1. Introduction
Emotions are fundamental in the daily lives of humans, and they play an essential role in decision-making, human interactions, and even mental health [
1]. For instance, in the medical field of psychiatry, detected emotional states of patients help identify those at a high risk of emotional disorders and depression [
2]. Thus, there has been much research on emotion recognition using facial expressions [
3], thermography [
4], motion capture system [
5], text [
6], and speech [
7]. However, these modes are difficult for representing people’s true feelings because they are sensitive to subject-specific variability. Moreover, people can express false emotions.
To solve this problem, electroencephalogram (EEG) has been considered as an alternative for detecting emotions produced unintentionally by the human brain. As a typical central nervous signal, the EEG signal directly reflects the strength and position of brain activity at a high temporal resolution [
8]. Therefore, EEG signals are more stable for extracting the actual emotional states of humans. Benefiting from many non-invasive and easy-to-wear EEG measuring devices, it is easy to monitor electrical brain activity with EEG. Due to these advantages, EEG-based research has been relatively active.
EEG-based emotion recognition model design can follow a user-dependent or a user-independent approach. In the case of a user-dependent model, training and testing data are chosen from the same subject. Therefore, an emotion recognition model typically shows high accuracy on a user-dependent model. However, such a user-dependent model lacks generalization and a tuning process is necessary for each new subject, which requires training data from each subject. Thus, it is desirable to develop a user-independent model. In this scenario, a recognition system is trained using data from some subjects while applied to new subjects in testing. In contrast, a user-independent model is more applicable to new users because there is no need to create a new model [
9].
The main issue about recognizing cross-subject emotion from EEG signals is to find effective representations that are robust to subject-specific variability and noise associated with the EEG data collection process. EEG signals have a low signal-to-noise ratio (SNR) and are affected by common noise pattern of sensor systems, as well as unintentional physical activities such as eye blinks and muscle movement, which make it difficult to recognize the emotion states from raw EEG signals. Moreover, due to the subject-specific variability, it is difficult to find invariant emotion-related features from different subjects. To handle these problems, various emotion-related feature extraction methods have been developed. These methods can be sorted into two categories: human crafted feature-based approaches and deep feature-based ones.
The most common methods to recognize human emotion from EEG signals have been relying on some hand-crafted features. Some methods extracted delta, theta, alpha, beta, and gamma waves using a bandpass filter [
10], and other methods implemented the wavelet transform (WT) to extract emotion-related features [
11]. In addition, researchers focused on investigating critical emotion-related frequency bands and channels. Zheng et al. found that different emotions have different emotion-related bands and channels [
12]. Although these signal processing methods can explicitly suppress noise and artifacts, they did not consider the subject-specific variability of EEG.
Recently, deep learning techniques are applied to automatically model brain activity. Moreover, with the discovery of the spatial connectivity of EEG, many studies have begun to combine the spatial connectivity of different brain regions with the temporal change of EEG signals, for a more accurate emotion recognition model. Yang et al. transformed the data into topology-preserving two-dimensional (2D) EEG frames based on the International 10–20 system [
13]. Then, the 2D matrices were input to a parallel convolutional recurrent neural network to learn the spatial and temporal representation separately. Wang et al. reshaped raw EEG data into three-dimensional (3D) tensors (2D electrode topological structure × time samples) and used a 3D CNN architecture, named EmotioNet, to extract the spatial and temporal features simultaneously [
14].
The hand-crafted feature-based approaches can explicitly reduce the noise and find emotion-related features. However, they rarely consider the subject-specific variability and usually required specified domain knowledge to extract hand-crafted features. By deep learning methods, the relevant features of the emotions are automatically extracted from the raw EEG signals. Generally, most of the works only report the results achieved by deep learning, without detailed explanations or insights about the results. Besides presenting the classification performance, it is also important to interpret the cause of such classification success.
To overcome the mentioned limitations of feature representation methods, we present an interpretable cross-subject EEG-based emotion recognition model using the combination of hand-crafted features and a deep learning approach. More specifically, we extract channel-wise features that integrate spatial connectivity of whole brain regions and use LSTM to learn temporal information. The channel-wise feature is defined by a symmetric matrix and considers the linear combination of every two-pair channels. In this way, the channel-wise feature is enabled to encode the features of individuals, and capable of complementarily handling subject-specific variability. We include visualizations of channel-wise features and show that the channel-wise features are robust to subject-specific variability. Then, to reduce the bias of subject-specific variability, a sequence of channel-wise features is fed to two-layer stacked LSTM layers. We allow the LSTM layer to automatically learn emotional features for discriminating between emotion type.
The effectiveness of our model was examined on two publicly accessible datasets, specifically the Dataset for Emotion Analysis using Physiological Signals (DEAP) [
15] and the SJTU (Shanghai Jiao Tong University) Emotion EEG Dataset (SEED) [
16]. For the DEAP, our model achieves state-of-the-art accuracy of 98.93% and 99.10% on two-class (high, low) valence and arousal classification tasks, respectively, and achieves 98.32% on four-class (high valence high arousal, high valence low arousal, low valence high arousal, low valence low arousal) classification in one model. For the SEED, emotion classification with three classes (positive, neutral, negative) achieves an accuracy of 99.63%.
Our contributions are summarized as follows:
We propose a cross-subject EEG-based emotion recognition model using a combination of channel-wise features and LSTM. The channel-wise features consider the spatial connectivity of whole brain regions, which have robust subject-specific variability, and LSTM can learn the temporal information and extract the emotion-related feature.
We implement extensive experiments in both the DEAP and SEED and carry out a systematic comparison with different studies. Experimental results outperform the state of the art by a large margin and demonstrate the effectiveness of the proposed model.
We investigate the properties of channel-wise features and experimentally demonstrate that the presented channel-wise features can reduce negative effects due to subject-specific variability.
The rest of this paper is organized as follows:
Section 2 begins by introducing the previous research of EEG-based emotion recognition and provides an understanding of some basic emotional feature extraction concepts such as hand-crafted features and deep features.
Section 3 summarizes the entire process of our model. A detailed description of the proposed method and LSTM structure is presented in
Section 4.
Section 5 contains the detailed information of the DEAP and SEED, experimental setting and results to demonstrate the effectiveness of our model. Finally, the main conclusion of our research is presented in
Section 6.
3. Overview of the Proposed Method
We propose a novel EEG-based emotion recognition model that considers subject-specific variability in predictions of the emotions of a user omitted from the training set. As we have argued above, the main issue centers on how to identify the features that are strongly related to human emotions. We believe that the spatial connectivity between whole brain regions is an important clue in finding the emotion-specific features as well as subject-specific features. From this assumption, we first transform raw EEG signals to channel-wise features that can effectively represent distinctive connectivity patterns. It is assumed that a channel-wise feature can be separated into subject-specific patterns and emotion-specific patterns. Therefore, by filtering the subject-specific patterns from channel-wise features, only emotion-specific patterns can remain, which are used for emotion classification. In this work, LSTM is employed to extract an emotion-specific pattern by modeling the temporal dynamic behavior of channel-wise features.
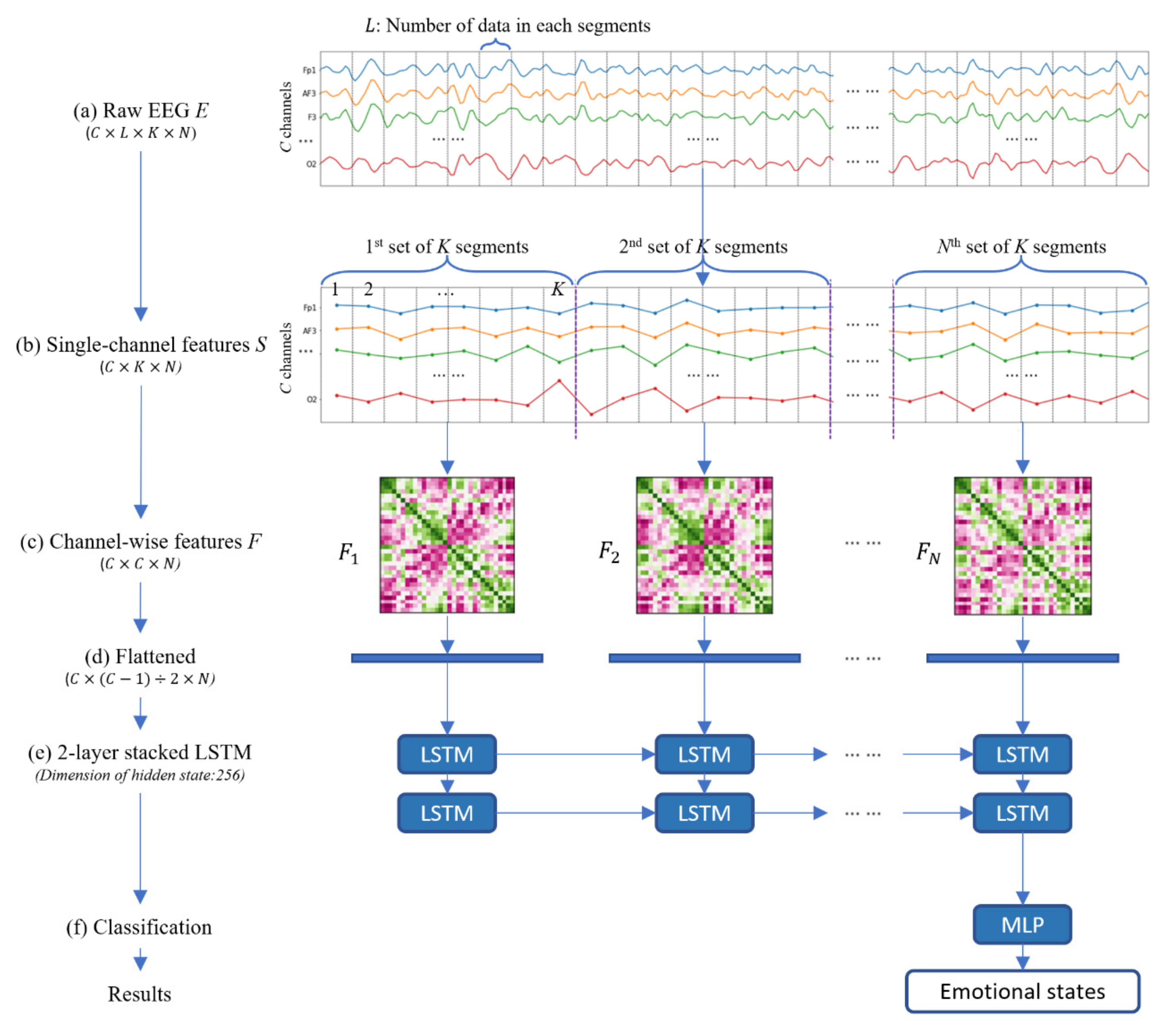
A flowchart of our model is shown in
Figure 1. First, we extracted single-channel features from raw EEG data to reduce the data size. Second, we extracted channel-wise features to model the spatial structure in neural correlations. Moreover, channel-wise features can explicitly model interdependencies between all channels, and this method can determine the unique pattern of each user’s EEG signal, allowing subject-specific variability to be considered. By successively extracting channel-wise features from several time steps, which are flattened and input into long short-term memory (LSTM), we can predict the emotions of users effectively. More formally, our model takes a sequence of raw EEG data
(
Figure 1a) as input, where
is the number of EEG channels,
is the number of EEG data samples in each segment for each channel,
is the number of segments needed for considering the correlation of all EEG channels and extracting the channel-wise feature, and
is the number of time steps in the LSTM to extract the temporal emotional feature. Firstly, our model calculated single-channel features
(
Figure 1b) by the dimension reduction from each
EEG data. Secondly, by considering the spatial connectivity between pairwise EEG channels from
single-channel feature values per channel, our model generates
channel-wise features
(
Figure 1c), where
. Then, we flatten the upper triangle of the channel-wise features (
Figure 1d) and input the data into LSTM (
Figure 1e). By training the parameters of LSTM, we can predict the emotional state accurately (
Figure 1f).
5. Experiments
Our goal is to develop an accurate cross-subject EEG-based emotion recognition model that considers subject-specific variability. To do this, we presented a novel emotional model with a combination of channel-wise features and a two-layer stacked LSTM.
To verify the effectiveness of the proposed method, various experiments are conducted on well-known datasets and the results are compared with those from state-of-the-art techniques. In this section, we introduce the datasets in
Section 5.1 and describe the details for the experiment setting in
Section 5.2. We then present hyperparameter optimization (
Section 5.3), experimental results (
Section 5.4), and the effectiveness of the proposed features (
Section 5.5).
5.1. Datasets
5.1.1. DEAP
The DEAP refers to the Database for Emotion Analysis using Physiological Signals. The EEG and peripheral physiological signals of 32 healthy participants (16 males and 16 females, aged between 19 and 37) were recorded while each watched 40 one-minute-long excerpts of music videos. EEG was recorded at a sampling rate of 512 Hz using 32 active AgCl electrodes (placed according to the international 10–20 system). The following peripheral nervous system signals were recorded: GSR, respiration amplitude, skin temperature, electrocardiogram, blood volume by plethysmograph, electromyograms of Zygomaticus and Trapezius muscles, and electrooculogram (EOG). The 32-channel EEG data were downsampled to 128 Hz and EOG removal was done by filtering 4.0–45.0 Hz from the data. Participants rated each video on a discrete nine-point scale for arousal, valence, like/dislike, dominance, and familiarity [
27]. We only measured EEG signals and self-assessment levels of valence and arousal in our experiments. We set rating values more than 5 as high valence/arousal and less than 5 as low valence/arousal.
Figure 3 plots the rating values of valence and arousal in the DEAP. The points around valence = 5 and arousal = 5 mean that subjects feel an ambiguous emotion when watching the music video. Thus, the experimental results in DEAP are not too high in previous research.
5.1.2. SEED
SEED is short for the SJTU Emotion EEG Dataset. The SEED contains 15 Chinese subjects’ (7 males and 8 females, mean aged: 23.27, std: 2.37) EEG signals recorded as they watched 15 film clips. The EEG data were downsampled to 200 Hz. A bandpass frequency filter from 0 to 75 Hz was applied. For feedback, participants were told to report their emotional reactions to each film clip by completing a questionnaire immediately after watching each clip [
28]. The selected videos can be understood without explanation and elicit a single desired target emotion. Thus, in our experiments, we used the labels of trials instead of the information from the questionnaires. The emotional labels contain positive, neutral, and negative attributes.
Table 1 shows the detailed information of the DEAP and SEED. As shown in this table, the two datasets have completely different properties, such as the numbers and nationalities of the subjects, and the number of trials and the channels. They also have different sampling rates. There is also an issue with noisy labels. The music videos in the DEAP are ambiguous, such that subjects may feel different emotions when watching the same video. In contrast, each film clip in the SEED is well edited to create coherent emotion elicitations and to maximize emotional meaning. Consequently, we choose the self-assessment labels in the DEAP and the categorical labels in the SEED to reduce the number of noisy labels. When a subject starts watching a video, we think that it will take some time to stimulate an emotion. Thus, we used EEG signals after 30 s in our experiments. If we can obtain good experimental results with these two different datasets, it will sufficiently explain the excellent capabilities of our model.
5.2. Experiment Setting
For the two-layer stacked LSTM, we set the dimension of the hidden state in the LSTM unit as 256. We adopt RMSProp to minimize the cross-entropy loss function, with a learning rate of 0.001 and a dropout probability of 0.5. Due to the limited sizes of the two EEG datasets, we apply data augmentation to increase the diversity of the training set. As we mentioned above, the input of our model is a sequence of EEG data that contains channels and data per channel. From the recorded raw EEG signal , we set th training data . Thus, the overlap ratio of each two adjacent training data is . By this method, the datasets are augmented and will represent a more comprehensive set of possible data points. Then, during the training step, we randomly retrieved a mini-batch with a size of 240. We use Tensorflow 2.0.0 (Mountain View, CA, USA) and Nvidia GeForce GTX 1660 Ti (Santa Clara, CA, USA) to train our model. We used a 10-fold cross validation strategy to evaluate the effectiveness of the E-EmotiConNet using a user-independent model. We randomly split 10-fold that the same subject and the same stimuli could be both in the training set and testing set. The accuracy of the whole system is the mean classification accuracy on the test set 10 times.
5.3. Hyperparameter Optimization
The hyperparameters in our model are , , and ; specifically, we extract the channel-wise features from consecutive EEG segments and consider the changeability of consecutive channel-wise features in the LSTM. For DEAP, the size of the channel-wise features is ; accordingly, the dimension of the upper triangle of the channel-wise feature is 496. For SEED, the size of the channel-wise features is , and the dimension of the upper triangle of the channel-wise feature is 1891. The flattened upper triangle of channel-wise features is fed into the two-layer stacked LSTM. Hence, each layer has LSTM units.
Emotions are related to a time sequence, implying that it is important to observe emotions from multiple time steps. The performance of the proposed system was affected by several parameters; in this case, the number of data samples in each segment
, the number of segments
and the number of time steps
. To evaluate the change of the accuracy considering such parameters, we performed the first experiment. We increased the number of data samples
, using values of 2, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, and 60, and extracted the channel-wise features identically to how this was done earlier, inputting them into the LSTM. We also conducted an experiment while changing the number of segments
from 4 to 12 and changing the number of channel-wise features
from 3 to 13 to measure the relationship between emotion recognition accuracy and the number of time steps in LSTM.
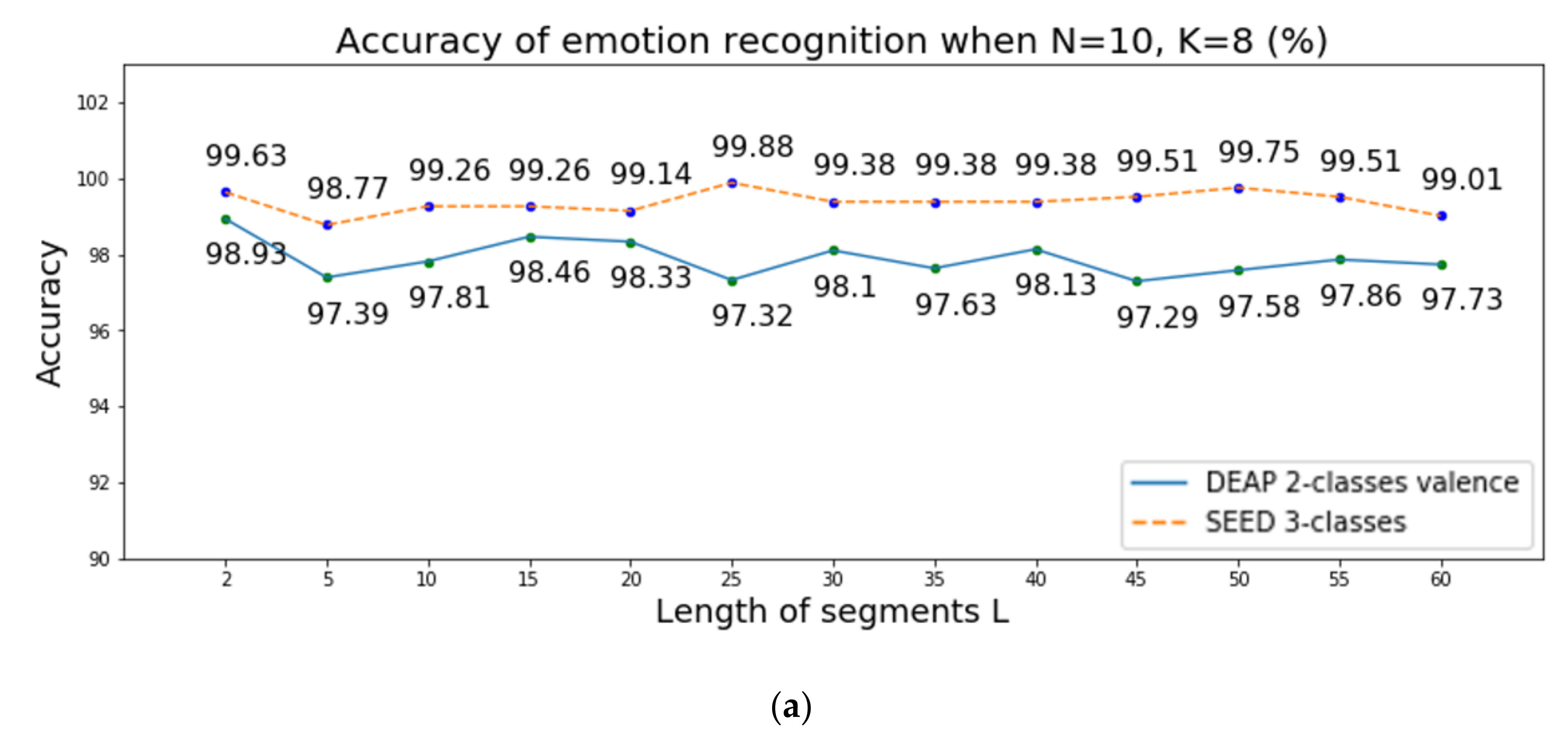
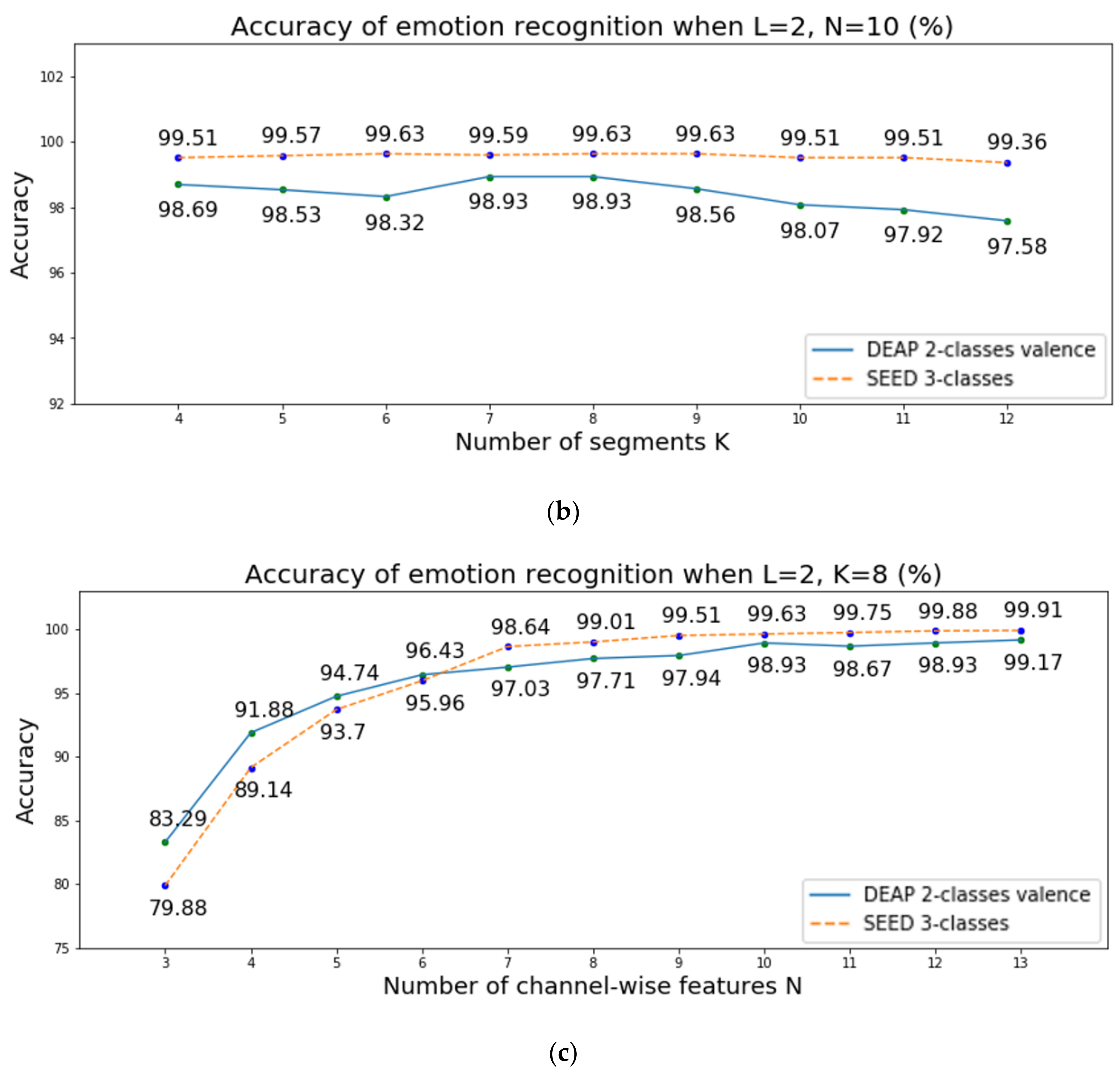
Figure 4 presents the accuracy of emotion recognition over two-class valence in DEAP when changing the length of the segments
, the number of segments
, and the number of channel-wise features
. The experimental results are shown in
Figure 4 and it shows three important discoveries:
When changing the length of the segments , the accuracy rates of emotion recognition are similar. We use a random number to initialize the parameters of LSTM. Thus, the accuracy may change slightly, and all accuracy rates are within acceptable limits. However, as increases, more EEG data are needed. Thus, in our model, we set the length of the segments to 2.
We can also observe from the second plot that although the accuracy rates of emotion recognition do not change greatly, the results show high accuracy in two datasets when the number of segments is 8.
For the third plot in
Figure 4, the accuracy of emotion recognition decreases when the number of channel-wise features is reduced. This occurs because the EEG signal consists of sequence data and the emotions change over time, implying that it is important to observe the emotions from multiple time steps. However, too much data can also be computationally expensive. Thus, we set the number of channel-wise features
to 10.
Thus, in our model, we set the number of data samples in each segment to 2, the number of segments to 8 and the number of channel-wise features to 10 to consider changes of 10 consecutive channel-wise features in the LSTM and classify the emotion accurately. Consequently, our model only requires data samples in each EEG channel for emotion recognition. Since the sampling rates in the DEAP and SEED are 128 Hz and 200 Hz, we only use 1.25 and 0.8 ( second EEG data, respectively.
5.4. Experiments Results
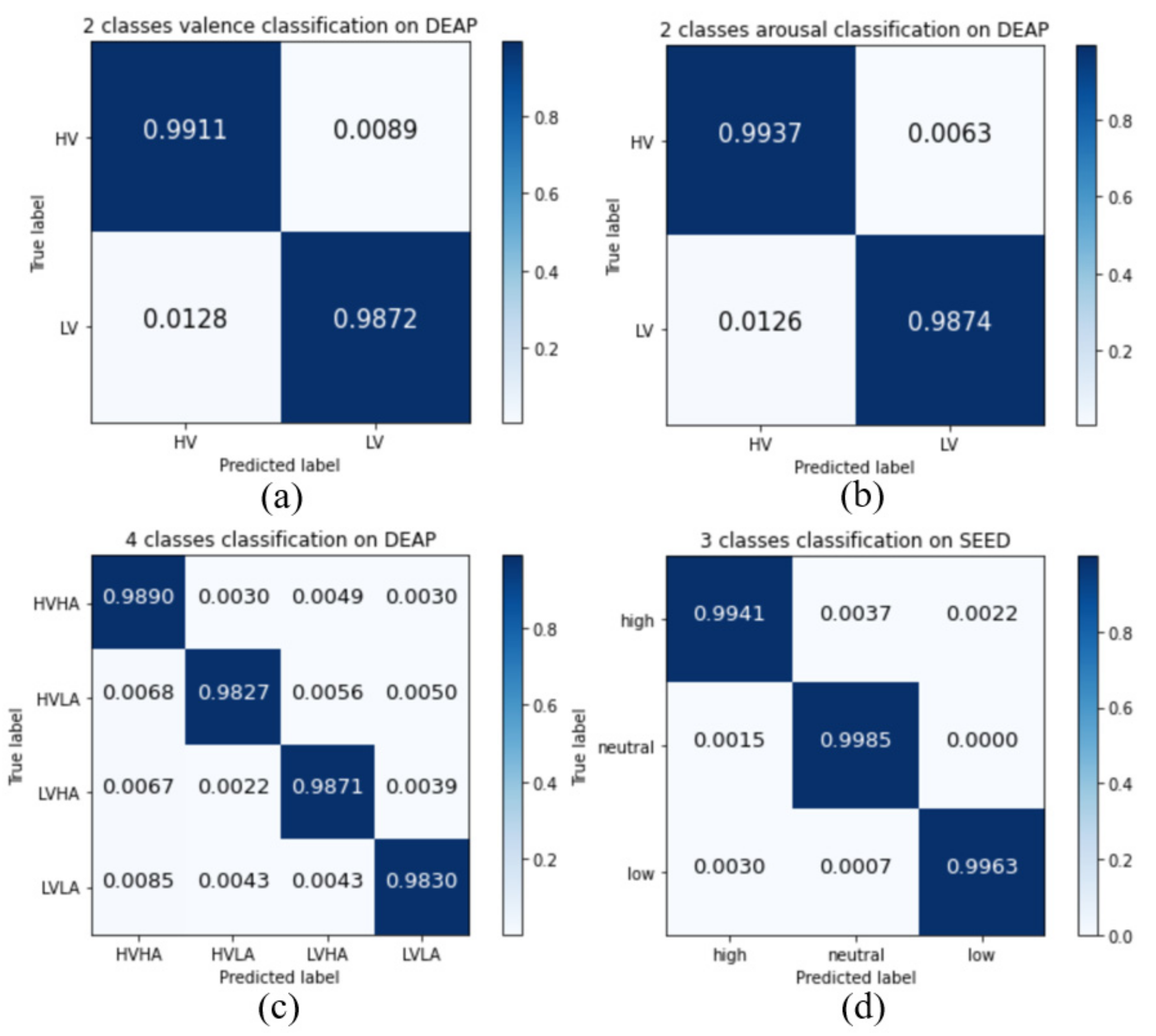
An experiment was performed to prove the effectiveness of the presented channel-wise features and the two-layer stacked LSTM for cross-subject emotion classification. For DEAP, the proposed method achieved accuracy rates of 98.93% and 99.10% over the two-class classification of valence and arousal, respectively. Moreover, our model achieves high accuracy of 98.60% for four-class emotion classification (high valence high arousal, high valence low arousal, low valence high arousal, and low valence low arousal). The four-class classification model can classify valence and arousal simultaneously, meaning that there is no need to train two models separately. It also can reduce by half the number of parameters. For the SEED, the proposed method achieved an accuracy of 99.63% over three-class (positive, neutral, negative) emotion classification. Although the two datasets are different from each other, our model shows high accuracy on both datasets. This proves the robustness of the proposed model.
Figure 5 shows the confusion matrices of the experiment result. Although the labels of EEG data are unbalanced, we observe that our model can recognize all the emotions correctly.
The results with the presented channel-wise features and two-layer stacked LSTM are compared with certain EEG-based emotion recognition models in
Table 2 and
Table 3. Wen et al. found novel convolutional neural networks for emotion recognition for the DEAP [
8]. Yang et al. reported an emotion recognition system with a combination of CNN-based features and LSTM-based features [
13]. Their system shows high accuracy rates of 90.80% and 91.03% on valence and arousal, respectively, but it is user-dependent in that a new model should be generated for each user. Tripathi et al. extracted nine specific values of single channels as features, with these features then being fed into a CNN [
21]. Although the model achieves corresponding accuracy rates of 81.406% and 73.36% on valence and arousal classification, it may be difficult for a user to wait 63 s for the collection of the EEG signals. Wang et al. used a 3D convolutional neural network on 4-s EEG signals for emotion recognition for the DEAP [
14]. Yang et al. used a combination of 10 EEG features and developed a cross-subject emotion recognition model that integrated the significance test/sequential backward selection and the support vector machine (ST-SBSSVM) [
10]. Gupta et al. used the flexible analytic wavelet transform (FAWT) [
22], testing their models for both the DEAP and SEED and showing accuracy rates for the DEAP below 80%, while also achieving nearly 90% accuracy for the SEED. Li. Y et al. used region and global features to develop a user-dependent emotion recognition model [
29] and Li. X et al. combined 18 EEG features and test the performance on SEED. Our model achieves state-of-the-art classification rates of 98.93% and 99.10%, respectively, for two-class valence and arousal for the DEAP and shows the accuracy of 99.63% for three-class classification for the SEED. It can prove that the proposed channel-wise features and two-layer stacked LSTM can significantly improve the average recognition accuracy.
5.5. Effectiveness of the Proposed Features
5.5.1. Effectiveness of the Channel-Wise Features
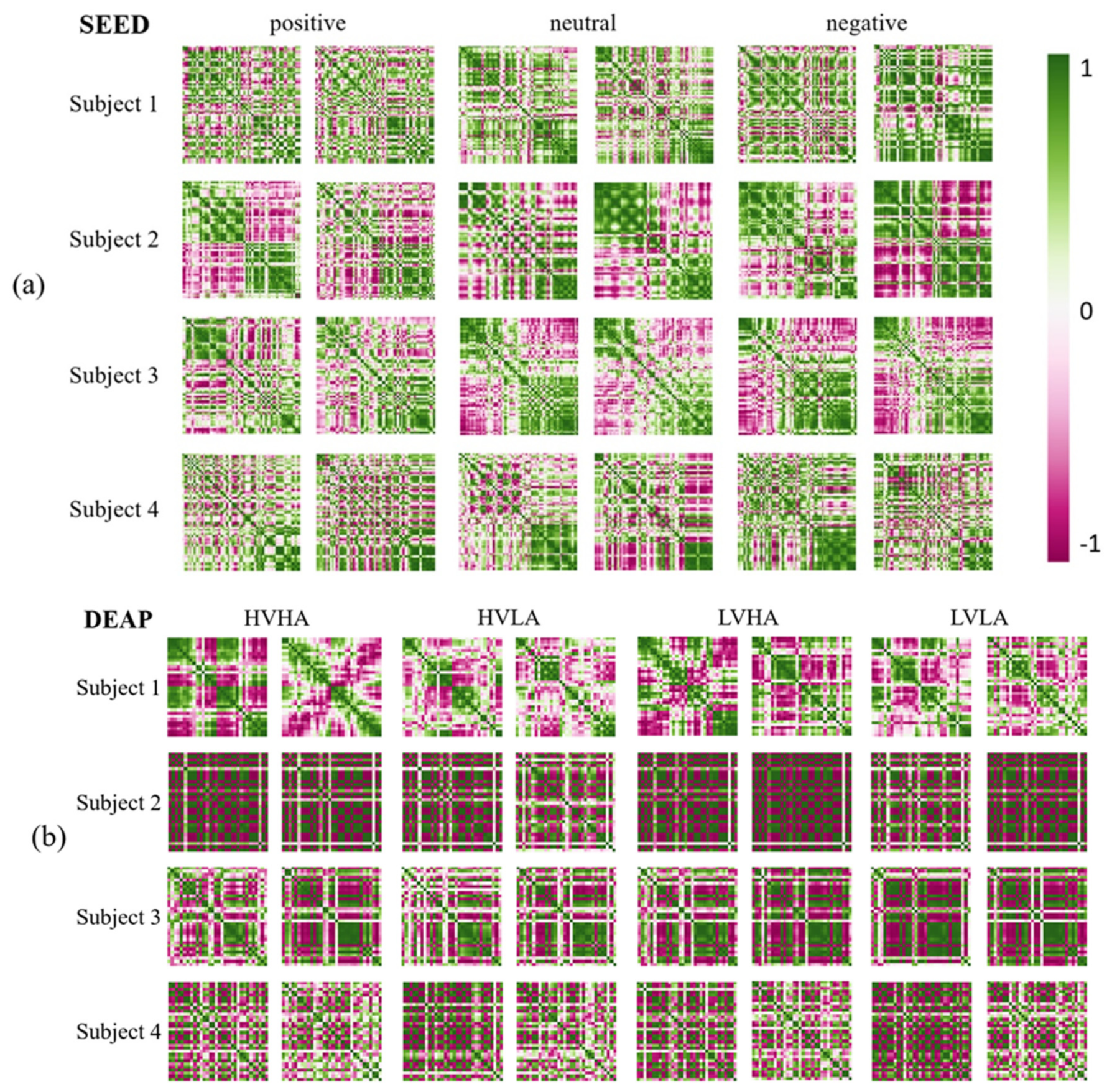
The examples of the channel-wise features are shown in
Figure 6. As shown in
Figure 6, the correlation is defined on two pairs of channels, and it is shown in different colors depending on the strength of the correlation. For a strong positive correlation, the corresponding cell is shown in green, while for a strong negative correlation, it is shown in red. Otherwise, for a weak correlation, the cell is white. The size of channel-wise features from SEED and DEAP are
and
, respectively, since there are 62 and 32 EEG channels in the datasets.
The channel-wise features from the SEED were extracted from Subject 1, 2, 3, and 4 when they were stimulated by positive, neutral, and negative emotions. Moreover, the channel-wise features from the DEAP were extracted from Subject 1, 2, 3, and 4 when they were stimulated by high valence high arousal (HVHA), high valence low arousal (HVLA), low valence high arousal (LVHA), and low valence low arousal (LVLA) emotions. Through visualization, we discovered that although people may experience the same stimuli when watching the same video, the channel-wise features varied from person to person. Moreover, all channel-wise features of an individual from different stimuli had similar patterns. This result demonstrated that the presented channel-wise feature could adequately describe the uniqueness of the respective individuals’ EEG signals.
When comparing the channel-wise feature with the existing method, it has some advantages. Channel-wise features have many excellent properties. First, no parameters are required when extracting channel-wise features. Thus, no training steps are needed and the calculation speed is fast. Second, unlike previous CNN-based methods, which consider only adjacent EEG channels, channel-wise features calculate the interdependency of every two pairs of channels to consider the subject-specific variability factor.
Due to these useful properties, inputting the channel-wise features into the model can filter the bias of subject-specific variability and ensure good performance by the user-independent emotion recognition model.
5.5.2. Effectiveness of the Emotional Features
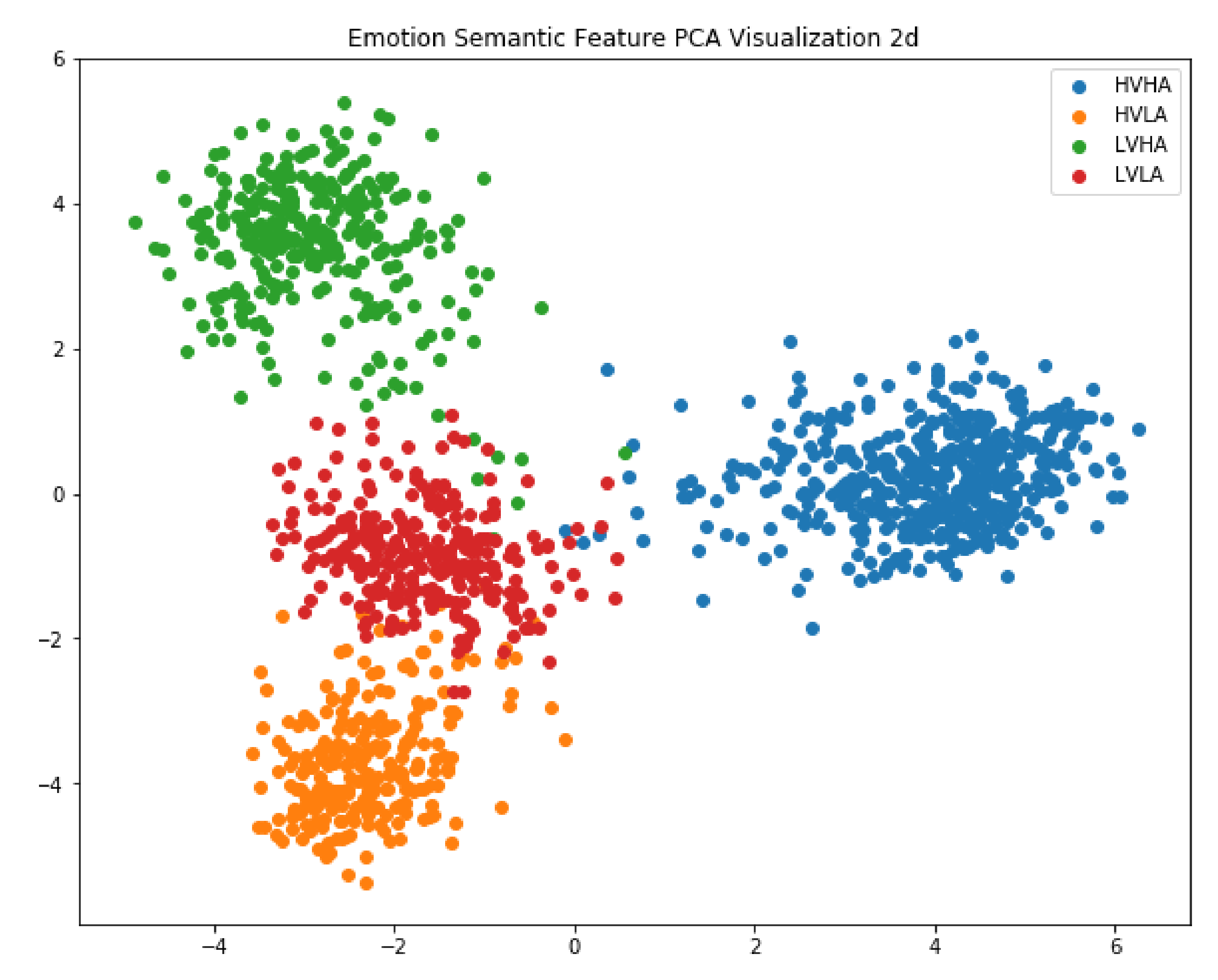
Repurposing a pre-trained model in transfer learning tasks can reduce the training time and increase accuracy. Thus, to explore the effectiveness of learned emotional features, we used a scatter plot to visualize the output vectors from the last time step in the second LSTM layer. The emotional features consist of 256 dimensions, since the hidden state in the LSTM unit has 256 nodes. We used principal component analysis (PCA) to reduce the dimension of emotional features to two.
Figure 7 shows the scatter plot of the dimension-reduced emotional features from the DEAP. The results agree with our observation in the following aspects: (1) emotional features coincide with corresponding emotions and can be classified using a simple method such as clustering or SVM; (2) our trained model can be used in transfer learning tasks such as intention detection or depression prediction.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}