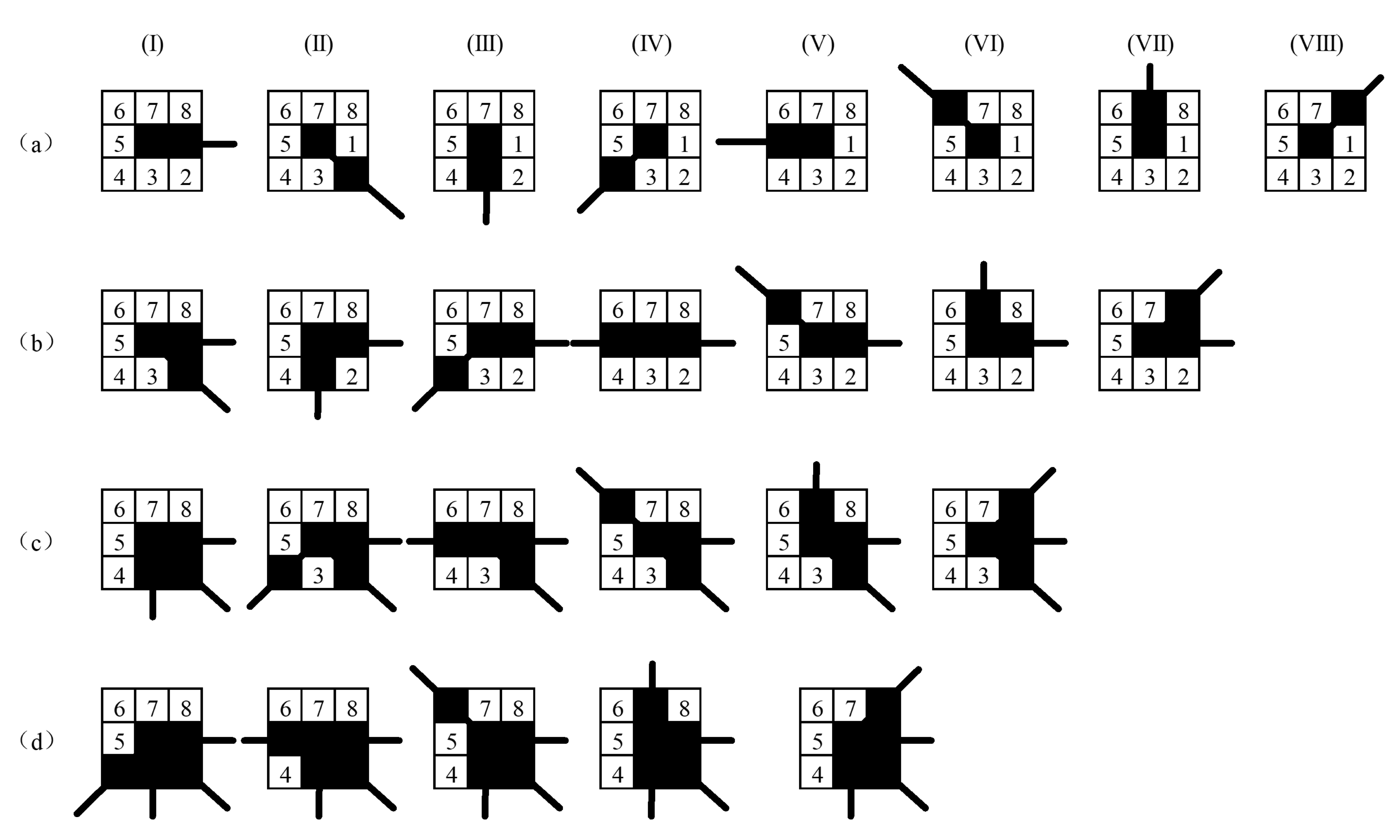
1. Introduction
Digital images consist of limited and discrete pixels obtained using digital image sensors (such as CCD or CMOS). These discrete pixels reflect energy intensity through numerical values, and the energy intensity is related to the characteristics of the captured object. Due to the existence of this relationship, the features of the captured object can be expressed by the pixels in the image. Feature detection is an abstraction of image information and a local decision-making method for each pixel whether there is a given type of feature. It is a fundamental problem in computer vision and has many practical applications, such as object detection [
1], stereo matching [
2], color matching [
3], and motion estimation [
4]. In order to response to diverse applications, many detection methods have been proposed [
5,
6]. Following traditional classification methods, feature detection can be divided into point, edge, and region detection. Feature point is most widely used because of its stability and uniqueness.
Feature point detection with geometric invariance and illumination invariance has always been a challenging problem. Geometric invariance includes translation, rotation, scale, and affine invariance. The illumination invariance is also called illumination robustness. The illumination robustness of the feature detector reflects the ability to extract features from low-illumination or overexposed images. In the past, this work was often used as a supplement to geometric invariance, and there were few dedicated studies as if it were not important. However, with the widespread application of computer vision, feature point detection in complex scenes (such as non-uniform illumination) has become a must. The illumination invariance becomes as important as the geometric invariance. This paper focuses on the feature point detection method of illumination robustness, proposes a novel method of illumination-robust feature point detection.
To the best of our knowledge, the early illumination-robust detection are all feature-based methods. One of the most common methods is to improve the illumination quality of the input image. For example, Faille [
7] decomposes the input image into illumination components and reflection components, and then uses a high-pass filter to remove low-frequency illumination components. Gevrekci et al. [
8] apply the contrast stretching function to two differently illuminated images. When the contrast center is changed, the two differently illuminated images obtain similar response images at different contrast centers. At this time, most feature detectors can obtain a better detection result. Xue and Gao [
9] constructed an illumination invariant color space based on adaptive histogram equ lization and dark channel priority theory, and then used AKAZE detector to extract feature points. Adaptive histogram equalization was used to enhance texture details and balance the illumination in the image, and dark channel priority was used to further reduce the impact of illumination on feature extraction.
Another better option is to consider the illuminance robustness during the design of the feature detector. Moravec [
10] proposed the earliest corner detection method. Harris and Stephens [
11] used the gradient to calculate the response function, and then used the response function to determine corners. The introduction of gradients reduced the impact of illumination on the detector. Lowe [
12] proposed a SIFT feature detector, and suggested using Hessian matrix instead of Harris for keypoints selection, and redefined the keypoints response function. The introduction of the Hessian matrix makes the detector robust to illumination. As an accelerated version of SIFT, SURF [
13] also uses the Hessian matrix for feature selection, and the response function is improved on the basis of the Harris detector. Lee and Chen [
14] proposed a method to detect feature points using histogram information. This method constructs a Hessian matrix that does not contain the second-order partial differential equation, but it contains the histogram information of the pixel neighborhood. Miao and Jiang [
15] proposed a feature detector based on a nonlinear filter which is named ROLG (Rank Order Laplace of Gaussian). The ROLG is a rank order filter, and its weight is proportional to the coefficients of the LoG (Laplace of Gaussian) filter. Wu et al. [
16] proposed a detection method that utilizes optimal multi-binary images to eliminate the noise and illumination effects. Considering the problem that low-contrast image structure is easily submerged by high-contrast image structure, Miao et al. [
17] proposed to construct a zero-norm LoG filter. Since the response of the zero-norm LoG filter is proportional to the weighted of pixels in the local area, the filter keeps the image contrast unchanged. Furthermore, based on the zero-norm LoG filter, they developed a new feature point detector. Hong-Phuoc and Guan [
18] pointed out that most hand-crafted feature detectors rely on pre-designed structures, and this pre-designed structure will be affected by uneven illumination. They proposed a feature detector to locate feature points in the image by calculating the complexity of the blocks surrounding the pixels.
Among the feature-based detection methods, Harris is considered to be the basis for the illumination robustness of the corner detectors, and the Hessian matrix is the root cause of the illumination robustness of the spot detection methods. However, Harris was based on the autocorrelation matrix introduces textured patterns and noise while detecting corners. The Hessian matrix contains second-order partial differential, and the feature detector constructed with the Hessian matrix as the response function will inevitably introduce unstable and error points around the structure [
18]. Though there are also some other illumination-robust feature detection methods, these methods are not widely used due to own limitations. For example, the Wu’s method [
16] must provide a reference image when extracting feature points. The method of Hong-Phuoc and Guan [
18] does not work well for severely underexposed or overexposed images.
When feature-based detection methods encounter bottlenecks, deep learning have been widely used in many fields as a brand-new problem-solving idea. Naturally, learning-based methods were also introduced into feature point detection as a new attempt.
TILDE [
19] introduced a learning-based method for feature point detection, and trained the regressor through supervised learning to work normally even if the illumination changes drastically. Unlike TILDE, which only performs feature detection, LIFT [
20] is a novel architecture that can perform detection, orientation estimation, and description at the same time. The training process introduces the inverse training, which can minimize the influence of illumination on feature point detection. Although LIFT can extract illumination-robust feature points well, it is still a supervised learning method. Quad-Networks [
21] is an unsupervised feature point detection method. It trains a neural network in an illumination-invariant manner and uses the network to sort pixels. If some pixels can achieve higher ranking under different illumination, these pixels are selected as candidate feature points. The network obtained by this training method is an illumination-robust feature detection network, which can extract illumination-robust feature points. The unsupervised learning of SuperPoint [
22] is different from Quad-Networks. It proposes pre-training the feature detector on the procedurally generated polygonal synthetic geometric data set, then uses the pre-training network to extract the feature points on the real data set and use them as label data, and finally uses these data to train the network. In addition, LF-Net [
23] exploit depth and relative camera pose to create a virtual target response for the network. Through this response relationship, training can be performed without hand-crafted detector, thereby performing sparse matching. D2-Net [
24] addresses the problem of poor performance of traditional sparse local features under illumination changes drastically by postponing the detection. Key.Net [
25] combines the hand-crafted detector and CNN filter in the shallow multi-scale framework, which reduces the number of network parameters and ensures the detection repeatibility rate. ASLFeat [
26] further improves the positioning accuracy of D2-Net keypoints.
With the widespread application of learning-based methods in feature detection, some inherent disadvantages have gradually been exposed, such as poor versatility, high training costs (time and equipment), and the need for large amounts of data for learning. In addition, the uninterpretability of learning results is also a problem that must be faced. Before these problems are solved, learning-based detection methods are not suitable in many application scenarios. In view of this, feature-based detection methods are still a key research area at present and for a long time in the future. However, feature-based detectors are basically extended based on Harris, Hessian, and FAST, and these detectors themselves do not have excellent illumination robustness. Our method is a brand-new detection method, which completely bypasses the conventional design ideas of the detector and uses the location information of eight-neighborhoods for detection. Since the eight-neighborhood of the pixel itself is very close to the position of the pixel, the detailed information can be well preserved and the illumination robustness of the detection can be improved. At the same time, our method is different from Wu’s method [
16]. Based on Wu’s method, we have further deepened and expanded the types of feature points from 8 types to 250 types. The expansion of types promotes the improvement of matching accuracy and matching speed. In addition, we designed a complete illumination robustness feature detection method and analyzed its matching performance. We also added experiments with different illumination intensity and illumination direction in the
Section 5 (Experimental Results). The contributions of this paper are as follows:
This paper proposes a novel feature point detection method based on the position of the neighborhood connection. At the same time, the paper also analyzed the computational complexity of the method.
By introducing multiple-optimal image binarization method before the feature point detection, it is ensured that the proposed detection method has better illumination invariance.
Experimental results prove that our method has significant advantages over the current state-of-the-art method in terms of the number of matching feature points and the stability of the repeatibility rate.
This paper is organized as follows. The second section introduces a multiple-optimal image binarization method. In the third section, we propose a novel feature point classification and detection method. The fourth section proposes a classification matching method based on the third section and theoretically analyzes the time consumption of different detection methods. The experimental results are given in the fifth section, and the conclusion is presented in the last section.
5. Experimental Results
In this section, we selected images with different illumination as experimental materials for feature point detection and matching. Some of these images are obtained by changing the exposure settings, and the others are captured at different time periods, such as morning and afternoon, daytime, and night. The experimental materials include indoor scenes, outdoor scenes, close-up, and long-distance scenes.
The comparison methods used in this paper include two types, which are feature-based and learning-based detection methods. Feature-based methods include Harris [
11], MinEigen [
34], SIFT [
12], SURF [
13], IRFET_Harris [
8], FAST [
35], ORB [
36], A-KAZE [
37], and Wu [
16]. In this section, unless otherwise specified, the Wu’s methods [
16] are all denoted as Wu. The learning-based methods select LIFT [
20], SuperPoint [
22], and LF-Net [
23]. The relevant parameters of the feature-based method all follow the parameters in the published paper, and the learning-based detection method uses the pre-trained model published by the author of the paper on github. The original setting number of keypoints in the LIFT and LF-Net pre-training models is small (LIFT is 1000 and LF-Net is 500), which seriously affects the fairness of the experimental result. In order to avoid the unfairness, we uniformly set the maximum number of keypoints in the pre-training model to a very large value to ensure that the most feature points can be detected.
We use several common feature detector evaluation indicators including the number of feature points, the number of matching points, and the repeatibility rate to evaluate the performance of the proposed method. Repeatibility rate is a key evaluation indicator, with various definitions, among which the definition of [
38] is widely used, and the expression is as follows:
where
is a pair of matching feature points,
is the distance between the pair of matching feature points, and the
is a homography matrix, used to transform point
in one image to another image.
5.1. Different Exposure Value
Figure 6 contains six groups of experimental materials with different exposure value. Each group of materials consists of two images of the same scene. The left image is overexposed, and the right image is underexposed.
The number of feature points is shown in
Figure 7. The left experimental result corresponds to the overexposed images in
Figure 6, and the right experimental result corresponds to the underexposed images. The number of matching points is shown in
Table 1. The repeatibility rate evaluation value based on Equation (
23) is shown in
Figure 8.
The number of feature points is one of the most important performance evaluation indicators for feature detectors.
Figure 7 indicates that our method can extract a large number of significant feature points from two images with large-photometric-variation. In most cases, our method can obtain the most feature points, and, in the remaining few experimental results, although the number of feature points extracted by the proposed method is not the most, it can still be guaranteed to be at the upper-middle level. In addition, ORB and LF-Net also show excellent performance in terms of the number of feature points extracted, sometimes even more than the proposed algorithm.
In addition, the number of matching points is another important evaluation indicator. In this article, we use the number of theoretical matching feature points and the actual number of matching feature points for algorithm evaluation. The calculation method of theoretical matching feature points is as follows. (1) First, extract feature points from underexposed images and overexposed images. (2) Secondly, the feature points in the overexposed image are transformed into the underexposed image through the homography matrix (since the scene is the same, the homography matrix here can be simplified to a unit matrix). (3) Finally, check whether there is a feature point at the corresponding position of the underexposed image. If it exists, we consider this pair of feature points as theoretical matching feature points.
Table 1 shows the number of theoretical matching feature points. The experimental result is obtained by Equation (
23).
In the first four groups of experimental results, the proposed method has obvious advantages. The number of matching points is several to several tens of times that of other detection methods. In the last two groups of experiments results, the proposed method is equivalent to LF-Net algorithm.
LF-Net shows very good performance in the matching experiment of large-photometric-variation, which is only slightly inferior to the proposed method; LIFT and A-KAZE are inferior to the former, but they perform well in terms of the number of matching points and matching stability; ORB and Wu can obtain a large number of matching feature points under certain scenes and illumination conditions, but their performance is not stable enough. In addition, Harris, FAST, and SURF perform extremely poorly under large-photometric-variation, and sometimes even a pair of matching points cannot be obtained.
In addition to the number of feature points and matching points, the repeatibility rate is also a commonly used evaluation indicator. It intuitively reflects the proportion of matching feature points in the extracted feature points and is used to characterize the availability and repeatibility of the feature points extracted by the feature detector. The repeatibility rate is shown in
Figure 8.
Figure 8 shows that the repeatibility rate of the proposed method is not the highest in most cases, but it is the most stable, basically around 30%, with a small fluctuation range of 20% to 40%. On the contrary, the repeatability rate of other methods fluctuates greatly. For example, Wu’s method has a repeatibility rate of 60% at the highest and close to 0 at the lowest. The repeatibility rate of SuperPoint exceeds 40% at the highest and about 10% at the lowest. Combining
Figure 7 and
Figure 8 and
Table 1, we find that the proposed method can extract the most feature points and obtain the most matching feature points, while the repeatibility rate changes the most stable. Therefore, we believe that the proposed method has the best illumination robustness.
However, this is not enough because we also need to verify whether the matching points can indeed be used for feature point matching in the real environment. The calculation method of actual matching feature points is as follows. First, extract the feature points from the two images; then, calculate the descriptor for each extracted feature point; finally, select the appropriate matching algorithm for feature point matching and calculate the actual number of matching feature points.
Table 2 shows the actual number of matching points (the same descriptor and matching method were used in the previous period).
There is a certain deviation between the data in
Table 1 and
Table 2. However, the proposed method still obtains the most matching feature points in most cases. Although the actual number of matching feature points in the other two groups is not the most, it performs well in the same group of experiments. In addition, although LF-Net performance is not as good as the proposed method in terms of the matching points number of theoretical calculations, the experimental results of “CadikDesk” and “Memorial” have exceeded the proposed method in actual matching experiments. At the same time, the experimental results of “BigTree” and “WindowSeries” are very close to the proposed method, which indicate that LF-Net also has excellent illumination robustness. In addition to LF-Net, SuperPoint and LIFT also surpass most feature-based detection methods (except the proposed methods) in the actual feature points matching experiment.
In order to further verify the previous experimental results, we give the alignment and overlay images of different experimental groups, as shown in
Table 3.
The experimental results in
Table 3 indicate that the alignment based on Harris and FAST is the worst; LIFT, SuperPoint, LF-Net, and the proposed method perform best in the image alignment experiments, and all can achieve correct image alignment. “Belgium” and “Memorial” have the largest illumination differences, so most feature detectors fail in these two experiments. “SnowMan”, “CadikDesk”, and “BigTree” are relatively difficult, so most detectors can extract enough matching feature points and perform correct alignment. The alignment results in
Table 3 can well prove the previous experimental results.
5.2. Different Capture Time
When the camera settings and pose are fixed and only the capture time is different, a series of images with different illumination directions or intensities can be obtained, as shown in
Figure 9. The first and second rows correspond to the same scene, the capture time of the first row is in the morning, and the capture time of the second row is in the afternoon. Therefore, we collectively refer to the first two rows as Morning-Afternoon dataset. The third and fourth rows correspond to the same scene, the third row of images were captured during the daytime, and the fourth row was captured at night. We call the last two rows Daytime-Night dataset. From left to right, the first column is named Scene_1, the second column is named Scene_2, and so on.
We extracted the feature points of each pair of images in the Morning-Afternoon dataset and shown them in
Table 4 and
Table 5.
The images in the Morning-Afternoon dataset show different states in different areas due to the different directions of sunlight. The originally bright area may become darker, and the originally darker area may become brighter. This makes it more difficult to match the feature points of the image.
Compared with other methods, the ORB, Wu’s method, LIFT, LF-Net, and the proposed method can extract more feature points when the illumination in different areas of the same scene changes significantly. Further, we count the number of theoretical matching points, and the statistical results are shown in
Table 6.
The experimental results in
Table 6 indicate that the proposed method can still obtain the most matching feature points when the image illumination direction changes. However, the situation reflected by Scence_3 cannot be ignored. When the light-dark area is completely reversed, the proposed method may not work well. In addition, ORB, Wu’s method, and LF-Net can also theoretically extract many matching feature points.
The number of theoretical matching feature points is obtained by Equation (
23), which does not consider feature descriptors and matching methods, so interference caused by algorithm compatibility can be eliminated. However, the number of theoretical matching points is extremely dependent on the control accuracy of the camera pose during the image capture process. Therefore, in addition to counting the number of theoretical matching points, we also need to further examine the actual number of matching feature points, and comprehensively consider the two to ensure the credibility of the result. The actual number of matching feature points is shown in
Table 7 (the same descriptor and matching method were used in the previous period).
In the 8 groups of experiments, 5 groups of proposed methods obtained the most matching feature points, and the other two groups ranked second, and the result of one group was poor (Scene_3). LF-Net followed closely behind.
When the illumination direction changes, Wu’s method, LIFT, LF-Net, and the proposed method can perform well in terms of the number of feature points and the number of matching points. In addition to considering the change of illumination direction, we also further consider the change of illumination intensity, as shown in the Daytime-Night dataset in
Figure 9.
The illumination intensity of the two images in the Daytime-Night dataset is very different, so it is more difficult to use feature detection methods to extract feature points from low-illuminance images and match them with other images. The number of feature points extracted by different feature detection methods from the Daytime-Night dataset is shown in
Table 8 and
Table 9.
The images in
Table 8 are captured during the daytime, so all detection methods can extract enough feature points. The images in
Table 9 are different. Because it is captured after the sun sets, the illumination is very poor, so the difficulty of extracting feature points is greatly increased. However, there are also some detection methods that can extract feature points from low-illumination images, such as Wu’s method, LIFT, SuperPoint, LF-Net, and the proposed method. Further, we conducted statistics on the number of theoretical matching points and obtained the experimental results shown in
Table 10.
Similarly, only Wu’s method, LIFT, SuperPoint, LF-Net, and the proposed method can obtain better matching results. The matching points of the proposed method is much higher than other methods, which indicates that the proposed method has the potential to obtain the most matching points under low illumination. In addition, the statistical results of actual matching points are shown in
Table 11.
The actual matching point statistics indicate that the proposed method can still obtain the most matching feature points, but the advantages are reduced compared to
Table 10. For example, the actual matching feature points of the proposed methods in Scene_5 and Scene_7 are very close to LF-Net. In addition, the feature points extracted by LF-Net have obvious performance advantages in the actual matching process, far exceeding other algorithms, followed by Wu’s method, SuperPoint and LIFT detection methods.
Through the analysis of the experimental results of the day-night dataset, it is found that, except for the methods of IRFET_Harris and Wu, other feature-based detection methods are difficult to extract enough feature points for matching. In contrast, learning-based methods have good phenotypes in terms of the number of feature points and the number of matching points, especially LF-Net, which has excellent illumination robustness. However, our proposed method surpasses LF-Net in all performance evaluation indicators. Furthermore, through analysis of the number of theoretical matching points and actual matching points, it is found that, due to the limitation of feature description and matching methods, many feature points cannot be matched correctly.
6. Discussion
This paper focuses on the illumination robustness of feature detection methods. In order to make the results more convincing, we used three types of data sets with different exposure values, different light directions, and different light intensities. For each data set, the proposed method and the other twelve feature detection methods are used for feature detection, extraction, and matching. Finally, the number of feature points and the number of matching points is used as evaluation indicators.
The experimental results of the three data sets are generally consistent, but due to the characteristics of the data sets themselves, the experimental results also have some differences in some details. In datasets with different exposure values, in addition to Wu, LIFT, SuperPoint, LF-Net, and the proposed method, the experimental results of other methods are not good. The reason is that the two images contained in each pair of experimental materials are underexposed images and overexposed images, respectively. Wu and the proposed method use multi-optimal image binarization to resist this large photometric variation. The other three groups of learning-based methods may have considered large photometric variation during the training process.
In the experiment where the illumination direction changes, most detection methods can extract enough feature points, which indicates that the change of the illumination direction has little effect on the detection method.
The last data set contains two images with different light intensities. Images captured during the daytime can extract enough feature points, while images captured at night have two extremes when extracting feature points. Some methods, including the proposed method and three learning-based methods, can still extract feature points equivalent to those during the daytime, but other methods cannot detect feature points at all. By comparing and analyzing the experimental results of the three data sets, we can conclude that the proposed method has the best illumination robustness.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














