Meta-Transfer Learning Driven Tensor-Shot Detector for the Autonomous Localization and Recognition of Concealed Baggage Threats

 , , , ,
, , , , 

Abstract
1. Introduction
2. Related Work
2.1. Meta-Learning Frameworks
2.2. Traditional Machine Learning Methods
2.3. Deep Learning Methods
2.3.1. Supervised Approaches
2.3.2. Unsupervised Approaches
3. Contributions
- A novel meta-transfer learning based single-shot detector capable of recognizing baggage threats under extreme occlusion.
- A highly generalizable detection framework that leverages the proposed dual-tensor scheme to localize and recognize the threatening items from the diverse ranging scans without retraining the backbone on the large set of examples.
4. Proposed Framework
4.1. Preprocessing
Inconspicuous Edge Map Generation
4.2. Proposed Dual Tensor Scheme
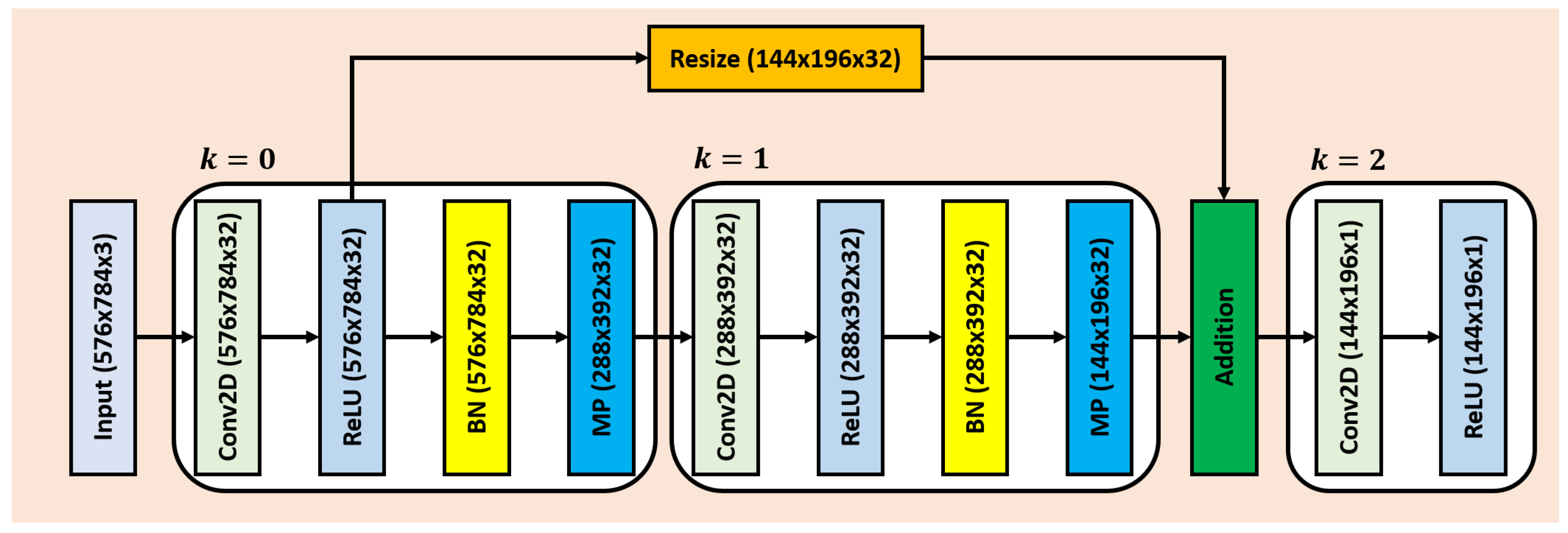
4.3. Edge Suppressing Backbone
4.4. Meta-One-Shot Classifier
4.5. Training via Meta-Transfer Learning
| Algorithm 1: Meta Transfer Learning Algorithm |
 |
4.6. Loss Function
5. Experimental Setup
5.1. Datasets
5.1.1. GRIMA X-ray Database
5.1.2. Security Inspection X-ray Dataset
5.2. Implementation Details
5.3. Evaluation Metrics
5.3.1. Intersection-over-Union
5.3.2. Dice Coefficient
5.3.3. Mean Average Precision
5.3.4. Confusion Matrix
5.3.5. Mean Squared Error
5.3.6. Qualitative Evaluations
6. Results
6.1. Ablation Study
6.1.1. Determining the Focal Loss Parameters
6.1.2. Determining the Classification Backbone
6.2. Evaluations on GDXray Dataset
6.3. Evaluations on SIXray Dataset
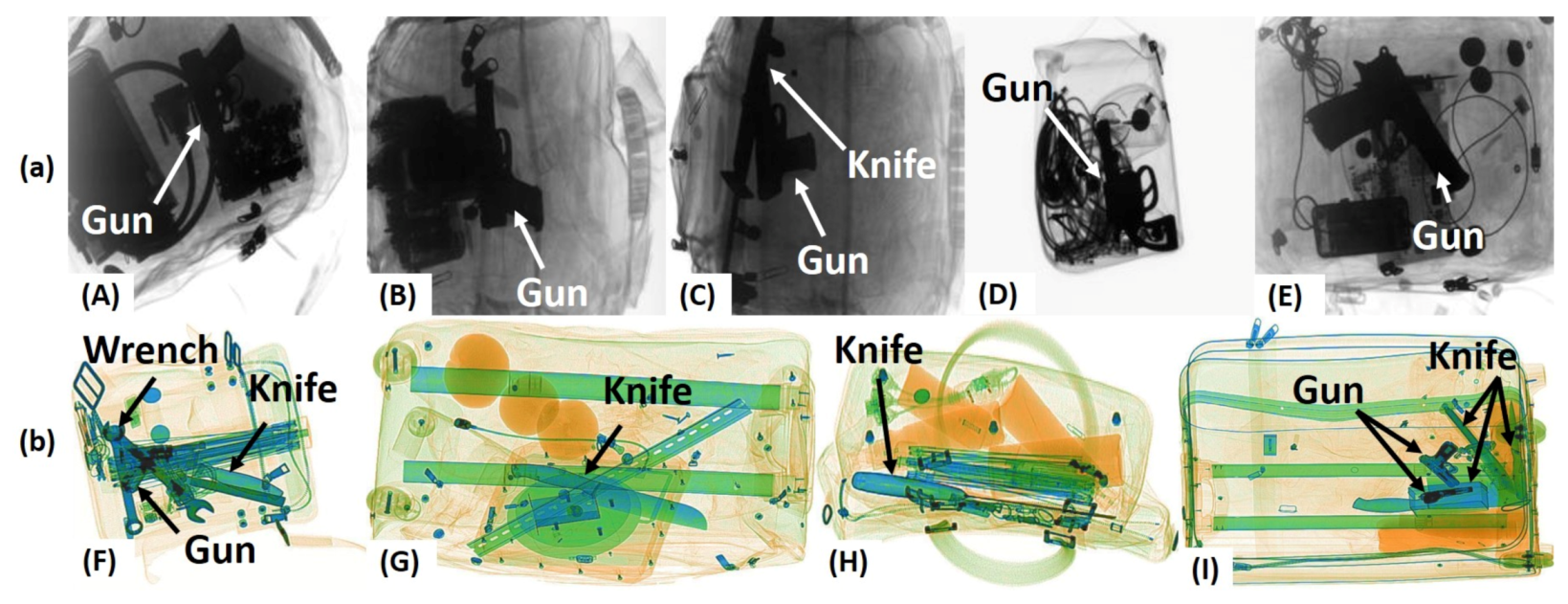
6.4. Qualitative Analysis
6.5. Generalizability Assessment
7. Discussion and Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- National Research Council. Airline Passenger Security Screening: New Technologies and Implementation Issues; National Academies Press: Washington, DC, USA, 1996. [Google Scholar]
- Cargo Screening. Aviation Security International. Available online: https://www.asi-mag.com/cargo-screening-improvement/ (accessed on 4 December 2019).
- Sterchi, Y.; Hattenschwiler, N.; Schwaninger, A. Detection measures for visual inspection of X-ray images of passenger baggage. Atten. Percept. Psychophys. 2019, 81, 1297–1311. [Google Scholar] [CrossRef] [PubMed]
- Wells, K.; Bradley, D. A Review of X-ray Explosives Detection Techniques for Checked Baggage. Appl. Radiat. Isot. 2012, 70, 1729–1746. [Google Scholar] [CrossRef] [PubMed]
- Hassan, T.; Bettayeb, M.; Akçay, S.; Khan, S.; Bennamoun, M.; Werghi, N. Detecting Prohibited Items in X-ray Images: A Contour Proposal Learning Approach. In Proceedings of the 27th IEEE International Conference on Image Processing (ICIP), Abu Dhabi, UAE, 25–28 October 2020; pp. 2016–2020. [Google Scholar]
- Bilsen, V.; Rademaekers, K.; Berden, K.; Zane, E.B.; Voldere, I.D.; Jans, G.; Mertens, K.; Regeczi, D.; Slingenberg, A.; Smakman, F.; et al. Study on the Competitiveness of the EU Eco-Industry; ECORYS Research and Publishing: Brussels, Belgium, 2009. [Google Scholar]
- Wells, K.; Bradley, D. Rethinking Checked Baggage Screening; Reason Public Policy Institute Policy Study: Los Angeles, CA, USA, 2002; p. 297. [Google Scholar]
- Bastan, M.; Byeon, W.; Breuel, T. Object Recognition in Multi-View Dual Energy X-ray Images. In Proceedings of the British Machine Vision Conference, Bristol, UK, 9–13 September 2013; p. 11. [Google Scholar]
- Akçay, S.; Kundegorski, M.E.; Willcocks, C.G.; Breckon, T.P. Using Deep Convolutional Neural Network Architectures for Object Classification and Detection Within X-ray Baggage Security Imagery. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2203–2215. [Google Scholar] [CrossRef]
- Gaus, Y.F.A.; Bhowmik, N.; Akçay, S.; Guillén-Garcia, P.M.; Barker, J.W.; Breckon, T.P. Evaluation of a Dual Convolutional Neural Network Architecture for Object-wise Anomaly Detection in Cluttered X-ray Security Imagery. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Hassan, T.; Akçay, S.; Bennamoun, M.; Khan, S.; Werghi, N. Trainable Structure Tensors for Autonomous Baggage Threat Detection Under Extreme Occlusion. arXiv 2020, arXiv:2009.13158. [Google Scholar]
- Akçay, S.; Kundegorski, M.E.; Devereux, M.; Breckon, T.P. Transfer learning using convolutional neural networks for object classification within X-ray baggage security imagery. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1057–1061. [Google Scholar]
- Wei, Y.; Tao, R.; Wu, Z.; Ma, Y.; Zhang, L.; Liu, X. Occluded Prohibited Items Detection: An X-ray Security Inspection Benchmark and De-occlusion Attention Module. arXiv 2020, arXiv:2004.08656. [Google Scholar]
- Miao, C.; Xie, L.; Wan, F.; Su, C.; Liu, H.; Jiao, J.; Ye, Q. SIXray: A Large-scale Security Inspection X-ray Benchmark for Prohibited Item Discovery in Overlapping Images. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 18–20 June 2019; pp. 2119–2128. [Google Scholar]
- Mery, D.; Riffo, V.; Zscherpel, U.; Mondragón, G.; Lillo, I.; Zuccar, I.; Lobel, H.; Carrasco, M. GDXray: The database of X-ray images for nondestructive testing. J. Nondestruct. Eval. 2015, 34, 42. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. arXiv 2017, arXiv:1703.03400. [Google Scholar]
- Sun, Q.; Liu, Y.; Chua, T.S.; Schiele, B. Meta-Transfer Learning for Few-Shot Learning. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 18–20 June 2019; pp. 403–412. [Google Scholar]
- Mery, D.; Svec, E.; Arias, M.; Riffo, V.; Saavedra, J.M.; Banerjee, S. Modern Computer Vision Techniques for X-Ray Testing in Baggage Inspection. IEEE Trans. Syst. Man Cybern. Syst. 2017, 4, 682–692. [Google Scholar] [CrossRef]
- Mery, D.; Saavedra, D.; Prasad, M. X-Ray Baggage Inspection With Computer Vision: A Survey. IEEE Access 2020, 8, 145620–145633. [Google Scholar] [CrossRef]
- Akçay, S.; Breckon, T. Towards Automatic Threat Detection: A Survey of Advances of Deep Learning within X-ray Security Imaging. arXiv 2020, arXiv:2001.01293. [Google Scholar]
- Wang, G.; Luo, C.; Sun, X.; Xiong, Z.; Zeng, W. Tracking by Instance Detection: A Meta-Learning Approach. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020; pp. 6288–6297. [Google Scholar]
- Hsu, K.; Levine, S.; Finn, C. Unsupervised Learning via Meta-Learning. arXiv 2018, arXiv:1810.02334. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching Networks for One Shot Learning. In Proceedings of the Neural Information Processing Systems (NIPS), Barcelona, Spain, 6–12 December 2016; pp. 3630–3638. [Google Scholar]
- Oreshkin, B.N.; Rodrıguez, P.; Lacoste, A. TADAM: Task dependent adaptive metric for improved few-shot learning. In Proceedings of the Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 3–8 December 2018; pp. 721–731. [Google Scholar]
- Turcsany, D.; Mouton, A.; Breckon, T.P. Improving Feature-based Object Recognition for X-ray Baggage Security Screening using Primed Visual Words. In Proceedings of the 2013 IEEE International Conference on Industrial Technology (ICIT), Cape Town, South Africa, 25–28 February 2013; pp. 1140–1145. [Google Scholar]
- Heitz, G.; Chechik, G. Object Separation in X-ray Image Sets. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2093–2100. [Google Scholar]
- Baştan, M. Multi-view Object Detection In Dual-energy X-ray Images. Mach. Vis. Appl. 2015, 26, 1045–1060. [Google Scholar] [CrossRef]
- Baştan, M.; Yousefi, M.R.; Breuel, T.M. Visual Words on Baggage X-ray Images. In Proceedings of the 14th International Conference on Computer Analysis of Images and Patterns, Seville, Spain, 29–31 August 2011; pp. 360–368. [Google Scholar]
- Kundegorski, M.E.; Akçay, S.; Devereux, M.; Mouton, A.; Breckons, T.P. On using Feature Descriptors as Visual Words for Object Detection within X-ray Baggage Security Screening. In Proceedings of the IEEE International Conference on Imaging for Crime Detection and Prevention (ICDP), Madrid, Spain, 23–25 November 2016; pp. 1–6. [Google Scholar]
- Mery, D.; Svec, E.; Arias, M. Object Recognition in Baggage Inspection Using Adaptive Sparse Representations of X-ray Images. In Pacific-Rim Symposium on Image and Video Technology; Springer: Cham, Switzerland, 2016; pp. 709–720. [Google Scholar]
- Riffo, V.; Mery, D. Automated Detection of Threat Objects Using Adapted Implicit Shape Model. IEEE Trans. Syst. Man Cybern. Syst. 2016, 46, 472–482. [Google Scholar] [CrossRef]
- Liu, Z.; Li, J.; Shu, Y.; Zhang, D. Detection and Recognition of Security Detection Object Based on YOLO9000. In Proceedings of the 2018 5th International Conference on Systems and Informatics (ICSAI), Nanjing, China, 10–12 November 2018; pp. 278–282. [Google Scholar]
- Jain, D.K. An evaluation of deep learning based object detection strategies for threat object detection in baggage security imagery. Pattern Recognit. Lett. 2019, 120, 112–119. [Google Scholar]
- Xu, M.; Zhang, H.; Yang, J. Prohibited Item Detection in Airport X-Ray Security Images via Attention Mechanism Based CNN. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision, Guangzhou, China, 23–26 November 2018; pp. 429–439. [Google Scholar]
- Jaccard, N.; Rogers, T.W.; Morton, E.; Griffin, L.D. Detection of Concealed Cars In Complex Cargo X-ray Imagery Using Deep Learning. J. X-ray Sci. Technol. 2017, 25, 323–339. [Google Scholar] [CrossRef]
- Griffin, L.D.; Caldwell, M.; Andrews, J.T.A.; Bohler, H. “Unexpected Item in the Bagging Area”: Anomaly Detection in X-Ray Security Images. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1539–1553. [Google Scholar] [CrossRef]
- An, J.; Zhang, H.; Zhu, Y.; Yang, J. Semantic Segmentation for Prohibited Items in Baggage Inspection. In Proceedings of the International Conference on Intelligence Science and Big Data Engineering Visual Data Engineering, Nanjing, China, 17–20 October 2019; pp. 495–505. [Google Scholar]
- Zou, L.; Yusuke, T.; Hitoshi, I. Dangerous Objects Detection of X-Ray Images Using Convolution Neural Network. In Security with Intelligent Computing and Big-data Services; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 29th Conference on Neural Information Processing Systems (NIPS 2015), Montreal, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Xiao, H.; Zhu, F.; Zhang, R.; Cheng, Z.; Wang, H.; Alesund, N.; Dai, H.; Zhou, Y. R-PCNN Method to Rapidly Detect Objects on THz Images in Human Body Security Checks. In Proceedings of the IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation, Guangzhou, China, 8–12 October 2018; pp. 1777–1782. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-Level Accuracy with 50× Fewer Parameters and <0.5 MB Model Size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems (NIPS 2012), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1106–1114. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Gaus, Y.F.A.; Bhowmik, N.; Akcay, S.; Breckon, T. Evaluating the Transferability and Adversarial Discrimination of Convolutional Neural Networks for Threat Object Detection and Classification within X-Ray Security Imagery. arXiv 2019, arXiv:1911.08966. [Google Scholar]
- Akçay, S.; Atapour-Abarghouei, A.; Breckon, T.P. GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training. In Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2018; pp. 622–637. [Google Scholar]
- Akçay, S.; Atapour-Abarghouei, A.; Breckon, T.P. Skip-GANomaly: Skip Connected and Adversarially Trained Encoder-Decoder Anomaly Detection. arXiv 2019, arXiv:1901.08954. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS – Improving Object Detection With One Line of Code. In Proceedings of the International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Bigun, J.; Granlund, G. Optimal Orientation Detection of Linear Symmetry. In Proceedings of the 1st International Conference on Computer Vision (ICCV), London, UK, 8–11 July 1987; pp. 433–438. [Google Scholar]
- Sun, Y.; Zuo, W.; Liu, M. RTFNet: RGB-Thermal Fusion Network for Semantic Segmentation of Urban Scenes. IEEE Robot. Autom. Lett. 2019, 4, 2576–2583. [Google Scholar] [CrossRef]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. FuseNet: Incorporating Depth into Semantic Segmentation via Fusion-based CNN Architecture. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 22–24 November 2016; pp. 213–228. [Google Scholar]
- European Commission. List of Prohibited Articles in your Cabin Baggage. Mobil Transp. Available online: https://ec.europa.eu/transport/sites/transport/files/modes/air/security/doc/info_travellers_hand_luggage.pdf (accessed on 1 October 2020).
- Chui, K.T.; Liu, R.W.; Zhao, M.; Pablos, P.O.D. Predicting Students’ Performance With School and Family Tutoring Using Generative Adversarial Network-Based Deep Support Vector Machine. IEEE Access 2020, 8, 86745–86752. [Google Scholar] [CrossRef]
- Fayed, H.A.; Atiya, A.F. Speed up grid-search for parameter selection of support vector machines. Appl. Soft Comput. 2019, 80, 202–210. [Google Scholar] [CrossRef]
- Tan, P.N.; Steinbach, M.; Kumar, V. Introduction to Data Mining; Pearson: London, UK, 2005; ISBN 0-321-32136-7. [Google Scholar]
- Murguia, M.; Villasenor, J.L. Estimating the effect of the similarity coefficient and the cluster algorithm on biogeographic classifications. Ann. Bot. Fenn. 2003, 40, 415–421. [Google Scholar]
- Pishro-Nik, H. Introduction to Probability, Statistics, and Random Processes; Kappa Research LLC: Sunderland, MA, USA, 2014; ISBN 0990637204. [Google Scholar]
- Riffo, V.; Mery, D. Active X-ray testing of complex objects. Insight Non Destr. Test. Cond. Monit. 2012, 54, 28–35. [Google Scholar] [CrossRef][Green Version]
- Mery, D. Automated detection in complex objects using a tracking algorithm in multiple X-ray views. In Proceedings of the IEEE CVPR 2011 Workshops, Colorado Springs, CO, USA, 20–25 June 2011; pp. 41–48. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | Methodology | Performance | Limitations |
|---|---|---|---|
| Miao et al. [14] | Developed CHR [14], an imbalanced resistant framework that leverages reversed connections class-balanced loss function to effectively learn the imbalanced suspicious item categories in a highly imbalanced SIXray [14] dataset. | Achieved an overall mean average precision score of 0.793, 0.606, and 0.381 on SIXray10, SIXray100, and SIXray1000 [14], respectively when coupled with ResNet-101 [46] for recognizing five suspicious item categories. | Although the framework is resistant to an imbalanced dataset, it is still tested only on a single dataset. |
| Hassan et al. [11] | Proposed a contour instance segmentation framework for recognizing baggage threats regardless of the scanner specifications. | Achieved a mean average precision score of 0.4657 on a total of 223,686 multivendor baggage X-ray scans. | Built upon a conventional fine-tuning approach that requires a large-scale training dataset. |
| Gaus et al. [51] | Evaluated the transferability of different one-staged and two-staged object detection and instance segmentation models on SIXray10 [14] subset of the SIXray [14] dataset and also on their locally prepared dataset. | Achieved a mean average precision of 0.8500 for extracting guns and knives on SIXray10 [14] dataset. | Tested on only one public dataset i.e., the SIXray10 [14] for only extracting guns and knives. |
| Wei et al. [13] | Proposed a plug-and-play module dubbed DOAM [13] that can be integrated with the deep object detectors to recognize and localized the occluded threatening items. | Achieved the mean average precision score of 0.740 coupled with SSD [54]. | DOAM [13] is not tested on publicly available GDXray [15] and SIXray [14] datasets. |
| Hassan et al. [5] | Developed a CST framework that leverages contours of the baggage content to generate object proposals that are screened via a single classification backbone. | Achieved a mean average precision score of 0.9343 and 0.9595 on GDXray [15] and SIXray [14] datasets. | CST, although, is tested on two public datasets, but it requires extensive parameter tuning to work well on both of them. |
| GDXray [15] | ||||
|---|---|---|---|---|
| 0.25 | 0.5 | 0.75 | ||
| 1 | 0.9059 | 0.8742 | 0.8693 | |
| 2 | 0.9162 | 0.8916 | 0.8869 | |
| 3 | 0.9143 | 0.8882 | 0.8807 | |
| 4 | 0.9017 | 0.8834 | 0.8762 | |
| 5 | 0.9064 | 0.8763 | 0.8691 | |
| SIXray [14] | ||||
| 0.25 | 0.5 | 0.75 | ||
| 1 | 0.5483 | 0.5140 | 0.4926 | |
| 2 | 0.6457 | 0.6283 | 0.6182 | |
| 3 | 0.6283 | 0.6036 | 0.5874 | |
| 4 | 0.6156 | 0.5709 | 0.5370 | |
| 5 | 0.6083 | 0.5472 | 0.5198 | |
| Network | GDXray [15] | SIXray10 [14] | SIXray100 [14] | SIXray1000 [14] | SIXray [14] * |
|---|---|---|---|---|---|
| VGG-16 [48] | 0.8691 | 0.7583 | 0.5721 | 0.4126 | 0.5810 |
| ResNet-50 [46] | 0.8917 | 0.7826 | 0.6284 | 0.4392 | 0.5915 |
| ResNet-101 [46] | 0.9162 | 0.8053 | 0.6791 | 0.4527 | 0.6457 |
| Dataset | Metric | Proposed | [14] | [51] | [33] | [31] | [65] | [66] |
|---|---|---|---|---|---|---|---|---|
| GDXray [15] | mean IoU | 0.9118 | - | - | - | - | - | - |
| mean DC | 0.9536 | - | - | - | - | - | - | |
| mAP | 0.9162 | - | - | - | - | - | - | |
| Accuracy | 0.9554 | - | - | 0.9840 | 0.9500 | - | - | |
| TPR | 0.9761 | - | - | 0.9800 | - | 0.8900 | 0.9430 | |
| TNR | 0.9305 | - | - | - | 0.9140 | - | 0.9440 | |
| FPR | 0.0694 | - | - | - | 0.0860 | - | 0.0560 | |
| PPV | 0.9441 | - | - | 0.9300 | - | 0.9200 | - | |
| F1 | 0.9598 | - | - | 0.9543 | - | 0.9047 | - | |
| SIXray [14] * | mean IoU | 0.9238 | - | - | - | - | - | - |
| mean DC | 0.9603 | - | - | - | - | - | - | |
| mAP | 0.6457 | 0.5938 | 0.8500 | - | - | - | - | |
| Accuracy | 0.8949 | 0.4577 | - | - | - | |||
| TPR | 0.8127 | - | - | - | - | |||
| TNR | 0.8956 | - | - | - | - | |||
| FPR | 0.1043 | - | - | - | - | |||
| PPV | 0.0621 | - | - | - | - | |||
| F1 | 0.1153 | - | - | - | - | - | - |
| Dataset | Items | Proposed | [14] | [51] | [5] |
|---|---|---|---|---|---|
| GDXray [15] | Handguns | 0.001436 | - | - | 0.008082 |
| Knives | 0.002683 | - | - | 0.000030 | |
| Razors | 0.007586 | - | - | 0.013782 | |
| Shuriken | 0.001459 | - | - | 0.000068 | |
| Mean | 0.003291 | - | - | 0.005490 | |
| STD | 0.002530 | - | - | 0.005802 | |
| SIXray [14] | Guns | 0.021874 | 0.018496 | 0.006400 | 0.000079 |
| Knives | 0.030905 | 0.021432 | 0.044100 | 0.004264 | |
| Wrenches | 0.060614 | 0.101251 | - | 0.000072 | |
| Scissors | 0.134762 | 0.166219 | - | 0.000038 | |
| Pliers | 0.087971 | 0.030241 | - | 0.005372 | |
| Mean | 0.067225 | 0.067528 | 0.025250 * | 0.001965 | |
| STD | 0.041015 | 0.057959 | 0.018850 * | 0.002355 |
| Level of Clutter and Concealment | Proposed | |
|---|---|---|
| Low | 0.7816 | 0.7453 |
| Partial or mild | 0.6593 | 0.5918 |
| Full or extreme | 0.5201 | 0.4632 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassan, T.; Shafay, M.; Akçay, S.; Khan, S.; Bennamoun, M.; Damiani, E.; Werghi, N. Meta-Transfer Learning Driven Tensor-Shot Detector for the Autonomous Localization and Recognition of Concealed Baggage Threats. Sensors 2020, 20, 6450. https://doi.org/10.3390/s20226450
Hassan T, Shafay M, Akçay S, Khan S, Bennamoun M, Damiani E, Werghi N. Meta-Transfer Learning Driven Tensor-Shot Detector for the Autonomous Localization and Recognition of Concealed Baggage Threats. Sensors. 2020; 20(22):6450. https://doi.org/10.3390/s20226450
Chicago/Turabian StyleHassan, Taimur, Muhammad Shafay, Samet Akçay, Salman Khan, Mohammed Bennamoun, Ernesto Damiani, and Naoufel Werghi. 2020. "Meta-Transfer Learning Driven Tensor-Shot Detector for the Autonomous Localization and Recognition of Concealed Baggage Threats" Sensors 20, no. 22: 6450. https://doi.org/10.3390/s20226450
APA StyleHassan, T., Shafay, M., Akçay, S., Khan, S., Bennamoun, M., Damiani, E., & Werghi, N. (2020). Meta-Transfer Learning Driven Tensor-Shot Detector for the Autonomous Localization and Recognition of Concealed Baggage Threats. Sensors, 20(22), 6450. https://doi.org/10.3390/s20226450