1. Introduction
Vehicle spatial distribution and 3D trajectory extraction is an important sub-task in the field of computer vision. With the development of intelligent transportation systems (ITS), a large amount of vehicle trajectory data reflecting movements is obtained through traffic surveillance videos, which can be used for traffic behavior analysis [
1,
2] such as speeding and lane change, traffic flow parameter (volume, density, etc.) calculation and prediction [
3,
4,
5] and so on. Based on these data, traffic state estimation [
6,
7] and traffic management and control [
8] can be conducted, which plays a key role in ensuring traffic efficiency and is of great research significance and practical value.
In current applications, trajectories mainly refer to two-dimensional trajectories in the image space, which do not contain spatial information of vehicles in the real world. Compared with 2D trajectories, 3D trajectories have one more dimension of spatial information, which has more obvious advantages in practical applications and can be further applied to traffic accident scene reconstruction and responsibility identification [
9], as well as vehicle path planning [
10] in autonomous driving and cooperative vehicle infrastructure system (CVIS) to avoid collision.
Currently, the most commonly used methods for obtaining 3D vehicle trajectories are based on object detection and feature point methods [
11,
12,
13], which have been maturely applied in single-camera scenes. With the development of deep convolutional neural networks (DCNNs), several excellent object detection networks [
14,
15,
16,
17,
18] have emerged, which greatly improve the accuracy and speed of object detection compared with the traditional feature extraction and classifier methods [
19]. Based on object detection, feature points are extracted for vehicles to obtain 3D trajectories in the world space combined with camera calibration. Although these methods have been widely and maturely used in single-camera scenes, the trajectory results are not accurate under the condition of low camera perspectives and vehicle occlusion. To solve the problem, 3D object detection is considered because only the presence, 2D location and rough type of vehicles in the image space can be obtained by 2D object detection method and it is difficult to achieve a fine-grained description of vehicles. Compared with 2D methods, perspective distortion can be eliminated by 3D object detection. Moreover, 3D bounding box fits the vehicle better and can describe vehicle size, pose, and other information on the physical scale. Therefore, 3D model is more suitable for 3D trajectory extraction in traffic scenes. At the same time, the visual angle of single-camera scene is usually narrow, which is unable to meet the needs of applications in wide range scenes, so it is necessary to solve the problem of 3D vehicle trajectory extraction in the whole space.
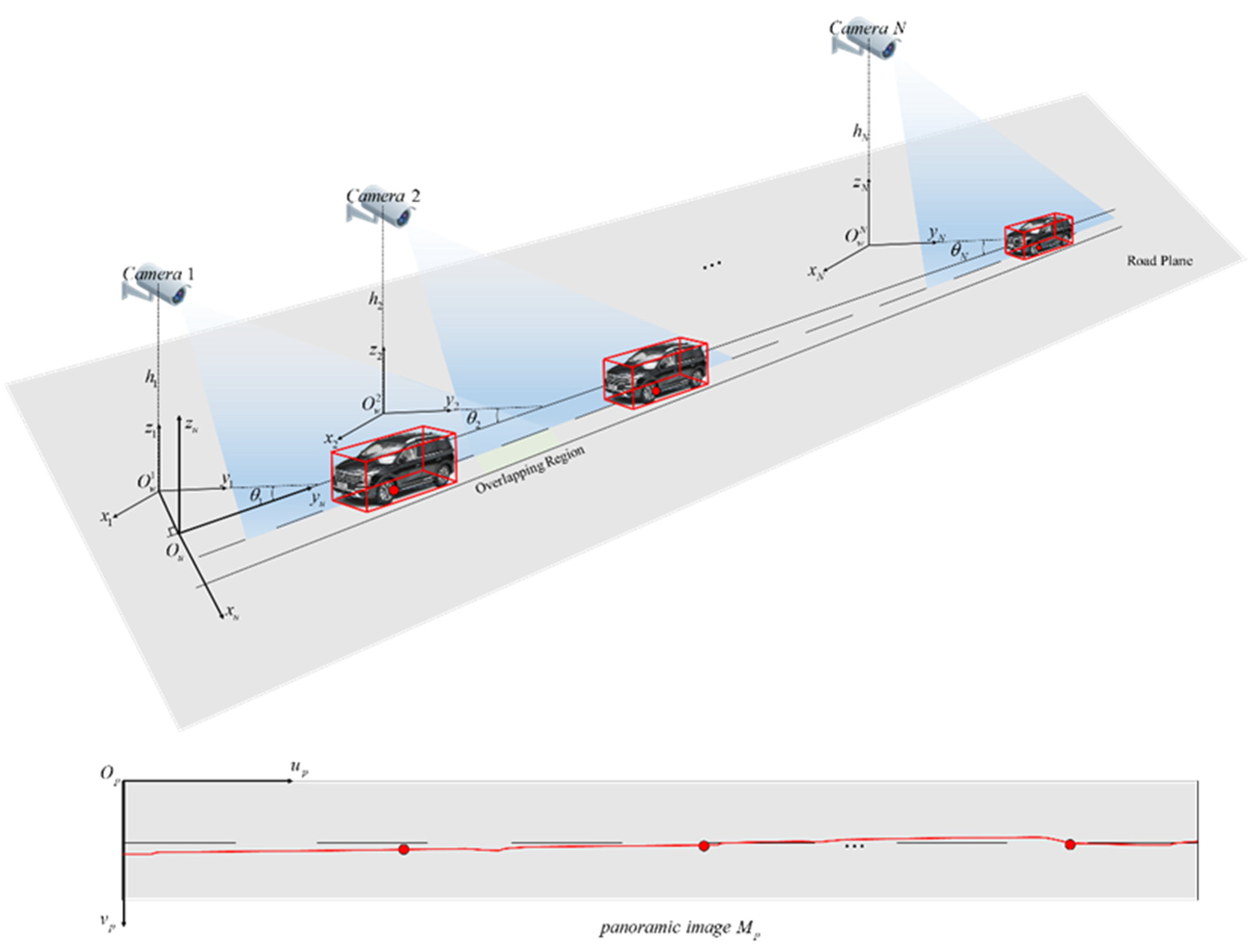
At present, full space fusion mainly relies on multi-scene stitching methods, which can be divided into two categories. (1) Image stitching based on image alignment [
20,
21]. The feature points of the overlapping areas in multiple images are detected and matched to construct homography matrixes between images. Then, the panoramic image is generated based on the matrixes. This kind of method is mature and widely used, especially in the panoramic photography of mobile phone applications [
22]. However, camera calibration is not used in these methods, which means physical information cannot be reflected in the panoramic image. (2) Image stitching based on camera calibration [
23,
24]. The transformation between world coordinate systems of the scenes are determined based on overlapping areas in the image and camera calibration to generate the panoramic image which contains actual physical information and can be used to measure and locate the world coordinates in the image. However, this kind of method requires complicated manual calibration of each camera, and has rarely been used in large scope of road measurement.
Methods of vehicle trajectory extraction in the whole space is cross-camera vehicle tracking, which means obtaining continuous vehicle trajectory from images taken by multiple cameras with or without overlapping areas. These methods usually contain three essential steps: camera calibration, vehicle detection, and tracking in single-camera scenes and cross-camera vehicle matching. For cameras with overlapping areas, the spatial correlation can be calculated by overlapping areas to obtain continuous trajectories. However, in practical applications, “blind areas” are often existed in images taken by multiple cameras. In case of this condition, methods of re-identification are used to accurately and efficiently match vehicles in different perspectives through vehicle apparent features. Then, continuous vehicle trajectories in the whole space can be obtained by space-time information inference.
Currently, re-identification methods used in cross-camera vehicle tracking are mostly based on vehicle features, such as vehicle color, shape, and texture, among which SIFT feature is the most commonly used due to its invariance to light, rotation, and scale. However, robustness of SIFT to affine transformation is low. To improve this problem, Hsu et al. [
25] proposed a method of cross-camera vehicle matching based on ASIFT feature and min-hash technique, which can overcome the influence of multi-camera perspectives to feature detection but cannot obtain 3D vehicle trajectory and solve the problem of vehicle occlusion. Castaneda et al. [
26] proposed a method of multi-camera detection and tracking of vehicles in non-overlapping tunnel scene, which uses optical flow and Kalman filter for vehicle tracking and state estimation in single scenes. Due to the special light environment in tunnel scene, vehicle color cannot be used as matching criterion. Thus, vertical and horizontal signatures are proposed to describe the similarity between vehicles. Combined with cross-camera vehicle travel time and lane position constraints, continuous vehicle trajectory can be obtained. To some extent, the problem of vehicle occlusion can be solved in this method, but the physical location of vehicle trajectory in 3D space is still not available. To further obtain vehicle trajectory in 3D space, multi-scene cameras should be calibrated in advance and the topological relationship between cameras should be determined to convert multi-camera perspectives into point sets in 3D coordinate system. Straw et al. [
27] proposed a method of cross-camera vehicle tracking which uses DLT and triangulation for camera calibration and Kalman filter for vehicle state estimation. Although continuous trajectory in 3D space could be obtained, the accuracy is low, which cannot meet practical applications. Peng et al. [
28] proposed a method of multi-camera vehicle detection and tracking in non-overlapping traffic surveillance, using convolutional neural network (CNN) for object detection and feature extraction and homography matrix for displaying vehicle trajectory to satellite map. This method can accurately show vehicle trajectory in panoramic map, but these trajectories do not contain physical location in 3D space. Byeon et al. [
29] proposed an online method of cross-camera vehicle positioning and tracking, which uses Tsai two-step calibration method for camera calibration and represents vehicle matching as multi-dimensional assignment to solve the problem of vehicle matching in multi-camera scenes. Vehicle trajectory can be obtained in this method, but the road panoramic image with spatial information is not generated. Qian et al. [
30] proposed a cross-camera vehicle tracking system for smart cities which uses object detection, segmentation, and multi-object tracking algorithms to extract vehicle trajectories in single-camera scenes. Then, a cross-camera multi-object tracking network is proposed to predict a matrix which measures the feature distance between trajectories in single-camera scenes. The system won the first place in AI City 2020 Challenge and can better solve the problem of vehicle matching in cross-camera scenes. However, continuous 3D trajectories of vehicles and the panoramic image of the scene cannot be obtained.
In view of the problems existing in current cross-camera vehicle tracking methods, such as the influence of visual angle, vehicle occlusion, and lack of continuous trajectories in 3D space, we propose an algorithm of vehicle spatial distribution and 3D trajectory extraction in cross-camera traffic scene. The main contributions of this paper are summarized as follows:
A method of road space fusion in cross-camera scenes based on camera calibration is proposed to generate a road panoramic image with physical information, which is used to convert cross-camera perspectives into 3D physical space.
A method of 3D vehicle detection based on geometric constraints is proposed to accurately obtain projection centroids of vehicles, which is used to describe vehicle spatial distribution in the panoramic image and 3D trajectory extraction of vehicles.
The rest of this paper is organized as follows. The proposed algorithm to complete vehicle spatial distribution and 3D trajectory extraction is illustrated in
Section 2. Experiment results and some comparison experiments are presented in
Section 3. Conclusions and future work are given out in
Section 4.
3. Results
In our experiments, we used the Intel Core i7-8700 CPU, NVIDIA 1080Ti GPU (Graphics Processing Unit), 32GB memory, and Windows 10 operating system. The open source framework Darknet is used for vehicle detection.
Experiments are carried out on the public dataset BrnoCompSpeed [
36] and actual road scene respectively, and the algorithm illustrated in
Section 2 is adopted in the experiments. First, road space fusion algorithm in cross-camera scenes is used to generate the panoramic image of road with spatial information. Secondly, YOLOv4 combined with geometric constraints is used for 3D vehicle detection to obtain projection centroids. Finally, the projection centroids are projected to the panoramic image to derive vehicle spatial distribution and 3D trajectories. The experiments can be divided into the following two aspects: (1) Verify the accuracy of projection centroids obtained by 3D vehicle detection algorithm for vehicle spatial distribution. (2) Compare the proposed 3D vehicle trajectory extraction algorithm with several 3D tracking methods in this paper.
3.1. BrnoCompSpeed Dataset Single-Camera Scene
Due to the lack of cross-camera datasets from road surveillance perspectives, we choose a public dataset of single-camera scenes from surveillance perspectives published by researchers of Brno University of Technology for our experiments. The cross-camera dataset made by ourselves and experiments carried out on this scene are described in detail in
Section 3.2.
The public dataset BrnoCompSpeed contains six traffic scenes captured by roadside surveillance cameras. Each scene can be divided into left, middle, and right perspectives, with a total of 18 HD (High Definition) videos (about 200 GB). The resolution of all the videos is 1920 × 1080. The dataset contains various types of vehicles such as hatch-back, sedan, SUV, truck and bus, and the position and velocity of vehicles are accurately recorded by radar. Therefore, this dataset can be used to verify the accuracy of vehicle spatial distribution and 3D trajectories in single-camera scenes.
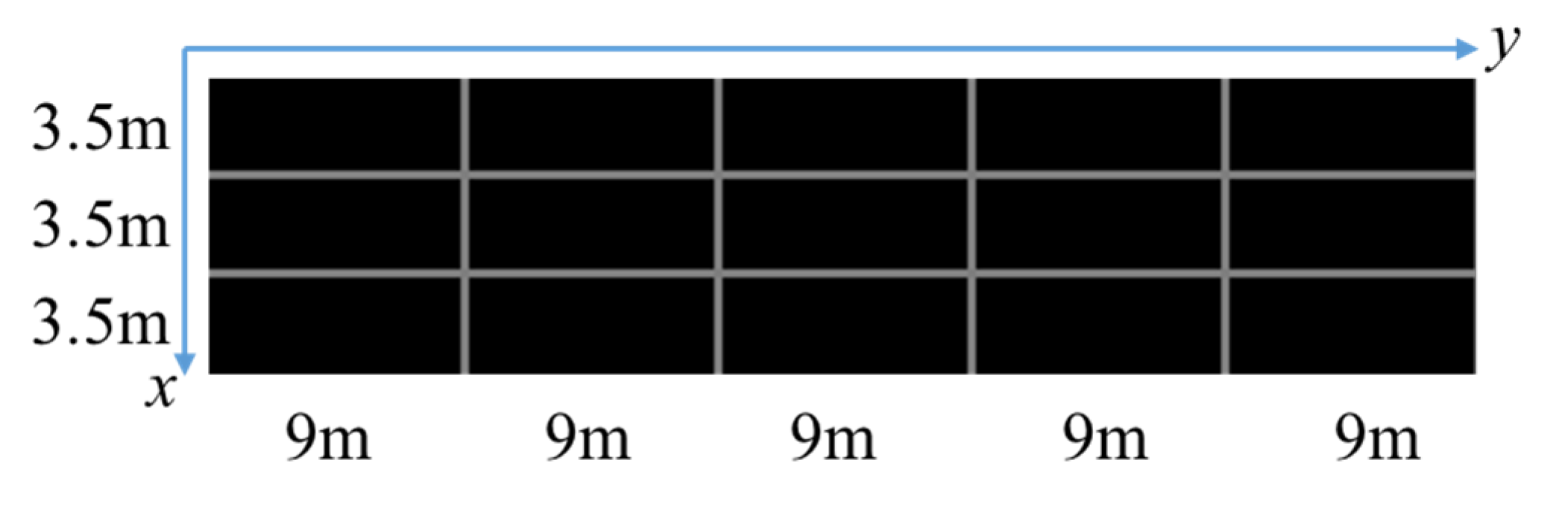
As shown in
Figure 10, we select three scenes of different perspectives from six scenes for verification which do not contain winding roads. In all the three scenes, the width of a single lane is 3.5 m, the length of a single short white marking line is 1.5 m, the length of a single long white marking line is 3 m, and the length between the starting points of the long white marking lines is 9 m. First, the three scenes are calibrated separately. Calibration results are shown in
Table 2. Based on calibration, the road space fusion algorithm described in
Section 2.2.2 is adopted to generate the panoramic image with physical information. Since the scenes in the dataset are single-camera scenes, we generate a roadblock containing physical information for convenience which is shown in
Figure 11. Each small square of the roadblock represents the actual road space size of 3.5 × 9 m.
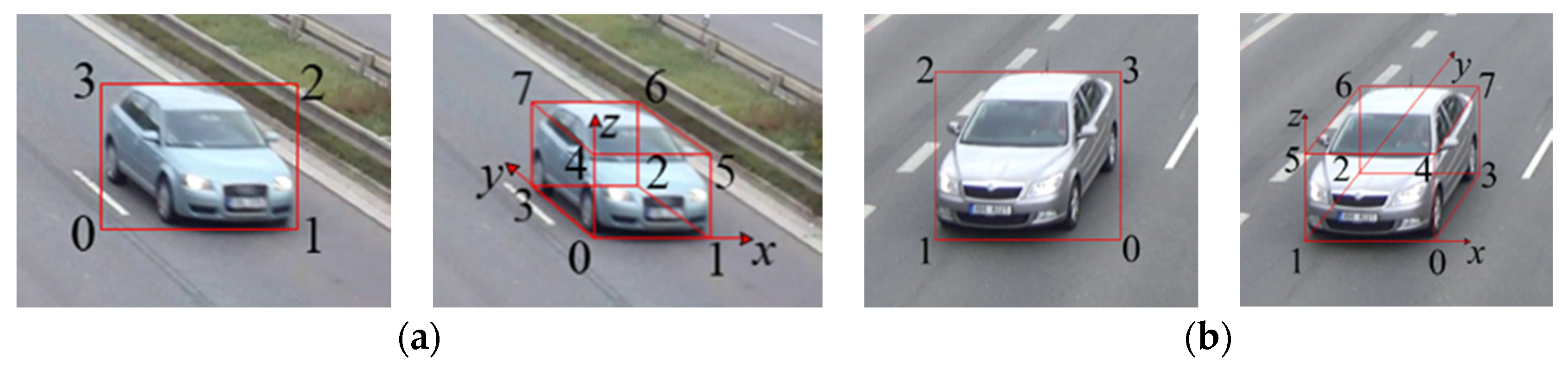
The real position of the vehicle in the world coordinate system is defined as
and the measured position is
. The effective field of view of the scene is set to
(m). Then, the vehicle spatial distribution error can be defined as:
Examples of the vehicle spatial distribution and 3D trajectories in dataset scenes are shown in
Figure 12. In this experiment,
is set to 450 m, and the base point in scene 2 can be selected using either left or right perspective. Each scene contains multiple vehicles, and there are some cases of vehicle occlusion. For each instance, the top image contains 3D vehicle detection and 2D trajectory results, and the roadblock on the bottom side contains vehicle spatial distribution and 3D trajectory results. Each vehicle corresponds to one color without repetition.
Table 3,
Table 4 and
Table 5 correspond to the 3D physical size, the image, and world coordinates and spatial distribution error of each vehicle in dataset scene 1 to scene 3. The value of y-axis in the world coordinate system is presented in an ascending order which indicates the distance between the vehicle and the camera is from near to far. To present the results in a straightforward way, the position and direction of the vehicle is marked in the roadblock with a white line segment and a white arrow respectively.
From the experimental results, it can be seen that the average error of vehicle spatial distribution within the scope of hundred meters is less than 5%, which means the accuracy can reach the centimeter level. In the meanwhile, the proposed algorithm is also adaptable to the situation of part vehicle occlusion.
3.2. Actual Road Cross-Camera Scene
To further verify the application ability of the proposed algorithm, we choose the actual road with large traffic flow which is located on the Middle Section of South Second Ring Road in Xi’an, ShaanXi Province, China to make a small dataset of cross-camera scenes. The dataset consists of three groups of HD videos (a total of six videos), and each of which is about 0.5 h long. The resolution of all the videos is 1280 × 720.
Figure 13 shows the image of the actual road scenes with no overlapping area which are taken by 2 cameras with a distance of 210 m. In the actual road scene, the road width is 7.5 m, the length of a single white marking line on the road plane is 6m, and the length between the starting points of the white marking lines is 11.80 m and 11.39 m in two scenes respectively. First, the scenes taken by two cameras are calibrated separately. Calibration results are shown in
Table 6. Based on calibration, the panoramic image with physical information is generated by the road space fusion algorithm described in
Section 2.2.2, which is shown in
Figure 14. A degree scale in the image represents an actual distance of the starting points of four white marking lines and 3.75 m in the image width and height direction.
In our experiment, we choose three examples of vehicles, which are shown in
Figure 15. For each example (similar to the dataset scene), 3D vehicle detection results in two cameras are shown in the first two lines respectively, and 3D vehicle trajectory extraction results are shown in the third line. Each vehicle corresponds to one color without repetition.
Table 7 shows the results of vehicle spatial distribution in actual road scene. Similar to the single-camera scenes, we mark the position and direction of the vehicle in the panoramic image with a green line segment and a white arrow, respectively. From the experimental results, it can be seen that continuous 3D trajectories of vehicles in cross-camera scenes can be effectively extracted.
As shown in
Figure 16, the proposed algorithm is compared with the 3D tracking methods based on feature point and 2D bounding box, which are represented by red, green, and orange respectively. It can be seen that the method based on feature point is greatly influenced by vehicle texture and surrounding environment, which cannot reflect true driving direction well, and may not be able to obtain continuous 3D trajectory under the condition of occlusion. The method based on 2D bounding box cannot accurately reflect the true driving position due to an unknown distance from bottom edge to the road plane. The proposed algorithm is superior to the existing methods because it can obtain accurate 3D vehicle bounding box, and is robust to vehicle occlusion and low visual angle of cameras. Comparison of the performance of several 3D tracking methods is summarized in
Table 8.
Since the proposed 3D vehicle detection algorithm is based on geometric constraints, the overall processing speed is fast. It can be seen from examples in
Figure 15, the average processing speed of our algorithm on the GPU platform is 16 FPS with an average time of 600 ms, which can achieve real-time performance.
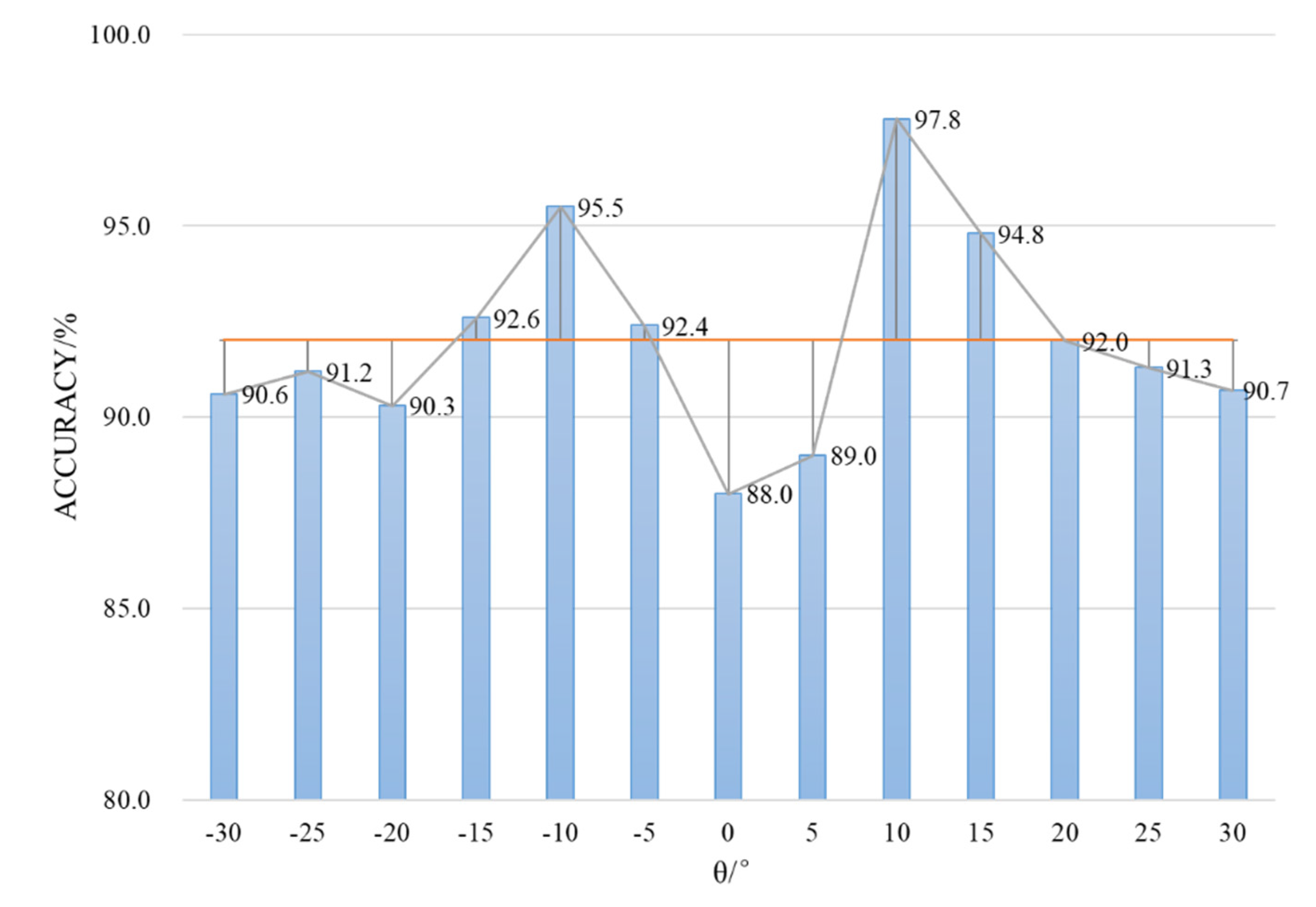
During the experiment, it can also be found that the accuracy of vehicle spatial distribution and 3D trajectory is related to the pan angle
of the camera. Therefore, we count the accuracy under different camera pan angles, which is shown in
Figure 17. When the pan angle is close to 0°, the information of the vehicle side surface is invisible, which leads to the decrease of 3D vehicle detection accuracy. In practical applications, the pan angle of the camera can be increased appropriately to retain most of the visual information of the vehicle.
4. Conclusions
Through experimental verification, the proposed algorithm of vehicle spatial distribution and 3D trajectory extraction in cross-camera scenes in this paper has achieved good results in both BrnoCompSpeed dataset single-camera scenes and actual road cross-camera scenes. The main contributions of this paper are as follows: (1) A road space fusion algorithm in cross-camera scenes based on camera calibration is proposed to generate the panoramic image with physical information in road space, which can be used to convert multiple cross-camera perspectives into continuous 3D physical space. (2) A 3D vehicle detection algorithm based on geometric constraints is proposed to accurately obtain 3D vehicle projection centroids, which is used to describe vehicle spatial distribution in the panoramic image and to extract 3D trajectories. Compared with existing vehicle tracking methods, continuous 3D trajectories can be obtained in the panoramic image with physical information by 3D projection centroids, which is helpful to applications in large scope road scenes.
However, 3D vehicle projection centroids obtained by the proposed algorithm in this paper is highly dependent on 2D vehicle detection results. When the vehicle is far from the camera, it is prone to be missed of detection and the accuracy will decrease when the camera pan angle is close to 0°. Moreover, the proposed algorithm cannot currently be adapted to various road situations and congested traffic. In future work, a more efficient method for road space fusion can be developed to generate the panoramic image and calculate vehicle spatial distribution more precisely and a more sophisticated vehicle detection network can be designed to fuse various types of geometric constraints to further improve the accuracy of 3D vehicle detection under different camera pan angles. In addition, only straight roads and simple traffic conditions are considered in this paper, which is necessary to be further extended to complex traffic scenes such as road-crossing (containing winding roads) and traffic congestion for more practical and advanced applications. Efforts are also needed to collect a large dataset of these complex traffic scenes for algorithm validation. This direction is a key and difficult point in the future work.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}