1. Introduction
Human–computer interaction (HCI) [
1,
2,
3] is a new research hotspot. In the past, HCI methods were mostly limited to hardware devices, such as touch screens, keyboards, etc. With the continuous development of HCI systems, many promising solutions have emerged. The in-air handwriting system based on inertial sensors introduced in this work is one of them. In-air handwriting means writing characters or words freely in 3D space, which is a smarter way of HCI. In recent years, with the development of MEMS (micro-electro-mechanical systems), smartphones and wearable devices with built-in inertial sensors have become more and more popular. Therefore, in-air handwriting systems based on inertial sensors have attracted wide attention from many researchers.
In the field of in-air handwriting, most of the previous works focused on character-level in-air handwriting recognition (char.-IAHR) [
4,
5]. Few studies involve word-level in-air handwriting recognition (word-IAHR). There is a big difference between char-IAHR and word-IAHR. Char-IAHR is a classification task based on a single character. Usually, this is a relatively simple task and does not require much training data. Using thousands of samples, the char-IAHR model can usually achieve good generalization performance [
6,
7,
8]. Unlike char-IAHR, word-IAHR not only needs to consider the characteristics of the current character, but also the influence of the characters before and after it. In other words, the word-IAHR model not only learns to classify characters, but also learns the combinations of characters. It is a more complicated task and usually requires a large amount of training data. In practice, for in-air handwriting system, outputting words has broader application prospects than outputting single characters. Therefore, the research on word-level in-air handwriting is more meaningful.
However, the word-IAHR task faces two difficulties. Firstly, the training of deep neural networks usually requires a particularly large data set. Adequate data collection is a solution, but it will take a lot of time and money. Furthermore, it is difficult to collect a well-distributed dataset. Secondly, a deep recognition network trained on a small data set can hardly recognize samples whose labels do not appear in the training set. In the word-IAHR task, the classification of the current character depends not only on its own characteristics, but also on characteristics of contextual characters. The recognition model is likely to fail to give the correct answer if the combination of characters is fresh to the model. Therefore, it is really important to introduce the corpus in the training process. For example, we use the dataset “economics” to represent a dataset whose vocabulary belongs to the field of economics. Generally, if training is performed on the dataset “medicine”, the recognition model will perform poorly on the dataset “economics”. This is because there are many professional words in the field of economics, and their character combinations are very rare in the field of medicine.
Therefore, it is of practical significance to apply a method to synthesize realistic word-level in-air handwritten samples. This will greatly solve the problem of insufficient data in the word-IAHR task.
In this work, we propose a novel synthesis method for in-air handwritten words, named the “air-writing word synthesizer”.
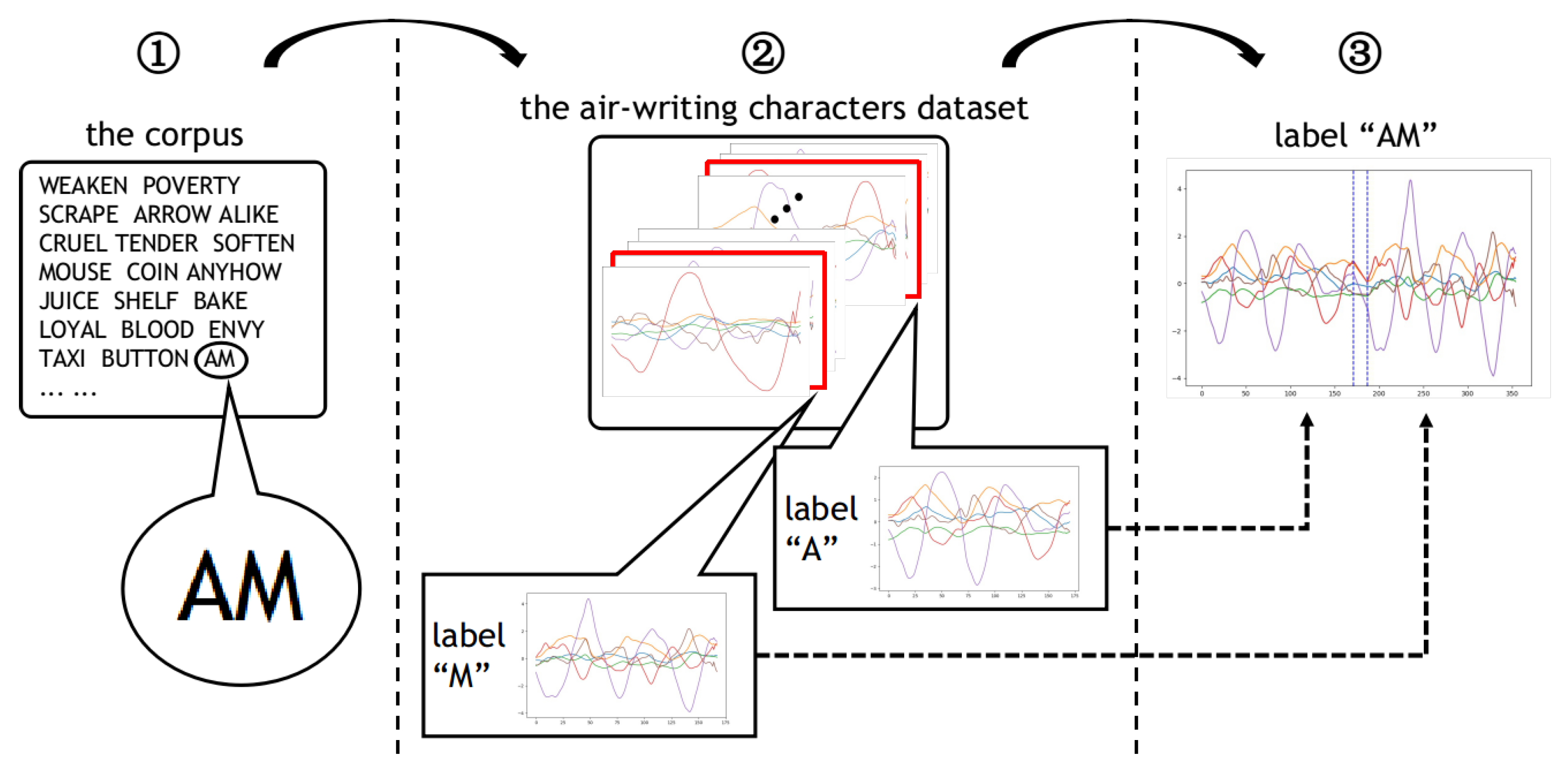
Figure 1 shows the pipeline of the air-writing word synthesizer. When the word synthesizer is well trained, the output of the generating module will be used to train a word-IAHR network.
The air-writing word synthesizer consists of two modules, namely the splicing module and the generating module. (1) The splicing module splices the character samples according to the corpus to get the spliced samples. Note that the corpus is a collection of words, which can provide a rich combination of characters for the proposed method. The splicing module is not trainable. It consists of a series of steps. The specific splicing steps will be introduced in
Section 3.2. (2) The generating module takes in the spliced samples and generates realistic word samples. We regard the conversion from the spliced samples to realistic word samples as a domain-transferring task. The generating module is actually a generator in a generative adversarial network (GAN). This is a trainable network that is trained by adversarial learning. In order to enable the network to process time series, we redesigned the network structure and loss function. The details of the generating module, including training details, network architecture, etc., will be introduced in
Section 3.3.
The air-writing word synthesizer proposed in this paper mainly includes the following characteristics:
The air-writing word synthesizer is a two-stage synthesis method. It creatively combines the splicing module and the generating module to achieve the best performance. Due to its unique design, the air-writing word synthesizer can synthesize a large number of realistic word samples based on limited character samples and word samples.
The splicing module introduces an additional word set, namely the corpus. The splicing module synthesizes word samples by splicing character samples according to words in the corpus. In our design, the corpus provides important guidance for the combination of characters.
To make the spliced samples more real, adversarial learning is adopted in the training process of the generating module. In order to process word samples of arbitrary length, we use a fully convolutional U-Net [
9] generator and a Markovian discriminator [
10]. This design also makes our model pay more attention to the details of the generated samples.
In the training process of the generating module, the distance loss is adopted to maintain semantic consistency.
In particular, we design a word recognition model to verify the effectiveness of the air-writing word synthesizer on a public dataset. Experiments show that the recognition model trained on synthetic data performs well on samples with fresh labels. To a certain extent, the proposed method solves the problem of insufficient data of in-air handwritten words.
We propose a novel and promising GAN-based synthesis method for in-air handwritten words. We believe that this work will provide some new inspiration for other researchers.
3. Methodology
We propose a novel two-stage synthesis method for in-air handwritten words. The proposed method can synthesize realistic samples under the condition of limited in-air handwritten character samples and word samples. The synthesis method proposed contains two modules. (1) Splicing module: The splicing module splices the air-written characters according to the order of characters in the specified word that comes from the corpus. The splicing module is not trainable. It consists of a couple of steps, which will be introduced in
Section 3.2. (2) Generating module: The generating module takes the output of the splicing module as input and outputs the generated samples. A well-trained generating module generates realistic word samples, which could be used to train a recognition network. The details of the generating module will be introduced in
Section 3.3.
For the convenience of the following description, we refer to the output samples of the splicing module as spliced samples and the output samples of the generating module as generated samples. The domain of spliced samples is called the spliced domain, and the domain of the real word samples is called the real word domain. The generating module mentioned above is actually a generator in a GAN. It takes in spliced samples and outputs realistic word samples. In other words, it learns the mapping from the spliced domain to the real word domain through adversarial training.
3.1. Motivations
The task of recognizing air-written words is similar to scene text recognition. In scene text recognition, a recognition network with good generalization performance not only learns to recognize a single character, but also learns a combination of characters (also called corpus information). Therefore, in the air-writing word synthesizer, we introduce a word set as a corpus to guide the splicing of character samples. The corpus can ensure that the synthetic dataset contains a variety of character combinations. Since the spliced samples are not realistic enough at the junctions, it is necessary to use adversarial training to modify the junctions of the spliced samples.
What the generating module does is somewhat similar to unsupervised image-to-image translation. However, when dealing with time series data, there are still several challenges to be solved.
Lack of paired training data: Usually, paired samples can provide a good guide for the model. However, in this synthesis task, a pairwise database requires the collector to record the start and end points of each character in the word while writing the words in the air. This is nearly impossible in practice. To solve this problem, cycle consistency is adopted.
Handling time series data. The in-air handwritten word samples based on inertial sensors are six-dimensional time series data. Due to the difference in the writing speed and the number of characters of different words, the duration of different word samples varies greatly. Interpolation or padding is usually used to normalize the length of time series data. However, when the duration varies greatly, interpolation or padding is not the best choice. In our work, we adopt U-Net as the backbone of the generator and a Markovian discriminator [
10] as the discriminator of our proposed network to solve the above problem.
3.2. Splicing Module
The splicing module produces spliced samples through the process shown in
Figure 3. In the splicing process, an air-writing character dataset and a word set (also called corpus) are needed. A word set is a collection of words. It can be a “.txt” file with many words in it. Through the splicing module, we can get a less real spliced sample.
The pipeline of the splicing module can be divided into three steps, as shown in
Figure 3. For example, first, we randomly select the word “AM” from the corpus. Then, since “AM” is composed of “A” and “M”, an inertial sample labeled “A” and an inertial sample labeled “M” are randomly selected from the character dataset. Finally, we stitch the two character samples together but leave a gap between them, and then fill the gap using linear interpolation. In our experimental setting, we set the length of the gap to 20.
3.3. Generating Module
The generating module is actually a generator of the GAN. In order to better train the generating module, we specially designed an adversarial network, as shown in
Figure 4. Note that the generating module in
Figure 1 refers to generator
.
As shown in
Figure 4, the network we designed consists of two generators (
and
) and two discriminators (
and
). Let
S and
R denote the spliced domain and the real word domain, respectively.
is used to learn the mapping from
S domain to
R domain, and
is used to learn the mapping from
R domain to
S domain.
and
represent the discriminators of
S domain and
R domain, respectively. They are used to distinguish whether the input sample is real or fake.
For the conversion from S domain to R domain, given a labeled spliced sample , maps into , which means the sample is translated into R domain. is shared by two parts. Firstly, uses it to produce a reconstructed sample . Secondly, the discriminator uses it to distinguish whether the sample is real. The conversion from R domain to S domain is similar to the above conversion.
3.3.1. Architecture Details
We assign a generator and a discriminator to each domain.
Figure 4 illustrates the architecture of generators and discriminators. In our design, the two generators
and
adopt the U-Net as the backbone. Each generator consists of a contracting path for capturing context and a symmetric expanding path for generating samples. Among them, the contracting path contains eight convolutional layers and the expanding path contains eight de-convolutional layers. As shown in
Figure 4, the input of each de-convolutional layer is a feature map that concatenates the output of the previous layer with the feature map of the same size in the contracting path. Both generators are fully convolutional networks, which are very suitable for handling variable-length input samples.
In
Figure 4, the two discriminators
and
are Markovian discriminators. Each discriminator consists of five convolutional layers. The first four convolutional layers are used to downsample the input samples. The last convolutional layer compresses feature maps with multiple channels into feature maps with one channel. The average value of the last feature map is output as the final score. There are two reasons for using the Markovian discriminator. Firstly, the length of the air-writing word samples varies greatly. In this case, padding or interpolation performs badly in the GAN. A fully convolutional network can solve this problem well. Secondly, since the splicing samples are not real enough at the junctions, we hope that the GAN model can pay more attention to the details of the generated samples. In the last feature map output by the Markovian discriminator, each point corresponds to a patch in the input sample. The Markovian discriminator tries to classify whether each patch is real or fake. In other words, the Markovian discriminator pays more attention to the details of the generated samples.
In addition, we have modified the structure of these models to handle time series input. We also adopt a strip-shaped convolutional kernel in all convolutional and de-convolutional layers. The kernel size of each layer in the generators and discriminators is .
In the last feature map output by the discriminator, each point corresponds to a patch of length 33 in the input sample. Therefore, in the splicing module, the gap between the two samples should not exceed the size of the discriminator’s receptive field. In the experimental setting, we set the length of the gap to 20.
3.3.2. Loss Functions
In this section, we will only introduce the loss functions in the conversion from S domain to R domain. The conversion from R domain to S domain uses similar loss functions. Since the training of the generating module is based on the GAN, we introduce the loss functions of the discriminator and the generator.
The loss function of the discriminator is as follows.
where
is the adversarial loss of the discriminator.
The loss function of the generator is mainly composed of three parts. In our attempt,
and
perform best.
where
is the adversarial loss of generator,
is the cycle loss, and
is the distance loss.
(1) Adversarial loss: The (generating module) learns a mapping from S domain to R domain by adversarial training. Unlike the original GAN, this proposed model uses a fully convolutional Markovian discriminator. As mentioned above, the Markovian discriminator tries to classify if each patch is real or fake across input samples and averages all responses to provide its final output.
The adversarial loss we used is as follows:
where
denotes real air-writing word samples,
denotes spliced air-writing word samples,
is the discriminator in the real word domain, and
is the generator that inputs spliced samples and outputs generated samples.
(2) Cycle consistency loss: The adversarial loss ensures that samples with the distribution of S are translated to samples with the distribution of R. However, there are many possible mappings. We apply cycle consistency loss to force the mapping from S to R to be the inverse process of the conversion from R to S, which reduces the number of admissible mappings. To a great extent, cycle consistency loss ensures stable training.
The following is the cycle consistency loss:
where
denotes spliced air-writing word samples,
is the generator that inputs spliced samples and outputs generated samples, and
is the generator that maps samples from
R domain to
S domain.
(3) Distance loss: To further maintain the semantic consistency between S domain and R domain, distance loss is adopted. The distance loss forces the distance between two samples in S domain to be preserved in the mapping to R domain.
The distance loss is as follows:
where
and
are spliced air-writing word samples, and
is the generator that inputs spliced samples and outputs generated samples.
3.3.3. Training Strategy
The air-writing word synthesizer is a two-stage synthesis strategy. Specifically, it includes a splicing module and a generating module. The splicing module is not trainable, while the generating module is end-to-end trainable. In this section, we introduce the specific training strategy of the generating module in detail.
Since the generating module is a part of the GAN, we adopt an alternate training strategy. We alternate between
k steps of optimizing the two discriminators and one step of optimizing the two generators. When training
and
, the parameters of
and
remain fixed. When training
and
, the parameters of
and
remain fixed. Note that we set
to keep the balance of adversarial training. With the ADAM [
30] optimization method, we set the learning rate to 2e-4 and batch size to 64. Finally, our model is trained on NVIDIA-1080Ti GPU, so it is GPU-accelerated.
4. Experiment
In this section, we aim to prove that the air-writing synthesizer can greatly improve the performance of the word recognition model. Therefore, we designed a word-IAHR model and conducted experiments on a public data set named 6DMG [
31].
4.1. Word-IAHR Model
The word-IAHR model contains five convolutional layers for downsampling and two layers of bidirectional LSTM (Long-Short Term Memory) [
32] for capturing long-distance information. Like the generating module in the air-writing word synthesizer, in order to better process the time series samples, we adopt a strip-shaped convolutional kernel in the convolutional layers. The kernel size of each layer is
. Finally, the model is trained by CTC loss. We use an ADAM optimizer to update the network with a learning rate of
and a batch size of 256.
Figure 5 illustrates the architecture of the word-IAHR model we used for experiments.
4.2. Dataset
The 6DMG dataset contains two subsets, namely the air-writing character dataset (char-6DMG) and the air-writing word dataset (word-6DMG). Both the character dataset and the word dataset are collected within a fixed range. A total of 25 volunteers participated in the collection of the dataset. Ten volunteers participated in the collection of both the char-6DMG dataset and the word-6DMG dataset, while the remaining 15 writers only participated in the char-6DMG dataset collection.
The char-6DMG is composed of 26 uppercase letter categories. It contains 6500 samples in total, with an average of 250 samples in each category. The number of samples in each category is approximately equal. In the char-6DMG dataset, most samples’ lengths vary between 100 and 200. The maximum length of a character sample is 297, and the minimum is 89.
Figure 6 shows some examples from the char-6DMG dataset. Samples of the same category or samples of different categories have different lengths.
The word-6DMG dataset contains 1230 samples in total, including 40 categories of words. The number of samples in each category is approximately equal.
Figure 7 shows some examples in the word-6DMG dataset. As shown in
Figure 7, the lengths of air-writing words vary greatly.
In the word-6DMG dataset, most samples’ lengths vary between 300 and 700. The number of characters in most word samples is usually between three and seven, but the longest word sample contains nine characters and is 1512 in length. The shortest word sample contains only two characters and is 145 in length.
Word set: Due to the particularity of our method, we use a word set (corpus). The word set is a text file consisting of 2000 common words. In our proposed method, the words in the word set are used as labels for synthetic samples. It is worth noting that the corpus we used in the training process does not contain the 40 words in the word-6DMG dataset.
Synthetic dataset: According to the method proposed in this work, if we suppose we want to synthesize a sample labeled “CAT”, we need to select the corresponding character samples from the char-6MDG dataset. Since each category in the char-6DMG dataset contains 250 samples, theoretically, in the synthetic dataset, there are a total of different samples in the “CAT” category. It is a very large dataset, which will bring challenges in terms of data storage and data reading.
Therefore, we use an online synthesis strategy instead of synthesizing the dataset in advance. The pipeline of the air-writing word synthesizer can be seen in
Figure 1. In the following part, the synthetic dataset refers to data synthesized by the proposed online synthesis method.
4.3. Dataset Pre-Processing
We apply a moving-average filter with a window length of 3 to filter out the noise in both the char-6DMG dataset and the word-6DMG dataset. For samples whose length exceeds 700 in the word-6DMG dataset and synthetic dataset, we resize their length to 700.
4.4. Experiments and Results
In order to demonstrate the superiority of our method, we conduct the following experiments under two principles. One is user-independent, which means that users in the test data will never appear in the training data. The other is user-mixed, which means that when the dataset is divided into folds, each fold is composed of samples recorded by each user.
4.4.1. Experiments on the Word-6DMG Dataset
In scene text recognition, a well-performed recognition network usually requires millions of samples for training. A recognition model can learn more corpus information from a larger dataset. Therefore, we design the following four experiments to verify whether a large dataset is necessary in the word-IAHR task.
Non-cross-label experiments: As shown in the first two rows of
Table 1, we take 80% of the word samples in 6DMG as the training set and the rest as the test set. When dividing the dataset, it is necessary to ensure that samples of the same categories can only appear in the same set and the labels of the training set cover all 26 capital letters. So, we call these non-cross-label experiments. For example, all samples labeled “AM” can only appear in either the training set or test set. That is, we take 32 categories out of 40 as the training set and the remaining eight categories as the test set. The training set contains 984 samples, and the test set contains 246 samples.
Cross-label experiments: The last two rows of
Table 1 show the settings of the cross-label experiments. We take 80% of the word samples in 6DMG as the training set and the rest as the test set. When dividing the dataset, we make sure both the training set and test set contain all 40 categories.
We report the results of these four experiments in
Table 2. Whether it is user-independent or user-mixed, the accuracy of the non-cross-label experiment is close to 0.0%. For cross-label experiments, under user-mixed principle, the word-level accuracy is 98.8%. Under the user-independent principle, the word-level accuracy is 88.1%.
Based on the experimental results, we can draw the following conclusions.
A word-IAHR model trained on a small dataset performs badly. It is almost impossible to identify samples that do not appear in the training set even if the labels of the training set have covered all 26 capital letters. A word-IAHR model with good generalization performance requires a large amount of data for training.
Even trained on such a small dataset, the model can still recognize samples whose labels have already appeared in the training set, regardless of whether it follows the principle of being user-mixed or user-independent. This is because samples of the same word category have similar features.
4.4.2. Quality Testing
According to the results in
Table 2, we can know that a recognition model can easily recognize a sample whose label is the same as that of the training sample.
In this section, we want to verify the quality of the synthetic dataset. Based on the experimental results of
Table 2, we can infer that synthetic samples can be considered to be of high quality if they are correctly recognized by the word-IAHR model.
In terms of the synthetic dataset used in this section, we use the labels of the word-6DMG dataset (40 words) as a corpus to synthesize a dataset. We refer to this synthetic dataset as the “synthetic dataset of 40 words”. It includes 40 categories and 1230 samples.
As shown in
Table 3, we conducted quality testing based on the user-mixed and user-independent principles. For comparison, the well-trained models (rows 3 and 4 of
Table 2) are adopted. In the quality testing based on the user-mixed principle, the training set is the same as the training set used in the third row of
Table 1. In the quality testing based on the user-independent principle, the training set is the same as the training set used in the fourth row of
Table 1. We take the “synthetic dataset of 40 words” as the test set. It is of great significance that the “synthetic dataset of 40 words” shares a label space with the word-6DMG dataset.
We report the results in
Table 4. In the quality testing based on the user-mixed principle, the word-level recognition accuracy is 86.7%. In the quality testing based on the user-independent principle, the word-level recognition accuracy is 72.3%. Compared with the results in the last two rows of
Table 2, the accuracy is slightly lower, but this also shows that the synthetic samples are very similar to the real word samples. The results prove that synthetic samples are of high quality.
4.4.3. Verification of Generalization Performance
As shown in
Table 5, we design generalization performance experiments based on the user-mixed and user-independent principles to verify the effectiveness of the proposed method. We use the synthetic dataset as the training set and the word-6DMG dataset as the test set. It is of great significance that not every category in the training set can appear in the test set.
We report the results in
Table 6. In the experiment under the user-mixed principle, the word-level recognition accuracy is 62.3%. In the experiment under the user-independent principle, the recognition accuracy is 44.6%. Compared with the non-cross-label results (the first two rows in
Table 2), the deep model trained on the synthetic dataset improves performance by 62% and 44%, respectively. With the help of the air-writing word synthesizer, the recognition model can achieve an excellent performance improvement in samples whose labels are fresh to the model. These experimental results demonstrate the success of our method.
The air-writing word synthesizer can synthesize a large number of samples under the condition of limited character samples and word samples. In our design, we have greatly enriched the combination of characters by introducing a corpus. This makes the recognition model not only learn to recognize a single character, but also learn combinations of characters (also known as the corpus information of the dataset). Generally speaking, a word-IAHR model can benefit a lot from the corpus information of the dataset.
4.5. Discussion on the Splicing Module and Generating Module
The air-writing word synthesizer is a two-stage synthesis method. In this section, we intend to show the respective effects of the splicing module and the generating module.
In
Figure 8, we illustrate several word sample outputs of the splicing module and the generating module (i.e., “JEW”, “RUN”, “HULK”, and “READ”). For example, we take the word “JEW” as the target word. First, we pick character samples “J”, “E”, and “W” from the char-6DMG. Then, we splice them using the splicing module to obtain the spliced sample. Finally, the generating module takes in the spliced sample labeled “JEW” and outputs the synthetic sample.
In
Figure 8, the dashed box represents the junctions between the characters in the spliced word sample. The characters in the spliced samples are connected by linear interpolation. We can see that, after processing by the generating module, the junctions become more natural. We believe that adversarial training helps a lot.
The main disadvantage of our model is the dependence on datasets. Our method requires that the character dataset and word dataset used for training must be collected under the same rules. For example, the users must write within a fixed range while collecting data. If the two datasets are collected under different rules, the air-writing word synthesizer will not perform so well. In addition, using linear interpolation to splice characters may not be the optimal solution. In the future, we will try to model the strokes between characters mathematically. In this way, we can figure out a better solution for splicing characters. In addition, we will try to apply the method to various datasets. For example, we can improve our method so that it can be used even if the data collection rules are different.
4.6. Evaluation of Computational Efficiency
In this section, we evaluate the computational efficiency of our proposed method. Note that the air-writing word synthesizer is a synthesis method that works in the training phase. This synthesis method can greatly improve the generalization performance of the recognition model, but it will not slow down the inference process.
In
Table 7, we report the computational efficiency of our proposed method. The “synthesis (per sample)” refers to the average time taken to synthesize one sample by the air-writing word synthesizer. The “recognition (per sample)” refers to the average time taken to recognize one sample. We argue that our approach is conducive to devices with limited computing resources and has a wide range of application scenarios.
5. Conclusions
In-air handwritten word recognition usually suffers from insufficient data. In this work, we propose a new two-stage synthesis method (named the air-writing word synthesizer) for in-air handwritten words to solve this problem. The proposed method includes two components: a splicing module and a generating module. In the splicing module, a corpus is introduced to provide guidance for word splicing. In the generating module, adversarial learning is introduced to guide word synthesis. In addition, the network architecture is carefully designed to handle time series.
Experiments on public datasets show that the proposed method can synthesize samples of high quality. Most air-writing recognition tasks can benefit from the air-writing word synthesizer.
The main disadvantage of our model is its dependence on datasets. Our method requires that the character dataset and the word dataset used for training are collected under the same rules. For example, the users must write within a fixed range while collecting. If the two datasets are collected under different rules, the air-writing word synthesizer will not perform so well. In addition, linear interpolation is adopted to splice characters, which may not be the optimal solution.
In the future, we will try to mathematically model the strokes between characters in a word. In this way, we may figure out a better plan for splicing characters. In addition, we will try to apply the method to multiple datasets. For example, we can improve our method so that it can be used even if the data collection rules are different.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}