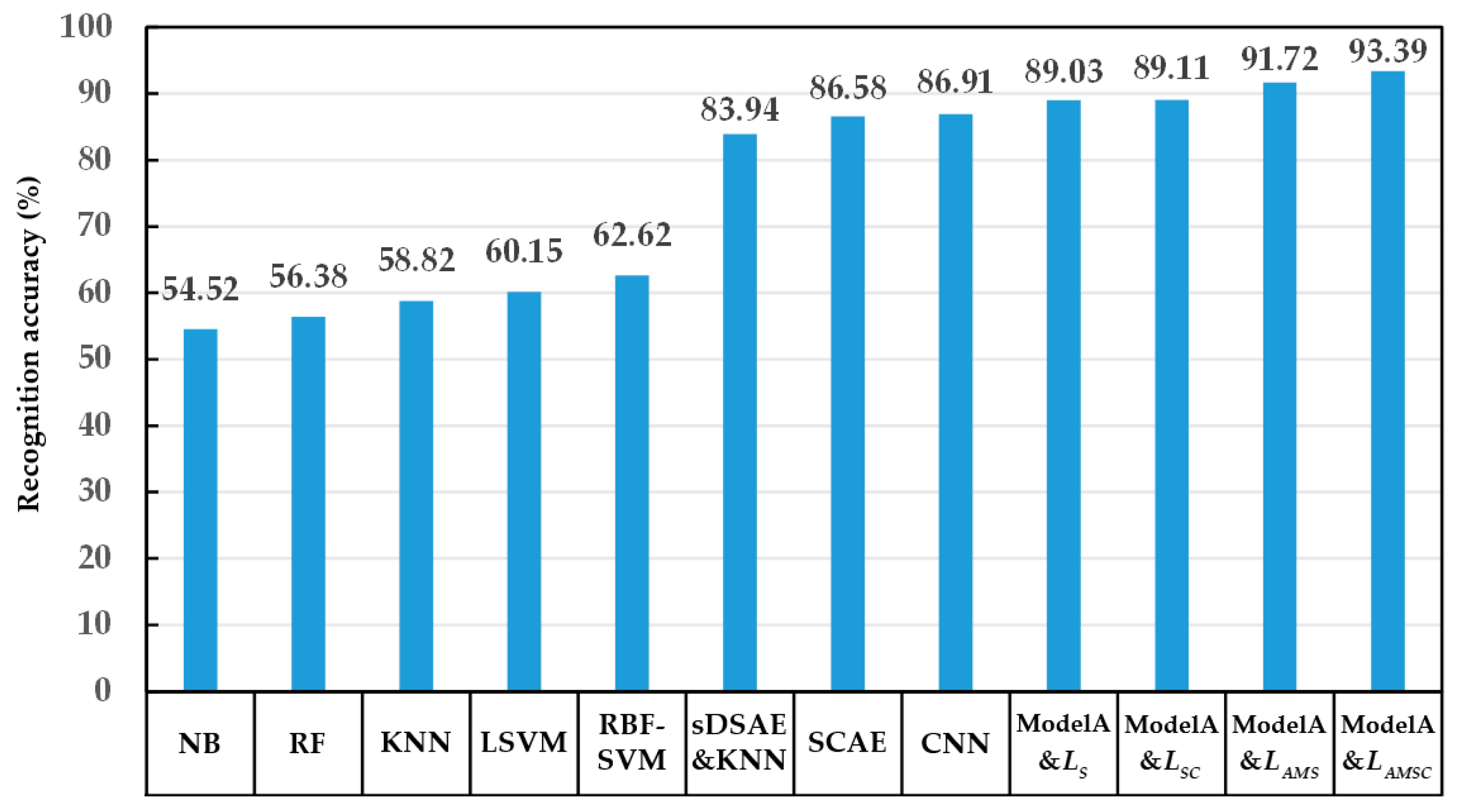
4.2.2. Analysis of the Recognition Effect of the Presented Model and the Comparison Model
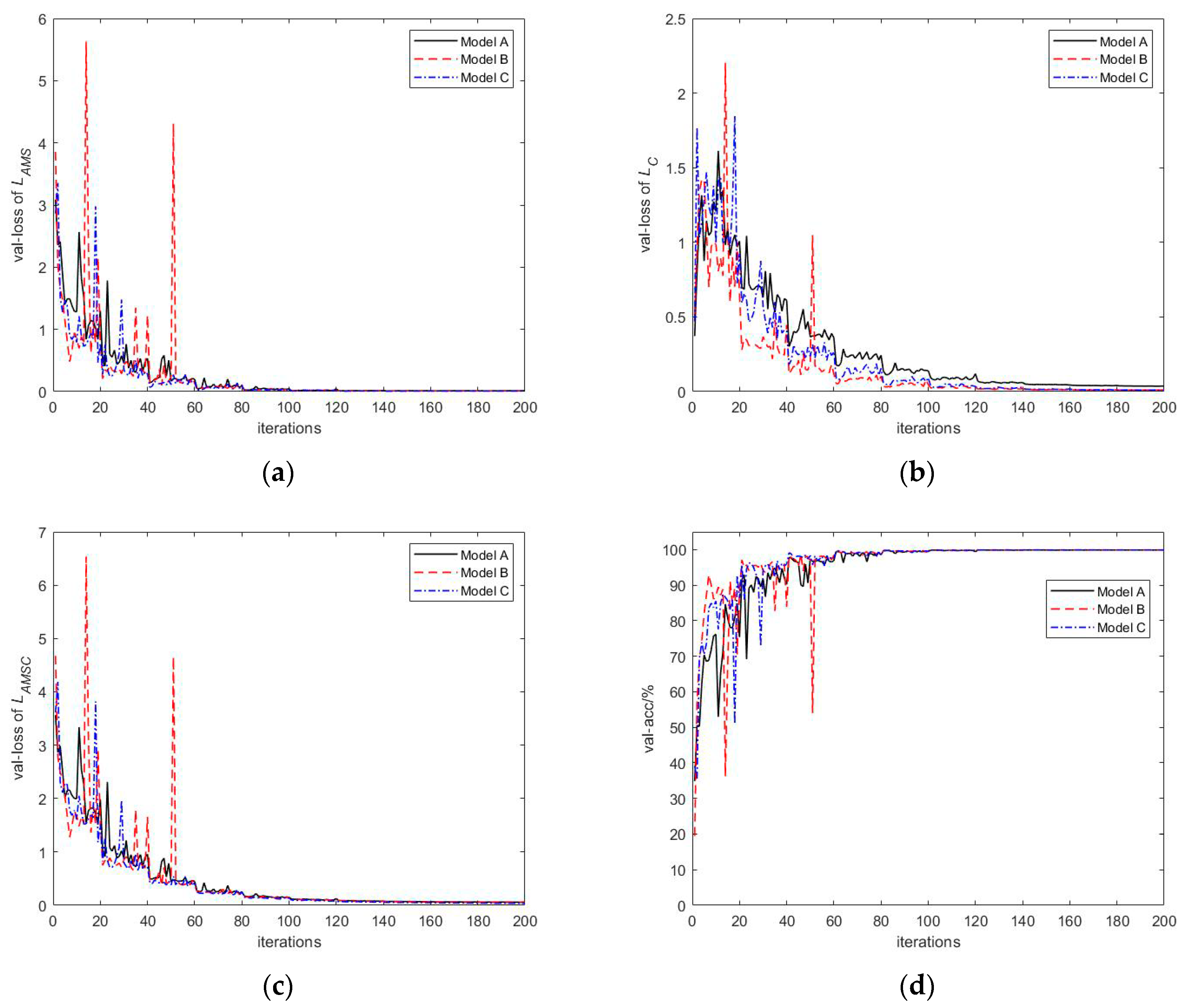
4.2.3. Effect of Model Complexity on Recognition Effect
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Li, Y.; Yu, L.; Yang, Y. Method of Aerial Target Length Extraction Based on High Resolution Range Profile. Mod. Radar 2018, 07, 32–35. [Google Scholar] [CrossRef]
- Wei, C.; Duan, F.; Liu, X. Length estimation method of ship target based on wide-band radar’s HRRP. Syst. Eng. Electron. 2018, 40, 1960–1965. [Google Scholar] [CrossRef]
- He, S.; Zhao, H.; Zhang, Y. Signal Separation for Target Group in Midcourse Based on Time-frequency Filtering. J. Radars 2015, 05, 545–551. [Google Scholar] [CrossRef]
- Chen, M.; Wang, S.; Ma, T.; Wu, X. Fast analysis of electromagnetic scattering characteristics in spatial and frequency domains based on compressive sensing. Acta Phys. Sin. 2014, 17, 50–54. [Google Scholar] [CrossRef]
- Liu, S. Research on Feature Extraction and Recognition Performance Enhancement Algorithms Based on High Range Resolution Profile. Ph.D. Dissertation, National University of Defense Technology, Changsha, China, 2016. [Google Scholar]
- Wu, J.; Chen, Y.; Dai, D.; Chen, S.; Wang, X. Target Recognition for Polarimetric HRRP Based on Fast Density Search Clustering Method. J. Electron. Inf. Technol. 2016, 10, 2461–2467. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, H.; Xu, F.; Jin, Y. Polarimetric SAR Image Classification Using Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1935–1939. [Google Scholar] [CrossRef]
- Pei, J.; Huang, Y.; Sun, Z.; Zhang, Y.; Yang, J.; Yeo, T. Multiview synthetic aperture radar automatic target recognition optimization: Modeling and implementation. IEEE Trans. Geosci. Remote. Sens. 2018, 56, 6425–6439. [Google Scholar] [CrossRef]
- Fu, H.; Li, Y.; Wang, Y.; Li, P. Maritime Ship Targets Recognition with Deep Learning. In Proceedings of the 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 9297–9302. [Google Scholar]
- Xing, S.; Zhang, S. Ship model recognition based on convolutional neural networks. In Proceedings of the 2018 IEEE International Conference on Mechatronics and Automation (ICMA), Changchun, China, 5–8 August 2018; pp. 144–148. [Google Scholar]
- Luo, C.; Yu, L.; Ren, P. A Vision-Aided Approach to Perching a Bioinspired Unmanned Aerial Vehicle. IEEE Trans. Ind. Electron. 2018, 65, 3976–3984. [Google Scholar] [CrossRef]
- Li, C.; Hao, L. High-Resolution, Downward-Looking Radar Imaging Using a Small Consumer Drone. In Proceedings of the 2016 IEEE Antennas and Propagation Society International Symposium (APSURSI), Fajardo, Puerto Rico, 26 June–1 July 2016; pp. 2037–2038. [Google Scholar]
- Yin, H.; Guo, Z. Radar HRRP target recognition with one-dimensional CNN. Telecommun. Eng. 2018, 58, 1121–1126. [Google Scholar] [CrossRef]
- Karabayir, O.; Yucedag, O.M.; Kartal, M.Z.; Serim, H.A. Convolutional neural networks-based ship target recognition using high resolution range profiles. In Proceedings of the 18th International Radar Symposium (IRS), Prague, Czech Republic, 28–30 June 2017; pp. 1–9. [Google Scholar]
- Lunden, J.; Koivunen, V. Deep learning for HRRP-based target recognition in multistatic radar systems. In Proceedings of the 2016 IEEE Radar Conference, Philadelphia, PA, USA, 2–6 May 2016; pp. 1–6. [Google Scholar]
- Gai, Q.; Han, Y.; Nan, H.; Bai, Z.; Sheng, W. Polarimetric radar target recognition based on depth convolution neural network. Chin. J. Radio Sci. 2018, 33, 575–582. [Google Scholar] [CrossRef]
- Visentin, T.; Sagainov, A.; Hasch, J.; Zwick, T. Classification of objects in polarimetric radar images using CNNs at 77 GHz. In Proceedings of the 2017 IEEE Asia Pacific Microwave Conference (APMC), Kuala Lumpur, Malaysia, 13–16 November 2017; pp. 356–359. [Google Scholar]
- Yang, Y.; Sun, J.; Yu, S.; Peng, X. High Resolution Range Profile Target Recognition Based on Convolutional Neural Network. Mod. Radar 2017, 39, 24–28. [Google Scholar] [CrossRef]
- Yu, S.; Xie, Y. Application of a convolutional autoencoder to half space radar hrrp recognition. In Proceedings of the 2018 International Conference on Wavelet Analysis and Pattern Recognition (ICWAPR), Chengdu, China, 15–18 July 2018; pp. 48–53. [Google Scholar]
- Feng, B.; Chen, B.; Liu, H. Radar HRRP target recognition with deep networks. Pattern Recogn. 2017, 61, 379–393. [Google Scholar] [CrossRef]
- Wang, C.; Hu, Y.; Li, X.; Wei, W.; Zhao, H. Radar HRRP target recognition based on convolutional sparse coding and multi-classifier fusion. Syst. Eng. Electron 2018, 11, 2433–2437. [Google Scholar] [CrossRef]
- Zhang, H. RF Stealth Based Airborne Radar System Simulation and HRRP Target Recognition Research. Master’s Dissertation, Nanjing University of Aeronautics and Astronautics, Nanjing, China, 2016. [Google Scholar]
- Zhang, J.; Wang, H.; Yang, H. Dimension reduction method of high resolution range profile based on Autoencoder. J. PLA Univ. Sci. Technol. (Nat. Sci. Ed.) 2016, 17, 31–37. [Google Scholar] [CrossRef]
- Zhao, F.; Liu, Y.; Huo, K. Radar Target Recognition Based on Stacked Denoising Sparse Autoencoder. J. Radars 2017, 6, 149–156. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics (AISTATS), Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the 31st AAAI Conference on Artificial Intelligence (AAAI), San Francisco, CA, USA, 4–10 February 2017; pp. 4278–4284. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. SphereFace: Deep hypersphere embedding for face recognition. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6738–6746. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Yang, M. Large-Margin Softmax Loss for Convolutional Neural Networks. In Proceedings of the 33th International Conference on Machine Learning (ICML), New York, NY, USA, 19–24 June 2016; pp. 1–10. [Google Scholar]
- Wang, F.; Xiang, X.; Cheng, J.; Yuille, A.L. NormFace: L2 Hypersphere Embedding for Face Verification. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1041–1049. [Google Scholar]
- Liu, Y.; Liu, Q. Convolutional neural networks with large-margin softmax loss function for cognitive load recognition. In Proceedings of the 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 4045–4049. [Google Scholar]
- Wang, F.; Cheng, J.; Liu, W.; Liu, H. Additive Margin Softmax for Face Verification. IEEE Signal Process. Lett. 2018, 25, 926–930. [Google Scholar] [CrossRef]
- Chen, F.; Du, L.; Bao, Z. Modified KNN rule with its application in radar HRRP target recognition. J. Xidian Univ. 2007, 34, 681–686. [Google Scholar]
- Bao, Z. Study of Radar Target Recognition Based on Continual Learning. Master Dissertation, Xidian University, Xi’an, China, 2018. [Google Scholar]
- Huang, Y.; Zhao, K.; Jiang, X. RBF-SVM feature selection arithmetic based on kernel space mean inter-class distance. Appl. Res. Comput. 2012, 29, 4556–4559. [Google Scholar] [CrossRef]
- Yao, L.; Wu, Y.; Cui, G. A New Radar HRRP Target Recognition Method Based on Random Forest. J. Zhengzhou Univ. (Eng. Sci.) 2014, 35, 105–108. [Google Scholar] [CrossRef]
- Yang, K.; Li, S.; Zhang, K.; Niu, S. Research on Anti-jamming Recognition Method of Aerial Infrared Target Based on Naïve Bayes Classifier. Flight Control Detect. 2019, 2, 62–70. [Google Scholar]
- Liu, X. The application of a multi-layers pre-training convolutional neural network in image recognition. Master Dissertation, South–Central University for Nationalities, Wuhan, China, 2018. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Output Size | Structure | Number of Parameters | ||
|---|---|---|---|---|---|
| Initial convolutional layer | 128 × 1 × 9 | 7 × 1, 9, s = 2 | 63 + 36 | ||
| Left branch | Right branch | ||||
| Convolutional module 1 | 64 × 1 × 18 | 1 × 1, 9 3 × 1, 3, s = 2, x = 3 1 × 1, 12 | 1 × 1, 15, s = 2 | 405 + 180 | |
| Convolutional module 2 | 32 × 1 × 36 | 1 × 1, 18 3 × 1, 6, s = 2, x = 3 1 × 1, 24 | 1 × 1, 30, s = 2 | 1620 + 360 | |
| Convolutional module 3 | 16 × 1 × 72 | 1 × 1, 36 3 × 1, 12, s = 2, x = 3 1 × 1, 48 | 1 × 1, 60, s = 2 | 6480 + 720 | |
| Convolutional module 4 | 8 × 1 × 144 | 1 × 1, 72 3 × 1, 24, s = 2, x = 3 1 × 1, 96 | 1 × 1, 120, s = 2 | 25,920 + 1440 | |
| Fully connected layer 1 | 144 | Global max pooling and global average pooling | 0 | ||
| Fully connected layer 2 | 2 | 288 | |||
| Output layer | 13 | Joint loss function | 26 | ||
| Total number of parameters | 37,538 | ||||
| Loss Function and Parameter | Recognition Accuracy(%) | |||
|---|---|---|---|---|
| SNR = 0 dB | SNR = 5 dB | SNR = 10 dB | SNR = 15 dB | |
| 60.32 | 89.03 | 98.06 | 99.72 | |
| , = 0.001 | 60.45 | 89.10 | 98.07 | 99.73 |
| , = 0.005 | 60.38 | 89.08 | 98.06 | 99.75 |
| , = 0.01 | 60.42 | 89.08 | 98.07 | 99.75 |
| , = 0.05 | 60.46 | 89.06 | 98.08 | 99.74 |
| , = 0.1 | 60.40 | 89.11 | 98.09 | 99.73 |
| , = 0.2 | 60.35 | 89.10 | 98.09 | 99.73 |
| , = 0.4 | 60.37 | 89.08 | 98.07 | 99.74 |
| , = 0.6 | 60.40 | 89.08 | 98.08 | 99.72 |
| , = 0.8 | 60.38 | 89.09 | 98.07 | 99.74 |
| , = 1 | 60.35 | 89.09 | 98.07 | 99.75 |
| Loss Function and Parameter | Recognition Accuracy(%) | |||
|---|---|---|---|---|
| SNR = 0 dB | SNR = 5 dB | SNR = 10 dB | SNR = 15 dB | |
| , = 0.001, = 0.05 | 71.26 | 93.39 | 98.91 | 99.89 |
| , = 0.01, = 0.05 | 70.58 | 93.16 | 99.03 | 99.89 |
| , = 0.1, = 0.05 | 72.28 | 92.90 | 99.08 | 99.91 |
| , = 0.2, = 0.05 | 69.70 | 92.46 | 98.89 | 99.91 |
| , = 0.3, = 0.05 | 70.61 | 93.09 | 99.00 | 99.90 |
| , = 0.4, = 0.05 | 71.14 | 92.36 | 98.99 | 99.90 |
| , = 0.6, = 0.05 | 69.78 | 92.49 | 99.00 | 99.88 |
| , = 0.8, = 0.05 | 70.92 | 92.85 | 99.08 | 99.91 |
| , = 1, = 0.05 | 71.41 | 93.26 | 99.06 | 99.91 |
| 65.03 | 91.72 | 98.84 | 99.84 | |
| 60.46 | 89.11 | 98.09 | 99.75 | |
| 60.32 | 89.03 | 98.06 | 99.72 | |
| Stage | Output Size | Structure | Number of Parameters |
|---|---|---|---|
| Convolutional layer 1 | 256 × 1 × 8 | 3 × 1, 8, s = 1 | 32 + 32 |
| Pooling layer 1 | 128 × 1 × 8 | 2 × 1, s = 2 | 0 |
| Convolutional layer 2 | 128 × 1 × 16 | 3 × 1, 16, s = 1 | 400 + 64 |
| Pooling layer 2 | 64 × 1 × 16 | 2 × 1, s = 2 | 0 |
| Convolutional layer 3 | 64 × 1 × 32 | 3 × 1, 32, s = 1 | 1568 + 128 |
| Pooling layer 3 | 32 × 1 × 32 | 2 × 1, s = 2 | 0 |
| Convolutional layer 4 | 32 × 1 × 64 | 3 × 1, 64, s = 1 | 6208 + 256 |
| Pooling layer 4 | 16 × 1 × 64 | 2 × 1, s = 2 | 0 |
| Convolutional layer 5 | 16 × 1 × 64 | 1 × 1, 64, s = 1 | 4160 + 256 |
| Pooling layer 5 | 8 × 1 × 64 | 2 × 1, s = 2 | 0 |
| Fully connected layer 1 | 64 | 32,832 | |
| Fully connected layer 2 | 2 | 130 | |
| Output layer | 13 | Ls | 39 |
| Total number of parameters | 46,105 | ||
| Stage | Output Size | Number of Parameters |
|---|---|---|
| Hidden layer 1 | 150 × 1 | 38,550 |
| Hidden layer 2 | 100 × 1 | 15,100 |
| Hidden layer 3 | 50 × 1 | 5050 |
| Hidden layer 4 | 10 × 1 | 510 |
| Total number of parameters | 59,210 | |
| Stage | Output Size | Structure | Number of Parameters |
|---|---|---|---|
| Convolutional layer 1 | 256 × 1 × 128 | 5 × 1, 128, s = 1 | 768 |
| Pooling layer 1 | 128 × 1 × 128 | 2 × 1, s = 2 | 0 |
| Convolutional layer 2 | 128 × 1 × 64 | 5 × 1, 64, s = 1 | 41,024 |
| Pooling layer 2 | 64 × 1 × 64 | 2 × 1, s = 2 | 0 |
| Convolutional layer 3 | 64 × 1 × 32 | 3 × 1, 32, s = 1 | 6176 |
| Pooling layer 3 | 32 × 1 × 32 | 2 × 1, s = 2 | 0 |
| Convolutional layer 4 | 32 × 1 × 16 | 3 × 1, 16, s = 1 | 1552 |
| Pooling layer 4 | 16 × 1 × 16 | 2 × 1, s = 2 | 0 |
| Convolutional layer 5 | 16 × 1 × 8 | 1 × 1, 8, s = 1 | 136 |
| Pooling layer 5 | 8 × 1 × 8 | 2 × 1, s = 2 | 0 |
| Output layer | 13 | Ls | 845 |
| Total number of parameters | 50,501 | ||
| Model Name | Number of Parameters | Computational Time for Each HRRP (us) | Recognition Accuracy (%) | |||
|---|---|---|---|---|---|---|
| SNR = 0 dB | SNR = 5 dB | SNR = 10 dB | SNR = 15 dB | |||
| Model A&LAMSC | 37538 | 258 | 72.28 | 93.39 | 99.08 | 99.91 |
| CNN | 46105 | 69 | 58.22 | 86.91 | 95.51 | 98.79 |
| SCAE | 50501 | 47 | 54.78 | 86.58 | 94.44 | 98.78 |
| sDSAE&KNN | 59210 | 68 | 46.50 | 83.94 | 93.44 | 98.65 |
| Stage | Output Size | Structure | Number of Parameters | ||
|---|---|---|---|---|---|
| Initial convolutional layer | 128 × 1 × 9 | 7 × 1, 9, s = 2 | 63 + 36 | ||
| Left branch | Right branch | ||||
| Convolutional module 1 | 64 × 1 × 18 | 1 × 1, 9 3 × 1, 3, s = 2, x = 3 1 × 1, 12 | 1 × 1, 15, s = 2 | 405 + 180 | |
| Convolutional module 2 | 32 × 1 × 36 | 1 × 1, 18 3 × 1, 6, s = 2, x = 3 1 × 1, 24 | 1 × 1, 30, s = 2 | 1620 + 360 | |
| Convolutional module 3 | 16 × 1 × 72 | 1 × 1, 36 3 × 1, 12, s = 2, x = 3 1 × 1, 48 | 1 × 1, 60, s = 2 | 6480 + 720 | |
| Convolutional module 4 | 8 × 1 × 144 | 1 × 1, 72 3 × 1, 24, s = 2, x = 3 1 × 1, 96 | 1 × 1, 120, s = 2 | 25,920 + 1440 | |
| Convolutional module 5 | 4 × 1 × 288 | 1 × 1, 144 3 × 1, 48, s = 2, x = 3 1 × 1, 192 | 1 × 1, 240, s = 2 | 103,680 + 2880 | |
| Fully connected layer 1 | 144 | Global max pooling and global average pooling | 0 | ||
| Fully connected layer 2 | 2 | 578 | |||
| Output layer | 13 | Joint loss function | 26 | ||
| Total number of parameters | 144,353 | ||||
| Stage | Output Size | Structure | Number of Parameters | ||
|---|---|---|---|---|---|
| Initial convolutional layer | 128 × 1 × 18 | 7 × 1, 18, s = 2 | 126 + 72 | ||
| Left branch | Right branch | ||||
| Convolutional module 1 | 64 × 1 × 36 | 1 × 1, 18 3 × 1, 3, s = 2, x = 6 1 × 1, 24 | 1 × 1, 30, s = 2 | 1458 + 360 | |
| Convolutional module 2 | 32 × 1 × 72 | 1 × 1, 36 3 × 1, 6, s = 2, x = 6 1 × 1, 48 | 1 × 1, 60, s = 2 | 5832 + 720 | |
| Convolutional module 3 | 16 × 1 × 144 | 1 × 1, 72 3 × 1, 12, s = 2, x = 6 1 × 1, 96 | 1 × 1, 120, s = 2 | 23,328 + 1440 | |
| Convolutional module 4 | 8 × 1 × 288 | 1 × 1, 144 3 × 1, 24, s = 2, x = 6 1 × 1, 192 | 1 × 1, 240, s = 2 | 93,312 + 2880 | |
| Fully connected layer 1 | 288 | Global max pooling and global average pooling | 0 | ||
| Fully connected layer 2 | 2 | 578 | |||
| Output layer | 13 | Joint loss function | 26 | ||
| Total number of parameters | 13,0132 | ||||
| Model Name | Number of Parameters | Computational Time for Each HRRP (us) | Recognition Accuracy (%) | |||
|---|---|---|---|---|---|---|
| SNR = 0 dB | SNR = 5 dB | SNR = 10 dB | SNR = 15 dB | |||
| Model A | 37538 | 258 | 72.28 | 92.90 | 99.08 | 99.91 |
| Model B | 144353 | 326 | 77.12 | 95.28 | 99.49 | 99.93 |
| Model C | 130132 | 323 | 76.31 | 95.50 | 99.43 | 99.93 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, Z.; Li, S.; Li, X.; Dan, B.; Wang, X. A Neural Network with Convolutional Module and Residual Structure for Radar Target Recognition Based on High-Resolution Range Profile. Sensors 2020, 20, 586. https://doi.org/10.3390/s20030586
Fu Z, Li S, Li X, Dan B, Wang X. A Neural Network with Convolutional Module and Residual Structure for Radar Target Recognition Based on High-Resolution Range Profile. Sensors. 2020; 20(3):586. https://doi.org/10.3390/s20030586
Chicago/Turabian StyleFu, Zhequan, Shangsheng Li, Xiangping Li, Bo Dan, and Xukun Wang. 2020. "A Neural Network with Convolutional Module and Residual Structure for Radar Target Recognition Based on High-Resolution Range Profile" Sensors 20, no. 3: 586. https://doi.org/10.3390/s20030586
APA StyleFu, Z., Li, S., Li, X., Dan, B., & Wang, X. (2020). A Neural Network with Convolutional Module and Residual Structure for Radar Target Recognition Based on High-Resolution Range Profile. Sensors, 20(3), 586. https://doi.org/10.3390/s20030586