A Review on Auditory Perception for Unmanned Aerial Vehicles



Abstract
1. Introduction
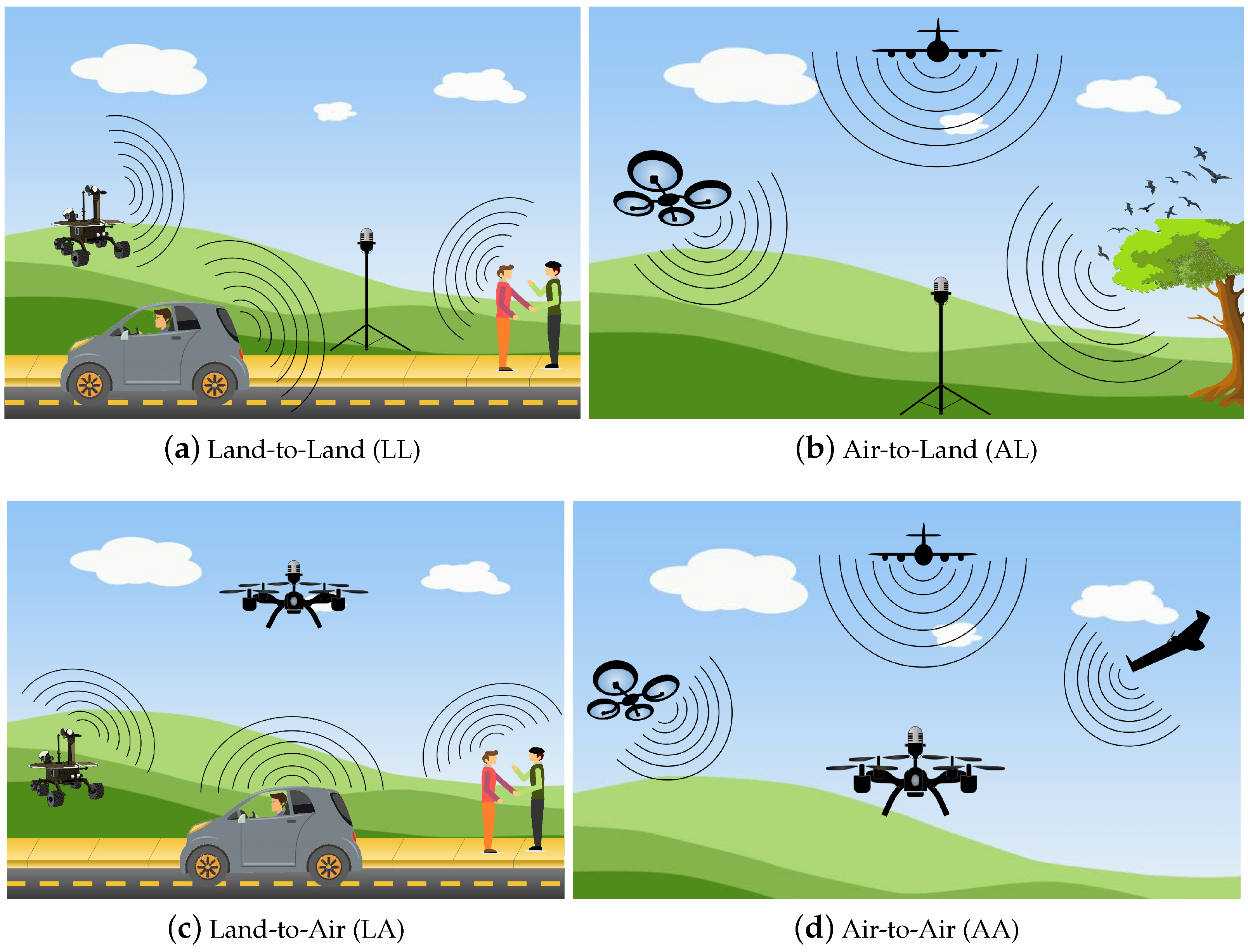
- 1.
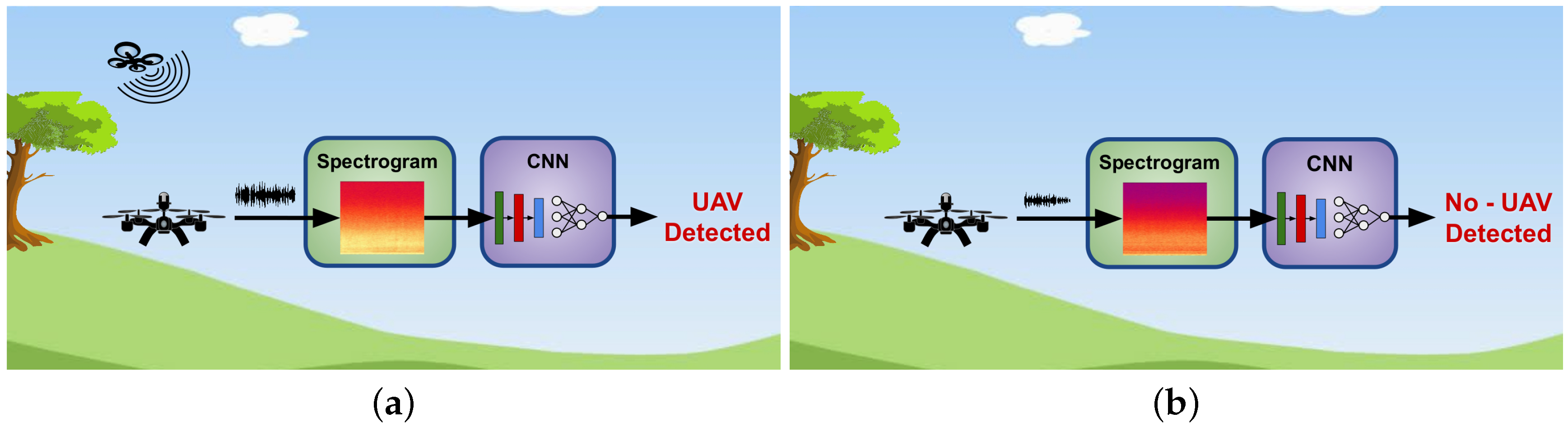
- Air-to-Land (AL): The sound originates in the air, and it is sensed by microphones on the land.
- 2.
- Land-to-Air (LA): The sound originates on the land, and it is sensed by microphones on-board a UAV.
- 3.
- Air-to-Air (AA): The sound originates in the air, and it is sensed by microphones on-board a UAV.
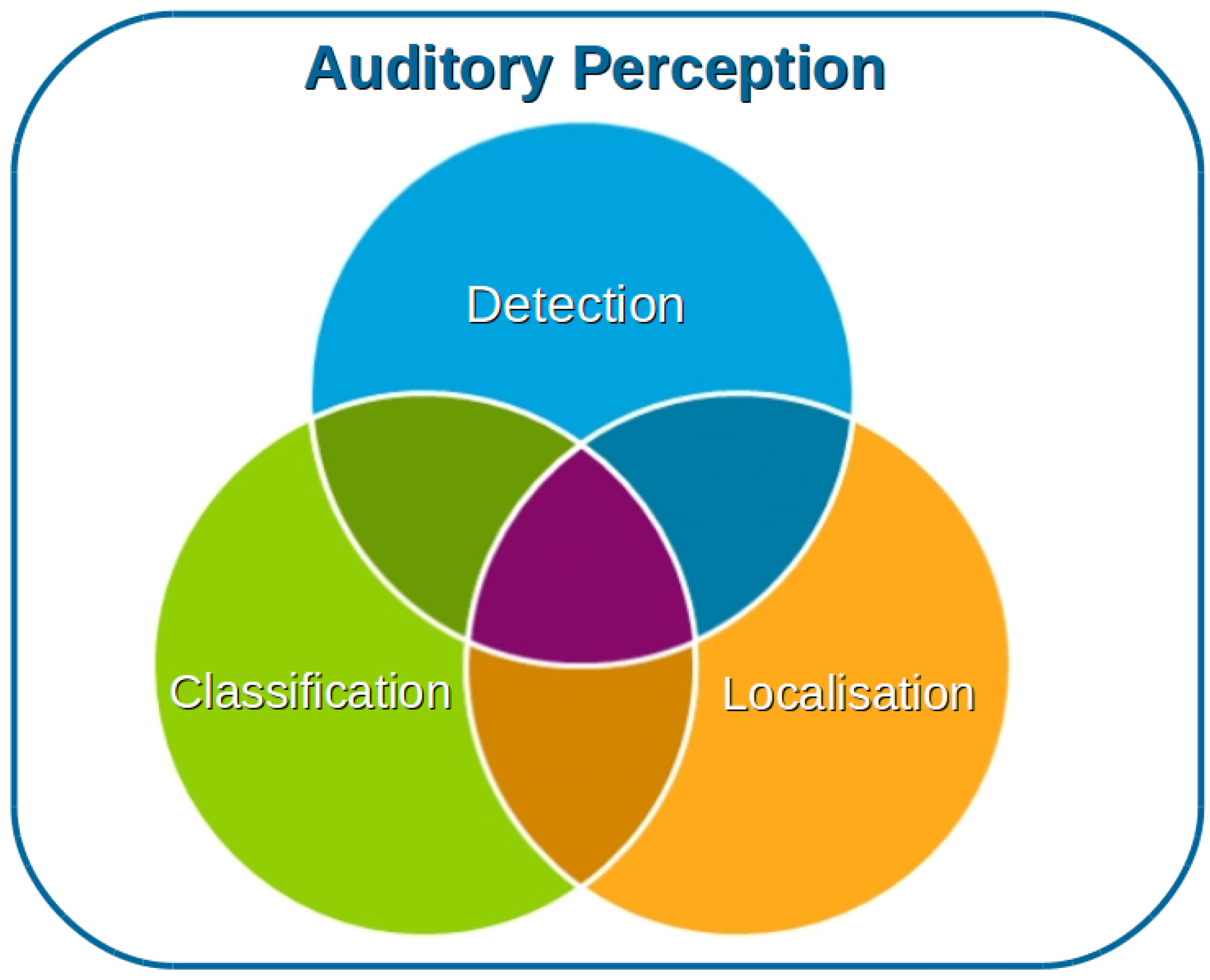
- 1.
- Detection: The signal recorded by the microphones is processed to determine whether a sound of interest is present in the scene.
- 2.
- Classification: The signal recorded by the microphones is processed to determine the entity from which the sound originated; for instance, a person, an animal, a UAV, etc.
- 3.
- Localization: The signal recorded by the microphones is processed to determine the location of the source. This could be represented by a vector describing the direction of the source with regards to the microphone, with the magnitude representing the distance from the microphone to the source. The angle and a depth value could also be used instead.
2. Theoretical Background on Audio Techniques and Hardware
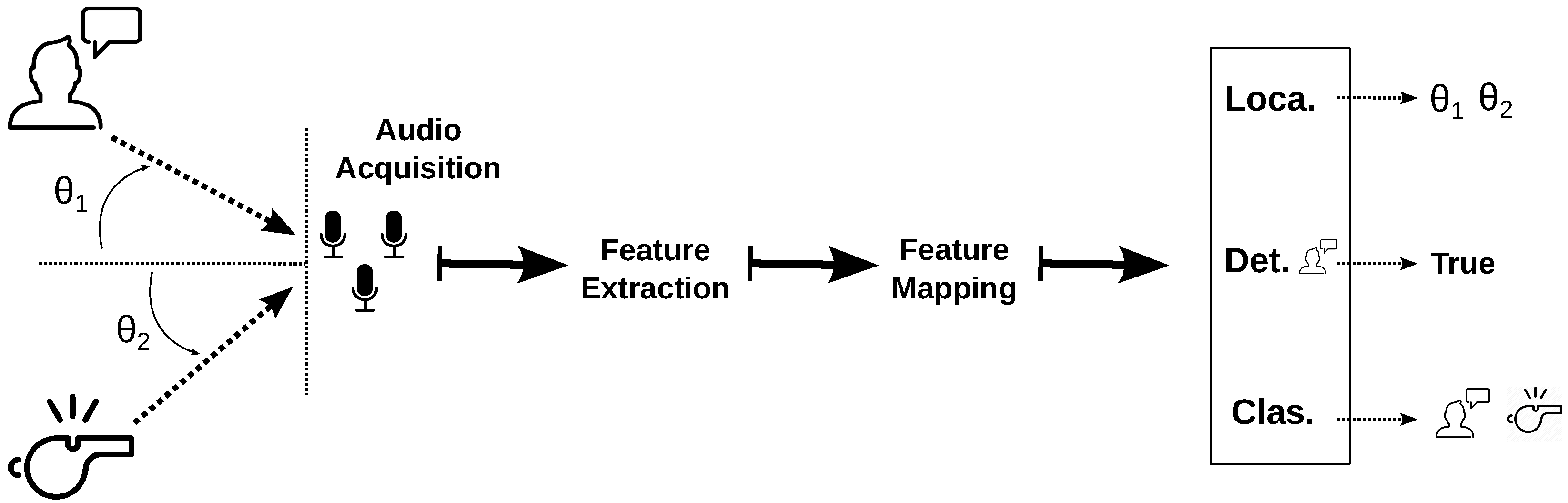
2.1. Auditory Perception Paradigm
2.1.1. Audio Acquisition
2.1.2. Feature Extraction
- Time-frequency (TF) spectrogram: This is a combination of the temporal and frequency domains in one data matrix. The recorded signal is windowed (either by the Hann or Hamming window function), and each window is transformed into the frequency domain via the Fourier transform. Since in most UAV auditory application scenarios, it is not required that the transformed recorded signal is transformed back into the time domain, several methods for data augmentation can be used in the transformation. The number of windows can be incremented by overlapping them, with a 50% overlap being a popular choice. In turn, the size of the windows can be incremented as well, which results in higher frequency resolution. It is important to mention that recently, because of the advent of end-to-end deep-learning-based solutions for auditory perception, it has become common not to calculate any features and to use the transformed signal as the input for the next step of processing. Thus, the TF spectrogram has gained popularity, since it presents not only the spectral shape of the acquired signal, but also how this shape changes through time. In this regard, it provides a two-fold signature of the sound source. In addition, the following features can also be extracted as a type of time-feature matrix if the frequency domain is not representative enough for the task at hand.
- Time difference of arrival between microphones (TDOA): This is the time difference between two captured recordings. There are several ways of calculating it, such as measuring the time difference between the moments of zero-level crossings of the signals [28] or between the onset times calculated from each signal [29]. If the recorded signals are narrowband at frequency f, the TDOA is equivalent to the inter-microphone phase difference (IPD), which can be calculated by [30], where is the phase of recording x at frequency f in radians. Another popular way of calculating the TDOA is the generalized cross-correlation with phase transform (GCC-PHAT) [31], which maximizes the cross-correlogram between the two recorded signals (CC), computed in the frequency domain as , where X is the Fourier transform of recorded signal x.
- Inter-microphone level difference (ILD): This is the difference spectrum () between the two short-time-frequency-transformed recorded signals, calculated as . It can also be calculated in the overtone domain [32], where a frequency is an overtone of another f when (given that ). In this domain, the harmonic structures of certain sounds (such as the noise of a UAV motor) are exploited, since the magnitudes between overtones are highly correlated through time.
- Spectral cues: This is a popular term used to refer to a feature set composed of the IPD and the ILD in conjunction.
- Filter bank: The outputs of a set of filters are spaced logarithmically in the frequency domain. The logarithmic spacing is usually set on the Mel-scale [33], which is popularly used to mimic human hearing. A filter bank provides a feature vector with a substantial smaller number of dimensions than the whole frequency spectrum. Additionally, the difference between the filter banks of two recorded signals can also be used as a feature set [34], which has been shown to be robust against noise.
- Mel-frequency cepstral coefficients (MFCCs): An important assumption of a feature vector is that every dimension is non-correlated to every other. Unfortunately, the outputs of a filter bank may be highly correlated to one another. To this effect, the discrete cosine transform is typically applied to the output of a Mel-spaced filter bank to remove correlation between the dimensions of the feature vector, resulting in a set of MFCCs [33]. These features have been frequently used for audio applications and, as seen later in this work, auditory perception in UAVs is no exception.
2.1.3. Feature Mapping
2.2. Relevant Localization Techniques
2.3. Relevant Detection/Classification Techniques
3. On the Number of Microphones and UAV Models
4. On-Ground Auditory Perception of UAVs (Air to Land)
5. Auditory Perception from a UAV (Land to Air)
- 1.
- (Optionally) carry out noise removal from input signals, such as Time-Frequency (TF) filtering, Improved Minima Controlled Recursive Averaging (IMCRA) for noise estimation, Wiener filtering, diagonal unloading (during the beamforming process), etc.
- 2.
- Extract features from which to estimate angles, such as inter-microphone time difference of arrival, directional energy response (via beamforming or Signal-to-Noise Ratio (SNR) measurements), spatial likelihood, etc.
- 3.
- (Optionally) employ a tracking algorithm for mobile sources, such as Kalman filtering, particle filtering, global nearest neighbor, etc.
6. Auditory Perception of a UAV from Another UAV (Air to Air)
- 1.
- Limited payload can restrict the hardware to be mounted onboard, including microphones and processing units.
- 2.
- The considerable amount of ego-noise forces researchers to either:
- (a)
- Place the microphones as far as possible from propellers or motors, or
- (b)
- Identify and characterize it to either:
- i.
- Remove it by pre-processing means, or
- ii.
- Consider it as part of the employed technique.
- 3.
- Aerial audio sources are highly mobile.
7. Discussion: Next Steps of Audio with UAVs
7.1. Disadvantages of Each Category
7.2. Representative Examples
7.3. Applications
- Bioacoustics: Obtaining a census of individuals of an animal species in an ecosystem is of interest for ecological purposes. Unfortunately, carrying out a census usually involves a considerable amount of preparation (both in human and logistical resources). Even if it is done through audio processing alone, the placement and recovery of audio acquisition hardware is labor-intensive, which results in data with a very low time resolution. Doing so by employing automatized drones would simplify data acquisition, and may even improve time resolution if the audio analysis is also carried out on-board.
- Urban security: Vision-based surveillance can only go so far in detecting and localizing crime-related activity, since the visual range is limited and can be relatively costly to expand. Audio-based techniques can provide an initial estimate of the direction of where a crime-related sound source is located, which can then be used to point the on-board camera.
- Collision avoidance: As mentioned before, because of UAVs’ high mobility, vision-based techniques may be too slow to provide information when avoid colliding with another UAV. On the other hand, audio-based techniques can be light and quick enough to provide an initial basis from which to move to avoid a collision, which can complement automatic navigation. It is noteworthy that the work of [69] does carry this out, but it is a rare exception, and we believe it would be beneficial if it was more prevalent.
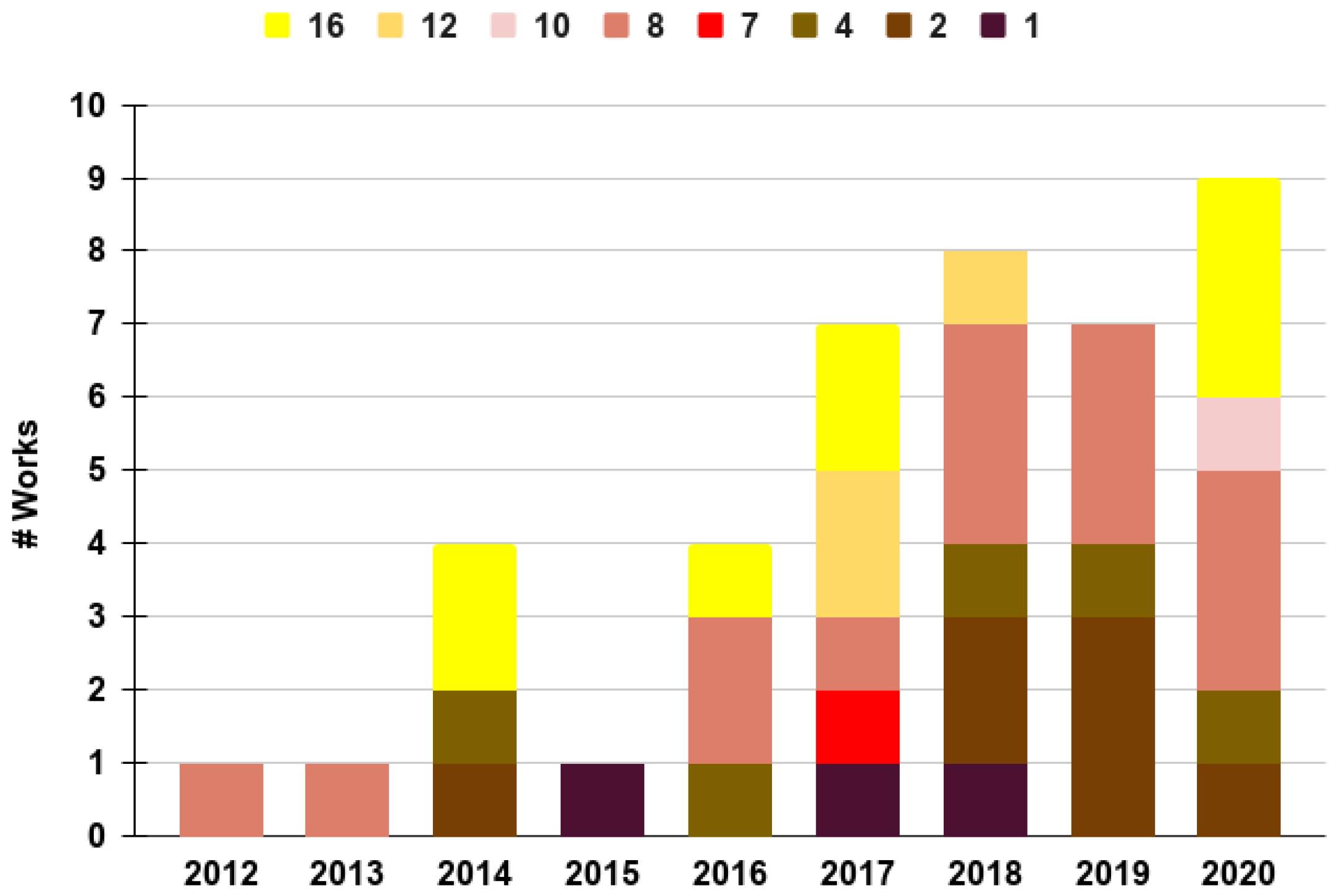
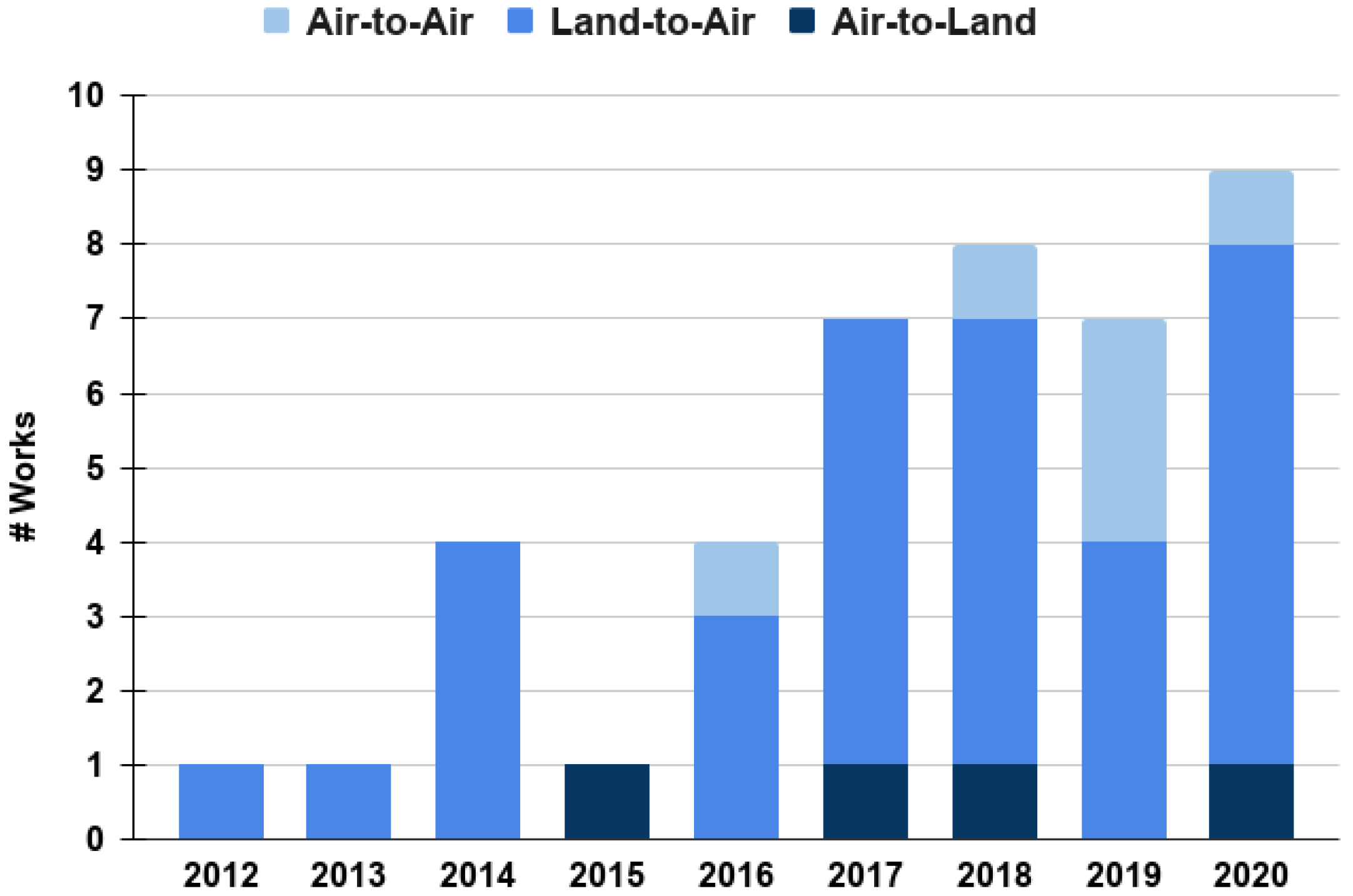
- Air-space policing through other UAVs: Although air-space policing through auditory perception is now quite common [82,83], it has been shown in this literature that the vast majority of works that do this belong to the air-to-land category. Furthermore, Figure 5 shows that the AL works have not been as prolific as those of the land-to-air category. To take advantage of the fact that UAVs are already able to locate land-bound sound sources, we believe that this application scenario could benefit if more works are focused on locating other UAVs. The works belonging in the AA category could be focused on this issue relatively easy.
- UAV swarm control: Moreover, having mentioned air-space policing through other UAVs as a possibility, a reasonable next step is to use that information to control a swarm of UAVs in a simplified manner. This means that if a UAV is able to locate other UAVs around it, the swarm of UAVs can be programmed as a set to move in parallel, not only avoiding collision, but automatically re-aligning themselves in an emerging manner without needing to be controlled by a central command center. It is important to note that the work of [75] does employ several UAVs to carry out sound source localization; however, it does not use this information to locate and control other UAVs.
- Acoustic environment characterization: The sole presence of the UAV acoustically impacts the environment. If this impact can be measured, it can provide information about the space itself. Because of the high mobility of the UAV, the space to be characterized can be quite sizable. A noteworthy example of this is presented in [47], in which the outer walls of a building were inspected using the UAV itself as a sound source. We believe that this idea can be generalized further. The noise of the UAV could be used as a type of reference with which an acoustic space in which reverberation is a factor (such as classrooms, concert halls, auditoriums, etc.) can be characterized and diagnosed in a finer manner compared to traditional methods. It is important to mention that it may be tempting to state that this application scenario is a step away from remotely sensing ground features. However, this would require a high-resolution characterization, which typically employs a highly directed type of signal; an acoustic signal can do this, but requires a high amount of power and hardware, which is impractical to carry on a UAV.
7.4. Limitations
7.5. Open Challenges
8. Concluding Remarks
Author Contributions
Funding
Conflicts of Interest
References
- Robotics, S. Robotics 2020 Multi-Annual Roadmap for Robotics in Europe; SPARC Robotics, EU-Robotics AISBL: The Hauge, The Netherlands, 2016; Volume 5, p. 2018. [Google Scholar]
- Bamburry, D. Drones: Designed for product delivery. Des. Manag. Rev. 2015, 26, 40–48. [Google Scholar]
- Achtelik, M.; Achtelik, M.; Brunet, Y.; Chli, M.; Chatzichristofis, S.; Decotignie, J.D.; Doth, K.M.; Fraundorfer, F.; Kneip, L.; Gurdan, D.; et al. Sfly: Swarm of micro flying robots. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 2649–2650. [Google Scholar]
- Watkins, S.; Burry, J.; Mohamed, A.; Marino, M.; Prudden, S.; Fisher, A.; Kloet, N.; Jakobi, T.; Clothier, R. Ten questions concerning the use of drones in urban environments. Build. Environ. 2020, 167, 106458. [Google Scholar] [CrossRef]
- Martinez-Carranza, J.; Varela, M.E.M.; Perez, L.O.R.; Ponce, A.A.C.; Jacob, E.; Cerón, S.; Colín, R.D. An Open-Source-Based Software to Capture Aerial Images and Video Using Drones. Real. Data Space Int. J. Stat. Geogr. 2020, 11, 25. [Google Scholar]
- Lippitt, C.D.; Zhang, S. The impact of small unmanned airborne platforms on passive optical remote sensing: A conceptual perspective. Int. J. Remote Sens. 2018, 39, 4852–4868. [Google Scholar] [CrossRef]
- Rojas-Perez, L.O.; Martinez-Carranza, J. Metric monocular SLAM and colour segmentation for multiple obstacle avoidance in autonomous flight. In Proceedings of the 2017 Workshop on Research, Education and Development of Unmanned Aerial Systems (RED-UAS), Linkoping, Sweden, 3–5 October 2017; pp. 234–239. [Google Scholar]
- Dionisio-Ortega, S.; Rojas-Perez, L.O.; Martinez-Carranza, J.; Cruz-Vega, I. A deep learning approach towards autonomous flight in forest environments. In Proceedings of the 2018 International Conference on Electronics, Communications and Computers (CONIELECOMP), Cholula, Mexico, 21–23 February 2018; pp. 139–144. [Google Scholar]
- Sanket, N.J.; Parameshwara, C.M.; Singh, C.D.; Kuruttukulam, A.V.; Fermüller, C.; Scaramuzza, D.; Aloimonos, Y. EVDodgeNet: Deep Dynamic Obstacle Dodging with Event Cameras. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 10651–10657. [Google Scholar]
- Fei, W.; Jin-Qiang, C.; Ben-Mei, C.; Tong, H.L. A comprehensive UAV indoor navigation system based on vision optical flow and laser FastSLAM. Acta Autom. Sin. 2013, 39, 1889–1899. [Google Scholar]
- Fasano, G.; Renga, A.; Vetrella, A.R.; Ludeno, G.; Catapano, I.; Soldovieri, F. Proof of concept of micro-UAV-based radar imaging. In Proceedings of the 2017 International Conference on Unmanned Aircraft Systems (ICUAS), Miami, FL, USA, 13–16 June 2017; pp. 1316–1323. [Google Scholar]
- Ludeno, G.; Fasano, G.; Renga, A.; Esposito, G.; Gennarelli, G.; Noviello, C.; Catapano, I. UAV radar imaging for target detection. In Multimodal Sensing: Technologies and Applications; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 11059, p. 110590F. [Google Scholar]
- Yang, L.; Feng, X.; Zhang, J.; Shu, X. Multi-ray modeling of ultrasonic sensors and application for micro-UAV localization in indoor environments. Sensors 2019, 19, 1770. [Google Scholar] [CrossRef] [PubMed]
- Wijnker, D.; van Dijk, T.; Snellen, M.; de Croon, G.; De Wagter, C. Hear-and-avoid for UAVs using convolutional neural networks. In Proceedings of the 11th International Micro Air Vehicle Competition and Conference (IMAV2019), Madrid, Spain, 29 September–4 October 2019; Volume 30. [Google Scholar]
- Cabrera-Ponce, A.A.; Martinez-Carranza, J.; Rascon, C. Detection of nearby UAVs using CNN and Spectrograms. In Proceedings of the International Micro Air Vehicle Conference and Competition (IMAV)(Madrid), Madrid, Spain, 29 September–4 October 2019. [Google Scholar]
- Cabrera-Ponce, A.A.; Martinez-Carranza, J.; Rascon, C. Detection of nearby UAVs using a multi-microphone array on board a UAV. Int. J. Micro Air Veh. 2020, 12. [Google Scholar] [CrossRef]
- Rascon, C.; Meza, I. Localization of sound sources in robotics: A review. Robot. Auton. Syst. 2017, 96, 184–210. [Google Scholar] [CrossRef]
- Shin, D.; Jun, M. Home IoT device certification through speaker recognition. In Proceedings of the 2015 17th International Conference on Advanced Communication Technology (ICACT), Seoul, Korea, 1–3 July 2015; pp. 600–603. [Google Scholar] [CrossRef]
- Tiwari, V.; Hashmi, M.F.; Keskar, A.; Shivaprakash, N. Virtual home assistant for voice based controlling and scheduling with short speech speaker identification. Multimed. Tools Appl. 2020, 79, 5243–5268. [Google Scholar] [CrossRef]
- Wang, L.; Cavallaro, A. Acoustic sensing from a multi-rotor drone. IEEE Sens. J. 2018, 18, 4570–4582. [Google Scholar] [CrossRef]
- Sibanyoni, S.V.; Ramotsoela, D.T.; Silva, B.J.; Hancke, G.P. A 2-D Acoustic Source Localization System for Drones in Search and Rescue Missions. IEEE Sens. J. 2018, 19, 332–341. [Google Scholar] [CrossRef]
- Fioranelli, F.; Ritchie, M.; Griffiths, H.; Borrion, H. Classification of loaded/unloaded micro-drones using multistatic radar. Electron. Lett. 2015, 51, 1813–1815. [Google Scholar] [CrossRef]
- Hoshiba, K.; Sugiyama, O.; Nagamine, A.; Kojima, R.; Kumon, M.; Nakadai, K. Design and assessment of sound source localization system with a UAV-embedded microphone array. J. Robot. Mechatron. 2017, 29, 154–167. [Google Scholar] [CrossRef]
- Hoshiba, K.; Washizaki, K.; Wakabayashi, M.; Ishiki, T.; Kumon, M.; Bando, Y.; Gabriel, D.; Nakadai, K.; Okuno, H.G. Design of UAV-embedded microphone array system for sound source localization in outdoor environments. Sensors 2017, 17, 2535. [Google Scholar] [CrossRef] [PubMed]
- Grondin, F.; Létourneau, D.; Ferland, F.; Rousseau, V.; Michaud, F. The ManyEars Open Framework. Auton. Robots 2013, 34, 217–232. [Google Scholar] [CrossRef]
- Labs, M. MATRIX Voice: Voice Development Board For Everyone. 2020. Available online: https://www.matrix.one/products/voice (accessed on 18 December 2020).
- Rudzki, T.; Gomez-Lanzaco, I.; Stubbs, J.; Skoglund, J.; Murphy, D.T.; Kearney, G. Auditory Localization in Low-Bitrate Compressed Ambisonic Scenes. Appl. Sci. 2019, 9, 2618. [Google Scholar] [CrossRef]
- Huang, J.; Supaongprapa, T.; Terakura, I.; Wang, F.; Ohnishi, N.; Sugie, N. A model-based sound localization system and its application to robot navigation. Robot. Auton. Syst. 1999, 27, 199–209. [Google Scholar] [CrossRef]
- Wang, F.; Takeuchi, Y.; Ohnishi, N.; Sugie, N. A mobile robot with active localization and disrimination of a sound source. J. Robot. Soc. Jpn. 1997, 15, 61–67. [Google Scholar] [CrossRef]
- Nakadai, K.; Lourens, T.; Okuno, H.G.; Kitano, H. Active audition for humanoid. In Proceedings of the National Conference on Artificial Intelligence (AAAI), Austin, TX, USA, 30 July–3 August 2000; pp. 832–839. [Google Scholar]
- Knapp, C.; Carter, G. The generalized correlation method for estimation of time delay. IEEE Trans. Acoust. Speech Signal Process. 1976, 24, 320–327. [Google Scholar] [CrossRef]
- Nakadai, K.; Hidai, K.; Okuno, H.G.; Kitano, H. Real-time speaker localization and speech separation by audio-visual integration. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Washington, DC, USA, 11–15 May 2002; Volume 1, pp. 1043–1049. [Google Scholar]
- Tiwari, V. MFCC and its applications in speaker recognition. Int. J. Emerg. Technol. 2010, 1, 19–22. [Google Scholar]
- Irie, R.E. Robust Sound Localization: An Application of an Auditory Perception System for a Humanoid Robot. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1995. [Google Scholar]
- Schmidt, R. Multiple emitter location and signal parameter estimation. IEEE Trans. Antennas Propag. 1986, 34, 276–280. [Google Scholar] [CrossRef]
- Nakamura, K.; Nakadai, K.; Okuno, H.G. A real-time super-resolution robot audition system that improves the robustness of simultaneous speech recognition. Adv. Robot. 2013, 27, 933–945. [Google Scholar] [CrossRef]
- Nakadai, K.; Okuno, H.G.; Mizumoto, T. Development, Deployment and Applications of Robot Audition Open Source Software HARK. J. Robot. Mechatron. 2017, 29, 16–25. [Google Scholar] [CrossRef]
- Valin, J.M.; Michaud, F.; Rouat, J. Robust localization and tracking of simultaneous moving sound sources using beamforming and particle filtering. Robot. Auton. Syst. 2007, 55, 216–228. [Google Scholar] [CrossRef]
- Grondin, F.; Michaud, F. Lightweight and optimized sound source localization and tracking methods for open and closed microphone array configurations. Robot. Auton. Syst. 2019, 113, 63–80. [Google Scholar] [CrossRef]
- Takeda, R.; Komatani, K. Discriminative multiple sound source localization based on deep neural networks using independent location model. In Proceedings of the 2016 IEEE Spoken Language Technology Workshop (SLT), San Diego, CA, USA, 13–16 December 2016; pp. 603–609. [Google Scholar]
- Takeda, R.; Komatani, K. Sound source localization based on deep neural networks with directional activate function exploiting phase information. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 405–409. [Google Scholar]
- Yalta, N.; Nakadai, K.; Ogata, T. Sound source localization using deep learning models. J. Robot. Mechatron. 2017, 29, 37–48. [Google Scholar] [CrossRef]
- Campbell, J.P. Speaker recognition: A tutorial. Proc. IEEE 1997, 85, 1437–1462. [Google Scholar] [CrossRef]
- Dehak, N.; Kenny, P.J.; Dehak, R.; Dumouchel, P.; Ouellet, P. Front-end factor analysis for speaker verification. IEEE Trans. Audio Speech Lang. Process. 2010, 19, 788–798. [Google Scholar] [CrossRef]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-vectors: Robust dnn embeddings for speaker recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- Rascon, C.; Ruiz-Espitia, O.; Martinez-Carranza, J. On the use of the aira-uas corpus to evaluate audio processing algorithms in unmanned aerial systems. Sensors 2019, 19, 3902. [Google Scholar] [CrossRef]
- Sugimoto, T.; Sugimoto, K.; Uechi, I.; Utagawa, N.; Kuroda, C. Outer wall inspection using acoustic irradiation induced vibration from UAV for noncontact acoustic inspection method. In Proceedings of the 2018 IEEE International Ultrasonics Symposium (IUS), Kobe, Japan, 22–25 October 2018; pp. 1–9. [Google Scholar]
- Okutani, K.; Yoshida, T.; Nakamura, K.; Nakadai, K. Outdoor auditory scene analysis using a moving microphone array embedded in a quadrocopter. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 3288–3293. [Google Scholar]
- Furukawa, K.; Okutani, K.; Nagira, K.; Otsuka, T.; Itoyama, K.; Nakadai, K.; Okuno, H.G. Noise correlation matrix estimation for improving sound source localization by multirotor UAV. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 3943–3948. [Google Scholar]
- Hausamann, P.; UAV Sound Source Localization. Computational Neuro Engineering Project Laboratory Practical Report. Available online: http://tum.neurocomputing.systems/en/publications/nst-practical-reports/ (accessed on 18 December 2020).
- Sayed, L.A.; Alboul, L. Acoustic Based Search and Rescue on a UAV. In Advances in Autonomous Robotics Systems, Proceedings of the 15th Annual Conference, TAROS 2014, Birmingham, UK, 1–3 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8717, p. 275. [Google Scholar]
- Ishiki, T.; Kumon, M. A microphone array configuration for an auditory quadrotor helicopter system. In Proceedings of the 2014 IEEE International Symposium on Safety, Security, and Rescue Robotics (2014), Hokkaido, Japan, 27–30 October 2014; pp. 1–6. [Google Scholar]
- Ohata, T.; Nakamura, K.; Mizumoto, T.; Taiki, T.; Nakadai, K. Improvement in outdoor sound source detection using a quadrotor-embedded microphone array. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 1902–1907. [Google Scholar]
- Park, S.; Shin, S.; Kim, Y.; Matson, E.T.; Lee, K.; Kolodzy, P.J.; Slater, J.C.; Scherreik, M.; Sam, M.; Gallagher, J.C.; et al. Combination of radar and audio sensors for identification of rotor-type unmanned aerial vehicles (uavs). In Proceedings of the 2015 IEEE SENSORS, Busan, Korea, 1–4 November 2015; pp. 1–4. [Google Scholar]
- Basiri, M.; Schill, F.; Lima, P.; Floreano, D. On-board relative bearing estimation for teams of drones using sound. IEEE Robot. Autom. Lett. 2016, 1, 820–827. [Google Scholar] [CrossRef]
- Morito, T.; Sugiyama, O.; Kojima, R.; Nakadai, K. Partially Shared Deep Neural Network in sound source separation and identification using a UAV-embedded microphone array. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 1299–1304. [Google Scholar]
- Morito, T.; Sugiyama, O.; Uemura, S.; Kojima, R.; Nakadai, K. Reduction of computational cost using two-stage deep neural network for training for denoising and sound source identification. In IEA/AIE 2016: Trends in Applied Knowledge-Based Systems and Data, Proceedings of the International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Morioka, Japan, 2–4 August 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 562–573. [Google Scholar]
- Washizaki, K.; Wakabayashi, M.; Kumon, M. Position estimation of sound source on ground by multirotor helicopter with microphone array. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 1980–1985. [Google Scholar]
- Jeon, S.; Shin, J.W.; Lee, Y.J.; Kim, W.H.; Kwon, Y.; Yang, H.Y. Empirical study of drone sound detection in real-life environment with deep neural networks. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017; pp. 1858–1862. [Google Scholar]
- Fernandes, R.P.; Apolinário, J.A.; Ramos, A.L. Bearings-only aerial shooter localization using a microphone array mounted on a drone. In Proceedings of the 2017 IEEE 8th Latin American Symposium on Circuits & Systems (LASCAS), Bariloche, Argentina, 20–23 February 2017; pp. 1–4. [Google Scholar]
- Wang, L.; Cavallaro, A. Time-frequency processing for sound source localization from a micro aerial vehicle. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 496–500. [Google Scholar]
- Nakadai, K.; Kumon, M.; Okuno, H.G.; Hoshiba, K.; Wakabayashi, M.; Washizaki, K.; Ishiki, T.; Gabriel, D.; Bando, Y.; Morito, T.; et al. Development of microphone-array-embedded UAV for search and rescue task. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5985–5990. [Google Scholar]
- Ohata, T.; Nakamura, K.; Nagamine, A.; Mizumoto, T.; Ishizaki, T.; Kojima, R.; Sugiyama, O.; Nakadai, K. Outdoor sound source detection using a quadcopter with microphone array. J. Robot. Mechatron. 2017, 29, 177–187. [Google Scholar] [CrossRef]
- Misra, P.; Kumar, A.A.; Mohapatra, P.; Balamuralidhar, P. Aerial drones with location-sensitive ears. IEEE Commun. Mag. 2018, 56, 154–160. [Google Scholar] [CrossRef]
- Harvey, B.; O’Young, S. Acoustic Detection of a Fixed-Wing UAV. Drones 2018, 2, 4. [Google Scholar]
- Salvati, D.; Drioli, C.; Ferrin, G.; Foresti, G.L. Beamforming-based acoustic source localization and enhancement for multirotor UAVs. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 987–991. [Google Scholar]
- Wang, L.; Sanchez-Matilla, R.; Cavallaro, A. Tracking a moving sound source from a multi-rotor drone. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 2511–2516. [Google Scholar]
- Hoshiba, K.; Nakadai, K.; Kumon, M.; Okuno, H.G. Assessment of MUSIC-based noise-robust sound source localization with active frequency range filtering. J. Robot. Mechatron. 2018, 30, 426–435. [Google Scholar] [CrossRef]
- Harvey, B.; O’Young, S. A Harmonic Spectral Beamformer for the Enhanced Localization of Propeller-driven Aircraft. J. Unmanned Veh. Syst. 2019, 7, 156–174. [Google Scholar] [CrossRef]
- Lee, D.; Jang, B.; Im, S.; Song, J. A New Sound Source Localization Approach Using Stereo Directional Microphones. In Proceedings of the 2019 IEEE 2nd International Conference on Information Communication and Signal Processing (ICICSP), Weihai, China, 28–30 September 2019; pp. 504–508. [Google Scholar]
- Chen, M.; Hu, W. Research on BatSLAM Algorithm for UAV Based on Audio Perceptual Hash Closed-Loop Detection. Int. J. Pattern Recognit. Artif. Intell. 2019, 33, 1959002. [Google Scholar] [CrossRef]
- Salvati, D.; Drioli, C.; Gulli, A.; Foresti, G.L.; Fontana, F.; Ferrin, G. Audiovisual Active Speaker Localization and Enhancement for Multirotor Micro Aerial Vehicles. In Proceedings of the 23rd International Congress on Acoustics: Integrating 4th EAA Euroregio, Aachen, Germany, 9–13 September 2019; pp. 9–13. [Google Scholar]
- Deleforge, A.; Di Carlo, D.; Strauss, M.; Serizel, R.; Marcenaro, L. Audio-Based Search and Rescue with a Drone: Highlights From the IEEE Signal Processing Cup 2019 Student Competition [SP Competitions]. IEEE Signal Process. Mag. 2019, 36, 138–144. [Google Scholar] [CrossRef]
- Choi, J.; Chang, J.H. Convolutional Neural Network-based Direction-of-Arrival Estimation using Stereo Microphones for Drone. In Proceedings of the 2020 International Conference on Electronics, Information, and Communication (ICEIC), Barcelona, Spain, 19–22 January 2020; pp. 1–5. [Google Scholar]
- Manickam, S.; Swar, S.C.; Casbeer, D.W.; Manyam, S.G. Multi-unmanned aerial vehicle multi acoustic source localization. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 2020. [Google Scholar] [CrossRef]
- Wang, L.; Cavallaro, A. Deep Learning Assisted Time-Frequency Processing for Speech Enhancement on Drones. IEEE Trans. Emerg. Top. Comput. Intell. 2020. [Google Scholar] [CrossRef]
- Yen, B.; Hioka, Y. Noise power spectral density scaled SNR response estimation with restricted range search for sound source localisation using unmanned aerial vehicles. EURASIP J. Audio Speech Music. Process. 2020, 2020, 1–26. [Google Scholar] [CrossRef]
- Blanchard, T.; Thomas, J.H.; Raoof, K. Acoustic localization and tracking of a multi-rotor unmanned aerial vehicle using an array with few microphones. J. Acoust. Soc. Am. 2020, 148, 1456–1467. [Google Scholar] [CrossRef] [PubMed]
- Wakabayashi, M.; Okuno, H.G.; Kumon, M. Multiple Sound Source Position Estimation by Drone Audition Based on Data Association Between Sound Source Localization and Identification. IEEE Robot. Autom. Lett. 2020, 5, 782–789. [Google Scholar] [CrossRef]
- Wakabayashi, M.; Okuno, H.G.; Kumon, M. Drone audition listening from the sky estimates multiple sound source positions by integrating sound source localization and data association. Adv. Robot. 2020, 1–12. [Google Scholar] [CrossRef]
- Wakabayashi, M.; Washizaka, K.; Hoshiba, K.; Nakadai, K.; Okuno, H.G.; Kumon, M. Design and Implementation of Real-Time Visualization of Sound Source Positions by Drone Audition. In Proceedings of the 2020 IEEE/SICE International Symposium on System Integration (SII), Honolulu, HI, USA, 12–15 January 2020; pp. 814–819. [Google Scholar]
- Patel, B.; Rizer, D. Counter-Unmanned Aircraft Systems; Technical Report; U.S Department of Homeland Security Science and Technology Directorate’s National Urban Security Technology Laboratory: New York, NY, USA, September 2019.
- Holland Michel, A. Counter Drone Systems; Technical Report; Center for the Study of the Drone at Bard College: Washington, DC, USA, 20 February 2018. [Google Scholar]
- Case, E.E.; Zelnio, A.M.; Rigling, B.D. Low-cost acoustic array for small UAV detection and tracking. In Proceedings of the 2008 IEEE National Aerospace and Electronics Conference, Dayton, OH, USA, 16–18 July 2008; pp. 110–113. [Google Scholar]
- Sedunov, A.; Haddad, D.; Salloum, H.; Sutin, A.; Sedunov, N.; Yakubovskiy, A. Stevens drone detection acoustic system and experiments in acoustics UAV tracking. In Proceedings of the 2019 IEEE International Symposium on Technologies for Homeland Security (HST), Woburn, MA, USA, 5–6 November 2019; pp. 1–7. [Google Scholar]
- Martinez-Carranza, J.; Bostock, R.; Willcox, S.; Cowling, I.; Mayol-Cuevas, W. Indoor MAV auto-retrieval using fast 6D relocalisation. Adv. Robot. 2016, 30, 119–130. [Google Scholar] [CrossRef]
- Moon, H.; Martinez-Carranza, J.; Cieslewski, T.; Faessler, M.; Falanga, D.; Simovic, A.; Scaramuzza, D.; Li, S.; Ozo, M.; De Wagter, C.; et al. Challenges and implemented technologies used in autonomous drone racing. Intell. Serv. Rob. 2019, 12, 137–148. [Google Scholar] [CrossRef]
- Loianno, G.; Brunner, C.; McGrath, G.; Kumar, V. Estimation, control, and planning for aggressive flight with a small quadrotor with a single camera and IMU. IEEE Robot. Autom. Lett. 2016, 2, 404–411. [Google Scholar] [CrossRef]
- Ahn, H.; Le, D.T.; Dang, T.B.; Kim, S.; Choo, H. Hybrid Noise Reduction for Audio Captured by Drones. In Proceedings of the 12th International Conference on Ubiquitous Information Management and Communication, Langkawi, Malaysia, 5–7 January 2018; pp. 1–4. [Google Scholar]
- Uragun, B.; Tansel, I.N. The noise reduction techniques for unmanned air vehicles. In Proceedings of the 2014 International Conference on Unmanned Aircraft Systems (ICUAS), Orlando, FL, USA, 27–30 May 2014; pp. 800–807. [Google Scholar]
- Brungart, T.A.; Olson, S.T.; Kline, B.L.; Yoas, Z.W. The reduction of quadcopter propeller noise. Noise Control Eng. J. 2019, 67, 252–269. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
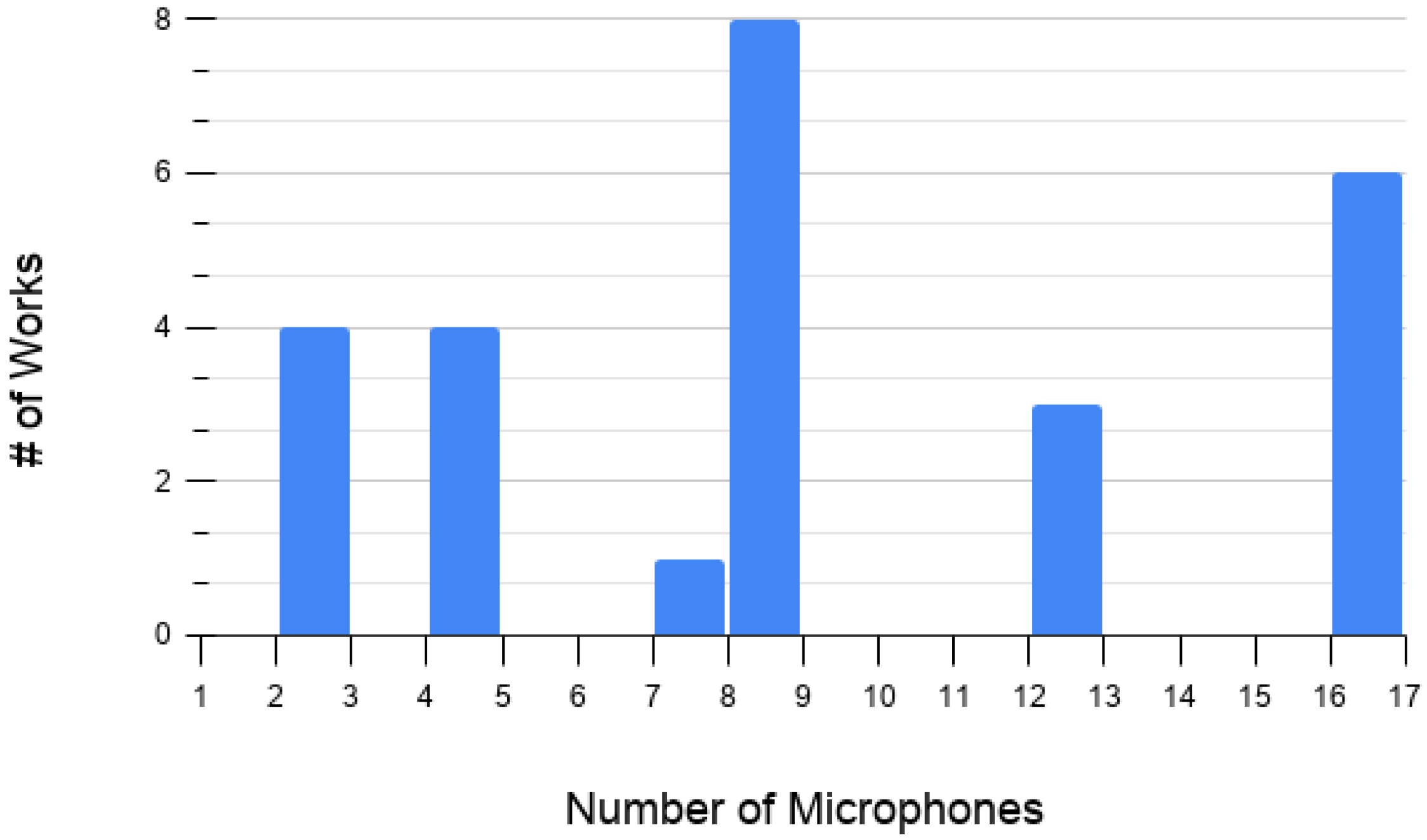
| # Microphones | # Works per | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Category | 1 | 2 | 4 | 7 | 8 | 10 | 12 | 16 | Category |
| Air-to-Land | 3 | 1 | 4 | ||||||
| Land-to-Air | 5 | 4 | 1 | 11 | 3 | 8 | 32 | ||
| Air-to-Air | 2 | 1 | 3 | 6 | |||||
| Total of works: | 42 | ||||||||
| Year | # Microphones | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 7 | 8 | 10 | 12 | 16 | |
| 2012 | AR drone [48] | |||||||
| 2013 | AR drone [49] | |||||||
| 2014 | Quad [50] | Quad [51] | Quad [52] Quad [53] | |||||
| 2015 | * Phantom I [54] * Phantom II [54] | |||||||
| 2016 | Quad [55] Quad size [55] | Bebop [56] Bebop [57] | Quad [58] | |||||
| 2017 | * Phantom 3 [59] * Phantom 4 [59] * Inspire [59] * 3DR Solo [59] | AR drone [60] | 3DR IRIS [61] | Quad [24] Hexa [24] Hexa [62] | Ballon [23] Bebop [23] Pelican [23] Zion [23] Quad [63] | |||
| 2018 | * Matrice 600 pro [47] | AR drone [64] Fixed- Wing [65] | Bebop [66] | Quad [21] Quad [20] Quad [67] | Hexa [68] | |||
| 2019 | Fixed- Wing [69] Quad [70] Quad [71] | Bebop [72] | Bebop [14] Bebop 2 [15] Matrice 100 [15] MK- Quadro [73] | |||||
| 2020 | Mavic Pro [74] | Quad [75] | Bebop 2 [16] Matrice 100 [16] Quad [76] Quad [77] | * Phantom I [78] | Quad [79] Quad [80] Hexa [81] | |||
| Loc. Technique | Reported Performance | Noise Removal | |
|---|---|---|---|
| Choi et al. [74] | CNN, energy-based features | 0.065 error | multi-Wiener |
| Fernandes et al. [60] | GCC-PHAT | 2.7 to 9.9 error | TLS in search |
| Furukawa et al. [49] | GEVD-MUSIC, Gaussian regression for noise matrix | 0.7 F-value with moderate SNR | - |
| Hausamann [50] | Inter-aural time difference | 7 to 23 error | - |
| Hoshiba et al. [68] | frequency-limited MUSIC | 80% success, 10 dB SNR | - |
| Hoshiba et al. [23] | iGSVD-MUSIC | 70% to 100% accuracy | - |
| Hoshiba et al. [24] | iGSVD-MUSIC, SEVD-MUSIC | 97% success, dB SNR | - |
| Ishiki et al. [52] | MUSIC (HARK) | - | - |
| Lee et al. [70] | K-medoids-based clustering using cosine distance | 98% accuracy | multi-IMCRA, multi-Wiener |
| Manickam et al. [75] | MAP multi-UAV clustering | 0.5 m to 1 m error | - |
| Misra et al. [64] | Intra-band beamforming | 0.001 m error, 0 dB SNR | - |
| Nakadai et al. [62] | iGSVD-MUSIC, SEVD-MUSIC | 98% success, -10 dB SNR | ORPCA |
| Ohata et al. [53] | iGSVD-MUSIC, correlation matrix scaling | 78% correct rate, 3 m away, 2.7 m height | - |
| Ohata et al. [63] | iGSVD-MUSIC, correlation matrix scaling | 89% correct rate, 2.7 m height | - |
| Okutani et al. [48] | iGEVD-MUSIC | 71% correct rate | - |
| Salvati et al. [66] | beamforming spectral distance response | 3.7 error, 0 dB SNR | diagonal unloading |
| Salvati et al. [72] | beamforming refined with face detection | >5 error, 0 dB SNR | diagonal unloading |
| Sayed et al. [51] | TDOA via cross-correlation | 0.35% error | - |
| Sibanyoni et al. [21] | TDOA, Kalman filter, triangulation based on drone movement | 80% of true value | - |
| Wakabayashi et al. [80] | Global nearest neighbor exploiting sound source features | 0.84 m to 2.65 m of error | - |
| Wang et al. [20] | DOA-weighted kurtosis-histogram measures | ∼1 correct ratio, 0 dB SNR | time-frequency filtering |
| Wang et al. [61] | TF spatial filtering, local spatial likelihood | 0.9 likelihood, dB SNR | - |
| Wang et al. [67] | TF spatial filtering, spatial confidence on non-Gaussianity, particle filtering | 3.8 to 11.5 of error | - |
| Washizaki et al. [58] | Weighted least mean square localisation with uncertainty estimation | 2.18 m of error | - |
| Yen et al. [77] | MVDR-based SNR response | 0.0833 Haversine dist. to ground-truth | denoising autoencoder |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martinez-Carranza, J.; Rascon, C. A Review on Auditory Perception for Unmanned Aerial Vehicles. Sensors 2020, 20, 7276. https://doi.org/10.3390/s20247276
Martinez-Carranza J, Rascon C. A Review on Auditory Perception for Unmanned Aerial Vehicles. Sensors. 2020; 20(24):7276. https://doi.org/10.3390/s20247276
Chicago/Turabian StyleMartinez-Carranza, Jose, and Caleb Rascon. 2020. "A Review on Auditory Perception for Unmanned Aerial Vehicles" Sensors 20, no. 24: 7276. https://doi.org/10.3390/s20247276
APA StyleMartinez-Carranza, J., & Rascon, C. (2020). A Review on Auditory Perception for Unmanned Aerial Vehicles. Sensors, 20(24), 7276. https://doi.org/10.3390/s20247276