Managing Big Data for Addressing Research Questions in a Collaborative Project on Automated Driving Impact Assessment

 ,
,  , , , , ,
, , , , , 
Abstract
1. Introduction
2. Related Work
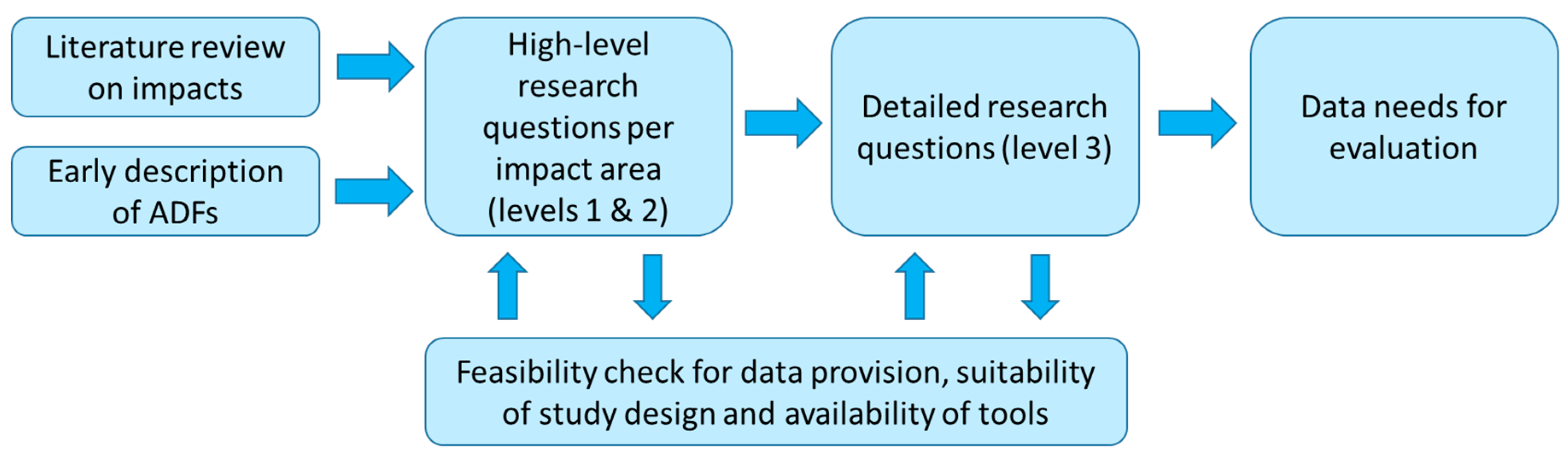
3. Methodology
3.1. Overview
3.2. Objective (Vehicular) Data
- Experimental conditions. Different conditions have to be considered, such as: baseline, ADF not available, ADF off, ADF on.
- Road types. Tests are performed on various road types, such as: motorways, major urban arterials, other urban roads.
- Driving scenarios. The system has to track different types of driving scenarios, that are typical driving situations, such as uninfluenced driving, lane change, lane merge, following a lead vehicle, etc. Scenarios are computed by the L3Pilot data toolchain, processing the vehicular time series [26].
3.3. Confidentiality
- It should not be possible to identify which pilot site the data came from. For example, attention was paid not to insert metadata, such as temperature and date, that might hint to identify the location of the pilot site.
- No personal data about the driver, passengers nor other test participants.
- No possibility to characterize in detail the behaviour of ADFs. This was achieved by the fact that vehicular sensor data are not uploaded to the CDB as time series but as summarised performance indicators, which are described later.
3.4. Subjective Data
3.5. Workflow Requirements
- Recursive upload. The user should define the source directory and the system should automatically detect the files to be processed and do the upload of their contents to the CDB. All the subdirectories should be recursively explored.
- CSV download. The system should allow the possibility of downloading contents in either .json or .csv format, which is the typical input format for the statistical processing packages used by the analysts. The granularity of download is at the feature level. That is, a user should be able to download all the measurements of all the accessible features (Trip_PI, Scenario_Instances, Datapoints, etc.) or only some of them.
- Postediting of the performance indicators. Once the performance indicators for a trip are computed, the data provider should be able to check and edit them before the upload to the CDB.
4. Design and Implementation of the Consolidated Database (CDB)
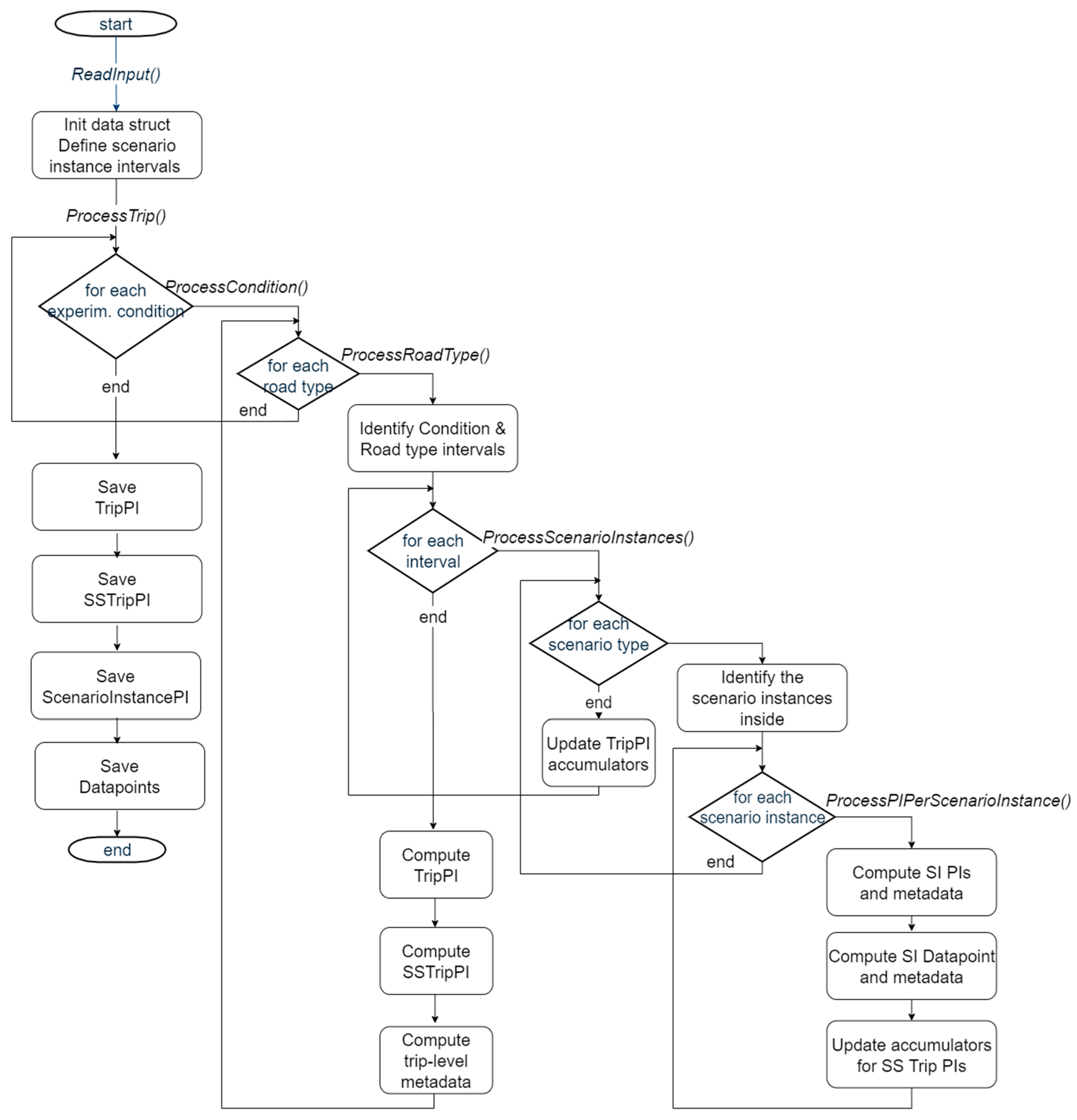
4.1. CDB PI Computation for Vehicular Sensor Data
4.2. Subjective Data Processing
4.3. Uploader
4.4. Measurement API Back-End
User Roles and Data Access Rights
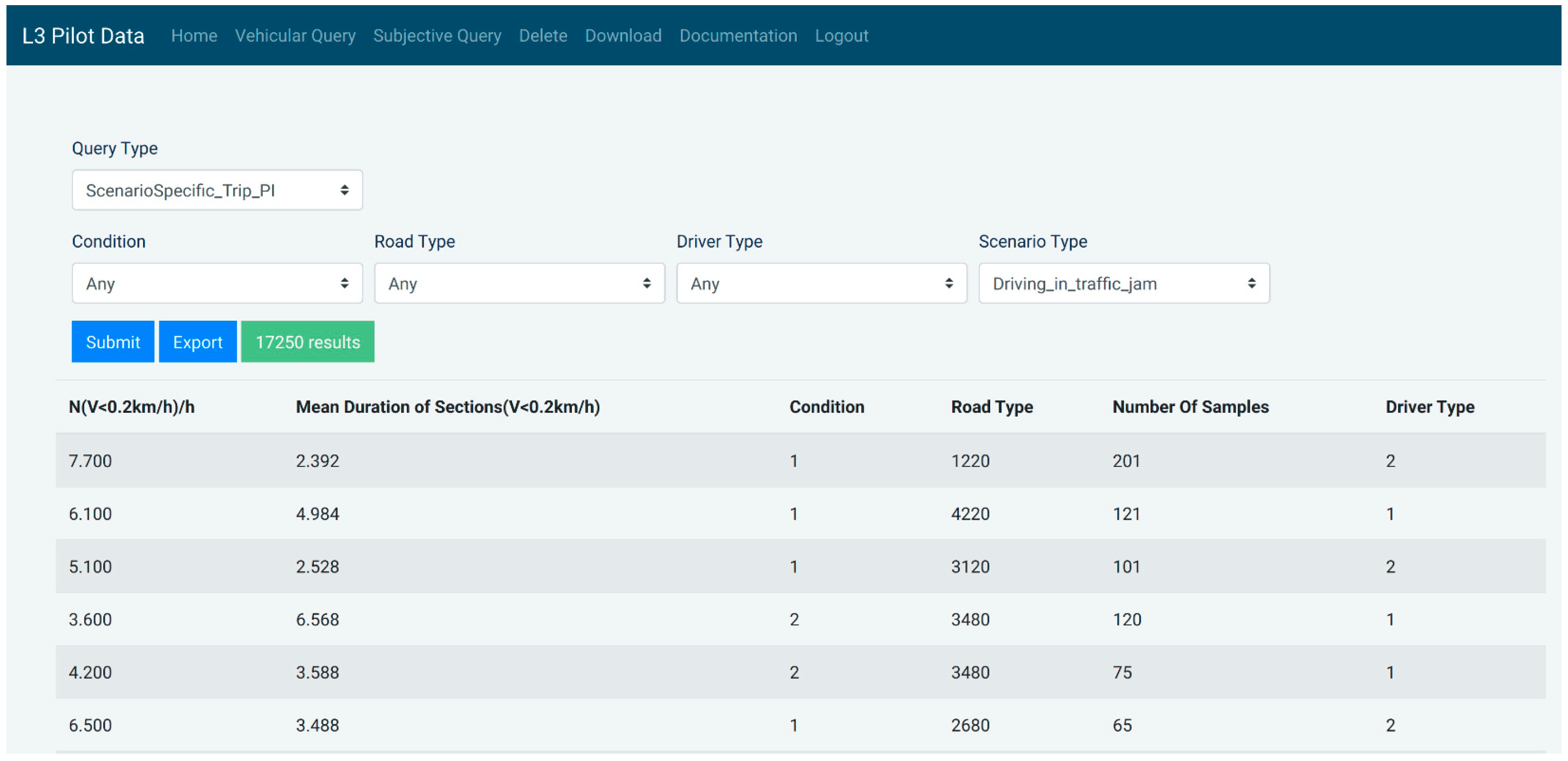
4.5. Graphical User Interface (GUI)
Implementation Details
4.6. Functionalities
5. Deployment at the Pilot Sites
- an extensive use of abstractions, in order to support functional extensibility and module/code reusability
- the modular approach depicted in Figure 3 for extracting PIs from signal time series revealed itself very useful to deal with a set of specification upgrades, that occurred during the project
- the development of a tool that computes the PIs from the raw data and makes them ready for sharing
- the possibility of postediting the PIs before inserting them in the shared database
- the definition of a tool for efficiently uploading files to the database.
- the development of a web-based, open-source GUI for supporting a proper user experience when querying the database
- the usage of effective, well-established data formats, such as .hdf5, .json, .csv. This was key to guarantee interoperability with different tools, particularly for data logging and data analysis, as research teams are accustomed to various tools, such as VBOX, DL2, Matlab, SPSS, etc.
- the use of state-of-the-art tools for distributed project development (e.g., for code versioning)
- Efficient storage and sharing of complex measurements, thanks to the underlying MongoDB nonrelational database management system.
- Easy configurability by specifying the features to be supported in the specific installation (i.e., application database). In the L3Pilot CDB, the features correspond to the types of vehicular and subjective data to be uploaded. Changes in the data structure are easily managed by simply changing the Feature records (old data are to be deleted and reinserted in the new format).
- Ability to seamlessly deal with both vehicular and subjective data
- Open source availability.
- Robustness, as the API was tested in other projects as well.
- Platform-independence, given by the use of the intrinsically platform-independent NodeJS technology and MongoDB open source tool for data storage
- Non-vendor-lockedness. Differently from the typical cloud-based data management solutions, Measurify does not depend on vendor APIs. This makes the service easily portable across cloud providers
- Ease of deployment. The CDB has been deployed in a cloud installation and locally in all the pilot sites, also on laptops.
6. Conclusions
- the Common Data Format (CDF) [25], which allowed all partners to deal with all the data in the same format, sharing tools and knowledge, but not the proprietary data, especially those coming from advanced driving assistance systems (ADAS). Not only does the CDF cover the original signal time-series but also additional information (e.g., the driving scenarios), that are computed by the Derived Measures—Performance Indicator Framework.
- the Measurify API, a non-vendor-locked cloud system for sharing appropriate measurements among relevant partners.
- a common data format can be defined for any application domain, if not yet available.
- the Measurify API is released open source and installations can be easily configured for different domains [31], by specifying different features (i.e., measurement types)
- the principles of the CDB Aggregator (segmentation and statistical data synthesis) are generally applicable. Different factors (experimental condition, types of context of usage of a new system to test, etc.) can be efficiently nested in the modular processing schema presented in Figure 3.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cummings, J.N.; Kiesler, S. Collaborative Research across Disciplinary and Organizational Boundaries. Soc. Stud. Sci. 2005, 35, 703–722. [Google Scholar] [CrossRef]
- Vom Brocke, J.; Lippe, S. Managing collaborative research projects: A synthesis of project management literature and directives for future research. Int. J. Proj. Manag. 2015, 33, 1022–1039. [Google Scholar] [CrossRef]
- Pérez-Padillo, J.; García Morillo, J.; Ramirez-Faz, J.; Torres Roldán, M.; Montesinos, P. Design and Implementation of a Pressure Monitoring System Based on IoT for Water Supply Networks. Sensors 2020, 20, 4247. [Google Scholar] [CrossRef]
- Stapel, J.; Mullakkal-Babu, F.A.; Happee, R. Automated driving reduces perceived workload, but monitoring causes higher cognitive load than manual driving. Transp. Res. Part F Traffic Psychol. Behav. 2019, 60, 590–605. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, Y.; Niu, Q. Multi-Sensor Fusion in Automated Driving: A Survey. IEEE Access 2020, 8, 2847–2868. [Google Scholar] [CrossRef]
- Ardelt, M.; Coester, C.; Kaempchen, N. Highly Automated Driving on Freeways in Real Traffic Using a Probabilistic Framework. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1576–1585. [Google Scholar] [CrossRef]
- Hibberd, D.; Louw, T.; Aittoniemi, E.; Brouwer, R.; Dotzauer, M.; Fahrenkrog, F.; Innamaa, S.; Kuisma, A.; Merat, N.; Metz, B.; et al. Deliverable D3.1 from Research Questions to Logging Requirements; Deliverable D3.1 of L3Pilot Project funded under the European Union’s Horizon 2020 research and innovation programme GA No: 723051. Available online: https://l3pilot.eu/download/ (accessed on 25 November 2020).
- Barnard, Y.; Innamaa, S.; Koskinen, S.; Gellerman, H.; Svanberg, E.; Chen, H. Methodology for Field Operational Tests of Automated Vehicles’. Transp. Res. Procedia 2016, 14, 2188–2196. [Google Scholar] [CrossRef]
- Biffl, S.; Moser, T.; Winkler, D. Risk Assessment in Multi-Disciplinary (Software+) Engineering Projects. International Journal of Software Engineering and Knowledge Engineering (IJSEKE). Spec. Session Risk Assess. 2011, 21, 211–236. [Google Scholar]
- Bhatia, J.; Breaux, T.D.; Friedberg, L.; Hibshi, H.; Smullen, D. Privacy Risk in Cybersecurity Data Sharing. In Proceedings of the 2016 ACM on Workshop on Information Sharing and Collaborative Security (WISCS ’16), Vienna, Austria, 24–28 October 2016; pp. 57–64. [Google Scholar]
- Fioretto, F.; Van Hentenryck, P. Privacy-Preserving Federated Data Sharing. In Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS ’19), Montreal, QC, Canada, 13–17 May 2019; pp. 638–646. [Google Scholar]
- Mehdizadeh, A.; Cai, M.; Hu, Q.; Alamdar Yazdi, M.; Mohabbati-Kalejahi, N.; Vinel, A.; Rigdon, S.; Davis, K.; Megahed, F. A Review of Data Analytic Applications in Road Traffic Safety. Part 1: Descriptive and Predictive Modeling. Sensors 2020, 20, 1107. [Google Scholar] [CrossRef] [PubMed]
- Ratcheva, V. Integrating diverse knowledge through boundary spanning processes—The case of multidisciplinary project teams. Int. J. Proj. Manag. 2009, 27, 206–215. [Google Scholar] [CrossRef]
- Winkler, D.; Ekaputra, F.J.; Serral, E.; Biffl, S. Efficient data integration and communication issues in distributed engineering projects and project consortia. In Proceedings of the 14th International Conference on Knowledge Technologies and Data-driven Business (i-KNOW ’14), Graz, Austria, 16–19 September 2014; pp. 1–4. [Google Scholar]
- Benmimoun, M.; Benmimoun, A. Large-Scale FOT for Analyzing the Impacts of Advanced Driver Assistance Systems. In Proceedings of the 17th ITS World Congress 2010, Busan, Korea, 25–29 October 2010. [Google Scholar]
- Burzio, G.; Mussino, G.; Tadei, R.; Perboli, G.; Dell’Amico, M.; Guidotti, L. A subjective field test on lane departure warning function in the framework of the euroFOT project. In Proceedings of the 2nd Conference on Human System Interactions, Catania, Italy, 21–23 May 2009; pp. 608–610. [Google Scholar]
- FOT-Net & CARTRE. FESTA Handbook. Version 7. December 2018. Available online: https://connectedautomateddriving.eu/wp-content/uploads/2019/01/FESTA-Handbook-Version-7.pdf (accessed on 25 November 2020).
- Adaptive Project Final Report. 2017. Available online: http://www.adaptive-ip.eu/files/adaptive/content/downloads/AdaptIVe-SP1-v1-0-DL-D1-0-Final_Report.pdf (accessed on 31 July 2020).
- Schulze, M.; Mäkinen, T.; Kessel, T.; Metzner, S.; Stoyanov, H. Final Report (D11.6) of DriveC2X. 2014. Available online: https://www.eict.de/fileadmin/redakteure/Projekte/DriveC2X/Deliverables/DRIVE_C2X_D11_6_Final_report__full_version_.pdf (accessed on 31 July 2020).
- Boban, M.; d’Orey, P.M. Measurement-based evaluation of cooperative awareness for V2V and V2I communication. In Proceedings of the 2014 IEEE Vehicular Networking Conference (VNC), Paderborn, Germany, 3–5 December 2014; pp. 1–8. [Google Scholar]
- Gellerman, H.; Svanberg, R.; Barnard, Y. Data Sharing of Transport Research Data. Transp. Res. Procedia 2016, 14, 2227–2236. [Google Scholar] [CrossRef]
- Bellotti, F.; Kopetzki, S.; Berta, R.; Lytrivis, P.; Amditis, A.; Raffero, M.; Aittoniemi, E.; Basso, R.; Radusch, I.; De Gloria, A. TEAM applications for Collaborative Road Mobility. IEEE Trans. Ind. Inf. 2019, 15, 1105–1119. [Google Scholar] [CrossRef]
- Metz, B.; Rösener, C.; Louw, T.; Aittoniemi, E.; Bjorvatn, A.; Wörle, J.; Weber, H.; Torrao, G.; Silla, A.; Innamaa, S.; et al. Deliverable D3.3 Evaluation Methods; Deliverable D3.3 of L3PilotS Project funded under the European Union’s Horizon 2020 research and innovation programme GA No: 723051. Available online: https://l3pilot.eu/download/ (accessed on 25 November 2020).
- Innamaa, S.; Aittoniemi, E.; Bjorvatn, A.; Borrack, M.; Di Lillo, L.; Fahrenkrog, F.; Gwehenberger, J.; Lehtonen, E.; Louw, T.; Malin, F.; et al. Deliverable D3.4 Evaluation Plan; Deliverable D3.4 of L3Pilot Project funded under the European Union’s Horizon 2020 research and innovation programme GA No: 723051. Available online: https://l3pilot.eu/download/ (accessed on 25 November 2020).
- Hiller, J.; Svanberg, E.; Koskinen, S.; Bellotti, F.; Osman, N. The L3Pilot Common Data Format—Enabling efficient automated driving data analysis. In Proceedings of the 26th International Technical Conference on the Enhanced Safety of Vehicles, Eindhoven, The Netherlands, 10–13 June 2019. [Google Scholar]
- Hiller, J.; Koskinen, S.; Berta, R.; Osman, N.; Nagy, B.; Bellotti, F.; Rahman, A.; Svanberg, E.; Weber, H.; Arnold, E.H.; et al. The L3Pilot Data Management Toolchain for a Level 3 Vehicle Automation Pilot. Electronics 2020, 9, 809. [Google Scholar] [CrossRef]
- Innamaa, S.; Merat, N.; Louw, T.; Metz, B.; Streubel, T.; Rösener, C. Methodological challenges related to real-world automated driving pilots. In Proceedings of the ITS World Congress, Singapore, 21–25 October 2019. [Google Scholar]
- L3Pilot Common Data Format. Available online: https://github.com/l3pilot/l3pilot-cdf (accessed on 31 July 2020).
- Louw, T.; Merat, N.; Metz, B.; Wörle, J.; Torrao, G.; Satu, I. Assessing user behaviour and acceptance in real-world automated driving: The L3Pilot project approach. In Proceedings of the 8th Transport Research Arena TRA 2020, Helsinki, Finland, 27–30 April 2020. [Google Scholar]
- Vassiliadis, P.; Sellis, T. A survey of logical models for OLAP databases. SIGMOD Rec. 1999, 28, 64–69. [Google Scholar] [CrossRef]
- Berta, R.; Kobeissi, A.; Bellotti, F.; De Gloria, A. Atmosphere, an Open Source Measurement-Oriented Data Framework for IoT. IEEE Trans. Ind. Inform. 2020. [Google Scholar] [CrossRef]
- Measurify. Available online: https://github.com/measurify (accessed on 31 July 2020).
- Macrae, C. Vue. js: Up and Running: Building Accessible and Performant Web Apps; O’Reilly Media, Inc.: Newton, MA, USA, 2018. [Google Scholar]
- Wohlgethan, E. Supporting Web Development Decisions by Comparing Three Major JavaScript Frameworks: Angular, React and Vue. Js. Ph.D. Thesis, Hochschule für Angewandte Wissenschaften Hamburg, Hamburg, Germany, 2018. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Example |
|---|---|
| Evaluation area | Technical and traffic |
| RQ level 1 | “What is the impact of the ADF on driving behaviour?” |
| RQ level 2 | “What is the ADF impact on driven speed in different scenarios?” |
| RQ level 3 | “What is the ADF impact on driven speed in driving scenario X?” |
| Hypothesis | Example 1: “There is no difference in the driven mean speed for the ADF compared to manual driving.” Example 2: “There is no difference in the standard deviation of speed for the ADF compared to manual driving.” |
| Required Performance indicators (PIs) | Mean speed, standard deviation of speed, max speed, plot (speed/time) |
| Logging requirements/sensors available | CAN bus of vehicle: Ego speed in x direction |
| PI Type | Description | Example of PIs |
|---|---|---|
| Trip PI | PIs computed at trip level | Mean (stdev) longitudinal acceleration, percentage of time elapsed per driving scenario type |
| Scenario specific Trip PI | PIs computed at trip level but only when a specific driving scenario occurs. Example of driving scenarios, described later, are: driving in a traffic jam, lane change. | Mean duration of sections with speed lower than a threshold |
| Scenario instance PI | PIs computed for each instance of a driving scenario. The same PIs are computed in each type of scenario | Mean (stdev) time headway, mean(stdev) position in lane |
| Datapoint for a Following a lead vehicle scenario | Datapoint PIs are computed for each instance of a driving scenario. Different types of scenario have a different datapoint structure. Here we report two examples. Datapoints are used as input for the impact assessment by either resimulating driving scenarios or constructing artificial scenarios based on statistical analyses of scenarios encountered during piloting | Mean (stdev) relative velocity, Time headway at minimum time to collision |
| Datapoint for Approaching a traffic jam scenario | Vehicle speed at brake or steering onset, Longit. position of object at brake or steering onset |
| Role | Description | L3Pilot Configuration/Notes |
|---|---|---|
| Providers | Provider users are data owners. They can upload data and retrieve only their own data. | In L3Pilot, Providers are vehicle owners or their in-depth analysis partner for vehicular sensor data and pilot leaders for subjective data |
| Analysts | Analyst users cannot upload data but can see all the data of their typology. | In L3Pilot, analysts are the experts responding to the research questions. Utilizing the Measurify’s Right resource, we have implemented three typologies, matching the type of relevant data: Technical and Traffic analysts, that access all vehicular sensor data apart from the Datapoints; Impact analysts, that access Datapoints; User analysts, that access subjective data |
| Admin | The admin configures the CDB (e.g., setting up the users and rights) and can see (only in case of need) all data entries | Given the adopted ID pseudonymization, the admin cannot resolve IDs (i.e., relating a data entry with its vehicle owner or driver). |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bellotti, F.; Osman, N.; Arnold, E.H.; Mozaffari, S.; Innamaa, S.; Louw, T.; Torrao, G.; Weber, H.; Hiller, J.; De Gloria, A.; et al. Managing Big Data for Addressing Research Questions in a Collaborative Project on Automated Driving Impact Assessment. Sensors 2020, 20, 6773. https://doi.org/10.3390/s20236773
Bellotti F, Osman N, Arnold EH, Mozaffari S, Innamaa S, Louw T, Torrao G, Weber H, Hiller J, De Gloria A, et al. Managing Big Data for Addressing Research Questions in a Collaborative Project on Automated Driving Impact Assessment. Sensors. 2020; 20(23):6773. https://doi.org/10.3390/s20236773
Chicago/Turabian StyleBellotti, Francesco, Nisrine Osman, Eduardo H. Arnold, Sajjad Mozaffari, Satu Innamaa, Tyron Louw, Guilhermina Torrao, Hendrik Weber, Johannes Hiller, Alessandro De Gloria, and et al. 2020. "Managing Big Data for Addressing Research Questions in a Collaborative Project on Automated Driving Impact Assessment" Sensors 20, no. 23: 6773. https://doi.org/10.3390/s20236773
APA StyleBellotti, F., Osman, N., Arnold, E. H., Mozaffari, S., Innamaa, S., Louw, T., Torrao, G., Weber, H., Hiller, J., De Gloria, A., Dianati, M., & Berta, R. (2020). Managing Big Data for Addressing Research Questions in a Collaborative Project on Automated Driving Impact Assessment. Sensors, 20(23), 6773. https://doi.org/10.3390/s20236773