1. Introduction
There are many recent studies that address the development of forecasting models in the context of a monitoring system for industrial and electrical equipment, based on the analysis of temporal signals obtained through sensors [
1,
2,
3,
4,
5]. In fact, real-time monitoring systems form one of the foundations of Industry 4.0 and have been developed to monitor various variables in industrial plants, electric generators/motors, and various other equipment [
6]. These systems become more and more popular with the advances in Internet of Things (IoT) and Cloud technologies, especially in the areas of manufacturing and maintenance, but mainly aimed at visualizing the data collected due especially to the difficulties of real-time processing [
6,
7].
In general, forecast models are trained with historical data and, even with the acquisition of new data, they are not automatically updated to improve your forecasts. New data are used to assess the quality of the predictions made by the model and, if necessary, a new training process is started with the updated historical data set [
1].
On the other hand, sensor data represent a significant opportunity for streaming and collecting from different devices every second, which creates important challenges on how to manipulate that data and perform data analysis online, given that current approaches are often limited by capacity, costs, and resources [
8]. In this context, the data platform based on the lambda architecture stands out, combining traditional batch data processing with a fast, real-time data flow and it represents the state of the art in online data processing architectures [
9].
This article presents a proposal to update a prediction model to improve forecast accuracy in the context of a distributed data platform based on the lambda architecture that combines real-time and batch processing techniques. The main contribution of the proposed system is the ability to combine the real-time and batch processing layers of the lambda architecture to update the forecasting model, with application in the estimation of partial discharges in power hydrogenerators. Partial discharges (PDs) are electrical discharges that occur inside or outside the insulation of a high-voltage system under electrical stress [
10,
11]. The proposed forecasting model is based on a long short-term memory (LSTM) recurrent neural network and explores the benefit of such models in allowing an update of weights as new data become available [
12].
We organized the rest of the paper as follows.
Section 2 discusses related work and research regarding online monitoring systems and prediction models. An overview of lambda architecture and the theory regarding forecasting models are presented in
Section 3. The proposed approach to update the artificial neural network-based prediction model on a lambda architecture for estimating partial discharges in an hydrogenerator is presented in
Section 4. Experimental results are presented in
Section 5 and
Section 6 concludes the work.
2. Related Work
Autoregressive model is a way to capture autocorrelation and seasonality in a sequence of observations ordered over time (time series) [
13]. The time series analysis has basically three objectives: to identify the nature of the represented phenomenon looking for a behavior pattern, such as the trend pattern, the existence of seasonal variation, outliers, structural changes, etc.; use the variation in one series to explain the variation in another series; and, finally, predict the evolution of the time series’ variable from a mathematical model that describes the behavior of the observations [
14].
The literature shows several studies that seek to improve the accuracy of autoregressive forecasting models, and many of these studies have used techniques that can be categorized into two groups: statistical approaches, such as regression analysis and time series analysis, and techniques based on artificial intelligence (AI), such as multilayer neural network, deep learning neural network, fuzzy logic, support vector machine (SVM), least squares support vector machine (LS-SVM), random forest, and deep learning, among others.
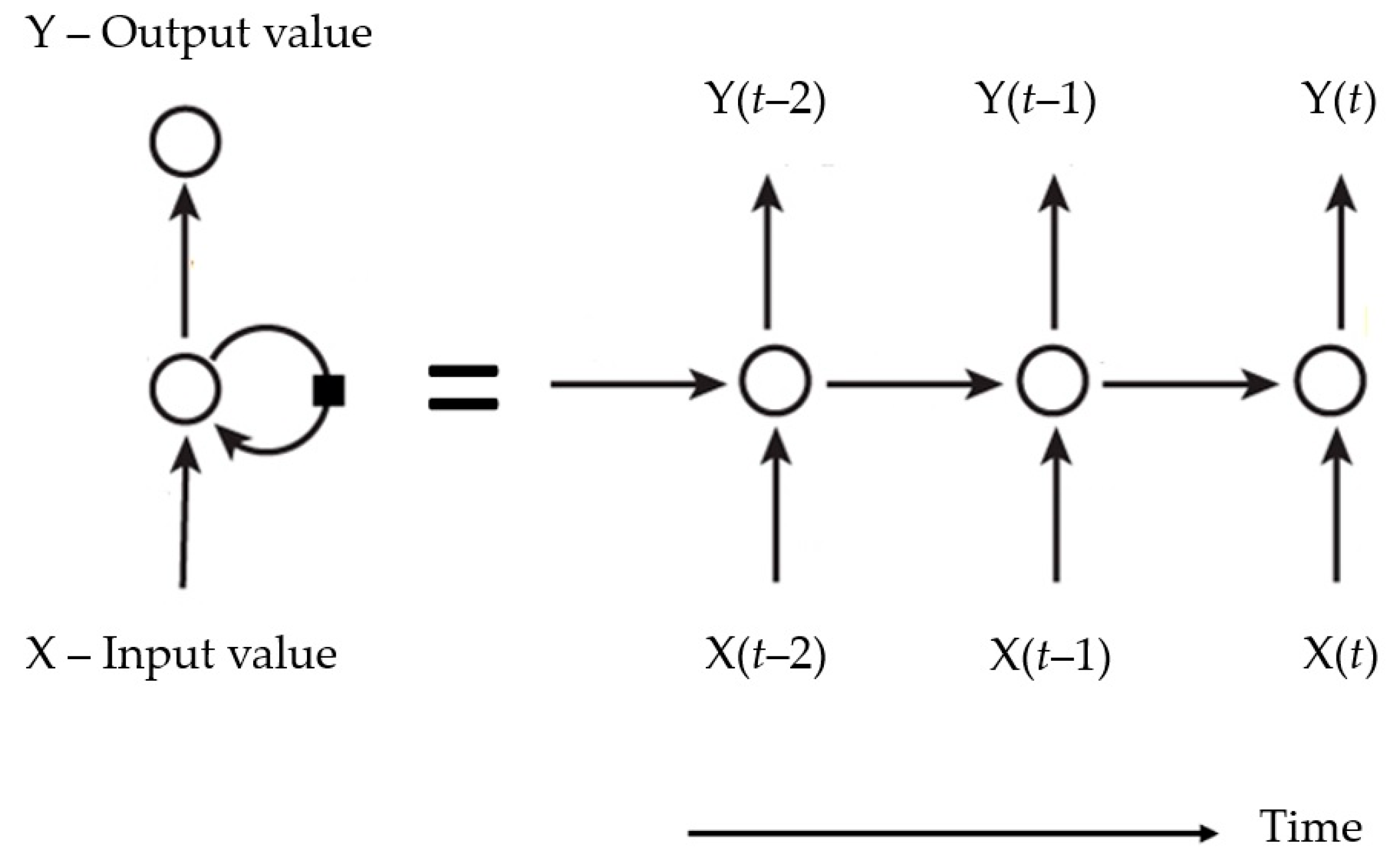
In [
15] a model was proposed combining advantages of the neural network with random weights and a support vector machine, which can capture more dynamic characteristics of the multivariate data of the time series by means of weighting samples. The mutual information is used to determine time delays, between the value of the variable at time
t, X(
t), and the value of the same variable at time
t-τ, X(
t-τ) with different τ (time delay), where the first local minimum value of mutual information corresponds to the time delay for time series.
Other prediction models based upon LS-SVM have been proposed by [
16,
17], just to name a few. These works address problems in different areas, for example, detecting mechanical failures in induction motors such as [
18] and estimating the concentration of gases dissolved in oil in transformers as in [
16], among others.
Regarding partial discharges (PD), the application of prediction models is also widespread. In this sense, analysis of electrical insulation failures reveal that this kind of failure is the root cause of more than 60% of the damage to high-voltage equipment [
19]. Thus, PD recognition has been a topic of interest to distinguish different sources of PD failure within energy appliance insulation systems [
11,
19,
20,
21,
22].
In [
11] the authors proposed a new technique to classify PD’s patterns based on the learning of neural networks by ensemble (ENN). The ENN technique is based on training a series of neural network models with statistical parameters of partial discharge patterns and combining their predictions. By combining the outputs of the constituent neural networks through an aggregation unit using the dynamically weighted average strategy, a final assessment of partial discharge patterns is provided in relation to a range of partial discharge failure types. As another example of work on the topic we can cite [
20], addressing a new method for locating PD in transformer windings.
Even in the context of partial discharges, the use of deep learning has received great attention and several contributions have shown that deep learning-based methods have better accuracy than typical machine learning methods, providing more efficient automated identification techniques. This kind of deep learning methods for PD classification was applied in [
22,
23], for example. In [
22], a convolutional neural network (CNN) of multiple columns was used to incorporate ultra-high-frequency (UHF) spectra of multiple resolutions and a long-term memory network was used to merge information from built-in multisensors. Long short-term memory (LSTM) neural networks were also applied by [
23] to classify partial discharges.
However, despite the evolution in the creation and precision of the forecasting model, the works generally do not describe mechanisms for manipulating and processing sensor data to update these models. This represents an important gap since improvements regarding the general applicability of the method can be made in a data acquisition process [
21]. Additionally, the adoption of this type of mechanism for manipulating and processing sensor data is fundamental for the development of data-driven applications in the context of Industry 4.0. In this sense, some recent studies have presented proposals to adapt models to the experimental collected data, showing significant improvements in results. In [
24], for example, the data-driven concept was used to adjust, optimize, and experimentally validate a model to optimize energy consumption on tower crane systems, presenting significantly superior results. Moreover, the implementation of efficient architectures for data collection, storage, and processing, possibly in a distributed way, can contribute significantly to mitigating the problems with limitations of computation abilities and communication channel bandwidth that are often described as complex tasks in data-driven practical control systems [
25]. The severity of these limitations has motivated numerous researchers for the development and extensions of event-triggered control schemes such as those presented in [
25,
26,
27,
28], just to name a few.
According to [
7], IoT and real-time, predictive maintenance systems face problems such as insufficient real-time data analysis, high cost to collect sensors’ data, and the configuration of fault detection rules. Such difficulties mean that the systems are often turned only to visualize the sensor data. The same authors suggest that the adoption of an architecture for real-time processing of sensor data, such as the lambda architecture, may favor the adoption of efficient preventive maintenance platforms.
In fact, lambda architecture is the state-of-the-art, real-time data processing technique [
29]. However, many works on this topic are dedicated to the theoretical aspects of this architecture [
9,
30], with few recent real applications such as in E-Commerce Analytics [
31] and intrusion and anomaly detection framework [
32]. Authors in [
7], for example, proposed a platform based on lambda architecture to accelerate automatic machine maintenance, but the application in a real situation was indicated as a future proposal of the work. Similarly, [
6] proposed an industrial IoT system for monitoring electric motors in real time, in the Industry 4.0 context, and indicated the creation of a predictive model based on machine learning as a long-term future work.
The analysis of these studies shows the gap in contemporary literature and establishes the contribution of this paper. By comparing the previous literatures, the main contribution of the proposed system is the ability to combine the real-time and batch processing layers of the lambda architecture to update the forecasting model, with application in the estimation of partial discharges in power hydrogenerators. The proposed system makes it possible to collect, store, and process data separately in the batch and speed layers. The batch that handles large volumes of data layer is performed only sporadically while the speed layer is often executed with low data volume, ensuring model updates and mitigating common limitations of computation and communication channel bandwidth problems in data-driven, practical control systems [
25,
26,
27,
28].
From the point of view of the plant’s operation, the proposed methodology makes it possible to understand the evolution of the model’s forecasting capacity and to estimate the moment from which the forecast results of the model can be considered suitable for the application.
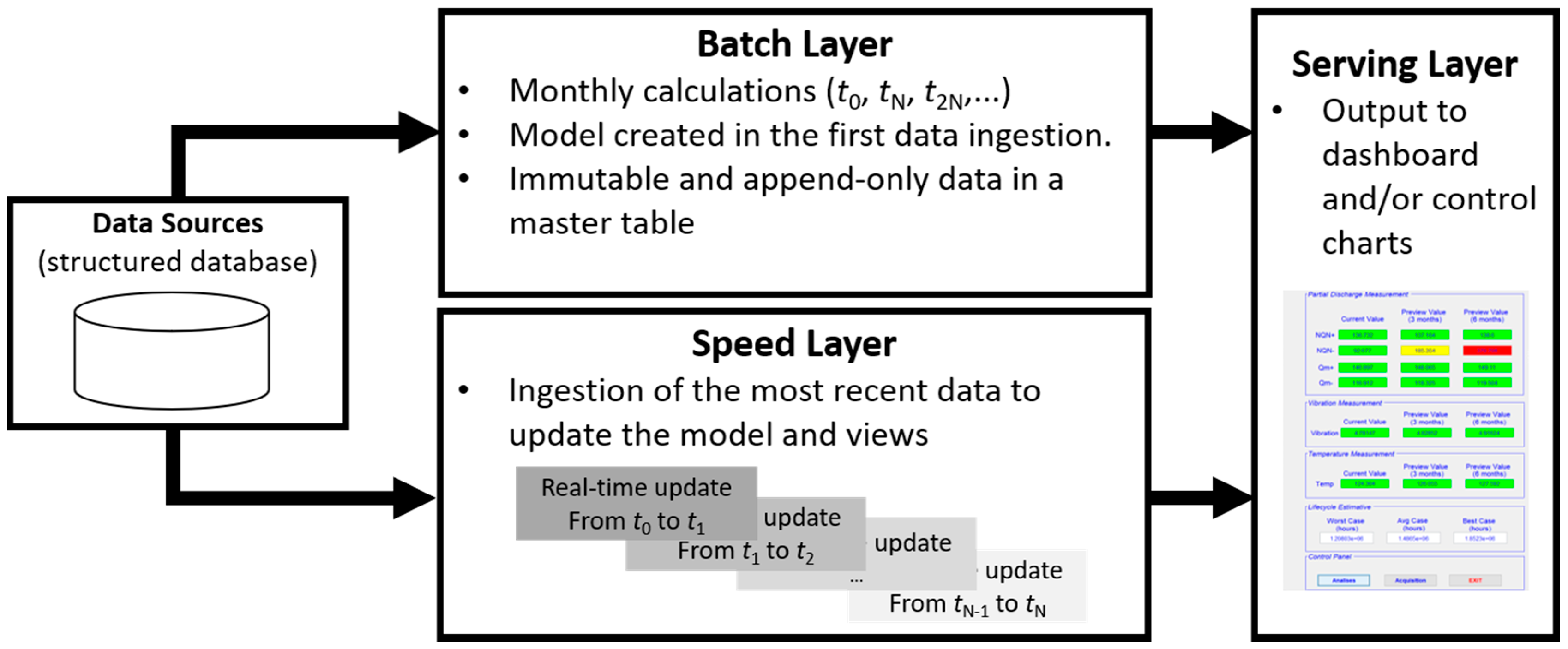
4. Proposed Approach
In this section, the steps in the development of the proposed system are presented and described, from obtaining data of sensor readings to automatically updating the predictive model. The steps are described in the context of the lambda architecture and, therefore, consider the integration between the batch layer and the speed layer through the tools of the Hadoop ecosystem as well as the integration of this architecture with the prediction model. An illustration of the proposed system is shown in
Figure 2.
4.1. Generation of Typical Partial Discharge Values
The partial discharge monitoring system that includes sensors, data architecture, and the autoregressive forecasting model is being implemented at the plant and, therefore, does not have enough data for a conclusive analysis of the hydrogenerator condition based on these variables and not even for the creation and evaluation of a forecasting model.
Thus, the methodology proposed here was evaluated based on a system simulation. Three scenarios were simulated for different hydrogenerator conditions in relation to the severity of partial discharges observed, defined according to [
36]. In addition to evaluating the proposed methodology, the simulation performed is important to understand the evolution of the model’s forecasting capacity and to estimate the moment from which the forecast results of the model can be considered suitable for the application.
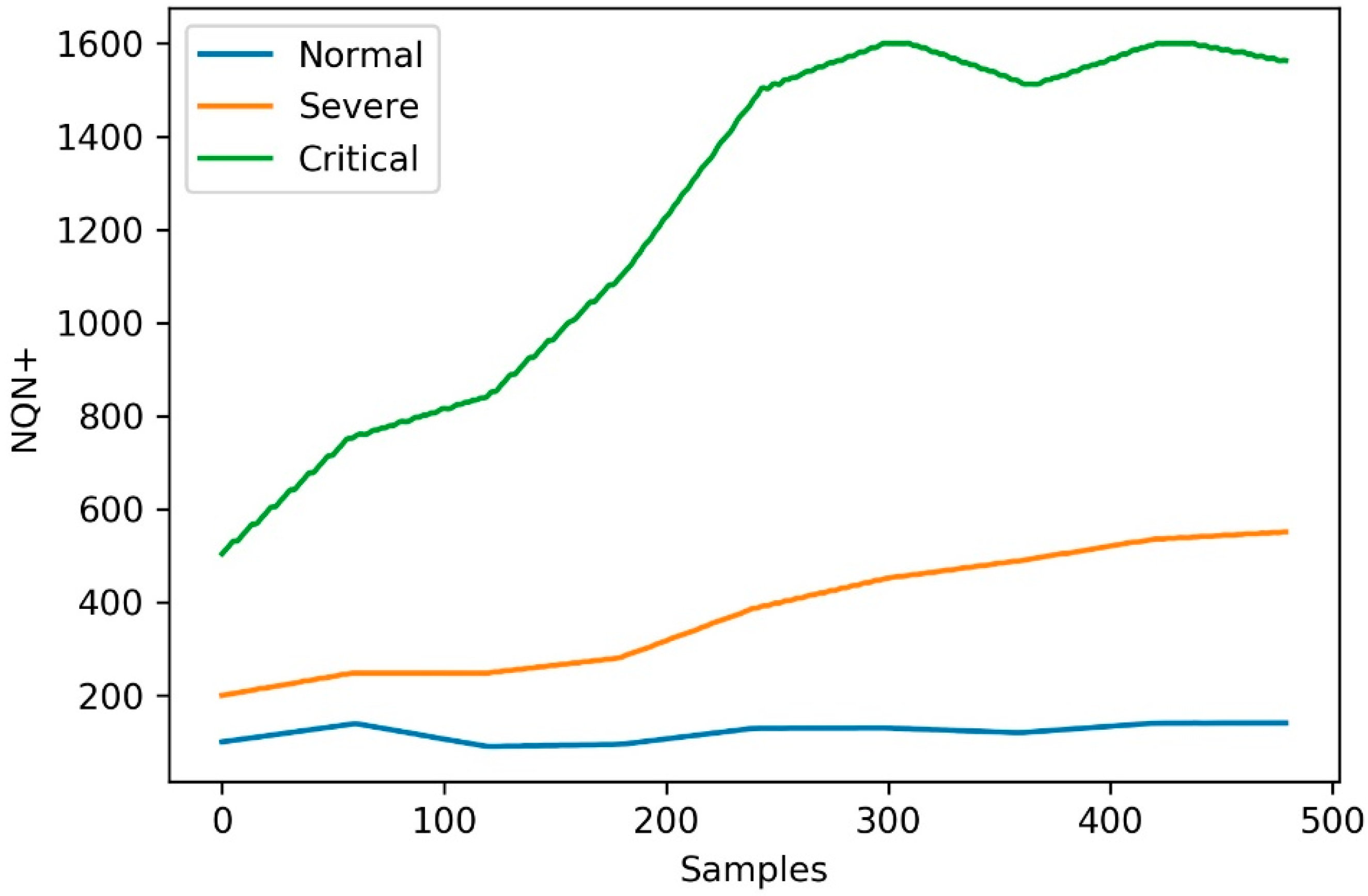
The simulated scenarios considered the temporal evolution of the Normalized Quantity Number NQN+ in three operating conditions in relation to the severity of partial discharges, called
normal,
severe, and
critical condition. The NQN+ values were obtained from the three conditions, as shown in
Figure 3. The NQN+ values were extracted from the graphics in
Figure 3 using a web-based plot digitizing tool for extracting data from a time series including XY coordinates, called WebPlotDigitizer [
37]. In the WebPlotDigitizer tool, after loading the image and calibrating the axes, assuming that axes are perfectly aligned with image coordinates, the data were extracted automatically using the ‘X step with interpolation algorithm‘ available in the tool, with the parameters adjusted as described in
Table 1 in order to get equivalent to a daily sample. The NQN values generated are available with this work as
Supplementary Material.
The reading of the sensor data was done in 30 s, but the reading frequency usually occurs in a week-wise manner. However, for the start of the system’s operation, a daily frequency was established to speed up the generation of a database for future application of the proposed methodology. Thus, the three scenarios considered simulated daily measurements of NQN + values.
The extracted values were used to represent NQN+ over a 16-month monitoring and analysis horizon, resulting in 480 samples, of which 360 samples were used to simulate the operation of the model over a 12-month period.
The three scenarios are described as follows.
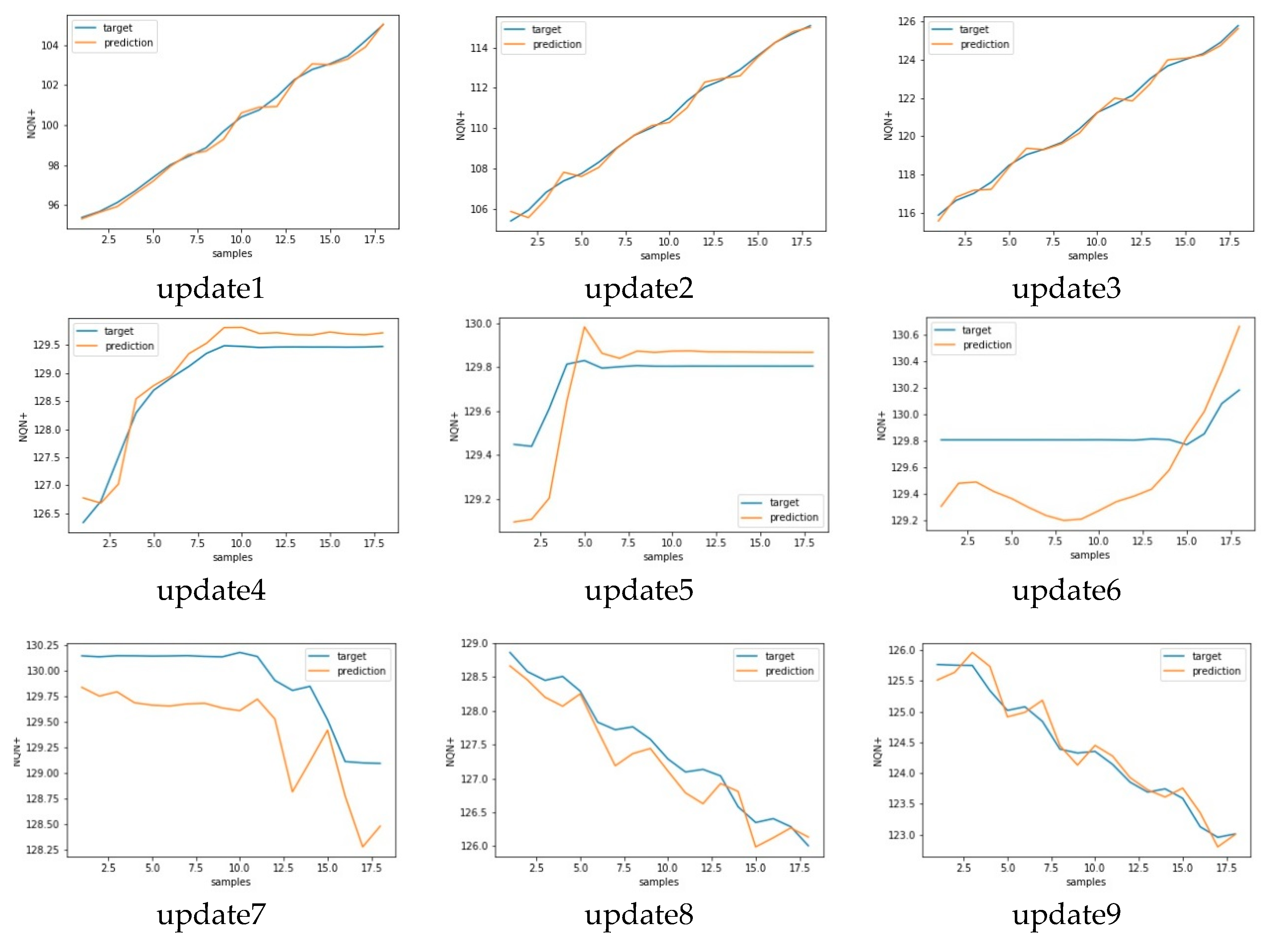
Scenario 1—normal: coils in relatively good condition since there is no general increase over time in the NQN values, with these values in the range between 100 and 200 as shown in
Figure 3 (blue line). In this scenario, ingestion of data in the batch layer occurs every six months, ingestion of data in the speed layer is carried out every two weeks, and the frequency of reading the data is daily. Therefore, the model was created from a sample of approximately 180 observations and received 10 consecutive updates with samples of 18 values each.
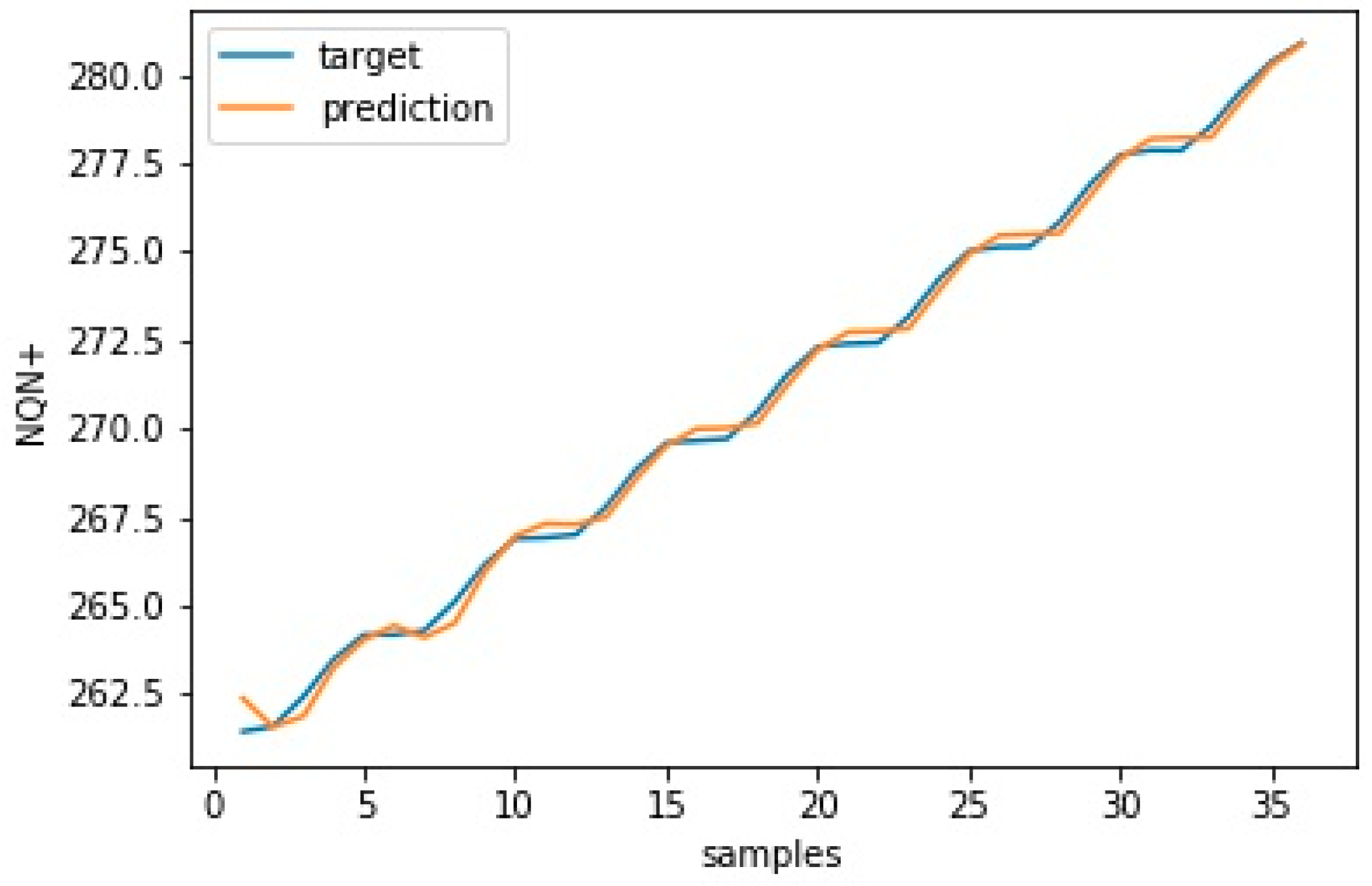
Scenario 2—severe: significant thermal deterioration or thermal cycling, resulting in delamination of the insulation. There is a fixed increase in NQN over time, with values ranging from 200 to 600, as shown in
Figure 3 (orange line). Here the batch layer is executed every six months with around 180 values and the speed layer every 10 days. In this case, model updates occurred more frequently due to the severity of partial discharges.
Scenario 3—critical: high NQN values indicating critical thermal deterioration and resulting in delamination and severely deteriorated coils. NQN values start around 500 and can reach a maximum value close to 1500 at which they tend to stabilize, although the winding continues to deteriorate, as shown in
Figure 3 (green line). For this scenario, the model was created with data from six months of measurements (180 samples) and received weekly updates due to the critical state of partial discharges.
4.2. Data Ingestion into Hadoop Distributed File System
The first step in the development of the proposed system concerns the data ingestion in Hadoop’s HDFS system from the data source. This ingestion task was performed using the Apache Sqoop tool, which is designed to transfer data between structured datastores and the HDFS file system. The tool used in this data ingestion task can vary depending on how the data collected by the sensors are stored. In this stage, two different types of sqoop jobs were created, one job to collect data in batches on a monthly basis, which may vary depending on the application, and another job for online collection as new data were generated.
4.3. Batch Layer and Speed Layer Creation in Hive
The ingestion of batch data was used in the creation of the so-called batch layer, which consolidates all the data collected immutably in a master table, to ensure the historical reliability of the data, and was used for the creation and training of the forecast model. The ingestion of data in the batch layer was carried out incrementally, usually on a monthly or weekly basis, but the forecasting model was created and training only in the first ingestion.
In the speed layer, on the other hand, data ingestion occurred in real time, collecting the data that was generated since the last batch layer update. In this case, the periodicity can be minute-wise also depending on the application and defined by the user.
The data collected in real time in the speed layer were used to update the training of the forecast model, as well as to provide the user with views of the current situation of the monitored equipment, together with the data of the batch layer, and views of the future situation of the equipment, together with the values estimated by the autoregressive forecasting model. Whenever the batch layer was updated, the speed layer data were deleted and the last-value parameter that indicates the starting point to restart the data reading for the new speed layer was also updated.
The structures for creating the batch layer as well as for the speed layer were tables created in the Hive data warehouse, developed for Apache Hadoop. As Hive is automatically connected to HDFS, views were updated whenever new data ingestion occurred in the speed layer, which also automatically updated the forecasting model. The automatic update can be managed with a workflow scheduler tool like Oozie, for example.
4.4. Forecast Model Creation
The proposed forecasting model was based on a LSTM recurrent neural network and it explored the possibility of updating the model as new data were generated. The creation and update of the model were carried out in the context of the lambda architecture, as illustrated in
Figure 2.
The batch layer can be updated weekly or monthly and, therefore, ingested a large volume of data. These data can be used to present views to the user and other purposes, but only the first intake was used to create the forecast model. The model was created in the Python environment using the machine learning scikit-learn keras and tensorflow libraries with Apache Spark’s in-memory primitives.
In this paper we used Keras framework for presenting the structure of the deep neural network prediction model because it is currently one of the most used libraries for this purpose. The Keras2DML framework can be used later to the parallel model training on Apache Spark.
4.5. Updating the Forecast Model
The forecast model was updated in the context of the lambda architecture after each speed layer new ingestion. The user can define exactly what frequency of update is desired, depending on the type of data collected by the sensors.
In this work, we dealt with variables related to partial discharges, in addition to generator vibration and temperature. These values can be correlated so that a condition (or event) can be evidenced that allows guiding operators on probable failures in progress and, thus, assisting them in decision making and strategic planning of stops and preventive maintenance.
4.6. Monitoring of Partial Discharges
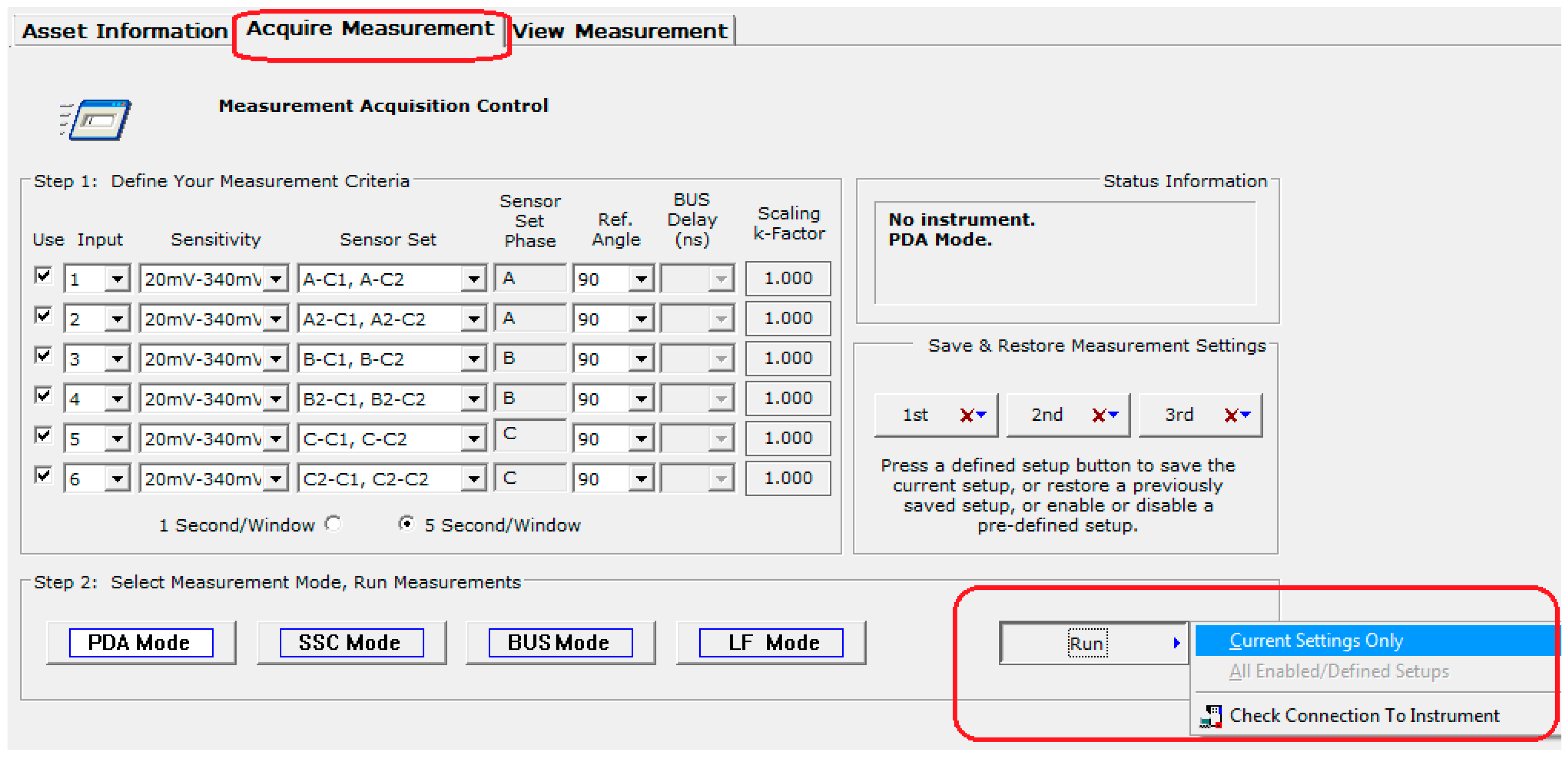
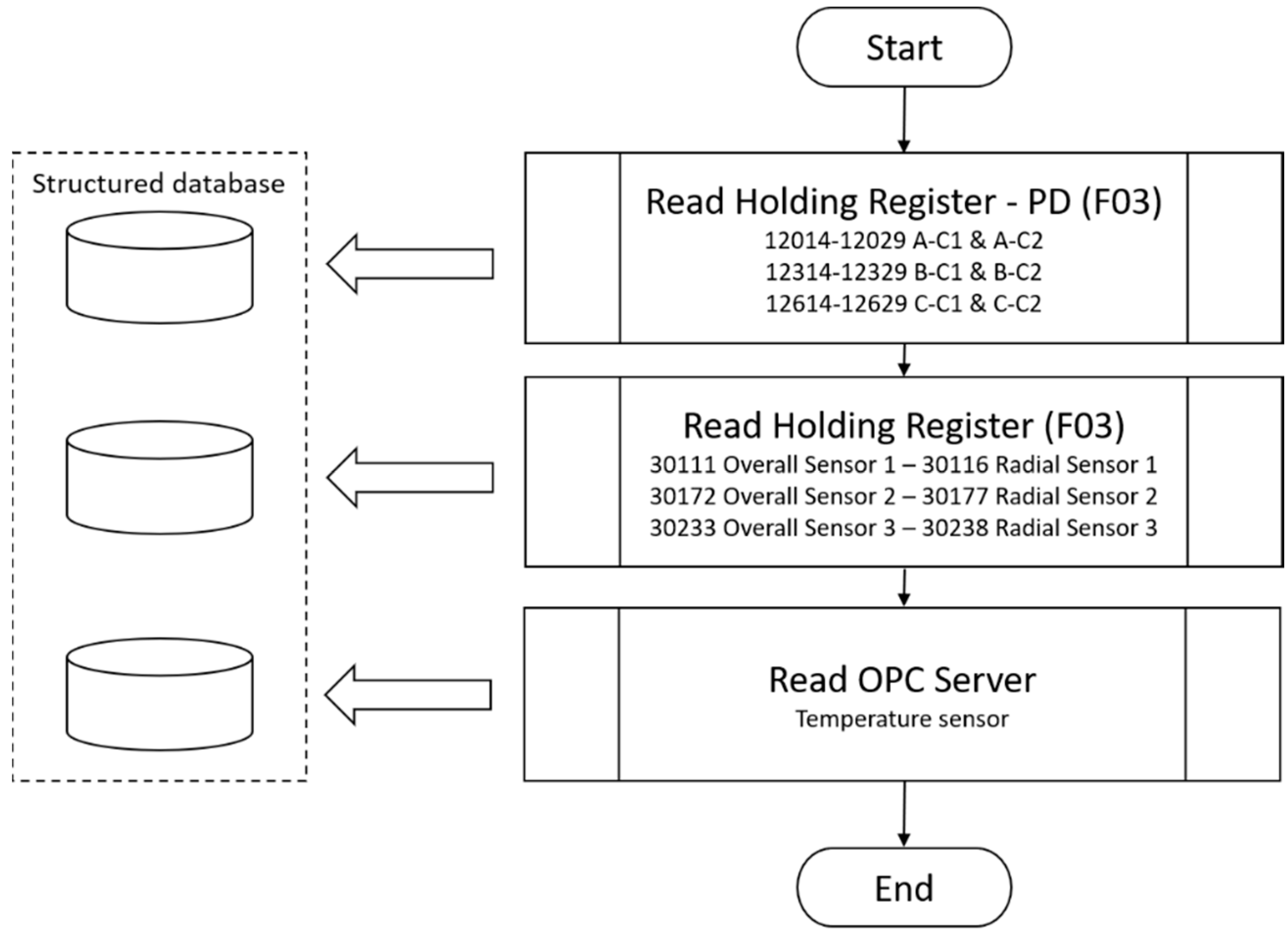
The partial discharge monitoring system was composed of power partial discharge epoxy mica capacitive sensors from Iris Power that were connected to the GuardII monitoring system for collecting of partial discharge pulse data through the sensors.
Figure 4 and
Figure 5 present, respectively, an illustration of this equipment and the installation panel for this system at the plant. Detailed information of the sensor including partial discharge pulse measurement, operating conditions, and testing and certification can be obtained in the Iris Power manual [
38].
The monitoring of partial discharges provides information about small electrical sparks that occur in the insulation due to its aging or deterioration. In this case, two important criteria were used to assess the operating conditions of the generator: The Normalized Quantity Number (NQN+ and NQN–) and the Maximum Amplitude Number (Qm+ and Qm–). The first data were obtained through the Holding Register on the condition-based monitoring instrument GuardII using the ModBus Transmission Control Protocol (TCP). The acquisition parameters were configured in the partial discharge sensors’ interface available in the system, according to
Figure 6.
After configuring the acquisition control parameters, the values were collected and stored in structured databases, as shown in the diagram in
Figure 7, for partial discharges, temperature, and vibration. The temperature values were read from an open platform communications server, PCL Siemens S7, which specified the communication of real-time sensor data.
The stator end-winding vibration caused by the loosening of the windings, together with the thermal cycling that deteriorates the condition of the insulators, can cause the rupture of the copper conductors or even failures due to the wear of the insulation.
5. Experimental Results
This section presents the results of a simulation of an application of the proposed approach for updating a model for forecasting future values of partial discharges in the stator insulation system of an hydrogenerator.
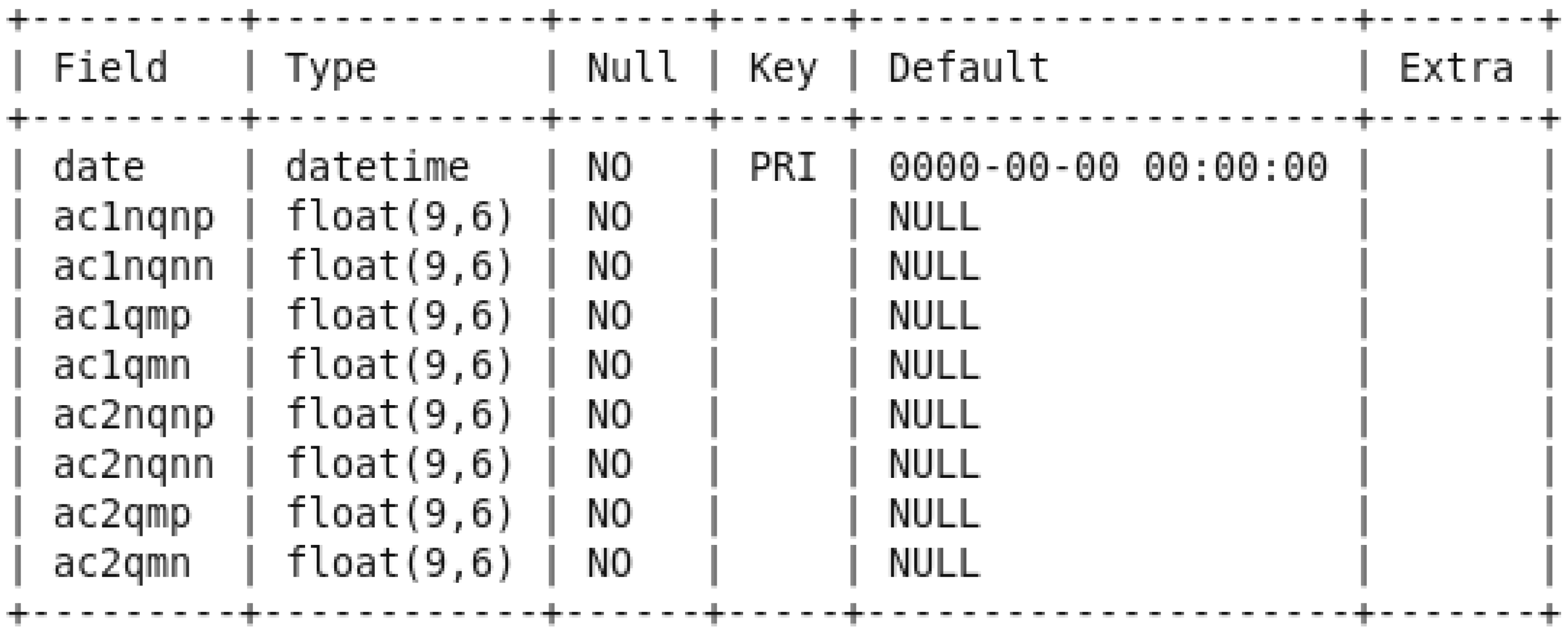
First, we created two sqoop jobs to get the collected sensor data from a structured mysql database to the Hadoop HDFS. The partial discharge data were in a table called
pddata from the
hydrogenerator_db database, which has the structure illustrated in
Figure 8, as an example for the set of sensors A-C1 & A-C2 and the variables NQN+, NQN–, Qm+, and Qm–.
The next step of the process was to ingest data into Hadoop’s HDFS from
hydrogenerator_db database to create the batch and the speed layers. We created two sqoop jobs to connect to the database and import data to the HDFS, according to the script in
Figure 9 for batch layer, for example.
Data ingestion was performed incrementally in HDFS according to the date parameter (primary key) and controlled by the last-value parameter that represented the last value read and, therefore, the starting point for the next import. In this simulation we considered a local database and the creation of a single process for the data ingestion task (m = 1). Sqoop imported the data to a directory in the default HDFS user directory created automatically with the same name as the source table.
Once the job was created it could be easily and repeatedly executed using the sqoop job –exec batchlayer command, with the job automatically saving the last-value parameter value for the next executions, ensuring that only the new data would be imported with each execution. It means the sqoop detected new registers in the database and updated the files in HDFS. In fact, the imported values were kept in HDFS in files in the comma-separated values (csv) format.
After data ingestion on HDFS, the next step was to create the master immutable table on Hive for the batch layer, batch views, and model training. Here we used the Beeline version 1.1.0-cdh5.13.0 as a wizard to run Hive queries [
39]. The connection to Hive was accomplished using the following command:
By default, Hive uses map reduce as a processing engine, which uses batch processing of large amounts of data. For our application, it was convenient to change the Hive processing engine to spark that works in memory and promotes a significant gain in relation to the processing time. The change of the execution engine can be made using the command
Then, we created on Hive a database to store the structures for master table in batch layer. The database was created exactly with the same name as the table inserted into HDFS,
pddata, and was linked to the file
csv in HDFS. It means that the master table was updated whenever a new data ingestion occurred in HDFS by executing the sqoop job. The master table was created in Hive database using a simple SQL-like query language, as the script presented in
Figure 10.
Again, it is important to note that the master table was automatically updated from any new importing data into HDFS. These data were used to create the forecast model, which can happen only once on first ingestion.
Model training can be performed using all or only part of the master table data set. It is possible, for example, to carry out the future forecast for all variables or for only one of the variables indicated in
Figure 6. As it is batch processing, the data are transferred to the forecast model by means of a file. In this case, we used the beeline tool to save a hive query output to a file using command:
in which
“hive.hql” is a sequence of commands in the Hive SQL-like query language as, for an example, for variable A-C1 NQN+,
“use pddata; select ac1nqnp from pddata_master;”.
In addition to training the forecasting model, data from the master table can be used to create views for the user as, for example, min and max values, first and third quartiles, and median values for box plot graphics.
A similar approach was applied to create the speed layer in Hive, with real-time processing. So, a sqoop job was created and executed to ingest the most recent data into Hadoop’s HDFS from hydrogenerator_db. In this case, however, two important points had to be considered: (1) As the Sqoop speedlayer job must acquire only the data generated since the last batch layer update, the last-value parameter must be updated whenever the batchlayer job is executed, at which point the speed layer data must be reset. This is done to ensure that there will be no duplicate data between the two layers. The value of the last-value parameter is defined after each execution of the batchlayer job using: var=$(mysql --user=root --password=userpass hydrogenerator _db -s -e “select max(date) from pddata;”) and the speed layer deleted by sqoop job --delete speedlayer. (2) When the sqoop speedlayer job ingests the data into HDFS a file with the same name as the batch layer is created. Therefore, to prevent the data collected online from overwriting the data in batch, a new directory must be created for speed layer, through the command: --target-dir.
The script for creating the Sqoop
speedlayer job is presented in
Figure 11. Unlike the batch layer, in the speed layer a temporary table was created in Hive, just for updating the forecast model and for creating views with data from the master table in the batch layer. The temporary table in the speed layer was created similarly to the master table, as shown in
Figure 10.
Finally, we applied the speed layer data saved in the local file output_speedlayer_file.csv to update the model’s training and improve its forecasting capacity, as discussed below.
Creating and Updating the Forecast Model
This section presents the results for creating and updating the forecast model using data from the batch and speed layers, respectively, as an example for variable A-C1 NQN+. The first phase was to divide the data into training and test samples and turn them into a supervised learning problem, in which previous time step samples were used as explanatory variables for the current time step sample. Also, in this phase we rescaled data to have values between –1 and 1.
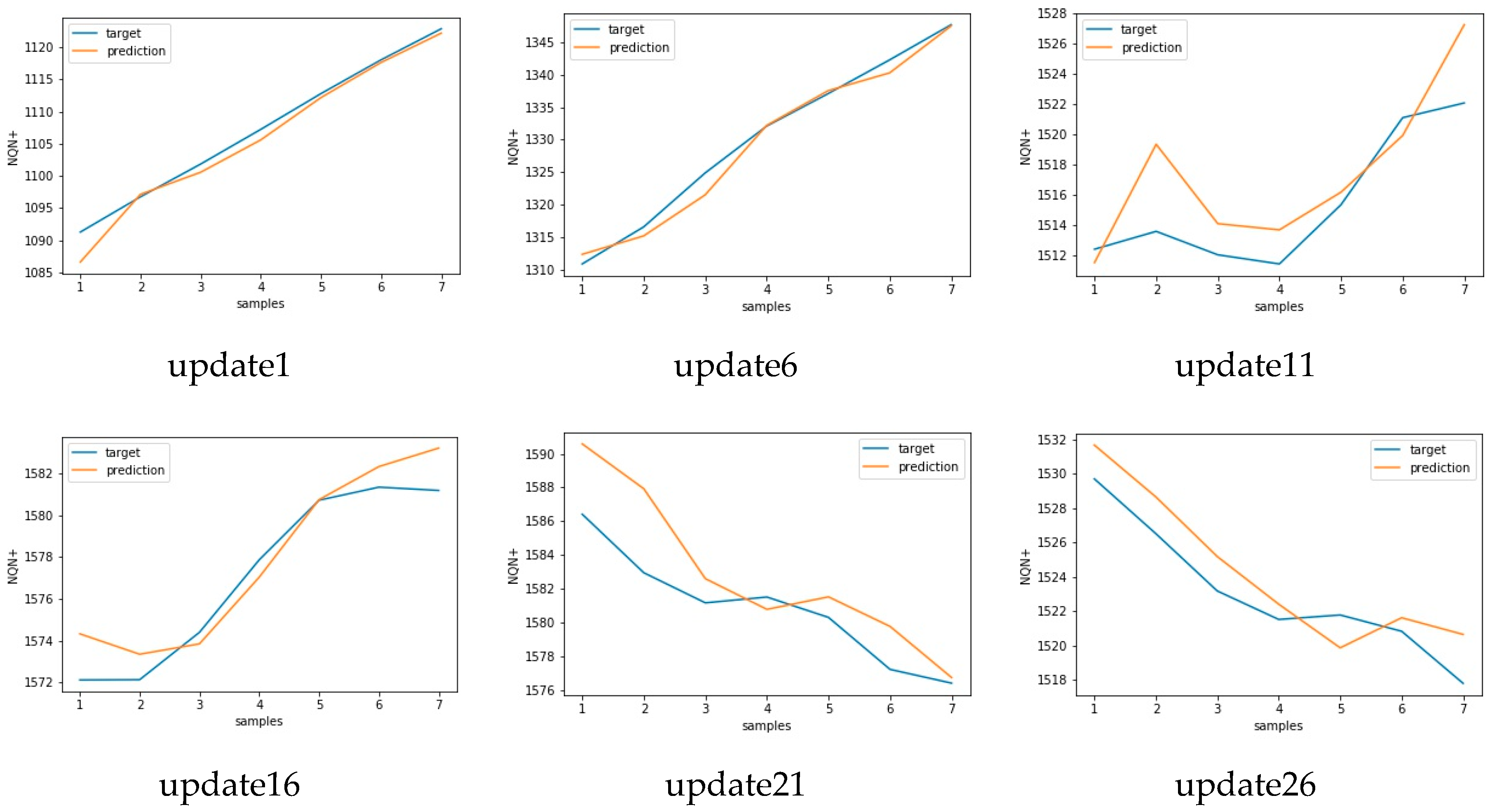
Thereafter, in each scenario the model was updated as new data became available in the speed layer. The model’s precision results before and after the updates were then presented and compared. In this simulation, a new sample was generated once a day, the batch layer job ran every six months, collecting 180 NQN+ values in each execution, and the speed layer was executed according to the severity of partial discharges.
The prediction model was based on a recurrent long short-term memory network (LSTM) with a backpropagation algorithm and the default sigmoid activation function. The model had an input layer with 1 neuron, a hidden layer with 10 LSTM blocks or neurons, and a single prediction output layer. The model was fit for 1000 epochs with online training (batch size of 1), Adaptive moment estimation (ADAM) optimization algorithm, and the root mean squared error (RMSE) loss function. A summary of the model is illustrated in
Figure 12.
The values of the model parameters were defined experimentally and results of the precision of predictions as well as the computational time as a function of the number of neurons in the hidden layer are shown in
Table 2, as an example for the third scenario. It is possible to see from the average values in the last row of the table that the use of 10 neurons in the hidden layer of the network produced the best results both in terms of RMSE and in relation to the computational cost in the training stage. This value was adopted in the following experiments. Other parameters did not produce significant changes in the results.
In each update the new data collected by the speed layer were added to the database, divided into training and test sets (80–20%), and the model evolved for an additional 50 epochs. The effects of the variation in the number of epochs for the model updating were also evaluated and are shown in
Table 3 for scenario critical. Results in the table show that this parameter had a great influence on the computational cost of the model without, however, promoting a significant performance gain. All experiments were performed on a Dell Inspiron 14 series 5000, Intel Core i7, 16 GB of RAN (Random Access Memory) computer from Dell Technologies Inc., Round Rock, Texas, United States of America, using IDE Spyder (Python 3.7).
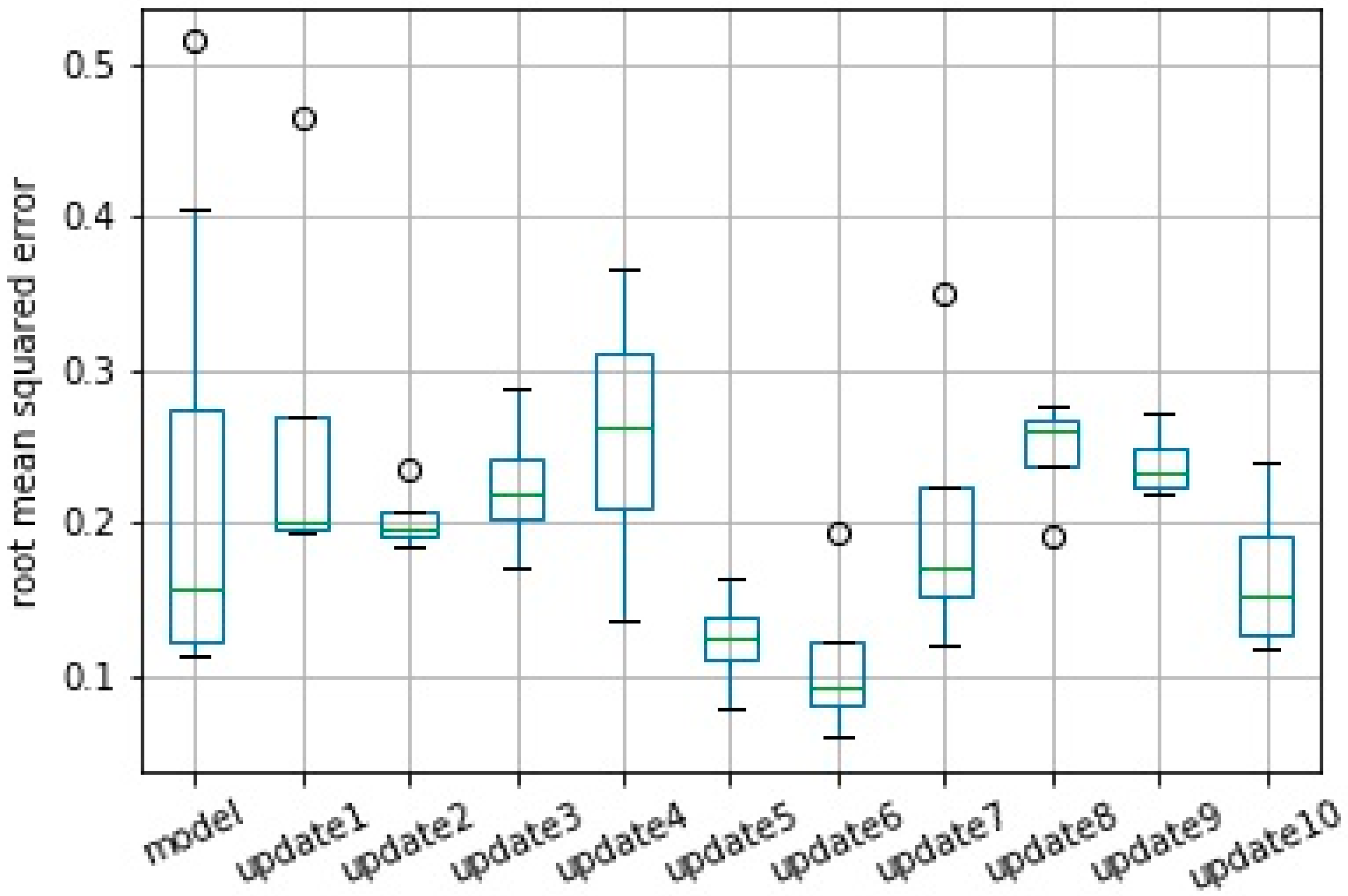
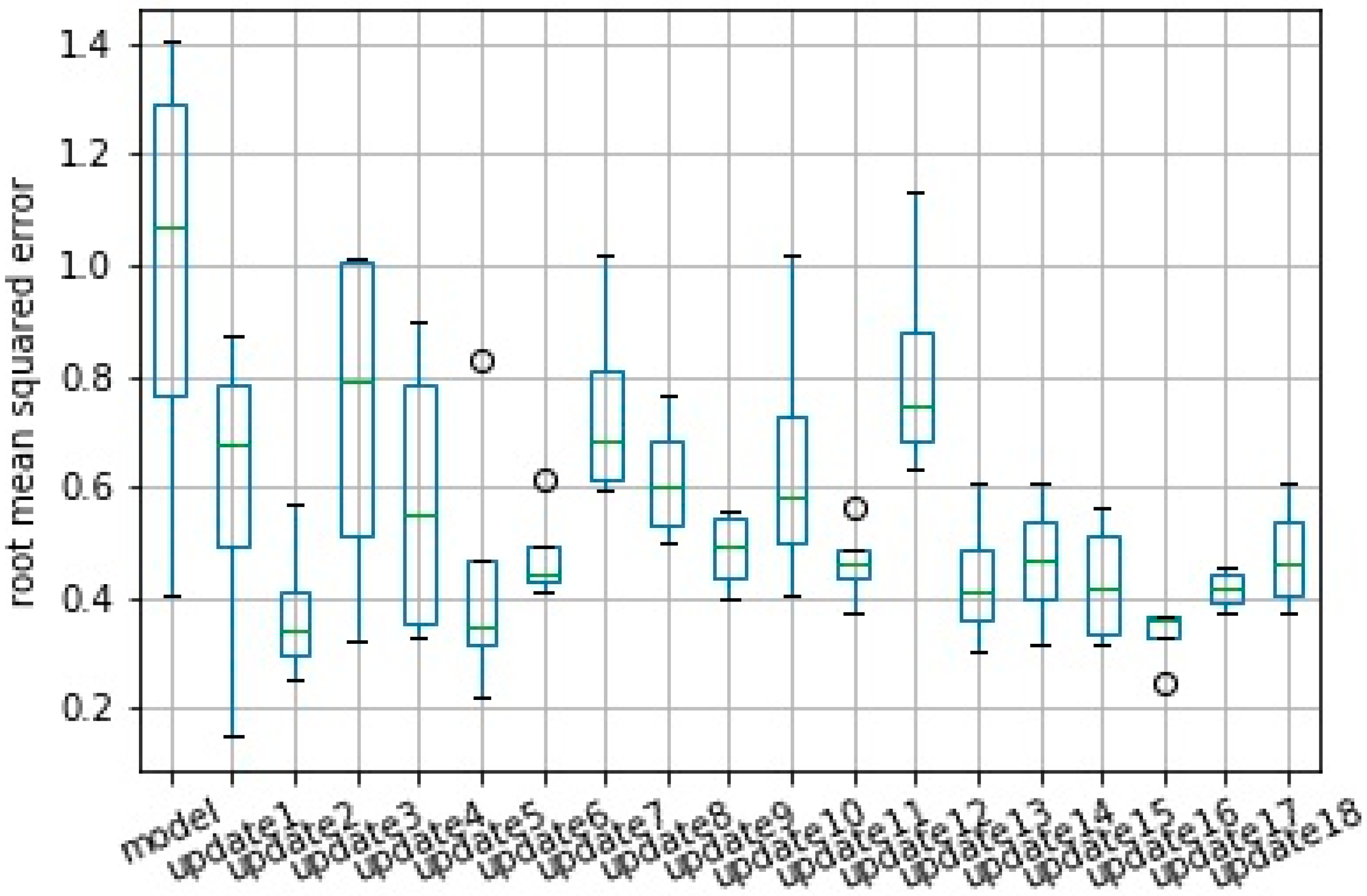
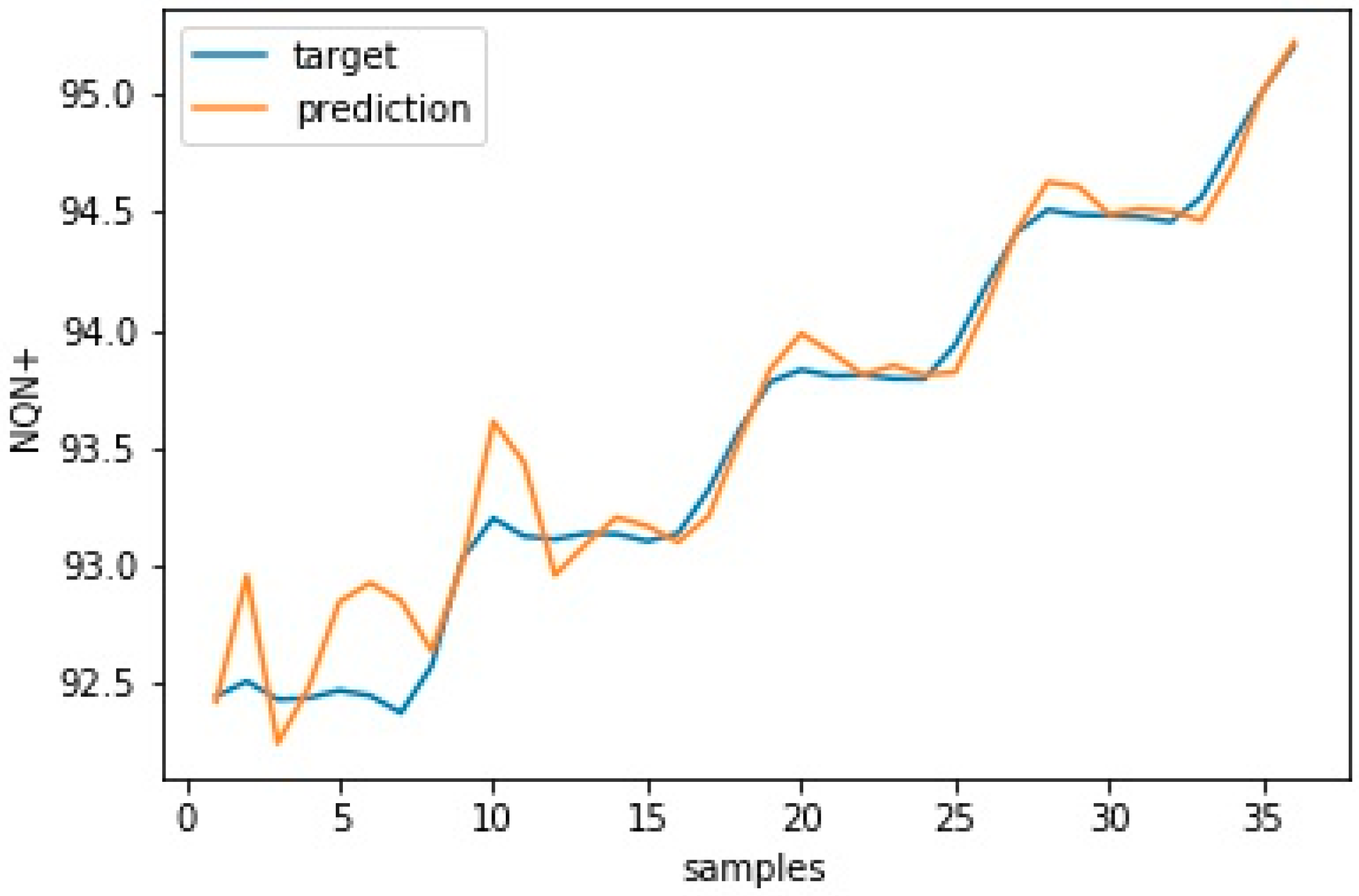
Performance of the prediction model evaluated by the RMSE is presented using a boxplot from 10 runs. Results from the original model, which was created with batch layer data, and from all consecutive model updates are presented in
Figure 13 and
Figure 14 for scenarios normal and severe, respectively.
It is important to note that the mean error obtained in model training for scenario normal, which was 0.222, represents a forecast accuracy of 99.7%, with a maximum error of 0.514 and an accuracy of 99.4%. The updates promoted a further small improvement in the model reaching 99.8% accuracy in relation to the RMSE in update 10. However, the reduction of the standard deviation of the error after the model updates stood out. The error of the original model had a deviation of 0.146, which was reduced to 0.055 after the 10th update, creating a more robust model.
For scenario 2—severe, the average error was reduced from 0.986 to 0.475, which represents an increase in model accuracy from 99.6% to 99.8%. This accuracy here was calculated as 1—nRMSE in which the nRMSE is the normalized RMSE defined according Equation (1).
in which mean(Y
t) is the average of the target values in the test set.
Also, in this case, the reduction of the standard deviation of the error was the most significant, reducing from 0.444 in the original model to 0.104 in the last update.
It is worth noting that the RMSE did not consider variations in the data collected in the speed layer and that this variation interfered with the accuracy of the model. Thus, even if an update improves the forecasting capacity of the model, the RMSE value may be higher than the previous error due to the variance of the new data used to evaluate this update.
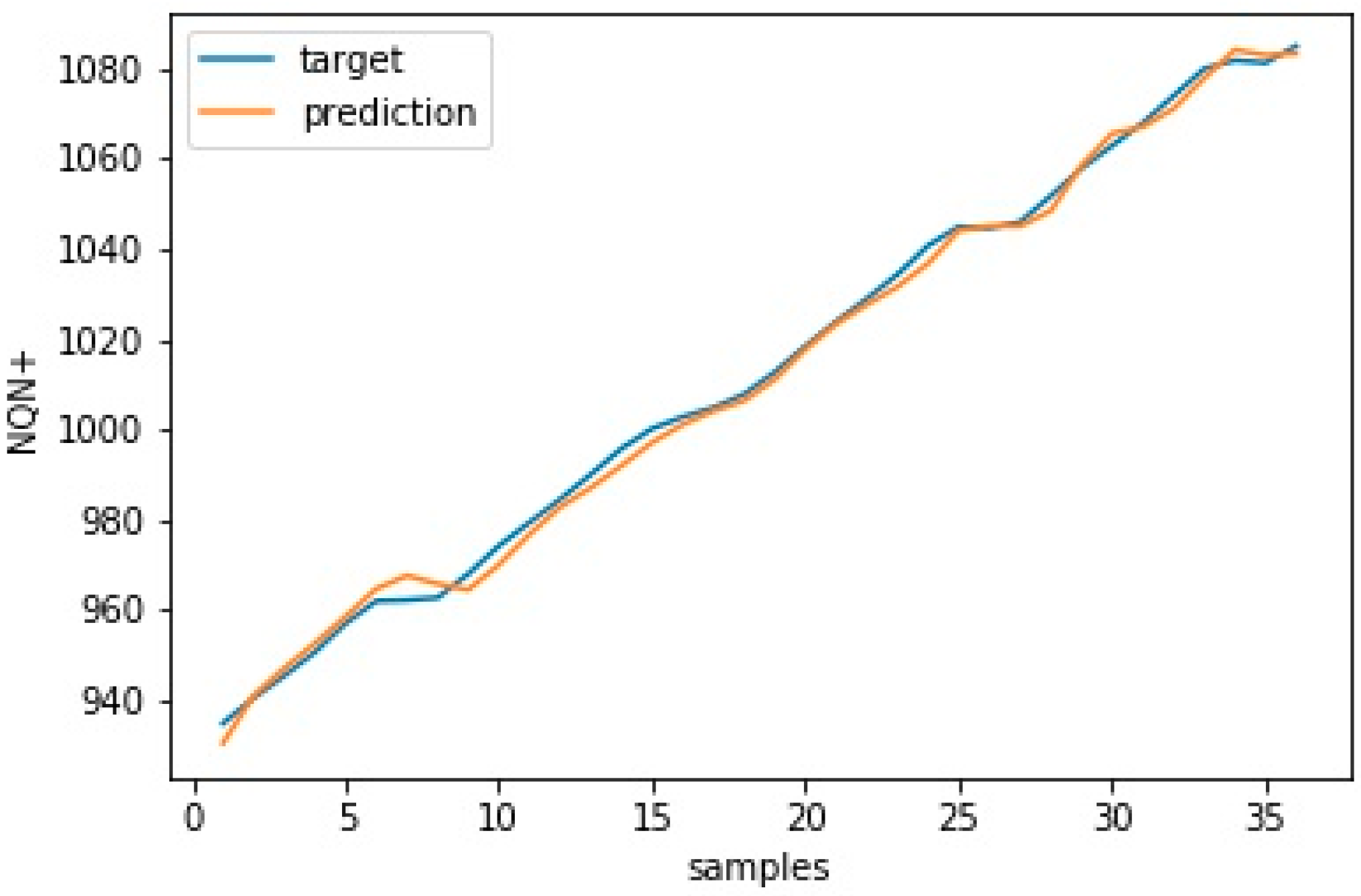
Figure 15 and
Figure 16 show the model’s validation results with plots for target versus prediction data for training and test data for scenario 1—normal.
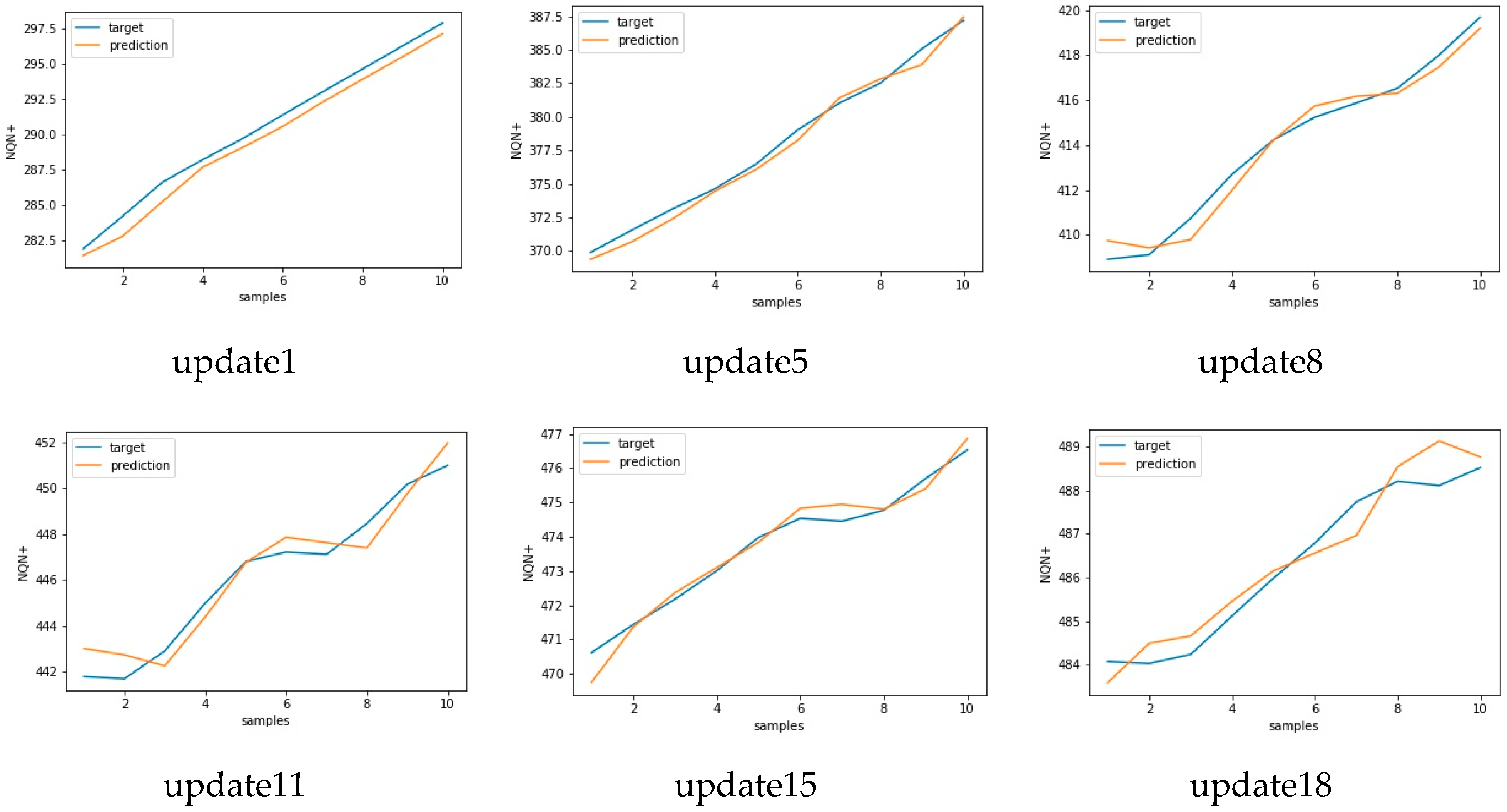
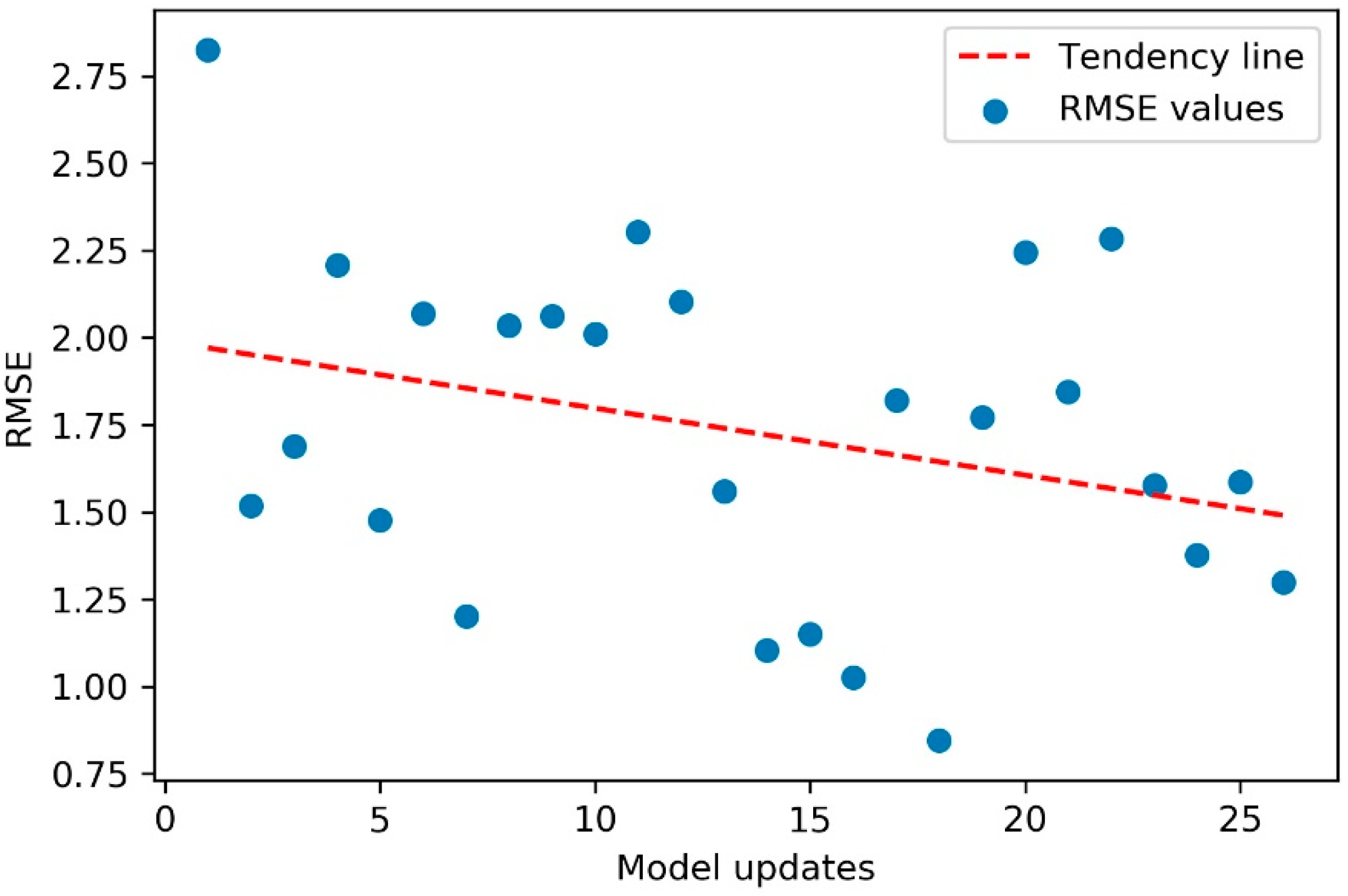
For scenario 3, the initial updates promoted an improvement in the RMSE obtained by the model, reducing the original model average error from 1708 to 1044 in update 17. This reduction in the average error represents a change in accuracy from 99.7% to 99.8%, which shows that there was little margin for improvements in the model. The standard deviation of RMSE was practically stable in this case.
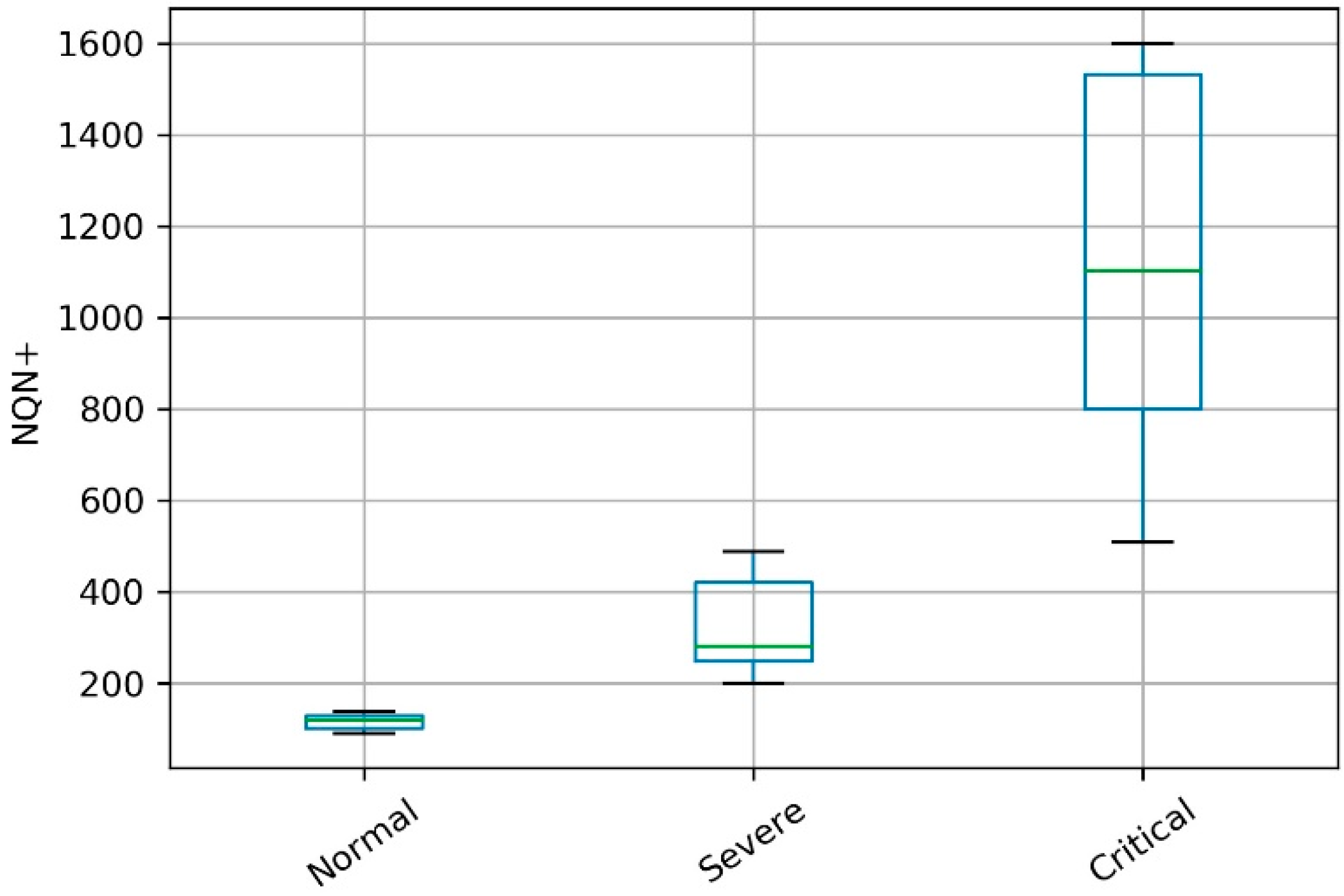
It is important to note that the values for scenario 3 had a greater standard deviation in relation to the other two scenarios, as illustrated in
Figure 21 as a boxplot format. But despite this greater variation, the accuracy of the model for this scenario was greater than 99% as well in the two other scenarios. This result indicates that the model presented low sensitivity in relation to variations in the severity of the partial discharge, presenting a competitive performance with the related literature regardless of the scenario tested: normal, severe, or critical conditions.
In addition, despite variations observed in the RMSE values, and a greater variation in the data for scenario 3, the model tended to increase in accuracy, as illustrated in the scatter plot of
Figure 22.
Table 4 shows a comparison of the proposed approach with some works that used partial discharge, type of partial discharge, and recognition accuracy.
6. Conclusions and Future Work
This paper proposed a method to update the forecasting model aiming to improve its accuracy, based on a distributed data platform with the lambda architecture, which combines real-time and batch processing techniques. The architecture allows the creation of a prediction model for partial discharges in hydrogenerators using historical data from batch layer processing. In addition, real-time data in the speed layer were used to update the model, gradually increasing the accuracy of its predictions. After updates, the model evolved in its ability to estimate partial discharges, promoting an increase in the accuracy of the forecast. In addition, the robustness of the model’s prediction stood out, which showed low variation in all forecasts, with a low standard deviation in RMSE values.
The model presented low sensitivity in relation to variations in the severity of the partial discharge, presenting a competitive performance with the related literature regardless of the scenario tested: normal, severe, or critical conditions. The use of a batch processing layer and a real-time processing layer made it possible to handle large volumes of data (batch layer) while ensuring that the model was updated by frequent execution of the speed layer. This approach allowed us to mitigate common limitations of computation and communication channel bandwidth problems in data-driven practical control systems.
A disadvantage of the proposed approach is the use of RMSE since this absolute error measure has a high influence of outliers in data on the forecast performance evaluation. In addition, RMSE has low reliability as the results could be different in different fraction of data. The use of a relative measure can result in greater accuracy of the model, especially in the latest model updates in scenario 3.
Future work includes the application of a technique based on the wavelet transform to determine the optimal delay in the autoregressive forecasting model and the application of the proposed architecture for forecasting future values for the other partial discharge variables, as well as for vibration and temperature. The coupling of the model forecast results with the equations for calculating the remaining life can also be considered.

 ,
, 






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}