Comparison of a Deep Learning-Based Pose Estimation System to Marker-Based and Kinect Systems in Exergaming for Balance Training

 ,
,  , ,
, ,  and
and
Abstract
1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Protocol
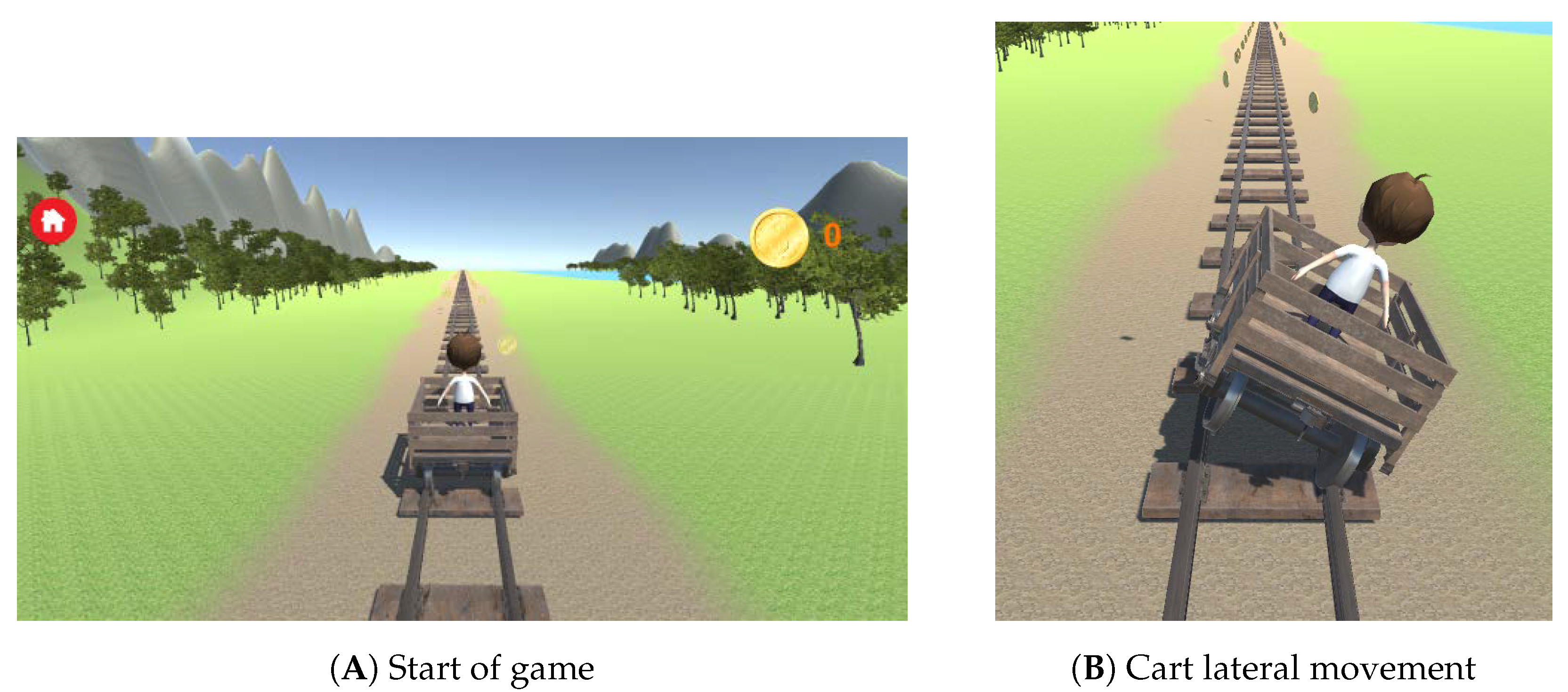
2.2.1. The Exergame
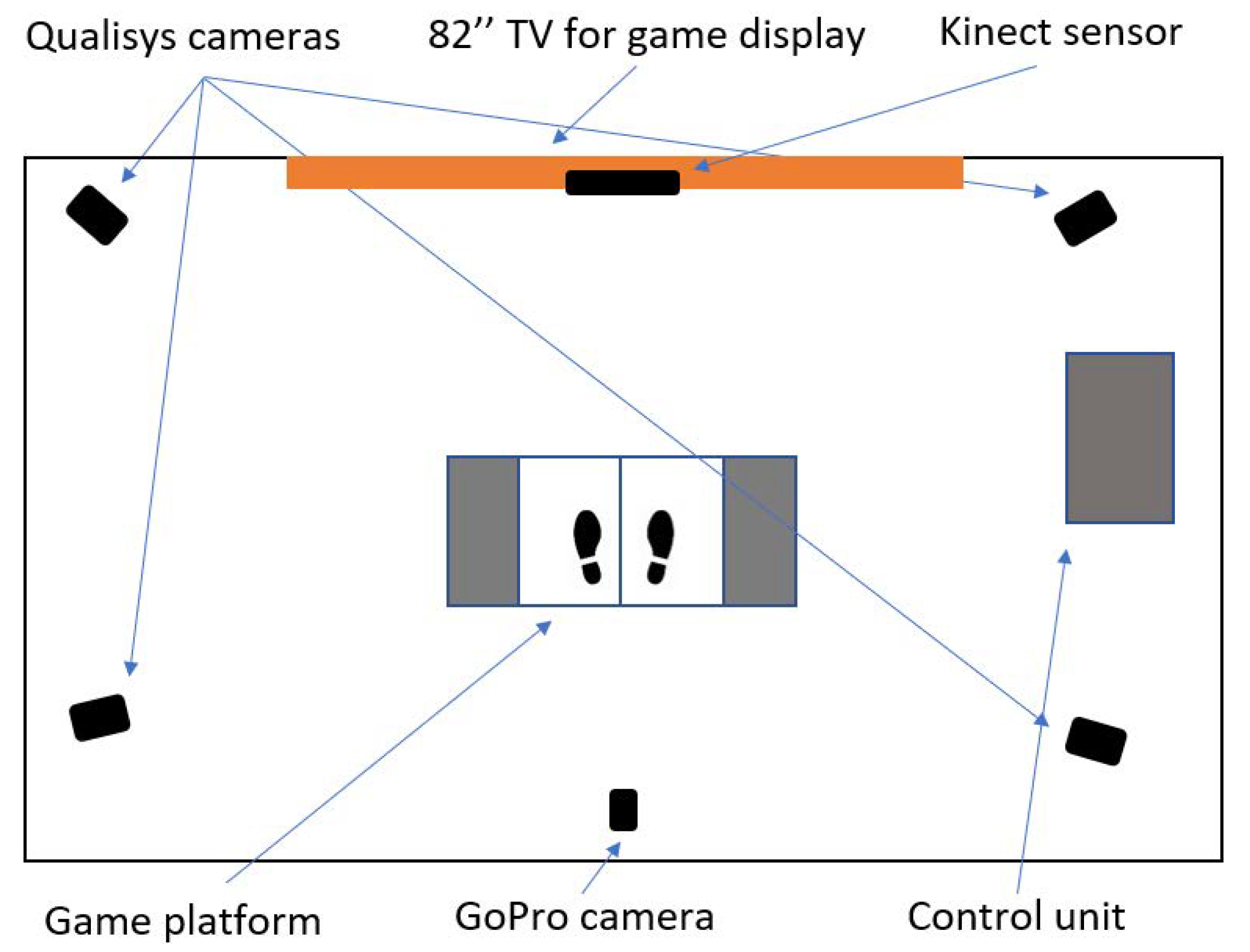
2.2.2. Equipment
2.3. Processing and Analysis
2.3.1. Dataset
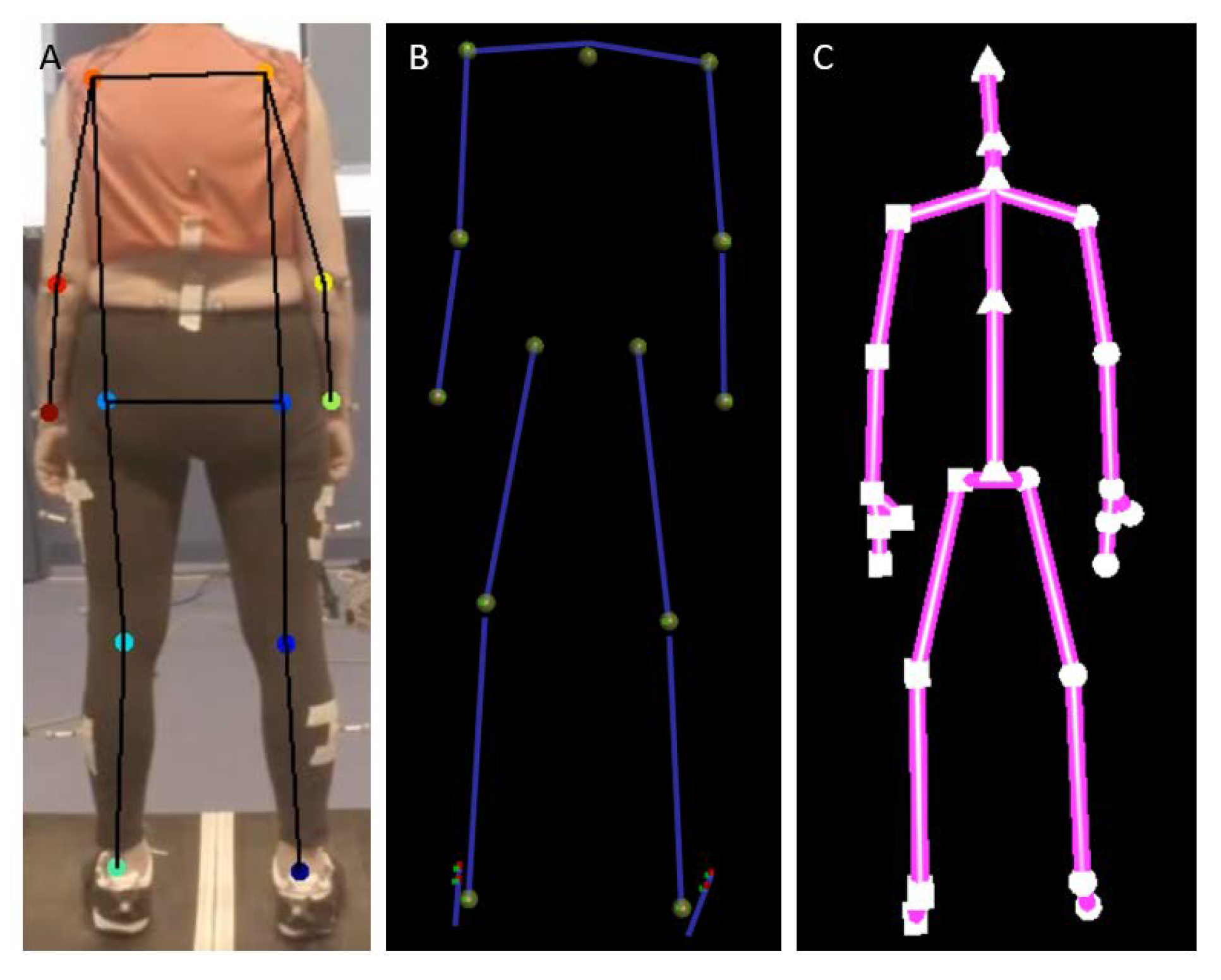
2.3.2. Preprocesssing of Kinect and 3DMoCap Data
2.3.3. Preprocessing of DeepLabCut Data
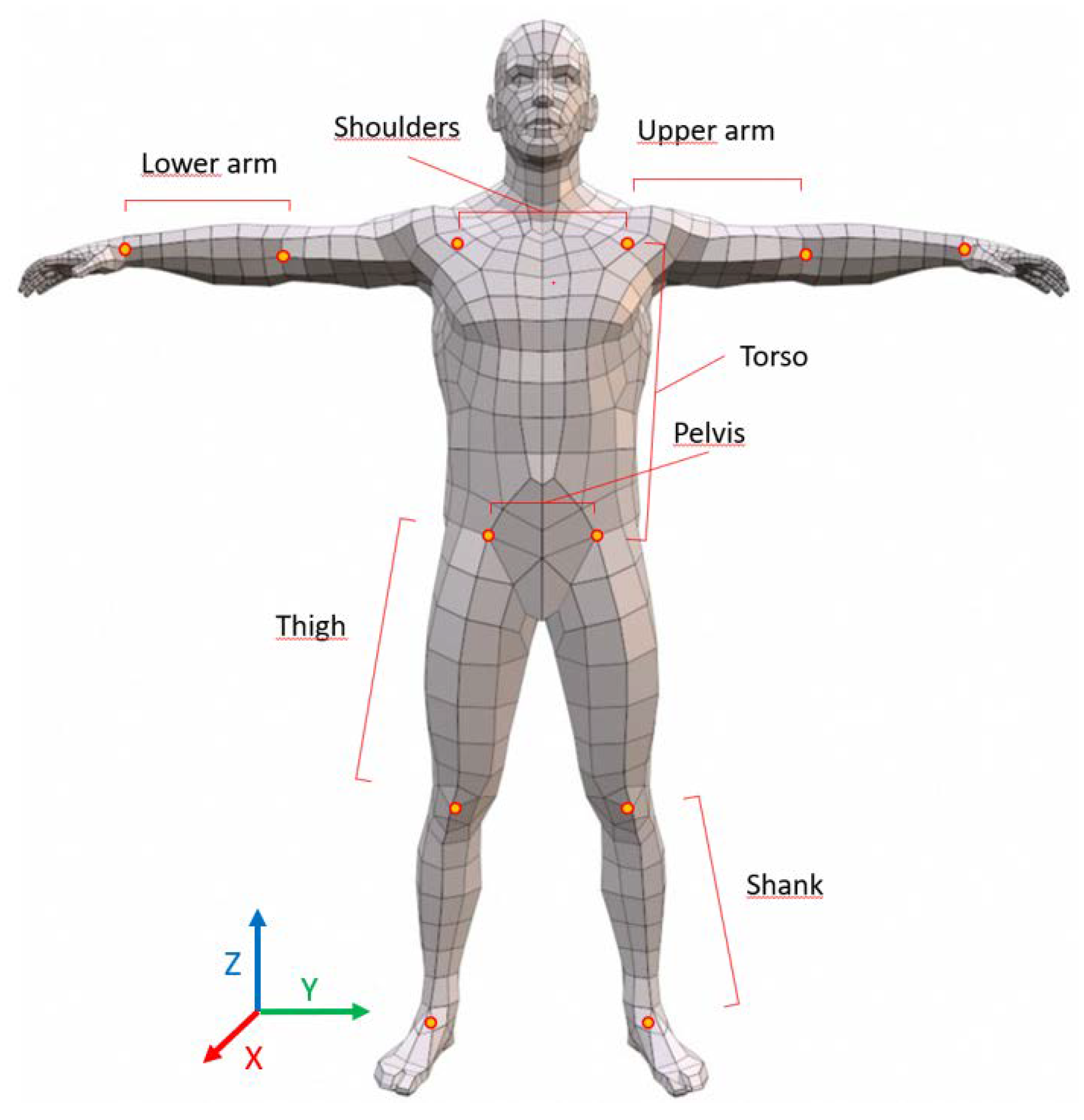
2.3.4. Calculation of Segment Lengths and Variability
2.3.5. Statistical Analysis
3. Results
3.1. Mean Lengths
3.2. Segment Length Variability
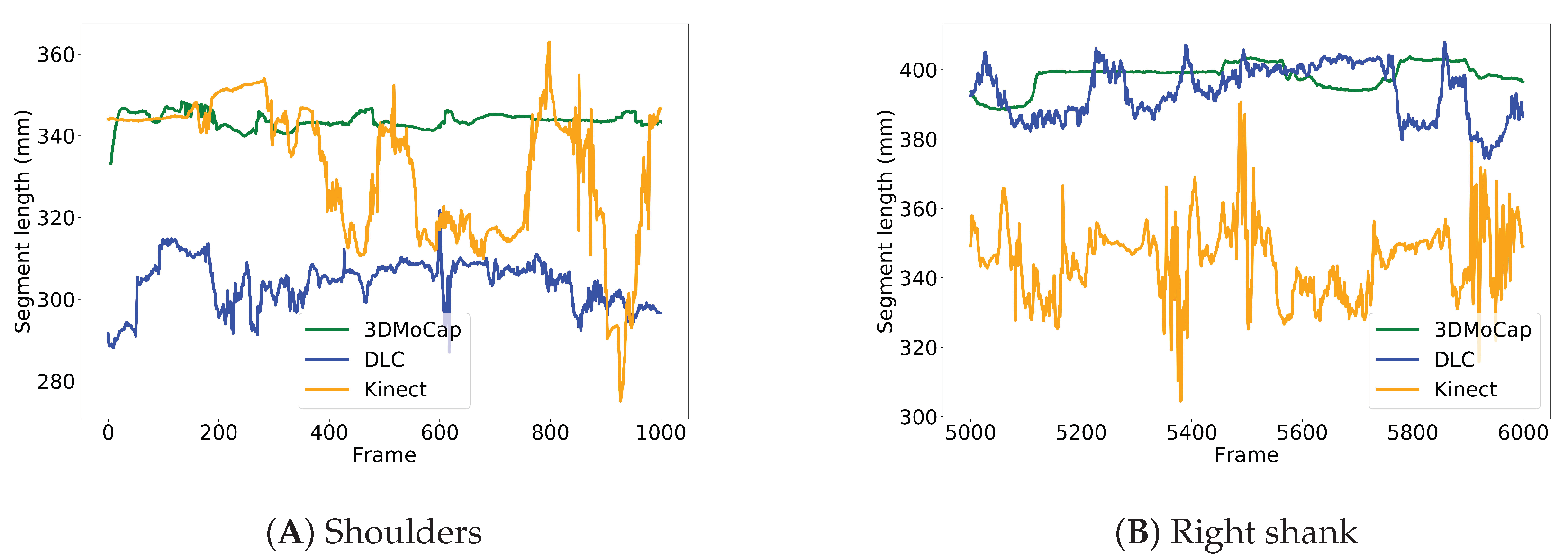
3.2.1. Upper and Lower Arm
3.2.2. Torso and Shoulders
3.2.3. Pelvis
3.2.4. Thigh and Shanks
4. Discussion
4.1. Implications
4.2. Related Work
4.3. Further Considerations and Future Directions
4.4. Limitations
4.5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| DL | Deep Learning |
| ML | Machine Learning |
| RBG-D | Red Blue Green - Depth |
| 3DMoCap | 3D Motion Capture |
| IMU | Inertial Measurement Unit |
| ResNet | Residual Neural Network |
| DLC | DeepLabCut |
| CNN | Convolutional Neural Network |
| SD | Standard Deviation |
| CoeffVar | Coefficient of Variation |
References
- Beard, J.R.; Bloom, D.E. Towards a comprehensive public health response to population ageing. Lancet 2015, 385, 658–661. [Google Scholar] [CrossRef]
- Proffitt, R.; Lange, B. Considerations in the Efficacy and Effectiveness of Virtual Reality Interventions for Stroke Rehabilitation: Moving the Field Forward. Phys. Ther. 2015, 95, 441–448. [Google Scholar] [CrossRef] [PubMed]
- Skjæret, N.; Nawaz, A.; Morat, T.; Schoene, D.; Lægdheim, J.; Vereijken, B. Exercise and rehabilitation delivered through exergames in older adults: An integrative review of technologies, safety and efficacy. Int. J. Med. Inform. 2016, 85, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Wuest, S.; Borghese, N.A.; Pirovano, M.; Mainetti, R.; van de Langenberg, R.; de Bruin, E.D. Usability and Effects of an Exergame-Based Balance Training Program. Games Health J. 2014, 3, 106–114. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.H.; Huang, L.L.; Wang, C.H. Developing a Digital Game for Stroke Patients’ Upper Extremity Rehabilitation—Design, Usability and Effectiveness Assessment. In Proceedings of the 6th International Conference on Applied Human Factors and Ergonomics (AHFE 2015) and the Affiliated Conferences, Las Vegas, NV, USA, 26–30 July 2015; Volume 3, pp. 6–12. [Google Scholar] [CrossRef]
- Rand, D.; Givon, N.; Weingarden, H.; Nota, A.; Zeilig, G. Eliciting upper extremity purposeful movements using video games: A comparison with traditional therapy for stroke rehabilitation. Neurorehabilit. Neural Repair 2014, 28, 733–739. [Google Scholar] [CrossRef] [PubMed]
- Lang, C.E.; Macdonald, J.R.; Reisman, D.S.; Boyd, L.; Kimberley, T.J.; Schindler-Ivens, S.M.; Hornby, T.G. Observation of Amounts of Movement Practice Provided During Stroke Rehabilitation. Arch. Phys. Med. Rehabil. 2009, 90, 1692–1698. [Google Scholar] [CrossRef] [PubMed]
- de Rooij, I.J.M.; van de Port, I.G.L.; Meijer, J.W.G. Effect of Virtual Reality Training on Balance and Gait Ability in Patients with Stroke: Systematic Review and Meta-Analysis. Phys. Ther. 2016, 96, 1905–1918. [Google Scholar] [CrossRef]
- Crabolu, M.; Pani, D.; Raffo, L.; Conti, M.; Cereatti, A. Functional estimation of bony segment lengths using magneto-inertial sensing: Application to the humerus. PLoS ONE 2018, 13, e203861. [Google Scholar] [CrossRef]
- Kainz, H.; Modenese, L.; Lloyd, D.; Maine, S.; Walsh, H.; Carty, C. Joint kinematic calculation based on clinical direct kinematic versus inverse kinematic gait models. J. Biomech. 2016, 49, 1658–1669. [Google Scholar] [CrossRef]
- Tak, I.; Wiertz, W.P.; Barendrecht, M.; Langhout, R. Validity of a New 3-D Motion Analysis Tool for the Assessment of Knee, Hip and Spine Joint Angles during the Single Leg Squat. Sensors 2020, 20, 4539. [Google Scholar] [CrossRef]
- Shotton, J.; Fitzgibbon, A.; Blake, A.; Kipman, A.; Finocchio, M.; Moore, B.; Sharp, T. Real-Time Human Pose Recognition in Parts from a Single Depth Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Gaglio, S.; Re, G.L.; Morana, M. Human Activity Recognition Process Using 3-D Posture Data. IEEE Trans. Hum.-Mach. Syst. 2015, 45, 586–597. [Google Scholar] [CrossRef]
- Obdrzalek, S.; Kurillo, G.; Ofli, F.; Bajcsy, R.; Seto, E.; Jimison, H.; Pavel, M. Accuracy and robustness of Kinect pose estimation in the context of coaching of elderly population. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, EMBS, San Diego, CA, USA, 28 August–1 September 2012; pp. 1188–1193. [Google Scholar] [CrossRef]
- van Diest, M.; Stegenga, J.; Wörtche, H.J.; Postema, K.; Verkerke, G.J.; Lamoth, C.J. Suitability of Kinect for measuring whole body movement patterns during exergaming. J. Biomech. 2014, 47, 2925–2932. [Google Scholar] [CrossRef] [PubMed]
- Ma, M.; Proffitt, R.; Skubic, M. Validation of a Kinect V2 based rehabilitation game. PLoS ONE 2018, 13, e202338. [Google Scholar] [CrossRef] [PubMed]
- Otte, K.; Kayser, B.; Mansow-Model, S.; Verrel, J.; Paul, F.; Brandt, A.U.; Schmitz-Hübsch, T. Accuracy and Reliability of the Kinect Version 2 for Clinical Measurement of Motor Function. PLoS ONE 2016, 11, e166532. [Google Scholar] [CrossRef]
- Bonnechère, B.; Jansen, B.; Salvia, P.; Bouzahouene, H.; Omelina, L.; Moiseev, F.; Sholukha, V.; Cornelis, J.; Rooze, M.; Van Sint Jan, S. Validity and reliability of the Kinect within functional assessment activities: Comparison with standard stereophotogrammetry. Gait Posture 2014, 39, 593–598. [Google Scholar] [CrossRef]
- Shu, J.; Hamano, F.; Angus, J. Application of extended Kalman filter for improving the accuracy and smoothness of Kinect skeleton-joint estimates. J. Eng. Math. 2014, 88, 161–175. [Google Scholar] [CrossRef]
- Cao, Z.; Hidalgo Martinez, G.; Simon, T.; Wei, S.E.; Sheikh, Y.A. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef]
- Insafutdinov, E.; Pishchulin, L.; Andres, B.; Andriluka, M.; Schiele, B. DeeperCut: A Deeper, Stronger, and Faster Multi-Person Pose Estimation Model. In European Conference on Computer Vision Computer Vision—ECCV 2016; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9910. [Google Scholar]
- Groos, D.; Ramampiaro, H.; Ihlen, E.A. EfficientPose: Scalable single-person pose estimation. Appl. Intell. 2020. [Google Scholar] [CrossRef]
- Mathis, A.; Mamidanna, P.; Cury, K.M.; Abe, T.; Murthy, V.N.; Mathis, M.W.; Bethge, M. DeepLabCut: Markerless Pose Estimation of User-Defined Body Parts with Deep Learning. Nat. Neurosci. 2018, 21, 1281–1289. [Google Scholar] [CrossRef]
- Mathis, A.; Schneider, S.; Lauer, J.; Mathis, M.W. A Primer on Motion Capture with Deep Learning: Principles, Pitfalls, and Perspectives. Neuron 2020, 108, 44–65. [Google Scholar] [CrossRef]
- Howe, T.E.; Rochester, L.; Neil, F.; Skelton, D.A.; Ballinger, C. Exercise for improving balance in older people. Cochrane Database Syst. Rev. 2011, 11. [Google Scholar] [CrossRef] [PubMed]
- Da Gama, A.; Fallavollita, P.; Teichrieb, V.; Navab, N. Motor Rehabilitation Using Kinect: A Systematic Review. Games Health J. 2015, 4, 123–135. [Google Scholar] [CrossRef] [PubMed]
- Vicon Motion Systems Limited. Plug-In Gait Reference Guide. Available online: https://usermanual.wiki/Document/Plugin20Gait20Reference20Guide.754359891/amp (accessed on 13 May 2020).
- Zhu, Y.; Zhao, Y.; Zhu, S.C. Understanding Tools: Task-Oriented Object Modeling, Learning and Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–26 June 2009. [Google Scholar]
- McCrum, C.; Gerards, M.H.; Karamanidis, K.; Zijlstra, W.; Meijer, K. A systematic review of gait perturbation paradigms for improving reactive stepping responses and falls risk among healthy older adults. Eur. Rev. Aging Phys. Act. 2017, 14, 3. [Google Scholar] [CrossRef] [PubMed]
- Sherrington, C.; Fairhall, N.J.; Wallbank, G.K.; Tiedemann, A.; Michaleff, Z.A.; Howard, K.; Clemson, L.; Hopewell, S.; Lamb, S.E. Exercise for preventing falls in older people living in the community. Cochrane Database Syst. Rev. 2019, 1. [Google Scholar] [CrossRef]
- Sarafianos, N.; Boteanu, B.; Ionescu, B.; Kakadiaris, I.A. 3D Human pose estimation: A review of the literature and analysis of covariates. Comput. Vis. Image Underst. 2016, 152, 1–20. [Google Scholar] [CrossRef]
- van Diest, M.; Lamoth, C.C.; Stegenga, J.; Verkerke, G.J.; Postema, K. Exergaming for balance training of elderly: State of the art and future developments. J. NeuroEng. Rehabil. 2013, 10, 101. [Google Scholar] [CrossRef]
- Capecci, M.; Ceravolo, M.G.; Ferracuti, F.F.; Iarlori, S.; Longhi, S.; Romeo, L.; Russi, S.N.; Verdini, F. Accuracy evaluation of the Kinect v2 sensor during dynamic movements in a rehabilitation scenario. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society—EMBS, Orlando, FL, USA, 16–20 August 2016; pp. 5409–5412. [Google Scholar] [CrossRef]
- Xu, X.; McGorry, R.W. The validity of the first and second generation Microsoft Kinect for identifying joint center locations during static postures. Appl. Ergon. 2015, 49, 47–54. [Google Scholar] [CrossRef]
- Chen, Y.; Tian, Y.; He, M. Monocular human pose estimation: A survey of deep learning-based methods. Comput. Vis. Image Underst. 2020, 192, 102897. [Google Scholar] [CrossRef]
- Sun, X.; Xiao, B.; Wei, F.; Liang, S.; Wei, Y. Integral Human Pose Regression. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 529–545. [Google Scholar]
- Arnab, A.; Doersch, C.; Zisserman, A. Exploiting temporal context for 3D human pose estimation in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3395–3404. [Google Scholar]
- Mehta, D.; Sotnychenko, O.; Mueller, F.; Xu, W.; Elgharib, M.; Fua, P.; Seidel, H.P.; Rhodin, H.; Pons-Moll, G.; Theobalt, C. XNect. ACM Trans. Graph. 2020, 39, 1–24. [Google Scholar] [CrossRef]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6M: Large scale datasets and predictive methods for 3D human sensing in natural environments. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1325–1339. [Google Scholar] [CrossRef]
- Nakano, N.; Sakura, T.; Ueda, K.; Omura, L.; Kimura, A.; Iino, Y.; Fukashiro, S.; Yoshioka, S. Evaluation of 3D Markerless Motion Capture Accuracy Using OpenPose With Multiple Video Cameras. Front. Sport. Act. Living 2020, 2, 50. [Google Scholar] [CrossRef]
- Della Croce, U.; Leardini, A.; Chiari, L.; Cappozzo, A. Human movement analysis using stereophotogrammetry Part 4: Assessment of anatomical landmark misplacement and its effects on joint kinematics. Gait Posture 2005, 21, 226–237. [Google Scholar] [CrossRef] [PubMed]
- Mündermann, L.; Corazza, S.; Andriacchi, T. The evolution of methods for the capture of human movement leading to markerless motion capture for biomechanical applications. J. Neuroeng. Rehabil. 2006, 3, 1–11. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Segment | Side | 3DMoCap | DLC | Kinect | |||
|---|---|---|---|---|---|---|---|
| N | N | N | |||||
| Shoulders | 11 | 328.8 (23.5) | 12 | 308.8 (25.5) | 12 | 330.9 (20.2) | |
| Upper arm | L | 11 | 269.5 (19.1) | 12 | 351.0 (20.5) | 12 | 269.8 (15.9) |
| R | 11 | 279.5 (22.6) | 12 | 357.8 (23.2) | 12 | 267.1 (13.2) | |
| Lower arm | L | 11 | 228.5 (20.4) | 12 | 228.7 (16.6) | 12 | 235.8 (13.3) |
| R | 11 | 225.1 (12.8) | 12 | 231.9 (16.1) | 12 | 235.3 (14.8) | |
| Torso | L | 11 | 444.7 (27.8) | 12 | 568.5 (33.7) | 12 | 503.8 (27.4) |
| R | 11 | 439.9 (25.9) | 12 | 566.1 (38.3) | 12 | 497.9 (27.6) | |
| Pelvis | 11 | 148.6 (5.6) | 12 | 280.6 (28.5) | 12 | 154.8 (9.5) | |
| Thigh | L | 11 | 409.0 (33.2) | 12 | 405.9 (21.9) | 12 | 373.8 (26.1) |
| R | 11 | 410.6 (33.0) | 12 | 411.9 (27.1) | 12 | 372.5 (29.4) | |
| Shank | L | 11 | 404.9 (23.4) | 8 | 415.2 (34.0) | 12 | 378.8 (29.0) |
| R | 11 | 402.8 (22.4) | 8 | 414.4 (33.5) | 12 | 374.3 (27.3) |
| Segment | Side | 3DMoCap | DLC | Kinect | |||
|---|---|---|---|---|---|---|---|
| N | N | N | |||||
| Shoulders | 11 | 9.1 (0.02) | 12 | 16.6 (0.04) | 12 | 17.3 (0.05) | |
| Upper arm | L | 11 | 7.4 (0.03) | 12 | 11.7 (0.04) | 12 | 15.1 (0.05) |
| R | 11 | 7.3 (0.02) | 12 | 13.0 (0.04) | 12 | 15.2 (0.06) | |
| Lower arm | L | 11 | 9.6 (0.04) | 12 | 14.4 (0.08) | 12 | 13.7 (0.06) |
| R | 11 | 10.2 (0.04) | 12 | 20.4 (0.08) | 12 | 13.3 (0.05) | |
| Torso | L | 11 | 15.9 (0.03) | 12 | 22.5 (0.04) | 12 | 12.8 (0.02) |
| R | 11 | 15.7 (0.09) | 12 | 22.5 (0.03) | 12 | 13.1 (0.02) | |
| Pelvis | 11 | 2.8 (0.01) | 12 | 7.3 (0.04) | 12 | 6.1 (0.03) | |
| Thigh | L | 11 | 8.3 (0.02) | 12 | 16.4 (0.03) | 12 | 25.5 (0.06) |
| R | 11 | 8.7 (0.02) | 12 | 20.5 (0.04) | 12 | 23.1 (0.06) | |
| Shank | L | 11 | 8.6 (0.02) | 8 | 14.5 (0.02) | 12 | 21.1 (0.05) |
| R | 11 | 8.6 (0.02) | 8 | 13.6 (0.02) | 12 | 20.5 (0.05) |
| Segment | Side | Mean Rank | ||||
|---|---|---|---|---|---|---|
| (df) | p | 3DMoCap | DLC | Kinect | ||
| Upper arm | L | 3.8 (2) | 0.148 | 1.55 | 2.09 | 2.36 |
| R | 8.7 (2) | 0.023 | 1.27 | 2.36 | 2.36 | |
| Lower arm | L | 11.6 (2) | 0.003 | 1.27 | 2.73 | 2.0 |
| R | 7.81 (2) | 0.020 | 1.45 | 2.64 | 1.91 | |
| Shoulders | 11.1 (2) | 0.004 | 1.18 | 2.45 | 2.36 | |
| Torso | L | 5.6 (2) | 0.060 | 1.91 | 2.55 | 1.55 |
| R | 5.5 (2) | 0.103 | 2.00 | 2.45 | 1.55 | |
| Pelvis | 20.2 (2) | 0.000 | 1.09 | 3.00 | 1.91 | |
| Thigh | L | 16.5 (2) | 0.000 | 1.18 | 1.91 | 2.91 |
| R | 16.9 (2) | 0.000 | 1.0 | 2.36 | 2.64 | |
| Shank | L | 4.6 (2) | 0.102 | 1.43 | 2.00 | 2.57 |
| R | 8.9 (2) | 0.012 | 1.14 | 2.14 | 2.71 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vonstad, E.K.; Su, X.; Vereijken, B.; Bach, K.; Nilsen, J.H. Comparison of a Deep Learning-Based Pose Estimation System to Marker-Based and Kinect Systems in Exergaming for Balance Training. Sensors 2020, 20, 6940. https://doi.org/10.3390/s20236940
Vonstad EK, Su X, Vereijken B, Bach K, Nilsen JH. Comparison of a Deep Learning-Based Pose Estimation System to Marker-Based and Kinect Systems in Exergaming for Balance Training. Sensors. 2020; 20(23):6940. https://doi.org/10.3390/s20236940
Chicago/Turabian StyleVonstad, Elise Klæbo, Xiaomeng Su, Beatrix Vereijken, Kerstin Bach, and Jan Harald Nilsen. 2020. "Comparison of a Deep Learning-Based Pose Estimation System to Marker-Based and Kinect Systems in Exergaming for Balance Training" Sensors 20, no. 23: 6940. https://doi.org/10.3390/s20236940
APA StyleVonstad, E. K., Su, X., Vereijken, B., Bach, K., & Nilsen, J. H. (2020). Comparison of a Deep Learning-Based Pose Estimation System to Marker-Based and Kinect Systems in Exergaming for Balance Training. Sensors, 20(23), 6940. https://doi.org/10.3390/s20236940