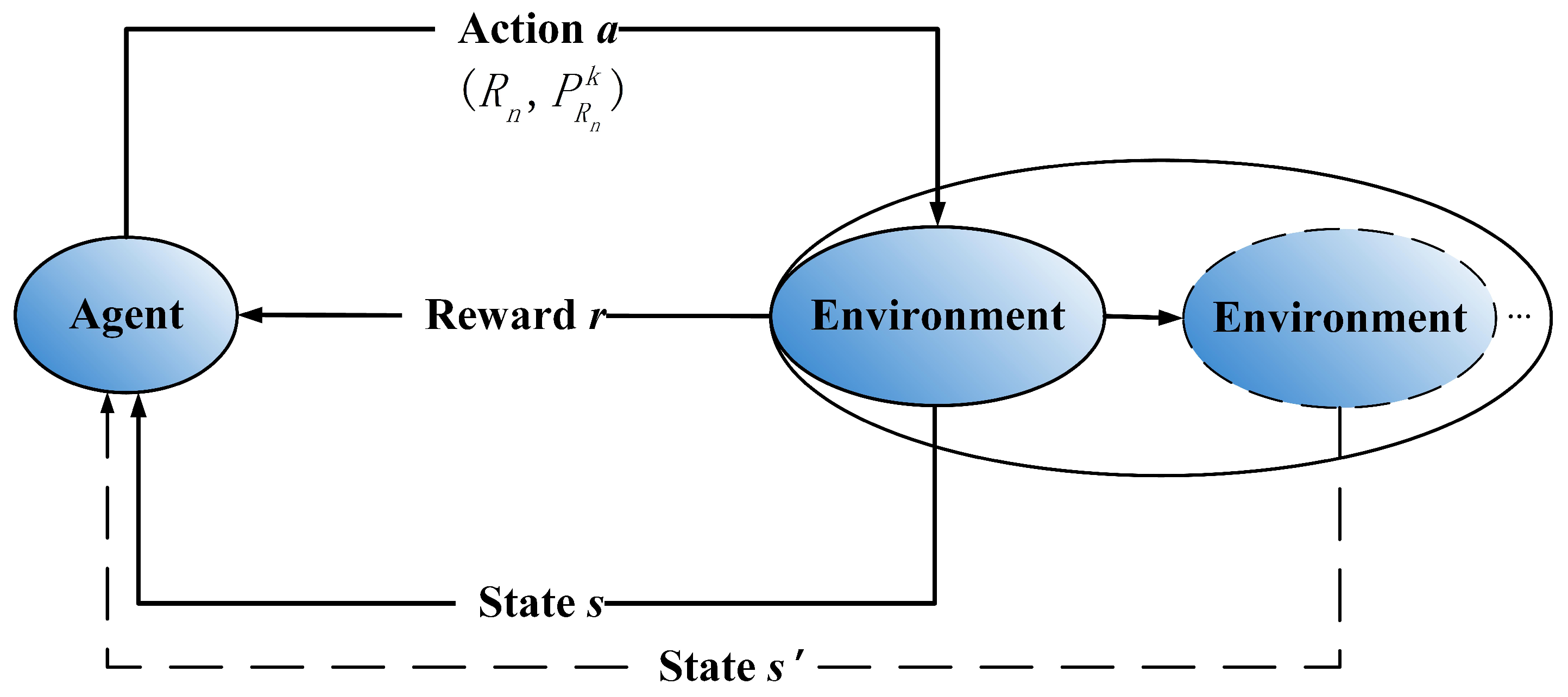
4.2. Results and Analysis
In this section, we compare the performance of the proposed JADQ-EH algorithm with other three algorithms: (i) Greedy optimal joint resources allocation (GOA) algorithm which assumes the perfect channel information is known. It is worth noting that the GOA algorithm calculates the corresponding network capacity of all links with the premise of no outages. And it selects the link which can maximize its capacity as the optimal strategy; (ii) Random algorithm; (iii) the basic Q-learning algorithm. To verify the effectiveness of the proposed algorithm, we evaluate the performance in terms of ; the number of outages in a working period ; the average working lifetime and the remaining battery at the end of every working period .
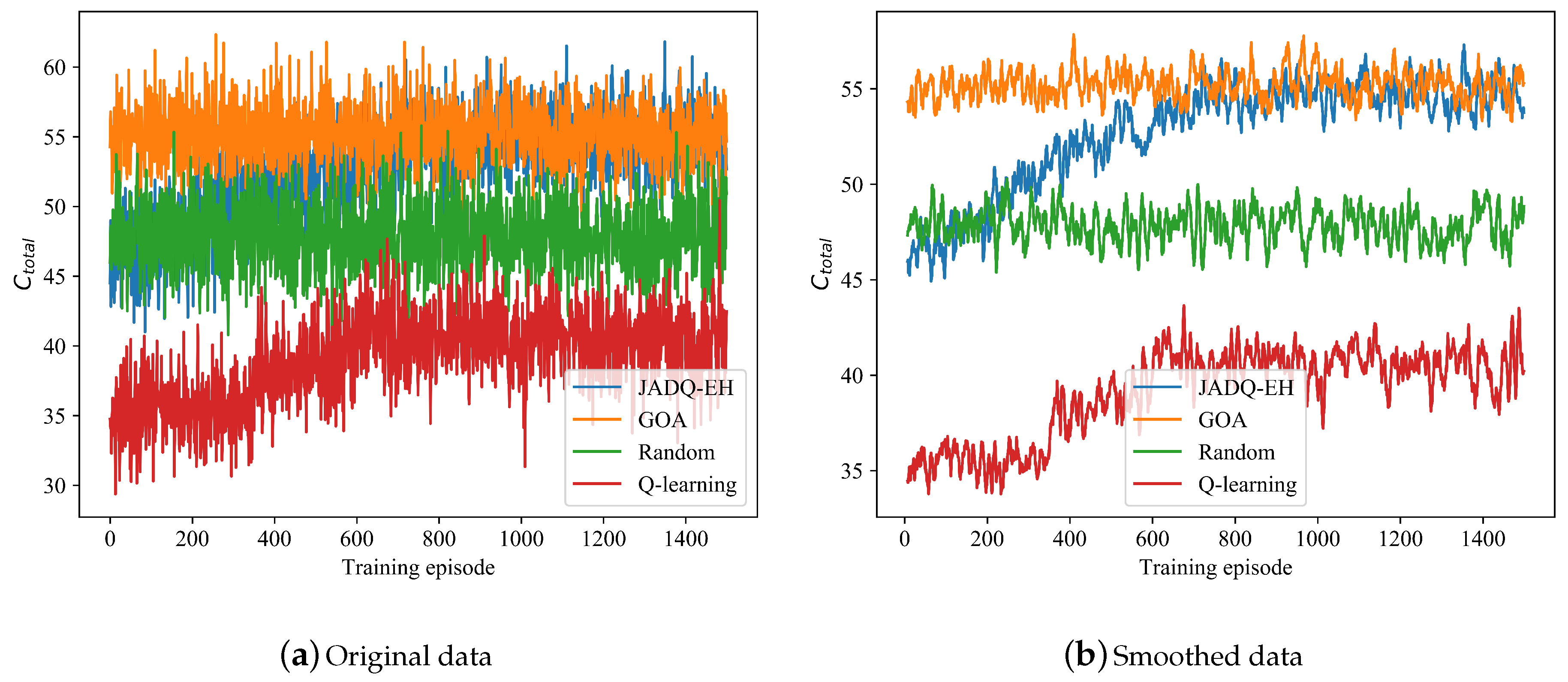
Figure 5 shows the
optimization processes of JADQ-EH algorithm and other algorithms under scenario 1. Given that the curves are too dense based on original data in
Figure 5a, the curves are smoothly processed to show the trend more clearly in
Figure 5b. It is worth noting that the smoothed data is the average value of a rolling window which consists of 8 original data. First, based on
Figure 5, the analysis of comparison between JADQ-EH algorithm and GOA algorithm are shown as follows. In initial training phase,
obtained by the GOA algorithm is superior that obtained by the proposed JADQ-EH algorithm. The main reason is because the GOA algorithm assumes the real-time perfect system information is known. In other words, at any moment in the entire process, GOA algorithm can obtain perfect channel information timely. Therefore, the GOA algorithm can achieve optimal joint relay selection and power allocation strategies. However, it is infeasible to obtain perfect real-time channel information in harsh underwater environment. With the continuous exploration and learning of the environment, the proposed JADQ-EH algorithm achieves the optimal performance (performance of GOA algorithm) without any prior channel information. Moreover, it is worth noting that the partial learning information of the proposed JADQ-EH algorithm is historical information which can be obtained easily. In addition, we set outdated channel information as a part of state, rather than any prior information about channel. These verify the reliability and rationality of the designed state expression and the learning ability of the proposed JADQ-EH algorithm in harsh underwater environment.
From
Figure 5, we can know that the proposed JADQ-EH algorithm absolutely outperforms the other algorithms. In
Figure 5, the performance obtained by JADQ-EH algorithm is almost the same as that obtained by Random algorithm, before about 200 episodes. This is mainly because that the agent randomly chooses actions to deepen environment exploration in initial training phase of the proposed JADQ-EH algorithm. However, the proposed JADQ-EH algorithm obviously outperforms the Random algorithm after 200 episodes. The learning ability of the proposed JADQ-EH algorithm is verified. In addition, the basic Q-learning algorithm shows the worst performance in the proposed joint optimization problem. The main reason is because the state space of the proposed problem is almost infinite. The agent can not explore all states with finite Q-table in basic Q-learning algorithm. Therefore, the agent falls into local optimal strategy under basic Q-learning algorithm. However, the proposed JADQ-EH algorithm utilizes RFc network to deal with infinite state space which overcomes the bottleneck of Q-learning algorithm. Simulation results verify the proposed effective state expression which reveals the environment characteristics can improve learning ability.
Figure 5 only shows the optimization process. In
Table 3, we further show the average cumulative capacity in a working period
comparison of different algorithms after convergence under scenario 1. It clearly shows that the proposed JADQ-EH algorithm has superior performance in the final convergence phase. The results in
Table 3 are consistent with the curves in
Figure 5. These further verify the above analysis and the superiority of the proposed JADQ-EH algorithm.
Different from scenario 1,
Figure 6 shows that the Q-learning algorithm does not achieve convergence under scenario 2. The main reason is because the state space is quite large and complex under scenario 2 which has more candidate relay nodes and stronger randomness. Given that the Q-learning algorithm cannot tackle large state space, the Q-learning algorithm does not learn optimization strategy knowledge under scenario 2. With the continuous exploration and learning of the environment,
achieved by the proposed JADQ-EH algorithm is close to that achieved by the GOA algorithm. The features of
under scenario 2 are similar to these of
Figure 5 under scenario 1. Given that the reasons of the features have been shown in the analysis of scenario 1, we do not repeat it here.
Table 4 shows that
achieved by the proposed JADQ-EH algorithm is superior to these achieved by Random algorithm and Q-learning algorithm under scenario 2. Although the capacity achieved by JADQ-EH algorithm show a little superiority in
Table 4, the cumulative services (outage, working lifetime) achieved by JADQ-EH algorithm absolutely outperform other algorithms. The other algorithms only consider the instantaneous capacity and ignore the long-term QoS. Outages which are caused by energy exhaustion easily appear under other algorithms. The outage performance and working life are sacrificed. However, the proposed JADQ-EH algorithm jointly consider the instantaneous capacity and the efficient utilization of energy. The proposed JADQ-EH algorithm not only maximizes capacity but also minimizes number of outages. The following simulation results about
and
can verify the above analysis.
The QoS is not only affected by capacity but also outage. When the battery of relay nodes can not afford the allocated transmitting power, an outage will happen on corresponding communication link. In a working period, too many outages will cause the severe degradation.
Figure 7 shows
comparison of different algorithms under scenario 1. Given that the GOA algorithm selects an action under the condition of no outages,
= 0 in the whole process. In
Figure 7, with the learning time increasing,
achieved by proposed JADQ-EH algorithm is declining. The performance obtained by the proposed JADQ-EH algorithm is almost the same as that obtained by GOA algorithm after 800 episodes. The main reason is because the proposed reward function can comprehensively balance the energy utilization and optimization objective to improve QoS. If the links generate outages, the agent will obtain a big penalty. Therefore, the agent will try to avoid outages with the guidance of the proposed reward function in the process of learning. In addition, the proposed JADQ-EH algorithm absolutely outperforms the other algorithms. The main reason is because the agent can obtain more training samples to explore and learn the dynamic EH-UASNs to improve QoS as the training episodes increase. The Random algorithm always makes decisions randomly. Therefore, the
achieved by Random algorithm has no obvious change. Given that the Q-learning is not applicable for large state space, it shows the worst performance in EH-UASNs.
Figure 7 shows that the starting points of the four resource allocation algorithms are inconsistent. The main reasons are that the proposed JADQ-EH algorithm collects the interactive experience first, and then optimize learning at the end of each working period. Therefore, the curve achieved by the JADQ-EH algorithm is similar to that of Random algorithm at the starting point. However, the learning mode of Q-learning algorithm is one-step update mode. The limited learning ability of Q-learning algorithm cannot support the agent to learn better strategy after several learning times. Therefore, the
of the Q-learning algorithm is higher at the starting point. Given that the GOA selects an action under the condition of no outages,
= 0 in the whole process.
Table 5 shows the average number of outages in a working period
comparison of different algorithms after convergence under scenario 1. It clearly shows that
achieved by the proposed JADQ-EH algorithm is close to 0. These verify the advantages of the proposed JADQ-EH algorithm in avoiding outages and improving QoS. Consequently, the proposed JADQ-EH algorithm shows the high applicability in dynamic unpredictable EH-UASNs.
Figure 8 shows the
optimization processes of JADQ-EH algorithm and other algorithms under scenario 2.
Table 6 shows the
comparison of different algorithms under scenario 2.
Figure 8 and
Table 6 show that the features of curves trend under scenario 2 are similar to that of scenario 1.
Figure 8 and
Table 6 clearly show that the proposed JADQ-EH algorithm absolutely outperforms the Random and Q-learning algorithms in minimizing
. The outage probability achieved by the JADQ-EH algorithm is only 0.07% under scenario 2. The
achieved by Random algorithm is 106 times that achieved by JADQ-EH algorithm. These further verify the universal applicability of the proposed JADQ-EH algorithm.
In order to verify the efficiency of proposed JADQ-EH algorithm further, the performance achieved by the proposed JADQ-EH algorithm is compared with that achieved by the JADQ algorithm which does not consider EH in reward function.
Figure 9 shows the
comparison between JADQ-EH algorithm and JADQ algorithm under scenario 1. The
Table 7 shows the
comparison between JADQ-EH algorithm and JADQ algorithm after convergence under scenario 1. In
Figure 9, convergence trend of
in JADQ algorithm is similar to that in JADQ-EH algorithm. However, numerous points where
increases sharply are shown on the curve of JADQ algorithm, while the JADQ-EH algorithm does not.
Table 7 shows that the
achieved by JADQ algorithm is 17.6 times that achieved by JADQ-EH algorithm after convergence. In the proposed JADQ-EH algorithm, the
is only 0.396. The main reason is because the proposed reward function in the JADQ-EH algorithm not only guarantees the optimization objective of maximizing capacity, but also considers energy utilization to reduce outages in dynamic and unknown EH-UASNs. The constructed reward function guides the agent to adequately utilize the harvested energy and charily to exploit the original battery by employing the adaptive power penalty item. The relay nodes can be prevented from overusing the battery and reserve a certain amount of battery to cope with the sudden service requests, thereby reducing
.
Figure 10 shows the
comparison between JADQ-EH algorithm and JADQ algorithm under scenario 1.
Table 8 shows the
comparison between JADQ-EH algorithm and JADQ algorithm after convergence under scenario 1. From
Figure 10, we can know that
obtained by the proposed JADQ-EH algorithm is superior to that obtained by JADQ algorithm.
Table 8 further verifies the result. In addition, numerous points where the
drops sharply can be observed on the curve of JADQ algorithm in the whole process. The main reason is because the JADQ algorithm only considers to meet the
and does not care remaining energy status. Therefore, the
and QoS achieved by the JADQ algorithm are degraded due to energy exhaustion. In
Table 7 and
Table 8,
achieved by JADQ is 17.6 times that achieved by JADQ-EH algorithm while
obtained by JADQ-EH algorithm is higher than that obtained by JADQ algorithm. It means that the proposed reward function can not only reduce outages but also improve
and QoS. Consequently, the proposed JADQ-EH algorithm has strong learning and optimization ability to deal with dynamic and complex EH-UASNs.
Figure 11a,b show the performance comparison between JADQ-EH algorithm and JADQ algorithm about
and
under scenario 2. The JADQ-EH and JADQ algorithms under scenario 2 show the similar convergent tendency about
and
to that under scenario 1, respectively. However,
Figure 11a shows that more points where
increases sharply are shown on the curve of JADQ algorithm under scenario 2 than the curve of scenario 1, while the JADQ-EH algorithm does not. Accordingly, the similar phenomenon occurs in
Figure 11b. This is mainly because that the energy condition and channel situation are more complex and unpredictable under scenario 2, thereby enlarging the state space strongly. The JADQ algorithm, which does not consider adaptive power penalty in reward function, is more difficult to tackle the complex and dynamic scenario 2. Therefore, the performance achieved by JADQ algorithm is severely degraded under scenario 2 than that under scenario 1.
Table 9 shows the performance comparison between JADQ-EH and JADQ about
and
under scenario 2. It clearly shows that the proposed JADQ-EH algorithm absolutely outperforms the JADQ algorithm.
Table 9 shows that
achieved by JADQ is 224 times that achieved by JADQ-EH. These verify the superiority of the proposed JADQ-EH algorithm under the scenario 2. The universal applicability of the proposed JADQ-EH algorithm is further verified.
We analyze the working lifetime of each relay node under scenarios 1 and 2. We define the time when the first outage occurs in each working period after algorithm convergence as the working lifetime J. We employ the average working lifetime to verify the universal applicability of the proposed JADQ-EH algorithm.
Table 10 shows that
of relay nodes under JADQ-EH algorithm absolutely outperform the other algorithms under any scenarios. Taking the
and
for example,
achieved by the proposed JADQ-EH algorithm can reach at least 83% of the working period. However,
achieved by Random and Q-learning are at most 15% and 7.6% of the working period, respectively. The superiority of the proposed JADQ-EH algorithm in improving the working lifetime is verified.
Based on the above analysis, we can know that and obtained by the proposed JADQ-EH algorithm are close to optimal performance (the performance achieved by GOA algorithm). In order to verify the superiority of the proposed JADQ-EH algorithm in improving long-term service capability, we evaluate the performance about remaining battery of relay node at the end of every working period under scenario 1.
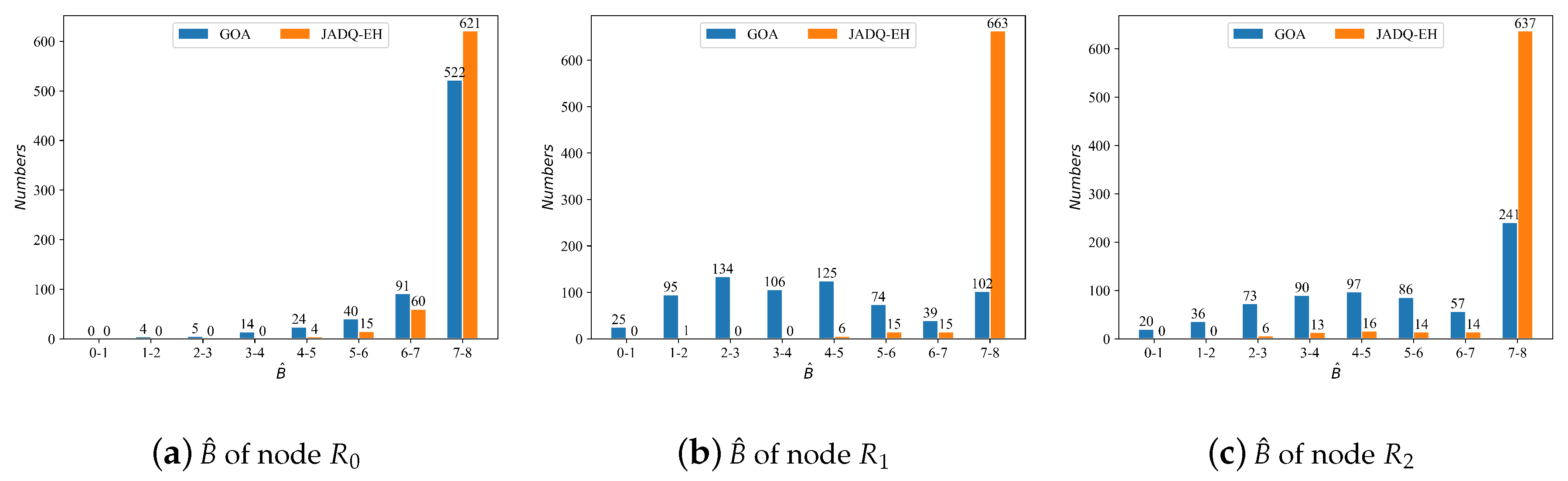
Figure 12 shows the
statistical information of each node using JADQ-EH algorithm and GOA algorithm under scenario 1. The x-axis and y-axis indicate different battery levels and the corresponding number of battery levels, respectively. The maximum battery capacity
of each relay node is 8 mJ.
Figure 12 shows that
of each relay node almost stay above 4 under the proposed JADQ-EH algorithm. It means that each node can retain at least half of
at the end of every working period. On the other words, each node can store enough energy to improve the long-term service capability. However, the
distribution of each node achieved by the GOA algorithm is relatively scattered. It means that number of battery levels which are at lower battery levels is more. Therefore, sudden service requests may not be served under GOA algorithm. Especially, the battery levels mainly concentrate in 7–8 mJ under the JADQ-EH algorithm. The relay nodes can tackle sudden and continuous requests with enough battery under the JADQ-EH algorithm. The main reason is because the proposed adaptive power penalty item guides the agent to adequately utilize the harvested energy and charily to exploit the original battery in the proposed JADQ-EH algorithm. The relay nodes can be prevented from overusing the battery and reserve as much battery as possible. The superiority of the proposed JADQ-EH algorithm in improving the long-term service capability is verified.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}