An Impartial Semi-Supervised Learning Strategy for Imbalanced Classification on VHR Images


 , ,
, , 
Abstract
1. Introduction
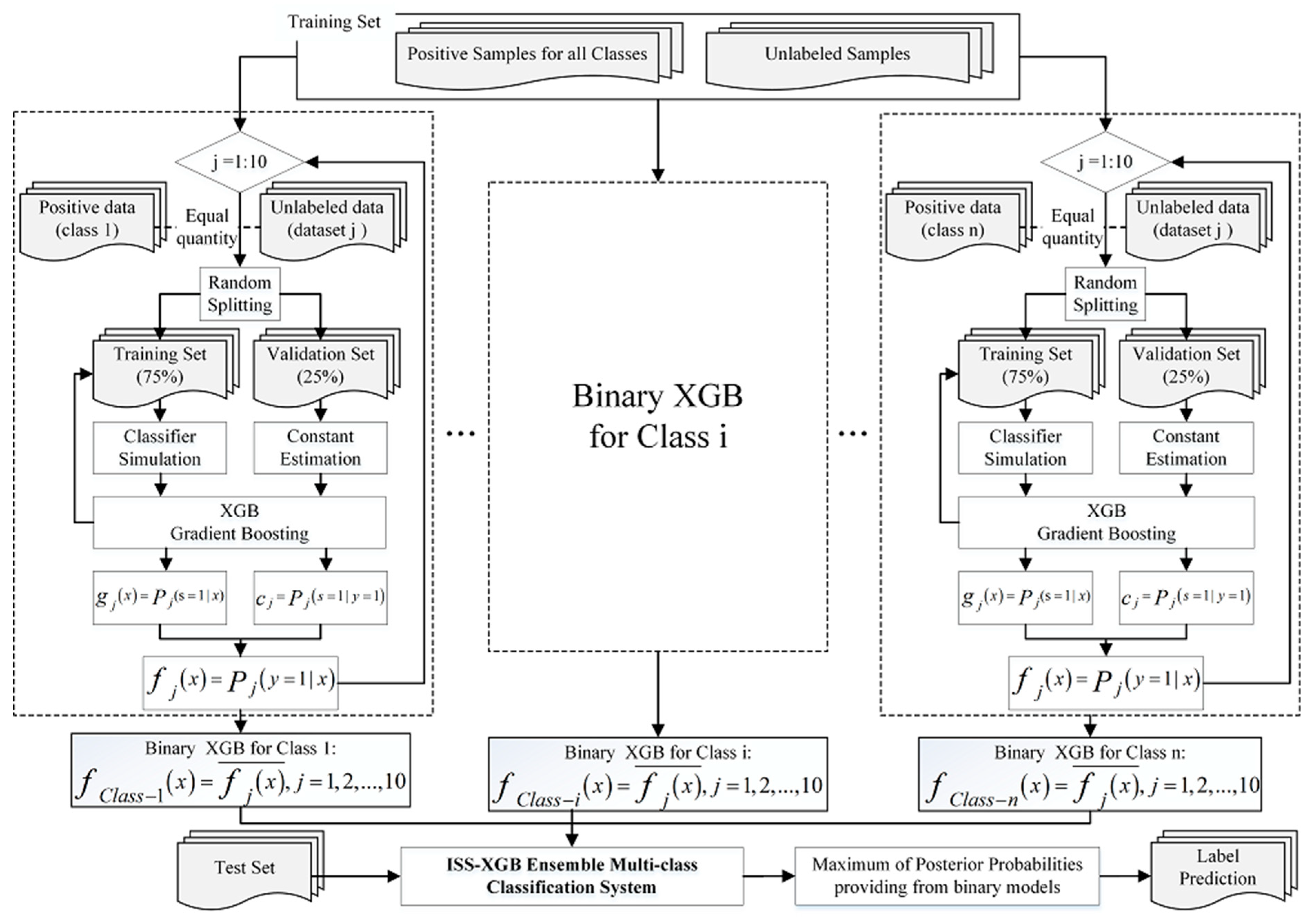
2. The Principle of ISS-XGB: Impartial Semi-Supervised Learning Strategy for Imbalanced Learning
3. Data and Experiment
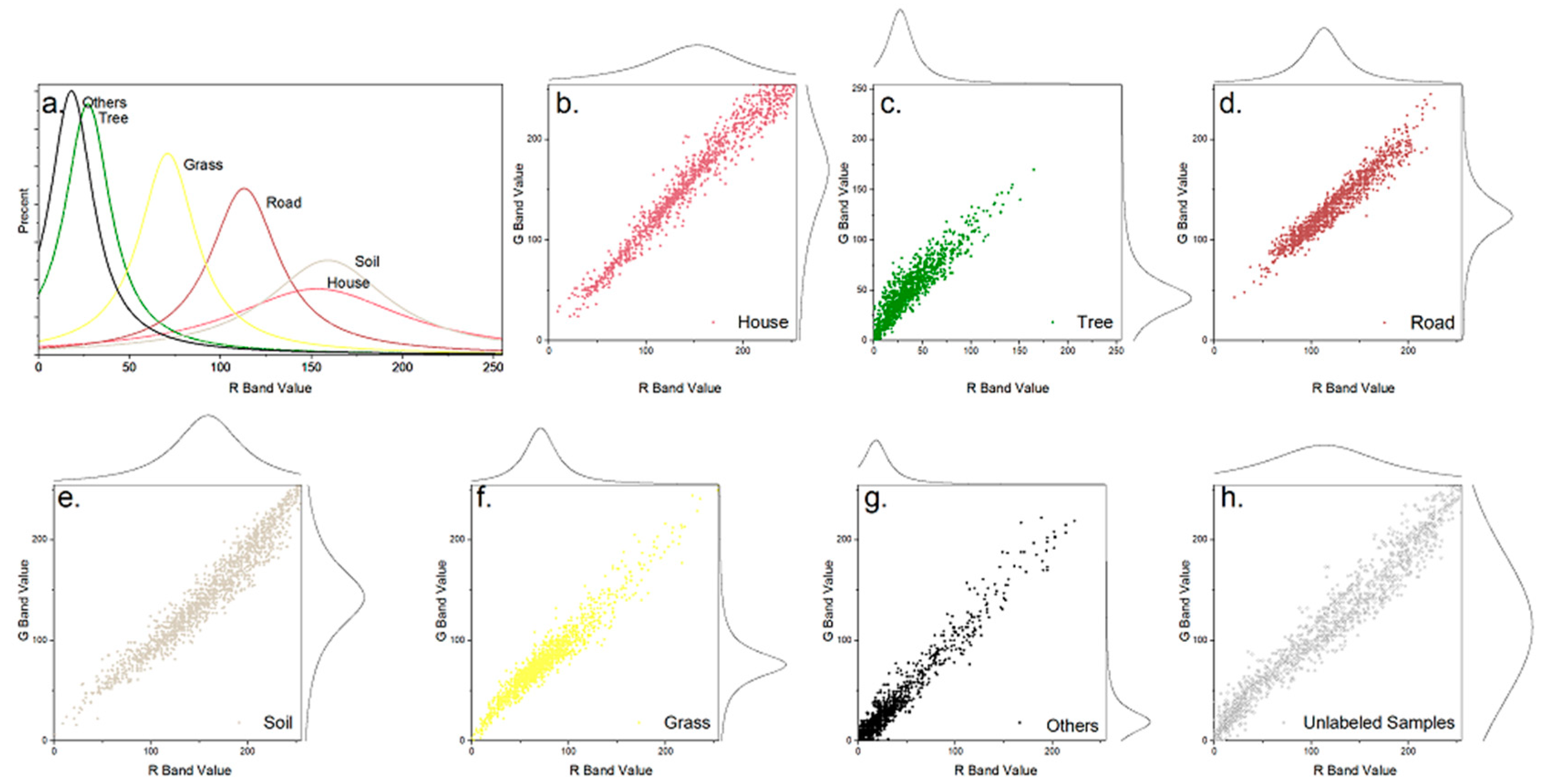
3.1. Study Areas and Data
3.2. Experimental Set-up and Accuracy Assessment
3.3. Parameter Optimization
4. Results
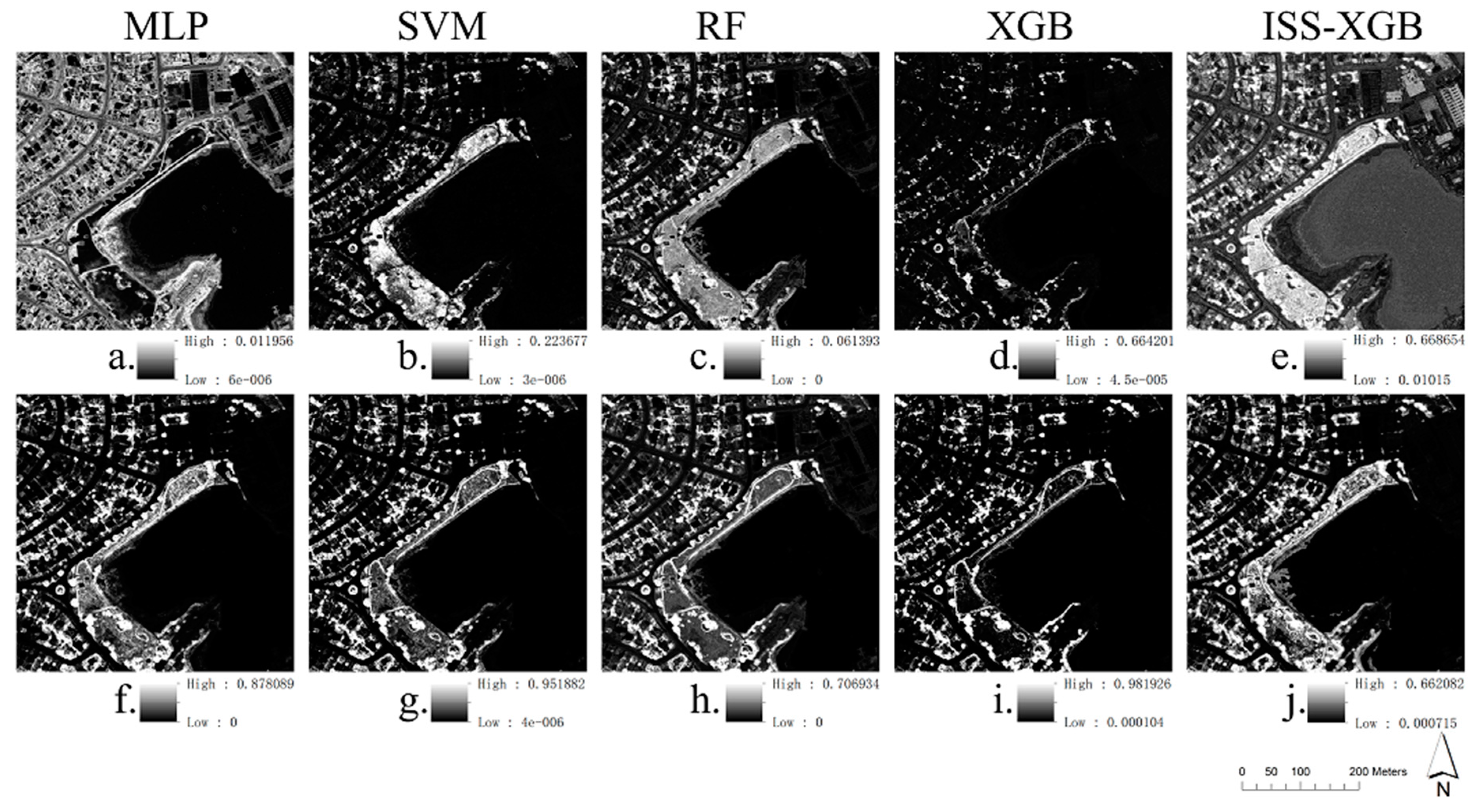
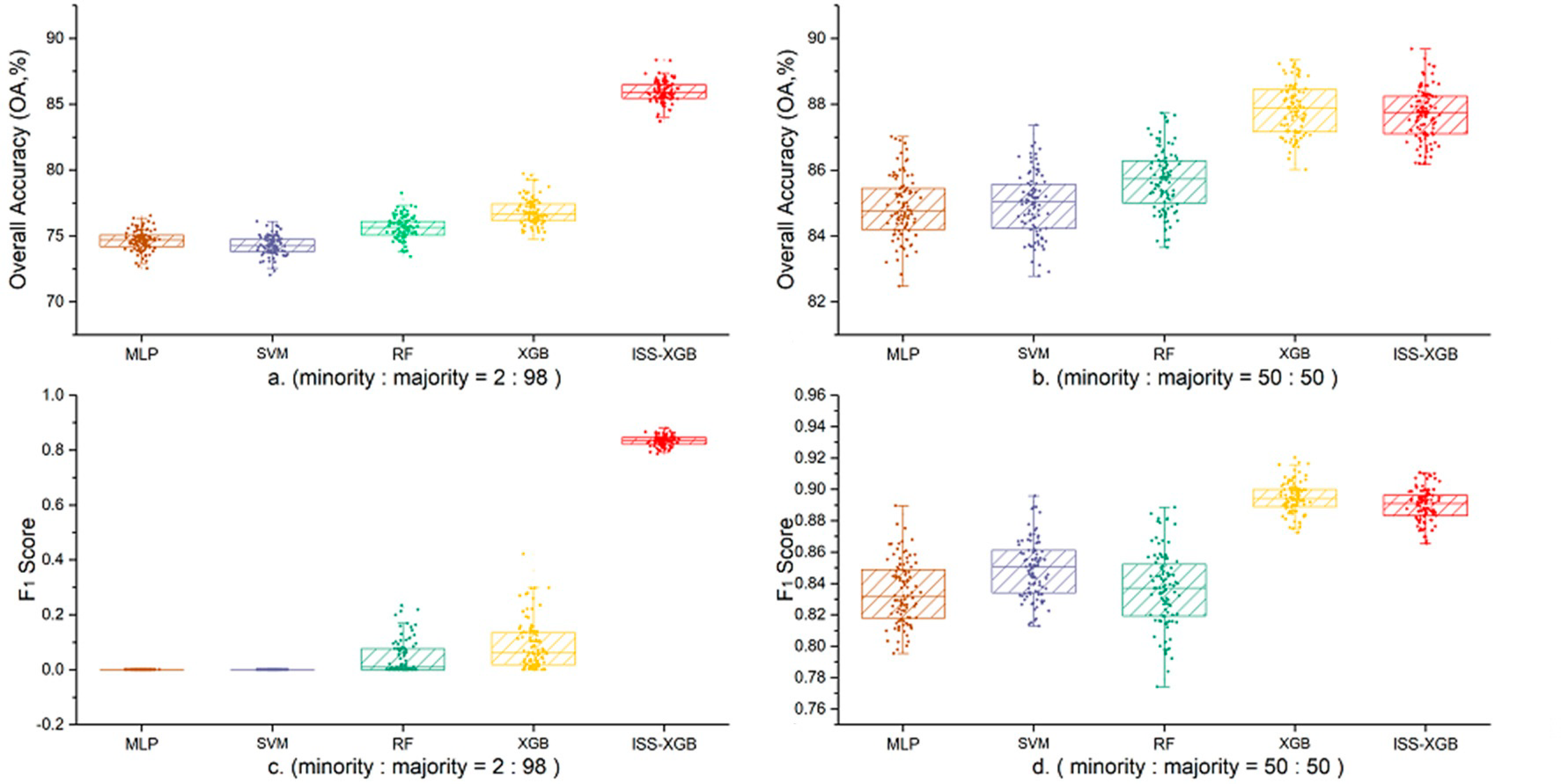
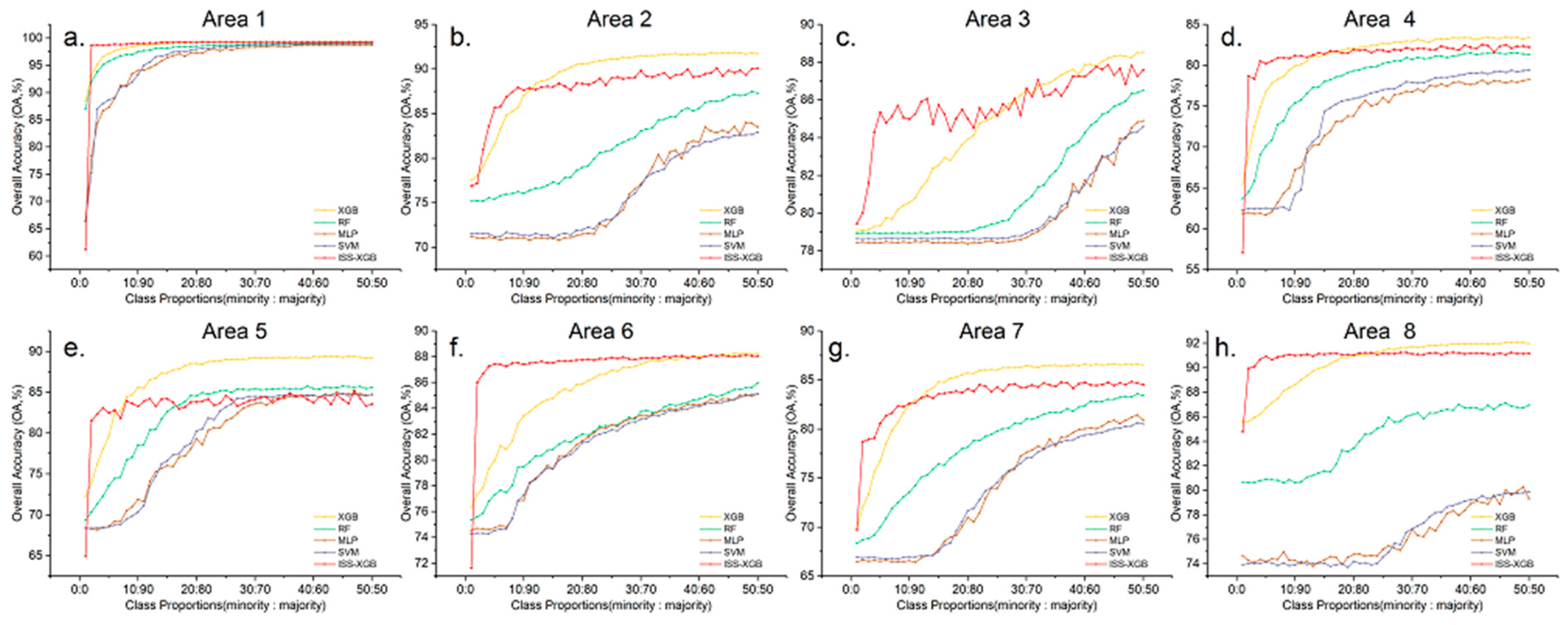
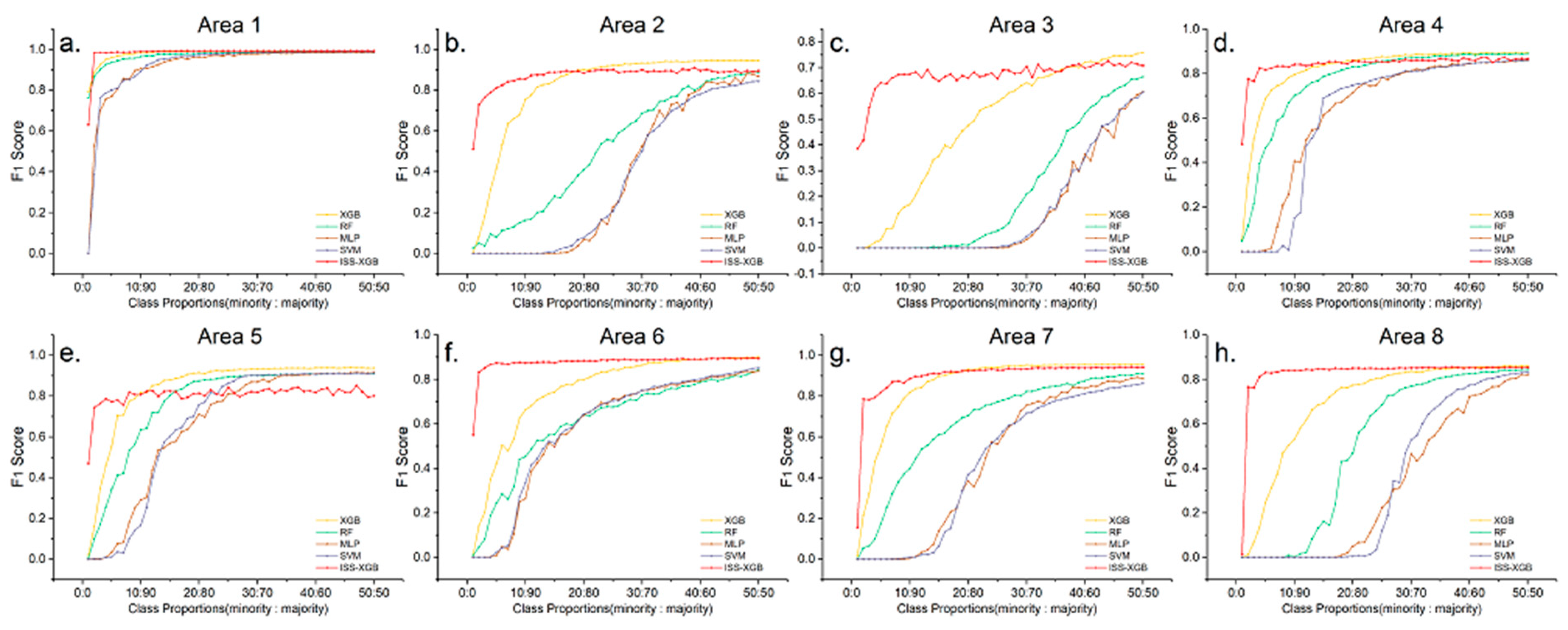
4.1. Performance on the Minority Class
4.2. Overall Performance
4.3. The Performance under Different Levels of Data Complexity
5. Discussion
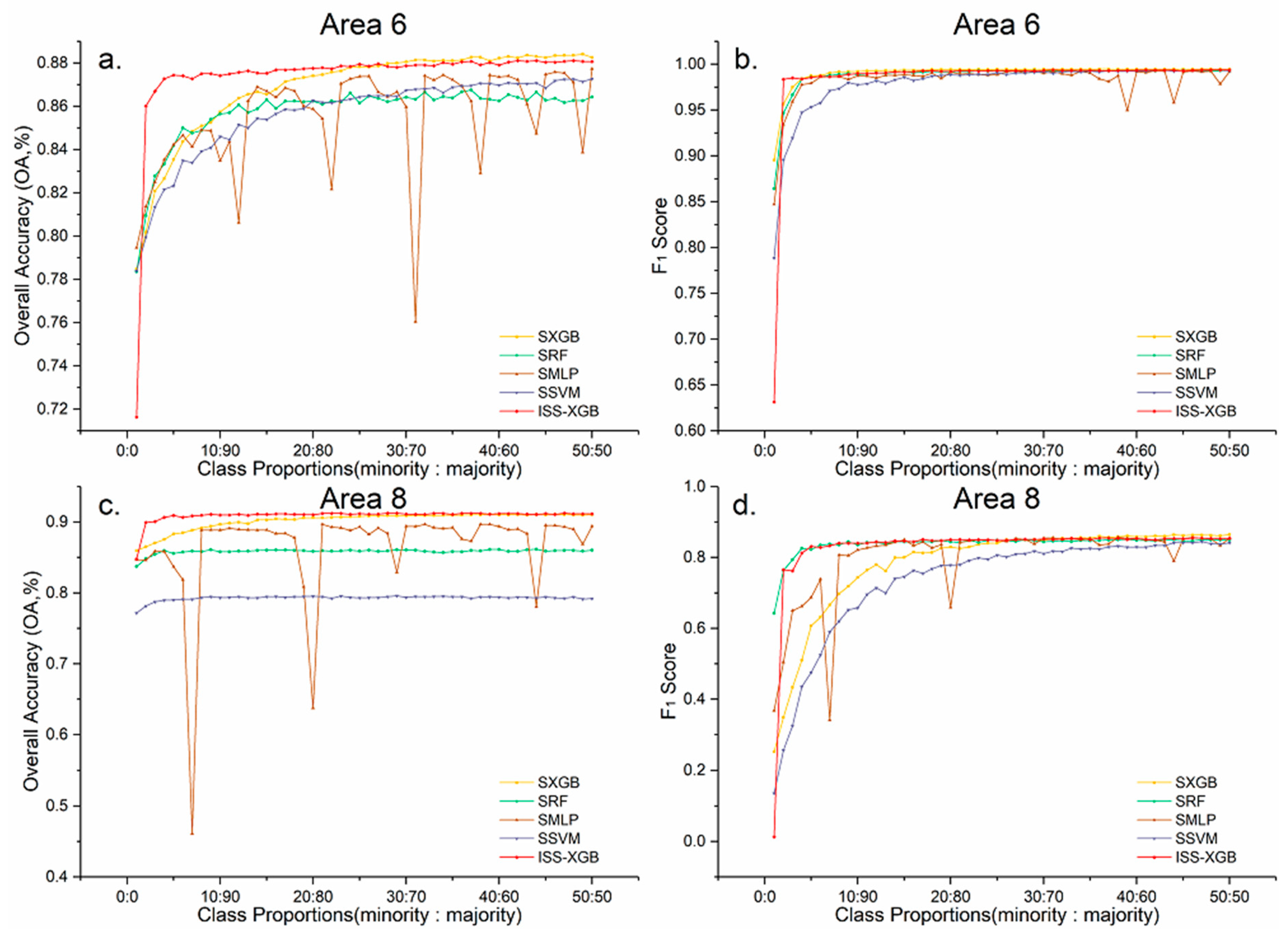
5.1. The Influence of Unlabeled Data on ISS-XGB
5.2. Comparison with PU-BP and PU-SVM
5.3. Comparison with SMOTE Sampling-Based Methods
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Lippitt, C.D.; Rogan, J.; Li, Z.; Eastman, J.R.; Jones, T.G. Mapping selective logging in mixed deciduous forest: A comparison of Machine Learning Algorithms. Photogramm. Eng. Remote Sens. 2008, 74, 1201–1211. [Google Scholar] [CrossRef]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- He, H.; Ma, Y. Imbalanced Learning: Foundations, Algorithms, and Applications; Wiley: Hoboken, NJ, USA, 2013. [Google Scholar]
- Ha, J.; Lee, J.-S. A New Under-Sampling Method Using Genetic Algorithm for Imbalanced Data Classification. In Proceedings of the 10th International Conference on Ubiquitous Information Management and Communication, Danang, Vietnam, 4−6 January 2016; pp. 1–6. [Google Scholar]
- Freeman, E.A.; Moisen, G.G.; Frescino, T.S. Evaluating effectiveness of down-sampling for stratified designs and unbalanced prevalence in Random Forest models of tree species distributions in Nevada. Ecol. Model. 2012, 233, 1–10. [Google Scholar] [CrossRef]
- Kumar, N.S.; Rao, K.N.; Govardhan, A.; Reddy, K.S.; Mahmood, A.M. Undersampled K-means approach for handling imbalanced distributed data. Prog. Artif. Intell. 2014, 3, 29–38. [Google Scholar] [CrossRef]
- Nekooeimehr, I.; Susana, K.; Yuen, L. Adaptive semi-unsupervised weighted oversampling (A-SUWO) for imbalanced datasets. Expert Syst. Appl. 2016, 46, 405–416. [Google Scholar] [CrossRef]
- Das, B.; Krishnan, N.C.; Cook, D.J. RACOG and wRACOG: Two Probabilistic Oversampling Techniques. IEEE Trans. Knowl. Data Eng. 2015, 27, 222–234. [Google Scholar] [CrossRef]
- Díez-Pastor, J.F.; Rodríguez, J.J.; García-Osorio, C.I.; Kuncheva, L.I. Diversity techniques improve the performance of the best imbalance learning ensembles. Inf. Sci. 2015, 325, 98–117. [Google Scholar] [CrossRef]
- Song, J.; Huang, X.; Qin, S.; Song, Q. A bi-directional sampling based on K-means method for imbalance text classification. In Proceedings of the 2016 IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS), Okayama, Japan, 26–29 June 2016; pp. 1–5. [Google Scholar]
- Tomek, I. Two Modifications of CNN. IEEE Trans. Syst. Man Cybern. 1976, SMC-6, 769–772. [Google Scholar] [CrossRef]
- Zhang, J.; Mani, I. KNN Approach to Unbalanced Data Distributions: A Case Study Involving Information Extraction. In Proceedings of the ICML’2003 Workshop on Learning from Imbalanced Datasets, Washington, DC, USA, 21 August 2003. [Google Scholar]
- Yun, J.; Ha, J.; Lee, J.-S. Automatic Determination of Neighborhood Size in SMOTE. In Proceedings of the 10th International Conference on Ubiquitous Information Management and Communication, Danang, Vietnam, 4–6 January 2016; pp. 1–8. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Int. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Pattanayak, S.S.; Rout, M. Experimental Comparison of Sampling Techniques for Imbalanced Datasets Using Various Classification Models. In Progress in Advanced Computing and Intelligent Engineering; Saeed, K., Chaki, N., Pati, B., Bakshi, S., Mohapatra, D., Eds.; Springer: Singapore, 2018; pp. 13–22. [Google Scholar]
- Andrew, E.; Taeho, J.; Nathalie, J. A Multiple Resampling Method for Learning from Imbalanced Data Sets. Comput. Intell. 2004, 20, 18–36. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.-Y.; Mao, B.-H. Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning. In Proceedings of the Advances in Intelligent Computing, Berlin, Heidelberg, Germany, 23−26 August 2005; pp. 878–887. [Google Scholar]
- Haibo, H.; Yang, B.; Garcia, E.A.; Shutao, L. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Fernandez, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for Learning from Imbalanced Data: Progress and Challenges, Marking the 15-year Anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]
- Yijing, L.; Haixiang, G.; Xiao, L.; Yanan, L.; Jinling, L. Adapted ensemble classification algorithm based on multiple classifier system and feature selection for classifying multi-class imbalanced data. Knowl.-Based Syst. 2016, 94, 88–104. [Google Scholar] [CrossRef]
- Kumar, L.; Ashish, S. Feature Selection Techniques to Counter Class Imbalance Problem for Aging Related Bug Prediction: Aging Related Bug Prediction. In Proceedings of the 11th innovations in software engineering conference, Hyderabad, India, 9–11 February 2018. [Google Scholar]
- Saeys, Y.; Inza, I.; Larranaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef]
- Haixiang, G.; Yijing, L.; Jennifer, S.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–2399. [Google Scholar] [CrossRef]
- Waldner, F.; Chen, Y.; Lawes, R.; Hochman, Z. Needle in a haystack: Mapping rare and infrequent crops using satellite imagery and data balancing methods. Remote Sens. Environ. 2019, 233, 111375. [Google Scholar] [CrossRef]
- Krawczyk, B.; Woźniak, M.; Schaefer, G. Cost-sensitive decision tree ensembles for effective imbalanced classification. Appl. Soft Comput. 2014, 14, 554–562. [Google Scholar] [CrossRef]
- Río, S.D.; López, V.; Benítez, J.M.; Herrera, F. On the use of MapReduce for imbalanced big data using Random Forest. Inf. Sci. 2014, 285, 112–137. [Google Scholar] [CrossRef]
- Vluymans, S.; Sánchez Tarragó, D.; Saeys, Y.; Cornelis, C.; Herrera, F. Fuzzy rough classifiers for class imbalanced multi-instance data. Pattern Recognit. 2016, 53, 36–45. [Google Scholar] [CrossRef]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A Review on Ensembles for the Class Imbalance Problem: Bagging-, Boosting-, and Hybrid-Based Approaches. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 463–484. [Google Scholar] [CrossRef]
- Dai, H.L. Imbalanced Protein Data Classification Using Ensemble FTM-SVM. IEEE Trans. Nanobiosci. 2015, 14, 350–359. [Google Scholar] [CrossRef] [PubMed]
- Wu, D.; Wang, Z.; Chen, Y.; Zhao, H. Mixed-kernel based weighted extreme learning machine for inertial sensor based human activity recognition with imbalanced dataset. Neurocomputing 2016, 190, 35–49. [Google Scholar] [CrossRef]
- Datta, S.; Das, S. Multiobjective Support Vector Machines: Handling Class Imbalance with Pareto Optimality. IEEE Trans. Neural Netw. Learn. Syst. 2018, 10, 7. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Yang, Z.; Zhang, Y.; Pan, X.; Wang, L. A maximum margin and minimum volume hyper-spheres machine with pinball loss for imbalanced data classification. Knowl.-Based Syst. 2016, 95, 75–85. [Google Scholar] [CrossRef]
- Bagherpour, S.; Nebot, À.; Mugica, F. FIR as Classifier in the Presence of Imbalanced Data. In Proceedings of the International Symposium on Neural Networks, Petersburg, Russia, 6−8 July 2016; pp. 490–496. [Google Scholar]
- Vigneron, V.; Chen, H. A multi-scale seriation algorithm for clustering sparse imbalanced data: Application to spike sorting. Pattern Anal. Appl. 2016, 19, 885–903. [Google Scholar] [CrossRef]
- Mellor, A.; Boukir, S.; Haywood, A.; Jones, S. Exploring issues of training data imbalance and mislabelling on random forest performance for large area land-cover classification using the ensemble margin. ISPRS J. Photogramm. Remote Sens. 2015, 105, 155–168. [Google Scholar] [CrossRef]
- Graves, S.J.; Asner, G.P.; Martin, R.E.; Anderson, C.B.; Colgan, M.S.; Kalantari, L.; Bohlman, S.A. Tree Species Abundance Predictions in a Tropical Agricultural Landscape with a Supervised Classification Model and Imbalanced Data. Remote Sens. 2016, 8, 161. [Google Scholar] [CrossRef]
- Sun, F.; Wang, R.; Wan, B.; Su, Y.; Guo, Q.; Huang, Y.; Wu, X. Efficiency of Extreme Gradient Boosting for Imbalanced Land-cover Classification Using an Extended Margin and Disagreement Performance. ISPRS Int. J. Geo-Inf. 2019, 8, 315. [Google Scholar] [CrossRef]
- Li, F.; Li, S.; Zhu, C.; Lan, X.; Chang, H. Cost-Effective Class-Imbalance Aware CNN for Vehicle Localization and Categorization in High Resolution Aerial Images. Remote Sens. 2017, 9, 494. [Google Scholar] [CrossRef]
- Krawczyk, B.; Galar, M.; Jeleń, Ł.; Herrera, F. Evolutionary undersampling boosting for imbalanced classification of breast cancer malignancy. Appl. Soft Comput. 2016, 38, 714–726. [Google Scholar] [CrossRef]
- Hassan, A.K.I.; Abraham, A. Modeling Insurance Fraud Detection Using Imbalanced Data Classification. Advances in Nature and Biologically Inspired Computing; Springer: Cham, Switzerland, 2016; pp. 117–127. [Google Scholar]
- Zhang, Z.; Krawczyk, B.; Garcìa, S.; Rosales-Pérez, A.; Herrera, F. Empowering one-vs-one decomposition with ensemble learning for multi-class imbalanced data. Knowl.-Based Syst. 2016, 106, 251–263. [Google Scholar] [CrossRef]
- Fernández, A.; del Jesus, M.J.; Herrera, F. Multi-class Imbalanced Data-Sets with Linguistic Fuzzy Rule Based Classification Systems Based on Pairwise Learning. In Proceedings of the International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems, Dortmund, Germany, 28 June−2 July 2010; Springer: Dortmund, Germany, 2010; pp. 89–98. [Google Scholar]
- Beyan, C.; Fisher, R. Classifying imbalanced data sets using similarity based hierarchical decomposition. Pattern Recognit. 2015, 48, 1653–1672. [Google Scholar] [CrossRef]
- Zhang, X.; Li, P.; Cai, C. Regional Urban Extent Extraction Using Multi-Sensor Data and One-Class Classification. Remote Sens. 2015, 7, 7671–7694. [Google Scholar] [CrossRef]
- Georganos, S.; Grippa, T.; Vanhuysse, S.; Lennert, M.; Shimoni, M.; Wolff, E. Very High Resolution Object-Based Land-use–Land-cover Urban Classification Using Extreme Gradient Boosting. IEEE Geosci. Remote Sens. Lett. 2018, 15, 607–611. [Google Scholar] [CrossRef]
- Chawla, N.V.; Karakoulas, G. Learning from labeled and unlabeled data: An empirical study across techniques and domains. J. Artif. Int. Res. 2005, 23, 331–366. [Google Scholar] [CrossRef]
- Elkan, C.; Noto, K. Learning classifiers from only positive and unlabeled data. In Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, Las Vegas, NV, USA, 24−27 August 2008; pp. 213–220. [Google Scholar]
- Guo, Q.; Li, W.; Liu, D.; Chen, J. A Framework for Supervised Image Classification with Incomplete Training Samples. Photogramm. Eng. Remote Sens. 2012, 78, 595–604. [Google Scholar] [CrossRef]
- Deng, X.; Li, W.; Liu, X.; Guo, Q.; Newsam, S. One-class remote sensing classification: One-class vs. Binary classifiers. Int. J. Remote Sens. 2018, 39, 1890–1910. [Google Scholar] [CrossRef]
- Li, W.; Guo, Q.; Elkan, C. A Positive and Unlabeled Learning Algorithm for One-Class Classification of Remote-Sensing Data. IEEE Trans. Geosci. Remote Sens. 2011, 49, 717–725. [Google Scholar] [CrossRef]
- Wang, R.; Wan, B.; Guo, Q.; Hu, M.; Zhou, S. Mapping Regional Urban Extent Using NPP-VIIRS DNB and MODIS NDVI Data. Remote Sens. 2017, 9, 862. [Google Scholar] [CrossRef]
- Wan, B.; Guo, Q.; Fang, F.; Su, Y.; Wang, R. Mapping US Urban Extents from MODIS Data Using One-Class Classification Method. Remote Sens. 2015, 7, 10143–10163. [Google Scholar] [CrossRef]
- Chen, X.; Yin, D.; Chen, J.; Cao, X. Effect of training strategy for positive and unlabelled learning classification: Test on Landsat imagery. Remote Sens. Lett. 2016, 7, 1063–1072. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13−17 August 2016; pp. 785–794. [Google Scholar]
- Carmona, P.; Climent, F.; Momparler, A. Predicting failure in the U.S. banking sector: An extreme gradient boosting approach. Int. Rev. Econ. Financ. 2019, 61, 304–323. [Google Scholar] [CrossRef]
- He, H.; Zhang, W.; Zhang, S. A novel ensemble method for credit scoring: Adaption of different imbalance ratios. Expert Syst. Appl. 2018, 98, 105–117. [Google Scholar] [CrossRef]
- Panuju, D.R.; Paull, D.J.; Trisasongko, B.H. Combining Binary and Post-Classification Change Analysis of Augmented ALOS Backscatter for Identifying Subtle Land-cover Changes. Remote Sens. 2019, 11, 100. [Google Scholar] [CrossRef]
- Ustuner, M.; Balik Sanli, F. Polarimetric Target Decompositions and Light Gradient Boosting Machine for Crop Classification: A Comparative Evaluation. ISPRS Int. J. Geo-Inf. 2019, 8, 97. [Google Scholar] [CrossRef]
- Madonsela, S.; Cho, M.A.; Ramoelo, A.; Mutanga, O.; Naidoo, L. Estimating tree species diversity in the savannah using NDVI and woody canopy cover. Int. J. Appl. Earth Obs. Geoinf. 2018, 66, 106–115. [Google Scholar] [CrossRef]
- McGarigal, K.S.; Samuel, C.; Maile, N.; Ene, E. FRAGSTATS v4: Spatial Pattern Analysis Program for Categorical and Continuous Maps. Available online: http://www.umass.edu/landeco/research/fragstats/fragstats.html (accessed on 6 April 2018).
- Leichtle, T.; Geiss, C.; Lakes, T.; Taubenboeck, H. Class imbalance in unsupervised change detection―A diagnostic analysis from urban remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2017, 60, 83–98. [Google Scholar] [CrossRef]
- Bruzzone, L.; Serpico, S.B. Classification of imbalanced remote-sensing data by neural networks. Pattern Recognit. Lett. 1997, 18, 1323–1328. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, T.; Li, T. Gradient Boosting Model for Unbalanced Quantitative Mass Spectra Quality Assessment. In Proceedings of the 2017 International Conference on Security, Pattern Analysis and Cybernetics (SPAC), Shenzhen, China, 15−17 December 2017; pp. 394–399. [Google Scholar]
- Foody, G.M. Status of land-cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Pontius, R.G., Jr.; Millones, M. Death to Kappa: Birth of quantity disagreement and allocation disagreement for accuracy assessment. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Vanderplas, J.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Area | SHDI | Species |
|---|---|---|
| 1 | 0.83 | Farmland with crops, Farmland without crops, Soil |
| 2 | 0.94 | House, Tree, Farmland with crops, Farmland without crops, Others |
| 3 | 1.02 | Tree, Farmland with crops, Farmland without crops, Soil, Water, Others |
| 4 | 1.19 | Tree, Farmland with crops, Farmland without crops, Soil, Grass |
| 5 | 1.21 | House, Tree, Farmland with crops, Farmland without crops, Soil, Others |
| 6 | 1.43 | House, Tree, Road, Soil, Grass, Others |
| 7 | 1.67 | House, Tree, Farmland with crops, Farmland without crops, Soil, Grass, Others |
| 8 | 2.22 | Water, Road, Tree, Buildings, Grass, Waterweeds, High-light Objects, Soil, Others (Buildings include three types of building roofs with different colors in pseudo mode) |
| Models | Quantity Accuracy of Models with Sample Sets of Different Imbalances | |||||||
|---|---|---|---|---|---|---|---|---|
| Minority:Majority = 2:98 | Minority:Majority = 50:50 | |||||||
| F1 | |Z| | QD’ (%) | AD’ (%) | F1 | |Z| | QD’ (%) | AD’ (%) | |
| MLP | 0 | 31.39 * | 100 | 0 | 0.86 | 28.30 * | 7.71 | 26.88 |
| SVM | 0 | 30.05 * | 100 | 0 | 0.84 | 25.47 * | 2.69 | 28.67 |
| RF | 0 | 21.04 * | 100 | 0 | 0.82 | 12.76 * | 0 | 30.82 |
| XGB | 0.01 | 12.12 * | 99.64 | 0 | 0.83 | 1.59 | 3.23 | 25.45 |
| ISS-XGB | 0.77 | - | 5.02 | 37.99 | 0.85 | - | 2.69 | 26.52 |
| Models | Average Accuracies and Standard Deviations with Sample Sets of Different Imbalances | |||||||
|---|---|---|---|---|---|---|---|---|
| Minority:Majority = 2:98 | Minority:Majority = 50:50 | |||||||
| OA (Avg./STD) | F1 (Avg./STD) | OA (Avg./STD) | F1 (Avg./STD) | |||||
| MLP | 74.65% | /0.0077 | 0 | 0 | 84.87% | /0.0093 | 0.8343 | /0.0198 |
| SVM | 74.30% | /0.0075 | 0 | 0 | 84.96% | /0.0093 | 0.8491 | /0.0180 |
| RF | 75.62% | /0.0083 | 0.0424 | /0.0588 | 85.69% | /0.0093 | 0.8361 | /0.0240 |
| XGB | 76.81% | /0.0099 | 0.0895 | /0.0864 | 87.85% | /0.0075 | 0.8944 | /0.0098 |
| ISS-XGB | 85.92% | /0.0080 | 0.8333 | /0.0179 | 87.69% | /0.0077 | 0.8899 | /0.0100 |
| Reference | Confusion Matrix of Classification with Sample Sets of Different Imbalances (Prediction) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Minority:Majority = 2:98 | Minority:Majority = 50:50 | ||||||||||||
| House | Tree | Road | Soil | Grass | Others | House | Tree | Road | Soil | Grass | Others | ||
| MLP (|Z| = 21.52 *) | House | 0 | 10 | 451 | 283 | 20 | 28 | 560 | 11 | 147 | 50 | 14 | 10 |
| Tree | 0 | 798 | 4 | 6 | 80 | 61 | 1 | 807 | 4 | 6 | 73 | 58 | |
| Road | 0 | 3 | 907 | 33 | 3 | 2 | 28 | 3 | 887 | 28 | 2 | 0 | |
| Soil | 0 | 4 | 9 | 864 | 72 | 7 | 18 | 5 | 14 | 840 | 73 | 6 | |
| Grass | 0 | 76 | 16 | 58 | 497 | 14 | 18 | 78 | 15 | 45 | 496 | 9 | |
| Others | 0 | 70 | 6 | 9 | 9 | 951 | 13 | 79 | 2 | 7 | 8 | 936 | |
| OA = 75.07% QD = NaN AD = NaN | OA = 84.58% QD = 8.05% AD = 6.52% | ||||||||||||
| SVM (|Z| = 21.77 *) | House | 0 | 6 | 551 | 176 | 27 | 32 | 616 | 6 | 91 | 48 | 20 | 11 |
| Tree | 0 | 791 | 4 | 5 | 89 | 60 | 1 | 792 | 4 | 5 | 89 | 58 | |
| Road | 0 | 3 | 910 | 30 | 3 | 2 | 39 | 3 | 880 | 23 | 3 | 0 | |
| Soil | 0 | 5 | 18 | 844 | 85 | 4 | 24 | 6 | 18 | 823 | 82 | 3 | |
| Grass | 0 | 83 | 20 | 46 | 503 | 9 | 20 | 86 | 7 | 39 | 502 | 7 | |
| Others | 0 | 75 | 4 | 8 | 9 | 949 | 12 | 82 | 3 | 7 | 6 | 935 | |
| OA = 74.70% QD = NaN AD = NaN | OA = 84.99% QD = 7.60% AD = 6.80% | ||||||||||||
| RF (|Z| = 20.98 *) | House | 2 | 6 | 226 | 366 | 164 | 28 | 570 | 6 | 143 | 46 | 17 | 10 |
| Tree | 0 | 802 | 3 | 6 | 72 | 66 | 1 | 806 | 4 | 6 | 72 | 60 | |
| Road | 0 | 3 | 908 | 34 | 2 | 1 | 31 | 2 | 883 | 28 | 4 | 0 | |
| Soil | 0 | 3 | 14 | 861 | 73 | 5 | 22 | 4 | 7 | 845 | 74 | 4 | |
| Grass | 0 | 74 | 7 | 55 | 520 | 5 | 20 | 75 | 6 | 45 | 511 | 4 | |
| Others | 0 | 67 | 3 | 11 | 8 | 956 | 13 | 62 | 2 | 7 | 7 | 954 | |
| OA = 75.67% QD = 18.44% AD = 4.64% | OA = 85.39% QD = 7.35% AD = 6.59% | ||||||||||||
| XGB (|Z| = 18.56 *) | House | 32 | 8 | 259 | 250 | 207 | 36 | 697 | 6 | 23 | 47 | 8 | 11 |
| Tree | 0 | 813 | 4 | 5 | 62 | 65 | 1 | 812 | 4 | 7 | 61 | 64 | |
| Road | 0 | 4 | 917 | 21 | 6 | 0 | 48 | 3 | 876 | 19 | 2 | 0 | |
| Soil | 1 | 5 | 11 | 857 | 78 | 4 | 19 | 5 | 10 | 841 | 77 | 4 | |
| Grass | 0 | 73 | 7 | 51 | 524 | 6 | 18 | 73 | 5 | 50 | 511 | 4 | |
| Others | 0 | 49 | 3 | 8 | 12 | 973 | 11 | 50 | 3 | 7 | 8 | 966 | |
| OA = 76.92% QD = 14.30% AD = 5.75% | OA = 87.89% QD = 7.11% AD = 5.94% | ||||||||||||
| ISS-XGB (|Z| = 6.80 *) | House | 697 | 8 | 24 | 35 | 16 | 12 | 700 | 6 | 20 | 49 | 7 | 10 |
| Tree | 1 | 820 | 4 | 6 | 63 | 55 | 1 | 821 | 4 | 6 | 61 | 56 | |
| Road | 83 | 3 | 846 | 13 | 2 | 1 | 69 | 3 | 855 | 19 | 2 | 0 | |
| Soil | 140 | 5 | 7 | 734 | 66 | 4 | 17 | 5 | 9 | 849 | 72 | 4 | |
| Grass | 19 | 72 | 4 | 52 | 509 | 5 | 19 | 70 | 4 | 47 | 516 | 5 | |
| Others | 12 | 55 | 2 | 8 | 5 | 963 | 12 | 52 | 2 | 8 | 7 | 964 | |
| OA = 85.38% QD = 7.26% AD = 8.15% | OA = 87.93% QD = 7.16% AD = 5.99% | ||||||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, F.; Fang, F.; Wang, R.; Wan, B.; Guo, Q.; Li, H.; Wu, X. An Impartial Semi-Supervised Learning Strategy for Imbalanced Classification on VHR Images. Sensors 2020, 20, 6699. https://doi.org/10.3390/s20226699
Sun F, Fang F, Wang R, Wan B, Guo Q, Li H, Wu X. An Impartial Semi-Supervised Learning Strategy for Imbalanced Classification on VHR Images. Sensors. 2020; 20(22):6699. https://doi.org/10.3390/s20226699
Chicago/Turabian StyleSun, Fei, Fang Fang, Run Wang, Bo Wan, Qinghua Guo, Hong Li, and Xincai Wu. 2020. "An Impartial Semi-Supervised Learning Strategy for Imbalanced Classification on VHR Images" Sensors 20, no. 22: 6699. https://doi.org/10.3390/s20226699
APA StyleSun, F., Fang, F., Wang, R., Wan, B., Guo, Q., Li, H., & Wu, X. (2020). An Impartial Semi-Supervised Learning Strategy for Imbalanced Classification on VHR Images. Sensors, 20(22), 6699. https://doi.org/10.3390/s20226699